S-ar putea să vă placă și
- Introduction A L'intelligence en Essaim (Slides)Document100 paginiIntroduction A L'intelligence en Essaim (Slides)Franck DernoncourtÎncă nu există evaluări
- INS-MV 1E - Mon Beau Navire, Ô Ma MémoireDocument7 paginiINS-MV 1E - Mon Beau Navire, Ô Ma MémoireMister PiwiÎncă nu există evaluări
- Injection MotoDocument48 paginiInjection Motolulu3232100% (2)
- Cours de Series TemporellesDocument178 paginiCours de Series TemporellesZeroualiBilelÎncă nu există evaluări
- Introduction à l’analyse des données de sondage avec SPSS : Guide d’auto-apprentissageDe la EverandIntroduction à l’analyse des données de sondage avec SPSS : Guide d’auto-apprentissageÎncă nu există evaluări
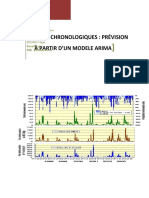
- Séries Chronologiques Version FinaleDocument24 paginiSéries Chronologiques Version FinaleSalem MriguaÎncă nu există evaluări
- Chapitre 2 L'Analyse en Composantes Principales (ACP)Document15 paginiChapitre 2 L'Analyse en Composantes Principales (ACP)ceiizÎncă nu există evaluări
- AcpDocument20 paginiAcpKarim Karim100% (1)
- Le Problème de L'être Et de La DestinéeDocument247 paginiLe Problème de L'être Et de La Destinéenicole_planteÎncă nu există evaluări
- 2017 2018 Examen CorrigéDocument10 pagini2017 2018 Examen CorrigéEl youssfi100% (1)
- L'analyse des données de sondage avec SPSS: Un guide d'introductionDe la EverandL'analyse des données de sondage avec SPSS: Un guide d'introductionÎncă nu există evaluări
- Cours Logiciels Économetriques 1Document89 paginiCours Logiciels Économetriques 1gondodiesamesperanceÎncă nu există evaluări
- Forme Générale Du Modèle de Régression Linéaire MultipleDocument6 paginiForme Générale Du Modèle de Régression Linéaire Multiplesporara alioÎncă nu există evaluări
- CoursPanel Chap1Document68 paginiCoursPanel Chap1fortvoyron100% (1)
- Modèles de Prévision Séries Temporelles Arthur CharpentierDocument196 paginiModèles de Prévision Séries Temporelles Arthur CharpentierDirumil0% (1)
- Séries TemporellesDocument150 paginiSéries TemporellesadivelmycryÎncă nu există evaluări
- Series ChronologiquesDocument146 paginiSeries Chronologiquessoufianebr67% (3)
- CatalogueDocument44 paginiCataloguevousfaitechier100% (2)
- TD Serie Temp 0607Document18 paginiTD Serie Temp 0607Serge Dedjinou50% (2)
- Analyse de FonnéesDocument45 paginiAnalyse de FonnéesmohammedÎncă nu există evaluări
- Series TemporellesDocument51 paginiSeries TemporellesAbderrahim MirhouarÎncă nu există evaluări
- Series ChronologiquesDocument16 paginiSeries ChronologiquesWalid Fezzani100% (1)
- Travail À FaireDocument11 paginiTravail À FaireMalika HartÎncă nu există evaluări
- Les Belges Dans L'afrique Centrale Tome IIIDocument534 paginiLes Belges Dans L'afrique Centrale Tome IIIVictor RosezÎncă nu există evaluări
- Cours ÉconométrieDocument45 paginiCours ÉconométrieHayfa ElkadhiÎncă nu există evaluări
- TD Cna-CanDocument5 paginiTD Cna-CanEmmanuelÎncă nu există evaluări
- Poly Cours Monte Carlo m1 ImDocument55 paginiPoly Cours Monte Carlo m1 ImJoe Castro100% (1)
- Pratique de L'économétrie Des Séries Chronologiques - Partie2Document64 paginiPratique de L'économétrie Des Séries Chronologiques - Partie2Samuel100% (1)
- Roadmap OVH 20120620Document14 paginiRoadmap OVH 20120620Franck DernoncourtÎncă nu există evaluări
- Guide EviewsDocument0 paginiGuide EviewsNassiri Mohamed100% (1)
- AcpDocument72 paginiAcpConv AincuÎncă nu există evaluări
- Finance Stochastique PDFDocument169 paginiFinance Stochastique PDFLarbiBenAllalÎncă nu există evaluări
- Gestion de Projet RapportDocument29 paginiGestion de Projet RapportMarizol Flores100% (1)
- Offre Statistique Filière DSDocument20 paginiOffre Statistique Filière DSamineÎncă nu există evaluări
- Séries Chro InseaDocument116 paginiSéries Chro InseaEL Hafa AbdellahÎncă nu există evaluări
- !!!!!!!!!!!!!!!!!!!!!!!!! 1 A Voir Econometrie Des Serie Temporelle !!!!!!!!!!!!!Document70 pagini!!!!!!!!!!!!!!!!!!!!!!!!! 1 A Voir Econometrie Des Serie Temporelle !!!!!!!!!!!!!EI Ahmed100% (1)
- Pratique de L'économétrie Linéaire - 2 - AutocorrélationDocument28 paginiPratique de L'économétrie Linéaire - 2 - AutocorrélationSoukaina IdlhajaliÎncă nu există evaluări
- Econometrie Suite LareqDocument109 paginiEconometrie Suite LareqSarah Rose100% (3)
- L'econométrie - Le Processus Stationnaire PDFDocument13 paginiL'econométrie - Le Processus Stationnaire PDFTaha Can100% (2)
- Sciences de Gestion Synthese de Cours Exercices CorrigesDocument19 paginiSciences de Gestion Synthese de Cours Exercices Corrigesalex hounkanrinÎncă nu există evaluări
- ARIMA ARMA FinalDocument40 paginiARIMA ARMA FinalWijdane ElouargaÎncă nu există evaluări
- 5-Intro Des Modeles A Equations SimultaneesDocument24 pagini5-Intro Des Modeles A Equations SimultaneesTarik AmalouÎncă nu există evaluări
- Introduction Series Chronologiques Chapitre 1Document6 paginiIntroduction Series Chronologiques Chapitre 1Hong Son PhanÎncă nu există evaluări
- Ec PanelsDocument237 paginiEc PanelsMohammed TaamÎncă nu există evaluări
- Etapes Simulation VARDocument10 paginiEtapes Simulation VARwidedbenmoussaÎncă nu există evaluări
- Cointegration de JohansenDocument27 paginiCointegration de JohansenABDESSAMAD EL YAHYAOUI100% (1)
- 2016 Economie Publique Corrige TD 9Document4 pagini2016 Economie Publique Corrige TD 9Mikapanga100% (1)
- As Jonas Recueil Kint2Document88 paginiAs Jonas Recueil Kint2SaadBourouisÎncă nu există evaluări
- Methodes Delphi Et Box JenkinsDocument10 paginiMethodes Delphi Et Box JenkinsMartin OlingaÎncă nu există evaluări
- Cours Économétrie Licence3 2023Document99 paginiCours Économétrie Licence3 2023Souleymane YeoÎncă nu există evaluări
- Master 1 MMD - Séries Temporelles (Paris-Dauphine)Document196 paginiMaster 1 MMD - Séries Temporelles (Paris-Dauphine)L.CamoÎncă nu există evaluări
- Econométrie 2023Document64 paginiEconométrie 2023Patrick MulebaÎncă nu există evaluări
- Modélisation Des Options Asiatiques Sur Le Taux de Change. Auteur: MARIANE Mouhammed, ENSAEDocument47 paginiModélisation Des Options Asiatiques Sur Le Taux de Change. Auteur: MARIANE Mouhammed, ENSAEmariane75% (4)
- Series TemporellesDocument30 paginiSeries TemporellesAbdelaziz BEN KHALIFAÎncă nu există evaluări
- Séance 1Document44 paginiSéance 1Soukaina Idlhajali100% (1)
- Econometri PDFDocument37 paginiEconometri PDFstevy darel100% (1)
- Non Stationnarité Et Tests de Racines UnitairesDocument85 paginiNon Stationnarité Et Tests de Racines UnitairesecohanaeÎncă nu există evaluări
- Cours Econometrie Des PanelDocument58 paginiCours Econometrie Des Paneljsk-merzouki-8387100% (1)
- Séries ChronologiquesDocument10 paginiSéries Chronologiquessjaubert100% (13)
- Analyse Des Séries ChronologiquesDocument26 paginiAnalyse Des Séries Chronologiqueswassim7Încă nu există evaluări
- Introduction À L'analyse Des Séries TemporellesDocument42 paginiIntroduction À L'analyse Des Séries TemporellesKediha YassineÎncă nu există evaluări
- La théorie des jeux: Thrillers judiciaires de Katerina Carter, #2De la EverandLa théorie des jeux: Thrillers judiciaires de Katerina Carter, #2Încă nu există evaluări
- Probabilités et statistiques: Ce que j'en ai compris, si ça peut aider…De la EverandProbabilités et statistiques: Ce que j'en ai compris, si ça peut aider…Încă nu există evaluări
- MPRA Paper 69824Document204 paginiMPRA Paper 69824Hans HermanÎncă nu există evaluări
- Lhomoparentalite FaitsetcroyancesDocument4 paginiLhomoparentalite FaitsetcroyancesFranck DernoncourtÎncă nu există evaluări
- Lancement Du Double Diplôme École Polytechnique/HEC ParisDocument2 paginiLancement Du Double Diplôme École Polytechnique/HEC ParisFranck DernoncourtÎncă nu există evaluări
- Colloque Complexite DiffuseDocument5 paginiColloque Complexite DiffuseFranck DernoncourtÎncă nu există evaluări
- 2006 - Utilitarisme Pragmatique Et Reconnaissance D'intention Dans Les Actes de Langage IndirectsDocument21 pagini2006 - Utilitarisme Pragmatique Et Reconnaissance D'intention Dans Les Actes de Langage IndirectsFranck DernoncourtÎncă nu există evaluări
- Contrat HUBIC 2012-03-19Document12 paginiContrat HUBIC 2012-03-19Franck DernoncourtÎncă nu există evaluări
- 1996 - Expression Et Reconnaissance Des Intentions Conceptuelles Apports de La MultimodalitéDocument9 pagini1996 - Expression Et Reconnaissance Des Intentions Conceptuelles Apports de La MultimodalitéFranck DernoncourtÎncă nu există evaluări
- Du Bon Usage de La Bibliometrie Pour L'evaluation Individuelle Des ChercheursDocument70 paginiDu Bon Usage de La Bibliometrie Pour L'evaluation Individuelle Des ChercheursDiego Julian CosentinoÎncă nu există evaluări
- Thèse - Architecture Et Apprentissage D'un Système Hybride Neuro-Markovien Pour La Reconnaissance de L'écriture Manuscrite En-Ligne (2005)Document213 paginiThèse - Architecture Et Apprentissage D'un Système Hybride Neuro-Markovien Pour La Reconnaissance de L'écriture Manuscrite En-Ligne (2005)Franck DernoncourtÎncă nu există evaluări
- Fuzzy Logic SDZ 2012Document17 paginiFuzzy Logic SDZ 2012mjimerÎncă nu există evaluări
- Les Colonnes de Buren À L'abandon (2011)Document5 paginiLes Colonnes de Buren À L'abandon (2011)Franck DernoncourtÎncă nu există evaluări
- 2002 - SFERES - Un Framework Pour La Conception de Systèmes Multi-Agents AdaptatifsDocument20 pagini2002 - SFERES - Un Framework Pour La Conception de Systèmes Multi-Agents AdaptatifsFranck DernoncourtÎncă nu există evaluări
- RMA GrosBillDocument2 paginiRMA GrosBillFranck DernoncourtÎncă nu există evaluări
- 200x - Le Pouvoir de Déstabilisation Des Hedge Funds - Évaluation Empirique Sur Les Indices BoursiersDocument36 pagini200x - Le Pouvoir de Déstabilisation Des Hedge Funds - Évaluation Empirique Sur Les Indices BoursiersFranck DernoncourtÎncă nu există evaluări
- 2002 - La Perspective Pragmatique Dans L'étude Du Raisonnement Et de La RationalitéDocument45 pagini2002 - La Perspective Pragmatique Dans L'étude Du Raisonnement Et de La RationalitéFranck DernoncourtÎncă nu există evaluări
- Linguistique - Théorie Du Liage (Slides)Document7 paginiLinguistique - Théorie Du Liage (Slides)Franck DernoncourtÎncă nu există evaluări
- IterativeDocument3 paginiIterativeFayçal BelkessamÎncă nu există evaluări
- 2003 - Problématiques D'intelligence Arti Cielle Dans Le Domaine Des Jeux Sur OrdinateurDocument20 pagini2003 - Problématiques D'intelligence Arti Cielle Dans Le Domaine Des Jeux Sur OrdinateurFranck DernoncourtÎncă nu există evaluări
- Logique Flou PDFDocument20 paginiLogique Flou PDFElyes Issaoui0% (1)
- AH1N1 Et l'ABC de La Culture MédicaleDocument44 paginiAH1N1 Et l'ABC de La Culture MédicaleFranck DernoncourtÎncă nu există evaluări
- Presentation - How Do We Deal With Uncertainty? Bayesian Computations in The Brain.Document56 paginiPresentation - How Do We Deal With Uncertainty? Bayesian Computations in The Brain.Franck DernoncourtÎncă nu există evaluări
- 2010 - E-Leclerc - Etude Des Prix Sur Les MédicamentsDocument56 pagini2010 - E-Leclerc - Etude Des Prix Sur Les MédicamentsFranck DernoncourtÎncă nu există evaluări
- 2004 - Les Méthodes de Raisonnement Dans Les ImagesDocument229 pagini2004 - Les Méthodes de Raisonnement Dans Les ImagesFranck DernoncourtÎncă nu există evaluări
- Introduction À La Logique Floue Appliquée Au Systèmes Décisionnels - Janvier 2011Document49 paginiIntroduction À La Logique Floue Appliquée Au Systèmes Décisionnels - Janvier 2011Franck Dernoncourt100% (1)
- Presentation - Motion-Induced Blindness Aka MIB - 2011Document40 paginiPresentation - Motion-Induced Blindness Aka MIB - 2011Franck DernoncourtÎncă nu există evaluări
- 2010 - E-Leclerc - Etude Des Prix Sur Les Médicaments - MéthodologieDocument6 pagini2010 - E-Leclerc - Etude Des Prix Sur Les Médicaments - MéthodologieFranck DernoncourtÎncă nu există evaluări
- 2009 - Les Algorithmes Évolutionnistes - Notions AvancéesDocument27 pagini2009 - Les Algorithmes Évolutionnistes - Notions AvancéesFranck DernoncourtÎncă nu există evaluări
- 2006 Algorithmes Memetiques Pour Les Problemes de Tournees de Vehicules SlidesDocument47 pagini2006 Algorithmes Memetiques Pour Les Problemes de Tournees de Vehicules SlidesMahmoud El FellahÎncă nu există evaluări
- Catalogue FR PDFDocument64 paginiCatalogue FR PDFYacine MezianiÎncă nu există evaluări
- Rapport 2Document20 paginiRapport 2Destroy'S XPÎncă nu există evaluări
- Deghaye, Pierre - Conférence (Boehme)Document6 paginiDeghaye, Pierre - Conférence (Boehme)Anonymous 8VbEv5tA3Încă nu există evaluări
- Examen 1 Physique Nucléaire 2023-2024Document1 paginăExamen 1 Physique Nucléaire 2023-2024ezzahidysaid91Încă nu există evaluări
- Arrêté 11 047 Du 4-12-95 (Mandat Sanitaire)Document2 paginiArrêté 11 047 Du 4-12-95 (Mandat Sanitaire)la020576Încă nu există evaluări
- TP Gesition de RisquesDocument3 paginiTP Gesition de RisquesMuambay Muambi MuhammedÎncă nu există evaluări
- Evaluation Bilan ElectriciteDocument2 paginiEvaluation Bilan Electricitebrahim chalhoubÎncă nu există evaluări
- Fiche Analyser Saposition ConcurentielleDocument3 paginiFiche Analyser Saposition ConcurentielleAdamÎncă nu există evaluări
- Rémy Chauvin - Les Secrets Des PortulansDocument171 paginiRémy Chauvin - Les Secrets Des PortulansEric ChabertÎncă nu există evaluări
- Devoir Blanc VDocument6 paginiDevoir Blanc Vzack slÎncă nu există evaluări
- Cours RNDocument13 paginiCours RNCédric KueteÎncă nu există evaluări
- ds2 sp2022Document2 paginids2 sp2022lolocheeÎncă nu există evaluări
- 14 PDFDocument19 pagini14 PDFEmil PotecÎncă nu există evaluări
- 5ASP FRDocument2 pagini5ASP FREurobrake Kevin Durand MericeÎncă nu există evaluări
- Planification de La Production de L'écrit.Document1 paginăPlanification de La Production de L'écrit.samoyÎncă nu există evaluări
- Matlab2009 tp6Document3 paginiMatlab2009 tp6Abdel DaaÎncă nu există evaluări
- Tutoriel PaintShoPro 7Document311 paginiTutoriel PaintShoPro 7MCÎncă nu există evaluări
- Catalogue Multimetrix - 2017Document16 paginiCatalogue Multimetrix - 2017ZorbanfrÎncă nu există evaluări
- Qe65Q6Fnatxxc: L'image, Et Rien D'autreDocument3 paginiQe65Q6Fnatxxc: L'image, Et Rien D'autreahmed oujÎncă nu există evaluări
- Memoire Final2020Document113 paginiMemoire Final2020Miss VlogsÎncă nu există evaluări
- Facturation Hospitalière DHSADocument23 paginiFacturation Hospitalière DHSAYouness AznagÎncă nu există evaluări
- DC 11 10 01 Airelec CDocument8 paginiDC 11 10 01 Airelec CabdosmartoÎncă nu există evaluări
- BTS 2Document6 paginiBTS 2Demorex KeuhouaÎncă nu există evaluări