S-ar putea să vă placă și
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Electrical Experimenter 07Document100 paginiElectrical Experimenter 07Daniel Knight100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Plan Bed Heirloom Arts and CraftsDocument13 paginiPlan Bed Heirloom Arts and Craftspoimandres0% (1)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Celtic Knots RTutorialDocument17 paginiCeltic Knots RTutorialpoimandres100% (1)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Beds - Four Poster Bed PlansDocument8 paginiBeds - Four Poster Bed Planspoimandres100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Bunk Beds: Start With The PanelsDocument5 paginiBunk Beds: Start With The PanelspoimandresÎncă nu există evaluări
- Bed and Storage BoxesDocument9 paginiBed and Storage Boxespoimandres100% (1)
- Attached In-Bed Computer DeskDocument12 paginiAttached In-Bed Computer DeskpoimandresÎncă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Zip Tie Domes - 2V Assembly Manual: Instructions For Assembling The 16 Foot 2V Frequency Geodesic DomeDocument14 paginiZip Tie Domes - 2V Assembly Manual: Instructions For Assembling The 16 Foot 2V Frequency Geodesic DomepoimandresÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Vegetable Gardening EncyclopediaDocument261 paginiVegetable Gardening EncyclopediaTezza13100% (26)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Vehicle Tax Write-OffsDocument10 paginiVehicle Tax Write-OffspoimandresÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Electroculture According To Rexresearch Part 3Document36 paginiElectroculture According To Rexresearch Part 3poimandresÎncă nu există evaluări
- MagnacultureDocument25 paginiMagnacultureJukka Juntunen67% (3)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Cup RinsDocument3 paginiCup RinspoimandresÎncă nu există evaluări
- Link Spam Detection Based On MassDocument21 paginiLink Spam Detection Based On MasspoimandresÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Electroculture 2Document46 paginiElectroculture 2poimandres100% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Electro CultureDocument14 paginiElectro Culturepoimandres83% (6)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Michel Agier - Between War and CityDocument25 paginiMichel Agier - Between War and CityGonjack Imam100% (1)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Education Law OutlineDocument53 paginiEducation Law Outlinemischa29100% (1)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
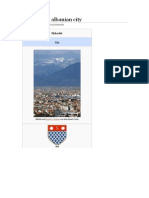
- Shkodër An Albanian CityDocument16 paginiShkodër An Albanian CityXINKIANGÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Zimbabwe Mag Court Rules Commentary Si 11 of 2019Document6 paginiZimbabwe Mag Court Rules Commentary Si 11 of 2019Vusi BhebheÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Gower Handbook of Project Management: Part 1: ProjectsDocument2 paginiThe Gower Handbook of Project Management: Part 1: ProjectschineduÎncă nu există evaluări
- Accountancy Department: Preliminary Examination in MANACO 1Document3 paginiAccountancy Department: Preliminary Examination in MANACO 1Gracelle Mae Oraller0% (1)
- (Abhijit Champanerkar, Oliver Dasbach, Efstratia K (B-Ok - Xyz)Document273 pagini(Abhijit Champanerkar, Oliver Dasbach, Efstratia K (B-Ok - Xyz)gogÎncă nu există evaluări
- Arctic Beacon Forbidden Library - Winkler-The - Thousand - Year - Conspiracy PDFDocument196 paginiArctic Beacon Forbidden Library - Winkler-The - Thousand - Year - Conspiracy PDFJames JohnsonÎncă nu există evaluări
- Guide To U.S. Colleges For DummiesDocument12 paginiGuide To U.S. Colleges For DummiesArhaan SiddiqueeÎncă nu există evaluări
- The Handmaid's Tale - Chapter 2.2Document1 paginăThe Handmaid's Tale - Chapter 2.2amber_straussÎncă nu există evaluări
- Capgras SyndromeDocument4 paginiCapgras Syndromeapi-459379591Încă nu există evaluări
- Hygiene and HealthDocument2 paginiHygiene and HealthMoodaw SoeÎncă nu există evaluări
- "We Like": Rohit Kiran KeluskarDocument43 pagini"We Like": Rohit Kiran Keluskarrohit keluskarÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- MGT501 Final Term MCQs + SubjectiveDocument33 paginiMGT501 Final Term MCQs + SubjectiveAyesha Abdullah100% (1)
- Capacitor Banks in Power System Part FourDocument4 paginiCapacitor Banks in Power System Part FourTigrillo100% (1)
- Dark Witch Education 101Document55 paginiDark Witch Education 101Wizard Luxas100% (2)
- A New Cloud Computing Governance Framework PDFDocument8 paginiA New Cloud Computing Governance Framework PDFMustafa Al HassanÎncă nu există evaluări
- ChitsongChen, Signalsandsystems Afreshlook PDFDocument345 paginiChitsongChen, Signalsandsystems Afreshlook PDFCarlos_Eduardo_2893Încă nu există evaluări
- Mwa 2 - The Legal MemorandumDocument3 paginiMwa 2 - The Legal Memorandumapi-239236545Încă nu există evaluări
- Sophia Vyzoviti - Super SurfacesDocument73 paginiSophia Vyzoviti - Super SurfacesOptickall Rmx100% (1)
- RWE Algebra 12 ProbStat Discrete Math Trigo Geom 2017 DVO PDFDocument4 paginiRWE Algebra 12 ProbStat Discrete Math Trigo Geom 2017 DVO PDFハンター ジェイソンÎncă nu există evaluări
- Research PresentationDocument11 paginiResearch PresentationTeano Jr. Carmelo C.Încă nu există evaluări
- August Strindberg's ''A Dream Play'', inDocument11 paginiAugust Strindberg's ''A Dream Play'', inİlker NicholasÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Saxonville CaseDocument2 paginiSaxonville Casel103m393Încă nu există evaluări
- Favis vs. Mun. of SabanganDocument5 paginiFavis vs. Mun. of SabanganAyra CadigalÎncă nu există evaluări
- Survey Results Central Zone First LinkDocument807 paginiSurvey Results Central Zone First LinkCrystal Nicca ArellanoÎncă nu există evaluări
- Pediatric Autonomic DisorderDocument15 paginiPediatric Autonomic DisorderaimanÎncă nu există evaluări
- CogAT 7 PlanningImplemGd v4.1 PDFDocument112 paginiCogAT 7 PlanningImplemGd v4.1 PDFBahrouniÎncă nu există evaluări
- Iso 20816 8 2018 en PDFDocument11 paginiIso 20816 8 2018 en PDFEdwin Bermejo75% (4)
- Ar 2003Document187 paginiAr 2003Alberto ArrietaÎncă nu există evaluări