S-ar putea să vă placă și
- The Likert Scale Used in Research On Affect - A Short Discussion of Terminology and Appropriate Analysing MethodsDocument11 paginiThe Likert Scale Used in Research On Affect - A Short Discussion of Terminology and Appropriate Analysing MethodsSingh VirgoÎncă nu există evaluări
- Likert PDFDocument16 paginiLikert PDFWahaaj AhmadÎncă nu există evaluări
- Likert Scale: PsychometricDocument9 paginiLikert Scale: PsychometricSamir Kumar SahuÎncă nu există evaluări
- LikertDocument13 paginiLikertTyler RinkerÎncă nu există evaluări
- Likert Scale Instructions On IBM SPSS 21Document16 paginiLikert Scale Instructions On IBM SPSS 21Andrey OrcalesÎncă nu există evaluări
- Resolving The 50 Year Debate Around Using and Misusing Likert ScalesDocument3 paginiResolving The 50 Year Debate Around Using and Misusing Likert Scalesrichardwtam100% (1)
- College of Nursing: Assignment ON Likert ScaleDocument6 paginiCollege of Nursing: Assignment ON Likert ScalePriyaÎncă nu există evaluări
- Analyzing Data Measured by Individual Likert-Type ItemsDocument5 paginiAnalyzing Data Measured by Individual Likert-Type ItemsCheNad NadiaÎncă nu există evaluări
- Measurement and Likert Scales PDFDocument3 paginiMeasurement and Likert Scales PDFZorille dela CruzÎncă nu există evaluări
- Toward A Common Procedure Using Likert and Likert-Type Scales in Small Groups Comparative Design ObservationsDocument10 paginiToward A Common Procedure Using Likert and Likert-Type Scales in Small Groups Comparative Design ObservationsParotÎncă nu există evaluări
- Analyzing Likert DataDocument5 paginiAnalyzing Likert Dataalphane2300100% (1)
- Questionnaires Lickert Cronbach WikipediaDocument8 paginiQuestionnaires Lickert Cronbach WikipediaArslan SheikhÎncă nu există evaluări
- Likert ScaleDocument5 paginiLikert ScaleAhmad PiraieeÎncă nu există evaluări
- Likert ScaleDocument35 paginiLikert ScaleGanesh SahÎncă nu există evaluări
- Misuse of Likert RatingDocument6 paginiMisuse of Likert Ratingsyu6678Încă nu există evaluări
- Another Look at Likert Scales-2016Document14 paginiAnother Look at Likert Scales-2016Kanagu RajaÎncă nu există evaluări
- Analyzing Likert DataDocument6 paginiAnalyzing Likert DataYC ChewÎncă nu există evaluări
- Likert ScaleDocument8 paginiLikert ScaleNeelam ShuklaÎncă nu există evaluări
- Likert Scale DissertationDocument7 paginiLikert Scale DissertationPaperWritersForCollegeUK100% (1)
- Likert Scale (Muhammad Amirrul Fahmi Bin Mukhtar)Document12 paginiLikert Scale (Muhammad Amirrul Fahmi Bin Mukhtar)Fahmi_mukhtarÎncă nu există evaluări
- Literature Review On Likert ScaleDocument5 paginiLiterature Review On Likert Scalefvgj0kvd100% (1)
- Scale of MeasurementDocument5 paginiScale of MeasurementSTEPHY LANCYÎncă nu există evaluări
- How To Use The Likert Scale in Statistical AnalysisDocument3 paginiHow To Use The Likert Scale in Statistical AnalysisAbhinandan Mishra100% (1)
- 3 Ways To Measure Employee EngagementDocument12 pagini3 Ways To Measure Employee Engagementsubbarao venkataÎncă nu există evaluări
- Likert ScaleDocument6 paginiLikert ScaleVanya MaximovÎncă nu există evaluări
- Likert Scales and Data Analyses + QuartileDocument6 paginiLikert Scales and Data Analyses + QuartileBahrouniÎncă nu există evaluări
- Psychmet 2atekhayeDocument8 paginiPsychmet 2atekhayeCherie Faye EstacioÎncă nu există evaluări
- Using Likert Type Data in Social Science Research: Confusion, Issues and ChallengesDocument14 paginiUsing Likert Type Data in Social Science Research: Confusion, Issues and Challengesanon_284779974Încă nu există evaluări
- A Rasch Analysis On Collapsing Categories in Item - S Response Scales of Survey Questionnaire Maybe It - S Not One Size Fits All PDFDocument29 paginiA Rasch Analysis On Collapsing Categories in Item - S Response Scales of Survey Questionnaire Maybe It - S Not One Size Fits All PDFNancy NgÎncă nu există evaluări
- 01 A Note On The Usage of Likert Scaling For Research Data AnalysisDocument5 pagini01 A Note On The Usage of Likert Scaling For Research Data AnalysisFKIAÎncă nu există evaluări
- Handout #4: Measuring VariablesDocument8 paginiHandout #4: Measuring VariablesSachin KhotÎncă nu există evaluări
- The Likert Scale Revisited: An Alternate Version. (Product Preference Testing)Document12 paginiThe Likert Scale Revisited: An Alternate Version. (Product Preference Testing)LucienÎncă nu există evaluări
- Thurstone Scale, Likert Scale and Seman몭c Differen몭al ScaleDocument8 paginiThurstone Scale, Likert Scale and Seman몭c Differen몭al ScaleAyush ChauhanÎncă nu există evaluări
- JKMIT 1.2 Final Composed 2.42-55 SNDocument15 paginiJKMIT 1.2 Final Composed 2.42-55 SNFauzul AzhimahÎncă nu există evaluări
- Semantic Differential2Document8 paginiSemantic Differential2amandguraya91293Încă nu există evaluări
- The Influence of Likert Scale Format On Response Result, Validity, and Reliability of Scale - Using Scales Measuring Economic Shopping OrientationDocument15 paginiThe Influence of Likert Scale Format On Response Result, Validity, and Reliability of Scale - Using Scales Measuring Economic Shopping OrientationlengocthangÎncă nu există evaluări
- Likert Scales and Data AnalysesDocument4 paginiLikert Scales and Data AnalysesPedro Mota VeigaÎncă nu există evaluări
- Carifio & Perla 2008 Resolving The 50 Year Debate On Likert Scales PDFDocument4 paginiCarifio & Perla 2008 Resolving The 50 Year Debate On Likert Scales PDFtrÎncă nu există evaluări
- Validity and Reliability of Survey Scales: About The AuthorsDocument16 paginiValidity and Reliability of Survey Scales: About The AuthorsgezahegnÎncă nu există evaluări
- Jamieson2004 Likert ScalesDocument7 paginiJamieson2004 Likert ScalesrobertphilÎncă nu există evaluări
- 8614 Assignment 1Document14 pagini8614 Assignment 1Madiha RubabÎncă nu există evaluări
- Fundamentals of Statistics 1Document3 paginiFundamentals of Statistics 1Rochelle PrieteÎncă nu există evaluări
- Usos e Abusos Da Escala Likert: Estudo Bibliométrico Nos Anais Do Enanpad de 2010 A 2015Document19 paginiUsos e Abusos Da Escala Likert: Estudo Bibliométrico Nos Anais Do Enanpad de 2010 A 2015Henri BarrisÎncă nu există evaluări
- Mpiklp Sekala LikertDocument47 paginiMpiklp Sekala LikertRizky Faqot100% (1)
- Template - Chapter 03Document12 paginiTemplate - Chapter 03Ruby Jane DuradoÎncă nu există evaluări
- Chapter 12 Notes...Document4 paginiChapter 12 Notes...Aqib khan MastoiÎncă nu există evaluări
- Variables and Research DesignDocument30 paginiVariables and Research DesignfarahisÎncă nu există evaluări
- Intro To Measurement and StatisticsDocument6 paginiIntro To Measurement and Statisticsjeff omangaÎncă nu există evaluări
- A Reply To "A Critique To Using Rasch Analysis To Create and Evaluate A Measurement Instrument For Foreign Language Classroom Speaking Anxiety' "Document4 paginiA Reply To "A Critique To Using Rasch Analysis To Create and Evaluate A Measurement Instrument For Foreign Language Classroom Speaking Anxiety' "lucianaeuÎncă nu există evaluări
- Like RT Fact SheetDocument11 paginiLike RT Fact SheetDeepak Daya MattaÎncă nu există evaluări
- Quantitative Research Methods For Linguists - A Questions and Answers Approach For StudentsDocument18 paginiQuantitative Research Methods For Linguists - A Questions and Answers Approach For StudentsSantiago Ruiz VegaÎncă nu există evaluări
- Analyzing and Interpreting Data From LikertDocument3 paginiAnalyzing and Interpreting Data From LikertAnonymous FeGW7wGm0Încă nu există evaluări
- From Verbal Scales To Numerical Scales in Decision MakingDocument58 paginiFrom Verbal Scales To Numerical Scales in Decision MakingOlga SavescuÎncă nu există evaluări
- Mba MB 0050 Set 1 Research MethodologyDocument12 paginiMba MB 0050 Set 1 Research MethodologyPreeti SuranaÎncă nu există evaluări
- Application of Fuzzy Logic To Improve The Likert SDocument8 paginiApplication of Fuzzy Logic To Improve The Likert SLettera MatematicaÎncă nu există evaluări
- Do Data Characteristics Change According To The Number of Scale Points Used ? An Experiment Using 5 Point, 7 Point and 10 Point Scales.Document20 paginiDo Data Characteristics Change According To The Number of Scale Points Used ? An Experiment Using 5 Point, 7 Point and 10 Point Scales.Angela GarciaÎncă nu există evaluări
- Maniba Bhula Nursing College: Sub: Nursing Education Topic: Attitude ScaleDocument13 paginiManiba Bhula Nursing College: Sub: Nursing Education Topic: Attitude Scalehiral mistry100% (2)
- Qualitative Research:: Intelligence for College StudentsDe la EverandQualitative Research:: Intelligence for College StudentsEvaluare: 4 din 5 stele4/5 (1)
- T-Building A CandE MatrixDocument11 paginiT-Building A CandE MatrixAbraxas LuchenkoÎncă nu există evaluări
- Accreditation StandardsDocument20 paginiAccreditation StandardsAbraxas LuchenkoÎncă nu există evaluări
- Reliabillity and ValidityDocument9 paginiReliabillity and ValidityAlbyziaÎncă nu există evaluări
- Maurice Nicoll The Mark PDFDocument4 paginiMaurice Nicoll The Mark PDFErwin KroonÎncă nu există evaluări
- Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling TestsDocument13 paginiPower Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling TestsAbraxas LuchenkoÎncă nu există evaluări
- Monitoring and EvaluationDocument18 paginiMonitoring and EvaluationAbraxas LuchenkoÎncă nu există evaluări
- Matrix Algebra For Beginners, Part I Matrices, Determinants, InversesDocument16 paginiMatrix Algebra For Beginners, Part I Matrices, Determinants, InversesAbraxas LuchenkoÎncă nu există evaluări
- L06 Top 10 Economic IndicatorsDocument4 paginiL06 Top 10 Economic IndicatorsabcjhkfajsgkÎncă nu există evaluări
- ScalingDocument11 paginiScalingAbraxas LuchenkoÎncă nu există evaluări
- Technical SpecificationDocument6 paginiTechnical SpecificationAbraxas LuchenkoÎncă nu există evaluări
- Matrix Algebra For Beginners, Part I Matrices, Determinants, InversesDocument16 paginiMatrix Algebra For Beginners, Part I Matrices, Determinants, InversesAbraxas LuchenkoÎncă nu există evaluări
- Fu ZEds 7 PDocument9 paginiFu ZEds 7 PAbraxas LuchenkoÎncă nu există evaluări
- The ABC Model of Attitudes - Affect, Behavior & Cognition - Social Psychology VideoDocument3 paginiThe ABC Model of Attitudes - Affect, Behavior & Cognition - Social Psychology VideoAbraxas Luchenko0% (1)
- GP 2000 02Document2 paginiGP 2000 02Abraxas LuchenkoÎncă nu există evaluări
- Deriving Valid Expressions From Ontology Definitions: Yannis Tzitzikas, Nicolas Spyratos, Panos ConstantopoulosDocument18 paginiDeriving Valid Expressions From Ontology Definitions: Yannis Tzitzikas, Nicolas Spyratos, Panos ConstantopoulosAbraxas LuchenkoÎncă nu există evaluări
- Organizational Maturity LevelsDocument5 paginiOrganizational Maturity LevelsAnggun WinursitoÎncă nu există evaluări
- Ch10 AnswersDocument7 paginiCh10 AnswersAbraxas LuchenkoÎncă nu există evaluări
- Ds 9 A FBNKDocument4 paginiDs 9 A FBNKAbraxas LuchenkoÎncă nu există evaluări
- Dip UVCqbDocument5 paginiDip UVCqbAbraxas LuchenkoÎncă nu există evaluări
- Estándares Wfme Pre-GradoDocument36 paginiEstándares Wfme Pre-GradopsychforallÎncă nu există evaluări
- Dip UVCqbDocument5 paginiDip UVCqbAbraxas LuchenkoÎncă nu există evaluări
- Reliability and Generalizability of Performance Judgments Based On A Video PortfolioDocument30 paginiReliability and Generalizability of Performance Judgments Based On A Video PortfolioAbraxas LuchenkoÎncă nu există evaluări
- Deriving Valid Expressions From Ontology Definitions: Yannis Tzitzikas, Nicolas Spyratos, Panos ConstantopoulosDocument18 paginiDeriving Valid Expressions From Ontology Definitions: Yannis Tzitzikas, Nicolas Spyratos, Panos ConstantopoulosAbraxas LuchenkoÎncă nu există evaluări
- Chicago 2009Document2 paginiChicago 2009Muktadir Boksh DulonÎncă nu există evaluări
- Lecture 11 Evaluation of Diagnostic and Screening Tests Validity and Reliability KanchanaraksaDocument82 paginiLecture 11 Evaluation of Diagnostic and Screening Tests Validity and Reliability Kanchanaraksapaster125Încă nu există evaluări
- Reliability and Generalizability of Performance Judgments Based On A Video PortfolioDocument30 paginiReliability and Generalizability of Performance Judgments Based On A Video PortfolioAbraxas LuchenkoÎncă nu există evaluări
- NIH Public Access: Author ManuscriptDocument15 paginiNIH Public Access: Author ManuscriptAbraxas LuchenkoÎncă nu există evaluări
- Example ExploratoryFactorAnalysisDocument2 paginiExample ExploratoryFactorAnalysisAbraxas LuchenkoÎncă nu există evaluări
- Morseetal - Verification Strategies For Establishing Reliability and ValidityDocument19 paginiMorseetal - Verification Strategies For Establishing Reliability and ValidityAbraxas LuchenkoÎncă nu există evaluări
- S 388 2007 LampiranDocument18 paginiS 388 2007 LampiranAbraxas LuchenkoÎncă nu există evaluări
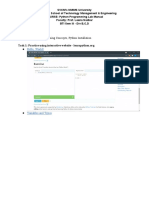
- Week - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationDocument13 paginiWeek - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationSahil Shah100% (1)
- Barrett Beyond Psychometrics 2003 AugmentedDocument34 paginiBarrett Beyond Psychometrics 2003 AugmentedRoy Umaña CarrilloÎncă nu există evaluări
- SOCIAL MEDIA DEBATE ScriptDocument3 paginiSOCIAL MEDIA DEBATE Scriptchristine baraÎncă nu există evaluări
- Crisis of The World Split Apart: Solzhenitsyn On The WestDocument52 paginiCrisis of The World Split Apart: Solzhenitsyn On The WestdodnkaÎncă nu există evaluări
- G1000 Us 1014 PDFDocument820 paginiG1000 Us 1014 PDFLuís Miguel RomãoÎncă nu există evaluări
- Persuasive Speech 2016 - Whole Person ParadigmDocument4 paginiPersuasive Speech 2016 - Whole Person Paradigmapi-311375616Încă nu există evaluări
- Electrical Engineering Lab Vica AnDocument6 paginiElectrical Engineering Lab Vica Anabdulnaveed50% (2)
- Report DR JuazerDocument16 paginiReport DR Juazersharonlly toumasÎncă nu există evaluări
- Environmental Science 13th Edition Miller Test BankDocument18 paginiEnvironmental Science 13th Edition Miller Test Bankmarykirbyifsartwckp100% (14)
- Camless EnginesDocument4 paginiCamless EnginesKavya M BhatÎncă nu există evaluări
- Bench-Scale Decomposition of Aluminum Chloride Hexahydrate To Produce Poly (Aluminum Chloride)Document5 paginiBench-Scale Decomposition of Aluminum Chloride Hexahydrate To Produce Poly (Aluminum Chloride)varadjoshi41Încă nu există evaluări
- S Setting Value, C Check Value) OT Outside Tolerance (X Is Set)Document1 paginăS Setting Value, C Check Value) OT Outside Tolerance (X Is Set)BaytolgaÎncă nu există evaluări
- Operator'S Manual Diesel Engine: 2L41C - 2M41 - 2M41ZDocument110 paginiOperator'S Manual Diesel Engine: 2L41C - 2M41 - 2M41ZMauricio OlayaÎncă nu există evaluări
- Community Architecture Concept PDFDocument11 paginiCommunity Architecture Concept PDFdeanÎncă nu există evaluări
- LEMBAR JAWABAN CH.10 (Capital Budgeting Techniques)Document4 paginiLEMBAR JAWABAN CH.10 (Capital Budgeting Techniques)Cindy PÎncă nu există evaluări
- Amritsar Police StationDocument5 paginiAmritsar Police StationRashmi KbÎncă nu există evaluări
- Working Capital Management 2012 of HINDALCO INDUSTRIES LTD.Document98 paginiWorking Capital Management 2012 of HINDALCO INDUSTRIES LTD.Pratyush Dubey100% (1)
- KCG-2001I Service ManualDocument5 paginiKCG-2001I Service ManualPatrick BouffardÎncă nu există evaluări
- Nfpa 1126 PDFDocument24 paginiNfpa 1126 PDFL LÎncă nu există evaluări
- LLM Letter Short LogoDocument1 paginăLLM Letter Short LogoKidMonkey2299Încă nu există evaluări
- SurveyingDocument26 paginiSurveyingDenise Ann Cuenca25% (4)
- Inventions Over The Last 100 YearsDocument3 paginiInventions Over The Last 100 YearsHombreMorado GamerYTÎncă nu există evaluări
- Lesson 1: Composition: Parts of An EggDocument22 paginiLesson 1: Composition: Parts of An Eggjohn michael pagalaÎncă nu există evaluări
- EZ Water Calculator 3.0.2Document4 paginiEZ Water Calculator 3.0.2adriano70Încă nu există evaluări
- Unit 2 - Industrial Engineering & Ergonomics - WWW - Rgpvnotes.inDocument15 paginiUnit 2 - Industrial Engineering & Ergonomics - WWW - Rgpvnotes.inSACHIN HANAGALÎncă nu există evaluări
- Beyond Models and Metaphors Complexity Theory, Systems Thinking and - Bousquet & CurtisDocument21 paginiBeyond Models and Metaphors Complexity Theory, Systems Thinking and - Bousquet & CurtisEra B. LargisÎncă nu există evaluări
- Designing and Drawing PropellerDocument4 paginiDesigning and Drawing Propellercumpio425428100% (1)
- Final Self Hypnosis Paperback For PrintDocument150 paginiFinal Self Hypnosis Paperback For PrintRic Painter100% (12)
- Embedded Systems Online TestingDocument6 paginiEmbedded Systems Online TestingPuspala ManojkumarÎncă nu există evaluări
- Nescom Test For AM (Electrical) ImpDocument5 paginiNescom Test For AM (Electrical) Impشاہد یونسÎncă nu există evaluări