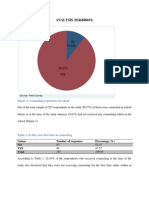
S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- 6th Central Pay Commission Salary CalculatorDocument15 pagini6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Business Applications of Multiple RegressionDocument48 paginiBusiness Applications of Multiple RegressionBusiness Expert Press50% (4)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Probabilistic Machine Learning: An IntroductionDocument826 paginiProbabilistic Machine Learning: An Introductionalasaarela100% (2)
- A Study On School DropoutsDocument6 paginiA Study On School DropoutsApam BenjaminÎncă nu există evaluări
- Oxygen Cycle: PlantsDocument3 paginiOxygen Cycle: PlantsApam BenjaminÎncă nu există evaluări
- Bookbinders Book Club Case: Assignment 5: Identifying Target Customers (Individual Assignment)Document4 paginiBookbinders Book Club Case: Assignment 5: Identifying Target Customers (Individual Assignment)stellaÎncă nu există evaluări
- Farmers' Perceptions of Mechanization and Land ReformDocument9 paginiFarmers' Perceptions of Mechanization and Land ReformJason GuiruelaÎncă nu există evaluări
- The Modelling and Computer Simulation of Mineral TreatmentDocument25 paginiThe Modelling and Computer Simulation of Mineral TreatmentDirceu NascimentoÎncă nu există evaluări
- Nitrogen Cycle: Ecological FunctionDocument8 paginiNitrogen Cycle: Ecological FunctionApam BenjaminÎncă nu există evaluări
- Impact of Feeding Practices on Infant GrowthDocument116 paginiImpact of Feeding Practices on Infant GrowthApam BenjaminÎncă nu există evaluări
- Research ProposalDocument6 paginiResearch ProposalApam BenjaminÎncă nu există evaluări
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDocument14 paginiHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminÎncă nu există evaluări
- Lecture5 Module2 Anova 1Document9 paginiLecture5 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- Counseling Experience and Location AnalysisDocument8 paginiCounseling Experience and Location AnalysisApam BenjaminÎncă nu există evaluări
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDocument12 paginiCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminÎncă nu există evaluări
- MANOVA Analysis of Plant Growth with LegumesDocument8 paginiMANOVA Analysis of Plant Growth with LegumesApam BenjaminÎncă nu există evaluări
- Lecture4 Module2 Anova 1Document9 paginiLecture4 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- Lecture7 Module2 Anova 1Document10 paginiLecture7 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaDocument9 paginiARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminÎncă nu există evaluări
- Lecture8 Module2 Anova 1Document13 paginiLecture8 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- Lecture6 Module2 Anova 1Document10 paginiLecture6 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- PLMDocument5 paginiPLMApam BenjaminÎncă nu există evaluări
- PLM IiDocument3 paginiPLM IiApam BenjaminÎncă nu există evaluări
- Ajsms 2 4 348 355Document8 paginiAjsms 2 4 348 355Akolgo PaulinaÎncă nu există evaluări
- Hosmer On Survival With StataDocument21 paginiHosmer On Survival With StataApam BenjaminÎncă nu există evaluări
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDocument7 paginiRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminÎncă nu există evaluări
- Trial Questions (PLM)Document3 paginiTrial Questions (PLM)Apam BenjaminÎncă nu există evaluări
- Personal Information: Curriculum VitaeDocument6 paginiPersonal Information: Curriculum VitaeApam BenjaminÎncă nu există evaluări
- Creating STATA DatasetsDocument4 paginiCreating STATA DatasetsApam BenjaminÎncă nu există evaluări
- How To Write A Paper For A Scientific JournalDocument10 paginiHow To Write A Paper For A Scientific JournalApam BenjaminÎncă nu există evaluări
- Banque AtlanticbanDocument1 paginăBanque AtlanticbanApam BenjaminÎncă nu există evaluări
- Asri Stata 2013-FlyerDocument1 paginăAsri Stata 2013-FlyerAkolgo PaulinaÎncă nu există evaluări
- l.4. Research QuestionsDocument1 paginăl.4. Research QuestionsApam BenjaminÎncă nu există evaluări
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDocument1 paginăMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminÎncă nu există evaluări
- Project ReportsDocument31 paginiProject ReportsBilal AliÎncă nu există evaluări
- Business Mathematics and Statistics: SyllabusDocument4 paginiBusiness Mathematics and Statistics: Syllabusanas ejazÎncă nu există evaluări
- Statistical Modeling 2 CulturesDocument18 paginiStatistical Modeling 2 Culturesinvisible_inÎncă nu există evaluări
- 4 Regression AnalysisDocument33 pagini4 Regression AnalysishijabÎncă nu există evaluări
- SM I 2013 LecturesWeek 6Document7 paginiSM I 2013 LecturesWeek 6dulanjaya jayalathÎncă nu există evaluări
- Komputasi Geologi: Muhammad Rizqy Septyandy, M.TDocument40 paginiKomputasi Geologi: Muhammad Rizqy Septyandy, M.TBagastio ラマダーンÎncă nu există evaluări
- The Determinants of Startup Valuation in The Venture Capital Context: A Systematic Review and Avenues For Future ResearchDocument34 paginiThe Determinants of Startup Valuation in The Venture Capital Context: A Systematic Review and Avenues For Future ResearchinesÎncă nu există evaluări
- Materials Handling Management:A Case Study: ArticleDocument13 paginiMaterials Handling Management:A Case Study: ArticleRINKAL LOUNGANIÎncă nu există evaluări
- 978 3 642 33712 3 PDFDocument901 pagini978 3 642 33712 3 PDFDebopriyo BanerjeeÎncă nu există evaluări
- Pol Part in Europe PDFDocument22 paginiPol Part in Europe PDFSheena PagoÎncă nu există evaluări
- A Robust Missing Value Imputation Method For Noisy DataDocument15 paginiA Robust Missing Value Imputation Method For Noisy DatacrackendÎncă nu există evaluări
- Regression Analysis AssignmentDocument8 paginiRegression Analysis Assignmentضیاء گل مروتÎncă nu există evaluări
- My PROPOSALSDocument33 paginiMy PROPOSALSdursam328Încă nu există evaluări
- Research Methods Statistics and Applications Second Edition Ebook PDF VersionDocument62 paginiResearch Methods Statistics and Applications Second Edition Ebook PDF Versiondonna.crow358100% (42)
- Probability Plots 2Document8 paginiProbability Plots 2hÎncă nu există evaluări
- Research Design For Mixed Methods: A Triangulation-Based Framework and RoadmapDocument31 paginiResearch Design For Mixed Methods: A Triangulation-Based Framework and RoadmapDavid Kusshi TakadiyiÎncă nu există evaluări
- The Identification Zoo: Meanings of Identification in EconometricsDocument10 paginiThe Identification Zoo: Meanings of Identification in EconometricsFABRIZIO QUINONEZ FLORENTINÎncă nu există evaluări
- PHD Thesis - Alfonso Palazzo 2015Document444 paginiPHD Thesis - Alfonso Palazzo 2015johanÎncă nu există evaluări
- Emerging Markets Review: Paresh Kumar Narayan, Susan Sunila Sharma, Dinh Hoang Bach Phan, Guangqiang Liu TDocument16 paginiEmerging Markets Review: Paresh Kumar Narayan, Susan Sunila Sharma, Dinh Hoang Bach Phan, Guangqiang Liu TDessy ParamitaÎncă nu există evaluări
- Determinants of Household Energy Consumption in Urban Areas of EthiopiaDocument13 paginiDeterminants of Household Energy Consumption in Urban Areas of EthiopiaSayed Imran Ur Rahman (Abid)Încă nu există evaluări
- Machine Learning Based Fatigue Life Prediction With Effects of Additivemanufacturing Process Parameters For Printed SS 316LDocument13 paginiMachine Learning Based Fatigue Life Prediction With Effects of Additivemanufacturing Process Parameters For Printed SS 316LVivekBhandarkarÎncă nu există evaluări
- Arzivian Stat 2023-281 Summer A SyllabusDocument7 paginiArzivian Stat 2023-281 Summer A SyllabusTatiana ArzivianÎncă nu există evaluări
- Nonlinear Regression Model - Quadratic ModelDocument18 paginiNonlinear Regression Model - Quadratic ModelLaura StephanieÎncă nu există evaluări
- Parental Satisfaction of Child 'S Perioperative CareDocument8 paginiParental Satisfaction of Child 'S Perioperative CareHasriana BudimanÎncă nu există evaluări
- FrontmatterDocument24 paginiFrontmatterSaivarshini RavichandranÎncă nu există evaluări
- Regression Analysis and Modeling For Decision SupportDocument45 paginiRegression Analysis and Modeling For Decision SupportRohit AgarwalÎncă nu există evaluări