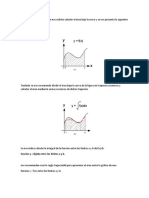
S-ar putea să vă placă și
- Sistemas Operacional Entrega 2Document15 paginiSistemas Operacional Entrega 2Cristian Camilo DuranÎncă nu există evaluări
- Reseña Historica de La Contabilidad en ColombiaDocument25 paginiReseña Historica de La Contabilidad en ColombiaKELLY KATHERINE RIVERA LINARES100% (1)
- Hilos Con Java y Python Guia de TrabajoDocument8 paginiHilos Con Java y Python Guia de TrabajojuanÎncă nu există evaluări
- Entrega 1Document19 paginiEntrega 1Gabo FrancoÎncă nu există evaluări
- Logica Combinacional CODIFICADORDocument10 paginiLogica Combinacional CODIFICADORWladimir SifontesÎncă nu există evaluări
- Programacion en ParaleloDocument45 paginiProgramacion en ParaleloJose Antonio Cruz Sanchez100% (1)
- Sistemas Distribuidos Entrega 3Document7 paginiSistemas Distribuidos Entrega 3Juan AriasÎncă nu există evaluări
- Quiz Sistemas DistribuidosDocument8 paginiQuiz Sistemas DistribuidosSergio GamboaÎncă nu există evaluări
- Estado Del Arte Computacion Paralela y DistribuidaDocument5 paginiEstado Del Arte Computacion Paralela y DistribuidaJoel Cesar Fernandez SeguraÎncă nu există evaluări
- La Tragedia de Lo PublicoDocument18 paginiLa Tragedia de Lo PublicoJ Angelica RuaÎncă nu există evaluări
- LAS FRONTERAS DIFUSAS para ExposicionDocument8 paginiLAS FRONTERAS DIFUSAS para ExposicionJ Angelica RuaÎncă nu există evaluări
- Antologia Base de DatosDocument95 paginiAntologia Base de DatosJuanELWeroÎncă nu există evaluări
- Documento SocketDocument289 paginiDocumento SocketAnonymous 5fo2lBK1Încă nu există evaluări
- Lab 1 Sumador MUX-DEMUXDocument12 paginiLab 1 Sumador MUX-DEMUXSeñor PopoÎncă nu există evaluări
- Sistemas DistribuidosDocument20 paginiSistemas DistribuidosDarwin De La CruzÎncă nu există evaluări
- Guia para La Elaboración Del Informe Tecnico de Residencia ProfesionalDocument28 paginiGuia para La Elaboración Del Informe Tecnico de Residencia ProfesionalChristiam BlancoÎncă nu există evaluări
- Las Paradojas de Las Revoluciones HispanoamericanasDocument4 paginiLas Paradojas de Las Revoluciones HispanoamericanasSebastian Cifuentes PeñaÎncă nu există evaluări
- Patrones Arquitectónicos y Diseño de SoftwareDocument156 paginiPatrones Arquitectónicos y Diseño de SoftwarecgomezvegaÎncă nu există evaluări
- Ejemplos NET USEDocument9 paginiEjemplos NET USEMaryury GarciaÎncă nu există evaluări
- Segunda Entrega Semana 5Document3 paginiSegunda Entrega Semana 5carlos mario pandales lopezÎncă nu există evaluări
- Front End PDFDocument9 paginiFront End PDFkevin hernandez lucioÎncă nu există evaluări
- GNS3 VpcsDocument16 paginiGNS3 VpcsiopdescargoÎncă nu există evaluări
- Hacking ÉticoDocument7 paginiHacking ÉticoGeovannyÎncă nu există evaluări
- Sockets en Java (Cliente y Servidor) - CodigoprogramacionDocument12 paginiSockets en Java (Cliente y Servidor) - CodigoprogramacionAlejandro Gonzalez TalamantesÎncă nu există evaluări
- Graphical Modeling Framework 2.0 (Lenguajes de Dominio Específico Gráficos)Document57 paginiGraphical Modeling Framework 2.0 (Lenguajes de Dominio Específico Gráficos)Vicente García DíazÎncă nu există evaluări
- Guia de POODocument10 paginiGuia de POOricardoneo_m2958Încă nu există evaluări
- Estándares y Modelos de PruebasDocument2 paginiEstándares y Modelos de Pruebaskarlapatis100% (1)
- Examen - Evaluacion Final - Escenario 8Document8 paginiExamen - Evaluacion Final - Escenario 8Edwin Corrales TrujilloÎncă nu există evaluări
- Ejercicios Resueltos Árboles - Estructuras de DatosDocument40 paginiEjercicios Resueltos Árboles - Estructuras de DatosJuan GutiérrezÎncă nu există evaluări
- Actividad de Puntos Evaluables - Escenario 2 - Gerencia de Proyectos InformaticosDocument6 paginiActividad de Puntos Evaluables - Escenario 2 - Gerencia de Proyectos InformaticosJohn Itzen100% (1)
- Computación Grafica e ImágenesDocument7 paginiComputación Grafica e ImágenesjoelGÎncă nu există evaluări
- Practica SSH JonathanDocument9 paginiPractica SSH JonathanJonathan Alexis100% (1)
- Atajos en NetBeansDocument3 paginiAtajos en NetBeanskoutanimeÎncă nu există evaluări
- Modelo de Prototipo Por ComponentesDocument2 paginiModelo de Prototipo Por ComponentesAlex HumanezÎncă nu există evaluări
- Primera EntregaDocument8 paginiPrimera EntregaAna Milena DiazÎncă nu există evaluări
- Tarea HDP 115Document6 paginiTarea HDP 115Wilfredo CeronÎncă nu există evaluări
- Manual Instalacion BOCCADocument13 paginiManual Instalacion BOCCAPaola PerezÎncă nu există evaluări
- Llibro de Visitas Con PHP y MySQLDocument7 paginiLlibro de Visitas Con PHP y MySQLNataly GonzalezÎncă nu există evaluări
- Modelo de Desarrollo XPDocument19 paginiModelo de Desarrollo XPwilpraÎncă nu există evaluări
- Resultado Del Examen Del Curso Gratis de Programación Básica Joan MontoyaDocument4 paginiResultado Del Examen Del Curso Gratis de Programación Básica Joan MontoyaKmmg46100% (1)
- Que Es ActivityDocument12 paginiQue Es ActivityArturo LÎncă nu există evaluări
- Niveles PSPDocument4 paginiNiveles PSPFlor SanchezÎncă nu există evaluări
- Sumador RetadorDocument9 paginiSumador RetadoralbertwillyÎncă nu există evaluări
- Bettercap en UbuntuDocument4 paginiBettercap en UbuntuJonny PerlazaÎncă nu există evaluări
- Introduccion Al Lenguaje C - B. CostalesDocument152 paginiIntroduccion Al Lenguaje C - B. CostalesIsaac HernandezÎncă nu există evaluări
- Manual PSeInt 2019Document8 paginiManual PSeInt 2019Jaime CoronelÎncă nu există evaluări
- Cálculo de PredicadosDocument19 paginiCálculo de PredicadosGricelda AguilarÎncă nu există evaluări
- Taller 2 Tasas EquivalentesDocument1 paginăTaller 2 Tasas Equivalentescesarhh59Încă nu există evaluări
- SistemasOperacionales - Entrega1Document14 paginiSistemasOperacionales - Entrega1Cristian Camilo DuranÎncă nu există evaluări
- Bases de DatosDocument15 paginiBases de DatosJerson Enrique Blanco OlmosÎncă nu există evaluări
- Libreria UNISTDDocument16 paginiLibreria UNISTDciberjovialÎncă nu există evaluări
- Taller Sistemas DistribuidosDocument33 paginiTaller Sistemas DistribuidosMauro189Încă nu există evaluări
- Informe de Analisis de AlgoritmoDocument11 paginiInforme de Analisis de AlgoritmoElder ValladaresÎncă nu există evaluări
- Paso 8-Estados Del Arte-EnsayoDocument4 paginiPaso 8-Estados Del Arte-Ensayofelipe campoÎncă nu există evaluări
- Primera EntregaDocument14 paginiPrimera EntregaJesus AlarconÎncă nu există evaluări
- 3.2.4.6 ResueltoDocument6 pagini3.2.4.6 ResueltoCarlos A.Încă nu există evaluări
- Entrega 3 Sist - DistribuidosDocument10 paginiEntrega 3 Sist - DistribuidosSebastián MontealegreÎncă nu există evaluări
- Guia-Laboratorio-No-2-Simulador GNS3-v2Document10 paginiGuia-Laboratorio-No-2-Simulador GNS3-v2Kevin Josue Villalta MuñozÎncă nu există evaluări
- Unidad 5 INDIVIDUAL 10porcientoDocument4 paginiUnidad 5 INDIVIDUAL 10porcientoDouglas BenitezÎncă nu există evaluări
- Compilador C CCS y Simulador Proteus para Microcontroladores PICDe la EverandCompilador C CCS y Simulador Proteus para Microcontroladores PICEvaluare: 2.5 din 5 stele2.5/5 (5)
- Temario Curso Linux UwasoftcoDocument9 paginiTemario Curso Linux UwasoftcoOmar Andres Castañeda LizarazoÎncă nu există evaluări
- Dancourt Rodriguez Jeanpier Alexander Java Foundations 2019 2 PDFDocument7 paginiDancourt Rodriguez Jeanpier Alexander Java Foundations 2019 2 PDFPADILLA GUTIERREZ FERNANDO ANDRESÎncă nu există evaluări
- PostgreSQL PersonalizadoDocument6 paginiPostgreSQL PersonalizadoangelÎncă nu există evaluări
- Exportar MSI de Agente Instalar Por GpoDocument31 paginiExportar MSI de Agente Instalar Por GpoJohana MarimonÎncă nu există evaluări
- Grupos Usarios, Permisos, LinuxDocument7 paginiGrupos Usarios, Permisos, LinuxlkromatyÎncă nu există evaluări
- Us Ode Line A de Comando So Consola ShellDocument31 paginiUs Ode Line A de Comando So Consola ShellOziel GarciaÎncă nu există evaluări
- Trabajo LinuxDocument13 paginiTrabajo LinuxSantiago SilvaÎncă nu există evaluări
- Laboratorio NachosDocument7 paginiLaboratorio NachosNestor Andres Donato ArizaÎncă nu există evaluări
- Primer Parcial Electiva Linux Con SolucionesDocument2 paginiPrimer Parcial Electiva Linux Con SolucionesFabianaÎncă nu există evaluări
- Sistemas de Archivos DistribuidosDocument50 paginiSistemas de Archivos DistribuidosRaquel MejiaÎncă nu există evaluări
- Manual Básico de Administración de Procesos en LinuxDocument9 paginiManual Básico de Administración de Procesos en Linuxadriana_crysÎncă nu există evaluări
- Registros Tia PortalDocument10 paginiRegistros Tia PortalLio SnÎncă nu există evaluări
- Sistemas OperativosDocument44 paginiSistemas OperativosAlfredo KaleniuszkaÎncă nu există evaluări
- Crystal SistemasDocument6 paginiCrystal SistemasCrystal GarciaÎncă nu există evaluări
- Comandos UnixDocument3 paginiComandos UnixLeslie Ivette Pérez LeónÎncă nu există evaluări
- Librerias Distribucion cr85Document7 paginiLibrerias Distribucion cr85Fernando SantizoÎncă nu există evaluări
- Linux 9-16 ExamenesDocument13 paginiLinux 9-16 ExamenesAndreaChicaiza70% (10)
- 11.4.2.7 Lab - File System CommandsDocument7 pagini11.4.2.7 Lab - File System CommandsMelissa Espinosa L�pezÎncă nu există evaluări
- Composer Libros WebDocument51 paginiComposer Libros WebfcosuntÎncă nu există evaluări
- Fundamentos de Sistemas OperativosDocument3 paginiFundamentos de Sistemas OperativosJuliette ViveroÎncă nu există evaluări
- Simulacro 1er Parcial - CAECEDocument2 paginiSimulacro 1er Parcial - CAECEAdrian Leonardo RivasÎncă nu există evaluări
- Instalacion de RAC Template en VBoxDocument29 paginiInstalacion de RAC Template en VBoxoscar_sanchez_baezaÎncă nu există evaluări
- Ejercicios de MenuDocument9 paginiEjercicios de MenuCamilaValeriaTgÎncă nu există evaluări
- VirtualizacionDocument18 paginiVirtualizacionHumberto Villanueva De MoyaÎncă nu există evaluări
- Lab 5 SincronizacionDocument4 paginiLab 5 SincronizacionCristian BelalcazarÎncă nu există evaluări
- Examen Paquetes ResueltoDocument2 paginiExamen Paquetes Resueltochristian_cadil8482Încă nu există evaluări
- Ejemplos de C#Document30 paginiEjemplos de C#Wendy QuiñonezÎncă nu există evaluări
- Instalación de Windows 98Document8 paginiInstalación de Windows 98Pablo SilvaÎncă nu există evaluări
- Sistemas Operativos Yael 2.0Document20 paginiSistemas Operativos Yael 2.0Yael Villafranco MartinezÎncă nu există evaluări
- Cuestionario RapidoDocument4 paginiCuestionario RapidoMoises CerratoÎncă nu există evaluări