S-ar putea să vă placă și
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsDe la EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsÎncă nu există evaluări
- Cheat SheetDocument2 paginiCheat SheetVarun NagpalÎncă nu există evaluări
- Christian Notes For Exam PDocument9 paginiChristian Notes For Exam Proy_getty100% (1)
- Actuarial Probability Exam (P): Passbooks Study GuideDe la EverandActuarial Probability Exam (P): Passbooks Study GuideÎncă nu există evaluări
- Guo-Deeper Understanding Faster Calc SOA MFE PDFDocument538 paginiGuo-Deeper Understanding Faster Calc SOA MFE PDFPierre-Louis TruchetÎncă nu există evaluări
- FM GuoDocument664 paginiFM GuoLoh Hui Yin86% (7)
- Deeper Understanding, Faster Calculation - Exam P Insights and ShortcutsDocument432 paginiDeeper Understanding, Faster Calculation - Exam P Insights and ShortcutsSteven Lai88% (8)
- Distribution Name Parameters and Domains Important FactsDocument4 paginiDistribution Name Parameters and Domains Important FactsKhurram ShahzadÎncă nu există evaluări
- SOA Exam P Sample SolutionsDocument68 paginiSOA Exam P Sample SolutionsInvisibleOzymandiasÎncă nu există evaluări
- Deeper Understanding Fall 08 Manual For FMDocument625 paginiDeeper Understanding Fall 08 Manual For FMAbdur RehmanÎncă nu există evaluări
- Exam PDocument517 paginiExam PHuy Do TruongÎncă nu există evaluări
- A&J Study Manual For SOA Exam FM/ CAS Exam 2Document19 paginiA&J Study Manual For SOA Exam FM/ CAS Exam 2anjstudymanual70% (10)
- Deeper Understanding Spring 11 Manual For PDocument443 paginiDeeper Understanding Spring 11 Manual For PJordan Zipkin100% (2)
- Exam P Practice Exam by Jared NakamuraDocument63 paginiExam P Practice Exam by Jared NakamuratomÎncă nu există evaluări
- Exam P FormulasDocument2 paginiExam P Formulasasdfg888100% (1)
- Soa Exam PDocument10 paginiSoa Exam PAnonymous ZL37my2K100% (1)
- Probability Distributions Summary - Exam PDocument1 paginăProbability Distributions Summary - Exam Proy_gettyÎncă nu există evaluări
- Practise Exam PDocument20 paginiPractise Exam PJosh ShielsÎncă nu există evaluări
- FM (Actuary Exam) FormulasDocument15 paginiFM (Actuary Exam) Formulasmuffinslayers100% (1)
- Guo Spring 08 PDocument434 paginiGuo Spring 08 PYutaro TanakaÎncă nu există evaluări
- SOA Exam MFE Flash CardsDocument21 paginiSOA Exam MFE Flash CardsSong Liu100% (2)
- A&J Flashcards For SOA Exam P/CAS Exam 1Document28 paginiA&J Flashcards For SOA Exam P/CAS Exam 1anjstudymanualÎncă nu există evaluări
- 1 Math Fundamentals: 1.1 Integrals, Factors and TechniquesDocument11 pagini1 Math Fundamentals: 1.1 Integrals, Factors and Techniquesroy_gettyÎncă nu există evaluări
- Formulas For SOA/CAS Exam FM/2Document15 paginiFormulas For SOA/CAS Exam FM/2jeff_cunningham_11100% (3)
- Exam C Manual PDFDocument2 paginiExam C Manual PDFJohnathan0% (1)
- ADAPT Formula Sheet PDFDocument2 paginiADAPT Formula Sheet PDFMariahDeniseCarumbaÎncă nu există evaluări
- Probability ExercisesDocument43 paginiProbability ExerciseshaffaÎncă nu există evaluări
- FM All ExercisesDocument115 paginiFM All Exercisesgy5115123Încă nu există evaluări
- Exam FM Practice Exam With Answer KeyDocument71 paginiExam FM Practice Exam With Answer KeyAki TsukiyomiÎncă nu există evaluări
- Guo S Manuals SOA Exam C PDFDocument284 paginiGuo S Manuals SOA Exam C PDFAustin FritzkeÎncă nu există evaluări
- GUO P ManualDocument432 paginiGUO P ManualYiran CaoÎncă nu există evaluări
- Examp Formula SheetsDocument6 paginiExamp Formula SheetsSanjay GhimireÎncă nu există evaluări
- DUMLC Guo ManualDocument68 paginiDUMLC Guo ManualJose Martinez-Gracida50% (2)
- Arch MLCDocument471 paginiArch MLCStéphanie Gagnon100% (3)
- Extensive Form Games: ECON2112Document38 paginiExtensive Form Games: ECON2112leobe89Încă nu există evaluări
- Acturarial Mathematics - BowersDocument780 paginiActurarial Mathematics - BowersEstefanía Luna Flores100% (1)
- Exam LTAM: You Have What It Takes To PassDocument12 paginiExam LTAM: You Have What It Takes To Passderianfg100% (1)
- Sample Chapter From Yufeng Guo's Study GuideDocument22 paginiSample Chapter From Yufeng Guo's Study Guide赤铁炎Încă nu există evaluări
- A&J Questions Bank For SOA Exam MFE/ CAS Exam 3FDocument24 paginiA&J Questions Bank For SOA Exam MFE/ CAS Exam 3Fanjstudymanual100% (1)
- Slides PDFDocument418 paginiSlides PDFvikasÎncă nu există evaluări
- Formulas For The MFE ExamDocument17 paginiFormulas For The MFE ExamrortianÎncă nu există evaluări
- MFE ManualDocument549 paginiMFE Manualashtan100% (1)
- Calculus Review and Formulas: 1 FunctionsDocument11 paginiCalculus Review and Formulas: 1 FunctionsRaymond BalladÎncă nu există evaluări
- Functions of A Real Variable: Unit 1Document9 paginiFunctions of A Real Variable: Unit 1Anonymous TlGnQZv5d7Încă nu există evaluări
- AssigmentsDocument12 paginiAssigmentsShakuntala Khamesra100% (1)
- Euclid Notes 2 Polynomials and FloorDocument7 paginiEuclid Notes 2 Polynomials and FloorHappy Dolphin100% (1)
- Tutorials MathsDocument6 paginiTutorials MathssaraaanshÎncă nu există evaluări
- Mathematics Cheat Sheet For Population Biology: James Holland JonesDocument9 paginiMathematics Cheat Sheet For Population Biology: James Holland JonesDinesh BarupalÎncă nu există evaluări
- SAT Subject Math Level 2 FactsDocument11 paginiSAT Subject Math Level 2 FactsSalvadorÎncă nu există evaluări
- Durrett Probability Theory and Examples Solutions PDFDocument122 paginiDurrett Probability Theory and Examples Solutions PDFKristian Mamforte73% (15)
- Materi PolynomialDocument20 paginiMateri PolynomialnormasulasaÎncă nu există evaluări
- Brouwer Homework 1Document7 paginiBrouwer Homework 1James RavorÎncă nu există evaluări
- The Polynomials: 0 1 2 2 N N 0 1 2 N NDocument29 paginiThe Polynomials: 0 1 2 2 N N 0 1 2 N NKaran100% (1)
- Year 10 Maths YearliesDocument29 paginiYear 10 Maths YearliesMusab AlbarbariÎncă nu există evaluări
- Chapter 4. Extrema and Double Integrals: Section 4.1: Extrema, Second Derivative TestDocument6 paginiChapter 4. Extrema and Double Integrals: Section 4.1: Extrema, Second Derivative TestStelios KondosÎncă nu există evaluări
- Quantum Mechanics Math ReviewDocument5 paginiQuantum Mechanics Math Reviewstrumnalong27Încă nu există evaluări
- Hw2 - Raymond Von Mizener - Chirag MahapatraDocument13 paginiHw2 - Raymond Von Mizener - Chirag Mahapatrakob265Încă nu există evaluări
- Maths Model Paper 2Document7 paginiMaths Model Paper 2ravibiriÎncă nu există evaluări
- Lectures 1141Document314 paginiLectures 1141BoredÎncă nu există evaluări
- Does Adding Salt To Water Makes It Boil FasterDocument1 paginăDoes Adding Salt To Water Makes It Boil Fasterfelixcouture2007Încă nu există evaluări
- FT2020Document7 paginiFT2020Sam SparksÎncă nu există evaluări
- Manhole Head LossesDocument11 paginiManhole Head Lossesjoseph_mscÎncă nu există evaluări
- SievesDocument3 paginiSievesVann AnthonyÎncă nu există evaluări
- CPD - SampleDocument3 paginiCPD - SampleLe Anh DungÎncă nu există evaluări
- Audi A4-7Document532 paginiAudi A4-7Anonymous QRVqOsa5Încă nu există evaluări
- 2013-01-28 203445 International Fault Codes Eges350 DTCDocument8 pagini2013-01-28 203445 International Fault Codes Eges350 DTCVeterano del CaminoÎncă nu există evaluări
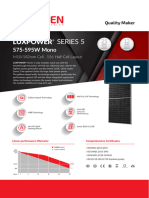
- Ficha Técnica Panel Solar 590W LuxenDocument2 paginiFicha Técnica Panel Solar 590W LuxenyolmarcfÎncă nu există evaluări
- SAMPLE MCQuestions ByTopicsDocument45 paginiSAMPLE MCQuestions ByTopicsVeeru ManikantaÎncă nu există evaluări
- DTR Testastretta Valve Adjustment ProcedureDocument10 paginiDTR Testastretta Valve Adjustment ProcedureTony LamprechtÎncă nu există evaluări
- Atmel 46003 SE M90E32AS DatasheetDocument84 paginiAtmel 46003 SE M90E32AS DatasheetNagarajÎncă nu există evaluări
- Ultra Electronics Gunfire LocatorDocument10 paginiUltra Electronics Gunfire LocatorPredatorBDU.comÎncă nu există evaluări
- Tomb of Archimedes (Sources)Document3 paginiTomb of Archimedes (Sources)Petro VourisÎncă nu există evaluări
- Class 12 Physics Derivations Shobhit NirwanDocument6 paginiClass 12 Physics Derivations Shobhit Nirwanaastha.sawlaniÎncă nu există evaluări
- BECED S4 Motivational Techniques PDFDocument11 paginiBECED S4 Motivational Techniques PDFAmeil OrindayÎncă nu există evaluări
- EPW, Vol.58, Issue No.44, 04 Nov 2023Document66 paginiEPW, Vol.58, Issue No.44, 04 Nov 2023akashupscmadeeaseÎncă nu există evaluări
- Multiple Choice Practice Questions For Online/Omr AITT-2020 Instrument MechanicDocument58 paginiMultiple Choice Practice Questions For Online/Omr AITT-2020 Instrument Mechanicمصطفى شاكر محمودÎncă nu există evaluări
- Executive Summary: 2013 Edelman Trust BarometerDocument12 paginiExecutive Summary: 2013 Edelman Trust BarometerEdelman100% (4)
- Waste Biorefinery Models Towards Sustainable Circular Bioeconomy Critical Review and Future Perspectives2016bioresource Technology PDFDocument11 paginiWaste Biorefinery Models Towards Sustainable Circular Bioeconomy Critical Review and Future Perspectives2016bioresource Technology PDFdatinov100% (1)
- MATH CIDAM - PRECALCULUS (Midterm)Document4 paginiMATH CIDAM - PRECALCULUS (Midterm)Amy MendiolaÎncă nu există evaluări
- TM Mic Opmaint EngDocument186 paginiTM Mic Opmaint Engkisedi2001100% (2)
- LG LFX31945 Refrigerator Service Manual MFL62188076 - Signature2 Brand DID PDFDocument95 paginiLG LFX31945 Refrigerator Service Manual MFL62188076 - Signature2 Brand DID PDFplasmapete71% (7)
- Types of Chemical Reactions: Synthesis and DecompositionDocument3 paginiTypes of Chemical Reactions: Synthesis and DecompositionAlan MartínÎncă nu există evaluări
- BPS C1: Compact All-Rounder in Banknote ProcessingDocument2 paginiBPS C1: Compact All-Rounder in Banknote ProcessingMalik of ChakwalÎncă nu există evaluări
- Jurnal Job DescriptionDocument13 paginiJurnal Job DescriptionAji Mulia PrasÎncă nu există evaluări
- Source:: APJMR-Socio-Economic-Impact-of-Business-Establishments - PDF (Lpubatangas - Edu.ph)Document2 paginiSource:: APJMR-Socio-Economic-Impact-of-Business-Establishments - PDF (Lpubatangas - Edu.ph)Ian EncarnacionÎncă nu există evaluări
- Cash Flow July 2021Document25 paginiCash Flow July 2021pratima jadhavÎncă nu există evaluări
- Intelligent Status Monitoring System For Port Machinery: RMGC/RTGCDocument2 paginiIntelligent Status Monitoring System For Port Machinery: RMGC/RTGCfatsahÎncă nu există evaluări
- Leveriza Heights SubdivisionDocument4 paginiLeveriza Heights SubdivisionTabordan AlmaeÎncă nu există evaluări
- str-w6754 Ds enDocument8 paginistr-w6754 Ds enAdah BumbonÎncă nu există evaluări
- Calculus Workbook For Dummies with Online PracticeDe la EverandCalculus Workbook For Dummies with Online PracticeEvaluare: 3.5 din 5 stele3.5/5 (8)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeDe la EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeEvaluare: 4 din 5 stele4/5 (2)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsDe la EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsEvaluare: 4.5 din 5 stele4.5/5 (3)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingDe la EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingEvaluare: 4.5 din 5 stele4.5/5 (21)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)De la EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Încă nu există evaluări
- Mental Math Secrets - How To Be a Human CalculatorDe la EverandMental Math Secrets - How To Be a Human CalculatorEvaluare: 5 din 5 stele5/5 (3)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryDe la EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryÎncă nu există evaluări
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.De la EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Evaluare: 5 din 5 stele5/5 (1)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsDe la EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsEvaluare: 3.5 din 5 stele3.5/5 (9)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormDe la EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormEvaluare: 5 din 5 stele5/5 (5)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathDe la EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathEvaluare: 5 din 5 stele5/5 (1)