S-ar putea să vă placă și
- Research ProposalDocument6 paginiResearch ProposalApam BenjaminÎncă nu există evaluări
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Document8 paginiMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminÎncă nu există evaluări
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDocument12 paginiCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminÎncă nu există evaluări
- Oxygen Cycle: PlantsDocument3 paginiOxygen Cycle: PlantsApam BenjaminÎncă nu există evaluări
- Nitrogen Cycle: Ecological FunctionDocument8 paginiNitrogen Cycle: Ecological FunctionApam BenjaminÎncă nu există evaluări
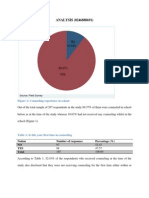
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocument8 paginiANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminÎncă nu există evaluări
- Lecture8 Module2 Anova 1Document13 paginiLecture8 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- PLM IiDocument3 paginiPLM IiApam BenjaminÎncă nu există evaluări
- Lecture6 Module2 Anova 1Document10 paginiLecture6 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- Lecture7 Module2 Anova 1Document10 paginiLecture7 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- Lecture4 Module2 Anova 1Document9 paginiLecture4 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- PLMDocument5 paginiPLMApam BenjaminÎncă nu există evaluări
- Lecture5 Module2 Anova 1Document9 paginiLecture5 Module2 Anova 1Apam BenjaminÎncă nu există evaluări
- Hosmer On Survival With StataDocument21 paginiHosmer On Survival With StataApam BenjaminÎncă nu există evaluări
- Finish WorkDocument116 paginiFinish WorkApam BenjaminÎncă nu există evaluări
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDocument7 paginiRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminÎncă nu există evaluări
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaDocument9 paginiARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminÎncă nu există evaluări
- Personal Information: Curriculum VitaeDocument6 paginiPersonal Information: Curriculum VitaeApam BenjaminÎncă nu există evaluări
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDocument14 paginiHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminÎncă nu există evaluări
- Trial Questions (PLM)Document3 paginiTrial Questions (PLM)Apam BenjaminÎncă nu există evaluări
- A Study On School DropoutsDocument6 paginiA Study On School DropoutsApam BenjaminÎncă nu există evaluări
- Ajsms 2 4 348 355Document8 paginiAjsms 2 4 348 355Akolgo PaulinaÎncă nu există evaluări
- How To Write A Paper For A Scientific JournalDocument10 paginiHow To Write A Paper For A Scientific JournalApam BenjaminÎncă nu există evaluări
- 6th Central Pay Commission Salary CalculatorDocument15 pagini6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Creating STATA DatasetsDocument4 paginiCreating STATA DatasetsApam BenjaminÎncă nu există evaluări
- Banque AtlanticbanDocument1 paginăBanque AtlanticbanApam BenjaminÎncă nu există evaluări
- l.4. Research QuestionsDocument1 paginăl.4. Research QuestionsApam BenjaminÎncă nu există evaluări
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDocument1 paginăMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminÎncă nu există evaluări
- Asri Stata 2013-FlyerDocument1 paginăAsri Stata 2013-FlyerAkolgo PaulinaÎncă nu există evaluări
- Project ReportsDocument31 paginiProject ReportsBilal AliÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- SEMM1911 Case Study 2 2022Document2 paginiSEMM1911 Case Study 2 2022Ruby RoseÎncă nu există evaluări
- Y13 Stats and Mechanics PracticeDocument4 paginiY13 Stats and Mechanics Practicekhadijaliyu3Încă nu există evaluări
- Week 7 - Data Intelligence PDFDocument42 paginiWeek 7 - Data Intelligence PDFloompapasÎncă nu există evaluări
- In Vitro Cytotoxicity of Different Thermoplastic Materials For Clear AlignersDocument4 paginiIn Vitro Cytotoxicity of Different Thermoplastic Materials For Clear AlignersIsmaelLouGomezÎncă nu există evaluări
- New Academic Wordlist With Arabic DefinitionsDocument149 paginiNew Academic Wordlist With Arabic Definitionsahibba.03862Încă nu există evaluări
- 000 Statistical Quality Control-Lec 3Document72 pagini000 Statistical Quality Control-Lec 3Arwa HusseinÎncă nu există evaluări
- Estimating Dynamic Common Correlated Effects Models in StataDocument41 paginiEstimating Dynamic Common Correlated Effects Models in StataSAWADOGOÎncă nu există evaluări
- Dr. Alonzo A. Gabriel-Hurdle Technology-Based Fruit Beverage ProcessingDocument32 paginiDr. Alonzo A. Gabriel-Hurdle Technology-Based Fruit Beverage ProcessingnataliatirtaÎncă nu există evaluări
- Elongation Tolerance - ACI Structural Journal - July 2017Document8 paginiElongation Tolerance - ACI Structural Journal - July 2017المصفوفة الحديثةÎncă nu există evaluări
- Demography Surveillance and Interpretation of DataDocument27 paginiDemography Surveillance and Interpretation of DataSonali SwainÎncă nu există evaluări
- An Overview and Framework For PD Backtesting and BenchmarkingDocument16 paginiAn Overview and Framework For PD Backtesting and BenchmarkingCISSE SerigneÎncă nu există evaluări
- Aimsun Dynamic Simulators Users Manual v7 PDFDocument480 paginiAimsun Dynamic Simulators Users Manual v7 PDFJorge OchoaÎncă nu există evaluări
- 2017 - The Effects of Improving Sleep On Mental Health (OASIS) A Randomised Controlled Trial With Mediation Analysis - Freeman Et AlDocument10 pagini2017 - The Effects of Improving Sleep On Mental Health (OASIS) A Randomised Controlled Trial With Mediation Analysis - Freeman Et AlFabian MaeroÎncă nu există evaluări
- T Test and ANOVA - Test: (Use Demo Discriptive - Sav Data File)Document5 paginiT Test and ANOVA - Test: (Use Demo Discriptive - Sav Data File)ishwaryaÎncă nu există evaluări
- Reciprocal ModelDocument7 paginiReciprocal ModelPalak SharmaÎncă nu există evaluări
- Tutorials On The Usage of The Geo RDocument113 paginiTutorials On The Usage of The Geo RGloria AcostaÎncă nu există evaluări
- Moments of Distribution, Skewness, KurtosisDocument16 paginiMoments of Distribution, Skewness, KurtosisAditya SharmaÎncă nu există evaluări
- StataCheatSheet AnalysisDocument1 paginăStataCheatSheet AnalysissgoranksÎncă nu există evaluări
- E-Learning Its Effectiveness As A Teaching Method ForDocument76 paginiE-Learning Its Effectiveness As A Teaching Method ForChristian Atuel100% (1)
- 150114863016cre Textnayeemshowkatnonprobabilityandprobabilitysampling PDFDocument10 pagini150114863016cre Textnayeemshowkatnonprobabilityandprobabilitysampling PDFFajriÎncă nu există evaluări
- Hypothesis Testing: Procedure in Testing Hypothesis Hypothesis Testing Using P-Value One Sample Z Test One Sample T TestDocument37 paginiHypothesis Testing: Procedure in Testing Hypothesis Hypothesis Testing Using P-Value One Sample Z Test One Sample T TestLenard Del Mundo0% (1)
- A Multi-Dimensional Study On The Relationship of Emotional Intelligence in Nursing StudentsDocument6 paginiA Multi-Dimensional Study On The Relationship of Emotional Intelligence in Nursing StudentsFrancis AdrianÎncă nu există evaluări
- Six Sigma ToolsDocument56 paginiSix Sigma Toolslandersjc100% (1)
- Mark-Recapture Lab: BIOL 3370LDocument2 paginiMark-Recapture Lab: BIOL 3370Lapi-475993899Încă nu există evaluări
- Impact of Motivational Factors On Employee's Job SatisfactionDocument12 paginiImpact of Motivational Factors On Employee's Job SatisfactionFerri WicaksonoÎncă nu există evaluări
- Price Transmission Asymmetry in Spatial Grain Markets in EthiopiaDocument11 paginiPrice Transmission Asymmetry in Spatial Grain Markets in EthiopiaSalah MuhammedÎncă nu există evaluări
- Operations Management Chapter 3Document37 paginiOperations Management Chapter 3Tina Dulla67% (3)
- Quantitative Techniques - WWW - Ifrsiseasy.com - NG PDFDocument561 paginiQuantitative Techniques - WWW - Ifrsiseasy.com - NG PDFAromasodun Omobolanle IswatÎncă nu există evaluări
- Jurnal InternationalDocument8 paginiJurnal InternationalSherly AuliaÎncă nu există evaluări
- Rasch ModelDocument3 paginiRasch ModelRaj'z KingzterÎncă nu există evaluări