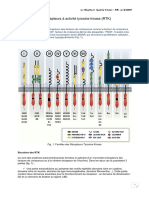
S-ar putea să vă placă și
- Appretement Et Presentation de L'agDocument41 paginiAppretement Et Presentation de L'agAnonymous FGGLsjzWi100% (2)
- Directives pour l'élaboration d'une stratégie nationale pour les ressources phytogénétiques pour l'alimentation et l'agricultureDe la EverandDirectives pour l'élaboration d'une stratégie nationale pour les ressources phytogénétiques pour l'alimentation et l'agricultureÎncă nu există evaluări
- Filiere Viande RougeDocument1 paginăFiliere Viande RougeIlyasse Ait HaddouÎncă nu există evaluări
- Chapitre I Généralités Sur Le Lait en Cours de FinalisationDocument15 paginiChapitre I Généralités Sur Le Lait en Cours de FinalisationAicha's PenÎncă nu există evaluări
- Biostatistiques. SakraniDocument77 paginiBiostatistiques. Sakraniamina aminaÎncă nu există evaluări
- Dynamique Du Systeme AlimentaireDocument9 paginiDynamique Du Systeme AlimentaireCristina EniÎncă nu există evaluări
- Les Biotechnologies RougesDocument6 paginiLes Biotechnologies RougesYohann LecroartÎncă nu există evaluări
- L'allergieDocument11 paginiL'allergieAbbassiÎncă nu există evaluări
- 01b-La Normalisation en AlgérieDocument15 pagini01b-La Normalisation en AlgérieLydia HAMCHAOUIÎncă nu există evaluări
- These217 19Document194 paginiThese217 19GlâdyâŤór GírLÎncă nu există evaluări
- Abattoire Oujda PDFDocument21 paginiAbattoire Oujda PDFSimo CharafÎncă nu există evaluări
- Récepteur de La Superfamille TNF AlphaDocument28 paginiRécepteur de La Superfamille TNF AlphaFatima ZahraÎncă nu există evaluări
- AN-t046Document9 paginiAN-t046oussama22Încă nu există evaluări
- Universite Mohammed V - Rabat Faculte de Medecine Et de PharmacieDocument187 paginiUniversite Mohammed V - Rabat Faculte de Medecine Et de PharmacieDelondon AlasckoÎncă nu există evaluări
- Chapitre 4. BiocapteursDocument13 paginiChapitre 4. BiocapteursFatimazahra ElmÎncă nu există evaluări
- ISO22KDocument44 paginiISO22KAbderrazzak ElazriÎncă nu există evaluări
- TP PhysiooDocument40 paginiTP Physiookenny100% (1)
- Support Du Cours Microbiologie de L'environnementDocument23 paginiSupport Du Cours Microbiologie de L'environnementGhanou NeddjarÎncă nu există evaluări
- Les Normes de Qualité Au Maroc Et Dans Le MondeDocument2 paginiLes Normes de Qualité Au Maroc Et Dans Le MondeAnass BounajraÎncă nu există evaluări
- Étude de La Phytochimie Et Activités Biologique...Document100 paginiÉtude de La Phytochimie Et Activités Biologique...Polo CXÎncă nu există evaluări
- Autorisation FRADocument6 paginiAutorisation FRANadia GoudaÎncă nu există evaluări
- Avis de Concours OnssaDocument20 paginiAvis de Concours OnssaSoufiane NaniÎncă nu există evaluări
- Sémio Med - Sémiologie EndocrinienneDocument3 paginiSémio Med - Sémiologie EndocrinienneRamzi Ch100% (1)
- Les Endotoxines 1-1Document16 paginiLes Endotoxines 1-1Mo À l'EuropeÎncă nu există evaluări
- Cours de Biochimie MétaboliqueDocument108 paginiCours de Biochimie MétaboliqueMBAÏADOUM NGARGUINAM Rodrigue100% (1)
- Waaub Diapo 2Document120 paginiWaaub Diapo 2Ilham TimadjerÎncă nu există evaluări
- Récepteurs À Activité Tyrosine Kinase DefDocument12 paginiRécepteurs À Activité Tyrosine Kinase DefFatima ZahraÎncă nu există evaluări
- SalmonellaDocument47 paginiSalmonellaTarik DamirÎncă nu există evaluări
- Presentation SQ ONISPADocument20 paginiPresentation SQ ONISPAqualite consultingÎncă nu există evaluări
- Candida Et Candidoses ResuméDocument4 paginiCandida Et Candidoses Resumékaka lotyÎncă nu există evaluări
- Les Lipides Version FinalenomarksDocument4 paginiLes Lipides Version Finalenomarksapi-243718294100% (1)
- Cours Génie Industriel AlimentaireDocument91 paginiCours Génie Industriel AlimentaireElbahi DjaalabÎncă nu există evaluări
- Codex Alimentaire 2 PDFDocument203 paginiCodex Alimentaire 2 PDFAsma TransformationÎncă nu există evaluări
- Le Cours de BiostatistiquesDocument16 paginiLe Cours de BiostatistiquesCHAIMAE AFIFÎncă nu există evaluări
- Mémoire Mehdi11Document60 paginiMémoire Mehdi11ikramÎncă nu există evaluări
- Classification EntrepriseDocument12 paginiClassification EntrepriseKodak drakeÎncă nu există evaluări
- Les Boissons Light': Conservation Et Effet Sur L'équilibre Du DiabèteDocument108 paginiLes Boissons Light': Conservation Et Effet Sur L'équilibre Du DiabètePatrick ConradÎncă nu există evaluări
- Une Politique Écologique Ambitieuse de Lutte Contre Le Plastique. La Logique Environnementale Et Sociale Du Recours Aux Consignes Pour RéemploiDocument12 paginiUne Politique Écologique Ambitieuse de Lutte Contre Le Plastique. La Logique Environnementale Et Sociale Du Recours Aux Consignes Pour RéemploiFondationEcoloÎncă nu există evaluări
- Bioch1an16-Enzymologie GhoualiDocument67 paginiBioch1an16-Enzymologie Ghoualiahlemm100% (1)
- Biostatistique. Université Frères Mentouri Constantine 3.3. Mr. LATELI Ahcene. L 2.Sc - BiologiquesDocument15 paginiBiostatistique. Université Frères Mentouri Constantine 3.3. Mr. LATELI Ahcene. L 2.Sc - BiologiquesdidineÎncă nu există evaluări
- Procédure StérilisationDocument7 paginiProcédure StérilisationMarcheÎncă nu există evaluări
- Partie Ii Biotechnologie Microbienne Chap ADocument6 paginiPartie Ii Biotechnologie Microbienne Chap AAmira AmouraÎncă nu există evaluări
- Evaluation Des Bonnes Pratiques D'hygiène Au Sein D'une Cuisine Centrale D'un Hôpital À Fès - Soukaina OUKADDOUDocument44 paginiEvaluation Des Bonnes Pratiques D'hygiène Au Sein D'une Cuisine Centrale D'un Hôpital À Fès - Soukaina OUKADDOUKawtar erramiÎncă nu există evaluări
- Labarere Jose p01 PDFDocument77 paginiLabarere Jose p01 PDFhubik38Încă nu există evaluări
- Contribution Au Maintien de La Certification ISO 22 000 - 2018 - Djiby THIAMDocument72 paginiContribution Au Maintien de La Certification ISO 22 000 - 2018 - Djiby THIAMYounas AbaliÎncă nu există evaluări
- Chapitre 1 Généralités Sur Les Risquesalimentaires PDFDocument6 paginiChapitre 1 Généralités Sur Les Risquesalimentaires PDFAsma MenaiÎncă nu există evaluări
- Fruits Et LegumesDocument7 paginiFruits Et Legumesdidi100% (1)
- Contribution À La Valorasation Des Déchets en Algérie-Ilovepdf-CompressedDocument54 paginiContribution À La Valorasation Des Déchets en Algérie-Ilovepdf-Compressedsection automateÎncă nu există evaluări
- Industries Agro-AlimentairesDocument733 paginiIndustries Agro-AlimentairesAzzoug BilalÎncă nu există evaluări
- 1-Anti-Inflammatoires Stéroïdiens - AIS.2020Document80 pagini1-Anti-Inflammatoires Stéroïdiens - AIS.2020khouloud gazzehÎncă nu există evaluări
- Méthode D'étude de La CelluleDocument33 paginiMéthode D'étude de La CelluleliliÎncă nu există evaluări
- Space: Go Green Community Presentation TemplateDocument13 paginiSpace: Go Green Community Presentation TemplateKhawlaÎncă nu există evaluări
- Cours Khelfaoui Recherche Documentaire Et Conception de M閙oireDocument23 paginiCours Khelfaoui Recherche Documentaire Et Conception de M閙oiresosso poissonÎncă nu există evaluări
- LeadershipDocument5 paginiLeadershipjackÎncă nu există evaluări
- Liste Des Produits PharmaceutiquesDocument78 paginiListe Des Produits Pharmaceutiqueshakimehakime100% (1)
- Labarere Jose p02Document26 paginiLabarere Jose p02youness.khalfaouiÎncă nu există evaluări
- G1-Aliments Riches en GlucidesDocument25 paginiG1-Aliments Riches en GlucidesRachid DjigaÎncă nu există evaluări
- Chapitre Fermentations Industrielles PDFDocument17 paginiChapitre Fermentations Industrielles PDFАпцгдк Ьфш БгднчллÎncă nu există evaluări
- Biotechnologie Et Molecules DinteretsDocument31 paginiBiotechnologie Et Molecules DinteretsAmal BouDechichaÎncă nu există evaluări
- Découverte de L'électron Et Détermination Du Rapport E/m de L'électronDocument2 paginiDécouverte de L'électron Et Détermination Du Rapport E/m de L'électronboustakatbÎncă nu există evaluări
- Caj 4461 yDocument2 paginiCaj 4461 yharold perezÎncă nu există evaluări
- TP BCGDocument13 paginiTP BCGyoubinemajdenizarÎncă nu există evaluări
- RMN SMC5Document25 paginiRMN SMC5Ahmed100% (1)
- Sec CCP 2003 Sic PSIDocument11 paginiSec CCP 2003 Sic PSIchoupi de la vieÎncă nu există evaluări
- Cinematique. CH 1. - Position D Un Solide. Etude Geometrique D Un SystemeDocument30 paginiCinematique. CH 1. - Position D Un Solide. Etude Geometrique D Un SystemeMariam DaaliÎncă nu există evaluări
- Calculs VéhiculesDocument25 paginiCalculs VéhiculesMohammed HmÎncă nu există evaluări
- 11577535série Force de LaplaceDocument2 pagini11577535série Force de LaplaceМохамед Ель Фахім100% (2)
- DS1 ÉlectrocinétiqueDocument6 paginiDS1 ÉlectrocinétiqueAnis SouissiÎncă nu există evaluări
- Cours PV - CH II-1Document43 paginiCours PV - CH II-1lolopopo28Încă nu există evaluări
- Capteurs Numeriques de Position Les Codeurs Optiques: Entraînement Avec CorrectionDocument4 paginiCapteurs Numeriques de Position Les Codeurs Optiques: Entraînement Avec Correctionkiojo100% (1)
- Prep Enon 0007Document4 paginiPrep Enon 0007Anowar SaleineÎncă nu există evaluări
- Efs 1 2020Document1 paginăEfs 1 2020mou tiemÎncă nu există evaluări
- 4-Circuits Equivalents de Thevenin Et NortonDocument14 pagini4-Circuits Equivalents de Thevenin Et NortonYahya HamdaniÎncă nu există evaluări
- Pinel ArticleDocument15 paginiPinel ArticlewebylomeÎncă nu există evaluări
- Cours de Chimie Generale Prepa (UNILU)Document97 paginiCours de Chimie Generale Prepa (UNILU)steventshipengÎncă nu există evaluări
- CH 7 Ancrage Et Recouvrement de BarresDocument20 paginiCH 7 Ancrage Et Recouvrement de BarresHaythem Ammar100% (5)
- Devoir N°8Document3 paginiDevoir N°8Arabqq MoaliÎncă nu există evaluări
- Projet Matlab0607S2Document8 paginiProjet Matlab0607S2Feno RamanantsoaÎncă nu există evaluări
- CDS Exemple Calcul Section BPDocument13 paginiCDS Exemple Calcul Section BPhamoumatÎncă nu există evaluări
- TP Ov-L2 BaadjDocument16 paginiTP Ov-L2 Baadj5d120a9950% (4)
- MQ-TD & ExamensDocument37 paginiMQ-TD & ExamensFatima ElmourabitÎncă nu există evaluări
- PSI MathDocument148 paginiPSI MathAdam ChoumaÎncă nu există evaluări
- TD3 Structure ElectroniqueDocument4 paginiTD3 Structure ElectroniqueAnis ChaibiÎncă nu există evaluări
- MINERA HTA-BT 100 250 kVADocument2 paginiMINERA HTA-BT 100 250 kVAkhakadamÎncă nu există evaluări
- FST TD Corri ÉlectricitéDocument20 paginiFST TD Corri ÉlectricitéOumar CamaraÎncă nu există evaluări
- Condasensation Et EbullitionDocument57 paginiCondasensation Et EbullitionIlyas El HarrakÎncă nu există evaluări
- Atomistique Chapitre 2 - 060920Document21 paginiAtomistique Chapitre 2 - 060920Farel DrbÎncă nu există evaluări
- Les Cellules Photovoltaiques PDFDocument5 paginiLes Cellules Photovoltaiques PDFkamel18100% (2)