Documente Academic
Documente Profesional
Documente Cultură
Course Notes Statistics
Încărcat de
Sam CincoDrepturi de autor
Formate disponibile
Partajați acest document
Partajați sau inserați document
Vi se pare util acest document?
Este necorespunzător acest conținut?
Raportați acest documentDrepturi de autor:
Formate disponibile
Course Notes Statistics
Încărcat de
Sam CincoDrepturi de autor:
Formate disponibile
JDEUSTAQUIO
1
Defining What Statistics Really Is
1.1 Nature of Statistics
The term Statistics came from the Latin word status which could be translated as
state. The usage of this term only became popular during the 18
th
century where they defined
Statistics as the science of dealing with data about the condition of a state or community. The
practice of statistics could be traced back even from the early biblical times where they gather
figures related to governance of the state for they realized the importance of these figures in
governing the people.
Even until today, worldwide, governments have intensified their data gathering and
even widen the scope of their numerical figures due to the rise of more cost-efficient methods
for collecting data. Some of the most popular figures that are being released by almost all
countries are Gross National Product (GNP), Birth rates, Mortality Rates, Unemployment Rate,
Literacy Rates and Foreign Currency Exchange Rates.
Also, the use of Statistics is not limited to government use only. Right now, almost all
business sectors and fields of study use statistics. Statistics serves as the guiding principle in
their decision making and helps them come up with sound actions as supported by the analysis
done in their available information.
Indicated below are some of the uses of Statistics in various fields:
Medicine: Medical Researchers use statistics in testing the feasibility or even the
efficacy of newly developed drugs. Statistics is also used to understand the spread of
the disease and study their prevention, diagnosis, prognosis and treatment
(Epidemiology).
JDEUSTAQUIO
2
Statistics is the branch of science that deals with the collection, presentation,
organization, analysis and interpretation of data.
1.2 Basic Concepts
Economics: Statistics aids Economists analyze international and local markets by
estimating some Key Performance Indicators (KPI) such as unemployment rate,
GNP/GDP, amount of exports and imports. It is also used to forecast economic
fluctuations and trends.
Market Research: derives statistics by conducting surveys and coming up decisions
from these statistics through feasibility studies or for testing the marketability of a new
product.
Manufacturing: use statistics to assure the quality of their products through the use of
sampling and testing some of their outputs
Accounting/Auditing: uses sampling techniques in statistics to examine and check
their financial books.
Education: Educators use statistical methods to determine the validity and reliability of
their testing procedures and evaluating the performance of teachers and students.
We normally hear the word statistics when people are talking about basketball or the vital
statistics of beauty contestants. In this context the word statistics is used in the plural form which
simply means a numerical figure. But the field of Statistics is not only limited to these simple figures and
archiving them. In the context of this course, the definition of Statistics is mainly about the study of
the theory and applications of the scientific methods dealing all about the data and making sound
decisions on this.
Sometimes, gathering the entire collection of elements is very tedious, expensive or even time-
consuming. Because of this data gatherers sometimes resort to collecting just a portion of the entire
collection of elements. The term coined for the entire collection of elements is called Population while
the subset of the population is referred as the Sample.
JDEUSTAQUIO
3
Population is the collection of all elements under consideration in a statistical inquiry
while the sample is a subset of a population.
The variable is a characteristic or attribute of the elements in a collection that can
assume different values for the different elements. While an observation is a realized
value of the variable, and the collection of these observations is called the data.
THINK: Could you say that the entire population is also a sample?
The specification of the population of interest depends upon the scope of the study.
Lets say that if we wish to know the average expenditure of all households in Metro Manila,
then the population of interest is the collection of all households in Metro Manila. If there is a
need to delimit the scope of the study due to some constraints, we could redefine the
population of interest. We could delimit the scope of the study to only specific city in Metro
Manila. With this the study would only include the collection of all households in ________
City.
The elements of the population is not only limited to individuals, it can be objects,
animals, geographical areas, in other words, almost anything. Some examples of possible
populations are: the set of laborers in a certain manufacturing plant, the set of foreigners
residing on Boracay for a certain day, set of Ford Fiesta produced in the entire Philippines on a
month.
In any studies involving the use of Statistics, there would be at least one attribute of the
element in the population which we would be studying. This attribute or characteristic is what
we call variable. Just like in the field of Mathematics, we normally denote a variable with a
single capital letter i.e. A, X, Z.
Example: The Department of Health is interested in determining the percentage of children
below 12 years old infected by the Hepatitis B virus in Metro Manila in 2006.
Population: Set of all children below 12 years old in Metro Manila in 2006
Variable of Interest: whether or not the child has ever been infected by the Hepatitis B virus.
Possible Observations: Infected, Never Infected
Regardless of whether every element of the data on the population or sample is used, it
is often still difficult to convey meaning to these observations is not summarized. This is the
JDEUSTAQUIO
4
The parameter is a summary measure describing a specific characteristic of a population
while a statistic is a summary measure describing a specific characteristic of the sample.
1.3 Fields of Statistics
Descriptive Statistics includes all the techniques used in organizing, summarizing, and
presenting the data on hand, while Inferential Statistics includes all the techniques used
in analyzing the sample data that will lead to generalizations about a population from
which the sample came from.
reason why it is important to condense these observations to a single figure to completely
describe the entire data. This condensed value is what we call summary measure.
There are two major fields in Statistics. The first one is (i) Applied Statistics, this deals
mainly with the procedures and techniques used in the collection, presentation, organization,
analysis and interpretation of data. On the other hand, the second one is (ii) Mathematical
Statistics, which is concerned with the development of the mathematical foundations of the
methods used in Applied Statistics.
In this course, we would mostly deal with the basics of Applied Statistics. This field
could also by sub-divided into two areas of interest. These two are Descriptive and Inferential
Statistics. Both are definitive of their names.
To clarify, we may use descriptive statistics for population data or sample data. If we
are dealing with population data, then the results of the study are applicable only to the
defined population. In the same manner, if we use descriptive statistics to sample data, then
the conclusions are applicable only to the selected sample.
JDEUSTAQUIO
5
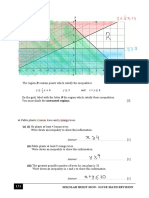
1.4 Statistical Inquiry
Statistical Inquiry is a designed research that provides information needed to solve a
research problem.
Oftentimes, researchers can now find an appropriate statistical technique that will help them
answer their research problems. This is because o the wide array of applications of the various statistical
techniques used in a statistical inquiry. Below is the diagram depicting the entire process of statistical
inquiry.
Step 1:
Identify the Problem
Step 2
Plan the Study
Step 3
Collect the Data
Step 4
Explore the Data
Step 5
Analyze Data and Interpret the Results
Step 6
Present the Results
JDEUSTAQUIO
6
Theory without data is just an Opinion
2.1 Measurement
Measurement is the process of determining the value or label of the variable based on
what has been observed.
Ratio level of measurement has all of the following properties :
a) the numbers in the system are used to classify a person/object into distinct,
nonoverlapping, and exhaustive categories;
b) the system arranges the categories according to magnitude;
c) the system has a fixed unit of measurement representing a standard size
throughout the scale; and
d) the system has an absolute zero.
The data used for statistical analysis should always be accurate, complete, and up-to-
date because the information that we would get is only as good as the data that we have. Good
quality data comes at a cost but if we have the assurance of obtaining essential information
that answers our research problem then it is all worth it.
Naturally, our interpretation of the values in our data will depend on the measurement
system or the rule that we used to assign the values to the different categories of the variable.
In particular, it will depend on the relationship among the values used in the system. The
general classification used to describe the types of relationship among these values or
categories is what is known as levels of measurement.
The four levels of measurement are nominal, ordinal, interval and ratio level. It is
necessary to know the level of measurement used to measure a variable because this will help
in the interpretation of the values of the variables and choosing the suitable statistical
technique to use in the analysis.
JDEUSTAQUIO
7
Interval Level of Measurement satisfies only the first three conditons of the ratio level of
measurement.
Some examples of variables with ratio level of measurement are:
1. Distance traveled by a car (in km)
2. Height of a flag pole (in metres)
3. Weight of a whole dressed chicken (in kilograms)
Now we will discuss each of the properties that is required for a measuring scale to have in
order for it to be considered as having a ratio level of measurement:
a) The numbers in the system are used to classify a person/object into distinct
nonoverlapping, and exhaustive categories.
This first condition requires that we use categories that would place the observations
logically into one and only one category. This means that two objects assigned the same value
must belong in the same category and be placed in a different category if the characteristics of
interest is really different.
b) The system arranges the categories according to magnitude.
This second property requires that the measurement system must arrange the
categories according to either ascending or descending order.
c) The system has a fixed unit of measurement representing a standard size
throughout the scale.
The third property requires the scale to use a unit of measure that depicts a fixed and
determinate quantity. This means that a one-unit difference must have the same
interpretation wherever it appears in the scale.
d) The system has an absolute zero.
The fourth property requires the measurement system to have an absolute zero or the
true zero point. This means that the scale considers the value, 0 (zero) as the complete
absence of the characteristic itself. One example of this is any monetary measurement where
zero means that there is absolutely no money.
The only difference of the interval level of measurement to the ratio level of
measurement is the absence of the absolute zero value. This means that the interval level of
measurement considers 0 (zero) as a value like any other numbers and not as the absence of
JDEUSTAQUIO
8
Ordinal Level of Measurement satisfies only the first two conditons of the ratio level of
measurement.
Nominal Level of Measurement satisfies only the first property of the ratio level of
measurement.
2.2 .1 Data Collection Methods
2.2 Collecting Data
the characteristic of interest. The most common example of this is measuring temperature in
Celsius or Fahrenheit where the value zero does not mean that there is no temperature.
The ordinal level of measurement only uses a scale that ranks or orders the observed
values in either ascending or descending order. The interval or simply the difference of the
scale from one point to another does not need to be equal all throughout the scale. For
example the ranking of the student in class according to their grades could be tagged as 1
st
,
2
nd
, 3
rd
, 4
th
and so on. The difference of the grade between the 1
st
student and the 2
nd
placed
student does not need to be of the same gap between the 4
th
placer and the 5
th
placer.
The nominal level of measurement is the weakest level of measurement among the
four. This is because its only aim is to classify the values into separate categories without
regards to the ordering of these categories in ascending or descending manner. Most often,
this level of measurement uses non-quantifiable categories like the different religions, zip code
or the student number.
The most commonly used methods for collecting data are: i.) Use of Documented Data,
ii.) Surveys, iii.) Experiments, and iv.) Observation.
Use of Documented Data
It is not necessary to use original data in conducting studies; sometimes it would make
things easier if the researcher uses the data that is already available if there is such one suitable
for the study.
The only dilemma with using documented data is its reliability and veracity. Therefore,
the researcher must look closely on the source of this data to have a measure on the reliability
JDEUSTAQUIO
9
Primary Data are data documented by the primary source, meaning, the data collectors
themselves documented the data.
Secondary Data are data documented by a secondary source, meaning, an
individual/agency, other than the data collectors, documented the data.
The Survey is a method of collecting data on the variable/s of interest by asking people
questions. When data came from asking all the people in the population, then it is called
census. On the other hand, when the data came from asking a sample of people selected
from a well-defined population, the it is called a sample survey.
The Experiment is a method of collecting data where there is direct human intervention
on the conditions that may affect the values of the variable of interest.
The Observation Method is a method of collecting data on the phenomenon of interest
by recording the observations made about the phenomenon as it actually happens.
of the data that would be used. Also, these documented data can be categorized in to two, the
primary data and the secondary data.
Surveys
Another common method of collecting data is the survey. The people who answer the
questions in a survey are called the respondents. This method is much more expensive than
collecting data using documented stuff. Another problem of using surveys is that reliability of
the data depends mainly on the survey process itself, either from the respondent, the survey
design, questionnaire or if it is a personal interview there might be a problem with the
interviewer if he/she lacks training.
Experiments
If the researcher is interested in something that involves cause-and-effect relationship,
conducting the experiment is most likely the suitable way of collecting data. The most
common experiment that is normally conducted during the primary level is the mongo seed
experiment. The aim of this experiment is to see the relationship of the growth of the mongo
in relation with sunlight exposure, amount of water and the type of soil.
Observation Method
JDEUSTAQUIO
10
2.2.2.1 Type of Questions
2.2.2 The Questionnaire
The observation method is useful in studying the reactions and behavior of individuals or
groups of persons/objects in a given situation or environment as it happens, For example, a
researcher may use the observation method to study the behavior patterns of an indigenous
tribe which is difficult to be gathered using the other methods.
The questionnaire is an instrument for measuring which is used in various data
collection methods (commonly used in surveys). The questionnaire may either be self-
administered or interview-based which are both explanatory of their names.
A Closed-ended question is a type of question that includes a list of response
categories from which the respondent will select his/her answer.
An Open-ended question is a type of question that does not include response
categories.
Comparison of Open-Ended and Closed-Ended Questions
Open-Ended Closed-Ended
A
d
v
a
n
t
a
g
e
s
+ Respondent can freely answer
+ Can Elicit feeling and emotions of the
respondent
+ Can reveal new ideas and views that the
researcher might not have considered
+ Good for complex issues
+ Good for questions whose possible
responses are unknown
+ Allow respondents to clarify answers
+ Get detailed answers
+ Shows how respondent think
+ Facilitates tabulation of responses
+ Easy to code and analyze
+ Saves time and money
+ High response rate since it is simple
and quick to answer
+ Response categories make questions
easy to understand
+ Can repeat the study and easily make
comparisons
JDEUSTAQUIO
11
2.2.2.2 Response Categories for Close-ended Questions
D
i
s
a
d
v
a
n
t
a
g
e
s
+ Difficult to tabulate and code
+ High refusal late because it requires more
time and effort on the respondent
+ Respondents need to be articulate
+ Responses can be inappropriate or vague
+ May threaten respondent
+ Responses have different levels of detail
+ Increases respondent to burden when
there are too many or too limited
response categories
+ Bias responses against categories
excluded in the choices
+ Difficult to detect if the respondent
misinterpreted the question
1. Two-way Question provides only two alternative answers from which the
respondent can chose
Example: Have you ever traveled outside the country by any means of transportation?
Yes No
2. Multiple-choice Question provides more than two alternatives from which the
respondent can only choose one.
Example: What is your marital status?
Never Married Married
Divorced/Separated Widowed
3. Checklist Question provides more than two alternatives from which the respondent
can choose as many responses that apply to him/her.
Example: What kind/s of novel do you like to read?
Comedy Horror
Romance Non-fiction
Fantasy Mystery
Sci-Fi Others, please specify ____________
JDEUSTAQUIO
12
4. Ranking Question provides categories that respondents have to either arrange from
highest to lowest or vice versa depending upon a particular criterion.
Example: Below is a list of considerations in choosing and buying a new laptop. Put number
(1) beside the quality that you prioritize the most, (2) for the second priority and so on.
Prize [ ]
Brand [ ]
Quality [ ]
Durability [ ]
Style [ ]
Novelty [ ]
Warranty [ ]
5. Rating Scale Question provides a graded scale showing all possible directions and
intensity of attitude of a respondent on a particular question or statement.
Example: How satisfied are you on the teaching method of your instructor in this course?
1 2 3 4 5
Very
Dissatisfied
Dissatisfied Neutral Satisfied Very
Satisfied
6. Matrix Question a type of question which places various questions together to save space
in the questionnaire. It is like having any of the five earlier types of questions and squeezing
more than one question in a form of a table.
Example: For each statement, please indicate with a checkmark whether you agree or
disagree with it
Statements Agree Disagree
Statistics is a very difficult subject
Only few people could understand Statistics
I would rather sleep than study Statistics at home
JDEUSTAQUIO
13
2.2.2.3 Pitfalls to Avoid in Wording Questions
1. Avoid Vague Questions State all question clearly. All respondents must have the same
interpretation to a question. If not, their answers will not be comparable, making it difficult
to analyze their responses.
Example: How often do you watch a movie in a movie theatre?
Very Often
Often
Not too often
Never
Problem: The word often is vague. Instead, you may ask how many times did he/she
watched a movie last month.
2. Avoid Biased Question A biased question influences the respondents to choose a
particular response over the other possible responses. Whether the bias is caused
accidentally or intentionally, the data would become useless because it still failed to reveal
the truth.
Example: There are many different types of sport like badminton, basketball, billiards,
bowling and tennis. Which type of sport d you enjoy watching?
Problem: The sports mentioned in the first sentence will be in the top of the minds of the
respondents. It is likely for the respondents to choose from among these sports. This will
result in a bias against the sports not mentioned in the list.
3. Avoid Confidential and Sensitive Questions These questions usually offend the pride or
jeopardize the prestige of the respondent.
Example: Do you bring home office supplies? If yes, how often do you bring home office
supplies?
Problem: The question may sound offensive to the pride of the respondent.
4. Avoid Questions that are difficult to answer Do not ask questions that are too difficult for
the respondent to answer truthfully. Such questions would only encourage respondents to
guess their answers, if not totally refuse to answer the question.
Example: If you are the president of the nation, what are you going to do to attain economic
recovery?
JDEUSTAQUIO
14
2.3 Sampling and Sampling Techniques
2.3.1 Basic Concepts
The target population is the population we want to study
The sampled population is the population from where we actually select the sample
5. Avoid Questions that are confusing or perplexing to answer Sometimes a poorly written
question can confuse the respondent on how to answer the question
Example: Did you eat out and watch a movie last weekend?
Problem: This is a double-barreled question, where you combine two or more question in to
a single question. You should opt to separate this question into two to avoid confusion.
6. Keep the Questions short and simple Long and complicated question can be difficult to
understand. The respondent may lose interest in the question because of its length or
might have problem comprehending very long statement needed to understand the
question.
As we have discussed on the previous Chapter 1, sample is the subset of a population. Some
people think that if we are basing our analysis on samples, why dont we just guess our analysis entirely
without any data?
This question could be partially answered by a quote from Sir Charles Babbage, the Father of the
Computer who said that, Errors using inadequate data are much less than those using no data at all.
So now, before we can talk about the different sampling selection procedures, we need to
familiarize ourselves first with some terms.
It is good if the target and the sampled population have the same collection of elements. The
problem is that often times in life, expectations do not jive well with reality. One example where the
target and the sampled population would be different from each other is the case where the target
population is the collection of all the residents of Metro Manila. If we would be using a telephone
directory to select our sample, this collection would be very different from the target population since
this would exclude all the residents that have no landline.
JDEUSTAQUIO
15
The sampling frame or frame is a list or map showing all the sampling units in the
population.
Sampling error is the error attributed to the variation present among the computed
values of the statistic from the different possible samples consisting of n elements.
Nonsampling errors is the error from other sources apart from sampling fluctuations
In any statistical inquiry, whether the data will come from a census or from a sample, it is
important that we are conscious of all the possible errors that we introduce (hopefully not intentionally)
in the results of the study. In order for us to do this and reduce these errors, we need to understand the
possible sources of errors, namely, the sampling errors and the nonsampling errors.
Note that the ONLY TIME that the sampling error would not be present is if we have conducted
a census. However, census results are NOT ERROR-FREE. Census and samples can both have
nonsampling errors (simply the errors not brought solely by sampling).
Diagram of the Various Sources of Error
Total Error
Nonsampling
Error
Error in the
implementation of
the sampling design
Selection Error
Frame Error
Population
Specification
Error
Measurement
Error
Instrument
Error
Response Error
Processing
Error
Interviewer
Bias
Surrogate
Information
Error
Sampling Error
JDEUSTAQUIO
16
2.3.2 Methods of Probability Sampling
Probability Sampling is a method of selecting a sample wherein each element in the
population has a known, nonzero chance of being included in the sample; otherwise, it
is a nonprobability sampling method.
2.3.2.1 Simple Random Sampling
Simple Random Sampling (SRS) is a probability sampling method wherein all
possible subsets consisting of n elements selected from the N elements of the
population have the same chances of selection.
In simple random sampling without replacement (SRSWOR), all the n elements in
the sample must be distinct from each other.
In simple random sampling with replacement (SRSWR), the n elements in the
sample need not be distinct, that is, an element can be seleceted more than once as a
part of the sample.
+ A nonzero chance of inclusion means that the sampling procedure must give all the
elements of the sample population an opportunity of being a part of the sample. All of
the elements that belong in the sampled population must be included in the selection
process.
+ Another requirement of probability sampling is that we should be able to determine
the chance that an element will be included in the selected sample. Take note that the
probability of each element in the sampled population need not be equal to each
other.
The most apparent example of SRSWOR that we could see every day on mass
media is the National lottery where the numbers that would be drawn must be distinct and
every number should have an equal chance of being selected in the draw.
JDEUSTAQUIO
17
2.3.2.2 Stratified Sampling
Stratified sampling is a probability sampling method where we divide the population
into nonoverlapping subpopulations or strata, and then select one sample from each
stratum. The sample consists of all the samples in the different strata.
Visual representation of Simple Random Sampling without Replacement.
Stratified sampling, in general, simply requires the division of the population into
nonoverlapping strata, wherein each element of the population needs to belong to exactly one
stratum. Then each sample would be selected form the strata using any probability sampling
method. If simple random sampling used for each sample in the strata then this sampling is
called stratified random sampling.
JDEUSTAQUIO
18
Visually, it might look something like the image below. With our population, we can easily
separate the individuals by color.
Once we have the strata determined, we need to decide how many individuals to select from
each stratum. The most common practice is that the number selected should be proportional.
In our case, 1/4 of the individuals in the population are blue, so 1/4 of the sample should be blue
as well. Working things out, we can see that a stratified (by color) random sample of 4 should
have 1 blue, 1 green and 2 red.
JDEUSTAQUIO
19
2.3.2.3 Systematic Sampling
Systematic sampling is a probability sampling method wherein the selection of the first
element is at random and the selection of the other elements in the sample is systematic by
taking every k
th
element from the random start, where k is the sampling interval
To select a sample using systematic sampling, we need to perform the following steps:
1. Decide on a method of assigning a unique serial number, from 1 to N, to each one of the
elements in the population.
2. Choose n = sample size so that it is a divisor of N = population size. Compute for the sampling
interval k = N/n.
3. Select a number from 1 to k, using a randomization mechanism. Denote the selected number by
r. The element in the population assigned to this number is the first element of the sample.
4. The other elements of the sample are those assigned to the numbers r + k, r + 2k, r +3 k, and so
on, until you get a sample size of n.
5. In case that k = N/n is not a whole number; the first element would still be r but would be a
randomly chosen number from 1 to N instead k as used on the previous step.
By visual explanation, so to use systematic sampling, we need to first order our individuals, then select
every kth.
In our example, we want to use 3 for k? Can you see why? Think what would happen if
we used 2 or 4.
JDEUSTAQUIO
20
2.3.2.4 Cluster Sampling
Cluster sampling is a probability sampling method wherein we divide the population into
nonoverlapping groups or clusters consisting of one or more elements, and then select a
sample of clusters. The sample will consist of all the elements in the selected clusters.
For our starting point, we pick a random number between 1 and k. For our visual, let's
suppose that we pick 2. The individuals sampled would then be 2, 5, 8, and 11.
To select a sample using cluster sampling, we need to perform the following steps:
1. Divide the population into nonoverlapping clusters.
2. Number the clusters in the population from 1 to N.
3. Select n distinct numbers from 1 to N using a randomization mechanism. The selected clusters
are the clusters associated with the selected numbers
4. The sample will consist of all the elements in the selected clusters.
Cluster sampling is often confused with stratified sampling, because they both involve
"groups". In reality, they're very different. In stratified sampling, we split the population up into
groups (strata) based on some characteristic.
In essence, we use cluster sampling when our population is already broken up into groups
(clusters), and each cluster represents the population. That way, we just select a certain
number of clusters.
JDEUSTAQUIO
21
With our visual, let's suppose the 12 individuals are paired up just as they were sitting in the
original population.
Since we want a random sample of size four, we just select two of the clusters. We would
number the clusters 1-6 and use technology to randomly select two random numbers. It might
look something like this:
JDEUSTAQUIO
22
2.3.2.5 Multistage Sampling
Multistage sampling is a probability sampling method where there is a hierarchical
configuration of sampling units and we select a sample of these units in stages.
2.3.3 Methods of Nonprobability Sampling
Unlike all the other previously presented sample selection procedures where the
process of sampling takes place in a single phase, we accomplish the selection of the elements
in the sample under multistage sampling after several stages of sampling. We first partition the
population into non-overlapping primary stage units (PSUs) and select a sample of PSUs. We
then subdivide the selected PSUs into non-overlapping second-stage units (SSUs) and select a
sample of SSUs. We continue the process until we identify the elements in the sample at the
last stage of sampling.
For example, consider a light-bulb example using two-stage sampling procedure. Let's
suppose that the bulbs come off the assembly line in boxes that each contains 20 packages of
four bulbs each. One strategy would be to do the sample in two stages:
Stage 1: A quality control engineer removes every 200th box coming off the line. (The plant
produces 5,000 boxes daily. (This is systematic sampling.)
Stage 2: From each box, the engineer then samples three packages to inspect. (This is an
example of cluster sampling.)
All sampling methods that do not satisfy the requirements of probability sampling are
considered as nonprobability sampling selection procedures. These methods do not make use
of randomization mechanism in identifying the sampling units included in the sample. It allows
the researcher to choose the units in the sample subjectively. And since the sample selection is
subjective, there is really no way to assess the reliability of the results without so much
assumptions (remember assumptions are very prone to mistakes).
JDEUSTAQUIO
23
2.3.3.1 Haphazard or Convenience Sampling
2.3.3.2 Judgement or Purposive Sampling
2.3.3.3 Quota Sampling
Despite this drawback of nonprobability sampling, these methods are still more
commonly used since it is less costly and easier to administer.
Here are some of the most basic nonprobability sampling selection procedures:
In haphazard or convenience sampling, the sample consists of elements that are most
accessible or easier to contact. This usually includes friends, acquaintances, volunteers, and
subject who are available and willing to participate at the time of the study.
The most common example that we could see on the television is the text polls about a
certain issue. This type of sampling the opinion of the people doesnt involve randomization
mechanism in the selection of the units in the sample. This is sometimes referred to as the
nonprobability counterpart of simple random sampling.
The elements are carefully selected to provide a representative sample. Studies have
demonstrated that selection bias can arise even with expert choice but nevertheless the
method may be appropriate for very small samples when the expert has a good deal of
information about the population-elements. The two common features of the method are: a.)
sampling units often consist of relatively large groups; and, b.) sampling units are chosen so
that they will provide accurate estimates for important control variables for which results are
known for the whole population and its hoped that it will give good estimates for other
variables that are highly correlated with the control variables. This sampling method may be
considered as the nonprobability counterpart of Cluster sampling.
This is considered as the nonprobability counterpart of stratified sampling. In this
method, interviewers are assigned quotas of respondents of different types to interview. The
quotas are sometimes chosen to be in proportion to the estimated population figures for
various types, often based on past census data. The researcher also chooses the groups or
strata in the study but the selection of the sampling units within the stratum does not make
use of a probability sampling method.
JDEUSTAQUIO
24
2.4 Presentation of Data
2.4.1 Textual Presentation
Textual Presentation of data incorporates important figures in a paragraph of text.
After data collection, we organize and analyze the data, and then we present the results
of our analysis in some form that will allow us to reveal and highlight the important
information that we were able to extract. Unless we do this, we will only get lost in huge
mound of numbers and labels that we have collected.
Our grade school teachers already taught us this various kinds of presenting the data so
why do we need to study this again?
We may be familiar with the line chart and the bar chart but we need to learn or review
the basic principles of constructing a good table and a good graph. With good data
presentation, we can discover, and even explore possible relationships. Poor data presentation
will only mislead, deceive, and misinform. It is therefore essential that we remember to put a
more conscious effort to use these different methods of presentation properly in order to
maximize data description and analysis.
In textual presentation, it aims to direct the readers attention to some data that need
particular emphasis as well as to some important comparisons and to supplement with a
narrative account from a table or a chart.
It could also show the summary measures like minimum, maximum, totals and
percentages. We do not need to put all figures in a textual presentation; we just have to select
the most important ones that we want to focus on.
Example: The Philippine Stock Exchange composite index lost 7.19 points to 2,099.12 after trading
between 2,095.30 and 2,108.47. Volume was 1.29 billion shares worth 903.15 million pesos
(16.7milliondollars). The broader all share index gained 5.21 points to 1,221.34. (From: Free mandated
March 17, 2005)
When the data become voluminous, the textual presentation is strongly not advised
because the presentation becomes almost incomprehensible.
JDEUSTAQUIO
25
2.4.2 Tabular Presentation
Tabular Presentation of data arranges figures in a systematic manner in rows and columns.
Tabular presentation is the most common method of data presentation. It can be used
for various purposes such as description, comparison, and even showing relationships between
two or more variables of interest.
We will discuss three types of presenting in tabular form, namely; Leader Work, Text
Tabulation and Formal Statistical table which is categorized according to their format and
layout.
Leader Work
Leader work has the simplest layout among the three types of tables. It contains no
table title or column headings and has no table borders. This table needs an introductory or
descriptive statement so that the reader can understand the given figures.
The Population in the Philippines for the Census Years 1975 to 2000 is as follows
a
1975 42,070,660
1980 48,098,460
1990 60,703,206
b
1995 68,616,536
b
2000 76,498,735
a
National Statistics Office
b
The 1990 and 1995 figures include the household population, homeless population, and Filipinos in Philippines embassies
and mission abroad. In addition, the census comprise institutional population found living quarters such as penal
institutions, orphanages, hospitals, military camps, etc.
As you can see, the above table would not be clear without the introductory statement.
Likewise, both have no table numbers that we can use to refer to these figures. Thus, we use
the leader work when there are only one or two columns of figures that we can incorporate as
part of the textual presentation for a more organized presentation.
Text Tabu lat io n
The format of text tabulation is a little bit more complex than leader work. It already
has column headings and table borders so that it is easier to understand than leader work.
However it still does not have table title and table number. Thus, it also requires an
introductory statement so that the readers can comprehend the given figures. Similar to leader
work, we can place additional explanatory statement in the footnote.
JDEUSTAQUIO
26
The Population in the Philippines for the Census Years 1975 to 2000 is as follow
a
Year
No. of Filipinos
(in thousands)
1975 42,070.66
1980 48,098.46
1990 60,703.21
b
1995 68,616.54
b
2000 76,498.74
a
National Statistics Office
b
The 1990 and 1995 figures include the household population, homeless population, and Filipinos in Philippines embassies and
mission abroad. In addition, the census comprise institutional population found living quarters such as penal institutions,
orphanages, hospitals, military camps, etc.
Form al Statistical Table
The formal statistical table is the most complete type of table since it has all the
different and essential parts of a table like table number, table title, head note, box head, stub
head, column headings, and so on. It could be a stand-alone table since it does not need any
accompanying texts and it could be easily understood on its own.
Heading consists of the table number, title and head note. It is located on top of the table of
figures.
i. Table number is the number that identifies the position of the table in a sequence.
ii. Table title states in telegraphic form of the subject, data classification, and place and period
covered by the figures in the table.
iii. Head note appears below the title but above the top cross rule of the table and provides
additional information about the table.
Box head consists of spanner heads and columns heads.
i. Spanner head is a caption or label describing two or more column heads.
ii. Column head is a label that describes the figures in a column.
iii. Panel is a set of column heads under the same spanner head.
Stub consists of row captions, center head, and stub head. It is located at the left side of the
table.
i. Row caption is a label that describes the figures in a row.
ii. Center head is a label describing a set of row captions.
iii. Stub head is a caption or label that describes all of the center heads and row captions. It is
located on the first row.
iv. Block is a set of row captions under the same center head.
JDEUSTAQUIO
27
Table 10.9 Employed Persons by Major Industry Group
January 2008 - October 2010
(in thousands)
Industry Group 2010 2009 2008
Oct Jul Apr Jan Oct Jul Apr Jan Oct Jul Apr Jan
Total
36,488 36,237 35,413 36,001 35,478 35,508 34,997 34,262 34,533 34,593 33,535 33,693
Agriculture 12,265 12,244 11,512 11,806 12,072 11,940 12,313 11,846 12,320 12,103 11,904 11,792
Agriculture, Hunting and
Forestry
10,769 10,760 10,073 10,351 10,563 10,476 10,841 10,446 10,860 10,695 10,450 10,409
Fishing
1,496 1,484 1,439 1,455 1,509 1,464 1,472 1,400 1,460 1,408 1,454 1,383
Industry
5,375 5,409 5,487 5,322 5,154 5,273 5,088 4,856 5,078 5,130 5,000 4,981
Mining nd Quarrying
197 194 212 193 169 177 166 152 176 154 151 152
Manufacturing
3,058 3,003 3,063 3,009 2,937 2,947 2,841 2,849 2,897 2,960 2,883 2,963
Electricity, Gas and Water
163 141 137 157 160 145 130 134 123 146 123 126
Construction
1,957 2,071 2,075 1,963 1,888 2,004 1,951 1,721 1,882 1,870 1,843 1,740
Services
18,550 18,585 18,414 18,872 18,250 18,294 17,595 17,560 17,135 17,360 16,630 16,919
Wholesale & Retail Trade,
Repair of Motor Vehicles,
Motorcycles & Personal &
Household Goods
7,158 7,030 6,885 7,064 6,901 6,725 6,681 6,635 6,528 6,599 6,322 6,333
Hotels and Restaurants
1,119 1,037 991 1,104 1,012 1,064 976 988 941 984 924 964
Transport, Storage and
Communication
2,711 2,704 2,741 2,735 2,735 2,694 2,628 2,660 2,587 2,525 2,575 2,674
Financial Intermediation
412 420 383 384 375 376 389 337 373 369 366 364
Real Estate, Renting and
Business Activities
1,239 1,166 1,061 1,119 1,100 1,090 1,023 1,044 985 969 953 904
Public Administration &
Defense, Compulsory Social
Security
1,771 1,835 1,959 1,823 1,771 1,772 1,794 1,659 1,690 1,741 1,661 1,612
Education
1,165 1,238 1,156 1,146 1,168 1,157 1,068 1,157 1,096 1,076 1,028 1,083
Health and Social Work
465 457 447 432 412 428 408 435 406 386 384 390
Other Community, Social &
Personal Service Activities
855 866 984 949 868 876 907 857 796 847 843 846
Private Households with
Employed Persons
1,954 1,831 1,804 2,114 1,908 2,110 1,718 1,785 1,733 1,863 1,572 1,747
Extra-Territorial
Organizations & Bodies
1 1 3 2 0 2 3 3 * 1 2 2
Notes:
1. Data were taken from the results of the quarterly rounds of the Labor Force Survey (LFS) using past week as reference peri od.
2. Details may not add up to totals due to rounding.
3. The definition of unemployment was revised starting the April 2005 round of the LFS. As such, LFPRs, employment rates and unemployment
rates are not comparable with those of previous survey rounds. Also starting with January 2007, estimates were based on 2000 Census-based
projections.
4. Data are as of January 2012.
p/ - preliminary
Source: National Statistics Office (NSO).
Heading
Table number
Title
Head note
Stub head
Spanner head
Column head
Panel
B
L
O
C
K
C
e
n
t
e
r
h
e
a
d
footnote
source note
JDEUSTAQUIO
28
2.4.3 Graphical Presentation
Tabular Presentation of data portrays numerical figures or relationships among variables
in pictorial form.
The graph or statistical chart is a very powerful tool in presenting data. It is an
important medium of communication because we can create a pictorial representation of the
numerical figures found in tables without showing too many figures.
We construct graphs not only for presentation purposes but also as an initial step in
analysis. The graph, as a tool for analysis, can exhibit possible associations among the variables
and can facilitate the comparison of different groups. It can also reveal trends over time.
The different types of statistical charts are line chart, vertical bar chart, horizontal bar
chart, pictograph, pie chart, and statistical map. It is important to know when and how to use
these different charts. The selection of the correct type of chart depends upon the specific
objective, the characteristic of the users, the kind of data, and the type of device and material
on hand.
Line Chart
The line chart is useful for presenting historical data. This chart is effective in showing
the movement of a series over time. As shown in the figures below, the movement can be
increasing, decreasing, stationary, or could be fluctuating.
0
5
10
15
20
1 2 3 4 5 6 7 8 9 10
N
o
.
o
f
A
c
c
i
d
e
n
t
s
Years of Service
No. of Accidents involving Company B during their Years of
Service
Title at Top
Scale figures for
y-axis
Scale label for
y-axis
Footnote
Source Note
Grid lines
Scale figures for
x-axis
Scale label for
x-axis
JDEUSTAQUIO
29
NEVER use line charts/graphs that are too stretched either horizontally or vertically, for
it may mislead the person looking at the graph and interpret it as something that it is not really
representing.
JDEUSTAQUIO
30
Types of Line Chart
Simple Line Chart This has only one curve and is appropriate for one series of time data.
Multiple Line Chart This type of line chart shows two or more curves. We use this if we wish
to compare the trends in two or more data series.
Although the use of Multiple Line Chart is now commonly used, it should be taken
notice the number of series that you include in a graph, if there are a lot of series in a single
chart, it might become too confusing to see.
Number of Daily Responses (Example of Single Line Chart)
JDEUSTAQUIO
31
Co lu m n Chart
We use the column charts to compare amounts in a time series data. The emphasis in
a column chart is on the differences in magnitude rather than the movement of a series.
+ We can also use the column chart to graph the frequency distribution of a
quantitative variable. We call this chart a frequency histogram.
+ For time series data, we arrange the columns on the horizontal axis in
chronological order, starting with the earliest date.
The proportions of the columns must be just right. Columns must not be too wide or too
narrow. The space between the bars must also be just right. Usually, the space between bars is
around one-fourth of the width of the column.
It is also advisable to use scale figures that are multiples of 5. If the observed values are so
small, we can use multiples of 1 or 2.
Title at Top
Scale figures for
y-axis
Scale label for
y-axis
Grid lines
Scale figures for
x-axis
JDEUSTAQUIO
32
Horizontal Bar Chart
Its use is appropriate when we wish to show the distribution of categorical data.
We use the horizontal bar chart so we can compare the magnitudes for the different
categories of a qualitative variable. We place the categories of the qualitative variable on the y-
axis. This will be more practical than placing the categories on the x-axis because there is more
space for text labels on the y-axis.
Just like the column charts, the bars should not be too wide, too narrow, too long and nor
too short.
+ Arranging the bars according to length usually facilitates comparisons. It may be
decreasing or ascending order.
+ If there are Others category, we always place this as the first or the last
category.
+ If the categorical variables have a natural ordering, such as a rating scale, then we
should retain the order of the categories in the scale instead of arranging the bars
according to length.
+ We should always choose appropriate colors or patterns for the bars. We should
avoid selecting wavy and weird patterns since this will only produce an optical
illusion.
JDEUSTAQUIO
33
Pie Chart
It is a circle divided into several sections. Each section indicates the proportion of each
component or category. This is useful for data sorted in to categories for a specific period.
The purpose is to show the component parts with respect to the total in terms of the
percentage distribution.
The components of the pie chart should be arranged according to magnitude.
If theres an Others category, we put it in the last section. We use different colors,
shading, or patterns to distinguish one section of the pie to the other sections.
We plot the biggest slice at 12 oclock.
If we want to emphasize a particular sector of the pie chart, we may explode that slice
by detaching it from the rest of the sectors.
The pie chart is applicable for qualitative rather than quantitative data. However, if
the variable has too many categories (more than 6), we should use the horizontal bar
chart rather than the pie chart.
JDEUSTAQUIO
34
Pictograph
o It is like a horizontal bar chart but instead of using bars, we use symbols or pictures to
represent the magnitude.
o The purpose of this chart is to get the attention of the reader.
o The pictograph provides an overall picture of the data without presenting the exact
figures.
o Usually, we can only show approximate figures in a pictograph since we have to round off
figures to whole numbers. It still allows the comparison of different categories even if we
just present only the approximate values.
o The choice for the symbol or picture should be apt for the type of data. It should be self-
explanatory, interesting, and simple.
Statistical Maps
+ This type of chart shows statistical data in geographical areas.
+ This could also be called as crosshatched maps or shaded maps.
+ Geographic areas may be barangays, cities, districts, provinces, and countries.
+ The figures in the map can be ratios, rates, percentages, and indices.
+ We do not use the absolute values and frequencies in statistical maps.
JDEUSTAQUIO
35
Types of Statistical Maps
Shaded Map map that makes use of shading patterns. The shading pattern
indicates the degree of magnitude. It usually runs gradually from dark to light
(Darker shading of the map usually means larger magnitude).
Dot map chart that gives either the location or the number of establishments in
a certain geographical area. The example below is a dot map of the number of
people with Hispanic decent in the US.
JDEUSTAQUIO
36
2.5.1 Raw Data and Array
Raw Data are data in their original form.
Array is an ordered arrangement of data according to magnitude. We also refer to the
array as sorted data or ordered data
The first step in data analysis is organizing the collected data. In its organized form,
important features of the data become clear and apparent.
The two common forms of organized data are the array and the frequency distribution
The actual data that we collect from surveys, observation, and experimentation are
what we call raw data. Raw data have not yet been organized or processed in any manner.
Example: Raw Data of the Final Grades of 100 Selected Students who took Stat 101
79 73 74 88 66 88 72 60 77 53
62 85 60 63 56 77 74 93 92 72
74 78 92 87 57 60 79 66 93 57
79 82 86 69 92 97 51 99 92 62
81 83 86 77 82 70 86 89 50 80
65 79 60 53 66 92 55 94 65 79
79 73 90 76 70 67 67 97 79 76
94 81 64 52 72 92 66 78 62 82
75 88 57 72 73 50 79 55 56 74
52 81 63 89 63 65 95 79 77 76
Arranging the observations manually according to magnitude is very tedious especially
if we are dealing with voluminous data. Thus, it is more convenient to use computer programs
to sort the data.
The array is not a summarized data set. It is simply an ordered set of observations. We
consider both the raw data and array as ungrouped data.
2.5 Organization of Data
JDEUSTAQUIO
37
2.5.2 Frequency Distribution (FDT)
The frequency distribution (FDT) is a way of summarizing data by showing the number of
observations that belong in the different categories or classes. We also refer to this as
grouped data.
Example: Array of the Final Grades of 100 Selected Students who took Stat 101
50 56 62 66 72 76 79 81 88 92
50 57 63 66 73 76 79 82 88 92
51 57 63 67 73 77 79 82 88 93
52 57 63 67 73 77 79 82 89 93
52 60 64 69 74 77 79 83 89 94
53 60 65 70 74 77 79 85 90 94
53 60 65 70 74 78 79 86 92 95
55 60 65 72 74 78 80 86 92 97
55 62 66 72 75 79 81 86 92 97
56 62 66 72 76 79 81 87 92 99
The frequency distribution is another way of organizing the data. It is a summarized
form of the raw data or array wherein we do not see the actual observed values anymore.
The two general forms of frequency distribution are single-value grouping and grouping
by class intervals:
1. Single-value grouping is a frequency distribution where the classes are the distinct
values of the variable. This is applicable for data with only a few unique values.
2. Grouping by Class Intervals is a frequency distribution where the classes are the
intervals.
Example: Suppose we have data on the number of children of 50 married women using any modern
contraceptive method.
0 0 1 2 2 2 3 3 4 4
0 0 1 2 2 3 3 3 4 4
0 1 1 2 2 3 3 3 4 4
0 1 1 2 2 3 3 3 4 5
0 1 1 2 2 3 3 3 4 5
JDEUSTAQUIO
38
Since there are only 6 unique values in the data set, then we use single-value grouping,
Distribution of Married Women Using Any Modern Method
of Contraceptive by Number of Children
No. of Children
Number of
Married Women
0 7
1 8
2 11
3 14
4 8
5 2
Concepts related to Frequency Distribution
1. Class Interval is the range of values that belong in the class or category.
2. Class Frequency is the number of observations that belong in a class interval.
3. Class Limits are the end numbers used to define the class interval. The lower
class limit (LCL) is the lower end number while the upper class limit (UCL) is the
upper end number.
4. Open Class Interval is a class interval with no lower class limit or no upper class
limit.
5. Class Boundaries are the true class limits. If the observations are rounded figures,
then we identify the class boundaries based on the standard rules of rounding as
follows: the lower class boundary (LCB) is halfway between the lower class limit of
the class and the upper class limit of the preceding class while the upper class
boundary (UCB) is halfway between the upper class limit of the class and the lower
class limit of the next class.
6. Class size is the size of the class interval. It is the difference between the upper
class boundaries of the class and the preceding class; or the difference between the
lower class boundaries of the next class and the class.
7. Class Mark - is the midpoint of a class interval. It is the average of the lower class
limit and the upper class limit or the average of the lower class boundary and upper
class boundary of a class interval.
JDEUSTAQUIO
39
After learning the concepts that we need to construct a frequency distribution table, we
can now list down the steps in constructing a frequency distribution table.
After constructing the basic frequency distribution table, we could now add some other
components to it that would help us in the analysis of the data.
o Relative Frequency is the class frequency divided by the total number of
observations
o Relative Frequency Distribution Percentage (RFP) is relative frequency multiplied
by 100.
Step 1:
Determine the adequate number of classes denoted by K
We can use the Sturges's rule to approximate the number of classes which is
given by K = 1+ 3.322(log n)
Step 2:
Determine the range, R = highest observed value - smallest observed
value
Step 3:
Compute for the pre-class size C' = R/K
Step 4:
Determine the class size, C, by rounding-off C' to a convenient
number
Step 5:
Choose the lower class limit of the first class. Make sure that the smallest
observation will belong in the first class.
Step 6:
List the class intervals. Determine the lower class limits of the suceeding classes y
adding the class size to the lower class limit of the previous class. The last lass
should include the largest observation.
Step 7:
Tally all the observed values in each class interval
Step 8:
Sum the frequency column and check against the total number of
observations
JDEUSTAQUIO
40
The relative frequency and RFP show the proportion and percentage of observations
falling in each class. The RFP allows us to compare two or more data sets with different total s.
The sum of the RFP column is one hundred percent (100%).
Another component that could be added to the FDT is the cumulative frequency
distribution which is comprised of two components.
o The less than cumulative frequency distribution (<CFD) shows the number of
observations with values smaller than or equal to the upper class boundary.
o The greater than cumulative frequency distribution (>CFD) shows the number of
observations with values higher than or equal to the lower class boundary.
Example: Using the data of the Grades of 10o Students who took Stat 101, we would
construct the frequency distribution table with the extra components; RF, RFP
<CFD and >CFD.
First, we will compute for K using the Sturges rule,
K = 1 + (3.322*log n) = 1 + (3.322*log 100)
= 1 + (3.322 *2) = 7.644 ~ 8
Secondly, we compute for the range, R
R = max. value min. value = 99 50 = 49
Third, compute for C and eventually C
C = R / K = 49 / 8 = 6.125 ~ 7
Now we can create the FDT for the data set,
Class Limits Class Boundaries Frequency Class Mark RF RFP CFD
LCL UCL LCB UCB f x f/n % < CFD > CFD
50 - 56 49.5 - 56.5 11 53 0.11 11 11 100
57 - 63 56.5 - 63.5 13 60 0.13 13 24 89
64 - 70 63.5 - 70.5 13 67 0.13 13 37 76
71 - 77 70.5 - 77.5 19 74 0.19 19 56 63
78 - 84 77.5 - 84.5 19 81 0.19 19 75 44
85 - 91 84.5 - 91.5 11 88 0.11 11 86 25
92 - 98 91.5 - 98.5 13 95 0.13 13 99 14
99 - 105 98.5 - 105.5
1 102 0.01 1 100 1
n=100
JDEUSTAQUIO
41
Graphical Presentation of the Frequency Distribution
We can effectively interpret the frequency distribution when displayed pictorially since
more people understand and comprehend the data in graphic form. In this section we would
discuss the various method of presenting the frequency distribution in graphical form.
1. Frequency Histogram
The frequency histogram shows the overall picture of the distribution of the observed
values in the dataset. It displays the class boundaries on the horizontal axis and the class
frequencies on the vertical axis.
The frequency histogram shows the shape of the distribution. The area under the
frequency histogram corresponds to the total number of observations. The tallest vertical bar
shows the frequency of the class interval with the largest class frequency.
2. Relative Frequency/ Relative Frequency Percentage Histogram
The RF or RFP histogram displays the class boundaries on the horizontal axis
and the relative frequencies or RFPs of the class intervals on the vertical axis. It
represents the relative frequency of each class by a vertical bar whose height is equal
to the relative frequency of the class. The shape of the relative frequency histogram
and frequency histogram are the same.
JDEUSTAQUIO
42
3. Frequency Polygon
For the frequency polygon, plot the class frequencies at the midpoint of the
classes and connect the plotted points by means of straight lines. Since it is a polygon
we need to close the ends of the graph. To close the polygon, add an additional class
mark on both ends of the graph wherein both ends have the frequency of 0.
The advantage of the frequency polygon over the frequency histogram is that
it allows the construction of two or more frequency distributions on the same plot
area. This facilitates the comparison of the different frequency distributions. The
frequency polygon also exhibits the shape of the data distribution.
JDEUSTAQUIO
43
4. Ogives
The ogive is the plot of the cumulative frequency distribution. This graphical
representation is used when we need to determine the number of observations below
or above a particular class boundary.
The less than ogive is the plot of the less than cumulative frequencies against the
upper class boundaries. On the other hand, the greater than ogive is the plot of the
greater than cumulative frequencies against the lower class boundaries. Connect the
successive points by straight lines.
If we superimpose the less than and greater than ogives, the point of intersection
gives us the value of the median. The median divides the ordered observations into
two equal parts.
JDEUSTAQUIO
44
The average is the popular term that is used to refer to a measure of central tendency.
Most are already accustomed to thinking in terms of an average as a way of representing the
collection of observations by a single value.
For instance, we often use the average score to represent the scores in the exam of all
students in a class. We can say that if the average score is high, then we conclude that the class
performed well. The average could also be used to compare the performance of two groups
based on the average of both groups and comparing which one has the higher average.
The most common measure of central tendency is the arithmetic mean. The two other
measures of central tendency that we will present in this section are the median and the mode.
All of these measures aim to give information about the center of the data or distribution.
The summation notation provides a compact way of writing the formulas for some of
the summary measures that would be discussed in this section. The capital Greek letter
sigma,E is the mathematical symbol that represents the process of summation.
The symbol,
is equal to X
1
+ X
2
+ X
3
+ + X
n
where X
i
= value of the variable for the i
th
observation
i = index of the summation (the letter below E).
1 = lower limit of the summation (the number below E).
n = upper limit of the summation (the letter above E).
We read
as summation of X sub i, where I is from 1 to n.
Summary Measures Part 1
3.1 Measures of Central Tendency
3.1 .1 Summation Notation
JDEUSTAQUIO
45
Some Notes on Summation:
1) The index (as indicated by the letter below E) may be any letter, but the letters i, j, k are
the most common. For example,
even if their indexes are different
because the terms of the sum and the index sets of the two summations are the same.
2) The lower limit of the summation may start with any number. For example we can have
. This is equal to X
3
+ X
4
+ X
5
+ X
6
since the index set of {3, 4, 5, 6}.
3) The index of the summation will not necessarily appear as a subscript in the terms of
the summation. For example, we can have
. This is equal to 1 + 2 + 3 + 4 + 5
since the notation indicates that the terms of the sum are the values of the index
themselves.
The arithmetic mean, or simply called the mean, is the most common type of average.
It is the sum of all observed values divided by the number of observations. When people use
the term average, usually they refer to the arithmetic mean.
By definition, the computation of the population mean and sample mean involve the
same process. To compute for their values, we get the sum of all the measures in the collection
and divide this sum by the number of elements in the collection. The main difference is that
the collections of measures used to compute the population mean is taken from all of the
elements in the population while the sample means collection is only taken from the selected
sample. Thus, the population mean is a parameter while the sample mean is a statistic.
3.1 .2 The Arithmetic Mean
The arithmetic mean is the sum of all the values in the collection divided by the total
number of elements in the collection.
The population mean for a finite population with N elements, denoted by the
lowercase Greek Letter mu, , is;
The sample mean for a sample with n elements, denoted by X
(read as "X-bar") is;
JDEUSTAQUIO
46
Example:
1. Consider the sample on the final grades on Stat 101 of the 100 selected students.
2. Five judges give their scores on the performance of a gymnast as follows: 8, 9, 9, 9, and
10. Find the mean score of the gymnast.
Approximating the Mean from Grouped Data:
Sometimes, the only data that we have is already the frequency distribution and the
raw data is not accessible. In this case, we cannot compute for the value of the mean for this
kind of data. However, we could still estimate the mean of the frequency distribution.
The formula for estimating the mean of the population and the sample are indicated
below:
Population Mean:
Sample Mean:
where f
i
= the frequency of the i
th
class
X
i
= the class mark of the i
th
class
k = total number of classes
N or n = total number of observations,
Example: Consider the frequency distribution of the Final Grades in Stat 101 of the 100
selected students.
Class Limits Frequency Class Mark RF
LCL UCL f x f
i
X
i
50 - 56 11 53 583
57 - 63 13 60 780
64 - 70 13 67 871
71 - 77 19 74 1406
78 - 84 19 81 1539
85 - 91 11 88 968
92 - 98 13 95 1235
99 - 105
1 102 102
n=100 Ef
i
x
i
=7484
JDEUSTAQUIO
47
Thus, the mean final grade of the 100 selected Stat 101 Students is approximately 74.84.
Remark: Note that we have computed the mean of the 100 selected Stat 101 Students using
the raw data and the frequency distribution. We could see that they are not equal but relatively
near to each other.
Some Modifications for the Mean:
a. Weighted Mean
Sometimes, we know that the individual observed values vary in their degree of
importance. In this case, it is recommended to use the weighted mean. The weighted
mean assigns weights to the observations depending on their relative importance.
The formula for the weighted mean is given below:
Example: Ron wants to determine his GWA for this semester given his grades on CRS.
Class Units Grade
EEE 10 3.0 2.00
Humanidades 1 THW1 3.0 1.25
Math 54 TWTHFU3 5.0 1.75
PE 2 UF WFC (2.0) 1.00
Physics 11 THV 3.0 2.50
Chem 14 WFW 3.0 1.25
() () () () () ()
JDEUSTAQUIO
48
b. Combined Mean
If we want to get the mean of the combination of several data sets but only
given the means and number of observations of each data set, we could use the
formula for the combined mean:
Example: Three sections of a statistics class containing 28, 32, and 35 students
averaged 83, 80, and 76 respectively, on the same final examination. What is the
combined population mean for all three sections?
Solution: We let N
1
= 28, N
2
= 32, and N
3
= 35,
1
=83,
2
=80, and
3
=76
() () ()
Thus, the mean grade of the students in the 3 sections is 79.4.
c. Trimmed Mean
Sometimes, we want to remove the outliers or the extreme values in the
data before getting the mean to get more reliable information. To do this, we
could use the trimmed mean. Below are the steps in computing the trimmed
mean:
1. Create an array from the raw data.
2. Decide on the percentage of the data set that we will remove in the
upper and lower end of the ordered observations.
The objective of the trimmed mean is to remove the influence of possible
outliers that appear in both the lower and upper portion of the ordered data.
Example: Compute for the 5% trimmed mean for the given data.
10 11 11 17 10 14 11 20
12 14 13 20 12 16 13 12
15 16 15 12 15 19 15 14
18 18 18 14 18 12 18 18
20 12 500 17 20 14 524 20
The arithmetic mean of the data is 39.95
JDEUSTAQUIO
49
Round-off Rule
In performing clculations, we only round-off the final answer and not the
transitional values. The final answer should increase by one digit of the original
observations. For example, the mean of the data set 3, 4, and 6 is 4.3333... . Round this
figure to the nearest tenth since the original observed values are whole numbers. Thus,
the mean becomes 4.3. On the other hand, if the original observed values have one
decimal place like 4.5, 6.3, 7.7, 8.9, then we round the final answer to two decimal places.
Thus, if we get the mean, the final answer is 6.85
First we create an array;
10 12 12 14 15 17 18 20
10 12 13 14 15 18 18 20
11 12 13 14 16 18 19 20
11 12 14 15 16 18 20 500
11 12 14 15 17 18 20 524
Then we compute the 5% of the total number of data points, 5% of 40 is 2,
therefore we remove the first 2 and the last two data points in the data that we
have. And we would have the 36 data points listed below.
11 12 12 14 15 16 18 18 20
11 12 13 14 15 16 18 18 20
11 12 13 14 15 17 18 19 20
12 12 14 14 15 17 18 20 20
Then we compute for the trimmed mean which is just simply the arithmetic
mean of the trimmed dataset which would result to 15.39 which is very far from
the arithmetic mean of the original data which is 39.95. We can see that 15.39 is a
better summary measure than 39.95 since it represents more of the data points.
JDEUSTAQUIO
50
The median is the value that divides the array into two equal parts.
Another summary measure for getting the central tendency is the median. The median
divides an ordered set of observations into two equal parts. In other words, it is the measure
occupying the positional center of the array.
If an observation is smaller than the median, then it belongs to the lower half of the
array while if the observation is greater than the median then it belongs in the upper half of the
array.
The first step in finding the median, denoted by
or Md, is to arrange the observations
in an array. We let X
(1)
is the smallest observation while X
(n)
is the largest observation. The
process of determining the median is different for the datasets with even and odd number of
observations.
Case I: Number of Observations is Odd ; The formula is:
/
, This formula means that the median is the .
observation in the array
Case II: Number of Observations is Even ; The formula is:
/
.
, this means that the median is the average of the two middle values.
Example:
a. The following are the number of years of operation of 8 oil distributing companies: 9, 11, 16, 12,
17, 20, and 18. Find the median
Array: 9, 11, 12, 16 , 17, 18, 20 ; Therefore the median year of operation is 16.
b. Using the data on the Final Grades of 100 Selected Stat 101 Students. Find the median.
We get the average of the 50
th
and 51
st
observations
= 76 ;
Therefore the median grade is 76%
3.1 .3 The Median
JDEUSTAQUIO
51
Approximating the Median from Grouped Data:
We can approximate the median from a frequency distribution. We obtain a good
approximate for the median if the observed values belonging in the median class are evenly
spaced throughout the class interval. The median class is the class interval containing the
median. To get the median, we perform the following steps:
Step 1: Calculate n/2, where n=
is the number of observations.
Step 2: Construct the less than cumulative frequency distribution (<CFD)
Step 3: Locate the value in the <CFD column that is greater than or equal to n/2. The
class interval corresponding to that value is the median class.
Step 4: Approximate the median using the formula given below:
)
where LCB
Md
is the lower class boundary of the median class
C is the class size
n is the total number of observations
<CF
Md-1
is the less than cumulative frequency preceding the median
class
f
Md
is the frequency of the median class
Example: Using the FDT of the Final Grades of 100 Selected Stat 101 Students. Find the median.
Class Boundaries Frequency
< CFD
LCB UCB f
49.5 - 56.5 11 11
56.5 - 63.5 13
24
63.5 - 70.5 13
37
70.5
- 77.5 19 - f
Md 56
77.5 - 84.5 19 75
84.5 - 91.5 11 86
91.5 - 98.5 13 99
98.5 - 105.5 1 100
) = 75.29 ;
Thus the median final grade of the 100 Stat 101 Students is 75.29
median class
<CF
Md-1
JDEUSTAQUIO
52
The mode is the observed value that occurs with greatest frequency in a data set.
The mode is the most frequent observed value in the dataset. If the data is small, we
could easily identify the mode if there is/are any just through inspection. However, for large
amount of data, identifying the computer manually is a difficult task. In general, the mode is
less popular than the mean and median in terms of being a measure of central tendency.
Examples:
1. We consider the height in inches of 10 basketball players: 70, 70, 71, 71, 72, 72, 72, 72,
75, and 75. Find the mode;
Answer: 72 is the modal height
2. We consider the shoe sizes of 24 female faculty members: 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 7, 8, 9, 9,
10, 10, 10, 10, 10, 10, 10, 10, and 11. Find the mode;
Answer: The modal shoe sizes are 6 and 10 (if there are two modes we can call this
phenomenon as bimodal distribution)
3. We consider the scores of 15 students in a quiz: 16, 16, 16, 17, 17, 17, 18, 18, 18, 19, 19, 19, 20,
20, and 20. Find the mode;
Answer: There is no mode (sometimes, the mode really does not exist)
Approximating the Mode from Grouped Data:
We can approximate the mode from a frequency distribution. To get the mode, we
just need perform the following steps:
Step 1: Locate the modal class. For frequency distributions with equal class sizes, the
modal class is the class interval with the highest frequency.
Step 2: Approximate the mode using the formula given below:
*
where LCB
Mo
is the lower class boundary of the modal class
C is the class size
f
1
is the frequency of the class preceding the modal class
f
2
is the frequency of the class following the modal class
f
Mo
is the frequency of the modal class
3.1 .4 The Mode
JDEUSTAQUIO
53
Example: Using the FDT of the Final Grades of 99 Selected Stat 101 Students. Find the mode.
Class Boundaries Frequency
LCB UCB f
49.5 - 56.5 11
56.5 - 63.5 13
63.5 - 70.5 13 f
1
70.5
- 77.5 19 - f
Mo
77.5 - 84.5 18 f
2
84.5 - 91.5 11
91.5 - 98.5 13
98.5 - 105.5 1
.
()
/ 76.5;
Thus the modal final grade of the 100 Stat 101 Students is 76.5
Summary of the Different Measures of Central Tendency
Measure of
Central
Tendency
Definition Data Requirement
Existence/
Uniqueness
Takes into
account
every
value?
Affected by
Outliers
Can treat
formula
algebraically?
Mean
"center of
mass"
At least interval scale
and values that are
close to each other
Always
exists/
Always
unique
Yes Yes Yes
Median
"center of
the array"
Divides the
array into
two equal
parts
At least ordinal scale
Always
exists/
Always
unique
No No No
Mode
"typical
value"
Most
frequent
value
Even if nominal scale
only
Might not
exist/ Not
always
unique
No No No
modal class
JDEUSTAQUIO
54
A measure of location provides us information on the percentage of observations
in the collection whose values are less than or equal to it. We also commonly refer
to these measures of locations as quantiles or fractiles.
The percentiles divide the ordered observations into 100 equal parts.
On the previous section, we have learned that the median is a measure of central
tendency. But in this section we also know that the median is also a measure of location and
three more measures of location; the percentiles, quartiles and deciles.
Recall: The median divides the ordered the observations into two equal parts. We
could interpret that at least 50% of the observation have values less than or
equal the median and at least 50% of the observation have values greater than
or equal the median value.
We could generalize this aspect of the median into percentiles, wherein the
percentiles divides the ORDERED observations into 100 equal parts. There is a total of 99
percentiles which can be denoted as; P
1
, P
2,
P
3 ,
P
99
.
For any k (1 to 99), we can interpret P
k
as a value for which at least k % of the
observations are less than or equal to its value and at least (100-k) % of the observations are
greater than or equal to the value of P
k
.
(i.e. the 56
th
percentile of a distribution P
56
is a value such that at least 56% of the observations
are less than or equal to its value and at least 44% are greater than or equal to its value)
3.2 Measures of Location
3.2.1 The Percentiles
JDEUSTAQUIO
55
Computing for the Percentile using Empirical Distribution with Averaging:
The steps involved in determining P
k
using the empirical distribution number with
averaging are as follows:
Step 1: Arrange the observations from lowest to highest. Denote the ordered
observations by X
(i)
. Thus, X
(i)
is the value on the i
th
position of the array.
Step 2: Compute for
, where n is the number of observations and k is the subscript
of P
k
. For example, if you want the 20
th
percentile, P
20
, then k =20.
Step 3: Use the following rule to determine the k
th
percentile:
If
is an integer, then P
k
=
If
is not an integer, then P
k
= X
(c)
where c is the closest integer greater than
Example:
a. The following are the total receipts of seven mining companies (in million pesos): 4.6,
1.3, 7.3, 6.6, 10.5, 50.7, and 12.6. Find the 75
th
percentile.
Solution:
Arrange the data in an array (lowest to highest).
Array: 1.3 4.6 6.6 7.3 10.5 12.6 50.7
Notation: X
(1)
X
(2)
X
(3)
X
(4)
X
(5)
X
(6)
X
(7)
Compute for nk/100 = (7) (75)/100 = 5.25. The number 5.25 is not an integer. Thus, we
use the second formula of the empirical distribution number with averaging. The closest
integer greater than 5.25 is 6 so the 75
th
percentile is X
(6)
, the sixth data item in the array.
Therefore, the 75
th
percentile is equal to 12.6.
b. The following are the number of years of operation of 20 mining companies: 4, 5, 6, 6,
7, 8, 10, 10, 11, 16, 17, 17, 18, 19, 20, 20, 21, 23, 25, and 30. Determine the 90
th
percentile.
Solution: Arrange the data in an array. Compute for nk/100=(20)(90)/100=18. The
number 18 is an integer. Thus, we use the first formula of the empirical distribution with
averaging.
/
.
()
()
Thus, we can say that 90 percent of the mining companies have been operating for less
than 24 years or 10% of the mining companies have been operating for more than 24 years.
JDEUSTAQUIO
56
Approximating the Percentile from Grouped Data:
To approximate the k
th
percentile from a frequency distribution, we just need to
perform the following steps:
Step 1: Calculate nk/100, where n=
is the number of observations.
Step 2: Construct the less than cumulative frequency distribution (<CFD)
Step 3: Locate the value in the <CFD column that is greater than or equal to nk/100. The
class interval corresponding to that value is the k
th
percentile class.
Step 4: Approximate the median using the formula given below:
)
where
is the lower class boundary of the P
k
th
class
C is the class size
n is the total number of observations
k is the percentile of interest
is the less than cumulative frequency preceding the P
k
th
class
is the frequency of the median class
Example: Using the FDT of the Final Grades of 100 Selected Stat 101 Students. Find the 75
th
percentile.
Class Boundaries Frequency
< CFD
LCB UCB f
49.5 - 56.5 11 11
56.5 - 63.5 13 24
63.5 - 70.5 13
37
70.5 - 77.5 19
56
77.5 - 84.5 19 f
p75
75
84.5 - 91.5 11 86
91.5 - 98.5 13 99
98.5 - 105.5 1 100
Compute for nk /100=75*100/100 = 75. From the <CFD column, the value that is
greater than or equal to nk/100 = 75. Now we compute,
/ = 84.5 ;
Thus we can say that at least 75% of all the students have a final grade in Stat 101 less than or equal
to 84.5. At the same time, at least 25% of the students have grades greater than or equal to 84.5.
P
75
th
class
<CF
Pk-1
JDEUSTAQUIO
57
The quartiles divide the ordered observations into 4 equal parts.
The deciles divide the ordered observations into 10 equal parts.
There are three quartiles; we interpret them in the following manner:
Q
1
, read as first quartile, is the value for which at least 25% of the observations are less
than or equal to it and 75% of the observations are greater than or equal to it.
Q
2
, read as second quartile, is the value for which at least 50% of the observations are
less than or equal to it and 50% of the observations are greater than or equal to it.
Q
3
, read as third quartile, is the value for which at least 75% of the observations are
less than or equal to it and 25% of the observations are greater than or equal to it.
As we can see, quartiles are just special cases of percentiles. Q
1
=P
25
, Q
2
=P
50
, and Q
3
=P
75
.
Therefore the computation for Q
1
would be the same as the computation for P
25
as so as the other
two quartiles.
There are nine deciles; we interpret them in the following manner:
D
1
, read as first decile, is the value for which at least 10% of the observations are less
than or equal to it and 90% of the observations are greater than or equal to it.
D
2
, read as second decile, is the value for which at least 20% of the observations are
less than or equal to it and 80% of the observations are greater than or equal to it.
D
9
, read as ninth decile, is the value for which at least 90% of the observations are less
than or equal to it and 10% of the observations are greater than or equal to it.
As we can see, quartiles are just special cases of percentiles. D
1
=P
10
, D
2
=P
20
, D
3
=P
30
,
D
4
=P
40
, D
5
=P
50
, D
6
=P
60
, D
7
=P
70
, D
8
=P
80
, and D
9
=P
90
. Therefore the computation for D
5
would be
the same as the computation for P
50
and Q
2
as so as the other deciles.
3.2.2 The Quartiles
3.2.3 The Deciles
JDEUSTAQUIO
58
The range is the distance between the maximum value and the minimum value. In
formula, we write this as:
Range = highest value - lowest value = maximum - minimum
The mean, median and the mode are not always sufficient to provide us the complete
picture of the data. Oftentimes, it is possible that two or more data sets have the same center
but differ in other aspects like the distance between the observations.
This aspect of the data could be described by the summary measures under the
measures of dispersion. This measure allows us to determine the degree of dispersion of the
observations about the center of the distribution. If the value of the summary measure is small,
then this indicates that the observations are not too different from each other so that the lump
of the observations is located on the center. On the other hand, if its value is large, then this
indicates that the observations are much dispersed and widely spread out of the center.
The range is the simplest and easiest-to-use measure of dispersion. It is a common
practice to present the range by stating the smallest and the largest values in the collection.
Example: Given the weight of five rabbits (in pound) 8, 12, 10, 14, 15. Compute for the range.
Solution: The lightest rabbit weighs 8 pounds and the heaviest rabbit weigh 15 pounds. Thus,
the range of the weights of the rabbit is;
Range = heaviest lightest = 15 8 = 7 pounds
4.1 Measures of Dispersion
4.1.1 The Range
JDEUSTAQUIO
59
Approximating the Percentile from Grouped Data:
We can approximate the range from a frequency distribution using the formula given below:
where
is the upper class limit of the last class interval
is the lower class limit of the first class interval
Example: Using the FDT of the Final Grades of 100 Selected Stat 101 Students. Find the range.
Class Boundaries
Frequency
LCL UCL f
50 - 56 11
57 - 63 13
64 - 70 13
71 - 77 19
78 - 84 19
85 - 91 11
92 - 98 13
99 - 105 1
The upper class limit of the last class interval is 105 and the lower class limit of the
first class interval is 50. Thus the range is: Range = 105 50 = 55.
The variance is a measure of dispersion that we can use to describe the variation of the
measurements in the collection. The variance could also be used to determine if the mean is a
good measure of central tendency. A relatively small variance indicates that the observations
are highly concentrated about the mean so that it is appropriate to use the mean to represent
all of the values in the collection. Whereas, if the variance is significantly large, then it signifies
that, on the average, the observations are very different from the mean.
4.1.2 The Variance and Standard Deviation
Lowest Class
Interval
Highest Class
Interval
JDEUSTAQUIO
60
The sample variance, unlike the population variance, is not the average of the squared
deviations of the mean from the observations. Its denominator is the total number of
observations in the sample minus one (n-1) and not n. We use (n-1) to make up for the
tendency of the estimator to underestimate.
The unit of the variance is the square of the unit of measurement which makes the
interpretation of the variance difficult to relate with the original observations. And because of
this, we may use the standard deviation.
The population variance for a finite population with N elements, denoted by o
2
(where o is the small Greek letter sigma) is:
The sample variance for a sample with n elements, denoted by s
2
, is;
where X
i
= measure taken from the i
th
unit in the collection
= population mean
= sample mean
The population standard deviation for a finite population with N elements, denoted
by o is:
The sample standard deviation for a sample with n elements, denoted by s is:
JDEUSTAQUIO
61
Example: Given the IQ of seven students in the sample, 100, 99, 110, 105, 112, 107, and 116,
compute for the standard deviation
Solution: Let X be the IQ of the i
th
student, i = 1, 2, , 7. The number of students in the
sample is n=7. The sample mean is;
Xi (X
i
-107) (X
i
-107)
2
100 -7 49
99 -8 64
110 3 9
105 -2 4
112 5 25
107 0 0
116 9 81
E(X
i
-107)
2
= 232
Thus the sample variance is
To get the standard deviation, we get the square root of the sample variance. Thus, the
sample standard deviation,
.
Computational Formula for Variance
Population variance:
Sample:
where X
i
= measure taken from the i
th
unit in the collection
N = is the number of observations in the population
n = is the number of observations in the sample
JDEUSTAQUIO
62
Approximating the Standard Deviation from Grouped Data:
We use the ff. notations and terms in the approximation of the variance and the
standard deviation from grouped data:
X
i
= midpoint or class mark of the i
th
class interval
f
i
= frequency of the i
th
class interval
k = number of classes
N = number of observation in the population
n = number of observation in the sample
= population mean
= sample mean
The computational formula for the Variance for the population and sample are as follows:
Population Variance:
Sample Variance:
Example: Consider the frequency distribution of the Final Grades in Stat 101 of the 100
selected students. Compute for the sample variance and sample standard deviation.
Class Limits Frequency Class Mark
LCL UCL f
i
x
i
f
i
X
i
f
i
X
i
2
50 - 56 11 53 583
30899
57 - 63 13 60 780
46800
64 - 70 13 67 871
58357
71 - 77 19 74 1406
104044
78 - 84 19 81 1539
124659
85 - 91 11 88 968
85184
92 - 98 13 95 1235
117325
99 - 105 1 102 102
10404
n=100
Ef
i
x
i
=7484 E f
i
X
i
2
=577672
( )
() ()
( )
( )
JDEUSTAQUIO
63
The z-score or the standard score measures how many standard deviations an
observed value is above or below the mean:
Population z-score
where is the population mean
o is the population standard deviation
Sample z-score
where
is the sample mean
s is the sample standard deviation
The z-score or standard score helps determine the relative position of an observed value
in the collection where the observed value is below or above the mean and it also measures
how far the observed value is from the mean in terms of the size of the standard deviation.
We can use the standard score two compare two or more observed values from
different data sets. We can also use the standard score in identifying possible outliers in our
dataset.
Example: The mean grade in Statistics 101 is 70% and the standard deviation is 10%, whereas in
Math 17, the mean grade is 80% and the standard deviation is 20%. Mark got a grade
of 75% in Stat 101 and a grade of 90% in Math 17. In which subject did Mark perform
better if we consider the grades of the other students in the two subjects?
Solution:
If we consider the grades of the other students in the two subjects, Marks score in
Stat 101 is just as good as his score in Math 17. Based on the z-scores, Marks scores in both
subjects are 0.5 standard deviations above their respective mean scores.
4.1.3 The Z-score
JDEUSTAQUIO
64
The coefficient of variation is the ratio of the standard deviation to the mean,
expressed as a percentage. The formula of the coefficient of variation (CV) is as
follows:
Population CV
100% where is the population mean
o is the population standard deviation
Sample CV
100% where
is the sample mean
s is the sample standard deviation
The coefficient of variation expresses the standard deviation as a percentage of the
mean. A large coefficient of variation indicates that the dataset is highly variable because its
standard deviation is large relative to the size of the mean.
We do not use the coefficient of variation is the mean is less than or equal to zero. When
the mean is zero, then the coefficient of variation will be undefined. When the mean is
negative, the coefficient of variation is meaningless.
Example: Suppose we want to buy a stock and we can select from one out of the two. The
prices of stock 1 and stock 2 per share are 2100 PhP and 650 PhP respectively. Let
us say that for the past months, we compiled data on a sample of prices f stock 1
and stock 2 at the close of trading and we have the following statistics:
Stocks 1 Stocks 2
Mean 2095 665
Standard Deviation 450 80
Solution: We compute for the coefficient of variation to know which stock has more variable price.
From the calculation, stock 1 has a more variable price than that of stock 2. Thus we
will select stock 1 if we want to take chance that its price will increase. We just have to
remember that by choosing stock 1, we are also taking the risk that its price will decrease.
4.1.4 The Coefficient of Variation
JDEUSTAQUIO
65
If it is possible to divide the histogram at the center into two identical halves, wherein
each half is a mirror image of the other, then the distribution is called a symmetric
distribution. Otherwise, it is called a skewed distribution.
Relying solely on a measure of central tendency and a measure of central tendency
and a measure of dispersion in figuring out the behavior of a dataset may sometimes be
misleading. It is possible for two datasets to have equal means and equal standard deviations;
and yet, the shapes of their histograms are extremely different.
The figure below shows various examples of symmetric and skewed distributions. We
will notice that there are two distinct types of skewness. Either the concentration of
observations is on the right side of the distribution which is tapering-off on the left side or the
other way around.
4.2 Measures of Skewness
4.2.1 Symmetry and Skewness
JDEUSTAQUIO
66
A distribution is said to be positively skewed or skewed to the right when the
concentration of the values is at the left-end of the distribution and the upper tail of
the distribution stretches out more than the lower tail.
A distribution is said to be negatively skewed or skewed to the left when the
concentration of the values is at the right-end of the distribution and the lower tail of
the distribution stretches out more than the upper tail.
Skewness presents a problem in the analysis of data because it can adversely affect the
behavior of certain summary measures. For this reason, certain procedures in statistics depend
on symmetric assumptions. It would be inappropriate to use these procedures in the presence
of severe skewness. Sometimes we need to perform special preliminary adjustments, such as
transformations before analyzing the data.
In general we should look if there is the presence of skewness in the data before
analysis for us to prevent contamination or errors in the succeeding analysis because it may
result to spurious conclusions.
Relationship of the Three Measure of Central Tendency and the Skewness of the Distribution
JDEUSTAQUIO
67
All measures of skewness that would be discussed are relative to each other, thus we
can always use the following interpretations for the computed measures:
Sk = 0 symmetric distribution
Sk > 0 positively skewed distribution
Sk < 0 negatively skewed distribution
Pearsons Coefficient for Skewness
The Pearsons first coefficient of skewness for a sample is,
The Pearsons second coefficient of skewness for a sample is,
The bases for these formulas are the relationship of the mean, median, and the
mode. The problem in first coefficient of skewness regarding the mode led to the development
of the second coefficient of skewness. The second coefficient formula is based on empirical
evidence on the distance of the median from the mean and the mode.
Example: Given the mean, median, mode and sample standard deviation of two different
sets of test scores in Stat 101 Finals, compute for the Pearsons coefficient of
skewness for these two sets of scores.
Set A: X
= 29.5
s=19.33
()
Set B: X
= 70.5
s=19.33
()
Both coefficients of skewness indicate that the distribution of set A is positively skewed while the
distribution of set B is negatively skewed. Their magnitudes are equal indicating that they have the same
degree of asymmetry but in opposite directions.
4.2.2 Common Measures of Skewness
A measure of skewness is a single value that indicates the degree and direction of
asymmetry.
JDEUSTAQUIO
68
Coefficient of Skewness Based on Third Moment
The population coefficient of skewness based on third moment is derived by
An unbiased estimator of the coefficient of skewness based on third moment is derived by
()
where
Example: Given the sample data of two sets of test scores in Stat 101 Finals, compute for the
unbiased estimator of the coefficient of skewness based on the third moment for
these two sets of scores.
Set A
10 10 15 15 15 15 15 15 15
15 15 15 15 15 15 20 20 20
20 20 20 20 20 20 20 20 25
25 25 25 25 25 25 25 35 35
40 40 40 40 40 45 45 45 50
60 75 75 80 95
Set B
5 20 25 25 40 50 55 55 55
60 60 60 60 60 65 65 75 75
75 75 75 75 75 75 80 80 80
80 80 80 80 80 80 80 80 85
85 85 85 85 85 85 85 85 85
85 85 85 90 90
Set A:
()
()
= 1.7297
Set B:
= -11757,
()
()
= - 1.7297
Sample coefficient of skewness
based on the third moment
JDEUSTAQUIO
69
Coefficient of Skewness Based on the Quartiles
The coefficient of skewness based on the quartiles is defined as:
) (
Example: Compute for the coefficient of skewness based on the quartiles of the two sets of
tests scores used in the previous example.
Set A:
=40
)(
()
Set B:
=85
)(
()
The term kurtosis came from the Greek word kurtos meaning convex. It is used to
describe the hump of a relative frequency distribution as compared to the normal distribution.
The normal distribution is a bell-shaped curve that is symmetric about its mean, . We
would discuss the further details of the normal distribution on the succeeding lessons. Below are the
three types of distribution according to its kurtosis based on the normal distribution:
1. Mesokurtic The hump is the same as the normal curve. It is neither too flat nor too
peaked.
2. Leptokurtic The curve is more peaked and the hump is narrower or sharper than the
normal curve. The prefix lepto came from the Greek word leptos
meaning small or thin.
3. Platykurtic The curve is less peaked and the hump is flatter than the normal curve.
The prefix platy from the Greek word platus means wide or flat.
4.3 Measures of Kurtosis
4.3.1 Types of Kurtosis
JDEUSTAQUIO
70
Coefficient of Kurtosis Based on the Fourth Moment
The population coefficient of kurtosis based on the fourth moment is derived by
The Sample coefficient of kurtosis based on the fourth momentis derived by
[
]
where
In general: kurt = 3 mesokurtic
kurt > 3 leptokurtic
kurt < 3 platykurtic
Exercise: Compute for the sample coefficient of kurtosis based on the fourth moment on
the two datasets of the scores of the students in Stat 101
(Hint: Set A and Set Bs coefficient of kurtosis should almost be equal and leptokurtic)
JDEUSTAQUIO
71
The Exploratory Perspective
Classical statistical techniques yield the most favorable results under the condition that
certain assumptions are satisfied. However, in reality, not all these assumptions are satisfied.
Exploratory data analysis involves probing the data before comparing them to any probabilistic
model. The techniques of exploratory data analysis help us to cope with a set of data in a fairly
informal way, guiding us toward structure relatively quickly and easily. It provides us with an
extensive repertoire of methods for the detailed study of a set of data.
EDA vs CDA
Confirmatory Data Analysis Exploratory Data Analysis
Assesses the reproducibility of the
observed patterns and effects.
Isolates patterns and features of the
data and reveals these forcefully to the
analyst.
Work under a stringent set of
assumptions
Flexible in distribution
Incorporates past gained info / data Explores the data at hand to discover
structure / relationships.
Four themes of EDA
- Resistance a resistant method produces results that change only slightly when a small
part of the data is replaced by new numbers.
- Residuals what remain after a summary or fitted model has been subtracted out of the
data according to the schematic equation:
Residual = data fit
- a key attitude of EDA asserts that an analysis of a set of data is not complete
without a careful examination of the residuals.
- Re-expression involves finding what scale would simplify the analysis of the data.
- Revelation visual displays meet the analysts need to see behavior and thus to grasp the
unexpected features as well as familiar regularities in the data.
JDEUSTAQUIO
72
Transforming Data
Frequently, the data that we obtain will not give straightforward information and is difficult
to summarize, occasionally, the cost and ease of analysis are seriously impaired. Among the
reasons that cause these difficulties are the following:
- Strong asymmetry
- Many outliers in one tail
- Widely differing measures of location and space.
- Large and systematic residuals
In order to avoid these difficulties, one possibility to consider is the use of data
transformation. We change not only the units by which the data are stated, but also the basic unit
of measurement.
Defn: A transformation of the batch x
1
, x
2
, . . . , x
n
, is a function T that replaces each x
i
by a
new value T(x
i
) so that the transformed values of the batch are T(x
1
), T(x
2
), . . , T(x
n
).
Properties of Transformations
1. They preserve the order of the data in a batch; that is, they are strictly increasing
function. Data values that are larger in the original scale will be larger in the re-
expressed scale, but the spacing may change.
2. They preserve letter of a batch except for small differences that may result from
interpolating between data points. In particular, because letter values rely on order,
medians are transformed to medians, and fourths to fourths.
3. They are continuous functions; this guarantees that points that are very close
together in the raw batch will also be very close together in the re-expressed batch,
at least relative to the scale being used.
4. They are smooth functions in that the functions we use have derivatives of all orders.
This requirement guarantees that the functions do not have sharp corners.
5. They are specified by elementary functions, so that re-expression with the aid of all
but the simplest hand-held calculators is quick and easy.
Reasons for Transforming Data
1. To enhance interpretation in a natural way.
Sometimes transformation provides a natural way of reporting the information.
For example, temperature reading is commonly reported in Fahrenheit degrees (
O
F).
Transforming it in Celsius degrees (
O
C) facilitates interpretation since 0
O
C and 100
O
C
are the freezing and boiling points, respectively, of water.
JDEUSTAQUIO
73
2. To arrive at a symmetric pattern.
Symmetry is a desirable property not just for aesthetic reasons. A typical value
like the average or median summarizes a batch and is best understood when the batch
pattern is symmetrical.
3. To stabilize the spread in several batches.
With several batches, an increase in the level of a batch usually brings about an
increase in spread. If the relationship between spread and level is strong, there is
often a need to transform the batches so that they will be better suited for
comparison, visual exploration, and confirmatory analysis, e.g. ANOVA models
assumes constant variance within groups. In addition, the individual batches will
become more nearly symmetric and may have fewer outliers.
4. To straighten out relationship between two variables.
There are advantages in working with a linear relationship between two variables.
Interpretation is easier and departures from fit are more easily detected.
Furthermore, interpolation and extrapolation are easy. Transformation of one or both
variables sometimes will straighten relationships that are not linear.
5. To simplify the structure in two-way tables.
The two-way table presents another data structure in which transformation may
lead to simplification. Transformation often makes it easier to understand and explain
all the systematic variation in the table using an additive model.
The Stem-and-Leaf display
JDEUSTAQUIO
74
The stem-and leaf display is a graphical tool used to organize data in such a way that the
shape/distribution of the data is seen clearly without losing the actual data values. It enables us to
notice such characteristics as:
- the symmetry of the batch
- how spread out the data values are
- the presence of values that are far removed from the rest
- the presence of areas wherein the data is concentrated
- the presence of gaps in the sorted data
Advantages
1. It helps us to see the distribution of the data values within each interval, as well as patterns
in the data values
2. By preserving more early digits of the data values, the display also shortens the link back to
the individual observation and any identifying information accompanying it.
3. The lines in the display provide more information than the bars in the histogram.
Constructing a basic stem-and-leaf display
1. Choose a suitable pair of adjacent digits in the data.
2. Split the data value between the two digits.
3. We allocate a separate line in the display for each possible string of leading digits (stem).
4. Write down the trailing digits (leaf) of each data value on the line corresponding to its
leading digits. As an option, the leaves can be sorted in ascending order.
5. Do not forget to indicate the title and unit.
Depth
Ranks are assigned by counting in from each end of the ordered batch. The depth of the data
value is the smaller of 2 ranks.
o Depth is symmetric and the median will have the highest depth.
o For lines having more than 1 leaf, the depth will be the maximum among the leaves on the
line.
o If the median falls on a stem, instead of putting the depth of the median on the line to
which it belongs, we count the leaves on the middle line and enclose it in parenthesis.
Otherwise, use the definition of depth.
Example
The following data show the commissions earned (in thousands of pesos) by a firm of 26
real-estate brokers in a month:
93 67 75 88 66 60 56 71 102 83 81 60 57 59 77 70 86 87 95 84 71 73 66 70 95 82
JDEUSTAQUIO
75
# n
M depth of median median
F depth of fourth lower fourth upper fourth
1 lower extreme upper extreme
# n reminds the reader that the
batch has n values
M stands for median
F stands for fourth
This column contains the depths
of M,F and the extremes
Stem Leaf (unit = 1) Depth
5 | 6 7 9 3
6 | 0 0 6 6 7 8
7 | 0 0 1 1 3 5 7 (7)
8 | 1 2 3 4 6 7 8 11
9 | 3 5 5 4
10 | 2 1
Note: Resistant methods are little affected by a small fraction of unusual data values. When
unusual data values are noticed, these are discarded, and the basis for the choice of scale is the
rest of the data that remains.
Letter Values
For exploratory purposes, it is often advantageous to use summaries based on sorting and
counting. Such summaries can be resistant, that is, an arbitrary change in a small part of the batch can
have only a small effect on the summary. Letter values are a collection of observations drawn
systematically from the batch, more densely from the tails than from the middle. These letter values
can be used to
- define resistant measures of location
- define the amount of spread in the batch
- search for outliers
If we are to make effective use of summary values, we must present them in a format that
reveals the important numerical features of a batch and invites simple calculations related to
location and spread. A simple, useful and flexible method is with the use of the 5-letter summary.
The skeleton of this letter-value display looks like the following:
JDEUSTAQUIO
76
Constructing the 5-number summary
1. Sort the data from lowest to highest.
2. Find the median and the depth of the median.
- The upward rank is the position of the value counting upward from the smallest value.
- The downward rank is the position of the value counting downward from the largest value.
- The depth of a data value is the smaller between its upward rank and its downward rank.
2
1 +
=
n
depth Median
3. Find the fourths/hinges and their depths
2
] 1 [ +
=
median of depth
fourth of Depth
4. Find the extremes
- the two data values with a depth of 1, namely, the minimum and the maximum
5. Present the data following the format shown above.
The 5-number summary can be extended to a 7-letter summary by adding two more summary
values, called the eighths. This simply follows the pattern started by defining the fourths, with the
depth of the eights being defined as
2
] 1 [ +
=
fourth of depth
eighth of Depth
For larger and larger batches we can continue to add pairs of summary values by halving he
fraction of the data remaining beyond the previous non-extreme summary value at each end of
the batch and stopping when the depths reaches 1.
Box-and-Whisker Plot
The box-and whisker plot, more commonly known as the boxplot, was developed by
John Tukey. It is a visual representation of the 5-number summary of a batch of numbers which
shows much of the structure of the batch. The boxplot shows characteristics that derive from
the actual data, not from an assumed distributional form. It can be used when we cannot or do
not assume a distributional form for the data.
From the boxplot, the following characteristics can be determined:
a. location
b. spread
c. skewness
d. tail length
e. outlying observations
JDEUSTAQUIO
77
Constructing Box-and-Whisker Plot
1. Obtain the 5-letter summary of the batch and the fourth spread. The cut-offs are defined as
the two point 1.5 midspreads (fourth-spread) away from the two fourths.
df = F
U
F
L
lower cut-off = F
L
1.5df upper cut-off = F
U
+ 1.5df
2. Construct the box. The left (bottom) end of the box is located at the lower fourth, the right
(top) end is located at the upper fourth. These are called the hinges. The median is a line
located inside the box, between the two fourths.
3. The tips/caps of the whiskers are lines located at the points in the batch farthest from the
hinges, but within the defined cut-offs.
4. Any cases beyond these marks are marked individually:
- outliers are points between 1.5 and 3 midspreads from the hinges, denoted by an
x-mark.
- extremes are points beyond 3 midspreads from the hinges, denoted by a circle.
Example:
Population of the 15 largest US cities in 1990
City Pop'n (in 10,000s) City Pop'n (in 10,000s)
New York 778 Washington D.C. 76
Chicago 355 St. Louis 75
Los Angeles 248 Milwaukee 74
Philadelphia 200 San Francisco 74
Detroit 167 Boston 70
Baltimore 94 Dallas 68
Houston 94 New Orleans 63
Cleveland 88
# 15 Population of 15 Largest US
Cities in 1960
M 8 88
F 3h 74 183.5
1 63 778
dF = FU FL = 109.5
Outside Cut-offs: (-90.25, 347.75)
Outliers: New York (778), Chicago (355)
JDEUSTAQUIO
78
An abstract model is a description of the essential properties of a phenomenon.
A deterministic model is a type of abstract model that describes a phenomenon through
known relationships among the states and events, in which a given input will always
produce the same output.
The development of probability theory was not originally intended to be used in solving
inferential problems. It was first developed to give answers to professional gamblers questions
on the systematic pattern of outcomes of games involving dice or cards that will allow them to
adjust their bets to the odds of success. This is the reason why most of the basic examples on
probability theory are die-throwing experiments and the selection in a deck of cards.
Today, many important phenomena that are of interest to humankind share something
in common with these games of chance. It is impossible to predict with certainty when such a
phenomenon will occur. By studying patterns, we can learn more about the behavior of the
phenomenon of interest and then be able to predict an occurrence of a phenomenon with a
certain degree of confidence.
The use of abstract models is actually not new to many of us. We apply the
mathematical formula provided by an abstract model to come up with an approximation of
reality
The deterministic model is a model that we commonly encounter during the
application part of Elementary Math. One example is the computation of the area of a certain
rectangular piece of land. The area that you would get would always be the same every time
you compute for it.
6.1 Probabilistic Models
JDEUSTAQUIO
79
A probabilistic/stochastic model is a type of abstract model that describes a phenomenon
by assigning a likelihood of occurrence to the different possible outcomes of the process.
A random experiment is a process that can be repeated under similar conditions but
whose outcome cannot be predicted with certainty beforehand.
The sample space, denoted by O (Greek letter, omega), is the collection of all
possible outcomes of a random experiment. An element of the sample space is called a
sample point.
An example of a stochastic model is the game that involves tossing a coin. The results
of the tosses would not be certain even if it is loaded (unfair coin). In fact, no matter how many
times we repeat the process, it is impossible to predict with certainty what the next outcome
will be.
In inferential statistics, the process of selecting a sample of size n from a population of
size N using probability sampling is one of the random experiments of interest. It is just like
selecting n cards at random from a deck of N=52 cards.
Even if we use exactly the same sample selection procedure, there is no way we can
predict, without any error, what the composition of the next sample will be.
We can show the sample space by using any of the various methods of listing. One
example is the roster method, where we list all the possible outcomes of the experiment.
Example: Specify the sample space of the experiment of tossing a coin twice.
First we use H to denote the result of getting a head in a toss and T to denote
the result of getting a tail in a toss. Then there are just four possible results therefore:
O = {HH, HT, TH, TT}
6.2 Basic Concepts of Probability
JDEUSTAQUIO
80
An event is a subset of the sample space whose probability is defined. We say that
an event occurred if the outcome of the experiment is one of the sample point belonging in
the event; otherwise, the event did not occur.
Aside from the roster method, we can specify the sample space using the rule method
which is usually more preferred when the experiment has a lot of results to list
entirely.
Example: Specify the sample space of the experiment of tossing a coin 1000 times.
Again, first we use H to denote the result of getting a head in a toss and T to
denote the result of getting a tail in a toss. Then there are 2
1000
= 1.0715E+301
possible results therefore we would use the rule method:
O = {(x1, x2, ,
)| xi c {H, T} for all i }
In set theory, a subset of the universal set is a set. Since an event is a subset of the
sample space (our universal set), then we can use the same notation to denote a set which is
any capital Latin letter to denote an event of interest.
Example: Consider the experiment of tossing a pair of colored dice, one is red and the
other one is green. Let O = {(x, y) | x c {1, 2, , 6} and y c {1, 2, , 6}} where x is for the red die
and y for the green die. This sample space contains 36 sample points by rules of counting.
Again, first we use H to denote the result of getting a head in a toss and T to denote the
result of getting a tail in a toss. Then there are 2
1000
= 1.0715E+301 possible results
therefore we would use the rule method:
Some examples of events are listed below:
A = event of having the same number of dots on both dice
= { (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6) }
B = event of 3 dots on the red die
= { (3, 1), (3, 2), (3, 3), (3, 4), (3, 5), (3, 6) }
C = event of getting a sum of 5 dots on both dice
= { (1, 4), (2, 3), (3, 2), (4, 1) }
D = event of 7 dots on the green die = C
JDEUSTAQUIO
81
The impossible event is the empty set, C. The sure event is the sample space, O
Two events A and B are mutually exclusive events if and only if AB=C; that is, A and
B have no common elements.
The event D is an example of an impossible event where we know that this event
would never happen. Also, sometimes two events could occur simultaneously but also
sometimes two events could never occur simultaneously. The easiest way to check if two
events could happen simultaneously is to look at the sample points of both events, if they have
at least one common sample point, this means that the two events can happen simultaneously
otherwise, if they do not have any common sample points, these events cannot occur
simultaneously which is also called mutually exclusive events.
The concept of mutually exclusive events can be extended to more than two events.
For example, three events, say A, B, and C are mutually exclusive events whenever it is
impossible for any pair of these events to occur simultaneously. Mathematically speaking,
AB=C, AC=C, and BC=C must all be true.
Review of Some Concepts in Set Theory for Probability Theory
Let A, B and C be events in O then:
1. Inclusion: We say that A is a subset of B if all points of a set A are also points in B. Symbolically,
( )
2. Equality: If and B , then A and B are said to be equal, denoted by A=B.
3. Intersection of A and B: AB = {x O: x A and x B}
4. Union of A and B: AB = {x O: x A or x B}
5. Complement of A: A
C
=* +
6. Set Difference: A\B = AB
C
= {x O: x A and x B}
7. Symmetric Difference: (A\B) (B\A) = {x O: x A and x B} or {x O: x B and x A}
Remarks:
a) Unions, intersections and set differences f events are also events.
b) Some of the properties of event composition and event relations listed below are
useful in answering problems on probability.
Some Properties of Event Composition and Event Relations:
1. Reflexivity of Inclusion: AA.
2. Transitivity of Inclusion: AB, B .
3. A\B and B\A are disjoint. AB and A\B = AB
C
are also disjoint.
4. AB + AB
C
= A
5. Reflexivity of Union and Intersection: AA=A and AA=A
JDEUSTAQUIO
82
The probability of an event A, denoted by P(A), is a function that assigns a measure
of chance that event A will occur and must satisfy the following properties:
a) () for any event A
b) P(O) = 1
c) Finite Additivity: If A can be expressed as the union of n mutually exclusive
events, that is, A=A
1
A
2
....
A
n
, then P(A) = P(A
1
) + P(A
2
) + ... + P(A
n
)
A simple event is an event which contains only one element of the sample space while a
compound event is an event that can be expressed as the union of simple events, thus
containing more than one sample point.
6. Commutative Property of Union and Intersection: AB= BA and AB=BA
7. Associative Property of Union and Intersection:(AB) C=A(BC)= (AC) B
(AB) C=A (BC) = (AC) B
8. Distributive Property of Union and Intersection: A (BC)= (AB) (AC)
A (BC) = (AB) (AC)
9. De Morgans Law: (A
C
)
C
= A
(AB) = A
C
B
C
(AB) = A
C
B
C
The last property, also called the finite additivity property, provides a useful tool in
computing for the probability of an event. It says we need to express event A as the union of
mutually exclusive events with known probabilities, and then, we simply get the sum of their
individual probabilities in order to compute for P(A).
Remarks:
1. Being a subset of the sample space, an event is itself a set not a number. On the other
hand, the probability of an event is a number.
2. Probability that is near to 1 indicates that the event is more likely to occur. It is not a
guarantee that the event would occur, it is just that it is a common occurrence. On the
other hand if the event is near to 0, it is a rare event, meaning it is less likely to occur
3. Probabilities near or 0.5 indicates that the event is just as likely to occur as to not.
JDEUSTAQUIO
83
Under classical approach, a probability of an event is determined even before the
experiment is performed using the following rule:
If an experiment can result in any one of N different equally likely outcomes, and if
exactly n of these outcomes corresponds to event A, then the probability of event A is:
()
Example: Tossing a Fair Coin Thrice
Note that in the experiment of tossing a fair coin thrice, it was already assumed that the
coin is fair meaning, heads and tails are equally likely to occur on each toss. It is apparent that
the random experiment need not be performed to assess the probability of occurrence of an
event. The number of sample points in event A, the event that there is at least one tails in three
tosses of a fair coin, is seven. Then P(A), the probability that three tosses of a coin would result
to at least one tails, is 7/8.
Under relative frequency approach, the probability of an event is determined by
repeating the experiment a large number of times using the rule:
()
Example:
Numerous intensive studies have been conducted to analyze consumer planning for the
purchase of durable goods such as television sets, refrigerators, washing machines, stoves and
automobiles. Suppose that a marketing director for a consumer electronics company was
interested in studying the intention of consumers to purchase new large television sets
(defined as 35 inches or larger) in the next 12 months and, as a follow-up, whether they in fact
actually purchased the television. Suppose that a sample of 1000 households was initially
6.3 Approaches to Assigning Probabilities
6.3.1 Classical Probability (A Priori)
6.3.2 Relative Frequency (A Posteriori)
JDEUSTAQUIO
84
selected and the respondents were asked whether they actually purchased the television. The
results are summarized below.
Purchase Behavior of 1,000 Household for Large
Televisions
Planned to
Purchase
Actually Purchased
Total
Yes No
Yes 200 50 250
No 100 650 750
Total 300 700 1000
Consider the random experiment of conducting an interview of a household
regarding the intention to purchase a large television and performing a follow-up as to
whether or not the said household purchased the television a year after. The random
experiment is performed for 1000 different households. Suppose that a new household with
same characteristics as previously surveyed is subjected to the same interview and follow-up.
The probability that the new household intends to buy a large television and pushes through a
year is approximately (200/100) = 0.20.
Under the Subjective Probability Approach, the probability of occurrence of an event is
determined by the use of intuition, personal beliefs, and other indirect information.
Example:
Suppose that an oil spill has occurred. An environmental scientist asks, What is the
probability that this spill can be contained before it causes widespread damage to nearby
beaches? Many factors come into play; among them are the type of spill, the amount of oil
spilled, the wind and water conditions during the clean-up operation, and the nearness of the
beaches. These factors make this spill unique. The scientist called upon to make a value
judgment, that is, to assign a probability to the event based on informed personal information.
6.3.3 Subjective Probability
JDEUSTAQUIO
85
Suppose an experiment can be divided into 2 stages. Then if the first stage of the
experiment can result in n distinct possible outcomes and if, for each outcome of the first
stage, there are m distinct possible outcomes, then, there are nm possible outcomes of this
experiment.
Example:
1. If a man has red, green and gold shirts and red, green and gold neckties, how many
ways can he choose different colors for his shirt and necktie?
A = {(x, y): x {R, G, Au} and y {R, G, Au}. The first coordinate of the ordered pair,
x, represents the color of the shirt selected while the second coordinate, y,
represents the color of the necktie selected.
Let n = number of choices for x
m = number of choices for y
Then n(A) =nm =(3)(3) = 9
2. From a menu containing 3 soups, 2 salads, 6 entrees, and 3 desserts, how many
different dinners can be ordered?
A = {(x
1
, x
2
, x
3
, x
4
): x
1
{1, 2, 3}, x
2
{1, 2}, x
3
{1, 2, 3, 4, 5, 6} and x
4
{1, 2, 3}.
where x
1
= type of soup ordered let n
1
= number of types of soup
x
2
= type of salad ordered n
2
= number of types of salads
x
3
= type of entrees ordered n
3
= number of types of entrees
x
4
= type of dessert ordered n
4
= number of types of desserts
Then n(A) = n
1
n
2
n
3
n
4
= (3)(2)(6)(3) = 108
3. How many 3-digit numbers can be formed from the digits 1,2,5,6 and 9
a. If each digit need not be distinct?
A = {(x
1
, x
2
, x
3
): x
i
{1, 2, 5, 6, 9}, i= 1, 2, 3}.
n(A) = (5)(5)(5) = 125
b. If each digit must be distinct?
B = {(x
1
, x
2
, x
3
): x
i
{1, 2, 5, 6, 9}, i= 1, 2, 3 where x
i
= x
j
for i = j}.
n(B) = (5)(4)(3) = 60
6.4 Counting Techniques
6.4.1 Basic Principle of Counting
JDEUSTAQUIO
86
An ordered r-tuple of elements of a nonempty set Z, say (z
1
, z
2
,...,z
k
), with distinct
components (that is, z
i
= z
j
) is called a permutation of r elements of Z. If set Z contains n
distinct elements, then the number of r-permutations of set Z is denoted by P(n,r) or
n
P
r
A subset {z
1
, z
2
,...,z
k}
} with k distinct elements of a nonempty set Z, is called a combination
of k elements of Z. If set Z contains n distinct elements, then the number of r-combinations
of set Z is denoted by C(n,r) or
n
r
4. If a multiple-choice test consists of 5 questions each with 4 possible answers of which
only 1 is correct,
a. How many different ways can a student answer the questions?
A = {( x
1
, x
2
, x
3
, x
4,
x
5
): x
i
{a, b, c, d }, i= 1, 2, 3, 4, 5}.
n(A) = (4)(4)(4)(4)(4) = 4
5
= 1024
1. How many different ways can a student answer all the 5 questions incorrectly?
B = {( x
1
, x
2
, x
3
, x
4,
x
5
): x
i
{a, b, c, d } {y}, where y is the correct answer,
i= 1, 2, 3, 4, 5}.
n(B) = (3)(3)(3)(3)(3) = 3
5
= 243
Exercise:
1. How many different 7-place license plates are possible if the first 2 places are for
letters and the other 5 are for numbers? What about if no letter or no number can
be repeated in a single license plate?
2. Paul, John, Ringo and George have formed a band consisting of 4 instruments. If
each of the boys can play all 4 instruments, how many different arrangements are
possible? What if Paul and John can play all 4 instruments but George and Ringo
can play only the piano and drums?
3. How many different ways can a true-false test consisting of 10 questions be
answered?
Example: Suppose Z = {1, 2, 3, 4, 5}. List down all the possible permutations of 3 elements
of Z. List down all possible combination of 3 elements of Z.
There are 60 possible permutations for this scenario.
Whereas, there are only 10 possible combinations as follows:
{1, 2, 3}, {1, 2, 4}, {1, 2, 5}, {1, 3, 4}, {1, 3, 5}, {1, 4, 5}, {2, 3, 4}, {2, 3, 5}, {2, 4, 5}, {3, 4, 5}.
6.4.2 Permutations and Combinations
JDEUSTAQUIO
87
If we are counting the number of ways k objects could be chosen from n objects without
regards on being distinct (getting th e same object more than once). We could get it by the
formula n
k
.
While if we need to take into account that the selected objects needs to be distinct. We
could get it by the formula n! = n x (n-1) x (n-2) x ..... x 1. We also define 0! = 1.
Remarks:
There are k! distinct permutations associated with each combination. k! represents the
number of ways in which you can arrange the elements that were included in the combination.
When we are counting the number of different groups of k objects that can be formed
from n distinct objects, we would count the combinations while if we are interested in
determining the number of different ordered arrangements of k objects selected from n
distinct objects, we count the permutations.
Example:
1. Consider the experiment of tossing 4 distinguishable dice.
a. How many possible outcomes are there?
O = {(x
1
, x
2
, x
3
, x
4
): x
i
c Z = {1, 2, 3, 4, 5, 6}}
n(O) = n
k
= 6
4
= 1296
b. How many possible outcomes are there for which no two dice show the same
number of spots?
A = {(x
1
, x
2
, x
3
, x
4
): x
i
c Z = {1, 2, 3, 4, 5, 6}, x
i
= x
j
for i= j}
n(A)= (n)
k
= (6)
4
= (6)(5)(4)(3) =360
c. How many possible outcomes are there for which all the spots are even?
B = {(x
1
, x
2
, x
3
, x
4
): x
i
c Z = {2, 4, 6}}
n(B) = n
k
= (3)
4
= 81
2. From a group of 5 men and 7 women.
1. How many committees of 5 persons can be formed?
Since we are counting the number of different groups of k=5 objects that could
be formed from a total of n=12 objects then we are counting the number of
combinations. Therefore, the number of possible committees of size 5 that can
be formed is (
) (
)
JDEUSTAQUIO
88
2. How many committees of 2 men and 3 women can be formed?
The experiment can be divided into 2 stages: (a) the selection of the men and (b)
the selection of women. Then by the basic principle of counting, there are n
1
n
2
possible committees where n
1
= number of ways that the men can be selected
and n
2
= number of ways that the women can be selected.
). Thus, the number of committees consisting of 2 men
and 3 women that can be formed is n
1
n
2
= (
) (
)=(10)(35) = 350.
Exercise:
1. Consider the game of poker where a player is given 5 cards.
a. How many 5-card poker hands are there?
b. How many of these 5-card poker hands contain exactly 3 hearts?
2. A class consists of 10 men and 20 women. An examination is given, and the students
are ranked according to their performance. Assume that no two students obtain the
same score.
a. How many different ranking are possible?
b. If the men were ranked just among themselves and the women among
themselves, how many different ranking are possible?
3. Five separate awards are to be presented to selected students from a class of 30.
How many different outcomes are possible if
a. A student can receive any number of awards;
b. Each student can receive at most 1 award
Example: How many different letter arrangements can be formed using the letters P E P P E R?
There are
possible letter arrangements
where n = number of letters r
1
= number of Ps
r
2
= number of Es r
3
= number of Rs
Additional Counting Theorems:
+The number of permutations of n distinct objects in a circle is (n-1)!
+The number of distinct permutations of n things of which r
1
are of the 1
st
kind, r
2
are of
the 2
nd
kind, ..., r
k
are of the k
th
kind is
where
JDEUSTAQUIO
89
Take note that there are actually 6! permutations of the letters P
1
, E
1
, P
2
, P
3
, E
3
, R when
the 3 Ps and 2 Es can be distinguished from each other. But in this case, we know that the
letters cannot be distinguished from each other.
Exercise:
1. How many different signals, each consisting of 9 flags hung in a line, can be made from
a set of 4 white flags, 3 red flags, and 2 blue flags, if all flags of the same color are
identical?
2. How many ways can 20 new applicants be assigned to the 5 committees of an
organization so that each committee will get 4 new applicants each?
Suppose an urn contains M balls, labeled 1 to M, and a sample of size n is drawn, then
there are:
i. M
n
ordered samples with replacement
ii. (M)
n
ordered samples without replacement
iii. (
) unordered samples without replacement
Example: Suppose an urn contains 10 balls, labeled 1 to 10, and a sample of size 5 is drawn.
1. How many ordered samples with replacement can be drawn? (10)
5
2. How many ordered samples without replacement can be drawn? (10)
5
3. How many unordered samples with replacement can be drawn? (
)
6.4.3 Special Results in Counting
Theorem:
Suppose an urn contains M balls, labeled 1 to M, and those labeled from 1 to K
(K<M) are defective. Define A
k
= the set containing all possible ordered samples of size n
which contains k defectives.
(i) under sampling with replacement, n(A
k
) =
(ii) under sampling without replacement, n(A
k
) =
JDEUSTAQUIO
90
Example:
1. Suppose an urn contains 10 balls, labeled 1 to 10, and those labeled from 1 to 4 are
defective. Define A
2
= the set containing all possible ordered samples of size 5 which
contains 2 defectives.
a. How many elements belong to A
2
if sampling is done with replacement?
(
) .
( )
n
(
( )
b. How many elements belong to A
2
if sampling is done without replacement?
(
) .
( )
*()
( )
2. If a multiple-choice test consists of 10 questions each with 4 possible answers such that
a. there are exactly 7 correct answers
(
) .
()
n
(
( )
b. there are at least 7 correct answers
(
) 0.
( )
n
1
[(
( )
c. there are at most 7 correct answers
(
) 0.
()
n
1
[(
( )
Exercise: Suppose a group of 20 undergraduate students and 10 post graduate students are
available to fill certain student government posts. If 6 students are to be randomly selected
from this group,
1. How many possible ordered samples with replacement are there;
2. How many possible ordered samples without replacement are there;
3. How many possible ordered samples with replacement will contain exactly 3
undergraduate students;
4. How many possible ordered samples without replacement will contain exactly 3
undergraduate students?
JDEUSTAQUIO
91
Bonus Exercise:
1. How many different letter arrangements can be made from the letters of the word
M I S S I S S I P P I?
2. How many ways can 8 people be seated in a row if
a. there are no restrictions on the seating arrangement;
b. Persons A and B must sit next to each other;
c. there are 4 men and 4 women and no 2 men or women can sit next to each
other;
d. there are 5 men and they must sit next to each other;
3. A woman has 8 friends, of whom she will invite 5 to a party. How many choices does she
have if 2 of the friends are feuding and will not attend together? How many choices
does she have if 2 of hers friends will only attend together?
4. How many ways can a man divide 7 gifts among his 3 children if the eldest is to receive 3
gifts and the others 2 each
5. Suppose a precinct consists of 150 voters, 100 of whom are women and the remaining
50 are men. Suppose a sample of 25 voters will be selected in this precinct, how many
possible
a. ordered sample with replacement are there?
b. ordered sample without replacement are there?
c. unordered sample without replacement are there?
d. ordered sample with replacement are there when 10 of the voters selected are
men?
e. ordered sample without replacement are there when 10 of the voters selected
are men?
f. ordered sample without replacement are there when at least 20 of the voters
selected are men?
JDEUSTAQUIO
92
Theorem (Complement Events): If A is an event then P(A
C
) = 1 P(A)
Thus, the sum of complementary events is 1; P(A) +P(A
c
) = 1
Theorem (Additive Rule): If A and B are any two events, then;
P(AB)= P(A)+P(B)- P(AB)
+ Corollary: If A and B are mutually exclusive, then P(AB)= P(A)+P(B)
+ Corollary: If A
1
, A
2,
A
3, ... ,
A
n
are mutually exclusive, then
+ P(A
1
A
2
A
3
A
n
)= P(A
1
) + P(A
2
) + P(A
3
) +
+P(A
n
)
Theorem: If A and Bare any two events, then using the previous two theorems;
P(AB
C
)= P(A) - P(AB)
Example: A health worker is studying the prevalence of certain diseases in a particular
community. Based on previous studies, the health worker was able to come up with the
following figures: 10% of the people in the community will contract disease A sometime during
their lifetime; 25% will contract disease B; and 5% will contract both diseases. Find the
probability that a randomly selected person from this community will contract:
a) at least one of the 2 diseases
b) disease B but not disease A
c) exactly one of the 2 diseases
Solution:
Let A = event that selected person will contract disease A
B = event that selected person will contract disease B
We can express the given percentages in terms of probabilities as follows:
P(A) = 0.10 P(B) = 0.25 P(AB) = 0.05
a) at least one of the 2 diseases; P(AB)= P(A)+P(B)- P(AB) = 0.10 + 0.25 - 0.05 = 0.30
b) disease B but not disease A; P(BA
C
)= P(B) - P(AB) = 0.25 -0.05 = 0.20
c) exactly one of the 2 diseases; P[(AB
C
) (BA
C
) = P(AB
C
) + P(BA
C
)
= [P(A) - P(AB)] + [P(B) - P(AB)] = 0.05 + 0.20 = 0.25
6.5 Probabilities of Events
JDEUSTAQUIO
93
Theorem: If A and B are any two events where P(B>0) then; P(A|B) =
()
()
There are times when we change our assignment of the probability of an event
whenever we have additional information concerning the occurrence of other events.
The original measure of the probability without using additional information
concerning the occurrence of other events is called an unconditional probability. While the
probability measure derived using the information concerning the occurrence of other events
that has already happened is called a conditional probability.
To reiterate the Conditional probability is the probability of event A occurring when we
already know that some event B has already occurred.
Example: There are 100 insurance claims that are classified according to the type of policy and
whether the claim is fraudulent or not. If a claim is selected at random,
Category
Type of Policy
Total
Fire Auto Other
Fraudulent 6 1 3 10
Non-fraudulent 14 29 47 90
Total 20 30 50 100
Find the probability of:
a) selecting a fraudulent claim given that such claim is for a fire policy
b) selecting a fraudulent claim given that such claim is for a policy that is not about fire
Solution:
Let A = event of selecting a fraudulent claim
B = event of selecting a fire policy
We can express the given data in terms of probabilities as follows:
P(A) = 10/100 = 0.10 P(B) = 20/100 = 0.20 P(AB) = 6/100 = 0.06
P(B
C
) = 80/100 = 0.80 P(AB
C
) = 4/100 = 0.04
a) P(A|B) =
()
()
b) P(A|B
C
) =
(
)
(
6.5.1 Conditional Probability
JDEUSTAQUIO
94
Exercise:
1. A movie critic feels that the probabilities that a certain movie will get an award for best
actress is 0.18, for best actor is 0.33, and at least one of these two awards is 0.40.
Suppose it was just announced that the movie won the best actor award, what is the
probability that it will win the best actress award?
2. The HR Department conducted a census to determine whether fear of flying is a major
problem in their company. The employees were first classified as flyers (flown at least
once), non-flyers likely to fly, or non-flyers not likely to fly. Then the employees were
asked whether they get anxious of flying. The results of the census were as follows:
Anxiety Level
Flight Experience
Flyers
Non-flyers
Likely to Fly
Non-flyers Not
likely to Fly
No anxiety 750 120 95
A little anxious 175 45 5
Very anxious 120 45 80
Two events A and B are said to be independent events if and only if any one of the
following conditions is satisfied:
a) P(A|B) = P(A) if P(B) > 0; or
b) P(B|A) = P(B) if P(A) > 0; or
c) P(AB) = P(A)* P(B)
Otherwise, the events are dependent.
Exercise:
1) The probability that Renzo will correctly answer the toughest question in an exam is
1/4. The probability that Sandro will correctly answer the same question is 4/5.
Assuming that the two events are independent (would not cheat), find the probability
of the following events:
a. Event that both Renzo and Sandro will answer the question correctly
b. Event that only Sandro will answer the question correctly
6.5.2 Independent Events
JDEUSTAQUIO
95
A random variable is a function whose value is a real number determined by each
element in the sample space.
2) The probability that a Japanese industry will locate in Cebu is 0.7. The probability that it
will locate in Bataan is 0.3, and the probability that it will locate in at least one of the
two provinces is 0.79. Define A = event that a Japanese Industry will locate in Cebu and
B = event that a Japanese Industry will locate in Bataan. Are A and B independent
events? Justify your answer.
3) Consider the experiment of tossing a fair die twice. Define the following event:
A = event of observing a sum of 11 dots in the two tosses
B = event of observing even number of dots in both tosses
C = event of observing 6 dots on the first toss
D = event of observing even number of dots on the first toss
Identify all pairs of independent events. Justify your claim by showing that one of the
conditions in the definition of independence is satisfied.
Remarks:
1. An uppercase letter is used to denote a random variable and its corresponding
lowercase letter is used to denote any one of its values.
2. To have an idea on the possible values that a random variable could take, it would be a
good practice to first understand the random experiment whose possible outcomes are
the elements of the sample space then define the random variable of interest. The
values that the random variable assumes would then depend on the individual sample
points in the said sample space.
7.1 Concept of a Random Variable
JDEUSTAQUIO
96
Discrete Sample Space - A sample space that contains a finite number of possibilites or
an unending sequence with as many elements as there are whole numbers.
Discrete Random Variable - A random variable defined over a discrete sample space.
Discrete Probability Distribution - A table or formula listing of all possible values of a
discete random variable along with the associated probabilities.
Example:
Consider a random experiment that requires a fair coin be tossed thrice. Then we
denote X as the resulting number of Heads. Then we have:
The Sample Points and the Number of Heads in
Three Tosses of a Fair Coin
Sample Point X Sample Point X
HHH 3 TTH 1
HHT 2 THT 1
HTH 2 HTT 1
THH 2 TTT 0
Each possible value of the random variable X represents an event that is a subset of the
sample space for a given experiment.
In the above experiment of tossing a coin thrice,
{X = 0} represents {TTT} = event of getting three tails (zero heads),
{X = 1} represents {HTT, THT, TTH} = event of getting one head in three coin tosses,
{X = 2} represents {HTH, HHT, THH} = event of getting two heads in three coin tosses,
{X = 3} represents {HHH} = event of getting three heads in three coin tosses
Exercise: Owner-Umbrella Match
A totally colorblind baggage attendant returns three umbrellas of the same design but
has different colors at random to three customers who had previously checked them. If Jason,
Charlie, and Michael, in that order, receives one of the umbrellas, list the sample points for the
possible orders returning the umbrellas and find the values m of the random variable M that
represents the number of correct matches.
7.2 Probability Distributions
7.2.1 Discrete Probablity Distribution
JDEUSTAQUIO
97
The probability mass function (PMF) of a discrete random variable, denoted by f(-), is
a function defined for any real number x as;
f(x) = P(X=x)
The values of the discrete random variable X for which f(x)>0 are called its mass points
***Note that the Discrete Probability Distribution and the Probability Mass Function are the same***
Example: Tossing a Fair Coin Thrice (Cont.)
The probability distribution table of X, the number of heads in three tosses of a fair
coin, is given by:
x 0 1 2 3
P(X=x) 1/8 3/8 3/8 1/8
Note that since X is the number of heads in three tosses of a fair coin, then P(X=x) is the
probability that the number of heads in three tosses of a fair coin is x. We then say that the
probability that 2 heads resulted in three tosses of a fair coin is 3/8.
What is the probability that there is only one head in three tosses of a fair coin?
What is the probability of getting more than one head in three tosses of a fair coin?
What is the probability of getting at least one head in three tosses of a fair coin?
How are these probabilities denoted?
Exercises:
1. Tossing A Fair Coin Thrice: Construct the probability distribution table for Y, which is
the difference of the number of tails from the number of heads.
2. Owner-Umbrella Match: Construct the probability distribution table for M, the
number of correct owner-umbrella matches
Remarks:
1. The probabilities associated with all possible values of a discrete random variable must
sum to 1.
2. If X is a discrete random variable, then P(X x) may not be the same as P(X > x).
3. Since (X>x) and (Xx) are complementary events, then P(X>x) + P(Xx) =1.
JDEUSTAQUIO
98
Continuous Sample Space - A sample space that contains a infinite number of
possibilites equal to the number of points on a line segment.
Continuous Random Variable - A random variable defined over a continuous sample
space.
Exercises:
For the following experiments, is the sample space discrete or continuous?
1. Throw a coin until a head occurs.
2. Measure the distance of a certain mode of transportation will travel over a prescribed
test course on 5 liters of gasoline.
3. Measure the length of time before a chemical reaction takes place.
4. Counting the number of brown-eyed children (out of 2) born to a heterozygous couple
for eye color.
5. Counting the number of signals correctly identified on a radar screen by a German air
traffic controller in a 30-minute time span in which 10 signals arrive.
Probability Density Function
The function with values f(x) is called a probability density function for the continuous
random variable X, if
a. the total area under its curve and above the horizontal axis is equal to 1; and
b. the area under the curve between any two ordinates x=a and x=b gives the
probability that X lies between a and b.
A continuous random variable has a probability of zero assuming exactly any of its
values. Consequently, its probability distribution cannot be given in tabular form.
Consider a random variable whose values are the heights of all the people over 21 years
old. Between any 2 values, say 163.5 and 164.5cm, theres an infinite number of height, of
which only 1 is 164cm. The probability of selecting a person at random who is 164cm tall, and
not one of the infinitely large set of heights so close to 164cm that you cannot humanly
measure the difference, is extremely remote. Thus, the probability of this event is almost equal
to zero. To get a useable probability we need to consider intervals instead of specific points.
7.2.2 Continuous Probablity Distribution
JDEUSTAQUIO
99
Example: Areas Under a Rectangle
A continuous random variable X that can assume values between 0 and 2 has a density
function given by:
() 2
a. Check if the total are under the rectangle and over the horizontal axis indeed 1, i.e. if
P(0 < X < 2) = 1
b. P(X > 1.5) = P(1.5 < X < 2) + P(X 2) = (0.5)(0.5) + 0 = 0.25
c. P(X < 0.75) = P(X < 0) + P(0 X 0.75) = 0 + (0.75)(0.5) = 0.375
d. P(X = 0.75) = 0
e. P(X 0.75) = P(X < 0.75) = 0.375
Remark:
Let X be a continuous random variable and a, b . Then, the following equities hold:
1. P(a X b) = P(X=a) + P(a < X b) = P(a < X b)
2. P(a X b) = P(a X < b) + P(X=b) = P(a X < b)
3. P(a X b) = P(X=a) + P(a < X < b) + P(X=b) = P(a < X < b)
Hence, P(a X b) = P(a X < b) = P(a < X b) = P(a < X < b)
Exercises: Areas Under a Rectangle
A continuous random variable X that can assume values between 2 and 4 has a density
function given by:
()
a. Show that P(2 < X < 4) = 1
b. Find P(X < 3.5)
c. Find P(2.5 < X < 3.5)
(Hint: Area of Trapezoid = )
JDEUSTAQUIO
100
Associated with ay random variable are constants, or parameters, that are descriptive
of the behavior of the random variable. Knowledge of the numerical values of these
parameters gives the researcher a quick insight into the nature of the variables. These
numerical values could be computed using expected values.
1. Expected Value (Mean)
The expected value, of a probability distribution is the long-run theoretical
average value of the random variable. It is the value one would expect that the
random variable would take upon repeated performance of the random experiment.
It is the value one would expect that the random variable would take upon repeated
performance of the random experiment.
In the discrete case, = E(X) =
In the continuous case, = E(X) ()
2. Variance
The variance of the probability distribution is the expected value of the squared
differences between the values that a random variable can take and its mean. It is a
measure indicating the extent of variability about the mean value of the values that
the random variable assumes.
In the discrete case, o
2
= E(X - )
2
= (
In the continuous case, o
2
= E(X - )
2
(
()
3. Standard Deviation
The standard deviation, o is the non-negative square root of the variance.
Example: Tossing a Fair Coin Thrice (Cont.)
The probability distribution table of X, the number of heads in three tosses of a fair
coin, is given by:
x 0 1 2 3
P(X=x) 1/8 3/8 3/8 1/8
The expected value of X, E(X), is; = E(X) = (0)(1/8) + (1)(3/8) + (2)(3/8) + (3)(1/8) =12/8 = 1.5
E(X) = 1.5 implies that on the average, the number of heads we will observe in three tosses of a
coin is 1.5. This makes sense since if the coin is fair, we would expect half of all the tosses to
result to heads and the other half to results to tails.
Variance; o
2
= E(X - )
2
= (
= (0-1.5)
2
(1/8) + (1-1.5)
2
(3/8) + (2-1.5)
2
(3/8)
+ (3-1.5)
2
(1/8) = 0.75
Exercise: Compute for the expected value and the variance of Y (difference of the no. tails
and heads)
7.3 Expected Values
JDEUSTAQUIO
101
A random experiment whose outcomes have been classified into two categories, labeled as
"success" and "failure", is called a Bernoulli trial.
Mathematicians have already developed many stochastic models throughout the
centuries. Several of these models are so important in theory and application, and repeatedly
used in practice. In this section, we will be presenting some of these models, together with
their means and variances.
With this experiment, the Bernoulli distribution only has 2 mass points. These are 0 and
1. We can equivalently define the Bernoulli random variable as:
{
Based on the definition of the Bernoulli random variable, we could see that it is an
example of a discrete random variable. Since, it is a discrete random variable, we could
determine its probability using the probability mass function (PMF) given by;
() {
where p = P(event of observing a success, 1)
If X follows a Bernoulli distribution, then we write X~Be(p). The Bernoulli distribution
has only 1 parameter, p. And if X~Be(p), the E(X) = p and Var(X) = p(1-p).
The Binomial experiment is a random experiment consisting of n Bernoulli trials. These
trials are strictly independent to each other and must be identical, meaning that the value of p
must be the same for each one of the Bernoulli trials.
7.4 Common Distributions
7.4.1 Bernoulli Distribution
7.4.2 Binomial Distribution
JDEUSTAQUIO
102
To reiterate a binomial experiment should satisfy the following:
a) It consists of observing the outcomes of a sequence of n trials.
b) Each trial can result in one of only 2 possible outcomes which we can label as success
or failure.
c) The probability of success, p, must be the same for each one of the n trials.
d) The trials are independent in the sense that the probability of success at a particular
trial should not be affected by the outcomes of the previous trials.
A simple random sampling with replacement to select a sample for studies that aim to estimate
the proportion is an example of a binomial experiment
Since the Binomial random variable is just an extension of the Bernoulli random
variable, we could see that it is also an example of a discrete random variable. Since, it is a
discrete random variable, we could also determine its probability using the probability mass
function (PMF) given by;
() {
.
( )
where n and p are such that n is a positive integer and p is any real number between 0 and 1.
If X follows a Binomial distribution, then we write X~Bi(n, p). The Binomial
distribution has 2 parameters, n and p. And if X~Bi(n, p), the E(X) = np and Var(X) = np(1-p).
Example: A multiple choice quiz has 15 questions, each with 4 possible answers of which only
1 is correct. Suppose a student has been abset for the past meetings and has no idea what the
quiz is all about. The student simply uses a randomization mechanism in answering the item.
a. What is the probability that the student will get a perfect score?
b. What is the probability that the student will get at least 3 correct answers?
c. What is the students expected number of correct answers?
Solution:
Define X = the number of correct answers out of the 15 items. This scenario could be
treated like a binomial experiment where there are n=15 trials and the probability of getting
the correct answer for each trial p= 1/4= 0.25.
Thus, X~Bi(n = 15, p = 0.25) and its PMF is;
() {
(
( )
JDEUSTAQUIO
103
a. P(X=15) is the probability that the student will get a perfect score.
Using the given PMF,
P(X=15) = f(15) = (
( )
As expected, there is a very small chance of getting a perfect score if a student is
simply guessing the answers.
b. P(X ) is the probability that the student will get at least 3 correct answers.
P(X ) ( ) ,() () ()-
( )
c. The students expected number of correct answers is E(X) = np = (15)(0.25) = 3.75 ~ 4
Exercise:
1. Rey is a fairly good basketball player. The chance that he can shoot from the free throw
line is as high as 0.8. If he were given 3 free throws (assuming his shots are
independent), what is the probability that he will be able to shoot the ball at least 2
times?
2. A soda company wishes to compare the taste appeal of a new formula (formula A) with
their original formula (formula B). The company got 10 people to judge the 2formulas.
Each judge is given 3 glasses in random order, two containing formula A and the other
one containing formula B. Each judge tastes all 3 and states which glass he enjoyed the
most. Suppose there is actually no distinguishable difference between the tastes of
formulas A and B.
a. Find the probability that at least 8 of the people state a preference for formula A.
b. What is the expected number of people out of the 10 who will state a preference
for formula A? What is the variance?
As discussed already on the video, the normal distribution is often times considered
as the most important distribution since it is the distribution that is related to most of the
natural phenomenon in our world. This is also why it is called the normal distribution since it is
often the assumed distribution of an experiment when the experiment is in its normal
condition. Thus this distribution would be the one that we would mostly use in the discussion
of inferential statistics, more specifically, the standard normal distribution which would also be
discussed later on.
7.4.3 The Normal Distribution
JDEUSTAQUIO
104
A continuous random variable X is said to be normally distributed if its density function
is given by:
()
} , for
Notation: If X follows the above distribution, we write X ~ N(, o
2
)
Example:
The curve below was generated for X ~ (64.4,2.4)
f
(
x
)
JDEUSTAQUIO
105
Recall:
1. How is a probability density function defined?
2. If X is a continuous random variable, how do we evaluate P(a<X<b) for ordinates a and
b?
3. What is the area under the curve generated by the density function f(x) and above the
horizontal axis?
Remarks:
1. If X ~ N(, o
2
), then E(X) = and Var(X) = o
2
.
2. The graph of the normal distribution is called the normal curve.
3. The curve is bell-shaped and symmetric about a vertical axis through the mean .
4. The normal curve approaches the horizontal axis asymptotically as we proceed in either
direction away from the mean.
5. The total area under the curve and above the horizontal axis is equal to 1.
6. The mathematical equation for the probability distribution of the normal distribution
depends upon two parameters, and o, its mean and standard deviation. Once and o
are specified, the normal curve is completely determined.
Below are the graphs of some normally distributed random variables with varying mean
and standard deviation. Try to identify the pattern of the graph by comparing each
distribution.
JDEUSTAQUIO
106
Since X is a continuous random variable, then for any real numbers a and b such that
a<b, we can get P(a<X<b) by getting the area of the shaded region below. This is true for
whatever value of and o
2
.
We saw how the normal curve is dependent upon the mean and standard deviation of
the distribution under investigation. The area under the curve between any two ordinates must
then also depend upon the values of and o.
The problem with this computation is that if there are to normally distributed random
variables, say X
1
~ N(
1
, o
1
2
) and X
2
~ N(
2
, o
2
2
) and
1
=
2
and o
1
2
= o
2
2
. Then P(a<X
1
<b) =
P(a<X
2
<b). But to be able to compare these two distributions, we could standardize them by
transforming all of the observations of any normal random variable X to a new set of
observations of a normal random variable with mean 0 and variance 1.
The distribution of a normal random variable with mean 0 and a standard deviation
equal to 1 is called a standard normal distribution.
Notation: If X follows the above distribution, we write X ~ N(0, 1)
Remarks:
If X ~ N(, o
2
), then X can be transformed into a standard normal random variable through
the following transformation:
Hence, whenever X is between the values x
1
and x
2
, the random variable Z falls between
and
. Thus, P(x
1
<X<x
2
) = P(z
1
<X<z
2
).
a b
7.4.4 The Standard Normal Distribution
JDEUSTAQUIO
107
Because now that we have learned a way to standardize a normally distributed random
variable, we can now just look on the table of areas for the standard normal distribution to get
the area (or probability) that we desire without using any integration and some other calculus
related concepts.
Example:
1. Area Under the Standard Normal Curve: Suppose Z ~ N(0, 1)
a. Find the probability
1
such that P(Z ) =
1
b. Find the probability
2
such that P(Z ) =
2
c. Find the probability
3
such that P(Z ) =
3
d. Find the probability
4
such that P(Z ) =
4
e. Find the probability
5
such that P( ) =
5
f. Find the probability
6
such that P( ) =
6
g. Find the standard score z
1
such that P(z< z
1
) = 0.50
h. Find the standard score z
2
such that P(z> z
2
) = 0.1788
i. Find the standard score z
3
such that P(-z
3
< z< z
3
) = 0.984
2. Area under a Normal curve: One of the major contributors to air pollution is
hydrocarbons emitted from the exhaust system of automobiles. The number of
hydrocarbons emitted by an automobile per mile is normally distributed with a mean of
1 gram and a standard deviation of 0.25 gram. What is the probability that a randomly
selected automobile will emit between 0.9 and 1.54 grams of hydrocarbon per mile?
Solution:
Let X = number of grams of hydrocarbons emitted by an automobile per mile, where
X ~ N(1, 0.25
2
)
( X ) .
/ ( )
( ) ( )
Thus 64% of the automobiles in operation emit between 0.90 and 1.54 grams of
hydrocarbons per mile driven.
3. Given the normally distributed random variable X with mean 18 and standard deviation
2.5, find the value of k such that P(x < k) = 0.2578
Solution:
(X ) (
X
*
(
*
but P(z<-0.65) = 0.2578.
Hence,
, solving for k gives us k = 16.375
JDEUSTAQUIO
108
Exercises:
1. The achievement scores for a college entrance examination are normally distributed
with mean 75 and standard deviation equal to 10. What fraction of the scores would one
expect to lie between 70 and 90?
2. A soda machine is regulated so that it dispenses an average of 200mL per cup. If the
amount of drink dispensed is normally distributed with a standard deviation equal to
15mL,
a. What fraction of the cups will contain more than 224 mL?
b. What is the probability that a cup contains between 191 mL and 209 mL?
c. How many cups will likely overflow if 230mL cups are used for the next 1000
drinks?
d. Below what value do we get the smallest 25% of the drinks?
Knowledge of sampling distributions of statistics is important to understand the
statistical methods under statistical inference. Under statistical inference, the interest lies in
being able to say something about a parameter with an unknown value. Recall that we can
only determine the true value of a parameter after getting pertinent information from ALL
units in the population. But sometimes we resort to getting just partial information from the
population by taking a random sample of units from which measurements will be obtained.
This partial information will then be the basis of conclusions regarding the unknown
parameter.
Consider the experiment of getting a random sample from a population with unknown
mean.
Question:
1. Will the mean of the sample measurements you obtained be exactly equal to the
unknown population mean?
2. If different samples of the same size are obtained from the same population, will the
sample means of measurements from the different samples be the same?
JDEUSTAQUIO
109
Example:
Consider the random experiment of getting a random sample of size two with
replacement from a population of units with measurements {2, 3, 4}. (Note that the population
mean of measurements is = 3 while the population variance is o
2
= 2/3.
The sample points in O are all the possible random sample of size 2 taken with
replacement from the population with measurements {2, 3, 4}.
It is apparent that the value of the sample
mean varies across the different possible sample
of size 2. Variability in the values sample mean
is visibly present. It can be further observed that
not all the sample means are equal to the
population mean of 3. We can then say that the
mean of the random sample is not necessarily
equal to the population mean.
On the average, what is the value of the
sample mean? What is the variance of the
sample mean?
Note the E(), the average sample means, is 3, which is equal to = 3. Also, Var(), the
variance of the sample mean is 1/3=(2/3)/2=o
2
/n where n is the sample size.
Another example for the sampling distribution is this;
An organization consists of 6 qualified voters: A
1
, A
2
, A
3
, A
4
, A
5
, and A
6
. Renzo and
Sandro are 2 candidates vying for the same position. A
1
, A
2
, A
3
, and A
4
are already decided to
vote for Renzo while A
5
and A
6
will vote for Sandro. Suppose we select a sample of size 2 using
SRSWOR. Construct the sampling distribution of .
where X
i
= {
for i = 1, 2, 3.
(Note that can also be viewed in this example as a sample proportion)
Solution:
Since n = 2, then there will be (
) = 15 possible samples.
JDEUSTAQUIO
110
Sample {X
1
, X
2
}
Sample {X
1
, X
2
}
{A
1
, A
2
} {1, 1} 1 {A
2
, A
6
} {1, 0}
{A
1
, A
3
} {1, 1} 1 {A
3
, A
4
} {1, 1} 1
{A
1
, A
4
} {1, 1} 1 {A
3
, A
5
} {1, 0}
{A
1
, A
5
} {1, 0} {A
3
, A
6
} {1, 0}
{A
1
, A
6
} {1, 0} {A
4
, A
5
} {1, 0}
{A
2
, A
3
} {1, 1} 1 {A
4
, A
6
} {1, 0}
{A
2
, A
3
} {1, 1} 1 {A
5
, A
6
} {0, 0} 0
{A
2
, A
5
} {1, 0}
All of these 15 possible samples have the same chance of selection because we select
the sample using SRSWOR. We then use the classical definition of probability to construct the
sampling distribution of X
.
Sampling Distribution of
0 1/2 1
f(
) 1/15 8/15 6/15
Exercise:
Consider the random experiment of taking a random sample of size n without
replacement from a population with measurement {2, 3, 4}
1. What are the sample points in O?
2. What are the values that takes on?
3. Verify that E() = = 3 and Var() =
/ = 1/6.
Remarks:
1. In the experiment of taking a random sample from a population, it can be seen that the
sample mean is a function taking on numerical values which depend on the random
sample taken. And the different possible random samples are the sample points in the
sample space. The sample mean is then a random variable. In fact, every statistic is a
random variable.
JDEUSTAQUIO
111
2. As a random variable, a statistic has a probability distribution. The probability
distribution of a statistic is called its sampling distribution.
3. Consider the random experiment of taking a random sample of size n with replacement
from a population of size N. Then, E()= and Var() =o
2
/n.
4. Consider the random experiment of taking a random sample of size n without
replacement from a population of size N. Then, E()= and Var() =
/ is called
the finite population correction factor.
5. () is the standard deviation of the sampling distribution of the sample mean . In
general, the standard deviation of the sampling distribution of a statistic is called the
standard error of the statistic.
6. If selection of a random sample is done without replacement from a large population, it
is as if the selection is done with replacement since as n becomes large, .
/ .
Suppose that a random sample (X
1
, , X
n
) of size n taken from a population of normally
distributed measurements with population mean E(X)= and variance Var(X)=o
2
. Then E()=
and Var()= o
2
/n.
If the sample size n is sufficiently large, approximately ~ N(,o
2
/n). Hence,
as n, Z = ( - )/(o/ ) approximately ~ N(0, 1).
Remarks:
1. The Central Limit Theorem tells us that if a sufficiently large random sample is taken
from a large or infinite population with mean and variance o
2
, then regardless of the
distribution of the measurements in the population , the sample mean will
approximately follow a Normal distribution with mean and variance o
2
/n.
2. Since approximately ~ N(,o
2
/n) and every Normally distributed random variable can
be transformed to a standard normal random variable. Then we could just use the Table
of Areas under the Standard Normal Curve in getting the probabilities instead of
performing integral calculus.
3. The normal approximation in the theorem will be good only if the population is not too
different from the normal distribution.
8.1 The Central Limit Theorem (CLT)
JDEUSTAQUIO
112
Example:
1. A hardware store receives a consignment of bolts whose diameter has a normal
distribution with a mean diameter of 1.2 inches and a standard deviation of 0.02 inch.
The consignment will be considered substandard and returned if the mean diameter of
a sample of 120 bolts is less than 1.197 inches or greater than 1.203 inches. Find the
probability that the consignment will not be returned.
Solution:
Let X = diameter of a bolt in a consignment received by a hardware store
Then X ~ N(1.2, 0.02
2
) n = 120 ~ N(1.2, 0.02
2
/120)
P(consignment will not be returned) = P( )
= P
( ) ( )
= 1 2(0.0505) = 1 0.1010 = 0.899
2. A forester for the DENR studying the effects of fertilization on certain species of
trees in the South is interested in estimating the average basal area of three trees. In
studying basal areas of similar trees for many years, he knows that these
measurements have a standard deviation of approximately 4 square inches. If the
forester samples n = 30 trees, find the probability that the sample mean will be within 2
square inches of the population mean.
Solution:
Let A = basal area (in square inches) of a tree of certain species
n = 30
~ N(, 4
2
/30)
(
) (
) (
)
(
) ( ) ()
One of the statistics of interest in many settings is the sample proportion. A number
of random variables are dichotomous (yields only one of the two categories as response).
The two outcomes of a dichotomous variable may be generically labeled as
success and failure. The outcome of interest is usually referred to as success.
8.2 Sampling Distribution of Proportion
JDEUSTAQUIO
113
Thus, we have the sample proportion,
n
which is the proportion for success
in n units and the population proportion,
, which is the proportion of success in
the population. Then E() = P and Var() =
()
n
.
And based on the Central Limit Theorem, if n is quite large and the population is large
or infinite then:
.
()
/ and
()
( )
Example:
Mr. Reyes believes that he can win a city election if in a survey he wishes to conduct prior to the
election; at least 55% of the randomly selected voters in the city are in favor of him. He also
believes that about 50% of the citys voters favor him. If 100 voters were randomly selected
and asked their preference, what is the probability that Mr. Reyes receives at least 55% of the
votes?
Solution:
Let
i = 1, 2, ., 100
The outcome of interest is favoring Mr. Reyes and a voter in the city is considered a trial.
The voters were given the same options and were polled in a similar manner. It is assumed that
the preference of one voter does not affect another voters choice. We must approximate
P( ), where
n
and when P = 0.50. Now, E() = P= 0.50 and the Var() =
()
n
()
. The sample size, 100 is sufficiently large to satisfy the conditions
of the Central Limit Theorem. Thus, approximately ~ N(0.5, 0.0025).
hence, ( ) (
()
()
) ( ) ( )
( )
JDEUSTAQUIO
114
Most of the time we are not fortunate enough to know the variance of the population
from which we select our random samples. For samples of size , a good estimate of o
2
is
provided by calculating S
2
. What then happens to the distribution of z-values in the CLT if we
replace o
2
by S
2
?
As long as S
2
is a good estimate of o
2
and does not vary much from sample to
sample, which is usually the case for n 30, the values (x -) / (/n) are still approximately
standard normal variables and the CLT is still valid.
If the sample size is small (n<30), the values of S
2
fluctuate considerably from sample
to sample and the distribution of the values (x -) / (S/n) is no longer a standard normal
distribution. We are now dealing with the distribution of a statistic that we shall call t, whose
values are given by
.
If and S
2
are the mean and variance respectively, of a random sample of size n
taken from a population which is normally distributed with mean and variance o
2
, then;
X
is a random variable having the t-distribution with v = n-1 degrees of freedom.
Comparison between the t-distribution and the Standard Normal Distribution
1. Both are symmetric about zero.
2. Both are bell-shaped but the t-distribution is more variable.
i. t-values depend on the fluctuation of two quantities: and S
2
.
ii. z-values depend only on the changes in from sample to sample.
3. When the sample size is large, i.e. n 30, the t-distribution can be well
approximated by the standard normal distribution.
Areas Under the Curve
Notation
T~ t
v
where v=n-1, n is the sample size
t
= is the t-score leaving an area of in the right tail of the t-distribution.
That is, if T~ t
v
, then P(T>t
) = . By symmetry of the t-distribution about 0, t
=- t
1-
Example:
1. Find t
0.99
when v=10 on the table of areas under the t-distribution.
2. Find k such that P(k<T<2.807) = 0.945 when T~t
23
.
8.3 The Student's t-distribution
JDEUSTAQUIO
115
Estimation and Hypothesis Testing
9.1 Estimation for Single Population
2.2 .1 Data Collection Methods
Concepts Related to Estimation
+ Estimator an estimator is any statistic whose value is used to estimate an
unknown parameter.
+ Estimate a realized value of an estimator
+ Unbiased Estimator An estimator is said to be unbiased if the average of the
estimates it produces under repeated sampling is equal to the true value of the
parameter being estimated.
+ Interval Estimator An interval estimator of a population parameter is a rule that
tells us how to calculate two numbers based on sample data, forming an interval
within which the parameter is expected to lie.
+ Interval Estimate or Confidence Interval An interval estimate is a realized
interval of values of an interval estimator. The endpoints of a confidence interval are
the lower and upper confidence limits.
+ Confidence Coefficient The confidence coefficient is the probability that the
interval estimator encloses the true value of the parameter.
Examples:
1. The sample mean, is an estimator of the population mean, .
Consider the following problem:
An electrical firm manufactures light bulbs that have a length of life that is
normally distributed, with a standard deviation of 40 hours. We are interested in
estimating the mean length of life of all light bulbs produced by this firm. A random
sample of 25 bulbs has a mean life of 780 hours.
JDEUSTAQUIO
116
In the above example, 780 hours is the point estimate of the true mean length of
life of all light bulbs produced by this firm.
2. Let
{
. Recall that P is the
probability of success. An estimator of P is the sample proportion,
, the
proportion of success in the sample.
Suppose the Math department is interested in estimating the true proportion of
all students who pass Math 17 on the first take. In a random sample of 200 students who
enrolled in Math 17, 138 passed on their first take.
The sample proportion 138/200 of students who passed Math 17 on their first
take is the point estimate of the true proportion of all students who pass Math 17 on first
take.
Remarks:
1. An estimator is not expected to estimate the population parameter without error. We
do not expect to estimate exactly, but we certainly hope that it is not too far off.
2. An estimator, being a statistic (and hence a random variable) has variability. Note that
point estimates may vary for different possible samples. Providing the point estimate
for a sample will not reflect the extent of the variability of the estimates that may be
obtained in estimating the parameter of interest. In other words, we do not have a
gauge of how near or how far the estimates are from the parameter. We then cannot
assess the precision of our estimation results. Interval estimation, however, takes into
account this extent of variability among the estimates. Hence, we can have an idea of
the proximity of our estimate from the true value.
Derivation of the Interval Estimator for the Mean, (when o is known):
(
)
(
) (
*
(
* (
*
(
*
Hence the probability that is enclosed in .
/ is 1-
JDEUSTAQUIO
117
Interpretation of (1-)100% Confidence Interval:
If we take repeated samples of size n and if for each of these samples, we compute the (1-
)100% confidence interval, then (1-)100% of the resulting confidence intervals will
contain the unknown value of the parameter.
A good confidence interval is one that is as narrow as possible and has a large
confidence coefficient, near 1. The narrower the interval, the more exactly we have located the
parameter; whereas the larger the confidence coefficient, the more confidence we have that a
particular interval encloses the true value of the parameter. However, for a fixed sample size,
as the confidence coefficient increases, the length of the interval also increases.
Recall the Central Limit Theorem and the t-distribution and the remarks regarding their
use. A (1-)100% confidence interval for is given by:
a. o known: .
/
b. o unknown, n < 30: .
/ where t
/2
is the t-
value with v=n-1 degrees of freedom.
c. o unknown, n 30: .
/
Remarks:
1. The above formulas hold strictly for random samples from a normal distribution.
However, they provide good approximate (1-)100% confidence intervals when the
distribution is not normal provided the sample size is large.
2. The derivation of the (1-)100% confidence interval estimator for when o is known
has already been derived.
9.1.1 Estimating the Population Mean
JDEUSTAQUIO
118
Example
An electrical firm manufactures light bulbs that have length of life that is normally
distributed, with a standard deviation of 40 hours. If a random sample of 25 bulbs has a mean
life of 780 hours, find a 95% confidence interval for the population mean of all bulbs produced
by this firm.
Solution:
Let X = length of life of a light bulb (in hours) manufactured by an electrical firm: X ~ N(,40
2
).
Why is there no value of in N(,40
2
)?
Given: = 780 n =25 1- = 0.95 = 0.05
= 0.025
= z
0.025
= 1.96
A (1-)100% confidence interval estimate for is given by .
/.
A 95% confidence interval for the true mean length of light bulb (in hours) manufactured by
a certain electrical firm is
( ( )
( )
*
= (764.32, 795.68)
Based on sample results, we are 95% confident that the light bulbs manufactured by a
certain electrical firm last, on the average, at least 764.32 hours and at most 795.68 hours.
X is normally
distributed
o
2
is known?
Formula a n > 30
Formula c Formula b
n >30
o
2
is known?
Formula a Formula c
Nonparametric
Methods
YES
YES
YES
YES
YES
NO
NO
NO
NO
NO
JDEUSTAQUIO
119
Exercises:
1. Regular consumption of presweetened cereals contribute to tooth decay, heart disease,
and other degenerative diseases, according to a study by Dr. M Albreight of the National
Institute of Health and Dr. D. Solomon, Professor of Nutrition and Dietetics at the
University of London. In a random sample of 20 similar servings of Alpha Bits, the mean
sugar content was 1.13 grams with a standard deviation of 2.45 grams. Assuming that the
sugar content is normally distributed, construct a 95% confidence for the mean sugar
content for single serving of Alpha Bits.
2. A random sample of 100 automobile owner shows that an automobile is driven on the
average 23,500 kilometers per year, in the state of Virginia, with a standard deviation of
3900km. Construct a 99% confidence interval for the average number of miles an
automobile is driven annually in Virginia.
An approximate (1-)100% confidence interval for p is given by;
(
)
Let X
Given:
1- = 0.95 = 0.05
= 0.025
= z
0.025
= 1.96
A 95% confidence interval for the true prop. of students who pass Math on their first take is
(
()()
()()
)
= (0.62590170, 0.754098293)
Based on sample results, we are 95% confident that the proportion of students who
pass Math on their first take is at least 0.63 and at most 0.75.
9.1.2 Estimating the Population Proportion
JDEUSTAQUIO
120
9.2 Sample Size Determination for Estimation
In previous sections, the steps in constructing a confidence interval in estimating an
unknown parameter ( or p) involves
1. Getting a random sample of size n from the population.
2. Computing the point estimate based on the sample.
3. Choosing the appropriate formula based on the problem (i.e. is the population
variance known? Is X normally distributed? Or is X
i
defined as a binary variable taking
on 1 for success or 0 for failure for the i
th
trial,i= 1, 2, , n? Is the sample size
large? And so on) to calculate the (1-)100% confidence interval.
4. Interpreting the resulting (1-)100% confidence interval.
Suppose that the population variance o
2
is known and we state, say, that we are (1-
)100% confident that is within the interval .
/.
Note that is going to be within the (1-)100% confidence interval if and only if the
error, e of estimating using is at most
. Then, saying we are (1-)100% confident
that is within the interval .
/ is equivalent to saying that We are
(1-)100% confident that the error e of estimating using cannot exceed
.
Now suppose a researcher desires to estimate using with (1-)100% confidence and
wishes that the random sample of size n that he takes will give an estimate which is within a
specified value e of . That is, he wishes to be (1-)100% confident that the random sample
that he would take will give a realized value of such that the error of estimating will not
exceed a specified value e. How large a sample is necessary should the researcher take?
In such scenario, we dont intend to construct (1-)100% confidence for from a
sample that is already taken from the population. In fact, the sample has not been taken yet
and we are about to determine the sample size first. What we have are the following:
1. The population standard deviation o is known.
2. The confidence coefficient (1-) is known, i.e. the researcher sets how confident he
wishes to be in estimating using .
3. The maximum amount of error
in estimating using is specified.
9.2.1 Sample Size for Estimating
JDEUSTAQUIO
121
Assuming (1), the objective then is to determine the sample size n that satisfies (2) and
(3). But since z
/2
, o and e are known, then the formula
will give .
.
So to interpret, We can be (1-)100% confident that getting a random sample of
.
will provide an estimate which is at most a specified amount e away from the value
of .
Note that the larger the sample size is, the smaller the standard error
of the sample
mean is. The possible values of the sample mean fluctuate less then as the sample size is
increased. But the sample size cannot be increased at the whim of the researcher since each
additional unit in the sample entails costs and in whatever study, the research design is
influenced by the budgetary constraints. The selection of the sample size is then a compromise
between the extent of precision of results desired and the financial considerations.
When the computed sample size is not an integer, we round it up to the nearest integer.
Example
An electrical firm manufactures light bulbs that have a length of life that is
approximately normally distributed, with a standard deviation of 40 hours. How large a sample
is needed if we wish to be 95% confident that the sample mean will be within 10 hours of the
true mean?
Solution
Let L = length of life (in hours) of a light bulb manufactured by a certain electrical firm
L approximately ~ N(, o
2
)
We can be (1-)100% confident that getting a random sample of .
will
provide an estimate which is at most a specified amount e away from the value of .
Given: o =40 e =10 1- = 0.95 = 0.05
= 0.025
= z
0.025
= 1.96
Then .
() ()
()
Therefore, we could be 95% confident that taking a random sample of 62 light bulbs
will provide an estimate which is within 10 hours of the true mean length of life of light bulbs.
JDEUSTAQUIO
122
Let.
{
. Recall that P is the
probability of success. An estimator of P is the sample proportion,
, the proportion of
success in the sample. Recall that E() = P and Var() =
()
n
.
Note that the standard error of involves P, the parameter of interest. Hence, in
constructing a (1-)100% confidence interval for P, the confidence limits are supposedly
()
and
()
, which are not independent of P, the parameter that is
supposedly being estimated. However, for large samples, little error is introduced in
substituting the statistic for the true proportion P. Therefore, an approximate (1-)100%
confidence interval for P is given by (
()
()
).
Similar to how we determine the sample size in estimating using , it can be
reasoned out that saying we are (1-)100% confident that P is within the interval
(
()
()
) is the same as saying we are (1-)100% confident that
the error e of estimating P using cannot exceed
()
.
Therefore, a researcher could be (1-)100% confident that getting a random sample of
()
will provide an estimate which is at most a specified amount e away from the
value of P.
The formula using
()
is used when an approximate value for p is available.
However in some cases when we do not have an approximation of P to start with, we might as
well work with the largest sample size that we could obtain given the degree of confidence and
the extent of error we are willing to commit. Such maximum sample size is attained by using
P= Q = 0.5. This will give us the conservative formula
.
Example: A chemist has prepared a product designed to kill 60% of a particular type of insect.
How large a sample should be used if he desires to be 95% confident that he is 0.02 of the true
fraction of insects killed?
9.2.2 Sample Size for Estimating P
JDEUSTAQUIO
123
9.3 Hypothesis Testing Procedures
Solution:
Let X = number of insects of a particular type killed by the new product, X ~Bi (n, p).
We can be (1-)100% confident that getting a random sample of
()
will provide an
estimate which is at most a specified amount e away from the value of p.
Given: P ~ 0.60 1- P ~ 0.40 e =0.02 1- = 0.95 = 0.05
= 0.025
= z
0.025
= 1.96
Then .
(
) ()()
/
Therefore, we could be 95% confident that taking a random sample of 2305 insects of a
particular type will provide an estimate which is within 0.02 of the true fraction of insects killed.
Exercise: What if an approximation for the true fraction of insects killed by the new product is
not available? How large a sample should be used if the chemist desires to be 95% confident
that he is 0.02 of the true fraction of insects killed?
Often, the problem confronting us is not so much the estimation of a parameter as
discussed in the previous section, but rather the formulation of a set of rules that lead to a
decision culminating in the non-rejection or rejection of some statement or hypothesis about
the population.
Examples:
1. A medical researcher might be required to decide on the basis of experimental evidence
whether a certain vaccine is superior to one presently being marketed.
2. An engineer might have to decide on the basis of sample data whether there is a
difference between the accuracy of kinds of gauges.
3. A sociologist might wish to collect appropriate data to enable her to decide whether the
blood type and the eye color of an individual are independent variables.
The procedures for establishing a set of rules that lead to the rejection or non-rejection of
these kinds of statements comprise a major area of statistical inference called Hypothesis
Testing.
The truth or falsity of a statistical hypothesis is never known with certainty unless we
examine the entire population. This, of course, would be impractical in most situations. Instead
we take a random sample from the population of interest and use the information contained in
this sample to decide whether the hypothesis is likely to be true or false.
JDEUSTAQUIO
124
Concepts Related to Estimation
1. Statistical Hypothesis is an assertion or conjecture concerning one or more
populations.
2. Null Hypothesis (H
o
) is the hypothesis that is being tested; it represents what the
experimenter doubts to be true.
3. Alternative Hypothesis (H
a
) is the operational statement of the theory that the
experimenter believes to be true and wishes to prove. It is the contradiction of the null
hypothesis.
4. One-tailed Test of Hypothesis is a test where the alternative hypothesis specifies a
one-directional difference for the parameter of interest.
Example: H
o
: =14 vs. H
a
: > 14 , H
o
: =14 vs. H
a
: < 14
5. Two-tailed Test of Hypothesis is a test where the alternative hypothesis does not
specify a directional difference for the parameter of interest.
Example: Ho: = 14 vs. Ha: = 14
6. Test Statistic is a statistic whose value is calculated from sample measurements and
on which the statistical decision will be based.
7. Critical Region or Rejection Region is the set of values of the test statistic for which
the null hypothesis will be rejected.
8. Acceptance Region is the set of values of the test statistic for which the null
hypothesis will not be rejected.
9. Critical Value the value of the test statistic separating the acceptance and rejection
regions.
10. Type I Error is the error made by rejecting the null hypothesis when it is true.
11. Type II Error is the error made by accepting (not rejecting) the null hypothesis when it
is false.
12. Level of Significance, is the maximum probability of Type I error the researcher is
willing to commit.
Decision
State of Nature
Null Hypothesis is True Null Hypothesis is False
Null Hypothesis is Rejected
Incorrect Decision (Type I
Error committed)
Correct Decision
Null Hypothesis is Not Rejected Correct Decision
Incorrect Decision (Type II
Error committed)
JDEUSTAQUIO
125
Steps in Hypothesis Testing
1. State the null hypothesis (H
o
) and the alternative hypothesis (H
a
).
2. Choose the level of Significance .
3. Select the appropriate test statistic and establish the critical region.
4. Collect the data and compute the value for the test statistic from the
sample data.
5. Make the decision. Reject H
o
if the value of the test statistic belongs in
the critical region. Otherwise, do not reject H
o
H
o
Test Statistic H
a
Critical Region
a. o known
=
o
<
o
>
o
=
o
z < -z
z > z
|z| > z
/2
b. o unknown
=
o
v = n-1
<
o
>
o
=
o
t < -t
t > t
|t| > t
/2
Remarks:
1. The above tests are exact -level tests for samples from a normal distribution.
However, they provide good approximate -level test when the distribution is not
normal provided that the sample size is large, i.e. n > 30.
2. If o is unknown and n > 30, use the test in (a) replacing the test statistic by
Problem: (Automobile Example)
It is claimed that an automobile is drawn on the average less than 25,000 km per year.
To test the claim, a random sample of 100 automobile owners is asked to keep a record of the
kilometers they travel. Would you agree with this claim if the random sample showed an
average of 23,500 km and a standard deviation of 3,900 km? Use a 0.01 level of significance.
9.3.1 The Hypothesis Testing Process
JDEUSTAQUIO
126
Solution:
Let X = number of kilometers an automobile is driven in a year
1. State the null hypothesis (H
o
) and the alternative hypothesis (H
a
).
Null Hypothesis hypothesis being tested, represents what the experimenter doubts
to be true.
Alternative Hypothesis operational statement of the theory that the experimenter
believes to be true and wishes to prove; contradiction of H
O
The null and alternative hypotheses are statistical hypotheses.
H
o
: = 25,000 vs. H
A
: < 25,000
2. Choose the level of significance .
= 0.01
3. Select the appropriate test statistic and establish the critical region.
Since o is unknown and n>30, choose to use the test statistic and the critical region
specified in remark (2).
The form of critical region would depend on the form of the alternative hypothesis.
Since the alternative hypothesis is one tailed and has the form H
A
: <
o
, then the critical
region takes the form Z < -z
.
Critical Region: Z < -z
= -z
0.01
= -2.326
This means that if the computed test statistic Z is less than -2.326, then Ho is
rejected at 0.01 level of significance.
The shaded region is the critical region.
The unshaded region is the acceptance region.
The value which separates the rejection region and the acceptance region is -2.326, the
critical value.
JDEUSTAQUIO
127
4. Collect the data and compute the value of the test statistic from the sample data.
Given: = 23,500 s = 3,900 n = 100
5. Make the decision. Reject H
o
if the value of the test statistic belongs in the critical
region. Otherwise, do not reject H
o
.
Since -3.846153846 < -2.326, we reject H
o
at 1% level of significance.
Reminders:
+ Rejection of a hypothesis by a statistical test does not mean that the hypothesis is false;
and in the same manner, its non-rejection by the test does not imply that it is true.
+ Rejecting the hypothesis only means that: given that the hypothesis is true, the observed
sample has a very small probability of occurrence. This is taken as evidence of the falsity
of the hypothesis.
Conclusion: At o.01 level of significance, based on the sample results, there is sufficient
evidence to say that the true average number of kilometers an automobile is driven per year is
less than 25,000 kilometers.
JDEUSTAQUIO
128
Decisions and States of Nature
1. A correct decision has been made when
+ The null hypothesis is not rejected when it is true
+ The null hypothesis is rejected when it is false
2. An incorrect decision has been made when
+ The null hypothesis is rejected when in fact, it is true. (Type I error)
+ The null hypothesis is not rejected when in fact, it is false. (Type II error)
Notations:
= probability of Type II error
= probability of not rejecting the null hypothesis when in fact it is false
1- = power of the test
= probability of rejecting the null hypothesis when in fact it is false
= level of significance
= maximum probability of Type I error the researcher is willing to commit
= maximum probability specified by the researcher of rejecting the null hypothesis
when in fact it is true.
Be aware that in fixing , the experimenter is controlling Type I error probabilities, not
the Type II error. If this approach is taken, the experimenter should specify the H
o
and H
a
so
that it is most important to control the Type I error probability. For example, suppose an
experimenter expects the data to support a particular hypothesis but he does not wish to
make the assertion unless the data do give convincing support. The test can be set up so
that the alternative hypothesis is the one that he expects the data to support, and hopes to
prove. By using a small , the experimenter is guarding against saying the data support H
a
when it is false.
Note: The level of significance is the area of the critical region. The level of significance is
specified prior to the hypothesis testing procedure and provides an objective way of
assessing when to reject the null hypothesis based on the sample results. The level of
significance is used to assess how likely (or unlikely) is it to get a random sample such as
what has been observed if the null hypothesis is true.
Question: When does one become stricter in avoiding the mistake of rejecting the null
hypothesis when it is true: when is decreased or increased?
Interpretation of the Level of Significance :
If we repeatedly take random sample of size n, and for each of these samples, the
hypothesis testing procedure is performed using the level of significance , then at most
*100% of all the decisions you make will result in rejecting the null hypothesis, when in fact
it is true.
JDEUSTAQUIO
129
Remarks:
1. The null hypothesis H
o
will always be stated using the equality sign so as to specify a
single value. In this way, the probability of committing a Type I error can be controlled.
Whether one sets up a one-tailed or a two-tailed test will depend on the conclusion to
be drawn if H
o
is rejected. The location of the critical region can only be determined
only after the H
a
has been stated.
2. Note the similarities between the scenarios of when to use the three available formulas
for estimating the population mean in the previous section and the scenarios of when
to use the test statistics and critical regions available for testing a hypothesis on the
population mean. The flowchart used in choosing the test statistic and establishing the
critical region in testing a hypothesis on the population mean.
Example A: Test H
o
: = 50 vs. H
a
: = 50, if a random sample of 16 subjects had mean 48 and
standard deviation of 5.8 at 0.05 level of significance. Assume that the sample
was taken from a Normal population with standard deviation of 6.
Solution:
i. Hypotheses: H
O
: = 50 vs. H
A
: = 50
ii. Level of Significance: = 0.05
iii. Test Statistic: Since the random sample was taken from a population of
measurements that follow a Normal distribution and the population standard
deviation o is known (o=6), we use the test statistic:
n
iv. Critical Region: |Z| > z
/2
= z
0.05 /2
= z
0.025
Z > z
0.025
or Z < -z
0.025
Z > 1.96
v. Computation: Given: = 48 o = 6 s = 5.8 n = 16 ;
JDEUSTAQUIO
130
vi. Decision: Since |Z| = |-1.33| 1.96, we do not reject H
O
at 5% level of significance.
vii. Conclusion: At 5% level of significance, there is not enough evidence to say that the
true mean is significantly different from 50.
Exercises: (Dietary Goal Problem) According to Dietary Goals for the United States (1977), high
sodium intake may be related to ulcers, stomach cancer, and migraine headaches.
The human requirement for salt is only 230mg per day, which is surpassed in most
single servings of ready-to-eat cereals. A random sample of 20 similar servings of
Special K had mean sodium content of 244mg of sodium and standard deviation of
24.5mg. Is there sufficient evidence to believe that the average sodium content for
single servings of Special K exceeds the human requirement for salt at =0.025? at
=0.10? Assume normality.
Remarks: For the same data set, as increases, the size of the critical region also increases.
Consequently, if H
o
is rejected at -level of significance, then H
o
will also be rejected
at a higher level of significance. For example, if H
o
is rejected at =0.05 then testing
at = 0.1 will also lead to the rejection of H
o
. However, H
o
will not necessarily be
rejected at = 0.01.
Example: (Automobile Example Continued)
For = 0.01, the critical region is Z < -2.326.
Question: Does the change in the level of significance entail a change in the value of test
statistic?
For = 0.05, the critical region is Z < -1.96.
JDEUSTAQUIO
131
Since H
o
: = 25,000 is rejected at 0.01 level of significance, it will also be rejected at 0.025
level of significance.
The p-value is the smallest value of for which H
o
will be rejected based on sample
information. It is the probability under H
o
of obtaining a sample as extreme as or more extreme
than the one that was observed
If p-value , then H
o
is rejected, otherwise, H
o
is not rejected.
Examples:
(Automobile Example) Recall that Z = -3.846153846. Since we have a one-tailed test
and the H
o
is rejected for values of Z such that Z<-z
0.01
, we consider the scenario of getting
a random sample as more extreme than observed if it gives us a computed value of
Z < -3.846153846. Hence, the p-value is given by;
p-value = P(Z -3.846153846) 0.
Since the p-value, which is approximately equal to 0, is less than 0.01 level of
significance.
9.3.2 Using the P-value in Tests of Hypothesis
JDEUSTAQUIO
132
(Example A) Note that Z = -1.333. Since we have two-tailed test and the H
o
is rejected
for values of Z such that |Z| > z
0.025
, we consider the scenario of getting a random sample
as more extreme than observed if it gives us a computed value of Z such that Z < -1.333 or
Z > 1.333, i.e., |Z| > 1.333. Hence, the p-value is given by;
p-value = P( |Z| > 1.333)
= P({Z < -1.333} {Z > 1.333})
= P({Z < -1.333}) + P({Z > 1.333})
= 2*P({Z < -1.333})
= 2*(0.0918)
p-value = 0.1836
Since 0.1836 is not 0.05, H
o
is not rejected at 0.05 level of significance.
Exercise: Compute for the p-value of the Dietary Goal Problem.
Consider the problem of testing the hypothesis that the proportion of successes in a
binomial experiment equals some specified value.
Let X be the number of successes in n trials.
If the unknown proportion P is not expected to be too close to 0 or 1 and n is large, a
large sample approximation is given by:
H
o
Test Statistic H
a
Critical Region
P = p
o
P < p
o
P > p
o
P = p
o
z < -z
z > z
|z| > z
/2
Example: A commonly prescribed drug on the market for relieving nervous tension is believed
to be only 60% effective. Experimental results with a new drug administered to a random
sample of 100 adults who were suffering from nervous tension showed that 70 received relief.
Is this sufficient evidence to conclude that the new drug is superior to the one commonly
prescribed? Use a 0.05 level of significance.
9.3.3 Test of Hypothesis for the Population Proportion
JDEUSTAQUIO
133
Solution:
Let
Then X = number of adults (out of 100) who received relief after taking the new drug
i. Hypotheses: H
O
: P = 0.60 vs. H
A
: P > 0.60
ii. Level of Significance: = 0.05
iii. Test Statistic:
iv. Critical Region: Z > z
= z
0.05
= 1.645 Z > 1.645
v. Computation: Given: x = 70 p
o
= 0.60 q
o
= 1-0.60 = 0.40 n = 100 ;
()()
()()()
vi. Decision: Since Z = 2.041241452 > 1.645, we reject H
O
at 5% level of significance.
vii. Conclusion: At 5% level of significance, based on sample results, there is sufficient
evidence to say that the new drug is superior to the one commonly prescribed.
Exercise: Swain vs. Alabama Case
In 1965, the U.S. Supreme Court decided the case of Swain vs. Alabama. Swain, a black
man, was convicted in Talladega County, Alabama, of raping a white woman. He was
sentenced to death. The case was appealed to the Supreme Court on the grounds that there
were no blacks on the jury; Moreover, no black within the memory of persons now living has
ever served on any petit jury in any civil or criminal case tried in Talladega County, Alabama.
The Supreme Court denied the appeal, on the following grounds. As provided by
Alabama law, the jury was selected from a panel of about 100 persons. There were 8 blacks on
the panel (They did not serve on the jury because they were struck, or removed, through a
maneuver called peremptory challenges by the prosecution. Such challenges were until quite
recently constitutionally protected.). The Supreme Court ruled that the presence of 8 blacks on
the panel showed The overall percentage disparity has been small and reflects no studied
attempt to include or exclude a specified a number of blacks.
At that time in Alabama, only men over the age of 21 were eligible for jury duty. There
were 16,000 such men in Talladega County, of whom about 26% were black.
If 100 people were chosen by simple random sampling from this population, what is the
chance that 8% or fewer would be black?
What do you conclude about the Supreme Courts opinion?
JDEUSTAQUIO
134
Estimation and Hypothesis Testing
10.1 Estimation Procedures Involving Two
Populations
In this chapter, the basic concepts learned in estimation and hypothesis testing are
applied in the scenario wherein the interest lies in the comparison between two population
means or two population proportions. This is quite useful especially when we would like to
conclude which among two methods is better or which among two groups obtained higher
scores. If the comparison is based on sample results, we will be able to readily see which
among the sample mean values is higher, if there exists any difference at all between the two
statistics.
But an important question to ask is if such difference exists by chance in the samples
that have been drawn. Perhaps, if information was taken from all units in the two populations
under consideration, results would show that there is no difference at all in the mean values.
How confident can we then be of generalizing results regarding the difference of two means or
proportions based on sample information to the populations of interest? When can we then
say that we have sufficient evidence based on sample results that the two population means or
proportions are significantly different from each other?
The said questions are answered by performing estimation and hypothesis testing
procedures involving two populations.
Consider getting a random sample of observations X
11
, , X
1n
with meanX
from a
population with mean
1
and variance o
1
2
. Similarly, consider getting a second random sample
X
21
, , X
2n
with mean X
from a population with mean
2
and variance o
2
2
. The point
estimator of the difference between
1
and
2
is the statistic X
.
If random sampling is done in two populations, it can be done either through (1)
selection of two independent samples or through (2) paired sampling.
Paired sampling is done to try to eliminate the effect of factors which are not of interest
to us but may affect the study results when comparison of two population means is performed.
This is achieved by matching or studying two related samples. Matching may be achieved by:
JDEUSTAQUIO
135
a) using the same subject in the two samples (e.g. in assessing whether there was
increased knowledge about a subject matter after an academic year, one may
compare test results at the start and at the end of classes of the same pupils).
b) pairing of subjects with respect to any extraneous variable which might affect or
influence the outcome (e.g., in assessing the effectiveness of one method over the
other in teaching kids, the extent of learning may also be affected by the
intelligence scores of the kids).
If the manner by which a random sample taken from a population does not depend in
any way on how the other random sample is taken from another population, or if units from
the two samples are not matched by controlling an extraneous factor, then two samples are
said to be independent.
A (1-) 100% Confidence Interval for
1
-
2
is given by:
a.
(X
b.
(X
c.
(X
d.
(X
10.1.1 Estimating the Difference of Two Population
Means Based on Two Independent Samples
JDEUSTAQUIO
136
Remarks:
1. Formulas (a) to (c) hold strictly for independent samples selected from normal
populations. However, they provide good approximate (1-)100% confidence intervals
when the distributions are not normal, provided both n
1
and n
2
are greater than 30 by
using the properties of the t-distribution and by invoking the Central Limit Theorem.
2. Even if the population variances are considerably different, formula (b) will still provide a
good estimate provided that n
1
=n
2
and both populations are normal. Therefore, in a
planned experiment, one should make every effort to equalize the size of the samples.
3. The flowchart above summarizes the cases by which the different formulas for the
(1-)100% confidence interval estimators for
1
-
2
are used.
Example:
A statistic test was given to a random sample of 50 girls and another random sample of
75 boys. The mean score of the girls is 80 with a standard deviation of 4 and the mean score of
the boys is 86 with a standard deviation of 6. Find a 95% confidence interval for the difference
B
-
G
.
X
1
and X
2
both
normally
distributed
o
1
2
and o
2
2
is
known?
Formula
a
n
1
and n
2
>30
Formula d o
1
2
= o
2
2
n
1
= n
2
Formula b Formula c
Formula b
n
1
and n
2
>30
o
1
2
and o
2
2
is known?
Formula a Formula d
Nonparametric
Methods
Flowchart of Formulas to Use in Estimating the Difference between
1
and
2
NO
NO
NO
NO
NO
NO
NO
YES
YES
YES
YES
YES
YES
YES
JDEUSTAQUIO
137
Solution:
Let B
i
= score of the i
th
boy in a statistic test, i = 1, 2, ..., 75
Let G
j
= score of the j
th
girl in a statistic test, i = 1, 2, ..., 50
Then X
approximately ~ N(
B
,
) and X
approximately ~ N(
G
,
)
Given: X
1- = 0.95 = 0.05 /2 = 0.025 z
/2
= z
0.025
= 1.96
A (1-)100% confidence interval estimate for
B
-
G
is given by
((X
(X
,
Question: Why use this formula among the four available interval estimators?
A 95% confidence interval for the difference of the true mean score of the girls from
the true mean score of the boys is;
(( ) ()
( )
, ( )
Based on sample results, we are 95% confident that the true mean score of the boys in
a statistics test exceeds the true mean score of the girls by at least 4.25 and by at most 7.75
points. Since all the values in the interval of differences are positive, there is indication that the
true mean score of the boys is higher than the true mean score of the girls in the said statistics
test.
Remark: Suppose that based on random samples taken from two populations with means
1
and
2
, a (1-)100% confidence interval for
1
-
2
has been constructed and the estimate is (a
1
,
b
1
). Then, based on the same random samples, a (1-)100% confidence interval for
2
-
1
will
give the estimate (-b
1
, -a
1
).
Exercises:
1. Students may choose between a 3-unit course in Physics without lab and a 4-unit course
with lab. The final written examination is the same for each section. The mean score of a
random sample of 12 students in the section with lab is 84 with a standard deviation of 4,
and the mean score of 18 students in the section without lab is 77 with a standard
deviation of 6. Find a 99% confidence interval for the difference between the mean
grades for the two courses. Assume the populations to be approximately normally
distributed with equal variances.
JDEUSTAQUIO
138
2. An obstetrician wanted to know the effectiveness of two methods of relieving pain in
women due for child delivery. Specifically, she wanted to see if there is a difference in the
mean duration of active labor (in minutes) in these women who were introduced to these
methods. She enrolled 20 women in labor in the study which she later on divided
randomly into two equal groups. Group A subjects were given continuous epidural
infusion while Group B subjects received hourly intermittent epidural injection. The
sample sizes, mean duration of active labor (in minutes) and standard deviations were as
follows:
Sample Group
Sample
Sizes
Mean Duration of Active
Labor (in minutes)
Standard Deviation
(in minutes)
Continuous Epidural Infusion
Group
10 134.1 79.79
Hourly Intermittent Epidural
Injection Group
10 88.8 85.01
Assume normality of duration of active labor (in minutes) and equality of
population variances. Construct a 98% confidence interval of the difference of the mean
duration of active labor (in minutes) of women introduced to these methods. Does this
suggest that there is a difference in the effects of the two methods in terms of reducing
the duration of active labor?
If taking of measurements for two groups is implemented from the same units or if
pairing of units from two groups with respect to some extraneous factor is done, then we come
up with related samples.
Let X
i
= the i
th
observation from the first group
Y
i
= the i
th
observation from the second group
d
i
= X
i
Y
i
, i = 1, 2, ,n and d
i
~ N(
D
, o
D
2
).
Then a (1-)100% confidence interval for
D
is given by;
(
( )
10.1.2 Estimating the Difference of Two Population
Means based on Two Related Samples
JDEUSTAQUIO
139
Example:
It claimed that a new diet will reduce a persons weight by 4.5 kilograms on the average
in a period of two weeks. The weights of a random sample of 7 women who followed the diet
were recorded before and after a 2-week period are as given in the table below. Compute a
95% confidence interval for the mean difference in the weight. Assume the distribution of
weights to be approximately normal.
Woman
1 2 3 4 5 6 7
Weight Before 58.5 60.3 61.7 69.0 64.0 62.6 56.7
Weight After 60.0 54.9 58.1 62.1 58.5 59.9 54.4
Solution:
Let W
Bi
= weight (in kgs) of the i
th
woman before undergoing a new diet
W
Ai
= weight (in kgs) of the i
th
woman after undergoing a new diet
d
i
= W
Bi
W
Ai
= difference in weight (in kgs) of the i
th
woman before and after
undergoing new diet for two weeks , i = 1, 2, ,7 and d
i
~ N(
D
, o
D
2
).
Woman
I 1 2 3 4 5 6 7
d
i
-1.5 5.4 3.6 6.9 5.5 2.7 2.3
1- = 0.95 = 0.05 /2 = 0.025 t
/2,v
= t
0.025, 6
= 2.447
A 95% confidence interval for the true mean difference in the weights of women after two
weeks of undergoing new diet is;
(()
()()
()
()()
+ ( )
Based on the sample results, we are 95% that on the average, there is weight loss of
at least 0.99 kg and at most 6.12 kg among women after two weeks of undergoing new diet.
Since 4.5 kg is within the interval, then there is insufficient evidence to discredit the claim.
Since all the values in the interval of mean weight loss are positive, there is indication that on
the average, there is weight loss.
JDEUSTAQUIO
140
Exercise: Twenty college freshmen were divided into 10 pairs, each member of the pair having
approximately the same IQ. One of each pair was selected at random and assigned
to a mathematics section using programmed materials only. The other member of
each pair was assigned to a section in which the professor lectured. At the end of the
semester, each group was given the same examination and the following results
were recorded.
Pair 1 2 3 4 5 6 7 8 9 10
Programmed Materials
76 60 85 58 91 75 82 64 79 88
Lectures
81 52 87 70 86 77 90 63 85 83
Find a 98% confidence interval for the mean difference in scores of the two learning
procedures. Assume normality.
Suppose we have two populations with proportions of success P
1
and P
2
respectively,
and we wish to estimate the difference P
1
P
2
.
Let X = number of successes in n
1
trials (sample 1) from the first population and
Y = number of successes in n
2
trials (sample 2) from the second population
Then a point estimator of P
1
P
2
is:
When n
1
and n
2
are large, an approximate (1-)100% confidence interval for P
1
P
2
is
given by:
((
,
10.1.3 Estimating the Difference of Two Population Proportions
JDEUSTAQUIO
141
Example:
In a random sample of 200 students, 78 of the 120 females and 60 of the 80 males
passed Math 17 on their first take. Construct a 95% confidence interval for p
1
-p
2
where p
1
and
p
2
are the true proportions of females and males, respectively, who passed Math 17 on their
first take.
Solution:
Let X = number of female students (out of 120) who passed Math 17 on their first take.
Y = number of male students (out of 80) who passed Math 17 on their first take.
where P
1
is the population proportion of females who pass Math 17 on first take and
P
2
is the population proportion of males who pass Math 17 on first take.
Given:
1- = 0.95 = 0.05 /2 = 0.025 z
/2
= z
0.025
= 1.96
A 95% confidence interval for the difference of the true proportion of male students
who pass Math on their first take from the true proportion of female students who pass Math
on their first take is
(( )
()()
()()
( )
()()
()()
,
( )
Based on the sample results, we are 95% confident that the difference of the true
proportion of male students who pass Math on their first take from the true proportion of
female students who pass Math on their first take is at least -0.23 and at most 0.028. Since the
interval contains both positive and negative values, there is a possibility that the true
proportions of male and female students who pass Math 17 on their first take do not differ.
JDEUSTAQUIO
142
10.2 Hypothesis Testing Involving Two Populations
The similarities in cases in choosing the appropriate interval estimators for
1
-
2
and for
D
and in selecting the appropriate test statistic in hypothesis testing can be noted.
H
o
Test Statistic H
a
Critical
Region
a. o
1
2
and o
2
2
known
1
-
2
= d
o
(
) (
1
-
2
< d
o
1
-
2
> d
o
1
-
2
= d
o
z < -z
z > z
|z| > z
/2
a. o
1
2
= o
2
2
but unknown
1
-
2
= d
o
(
) (
)
v = n
1
+n
2
-2
1
-
2
< d
o
1
-
2
> d
o
1
-
2
= d
o
t < -t
t > t
|t| > t
/2
b. o
1
2
= o
2
2
and unknown
1
-
2
= d
o
(
) (
)
,(
) (
)-
1
-
2
< d
o
1
-
2
> d
o
1
-
2
= d
o
t < -t
t > t
|t| > t
/2
Remarks:
1. The remarks made in the previous section regarding the use of the appropriate interval
estimator for
1
-
2
is applicable in choosing the appropriate test statistic and
establishing the critical region in hypothesis testing procedures involving
1
-
2
.
2. If o
1
2
and o
2
2
are unknown but n
1
and n
2
are greater than 30, use S
1
2
and S
2
2
in place of
o
1
2
and o
2
2
in the test statistic in Case (a) so that the test statistic is:
10.2.1 Test of Hypothesis for the Difference of Two
Population Means Based on Two Independent Samples
JDEUSTAQUIO
143
(
) (
)
The critical region stays the same.
3. The flowchart which serves as a guide in the usage of the interval estimators for
1
-
2
in
the previous section can be applied to hypothesis testing procedure for
1
-
2
.
Example:
A statistic test was given to 50 girls and 75 boys. The girls made an average of 80 with a
standard deviation of 4 ad the boys had an average of 86 with a standard deviation of 6. Is
there sufficient evidence at 0.05 level of significance that the average grades of girls and boys
differ?
Solution:
Let B
i
= score of the i
th
boy in a statistic test, i = 1, 2, ,75
G
j
= score of the j
th
girl in a statistic test, j = 1, 2, ,50
Then
approximately ~ N(
G
, o
G
2
/50)
i. Hypotheses: H
o
:
B
=
G
B
-
G
= 0 H
a
:
B
=
G
B
-
G
= 0
Note: Be careful in the formulation of H
O
and H
a
ii. Level of Significance: =0.05
iii. Test Statistic: Since o
B
2
and o
G
2
are unknown but n
B
>30 and n
G
>30 then the formula is:
(
) (
)
iv. Critical Region: |Z| > z
/2
= z
0.025
Z > z
0.025
or Z < -z
0.025
Z > 1.96 or Z < -1.96
v. Computation:
Given:
( )
( ) ( )
vi. Decision: Since z = 6.708203933
vii. Conclusion: At 5% level of significance, based on sample results, there is sufficient
evidence to say that the average grades of girls and boys differ. There is indication that
the true mean score of the boys is higher than the true mean score of the girls in the said
statistics test.
Question: If the hypotheses are written as follows:
H
o
:
G
=
B
G
-
B
= 0 H
a
:
G
=
B
G
-
B
= 0, how will the testing procedure change?
JDEUSTAQUIO
144
In general, if the alternative hypothesis is stated as
1. H
a
:
1
>
2
1
-
2
> 0, what test statistic will be used? What critical region will be
established?
2. H
a
:
1
<
2
1
-
2
< 0, what test statistic will be used? What critical region will be
established?
3. H
a
:
2
>
1
2
-
1
> 0, what test statistic will be used? What critical region will be
established?
4. H
a
:
2
<
1
2
-
1
< 0, what test statistic will be used? What critical region will be
established?
Reminder:
As seen in the solved problem, it does not matter if the alternative hypothesis is
formulated as H
a
:
1
=
2
or as H
a
:
2
=
1
. Though there are changes in the testing procedure,
the conclusion will be the same.
In general, the conclusion will be the same for (1) and (4) also, (2) and (3) would have the
same conclusions.
H
o
Test Statistic H
a
Critical
Region
D
= d
o
D
< d
o
D
> d
o
D
= d
o
t < -t
t > t
|t| > t
/2
Example:
A taxi company is trying to decide whether the use of radial tires instead of regular
belted tires improves fuel economy. Twelve cars were driven twice over a prescribed test
course, each time using a different type of tires (radial and belted) in random order. At
0.025 level of significance, we can conclude that cars equipped with radial tires give better
fuel economy than those equipped with belted tires? Assume the populations to be
normally distributed.
10.2.2 Test of Hypothesis for the Mean Difference
Based on Two Related Samples
JDEUSTAQUIO
145
Car No. x
1i
x
2i
d
i
Car No. x
1i
x
2i
d
i
1 4.2 4.1 0.1 7 5.7 5.7 0.0
2 4.7 4.9 -0.2 8 6.0 5.8 0.2
3 6.6 6.2 0.4 9 7.4 6.9 0.5
4 7.0 6.9 0.1 10 4.9 4.7 0.2
5 6.7 6.8 -0.1 11 6.1 6.0 0.1
6 4.5 4.4 0.1 12 5.2 4.9 0.3
Solution:
We are going to use the formula on testing the difference between two population
means using two related samples. Why?
Let x
1i
= mileage (in km/liter) of the i
th
car using radial tires
x
2i
= mileage (in km/liter) of the i
th
car using regular belted tires
d
i
= x
1i
- x
2i
= difference of mileage of the i
th
car using regular belted tires from its
mileage using radial tires. i = 1, 2, , 12.
Note how the d
i
was defined affects the formulation of the null and alternative hypothesis.
d
i
~ N(
D
, o
D
2
)
i. Hypotheses: H
o
:
D
= 0 vs. H
a
:
D
> 0
ii. Level of Significance: = 0.05
iii. Test Statistic:
n
iv. Critical Region: t > t
, n-1
= t
0.025, 11
=
2.201
v. Computation:
Given:
vi. Decision: Since t = 2.484515151 > 2.201, we reject H
o
at 2.5% level of significance.
vii. Conclusion: At 2.5% level of significance, based on sample results, there is sufficient
evidence to conclude that on the average, cars equipped with radial tires give better fuel
economy than those equipped with regular belted tires.
Question: How is the testing procedure affected if d
i
is defined as d
i
= x
2i
-x
1i
, i = 1, 2, , 12?
JDEUSTAQUIO
146
Exercise:
For determination of whether or not a heat treatment is effective in reducing the
number of bacteria in skim milk at Kroft Foods Inc., counts were made before and after
treatment on 12 samples of skim milk with the results shown in the table below. The data are in
the form of log DMC, the logarithms of direct microscopic counts. Test the hypothesis at 0.05
level of significance that the heat treatment is effective. Assume normality of log DMC
measurements.
Sample 1 2 3 4 5 6 7 8 9 10 11 12
Before Treatment 6.98 7.08 8.34 5.30 6.26 6.77 7.03 5.56 5.97 6.64 7.03 7.69
After Treatment 6.95 6.94 7.17 5.15 6.28 6.81 6.59 5.34 5.98 6.51 6.84 6.99
Suppose that interest lies in the comparison of proportions P
1
and P
2
of an attribute in
two populations. We want to see whether based on the sample results; there is sufficient
evidence to say that P
1
is significantly different from P
2
. In other words, it is of interest to test
the null hypothesis H
o
: P
1
= P
2
where P
1
and P
2
are the two population proportions of interest.
The testing procedure involves selection of independent samples of size n
1
and n
2
from
two binomial populations.
Let X = number of successes in n
1
trials (sample 1) from the first population and
Y = number of successes in n
2
trials (sample 2) from the second population
The sample proportions
and
are computed and the common
(population) proportion P is given as the pooled estimate
. The test is as follows:
H
o
Test Statistic H
a
Critical
Region
p
1
= p
2
/
p
1
< p
2
p
1
> p
2
p
1
= p
2
z < -z
z > z
|z| > z
/2
10.2.3 Test of Hypothesis for the Difference of Two
Population Proportions
JDEUSTAQUIO
147
Example:
In a survey of 200 students, 78 out of the 120 females in the sample passed Math 17 on
their first take while this figure is 60 among the 80 male students. Will you agree that the
proportion of males who passed Math 17 on their first take is higher than the proportion of
females who passed the same course on their first take? Test at =0.05.
Solution:
Let X = number of females (out of 120) who passed Math 17 on their first take
Y = number of males (out of 80) who passed Math 17 on their first take
Where P
1
is the population proportion of females who pass Math 17 on first
take and P
2
is the population proportion of males who pass Math 17 on their first take.
i. Hypotheses: H
o
: P
1
= P
2
vs. H
a
: P
1
< P
2
ii. Level of Significance: = 0.05
iii. Test Statistic:
/
iv. Critical Region: z > -z
= -z
0.05
= -1.645
v. Computation:
()() .
/
vi. Decision: Since z = -1.498011773 -1.645, we do not reject H
o
at 5% level of significance.
vii. Conclusion: At 5% level of significance, based on sample results, there is insufficient
evidence to say that the proportion of males who passed Math 17 on their first take is
significantly different from the population of females who passed Math 17 on their first
take.
JDEUSTAQUIO
148
Chi-Square Test
Suppose a sample of units has been taken from a population and information on
classification according to two nominal variables has been obtained. Tests of independence are
useful in assessing whether classification in one categorical variable has a relationship with
classification in another categorical variable.
For example, suppose that an employee responsible for monitoring the quality of
products manufactured by their firm is concerned with determining whether or not there is a
relationship between the production shift and the presence of a defect in the units produced.
If in the population of all units manufactured by the firm, the true proportion of
defective items per shift is 5%, then being classified as defective or not has nothing to do with
the shift of production of the unit. In this scenario, presence of defect is independent of the
production shift. If however, the true proportions of defective items differ among the
production shifts, then the presence of defect in a unit is related to when the unit has been
produced.
Unfortunately, the employee has no way of knowing the proportion of defectives per
shift in the population of units manufactured by the firm unless he subjects each unit produced
by the firm to testing, which would be impractical. What he can do is to take a random sample
of units from the population, classify the units according to production shift and presence of
defect (the two categorical variables of interest), and to test the independence of the said
variables.
Now it is possible that even if production shift and presence of defect are independent
in the population, he may get a sample of units such that the sample proportions of defective
units vary among the production shifts. This is because of sampling error, the error committed
because only a sample has been taken from the population instead of taking information from
all units in the population. But if the presence of defectives and non-defectives per shift in the
sample of units would not differ much from what is expected under independence.
To illustrate, suppose that the employee obtained a sample of units such that the
number of units classified per shift and the number of defectives and non-defectives are as
follows:
JDEUSTAQUIO
149
Cross-tabulation of Units According to Production Shift and Presence of Defect
Shifts Without Defect With Defect Total
Morning E
11
= r
1
c
1
= (400)(950)/1000 E
12
= r
1
c
2
= (400)(50)/1000 r
1
= 400
Afternoon E
21
= r
2
c
1
= (300)(950)/1000 E
22
= r
2
c
2
= (300)(50)/1000 r
2
= 300
Night E
31
= r
3
c
1
= (300)(950)/1000 E
32
= r
3
c
2
= (300)(50)/1000 r
3
= 300
Total c
1
= 950 c
2
= 50 N = 1000
The marginal frequencies and grand total are then as follows:
r
1
= the number of units in the sample produced under Morning shift = 400
r
2
= the number of units in the sample produced under Afternoon shift = 300
r
3
= the number of units in the sample produced under Night shift = 300
c
1
= the number of units in the sample without defects = 950
c
2
= the number of units in the sample with defects = 50
N = the number of units in the sample = 1000
Note that among the 1000 units in the sample, 95% are classified as not being defective
and 5% are classified as being defective. If production shift and presence of defect are truly
independent, then we should expect that than, per production shift, we will be able to classify
95% of the units as non-defective and 5% as defective. That is,
E
11
= number of units in the sample produced under Morning shift and classified as not
having defects that we expect to obtain if production shift and presence of
defect are truly independent = (400)(950)/1000 = 380.
E
12
= number of units in the sample produced under Morning shift and classified as
having defects that we expect to obtain if production shift and presence of
defect are truly independent = (400)(50)/1000 = 20.
In general, E
ij
= the number of units in the sample produced under Shift I and outcome j
that we expect to obtain if production shift and presence of defect are truly independent,
i= 1, 2, 3, and j= 1,2.
The other expected frequencies under independence of production shift and presence
of defect can be similarly calculated and are presented in the table below.
Expected Frequencies Under Independence of
Production Shift and Presence of Defect
Shifts Without Defect With Defect Total
Morning 380 20 400
Afternoon 285 15 300
Night 285 15 300
Total 950 50 1000
JDEUSTAQUIO
150
Note that the expected frequencies were calculated using the marginal frequencies
and the grand total. To illustrate,
()()
()()
If the observed number of units in the sample classified under the variables production
shift and presence of defect (the observed frequencies) are not much different from what is
expected (expected frequencies, E
ij
s) under independence of production shift and presence of
defect in the population, then there is no sufficient evidence based on the sample to reject
independence . But if the said differences are large, then we tend to reject the hypothesis of
independence of production shift and presence of defect in the units produced by the firm.
The question now is, how large should the differences between the observed frequencies
and the expected frequencies under independence be for the employee to reject independence
of production shift and presence of defect?
For example, suppose that the employee has already constructed the contingency table
of 1000 units classified according to production shift and presence of defect:
Observed Frequencies of 1000 Units Classified
According to Production Shift and Presence of Defect
Shifts Without Defect With Defect Total
Morning 392 8 400
Afternoon 275 25 300
Night 283 17 300
Total 950 50 1000
Note that the sample percentages of defectives are different for the three shifts: 2% for
Morning shift, 8.33% for Afternoon shift, 5.67% for Night shift. There are then differences
between the observed and the expected number of units classified according to production
shift and presence of defect. As an example, there are more units produced under afternoon
shift that have defects (O
22
=25) than what one would expect if production shift and presence of
defect are independent (E
22
=15). The differences O
ij
-E
ij
can be assessed for the three shifts
(i=1,2,3) and outcome (j=1,2). But are these differences large enough for us to reject
independence of production shift and presence of defect?
The Chi-Square Test of Independence is a formal statistical test that provides an
objective assessment as to whether or not the magnitude of the differences between observed
and expected frequencies are large enough to reject the null hypothesis (independence).
JDEUSTAQUIO
151
It makes use of the following test statistic and critical region:
(r)()
where r = number of levels of the row variable and
c = number of levels of the column variable
Questions:
1. Will
2
be ever a negative value? Why?
2. When will
2
take the value of zero?
3. When does
2
tend to be a large value?
Let us test the hypothesis of independence of production shift and presence of defect
using the chi-square test of independence.
Example: Given below is a 3 x 2 contingency table of 1000 units classified according to
production shift and presence of defect.
Observed Frequencies of 1000 Units Classified
According to Production Shift and Presence of Defect
Shifts Without Defect With Defect Total
Morning 392 8 400
Afternoon 275 25 300
Night 283 17 300
Total 950 50 1000
Test the hypothesis of independence of production shift and presence of defect at 5%
level of significance.
Solution:
a. Hypothesis: H
o
: Production shift and presence of defect are not related.
H
A
: Production shift and presence of defect are related.
b. Level of Significance: = 0.05
c. Test Statistic:
d.
(r)()
()()
JDEUSTAQUIO
152
e. Computations:
Observed Frequencies of 1000 Units Classified According to
Production Shift and Presence of Defect
Shifts
Without Defect With Defect
Total
Observed Expected Observed Expected
Morning 392 380 8 20 400
Afternoon 275 285 25 15 300
Night 283 285 17 15 300
Total 950 50 1000
f. Decision: Since
2
= 14.87719 > 5.991, we reject H
o
at 5% level of significance.
g. Conclusion: At 5% level of significance, based on sample results, there is
sufficient evidence to say that presence of defect in a unit is related to the shift
when it was produced.
Exercises:
1. Mediterranean Diet Case Study: In the study, 605 survivors of heart attack who were made to
undergo either the AHA diet or the Mediterranean diet were monitored and classified according to
health condition. The resulting contingency table of subjects according to diet followed and health
condition is presented below.
Diet
Health Condition
Cancers Deaths Nonfatal Illness Healthy Total
AHA 15 24 25 239 303
Mediterranean 7 14 8 273 302
Total 22 38 33 512 605
Is there sufficient evidence to say that diet and health condition are related at =0.05
2. A research was undertaken to study factors related to mothers choice of infant feeding method.
One of the factors examined was monthly family income. Do the data below indicate an association
between family income and method of feeding? Use 0.10 level of significance.
Monthly
Family Income
Method of Feeding
Total
Bottle Breast
200 - 249 4 65 69
250 -499 24 12 36
500 - 749 5 29 34
750 - 1000 6 4 10
Total 39 110 149
JDEUSTAQUIO
153
Remarks:
1. The test is VALID if at least 80% of the cells have expected frequencies of AT
LEAST 5 and no cell has an expected frequency 1.
2. If many expected frequencies are very small, researchers commonly combine
categories of variables to obtain a table having larger cell frequencies. Generally,
one should not pool categories unless there is a natural way to combine them.
3. For a 2 x 2 contingency table, a correction called Yates correction for continuity is
applied. The formula then becomes;
(|
| )
4. We could also test the independence of a 2 x 2 contingency table without
computing for the expected frequencies using the formula below;
Variable X
Variable Y
Total
Category 1 Category 2
Category A a b a+b
Category B c d c+d
Total a+c b+d a+b+c+d = N
.| |
( )( )( )( )
Example: A service company is classified as small if the number of its employees is at
most 200, and it is classified as big otherwise. Profit in sales of services, such as training
and consulting, is classified as either low or high.
Profit Level
Size of Company
Small Big
Low Service Profit 30 63
High Service Profit 75 32
Test whether the size of the service company is independent of the level of profit in sales
of services at the 0.05 level of significance.
Solution:
a. Hypothesis: H
o
: Size of the service company is independent of the level of profit
in sales of services.
H
A
: Size of the service company is not independent of the level of
profit in sales of services.
JDEUSTAQUIO
154
b. Level of Significance: = 0.05
c. Test Statistic:
n.||
()()()()
d.
(r)()
()()
e. Computations:
Profit Level
Size of Company
Total
Small Big
Low Service Profit 30 63 93
High Service Profit 75 32 107
Total 105 95 200
.| |
( )( )( )( )
.|()() ()()|
( )( )( )( )
f. Decision: Since
2
= 27.064 > 3.841, we reject H
o
at 5% level of significance.
g. Conclusion: At 5% level of significance, based on sample results, there is
sufficient evidence to say that Size of the service company is not independent of
the level of profit in sales of services.
JDEUSTAQUIO
155
Introduction to Correlation and Regression Analysis
6.1 Introduction to Correlation
In the estimation and hypothesis testing procedures for parameters that we performed
in the previous chapters, we are concerned about a single variable of interest which we
measure from units drawn from one or two populations.
In this chapter, the focus would be on finding and assessing relationships existing
between variables of at least interval scale. We are specifically interested in determining,
estimating and assessing a linear relationship existing between two variables.
To visualize the relationship that exists between two variables X and Y of at least
interval scale, a scatter diagram which plots the ordered measurements (X
i
, Y
i
) taken from n
observations would be helpful.
Example (GPI and Starting Salary):
Suppose a researcher wishes to investigate the relationship between the achieved
grading-point index (GPI) and the starting salary f recent graduates majoring in business. A
random sample of 30 recent graduates majoring in business is drawn, and the data pertaining
to the GPI and starting salary (in thousands of dollars) are recorded for each individual in the
following table:
6.1.1 Graphical Presentation of Linear Relationship
JDEUSTAQUIO
156
GPI and Starting Salary of 30 Recent Graduates Majoring in Business
(in thousands of dollars)
Individual GPI Salary Individual GPI Salary
1 2.7 17.0 16 3.0 17.4
2 3.1 17.7 17 2.6 17.3
3 3.0 18.6 18 3.3 18.1
4 3.3 20.5 19 2.9 18.0
5 3.1 19.1 20 2.4 16.2
6 2.4 16.4 21 2.8 17.5
7 2.9 19.3 22 3.7 21.3
8 2.1 14.5 23 3.1 17.2
9 2.6 15.7 24 2.8 17.0
10 3.2 18.6 25 3.5 19.6
11 3.0 19.5 26 2.7 16.6
12 2.2 15.0 27 2.6 15.0
13 2.8 18.0 28 3.2 18.4
14 3.2 20.0 29 2.9 17.3
15 2.9 19.0 30 3.0 18.5
Preliminary investigation on the scatterplot below indicates that there is a positive
linear relationship between the grade-point index and the starting salaries (in thousand dollars)
of the random sample of 30 recent graduates majoring in Business. As the grade-point index
increases, the starting salary (in thousand dollars) also tends to increase approximately, on a
straight line.
0.0
5.0
10.0
15.0
20.0
25.0
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
S
t
a
r
t
i
n
g
S
a
l
a
r
y
(
i
n
0
0
0
'
s
)
GPI
Scatterplot of the Grade-Point Index vs. the Starting Salaries (in
000's) of 30 Recent Graduates Majoring in Business
JDEUSTAQUIO
157
Though the linear relationship between the GPI and the starting salaries of the 30
recent graduates can be clearly seen in the above graph, it would be much informative to
quantify the strength of the said linear relationship by computing a summary measure called
linear correlation coefficient.
The correlation coefficient is a summary measure on the strength of the linear
relationship between two variable X and Y that is independent of their respective scales of
measurement.
Properties of the Linear Correlation Coefficient:
1. The correlation coefficient takes values from -1 to 1.
2. A positive value of indicates that the line slopes upward to the right. This means that
as X increases, Y tends to increase also. Similarly as X decreases, Y also tends to
decrease. On the other hand, a negative value of indicates that the line slopes
downward to the right. This means that as X increases, Y tends to decrease.
Alternatively, as X decreases, Y tends to increase.
3. When is -1 or 1, there is perfect linear relationship between X and Y and all the points
(x, y) fall on a straight line. A close to -1 or 1 indicates a strong linear relationship but it
does not necessarily imply that X causes Y or Y causes X. It is possible that a third
variable may have caused the change of both X and Y (spurious correlation), producing
the observed relationship.
4. If = 0, then there is no linear correlation between X and Y. A value of = 0, however,
does not mean a lack of association. For example, if a strong quadratic relationship
exists between X and Y, it is still possible to obtain a zero correlation to indicate
nonlinear relationship.
Properties of the Linear Correlation Coefficient:
For a random sample of n pairs of measurements (X
i
, Y
i
), i= 1, 2, , n, the Pearson
Product Moment Coefficient of Correlation, denoted by r, can be computed using the formula:
X
( X
)(
)
( X
( X
)(
)
6.1.2 The Pearson Product Moment Coefficient of
Correlation
JDEUSTAQUIO
158
GPI and Starting Salary Example (Cont.)
Let X
i
= grade-point index of the i
th
graduate majoring in Business
Y
i
= starting salary (in thousand dollars) of the i
th
graduate majoring in Business
From the calculated value of r, there is a strong positive linear relationship between the
GPI and the starting salary of the 30 recent graduates majoring in Business. As the GPI of the
recent graduate increases, the starting salary tends to increase.
Graduate
(i)
GPI
(X
i
)
Starting Salary
(Y
i
) X
i
Y
i
X
i
2
Y
i
2
1 2.7 17.0 45.9 7.29 289.00
2 3.1 17.7 54.87 9.61 313.29
3 3.0 18.6 55.8 9.00 345.96
4 3.3 20.5 67.65 10.89 420.25
5 3.1 19.1 59.21 9.61 364.81
6 2.4 16.4 39.36 5.76 268.96
7 2.9 19.3 55.97 8.41 372.49
8 2.1 14.5 30.45 4.41 210.25
9 2.6 15.7 40.82 6.76 246.49
10 3.2 18.6 59.52 10.24 345.96
11 3.0 19.5 58.5 9.00 380.25
12 2.2 15.0 33 4.84 225.00
13 2.8 18.0 50.4 7.84 324.00
14 3.2 20.0 64 10.24 400.00
15 2.9 19.0 55.1 8.41 361.00
16 3.0 17.4 52.2 9.00 302.76
17 2.6 17.3 44.98 6.76 299.29
18 3.3 18.1 59.73 10.89 327.61
19 2.9 18.0 52.2 8.41 324.00
20 2.4 16.2 38.88 5.76 262.44
21 2.8 17.5 49 7.84 306.25
22 3.7 21.3 78.81 13.69 453.69
23 3.1 17.2 53.32 9.61 295.84
24 2.8 17.0 47.6 7.84 289.00
25 3.5 19.6 68.6 12.25 384.16
26 2.7 16.6 44.82 7.29 275.56
27 2.6 15.0 39 6.76 225.00
28 3.2 18.4 58.88 10.24 338.56
29 2.9 17.3 50.17 8.41 299.29
30 3.0 18.5 55.5 9.00 342.25
Sum 87.0 534.3 1564.2 256.1 9593.4
Sum2 7569.0 285476.5
r 0.865088
JDEUSTAQUIO
159
Remarks:
1. The sample Pearson correlation coefficient r is used to estimate based on a random
sample of n pairs of measurements (X
i
, Y
i
), for i = 1, 2, , n.
2. r also takes on values between -1 and 1.
3. Just like , when r = 1 or -1, all the points (x
i
, y
i
), for i= 1, 2, ,n, fall on a straight line;
when r = 0, they are scattered and give no evidence of a linear relationship. Any other
value of r suggests the degree to which the points tend to be linearly related.
Example: The table below presents the pairs of measurements (X
i
, Y
i
), for i = 1, 2, , 30 and the
computation for the sample Pearson product moment coefficient of correlation r.
i X
i
Y
i
X
i
Y
i
X
i
2
Y
i
2
1 1 2 2 1 4
2 2 4 8 4 16
3 3 6 18 9 36
4 4 8 32 16 64
5 5 10 50 25 100
6 6 12 72 36 144
7 7 14 98 49 196
8 8 16 128 64 256
9 9 18 162 81 324
10 10 20 200 100 400
11 11 22 242 121 484
12 12 24 288 144 576
13 13 26 338 169 676
14 14 28 392 196 784
15 15 30 450 225 900
16 16 30 480 256 900
17 17 28 476 289 784
18 18 26 468 324 676
19 19 24 456 361 576
20 20 22 440 400 484
21 21 20 420 441 400
22 22 18 396 484 324
23 23 16 368 529 256
24 24 14 336 576 196
25 25 12 300 625 144
26 26 10 260 676 100
27 27 8 216 729 64
28 28 6 168 784 36
29 29 4 116 841 16
30 30 2 60 900 4
JDEUSTAQUIO
160
X
i
Y
i
X
i
Y
i
X
i
2
Y
i
2
Sum 465 480 7440 9455 9920
Sum2 216225 230400
r 0
It would be erroneous to conclude that since the value of r is 0, there is no relationship
between X and Y. Based on examination of the values of X and Y in the above table, and
based on what can be clearly seen on the scatter diagram below, there is a relationship
between X and Y, but this relationship is not linear.
The correlation coefficient measures the degree of linear relationship between two
variables X and Y. A value of 0 for the correlation coefficient does not imply absence of
relationship.
Source: http://en.wikipedia.org/wiki/Correlation
0
5
10
15
20
25
30
35
0 5 10 15 20 25 30 35
Y
X
Scatterplot of Values of X vs. Values of Y
JDEUSTAQUIO
161
Remark: Several sets of (x, y) points, with the Pearson correlation coefficient of x and y for each set.
Note that the correlation reflects the noisiness and direction of a linear relationship (top row),
but not the slope of that relationship (middle), nor many aspects of nonlinear relationships
(bottom). N.B.: the figure in the center has a slope of 0 but in that case the correlation
coefficient is undefined because the variance of Y is zero.
The computation and interpretation of r is applicable to the data on hand. The linear
relationship being described by the sample correlation holds for the same units from which the
measurements on X and Y where obtained.
However, there is an important question that we may want answered: Does the linear
relationship described by the sample correlation hold for the population from which the
sample of units has been taken? or did the presence of linear relationship among sample
measurements of X and Y only occur by chance?
To answer the said question, we can perform hypothesis testing procedure fro the
correlation coefficient.
H
o
Test Statistic H
a
Critical Region
= 0
< 0
> 0
= 0
t < -t
, v
t > t
, v
|t| > t
/2, v
GPI and Starting Salary Example (Cont.)
Is the linear correlation coefficient between GPI and starting salary of all recent
graduates majoring in Business significantly different from zero? Test at = 0.01.
a. Hypotheses: H
o
: = 0 vs. H
a
: = 0
b. Level of Significance: = 0.01
c. Test Statistic:
n
,
d. Critical Region: |t| > t
/2, n-2
= |t| > t
0.005, 28
= 2.763
e. Computations: r = 0.865088 n = 30
()
6.1.3 Hypothesis Testing Procedure for the Correlation
Coefficient
JDEUSTAQUIO
162
6.2 Introduction to Regression Analysis
f. Decision: Since |t| = 9.12564431079317 > 2.763, we reject H
o
at 1% level of significance.
g. Conclusion: At 1% level of significance, based on sample results, there is sufficient
evidence to say that the linear relationship between GPI and starting salaries of recent
graduates majoring in Business is significant.
Until now, we have discussed statistical inferences based on the sample measurements
of a sing variable. In many investigations, two or more variables are observed for each
experimental unit in order to determine: (1) whether the variables are related, (2) how
strong the relationships appear to be and (3) whether one variable of primary interest can be
predicted from observations of the other variables.
Regression analysis concerns the study of relationships between variables with the
object of identifying, estimating, and validating the relationship. The estimated relationship
can then be used to predict one variable from the value of the other variable/s. In this
course, we study the subject with specific reference to the straight-line model.
A regression problem involving a single predictor (also called simple linear regression)
arises when we wish to study the relation between two variable X and Y and use it to predict
Y from X. The variable X acts as an independent variable whose values are controlled while
the variable Y depends on X and is also subjected to unaccountable variations or errors.
Illustration (Drug Evaluation Study): In one stage of the development of a new drug from
an allergy, an experiment is conducted to study how different dosages of the drug affect the
duration of relief from the allergic symptoms. Ten patients are included in the experiment.
Each patient receives a specified dosage of the drug and is asked to report back as soon as
the protection of the drug seems to wear off. The observations are recorded below, which
shows the dosage x and duration of relief y for the 10 patients.
6.2.1 Simple Linear Regression (SLRM)
X is called the independent/ explanatory/ predictor/ causal or input variable
Y is called the dependent or response variable
JDEUSTAQUIO
163
Dosage (in mL) and the Number of Days of Relief from Allergy of 10 Patients
Dosage
(x
i
)
Duration of Relief
(y
i
)
3 9
3 5
4 12
5 9
6 14
6 16
7 22
8 18
8 24
9 22
Seven different dosages are used in the experiment, and some of these are repeated for
more than one patient. A glance at the table shows that y generally increases with x, but it is
difficult to say much more about the form of the relation simply by looking at this tabular
data.
Generally, for any (generic) experiment, we use n to denote the sample size or the
number of runs of the experiment. Each run gives a pair of observations (x, y) in which x is
the fixed setting of the independent variable and y denotes the corresponding response.
Data Structure for a Simple Regression
Independent
Variable
Response
Variable
x
1
y
1
x
2
y
2
x
3
y
3
.
.
.
.
.
.
x
n
y
n
We always begin our analysis by plotting the data because the eye can easily detect
patterns along a line or a curve. Thus, plotting a scatter diagram is an important preliminary
step prior to undertaking a formal statistical analysis of the relationship between two variables
JDEUSTAQUIO
164
Recall that if the relation between y and x is exactly a straight line, then the variables
are connected by the formula;
where
0
indicates the intercept of the line with y-axis and
1
represents the slope of
the line. Statistical ideas must be introduced into study of the relation when the points in a
scatter diagram do not lie perfectly on a line, as in the scatter plot above. We think of these
data as observations on an underlying linear relation that is being masked by random
disturbances or experimental errors due in part to differences in severity of allergy, physical
condition of subjects, their environment, and so on. Given this viewpoint, we formulate the
following linear regression model as a tentative representation of the mode of relationship
between y and x.
THE SIMPLE LINEAR REGRESSION MODEL
We assume that the response Y is a random variable that is related to the predictor
variable x by:
, i = 1, 2, , n
1. Y
i
denotes the response corresponding to the i
th
observation/experimental unit in
which the input variable x is set at the value x
i
.
2.
n
are the unknown error components that are superimposed on the true
linear relation. We assume that they are normally distributed with mean 0 and an
unknown variance o
2
.
3. The parameters
0
and
1
, which together locate the straight line, are unknown.
0
5
10
15
20
25
30
0 2 4 6 8 10
D
u
r
a
t
i
o
n
o
f
R
e
l
i
e
f
Dosage
Scatter Diagram of Dosage (x) against Duration
of Relief (y)
JDEUSTAQUIO
165
Because we again are just using a sample of the entire population of interest, we would
only be estimating
0
and
1
. The problem of estimating the regression parameters
0
and
1
can be viewed as fitting the best line of the y to x relationship on the scatter diagram. One can
draw a line by eyeballing the scatter diagram, but such a judgment may be open to dispute.
Moreover, statistical inferences cannot be based on a line that is estimated subjectively. On
the other hand, the method of least squares is an objective and efficient method of
determining the best-fitting straight line. Moreover, this method is quite versatile because its
application extends beyond the simple straight-line regression model.
Suppose that an arbitrary line y = b
0
+ b
1
x is drawn on the scatter diagram. At the value x
i
of the independent variable, the y-value predicted by this line is b
0
+ b
1
x
i
whereas the observed
value is y
i
. The discrepancy between the observed and predicted ys is then (y
i
-b
0
-b
1
x
i
) = d
i
,
which is the vertical distance of the point from the line.
Considering such discrepancies at all the n points, we take
as an overall measure of the discrepancy of the observed point from the trial line
y
i
-b
0
-b
1
x
i
. The magnitude of D obviously depends on the line that is drawn. In other words, it
depends on b
0
and b
1
, the two quantities that determine the trial line. A good fit will make D as
small as possible. We now state the principle of least squares in general terms to indicate its
usefulness to fitting many other models.
THE PRINCIPLE OF LEAST SQUARES
Determine the values for the parameters so that the overall discrepancy
( )
is minimized. The estimates thus determined are called the least square
estimates.
For the straight-line model, the least squares principle involves the determination of
b
0
and b
1
to minimize.
The quantities b
0
and b
1
thus determined are denoted by
and
, respectively and
called the least squares estimates of the regression parameters
0
and
1
. The best-fitting
straight line is then given by the equation
6.2.2 Least Squares Method of Parameter Estimation
JDEUSTAQUIO
166
The Formulas for the Least Squares Estimates are;
Least Squares Estimate of
0
:
Least Squares Estimate of
1
:
+(
+
so that the estimated regression line is
.
Interpretation:
-
is the estimated mean value of Y when the value of Y when the value of X is
set to 0.
-
is the estimated increase/decrease in the mean of Y for every unit increase
in the value of X.
Cause-and-Effect and Linear Relationships
One source of misconception of statistics in the area of correlation and regression is
the inference of a cause-and-effect relationship between characteristics from the
appearance of a string linear relationship.
When anyone states, Studies show that A is a cause of B and some statistics back it
up, be ready to reply, Correlation does not imply causation. Always be on the lookout for
what lurks beneath the data.
Examples:
1. Sleeping with one's shoes on is strongly correlated with waking up with a headache.
Therefore, sleeping with one's shoes on causes headache.
The above example commits the correlation-implies-causation fallacy, as it prematurely concludes
that sleeping with one's shoes on causes headache. A more plausible explanation is that both are
caused by a third factor, in this case going to bed drunk, which thereby gives rise to a correlation. So
the conclusion is false.
JDEUSTAQUIO
167
2. Young children who sleep with the light on are much more likely to develop myopia in
later life. Therefore, sleeping with the light on causes myopia.
This is a scientific example that resulted from a study at the University of Pennsylvania Medical
Center. Published in the May 13, 1999 issue of Nature, the study received much coverage at the time
in the popular press. However, a later study at Ohio State University did not find that infants
sleeping with the light on caused the development of myopia. It did find a strong link between
parental myopia and the development of child myopia, also noting that myopic parents were more
likely to leave a light on in their children's bedroom. In this case, the cause of both conditions is
parental myopia, and the above-stated conclusion is false.
3. As ice cream sales increase, the rate of drowning deaths increases sharply. Therefore,
ice cream consumption causes drowning.
The aforementioned example fails to recognize the importance of time and temperature in
relationship to ice cream sales. Ice cream is sold during the hot summer months at a much greater
rate than during colder times, and it is during these hot summer months that people are more likely
to engage in activities involving water, such as swimming. The increased drowning deaths are
simply caused by more exposure to water-based activities, not ice cream. The stated conclusion is
false.
4. Since the 1950s, both the atmospheric CO2 level and obesity levels have increased
sharply. Hence, atmospheric CO2 causes obesity.
Richer populations tend to eat more food and consume more energy
5. HDL ("good") cholesterol is negatively correlated with incidence of heart attack.
Therefore, taking medication to raise HDL will decrease the chance of having a heart
attack.
Further research has called this conclusion into question. Instead, it may be that other underlying
factors, like genes, diet and exercise, affect both HDL levels and the likelihood of having a heart
attack; it is possible that medicines may affect the directly measurable factor, HDL levels, without
affecting the chance of heart attack.
These conclusions are example of spurious (false) correlation. It simply means that
two variables are correlated due to some other variable that is related to both the former
variables.
JDEUSTAQUIO
168
Example:
1. Apply the least squares method to the given dataset on the Drug Evaluation Study
Solution:
Computations for the Least Squares Line
Dosage
(x)
Duration of Relief
(y)
x
2
xy
3 9 9 27 7.15
3 5 9 15 7.15
4 12 16 48 9.89
5 9 25 45 12.63
6 14 36 84 15.37
6 16 36 96 15.37
7 22 49 154 18.11
8 18 64 144 20.86
8 24 64 192 20.86
9 22 81 198 23.60
Sum 59 151 389 1003 151
5.9
15.1
()
() ()()
()()
Thus, the estimated regression line is given by: .
0
5
10
15
20
25
30
2 3 4 5 6 7 8 9 10
D
u
r
a
t
i
o
n
o
f
R
e
l
i
e
f
Dosage
Scatter Diagram of Dosage (x) against Duration of
Relief (y)
JDEUSTAQUIO
169
2. Suppose that the following data were collected on emphysema patients: the number of
years the patient smoked (x) and a physicians evaluation of the patients lung capacity
(y) (measured on a scale of 0 to 100). The results for a sample of ten patients appear in
the accompanying table:
Patient Years of Smoking
(X)
Lung Capacity
(Y)
1 25 55
2 36 60
3 22 50
4 15 30
5 48 75
6 39 70
7 42 70
8 31 55
9 28 30
10 33 35
i. Plot the data on a scatter diagram.
ii. Use the method of least squares to estimate the regression line.
iii. Predict a persons lung capacity after 30 years of smoking.
Solution:
For (i), the scatter plot is given below:
y = 1.3092x + 11.238
0
10
20
30
40
50
60
70
80
10 20 30 40 50
L
u
n
g
C
a
p
a
c
i
t
y
Years of Smoking
Scatter Diagram of Years of Smoking vs. Lung Capacity
JDEUSTAQUIO
170
6.3 Diagnostic Checking for Regression
The individual deviations of the observations y
i
from the fitted values are called the
residuals, and we denote these by e
i
. That is;
Remarks:
1. The residuals are not viewed as the estimates of the error terms
i
s, however, they are
important since their values are used to check the assumptions of the regression model.
2. Although some residuals are positive and some negative, a property of the least squares
fit/estimates is that the sum of the residuals is always zero.
3. The residual sum of squares is also called the sum of the squares due to error and is
abbreviated as SSE.
4. An estimate of the error variance o
2
is obtained by dividing SSE by n-2. The reduction by
tow is because two degrees of freedom are lost from estimating the two parameters
0
and
1
.
Example (Drug Evaluation Study cont.): Using the data from the Drug Evaluation Study,
compute for the estimate of the error.
Solution:
y
i
9 5 12 9 14 16 22 18 24 22
7.15 7.15 9.89 12.63 15.37 15.37 18.11 20.86 20.86 23.60
e
i
1.85 -2.15 2.11 -3.63 -1.37 0.63 3.89 -2.86 3.14 -1.60
so that,
()
()
()
6.3.1 Residual and Error Variance Estimate
JDEUSTAQUIO
171
In terms of the sum of squares of X and Y,
()
()
It is important to remember that the line
obtained by the principle of
least squares is an estimate of the unknown true regression line. In our drug evaluation
problem, the estimated line is
Its slope 2.74 suggests that the mean duration of relief increases by 2.74 days for each
unit dosage of the drug. Also, if we were to estimate the mean or expected duration of relief
for a specified dosage x=4.5 mg, we would naturally use the fitted regression line to calculate
the estimate -1.07+2.74(4.5) = 11.26 days. A few questions concerning these estimates
naturally arise at this point.
1. In light the value 2.74 for
, could the slope
1
of the true regression line be as much
as 4? Could it be zero so that the true regression line is y =
0
, which does not depend
on x? What are the plausible values for
1
.
2. How much uncertainty should be attached to the estimated duration of 11.26 days
corresponding to the given dosage x = 4.5?
To answer these and other related questions, we must know something about the
sampling distribution of the least squares estimators. These sampling distributions will enable
us to test the hypotheses and set confidence intervals for the parameters
0
and
1
that
determine the straight line and for the straight line itself.
Again, the t-distribution would be used.
6.3.2 Inferences on
1
and
0
(Test of Significance)
JDEUSTAQUIO
172
Inferences Concerning the Slope
1
The standard error of the least squares estimator
is
(
and the estimated standard error is given by
(
(i) To test H
0
:
1
= 0 vs.
1
=0, use the test statistic
)
and reject H
0
when |t| t
/2, n-2
(ii) A (1-)100% confidence interval for
1
is
(
n
(
))
where t
/2, n-2
is the upper /2 point of the t-distribution with n-2 degrees of freedom
Inferences Concerning the Intercept
0
The standard error of the least squares estimator
is
(
and the estimated standard error is given by
(
(i) To test H
0
:
0
= 0 vs.
0
=0, use the test statistic
)
and reject H
0
when |t| t
/2, n-2
(ii) A (1-)100% confidence interval for
0
is
(
n
(
))
where t
/2, n-2
is the upper /2 point of the t-distribution with n-2 degrees of freedom
JDEUSTAQUIO
173
Example:
1. Do the data on the Drug Evaluation Study constitute strong evidence that the intercept
and the slope are both significantly different from zero?
Solution:
For
1
, we are to test the null hypothesis H
0
:
1
= 0 against the alternative
hypothesis H
a
:
1
= 0. The test statistic is given by:
(
Since t=6.21 t
/2, n-2
, we conclude that
1
is significantly different from zero and
that the duration of relief tends to vary linearly (in this case, increasing) with the
dosage of the drug over the range of values considered in the study.
For
0
, we are to test the null hypothesis H
0
:
0
= 0 against the alternative
hypothesis H
a
:
0
= 0. The test statistic is given by:
(
()
Since t= |-0.3888| t
/2, n-2
, we accept the null hypothesis that the intercept is
not significantly different from zero. Anyway, the parameter
0
is of little
importance to us because the range of x values covered in the experiment was 3 to
9 and it would be unrealistic to extend the line to x=0.
2. Do the data on the Smoking and Lung Capacity Study constitute strong evidence that
the intercept and the slope are both significantly different from zero?
Solution:
For
1
, we are to test the null hypothesis H
0
:
1
= 0 against the alternative
hypothesis H
a
:
1
= 0. The test statistic is given by:
(
Conclusion?
For
0
, we are to test the null hypothesis H
0
:
0
= 0 against the alternative
hypothesis H
a
:
0
= 0. The test statistic is given by:
(
()
, Conclusion?
JDEUSTAQUIO
174
To arrive at a measure of adequacy of the straight-line model, we examine how
much of the variation in the response variable is explained by the fitted regression line. To
this end, we view an observed y
i
as consisting of two components:
or in terms of the estimated regression model,
Recall that the purpose of regression is to explain the variability of the dependent
variable Y using the variability of the independent variable x. The total variability of the y-
values is reflected in the sum of squared deviations from their mean, that is
(
Using the formula for SSE,
we have,
DECOMPOSTION OF VARIABILITY
6.3.3 The Coefficient of Determination
observed
value
part explained by the
linear relation
part unaccounted
by the linear relation
observed
value
predicted value residual
Total
Variability
Unexplained Variability/
Variability due to other factors
Variability explained
by the Linear relation
JDEUSTAQUIO
175
Remarks:
1. The first term on the right-hand side of the equation is called the sum of squares due
to linear regression (SSR). Likewise, S
YY
is also called the total sum of squares of Y
(SST).
2. In order for the straight-line model to be considered as providing a good fit of the
data, SSR should comprise a large portion of SST.
3. As an index of how well the straight-line model fits, its reasonable to consider the
proportion of the y-variability explained by the linear relation.
Definition: The Coefficient of Determination, denoted by R
2
, is given by;
It is the proportion of variation in Y that can be attributed to a linear relationship
between X and Y.
Example:
1. Let us consider the drug evaluation data given in the previous sections. From our
earlier computations,
S
YY
= 370.9 S
XX
= 40.9 S
XY
= 112.1
The coefficient of determination is given by;
()
()()
2. For the lung capacity data,
) .
/
JDEUSTAQUIO
176
Remark: When the value of R
2
is small, we can only conclude that a straight-line relation
does not give a good fit to the data. Such a case may arise due to the following
reasons:
i. There is little relation between the variables in the sense that the scatter
diagram fails to exhibit any pattern. In this case, the use of a different
regression model is not likely to reduce the SSE or explain a substantial part of
SST.
ii. There is prominent relation but it is nonlinear in nature, that is, the scatter
diagram is banded more around a curve than a line. The part of SST that is
explained by a straight-line regression is small because the model is
inappropriate. Some other relationship may improve the fit substantially.
JDEUSTAQUIO
177
Assignment 1:
Classify each statement according to the level of measurement used to get the value 7:
1) Teddy measured the temperature of the object as 7.
2) Teddy has a score of 7 in the Stat Quiz.
3) Teddys basketball shirt number is 7.
4) Teddys shoe size is 7.
5) Teddy has 7 cousins.
What method of data collection is most appropriate for the ff. cases (survey, experiment,
observation):
6) Studying two groups of patients and determining if exercise lowers the blood
pressure.
7) A group of medical intern students studies the effects of laughter to patients in a
hospital.
8) An NGO compares the household expenditures in Quezon City.
9) A car manufacturer studies the preference of cars for the next production.
10) The DOH evaluates the benefits of the family planning methods given to a certain
community.
Exercise 1: Construct the Frequency Distribution Table of the Final Grades of the 92 Stat
101 Students last Semester of the.
68 68 95 88 84 43 74 80 76 68
81 80 92 79 71 90 76 78 64 75
80 65 79 67 90 84 71 71 78
76 95 81 77 44 50 65 70 70
96 18 91 83 47 66 43 84 62
83 83 68 32 62 91 77 72 82
60 81 82 70 73 83 83 72 75
66 88 56 86 53 93 76 93 61
83 96 77 90 92 85 80 75 82
78 18 84 65 76 70 89 93 70
JDEUSTAQUIO
178
Assignment 2: Compute for the Variance and Standard deviation of height, weight and
BMI
Exercise 2: Compute the Skewness of each of the THREE data sets (A, B, and C).
A
B
C
68 74 78 80 85
58 76 86 89 92
58 70 71 80 93
68 74 79 80 86
59 76 87 89 92
59 70 71 81 94
69 75 79 81 87
59 76 87 89 92
59 70 71 83 94
69 75 79 82 87
59 76 87 89 93
59 70 72 84 94
69 75 79 82 88
61 76 88 90 93
64 69 72 84 94
70 76 79 83 89
62 76 88 90 94
64 69 72 85 94
71 76 79 83 89
63 76 88 90 97
64 69 73 85 97
71 77 79 83 89
64 77 88 91 98
64 69 73 85 98
72 78 79 84 90
65 77 88 91 98
66 70 73 86 98
73 78 80 84 90
66 78 88 92 98
66 71 74 86 98
Mean = 79
Mean = 82
Mean = 77
Exercise 3:
I.
the probabilities of the following events:
a) AB
b) BA
c
c) (AB)
c
d) AB
c
e) (AB
c
) (BA
c
)
f) A
c
B
c
II. A die is loaded so that all the numbers have the same chances of occurrence except for
a 6 whose chance of coming up is three times the chance of any other number coming
up. Find the probabilities of the following events: (Hint consider 8 possible outcomes)
a) Event that a 6 comes up in a single toss.
b) Event of observing an even number in a single toss
c) Event of observing a number less than 5 in a single toss
JDEUSTAQUIO
179
III. Three methods, A, B and C are available for teaching a certain industrial skill. Only one
of these methods used in teaching a particular worker. The failure rate is 20% for
method A, 10% for method B, and 30% for method C. However, method B is a lot
more expensive and hence is used only 10% of the time while method C is very cheap
and is used 50% of the time. Suppose a worker was selected at random and failed to
learn the skill correctly, what is the probability that the worker was taught using
method C?
IV. Suppose that 30% of the licensed drivers in Metro Manila are incompetent. Suppose
also that a diagnostic test is available. If a randomly selected driver is incompetent,
the probability that the test will so indicate is 0.9; and if the selected driver is
competent, the probability that the test will so indicate is 0.85.
a) Given that the test indicates that a particular driver is incompetent, what is the
probability that the test is correct?
b) Given that the test indicates that a particular driver is competent, what is the
probability that the test is wrong?
V. The probability that a Japanese industry will locate in Cebu is 0.7. The probability that
it will locate in Bataan is 0.3, and the probability that it will locate in at least one of the
two provinces is 0.79. Define A = event that a Japanese industry will locate in Cebu and
B = event that a Japanese industry will locate in Bataan. Are A and B independent
events? Justify your answer by showing that the condition/s of independence is/are
satisfied or not satisfied.
VI. Suppose that a computer contains 6 boards, 2 of which are defective and the
remaining 4 boards are non-defective. Four boards are selected randomly and each
one is examined to determine if it is defective or not. Define X = number of defective
boards in a sample of size 4.
a) Construct the probability mass function of X.
b) Use the PMF derived in (a) to compute for the probability that the sample
selected will contain only 1 defective board.
c) Use the PMF derived in (a) to compute for the probability that the sample
selected will contain at least 1 defective board.
VII. The CDF of a continuous random variable X is as follows:
() {
Find the following probabilities using this CDF:
a) P(X > 0.25)
b) P (0.3 < X < 0.7)
c) P(0.4 X 1.250
JDEUSTAQUIO
180
VIII. Suppose a gambler wins 50 PhP if the sum of dots in a toss of a pair of fair dice is
either 7 or 11, and loses 10 PhP, otherwise. Find the expected gain/loss.
IX. A wines distinctive taste is a result of ageing it in wooden casks. Some of the wine
evaporates while it is aging in the porous wooden casks. Some of the wine evaporates
while it is aging in the porous wooden casks. Define X = percentage of wine in the cask
that is lost due to evaporation. Suppose X is normally distributed with mean 5% and a
standard deviation of 1%. What is the probability of losing more than 7.5% of the wine
due to evaporation?
X. Suppose that the IQs of applicants of a certain science high school follow a normal
distribution with mean of 120 and a standard deviation of 9.
a) One of the requirements of the school in accepting a student is that the
students IQ must be at least 115. What proportion of the applicants will be
rejected on the basis of their IQ?
b) What is the 97.5
th
percentile IQ of the applicants?
Assignment 3:
I. Suppose the measures of the 40 elements in the population are as follows:
Element x Element x Element x Element x
1 2 11 22 21 42 31 62
2 4 12 24 22 44 32 64
3 6 13 26 23 46 33 66
4 8 14 28 24 48 34 68
5 10 15 30 25 50 35 70
6 12 16 32 26 52 36 72
7 14 17 34 27 54 37 74
8 16 18 36 28 56 38 76
9 18 19 38 29 58 39 78
10 20 20 40 30 60 40 80
Suppose we select a sample of size 4 from this population using systematic sampling. If
n=4 then the sampling interval is k=40/4=10. There will be only 10 possible samples if we
use systematic sampling and we will be giving each one of these samples the same
chances of selection.
a.) List down all of the 10 possible samples.
b.) Construct the sampling distribution of .
c.) Determine E( ) and Var( ).
JDEUSTAQUIO
181
II. Suppose the mean monthly income, , of the households in the exclusive subdivisions
in Metro Manila is 200,000PhP with a standard deviation o = 150,000PhP. What is the
probability of selecting a random sample of 100 families whose mean monthly income is
larger than 250,000PhP?
III. Let (X
1
, X
2
, . . ., X
n
) be a random sample. Find the value of c that satisfies the condition
that P(-c < <c ) is approximately equal to 0.95 for each of the following conditions:
a.) the sample size n = 100 and the population mean is = 6 and variance is o
2
=
42.25.
b.) the sample size is n=25 and the population is normally distributed with =6 and
variance o
2
= 42.25.
c.) the sample size is n=25 and the population is normally distributed with =6 but
the variance o
2
is unknown and is estimated by the sample variance S
2
=42.25.
Assignment 4:
I. Laboratory tests of bacterial counts are often used for declaring a water source
polluted. Suppose that the distribution of bacterial counts in a sample taken from a
certain lake is normally distributed with a variance of 9,000,000.
a.) Suppose 25 water samples were taken over the course of July 2004 and yielded
a mean count of 12,000. Construct an 80% confidence interval estimate of the
unknown mean bacterial count in this lake at this time.
b.) In July 2005, another set of water samples was taken from the same lake and
noted a bacterial count of 14,000. Is this an evidence of pollution effect? Explain
your answer.
II. According to a 1984 American study, about one in three individuals feels shopping is an
unpleasant experience (Journal of Marketing Research February/March 1984). Suppose we
take a national sample of 4,100 Filipino male and female adults, and we determine each
respondents opinion on the pleasantness of shopping. The survey produced the
following results:
Males Females
Sample Size 2,015 2,085
Number who think shopping is
an unpleasant experience
850 570
a.) Compute a 95% confidence interval for the proportion of males in the sample
who think shopping is an unpleasant experience.
b.) Compute a 95% confidence interval for the proportion of females in the sample
who think shopping is an unpleasant experience.
JDEUSTAQUIO
182
c.) Which group appears to dislike shopping more? Explain your answer.
III. If you wanted to estimate the proportion of births which are girls to within 0.01 with
90% confidence, what sample size would be necessary? How large must the sample size
be for 95% confidence? How large must the sample size be for 99% confidence?
IV. What can you conclude about the relationship of the sample size with the confidence
coefficient?
Assignment 5:
I. An experiment was conducted to determine whether different baking times produce different
rises of chocolate chip muffins. Twenty four muffins were baked for 20 minutes and the rise of
each muffin was recorded. Another set of 20 muffins were baked for 25 minutes and the rise of
each muffin was also recorded. The data, in centimeters, are given below.
20 minutes 25 minutes
2.8 3.0 2.8 3.1
3.0 3.1 2.7 3.1
3.1 3.0 2.9 3.0
2.9 3.1 2.9 3.1
2.7 3.0 3.1 3.1
2.6 3.1 3.0 3.0
2.6 3.0 2.6 3.0
2.8 3.2 2.7 3.1
2.7 3.1 2.8
2.6 3.0 2.7
2.8 3.0 2.8
2.9 3.1 2.8
Provide a point estimate for the difference in the mean rise of a chocolate chip muffin between
those baked for 20 minutes and those baked for 25 minutes.
II. Using the data on the previous question, Provide a 99% confidence interval estimate of the
difference between the mean rise of muffins baked for 20 minutes and those baked for 25
minutes. Assume the normality of the data.
III. Consider the data on the number of births per 1,000 populations in African and Asian countries
indicated below.
a.) Estimate the proportion of African countries with number of births greater than 30,000.
b.) Estimate the proportion of Asian countries with number of births greater than 30,000.
c.) Find a 95% confidence interval for the difference of population proportions of countries
with number of births greater than 30,000.
JDEUSTAQUIO
183
Births (per 1,000 population)
African Countries Asian Countries
Algeria 20 Armenia 10
Benin 41 Brunei 22
Botswana 27 China 12
Burkina Faso 45 Georgia 11
Cameroon 37 India 25
Cape Verde 29 Indonesia 22
Chad 49 Iran 18
Comoros 47 Japan 9
Eritrea 39 Kuwait 18
Ethiopia 41 Kyrgyzstan 21
Gambia 41 Lebanon 23
Guinea-Bissau 50 Malaysia 26
Lesotho 33 Maldives 18
Libya 28 Mongolia 18
Madagascar 43 Myanmar 25
Malawi 51 Nepal 34
Mali 50 North Korea 17
Mauritius 16 Oman 26
Mayotte 41 Pakistan 34
Senegal 37 Philippines 26
Seychelles 18 Qatar 20
Sudan 38 Syria 28
Togo 38 Turkey 21
Tunisia 17 UAE 16
Zambia 42 Uzbekistan 24
IV. Discuss Briefly: Differentiate sampling independently from two populations from paired
sampling from two populations.
JDEUSTAQUIO
184
Exercise 4:
I. A mortgage type of loan that is secured by a designated piece of property. If the borrower
defaults on the loan, the lender can sell the property to recover the outstanding debt. The
following data are outstanding principal balance of home mortgages foreclosed by the bank
due to default by the borrower during the last 3 years obtained from a random sample of 12
foreclosed mortgages:
95,982 81,422 39,888 46,836 66,899 69,110
59,200 62,331 105,812 55,545 56,635 72,123
Test the claim that the average outstanding balance of home mortgages is less than
80,000 using a 0.05 level of significance.
II. The manager of the credit department for an oil company would like to determine whether the
average monthly balance of credit card holders is higher than 3,000 PhP. An auditor randomly
samples 150 accounts and finds that the average owed is 4,170 PhP with a standard deviation of
1,182.50 PhP. Using 0.05 level of significance, can the auditor conclude that there is evidence
that the average monthly balance is really higher than 3,000 PhP.
III. A television manufacturer claims in its warranty that in the past, less than 15% of its television
sets needed any repair during their first two years of operation. In order to test the validity of
this claim, a government testing agency selects a sample of 100 sets and finds that 12 sets
requires some repair within their first two years of operation. Is the manufacturers claim
valid? Test at 0.01 level of significance.
IV. Consider the cellphone data usage below:
a) Test the claim that the average monthly expense on cellphone use of more than half
of the female undergraduate students in UPD is at least 500 PhP. Use = 0.05.
b) Test the claim that the average monthly expense on cellphone use of more than half
of the male undergraduate students in UPD is at least 500 PhP. Use = 0.05.
Average Monthly Expense on Cellphone Use Among
Females
8000 1000 600 500 300 250
4000 1000 600 500 300 250
2300 1000 600 500 300 250
2000 1000 600 500 300 250
2000 1000 600 500 300 250
2000 1000 600 500 300 225
2000 900 600 500 300 200
2000 900 600 500 300 200
1800 900 560 500 300 200
1700 900 550 500 300 200
1500 900 550 500 300 200
JDEUSTAQUIO
185
1500 900 500 500 300 200
1500 900 500 500 300 200
1500 900 500 500 300 200
1400 900 500 500 300 125
1200 800 500 500 300 250
1200 800 500 500 300 250
1200 750 500 500 300 250
1200 750 500 500 300 250
1100 750 500 500 300 250
1100 750 500 500 275 250
1000 750 500 500 250 250
1000 750 500 500 250 225
1000 700 500 500 250 200
1000 700 500 400 250 200
1000 700 500 400 250 250
1000 600 500 400 250 250
1000 600 500 400 250 250
1000 600 500 400 250 250
1000 600 500 400 250
1000 600 500 300 250
1000 600 500 300 250
1000 600 500 300 250
1000 600 500 300 250
1000 600 500 300 250
Average Monthly Expense on Cellphone Use Among Males
3000 900 500 500 300 250
2500 750 500 500 300 250
2000 750 500 400 300 250
1500 700 500 350 300 250
1462 600 500 300 300 250
1200 600 500 300 300 150
1000 600 500 300 300 125
1000 600 500 300 300 100
1000 600 500 300 300 100
1000 600 500 300 275 100
1000 600 500 300 270 250
1000 600 500 300 250 250
1000 600 500 300 250 250
1000 500 500 300 250 250
1000 500 500 300 250 250
900 500 500 300 250
JDEUSTAQUIO
186
Exercise 5:
I. Consider the data on seating capacity in cinemas in European countries in 1997 and 1999.
Test the hypothesis that the mean seating capacity in cinemas has increased by more
than 5,000 from 1997 to 1999. Use the 0.01 level of significance. What assumptions did
you make in testing this hypothesis?
Seating Capacities in Cinemas (in thousands)
European
Country
Year
1997 1999
Croatia 53 52
Czech Republic 300 292
Denmark 51 52
Germany 772 801
Iceland 10 9
Latvia 23 26.1
Lithuania 28.2 26.1
Luxembourg 26 21
Norway 90.1 89
Poland 200 211
Portugal 97.1 143
Romania 149 129
Slovakia 83.6 95.3
Slovenia 27 24
Switzerland 110.9 230.8
II. In a study made by Cain, Oakhill, and Lemmon (2005), the ability of participants to read
and understand written words out of sentence context (Gates-MacGinitie Primary Two
Vocabulary Test), and word reading accuracy in context and reading comprehension
(Neale Analysis of Reading Ability) were among several characteristics measured in 28
participants. Two groups participated in the study: 14 good comprehenders and 14 poor
comprehenders. The following table shows the summary:
Characteristics
Good Comprehenders Poor Comprehenders
Mean Standard Deviation Mean Standard Deviation
Gates-MacGinitie Vocabulary
34.2 2.75 34 2.04
Neale Analysis Word Reading Accuracy 10.6 7.05 10.7 6.97
JDEUSTAQUIO
187
At 0.05 level of significance, determine whether the mean performance of good
and poor comprehenders differ in each of the three characteristics. Assume normality
of both.
III. In 1999, a study showed that in a sample of 2,200 students enrolled at the tertiary
level in the Philippines, 54.91% are females. In the same year, in a sample of 1,701
students enrolled at the tertiary level in Bangladesh, only 32.33% are females. Is there
sufficient evidence to conclude that the proportion of females receiving tertiary
education is higher in the Philippines than in Bangladesh? Test at 0.05 level of
significance.
IV. In 2001, a sample of 1,980 illiterate individuals from country A showed that 1,236 of
these individuals are females. In the same year, a sample of 2,108 illiterate individuals
from country B showed that 1,209 of these individuals are females. Can we conclude
that the proportions of females among illiterate individuals are different for the two
countries? Test at 0.05 level of significance.
V. In a sample of 160 students enrolled in private schools, 60 were found to be smokers.
In a sample of 650 students enrolled in public schools, 115 were found to be smokers.
Is there sufficient evidence to conclude that there is a higher proportion of student
smokers in private schools than in public schools? Test at 0.01 level of significance.
Assignment 6:
I. How many cells may be allowed to have expected frequencies less than 5 (but at least 1) for the
chi-square test for independence to be valid if you have a contingency table of dimension?
a) 2 x 2
b) 2 x 3
c) 3 x 5
d) 4 x 4
e) 5 x 5
II. The following data is a tabulation of the nature of work of working children and job satisfaction.
The summarized data came from the masteral thesis by Viria (2002).
Job Satisfaction
Nature of Work
Permanent Non-permanent
Satisfied with Job 1145 3026
Not Satisfied 267 1215
Test at 0.05 level of significance if nature of work and job satisfaction are related.
Viria also summarized data on the nature of work of working children and present
preference, whether they want to study or to work as shown below:
JDEUSTAQUIO
188
Present Preference
Nature of Work
Permanent Non-permanent
To Study 736 3311
To work 676 930
Test at 0.05 level of significance if nature of work and preference to study or work are
related.
III. The following table was part of the results of a pilot project conducted by the Nutrition Center
of the Philippines in Bauan, Batangas, on the development of an anemia control program.
Perform a test for independence on the summarized data using the 0.05 level of significance. The
data is obtained from Mendoza et al. (2000).
Classification of
Subjects
Nutritional Status
Normal 1
0
Malnourished 2
0
Malnourished 3
0
Malnourished
Normal 332 531 122 11
Anemic 198 404 217 23
Exercise 6:
The data below refers to the amount of Greenhouse gas emission (Greenhouse), number of
disposal sites for solid wastes to be recycled of the states (Landfill) and emission of sulfur
dioxide and nitrogen oxide measured in thousand tons (Acid) of 30 states in the US.
US State Landfill Acid Greenhouse
1 108 954.2 129.0
2 64 217.5 62.4
3 140 94.9 72.3
4 3 158.6 14.2
5 170 1135.8 167.4
6 180 1397.6 145.4
7 76 2526.2 217.1
8 82 388.6 68.5
9 115 330.8 70.8
10 34 1174.7 109.6
11 31 1008.9 172.9
12 30 491.1 77.9
13 139 362.1 89.9
14 55 833.7 181.5
15 53 316.2 83.1
16 75 238.2 51.0
17 78 1412.1 112.8
18 36 164.1 39.6
JDEUSTAQUIO
1
19 110 94.9 21.0
20 153 466.4 54.2
21 47 326.4 43.5
22 87 3320.3 255.2
23 130 332.3 90.7
24 44 1815.7 254.6
25 9 1307.7 110.2
26 750 2407.5 459.0
27 30 135.6 42.8
28 39 1341.8 95.9
29 150 545.2 99.9
30 80 164.5 54.8
I. Using the variables Landfill and Greenhouse:
a.) Plot a scatter diagram of the data on the amount of greenhouse gas emission and number
of disposal sites for solid wastes (greenhouse takes the y-axis). Does there appear to be a
linear relationship between the two variables?
b.) Compute for the Pearson correlation coefficient. What conclusion can you draw based on
the value of the correlation coefficient?
c.) Test whether is different from 0 using 0.05 level of significance.
d.) Fit a regression model using the two variables with greenhouse as the dependent variable.
e.) Compute for the coefficient of determination. Does the data have a good fit with the data?
II. Using the variables Acid and Greenhouse:
a) Plot a scatter diagram of the data on the amount of greenhouse gas emission and acid
precipitation precursor of the states (greenhouse takes the y-axis). Does there appear to be
a linear relationship between the two variables?
b) Compute for the Pearson correlation coefficient. What conclusion can you draw based on
the value of the correlation coefficient?
c) Test whether is different from 0 using 0.05 level of significance.
d) Fit a regression model using the two variables with greenhouse as the dependent variable.
e) Compute for the coefficient of determination. Does the data have a good fit with the data?
JDEUSTAQUIO
2
Areas Under the Standard Normal Distribution: P(Z < z)=
Z 0.0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359
0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753
0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141
0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517
0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879
0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224
0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549
0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852
0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133
0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389
1.0 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621
1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830
1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015
1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177
1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319
1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441
1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545
1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633
1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9699 0.9706
1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.9750 0.9756 0.9761 0.9767
2.0 0.9772 0.9778 0.9783 0.9788 0.9793 0.9798 0.9803 0.9808 0.9812 0.9817
2.1 0.9821 0.9826 0.9830 0.9834 0.9838 0.9842 0.9846 0.9850 0.9854 0.9857
2.2 0.9861 0.9864 0.9868 0.9871 0.9875 0.9878 0.9881 0.9884 0.9887 0.9890
2.3 0.9893 0.9896 0.9898 0.9901 0.9904 0.9906 0.9909 0.9911 0.9913 0.9916
2.4 0.9918 0.9920 0.9922 0.9925 0.9927 0.9929 0.9931 0.9932 0.9934 0.9936
2.5 0.9938 0.9940 0.9941 0.9943 0.9945 0.9946 0.9948 0.9949 0.9951 0.9952
2.6 0.9953 0.9955 0.9956 0.9957 0.9959 0.9960 0.9961 0.9962 0.9963 0.9964
2.7 0.9965 0.9966 0.9967 0.9968 0.9969 0.9970 0.9971 0.9972 0.9973 0.9974
2.8 0.9974 0.9975 0.9976 0.9977 0.9977 0.9978 0.9979 0.9979 0.9980 0.9981
2.9 0.9981 0.9982 0.9982 0.9983 0.9984 0.9984 0.9985 0.9985 0.9986 0.9986
3.0 0.9987 0.9987 0.9987 0.9988 0.9988 0.9989 0.9989 0.9989 0.9990 0.9990
3.1 0.9990 0.9991 0.9991 0.9991 0.9992 0.9992 0.9992 0.9992 0.9993 0.9993
3.2 0.9993 0.9993 0.9994 0.9994 0.9994 0.9994 0.9994 0.9995 0.9995 0.9995
3.3 0.9995 0.9995 0.9995 0.9996 0.9996 0.9996 0.9996 0.9996 0.9996 0.9997
3.4 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9998
JDEUSTAQUIO
3
Areas Under the Standard Normal Distribution: P(Z < z)=
Z 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
-0 0.5 0.496 0.492 0.488 0.484 0.4801 0.4761 0.4721 0.4681 0.4641
-0.1 0.4602 0.4562 0.4522 0.4483 0.4443 0.4404 0.4364 0.4325 0.4286 0.4247
-0.2 0.4207 0.4168 0.4129 0.409 0.4052 0.4013 0.3974 0.3936 0.3897 0.3859
-0.3 0.3821 0.3783 0.3745 0.3707 0.3669 0.3632 0.3594 0.3557 0.352 0.3483
-0.4 0.3446 0.3409 0.3372 0.3336 0.33 0.3264 0.3228 0.3192 0.3156 0.3121
-0.5 0.3085 0.305 0.3015 0.2981 0.2946 0.2912 0.2877 0.2843 0.281 0.2776
-0.6 0.2743 0.2709 0.2676 0.2643 0.2611 0.2578 0.2546 0.2514 0.2483 0.2451
-0.7 0.242 0.2389 0.2358 0.2327 0.2296 0.2266 0.2236 0.2206 0.2177 0.2148
-0.8 0.2119 0.209 0.2061 0.2033 0.2005 0.1977 0.1949 0.1922 0.1894 0.1867
-0.9 0.1841 0.1814 0.1788 0.1762 0.1736 0.1711 0.1685 0.166 0.1635 0.1611
-1 0.1587 0.1562 0.1539 0.1515 0.1492 0.1469 0.1446 0.1423 0.1401 0.1379
-1.1 0.1357 0.1335 0.1314 0.1292 0.1271 0.1251 0.123 0.121 0.119 0.117
-1.2 0.1151 0.1131 0.1112 0.1093 0.1075 0.1056 0.1038 0.102 0.1003 0.0985
-1.3 0.0968 0.0951 0.0934 0.0918 0.0901 0.0885 0.0869 0.0853 0.0838 0.0823
-1.4 0.0808 0.0793 0.0778 0.0764 0.0749 0.0735 0.0721 0.0708 0.0694 0.0681
-1.5 0.0668 0.0655 0.0643 0.063 0.0618 0.0606 0.0594 0.0582 0.0571 0.0559
-1.6 0.0548 0.0537 0.0526 0.0516 0.0505 0.0495 0.0485 0.0475 0.0465 0.0455
-1.7 0.0446 0.0436 0.0427 0.0418 0.0409 0.0401 0.0392 0.0384 0.0375 0.0367
-1.8 0.0359 0.0351 0.0344 0.0336 0.0329 0.0322 0.0314 0.0307 0.0301 0.0294
-1.9 0.0287 0.0281 0.0274 0.0268 0.0262 0.0256 0.025 0.0244 0.0239 0.0233
-2 0.0228 0.0222 0.0217 0.0212 0.0207 0.0202 0.0197 0.0192 0.0188 0.0183
-2.1 0.0179 0.0174 0.017 0.0166 0.0162 0.0158 0.0154 0.015 0.0146 0.0143
-2.2 0.0139 0.0136 0.0132 0.0129 0.0125 0.0122 0.0119 0.0116 0.0113 0.011
-2.3 0.0107 0.0104 0.0102 0.0099 0.0096 0.0094 0.0091 0.0089 0.0087 0.0084
-2.4 0.0082 0.008 0.0078 0.0075 0.0073 0.0071 0.0069 0.0068 0.0066 0.0064
-2.5 0.0062 0.006 0.0059 0.0057 0.0055 0.0054 0.0052 0.0051 0.0049 0.0048
-2.6 0.0047 0.0045 0.0044 0.0043 0.0041 0.004 0.0039 0.0038 0.0037 0.0036
-2.7 0.0035 0.0034 0.0033 0.0032 0.0031 0.003 0.0029 0.0028 0.0027 0.0026
-2.8 0.0026 0.0025 0.0024 0.0023 0.0023 0.0022 0.0021 0.0021 0.002 0.0019
-2.9 0.0019 0.0018 0.0018 0.0017 0.0016 0.0016 0.0015 0.0015 0.0014 0.0014
-3 0.0013 0.0013 0.0013 0.0012 0.0012 0.0011 0.0011 0.0011 0.001 0.001
-3.1 0.001 0.0009 0.0009 0.0009 0.0008 0.0008 0.0008 0.0008 0.0007 0.0007
-3.2 0.0007 0.0007 0.0006 0.0006 0.0006 0.0006 0.0006 0.0005 0.0005 0.0005
-3.3 0.0005 0.0005 0.0005 0.0004 0.0004 0.0004 0.0004 0.0004 0.0004 0.0003
-3.4 0.0003 0.0003 0.0003 0.0003 0.0003 0.0003 0.0003 0.0003 0.0003 0.0002
JDEUSTAQUIO
4
100(1-)
th
Percentiles of the t-Distribution: t
Degrees
of
Freedom
0.1 0.05 0.025 0.01 0.005
1 3.078 6.314 12.706 31.821 63.657
2 1.886 2.920 4.303 6.965 9.925
3 1.638 2.353 3.182 4.541 5.841
4 1.533 2.132 2.776 3.747 4.604
5 1.476 2.015 2.571 3.365 4.032
6 1.440 1.943 2.447 3.143 3.707
7 1.415 1.895 2.365 2.998 3.499
8 1.397 1.860 2.306 2.896 3.355
9 1.383 1.833 2.262 2.821 3.250
10 1.372 1.812 2.228 2.764 3.169
11 1.363 1.796 2.201 2.718 3.106
12 1.356 1.782 2.179 2.681 3.055
13 1.350 1.771 2.160 2.650 3.012
14 1.345 1.761 2.145 2.624 2.977
15 1.341 1.753 2.131 2.602 2.947
16 1.337 1.746 2.120 2.583 2.921
17 1.333 1.740 2.110 2.567 2.898
18 1.330 1.734 2.101 2.552 2.878
19 1.328 1.729 2.093 2.539 2.861
20 1.325 1.725 2.086 2.528 2.845
21 1.323 1.721 2.080 2.518 2.831
22 1.321 1.717 2.074 2.508 2.819
23 1.319 1.714 2.069 2.500 2.807
24 1.318 1.711 2.064 2.492 2.797
25 1.316 1.708 2.060 2.485 2.787
26 1.315 1.706 2.056 2.479 2.779
27 1.314 1.703 2.052 2.473 2.771
28 1.313 1.701 2.048 2.467 2.763
29 1.311 1.699 2.045 2.462 2.756
30 1.310 1.697 2.042 2.457 2.750
1.282 1.645 1.96 2.326 2.576
JDEUSTAQUIO
5
100(1-)
th
Percentiles of the Chi-Square Distribution:
2
Degrees
of
Freedom
0.995 0.99 0.975 0.95 0.9 0.1 0.05 0.025 0.01 0.005
1 0.000 0.000 0.001 0.004 0.016 2.706 3.841 5.024 6.635 7.879
2 0.010 0.020 0.051 0.103 0.211 4.605 5.991 7.378 9.210 10.597
3 0.072 0.115 0.216 0.352 0.584 6.251 7.815 9.348 11.345 12.838
4 0.207 0.297 0.484 0.711 1.064 7.779 9.488 11.143 13.277 14.860
5 0.412 0.554 0.831 1.145 1.610 9.236 11.070 12.833 15.086 16.750
6 0.676 0.872 1.237 1.635 2.204 10.645 12.592 14.449 16.812 18.548
7 0.989 1.239 1.690 2.167 2.833 12.017 14.067 16.013 18.475 20.278
8 1.344 1.646 2.180 2.733 3.490 13.362 15.507 17.535 20.090 21.955
9 1.735 2.088 2.700 3.325 4.168 14.684 16.919 19.023 21.666 23.589
10 2.156 2.558 3.247 3.940 4.865 15.987 18.307 20.483 23.209 25.188
11 2.603 3.053 3.816 4.575 5.578 17.275 19.675 21.920 24.725 26.757
12 3.074 3.571 4.404 5.226 6.304 18.549 21.026 23.337 26.217 28.300
13 3.565 4.107 5.009 5.892 7.042 19.812 22.362 24.736 27.688 29.819
14 4.075 4.660 5.629 6.571 7.790 21.064 23.685 26.119 29.141 31.319
15 4.601 5.229 6.262 7.261 8.547 22.307 24.996 27.488 30.578 32.801
16 5.142 5.812 6.908 7.962 9.312 23.542 26.296 28.845 32.000 34.267
17 5.697 6.408 7.564 8.672 10.085 24.769 27.587 30.191 33.409 35.718
18 6.265 7.015 8.231 9.390 10.865 25.989 28.869 31.526 34.805 37.156
19 6.844 7.633 8.907 10.117 11.651 27.204 30.144 32.852 36.191 38.582
20 7.434 8.260 9.591 10.851 12.443 28.412 31.410 34.170 37.566 39.997
21 8.034 8.897 10.283 11.591 13.240 29.615 32.671 35.479 38.932 41.401
22 8.643 9.542 10.982 12.338 14.041 30.813 33.924 36.781 40.289 42.796
23 9.260 10.196 11.689 13.091 14.848 32.007 35.172 38.076 41.638 44.181
24 9.886 10.856 12.401 13.848 15.659 33.196 36.415 39.364 42.980 45.559
25 10.520 11.524 13.120 14.611 16.473 34.382 37.652 40.646 44.314 46.928
26 11.160 12.198 13.844 15.379 17.292 35.563 38.885 41.923 45.642 48.290
27 11.808 12.879 14.573 16.151 18.114 36.741 40.113 43.195 46.963 49.645
28 12.461 13.565 15.308 16.928 18.939 37.916 41.337 44.461 48.278 50.993
29 13.121 14.256 16.047 17.708 19.768 39.087 42.557 45.722 49.588 52.336
30 13.787 14.953 16.791 18.493 20.599 40.256 43.773 46.979 50.892 53.672
S-ar putea să vă placă și
- Inferential StatisticsDocument16 paginiInferential Statisticsmalyn1218100% (2)
- Multivariate Analysis: Are Some of The Variables Dependent On Others?Document16 paginiMultivariate Analysis: Are Some of The Variables Dependent On Others?rahul100% (1)
- StatisticsDocument12 paginiStatisticsatifas20020% (3)
- Type I and Type II Errors PDFDocument5 paginiType I and Type II Errors PDFGulfam AnsariÎncă nu există evaluări
- Statistics Basic (1-3)Document37 paginiStatistics Basic (1-3)towfik sefaÎncă nu există evaluări
- Handbook of Parametric and Nonparametric Statistical Procedures PDFDocument972 paginiHandbook of Parametric and Nonparametric Statistical Procedures PDFPopa Andreea100% (3)
- Econometric Analysis of Health DataDocument231 paginiEconometric Analysis of Health DataMarisela FuentesÎncă nu există evaluări
- Student Study Guide and Solutions Chapter 1 FA14 PDFDocument7 paginiStudent Study Guide and Solutions Chapter 1 FA14 PDFJeff CagleÎncă nu există evaluări
- Statistics Books With AnswersDocument210 paginiStatistics Books With AnswersIrfanullah Jan75% (8)
- n = (40)2 × (1.282 + 1.96)2 / (-20)2 = 64So a sample size of at least 64 is neededDocument36 paginin = (40)2 × (1.282 + 1.96)2 / (-20)2 = 64So a sample size of at least 64 is neededPallavi ShettigarÎncă nu există evaluări
- I10064664-E1 - Statistics Study Guide PDFDocument81 paginiI10064664-E1 - Statistics Study Guide PDFGift SimauÎncă nu există evaluări
- Unit4 Fundamental Stat Maths2 (D)Document28 paginiUnit4 Fundamental Stat Maths2 (D)Azizul AnwarÎncă nu există evaluări
- R Programming IntroductionDocument20 paginiR Programming Introductionkeerthan reddyÎncă nu există evaluări
- Business StatisticsDocument123 paginiBusiness StatisticsCarla Tate100% (2)
- 2018 Book FoundationsOfBiostatistics PDFDocument474 pagini2018 Book FoundationsOfBiostatistics PDFferi100% (2)
- Hypothesis Testing - A Visual Introduction To Statistical SignificanceDocument137 paginiHypothesis Testing - A Visual Introduction To Statistical Significancekhundalini100% (2)
- SPSS Statistics 27 Step by Step Answers To Selected ExercisesDocument102 paginiSPSS Statistics 27 Step by Step Answers To Selected ExercisesSheraz MughalÎncă nu există evaluări
- STUDENT T-TestDocument20 paginiSTUDENT T-TestDr. M. Prasad NaiduÎncă nu există evaluări
- Lecture Notes for 36-707 Linear RegressionDocument228 paginiLecture Notes for 36-707 Linear Regressionkeyyongpark100% (2)
- Stac101 PDFDocument91 paginiStac101 PDFShanmukh SagarÎncă nu există evaluări
- The Dynamics of Disease TransmissionDocument18 paginiThe Dynamics of Disease TransmissionJ MÎncă nu există evaluări
- Hypothesis Testing Sept 2016Document54 paginiHypothesis Testing Sept 2016Somil GuptaÎncă nu există evaluări
- Correlation and RegressionDocument36 paginiCorrelation and Regressionanindya_kundu100% (3)
- Probability DistributionsDocument12 paginiProbability Distributionsyashar2500Încă nu există evaluări
- Data Visualization in R - With Cheat Sheets PDFDocument62 paginiData Visualization in R - With Cheat Sheets PDFbsrpropÎncă nu există evaluări
- On The Theory of Scales of Measurement - S. S. StevensDocument5 paginiOn The Theory of Scales of Measurement - S. S. StevensClases Particulares Online Matematicas Fisica Quimica100% (3)
- Sample Size Determination in Clinical TrialsDocument42 paginiSample Size Determination in Clinical TrialsRajabSaputraÎncă nu există evaluări
- Correlation and RegressionDocument48 paginiCorrelation and RegressionClyette Anne Flores BorjaÎncă nu există evaluări
- Parametric & Non-Parametric TestsDocument34 paginiParametric & Non-Parametric TestsohlyanaartiÎncă nu există evaluări
- Statistics in ActionDocument903 paginiStatistics in ActionSam92% (13)
- Data Analysis With SASDocument353 paginiData Analysis With SASVictoria Liendo100% (1)
- Hypothesis Testing & SPSSDocument34 paginiHypothesis Testing & SPSSRoshna VargheseÎncă nu există evaluări
- Bibliometrix PresentationDocument41 paginiBibliometrix Presentationdaksh gupta100% (1)
- Hypothesis Testing RoadmapDocument2 paginiHypothesis Testing RoadmapRam KumarÎncă nu există evaluări
- Exploratory Data Analysis - Komorowski PDFDocument20 paginiExploratory Data Analysis - Komorowski PDFEdinssonRamosÎncă nu există evaluări
- Pt1 Simple Linear RegressionDocument77 paginiPt1 Simple Linear RegressionradhicalÎncă nu există evaluări
- Parametric Statistical Analysis in SPSSDocument56 paginiParametric Statistical Analysis in SPSSKarl John A. GalvezÎncă nu există evaluări
- Standard ErrorDocument3 paginiStandard ErrorUmar FarooqÎncă nu există evaluări
- Dynamics of Disease TransmissionDocument23 paginiDynamics of Disease TransmissionAkshay SavvasheriÎncă nu există evaluări
- Stats Xi All Chapters PptsDocument2.046 paginiStats Xi All Chapters PptsAnadi AgarwalÎncă nu există evaluări
- Statistics With R 2014vb PDFDocument102 paginiStatistics With R 2014vb PDFkezudin1465Încă nu există evaluări
- Errors of Regression Models: Bite-Size Machine Learning, #1De la EverandErrors of Regression Models: Bite-Size Machine Learning, #1Încă nu există evaluări
- Statistics XIDocument332 paginiStatistics XIbhanu.chandu100% (1)
- SPSS Data Analysis: Drowning in DataDocument47 paginiSPSS Data Analysis: Drowning in DataDdy Lee100% (4)
- Non Parametrical Statics Biological With R PDFDocument341 paginiNon Parametrical Statics Biological With R PDFJhon ReyesÎncă nu există evaluări
- AP Statistics 1st Semester Study GuideDocument6 paginiAP Statistics 1st Semester Study GuideSusan HuynhÎncă nu există evaluări
- Business Research Method: Factor AnalysisDocument52 paginiBusiness Research Method: Factor Analysissubrays100% (1)
- RegressionDocument43 paginiRegressionNikhil AggarwalÎncă nu există evaluări
- ARCH ModelDocument26 paginiARCH ModelAnish S.MenonÎncă nu există evaluări
- Summary Statistics and Visualization Techniques To ExploreDocument30 paginiSummary Statistics and Visualization Techniques To ExploreMarshil ShibuÎncă nu există evaluări
- StatisticsDocument158 paginiStatisticsAarav AaravÎncă nu există evaluări
- Regression Analysis PDFDocument205 paginiRegression Analysis PDFandrew myintmyat100% (2)
- BusinessStatistics QTtS9FR8XcDocument195 paginiBusinessStatistics QTtS9FR8Xcpartha327350% (2)
- Regression Analysis Willey PublicationDocument15 paginiRegression Analysis Willey PublicationVikas20% (5)
- Understand StatisticsDocument146 paginiUnderstand StatisticsSaha2100% (5)
- Sampling Theory and MethodsDocument191 paginiSampling Theory and Methodsagustin_mx100% (4)
- Kent Marcial L. Catubis: Prepared By: Course InstructorDocument89 paginiKent Marcial L. Catubis: Prepared By: Course InstructorValerie UrsalÎncă nu există evaluări
- Mathematics in The Modern World: GEED 10053Document33 paginiMathematics in The Modern World: GEED 10053Hilo MethodÎncă nu există evaluări
- Chapter 1 Introduction To Statistics What Is Statistics?: PopulationDocument62 paginiChapter 1 Introduction To Statistics What Is Statistics?: PopulationAli HussainÎncă nu există evaluări
- CH.01.Nature of StatisticsDocument7 paginiCH.01.Nature of StatisticsHaider WaseemÎncă nu există evaluări
- A Review of Social Insurance in The Philippines - PIDsDocument22 paginiA Review of Social Insurance in The Philippines - PIDsSam CincoÎncă nu există evaluări
- Ch1 Why Study Banking & Financial InstitutionsDocument25 paginiCh1 Why Study Banking & Financial InstitutionsSam CincoÎncă nu există evaluări
- Scene 1-Room of Migs - Migs Getting Ready - Looks at The Necklace That He Bought For RoxDocument3 paginiScene 1-Room of Migs - Migs Getting Ready - Looks at The Necklace That He Bought For RoxSam CincoÎncă nu există evaluări
- Englcom FinalDocument4 paginiEnglcom FinalSam CincoÎncă nu există evaluări
- Englcom FinalDocument4 paginiEnglcom FinalSam CincoÎncă nu există evaluări
- Template For PrimerDocument1 paginăTemplate For PrimerSam CincoÎncă nu există evaluări
- Problem Set 2 - 1st Sem 2013 - 2014Document5 paginiProblem Set 2 - 1st Sem 2013 - 2014Sam CincoÎncă nu există evaluări
- Possible Questions For SiblingsDocument1 paginăPossible Questions For SiblingsSam CincoÎncă nu există evaluări
- We Are The Jar GroupDocument1 paginăWe Are The Jar GroupSam CincoÎncă nu există evaluări
- Topic 3: Philippine Society and CultureDocument1 paginăTopic 3: Philippine Society and CultureSam CincoÎncă nu există evaluări
- UP Pride Week 2013Document1 paginăUP Pride Week 2013Sam CincoÎncă nu există evaluări
- Land Based SensorsDocument40 paginiLand Based SensorsJ.MichaelLooneyÎncă nu există evaluări
- UNIT IV: Calculating Probability Using Fundamental ConceptsDocument15 paginiUNIT IV: Calculating Probability Using Fundamental ConceptsGaurav SonkarÎncă nu există evaluări
- Solution To Solved Problems: 1.S1 Make or BuyDocument3 paginiSolution To Solved Problems: 1.S1 Make or BuyHIEN TRAN THEÎncă nu există evaluări
- (Advances in Cryogenic Engineering 37) Takayuki Kishi, Mizuo Kudo, Hiromasa Iisaka (Auth.), R. W. Fast (Eds.) - Advances in Cryogenic Engineering-Springer US (1991)Document729 pagini(Advances in Cryogenic Engineering 37) Takayuki Kishi, Mizuo Kudo, Hiromasa Iisaka (Auth.), R. W. Fast (Eds.) - Advances in Cryogenic Engineering-Springer US (1991)ksvvijÎncă nu există evaluări
- Coreldraw 12 Hotkeys - Keyboard ShortcutsDocument6 paginiCoreldraw 12 Hotkeys - Keyboard ShortcutsRais AhmadÎncă nu există evaluări
- Maintenance of SubstationDocument129 paginiMaintenance of Substationrama mohan100% (1)
- The Interpretive TheoryDocument15 paginiThe Interpretive TheorySomia Zergui100% (14)
- The Nature of Philosophy and Its ObjectsDocument9 paginiThe Nature of Philosophy and Its Objectsaugustine abellanaÎncă nu există evaluări
- Supervision Circuito de DisparoDocument10 paginiSupervision Circuito de DisparoedwinoriaÎncă nu există evaluări
- 11 - Biennial - Form/3 Component Uphole Survey For Estimation of SHDocument5 pagini11 - Biennial - Form/3 Component Uphole Survey For Estimation of SHVishal PandeyÎncă nu există evaluări
- PFR Lime Kiln Process With Blast Furnace Gas and OxygenDocument4 paginiPFR Lime Kiln Process With Blast Furnace Gas and OxygenVitor Godoy100% (1)
- Basic Engineering Correlation Calculus v3 001Document3 paginiBasic Engineering Correlation Calculus v3 001Ska doosh100% (1)
- Skripsi #2 Tanpa HyperlinkDocument19 paginiSkripsi #2 Tanpa HyperlinkindahÎncă nu există evaluări
- Huawei E5885ls 93a Mobile Wifi DatasheetDocument22 paginiHuawei E5885ls 93a Mobile Wifi DatasheetMohammed ShakilÎncă nu există evaluări
- What Is Canal LiningDocument6 paginiWhat Is Canal LiningFiaz GujjarÎncă nu există evaluări
- 50-555circuits 2 PDFDocument102 pagini50-555circuits 2 PDFAlfonso RamosÎncă nu există evaluări
- Fluid Mechanics Chapter on Mechanical Energy and EfficiencyDocument43 paginiFluid Mechanics Chapter on Mechanical Energy and EfficiencyShazrel IzlanÎncă nu există evaluări
- High Performance Techniques For Microsoft SQL Server PDFDocument307 paginiHigh Performance Techniques For Microsoft SQL Server PDFmaghnus100% (1)
- AtmegaDocument22 paginiAtmegaMUKILANÎncă nu există evaluări
- ContentServer PDFDocument16 paginiContentServer PDFdaniel leon marinÎncă nu există evaluări
- IGCSE Math (Worked Answers)Document22 paginiIGCSE Math (Worked Answers)Amnah Riyaz100% (1)
- 20-SDMS-02 Overhead Line Accessories PDFDocument102 pagini20-SDMS-02 Overhead Line Accessories PDFMehdi SalahÎncă nu există evaluări
- Elasticity and Its Applications: For Use With Mankiw and Taylor, Economics 4 Edition 9781473725331 © CENGAGE EMEA 2017Document39 paginiElasticity and Its Applications: For Use With Mankiw and Taylor, Economics 4 Edition 9781473725331 © CENGAGE EMEA 2017Joana AgraÎncă nu există evaluări
- 2 Nuts and Bolts: 2.1 Deterministic vs. Randomized AlgorithmsDocument13 pagini2 Nuts and Bolts: 2.1 Deterministic vs. Randomized AlgorithmsEdmund ZinÎncă nu există evaluări
- Mos PDFDocument194 paginiMos PDFChoon Ewe LimÎncă nu există evaluări
- On Handwritten Digit RecognitionDocument15 paginiOn Handwritten Digit RecognitionAnkit Upadhyay100% (1)
- CO2 Production PlantsDocument4 paginiCO2 Production PlantsBoojie Recto100% (1)
- Grading CapacitorsDocument4 paginiGrading CapacitorsenmavelÎncă nu există evaluări
- XXXXX: Important Instructions To ExaminersDocument21 paginiXXXXX: Important Instructions To ExaminersYogesh DumaneÎncă nu există evaluări
- Open Die ForgingDocument7 paginiOpen Die ForgingCharanjeet Singh0% (1)