S-ar putea să vă placă și
- CH 00Document4 paginiCH 00Wai Kit LeongÎncă nu există evaluări
- Chap 2Document9 paginiChap 2MingdreamerÎncă nu există evaluări
- Generating Random VariablesDocument7 paginiGenerating Random VariablesTsvetanÎncă nu există evaluări
- Lindeberg Condition PDFDocument7 paginiLindeberg Condition PDFdeepeshbhatiÎncă nu există evaluări
- Geometry in SpaceDocument9 paginiGeometry in SpacejennajennjenjejÎncă nu există evaluări
- Basis and DimensionDocument48 paginiBasis and DimensionMuhd Faisal Samsudin100% (2)
- Metric Spaces and ExamplesDocument10 paginiMetric Spaces and ExamplesPiÎncă nu există evaluări
- 2014 - OjsDocument14 pagini2014 - OjsPaulo MarquesÎncă nu există evaluări
- On Zero-Divisor Graphs of Small Finite Commutative Rings: Shane P. RedmondDocument17 paginiOn Zero-Divisor Graphs of Small Finite Commutative Rings: Shane P. Redmondsaroj gurungÎncă nu există evaluări
- Cauchy Best of Best Est-P-9Document22 paginiCauchy Best of Best Est-P-9sahlewel weldemichaelÎncă nu există evaluări
- Assignment 4Document8 paginiAssignment 4LittleEXÎncă nu există evaluări
- File Journal 2011171 Journal2011171101Document9 paginiFile Journal 2011171 Journal2011171101Maliya QiyaÎncă nu există evaluări
- Hwang 1973Document8 paginiHwang 1973FlorinÎncă nu există evaluări
- Regression 7Document6 paginiRegression 7Benedikta AnnaÎncă nu există evaluări
- Notes On Point Set Topology, Fall 2010: Stephan Stolz September 3, 2010Document11 paginiNotes On Point Set Topology, Fall 2010: Stephan Stolz September 3, 2010tbrackman99Încă nu există evaluări
- Mirzaei ElasticityLectureDocument127 paginiMirzaei ElasticityLectureNagar NitinÎncă nu există evaluări
- Solution Set 2Document10 paginiSolution Set 2TomicaTomicatomicaÎncă nu există evaluări
- Schrodinger EquationDocument21 paginiSchrodinger EquationSukhwinder Singh Gill100% (3)
- Chapter 8: Orbital Angular Momentum And: Molecular RotationsDocument23 paginiChapter 8: Orbital Angular Momentum And: Molecular RotationstomasstolkerÎncă nu există evaluări
- Inverse Elliptic Functions and Legendre PolynomialsDocument5 paginiInverse Elliptic Functions and Legendre Polynomialsعقبة عقبةÎncă nu există evaluări
- Images De-Noising With Mapshrink Estimate and Dual-Threshold in Curvelet DomainDocument5 paginiImages De-Noising With Mapshrink Estimate and Dual-Threshold in Curvelet DomainjebileeÎncă nu există evaluări
- Advanced StatisticsDocument131 paginiAdvanced Statisticsmurlder100% (1)
- Approximation Solution of Fractional Partial Differential EquationsDocument8 paginiApproximation Solution of Fractional Partial Differential EquationsAdel AlmarashiÎncă nu există evaluări
- EuclideanSpace University of ArizonaDocument6 paginiEuclideanSpace University of ArizonaSawon KhanÎncă nu există evaluări
- ANALYSIS OF STRAINS Assignment 2 PDFDocument3 paginiANALYSIS OF STRAINS Assignment 2 PDFLuWang Alex100% (1)
- ANALYSIS OF STRAINS (Assignment#2Document3 paginiANALYSIS OF STRAINS (Assignment#2Stephanie Carolina Cely RodriguezÎncă nu există evaluări
- Shaped Beams From Thick Arrays: B. Sadasiva Rao and Dr. G.S.N. RajuDocument16 paginiShaped Beams From Thick Arrays: B. Sadasiva Rao and Dr. G.S.N. Rajuganga_chÎncă nu există evaluări
- Expectation: Moments of A DistributionDocument39 paginiExpectation: Moments of A DistributionDaniel Lee Eisenberg JacobsÎncă nu există evaluări
- Dimension reduction in transformation modelsDocument6 paginiDimension reduction in transformation modelsPaul GokoolÎncă nu există evaluări
- Inferences On Stress-Strength Reliability From Lindley DistributionsDocument29 paginiInferences On Stress-Strength Reliability From Lindley DistributionsrpuziolÎncă nu există evaluări
- On The Average Number of Real Roots of A Random Algebric Equation by M. KacDocument7 paginiOn The Average Number of Real Roots of A Random Algebric Equation by M. Kacadaniliu13Încă nu există evaluări
- JaBuka TopologyDocument131 paginiJaBuka TopologyGabriel Dalla VecchiaÎncă nu există evaluări
- Estimation of Parametric Functions in Downton'sDocument17 paginiEstimation of Parametric Functions in Downton'sRacha A AliÎncă nu există evaluări
- Metric Space NotesDocument70 paginiMetric Space NotesNehal AnuragÎncă nu există evaluări
- Metric Spaces and Complex AnalysisDocument120 paginiMetric Spaces and Complex AnalysisMayank KumarÎncă nu există evaluări
- Double Cyclic Codes: 2 Cristina Fernández-Córdoba Roger Ten-VallsDocument17 paginiDouble Cyclic Codes: 2 Cristina Fernández-Córdoba Roger Ten-VallsmathsÎncă nu există evaluări
- General relativity for undergraduates - Chapter 1 overviewDocument29 paginiGeneral relativity for undergraduates - Chapter 1 overviewAlexandre Masson VicenteÎncă nu există evaluări
- Basic Notions and Examples: 2.1 The Notion of A Dynamical SystemDocument20 paginiBasic Notions and Examples: 2.1 The Notion of A Dynamical SystemluisÎncă nu există evaluări
- Identifying Codes and Locating-Dominating Sets On Paths and CyclesDocument8 paginiIdentifying Codes and Locating-Dominating Sets On Paths and CyclesJayagopal Research GroupÎncă nu există evaluări
- p117 - LuminosityDocument14 paginip117 - LuminosityMicMasÎncă nu există evaluări
- General Relativity by Robert M. Wald Chapter 2: Manifolds and Tensor FieldsDocument8 paginiGeneral Relativity by Robert M. Wald Chapter 2: Manifolds and Tensor FieldsSayantanÎncă nu există evaluări
- Splitting of Some More Spaces: Math. Proc. Camb. Phil. Soc. (1979), 86, 227 2 2 7 Printed in Great BritainDocument10 paginiSplitting of Some More Spaces: Math. Proc. Camb. Phil. Soc. (1979), 86, 227 2 2 7 Printed in Great BritainEpic WinÎncă nu există evaluări
- OU Open University SM358 2009 Exam SolutionsDocument23 paginiOU Open University SM358 2009 Exam Solutionssam smithÎncă nu există evaluări
- Two-Dimensional Random VariablesDocument13 paginiTwo-Dimensional Random VariablesAllen ChandlerÎncă nu există evaluări
- Group07 CC02 Application of Linear Algebra in SVD For CompressionDocument9 paginiGroup07 CC02 Application of Linear Algebra in SVD For CompressionĐẠT NGUYỄN HOÀNG TẤNÎncă nu există evaluări
- J. R. Herring Et Al - Statistical and Dynamical Questions in Strati Ed TurbulenceDocument23 paginiJ. R. Herring Et Al - Statistical and Dynamical Questions in Strati Ed TurbulenceWhiteLighteÎncă nu există evaluări
- Measures of Multivariate Skewness and KurtosisDocument12 paginiMeasures of Multivariate Skewness and KurtosisbrenyokaÎncă nu există evaluări
- BessonoDocument12 paginiBessonoAYmen BaltyÎncă nu există evaluări
- A Generalization of A Theorem of ArchimedesDocument4 paginiA Generalization of A Theorem of Archimedesykw kcckcÎncă nu există evaluări
- 0241-0247Document7 pagini0241-0247jhudddar99Încă nu există evaluări
- Introduction To Metric SpacesDocument15 paginiIntroduction To Metric Spaceshyd arnes100% (1)
- An Interpolation Process On The Roots of Hermite Polynomials On Infinite IntervalDocument9 paginiAn Interpolation Process On The Roots of Hermite Polynomials On Infinite IntervalAJER JOURNALÎncă nu există evaluări
- Polytopes Related To Some Polyhedral Norms.: Geir DahlDocument20 paginiPolytopes Related To Some Polyhedral Norms.: Geir Dahlathar66Încă nu există evaluări
- Joint DistributionDocument13 paginiJoint DistributionASClabISBÎncă nu există evaluări
- Linear Algebra ProjectDocument9 paginiLinear Algebra ProjectĐẠT NGUYỄN HOÀNG TẤNÎncă nu există evaluări
- A Exam Presentation: Instantons and The U (1) Problem: Christian SpethmannDocument44 paginiA Exam Presentation: Instantons and The U (1) Problem: Christian Spethmann11111__11__1111Încă nu există evaluări
- A Cantor Function ConstructedDocument12 paginiA Cantor Function ConstructedEgregio TorÎncă nu există evaluări
- Lectures on P-Adic L-Functions. (AM-74), Volume 74De la EverandLectures on P-Adic L-Functions. (AM-74), Volume 74Încă nu există evaluări
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsDe la EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsÎncă nu există evaluări
- Анатольев С. Эконометрика для продолжающих курс лекций, 2003Document60 paginiАнатольев С. Эконометрика для продолжающих курс лекций, 2003GarrynskÎncă nu există evaluări
- Cochrane Random Walk in GNP (JPE)Document29 paginiCochrane Random Walk in GNP (JPE)dauren_pcÎncă nu există evaluări
- Peter C. B. Phillips and Tassos Magdalinos 2008Document32 paginiPeter C. B. Phillips and Tassos Magdalinos 2008dauren_pcÎncă nu există evaluări
- White John S. The Limiting Distribution of The Serial Correlation Coefficient in The Explosive CaseDocument11 paginiWhite John S. The Limiting Distribution of The Serial Correlation Coefficient in The Explosive Casedauren_pcÎncă nu există evaluări
- AdfDocument6 paginiAdfdauren_pcÎncă nu există evaluări
- On Approximate Jacobian Matrices in Simulation of Multibody SystemsDocument2 paginiOn Approximate Jacobian Matrices in Simulation of Multibody Systemssvk_ntÎncă nu există evaluări
- CBSE Class 11 Mathematics Worksheet - Complex Numbers and Quadratic EquationDocument6 paginiCBSE Class 11 Mathematics Worksheet - Complex Numbers and Quadratic EquationPragathi ShanmugamÎncă nu există evaluări
- Real Time Heuristic SearchDocument35 paginiReal Time Heuristic SearchAditya NambiarÎncă nu există evaluări
- 8-2 Simple Closed Curves ColingDocument14 pagini8-2 Simple Closed Curves ColingJunet CañameroÎncă nu există evaluări
- Hanani Abd Wahab BDA 3073 16 July 2008Document34 paginiHanani Abd Wahab BDA 3073 16 July 2008Hafzal GaniÎncă nu există evaluări
- Terna Engineering College: LAB Manual Part ADocument7 paginiTerna Engineering College: LAB Manual Part APrathmesh GaikwadÎncă nu există evaluări
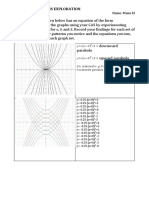
- Quadratic Graphs ExplorationDocument4 paginiQuadratic Graphs ExplorationMona LisaÎncă nu există evaluări
- What is the shortest distance she must travel to7: What is the true bearing equivalent to the compass bearing S 35Document3 paginiWhat is the shortest distance she must travel to7: What is the true bearing equivalent to the compass bearing S 35Yon Seo YooÎncă nu există evaluări
- 1966 EngulfingDocument3 pagini1966 Engulfingnishio fdÎncă nu există evaluări
- Circle-3Document62 paginiCircle-3Satwik MishraÎncă nu există evaluări
- Gauss EliminationDocument3 paginiGauss Eliminationaniket choleÎncă nu există evaluări
- Math 19B: linear algebra and probability examDocument3 paginiMath 19B: linear algebra and probability examThahir ShahÎncă nu există evaluări
- Acceleration Methods: Aitken's MethodDocument5 paginiAcceleration Methods: Aitken's MethodOubelaid AdelÎncă nu există evaluări
- SCI101SC - PHA101SC - (B) - Assessment - 202101 - Joy and FisherDocument6 paginiSCI101SC - PHA101SC - (B) - Assessment - 202101 - Joy and FisherAhmed Sami YounisÎncă nu există evaluări
- Lesson 03-Eigenvalues and EigenvectorsDocument3 paginiLesson 03-Eigenvalues and EigenvectorsPrabazhini KalirajahÎncă nu există evaluări
- Graphing Simple Rational FunctionsDocument4 paginiGraphing Simple Rational Functionsscribd-in-actionÎncă nu există evaluări
- Hill CipherDocument22 paginiHill Cipherpavan yadavÎncă nu există evaluări
- abdi-PLSC and PLSR2012Document31 paginiabdi-PLSC and PLSR2012Milton CocaÎncă nu există evaluări
- FDLF TracinBifurcationDocument6 paginiFDLF TracinBifurcationLuis MuñozÎncă nu există evaluări
- Analytical Geometry For BeginnersDocument234 paginiAnalytical Geometry For Beginnersscubadru100% (3)
- Com PdeDocument313 paginiCom PdeHam KarimÎncă nu există evaluări
- 0580 Vectors Lesson4 v1Document6 pagini0580 Vectors Lesson4 v1Soham TalwarÎncă nu există evaluări
- Mat480 Chapter 2 Summary of Legendre PolynomialsDocument2 paginiMat480 Chapter 2 Summary of Legendre Polynomialsfauzan1698Încă nu există evaluări
- EE506 - Engineering Mathematics: Quadratic Forms, Positive Definiteness and Singular Value DecompositionDocument158 paginiEE506 - Engineering Mathematics: Quadratic Forms, Positive Definiteness and Singular Value DecompositionMutaharZahidÎncă nu există evaluări
- Edgenuity - Student Learning ExperienceDocument1 paginăEdgenuity - Student Learning ExperienceNicole MunevarÎncă nu există evaluări
- Statistical Quality Control 2Document34 paginiStatistical Quality Control 2Tech_MXÎncă nu există evaluări
- Finite Element Methods Course OverviewDocument50 paginiFinite Element Methods Course OverviewShahzaib Anwar OffÎncă nu există evaluări
- Week 3-4, 5-8cahpter I. Linear Algebrasolving Systems of Linear Equations Linear Algebra 1Document51 paginiWeek 3-4, 5-8cahpter I. Linear Algebrasolving Systems of Linear Equations Linear Algebra 1Shela RamosÎncă nu există evaluări
- Weighted Mean Excel Template: Visit: EmailDocument3 paginiWeighted Mean Excel Template: Visit: EmailMark Ruby OpawonÎncă nu există evaluări
- DAA Unit Wise Importtant QuestionsDocument2 paginiDAA Unit Wise Importtant QuestionsAditya Krishna100% (4)