S-ar putea să vă placă și
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- PON Downtown AxisDocument2 paginiPON Downtown AxisMashrur RahmanÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Nook Quick Start GuideDocument16 paginiNook Quick Start Guideyamanta_rajÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- InProc ComponentsDocument57 paginiInProc Componentssangeethaag19Încă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Tickets Vincent Van GoghDocument4 paginiTickets Vincent Van GoghCitlali LlamasÎncă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Resultats EnqueteDocument63 paginiResultats EnqueteSenthil KumarÎncă nu există evaluări
- RMSA Assam Advt....Document5 paginiRMSA Assam Advt....nazmulÎncă nu există evaluări
- NEW Cultural Centre SynopsisDocument32 paginiNEW Cultural Centre SynopsisAkshat SharmaÎncă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Plex Getting Started ENUDocument21 paginiPlex Getting Started ENUjonathan hernandezÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Quiz 1843 TOEFL Primary 1 Book 1 Unit 3 at The Library Mike in The LibraryDocument4 paginiQuiz 1843 TOEFL Primary 1 Book 1 Unit 3 at The Library Mike in The LibraryHanhbeo VuÎncă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Bushby Tony - The Forged Origins of The New TestamentDocument11 paginiBushby Tony - The Forged Origins of The New Testamentsavoisien88100% (4)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- THOMPSON, Nato - Living As Form PDFDocument11 paginiTHOMPSON, Nato - Living As Form PDFJoão Paulo AndradeÎncă nu există evaluări
- 2006-04-21Document14 pagini2006-04-21The University Daily KansanÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- CLASS VII - FinalDocument85 paginiCLASS VII - FinalRebecca LutherÎncă nu există evaluări
- PointillismDocument10 paginiPointillismalejandro jeanÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- (New Studies in American Intellectual and Cultural History) Oz Frankel - States of Inquiry_ Social Investigations and Print Culture in Nineteenth-Century Britain and the United States-The Johns HopkinDocument383 pagini(New Studies in American Intellectual and Cultural History) Oz Frankel - States of Inquiry_ Social Investigations and Print Culture in Nineteenth-Century Britain and the United States-The Johns HopkinEmilia Avis100% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Sports & Sportsmen - Hunting Part IDocument109 paginiSports & Sportsmen - Hunting Part IThe 18th Century Material Culture Resource Center100% (13)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Lightroom SDK 3.2 GuideDocument204 paginiLightroom SDK 3.2 Guideiliade2012Încă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- AP Art History-David PaperDocument4 paginiAP Art History-David PaperNishant GroverÎncă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- JavaFX 2 Tutorial Part VII - Deployment With e (FX) Clipse - Edu - Makery PDFDocument13 paginiJavaFX 2 Tutorial Part VII - Deployment With e (FX) Clipse - Edu - Makery PDFManuel Alejandro Paredes GranadosÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Diversity in Rain Forests and Coral ReefsDocument17 paginiDiversity in Rain Forests and Coral ReefsKike EscobarÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Adobe Flash LectureDocument10 paginiAdobe Flash Lecturelorshie127Încă nu există evaluări
- OPC Data Manager ManualDocument50 paginiOPC Data Manager ManualiedmondÎncă nu există evaluări
- Mahendras Reasoning Practice Set 2Document33 paginiMahendras Reasoning Practice Set 2abhishekchauhan0096429Încă nu există evaluări
- MAD Unit4Document125 paginiMAD Unit4Rithika ThakurÎncă nu există evaluări
- An Analysis of Current Awareness Services and Selective Dissemination of Information in University of JOS LibraryDocument12 paginiAn Analysis of Current Awareness Services and Selective Dissemination of Information in University of JOS LibraryTiago AlmeidaÎncă nu există evaluări
- Assignment No1 of Modern Programming Tools & Techniques Iii: Submitted To Submitted BYDocument8 paginiAssignment No1 of Modern Programming Tools & Techniques Iii: Submitted To Submitted BYAnkur SinghÎncă nu există evaluări
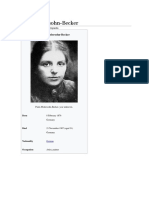
- Paula ModersohnDocument9 paginiPaula ModersohnMawaddahÎncă nu există evaluări
- The Art Market's Presence OnlineDocument9 paginiThe Art Market's Presence Onlinealexander_podosenovÎncă nu există evaluări
- Curriculum Community and Urban School ReformDocument273 paginiCurriculum Community and Urban School ReformmarnekibÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Case of The Kate HatersDocument132 paginiCase of The Kate HatersJayson HaughtonÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)