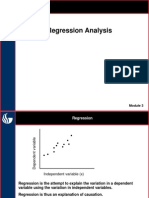
S-ar putea să vă placă și
- Econometrics: Two Variable Regression: The Problem of EstimationDocument28 paginiEconometrics: Two Variable Regression: The Problem of EstimationsajidalirafiqueÎncă nu există evaluări
- Chapter 2-Simple Regression ModelDocument25 paginiChapter 2-Simple Regression ModelMuliana SamsiÎncă nu există evaluări
- Econometrics PracticalDocument13 paginiEconometrics Practicalakashit21a854Încă nu există evaluări
- DOM105 Session 20Document10 paginiDOM105 Session 20DevanshiÎncă nu există evaluări
- Simple Linear Regression AnalysisDocument19 paginiSimple Linear Regression Analysisyeşim ozanÎncă nu există evaluări
- Temas 4 Al 7Document191 paginiTemas 4 Al 7mariaÎncă nu există evaluări
- P1.T2. Quantitative Analysis: Stock & Watson, Introduction To Econometrics Linear Regression With One RegressorDocument34 paginiP1.T2. Quantitative Analysis: Stock & Watson, Introduction To Econometrics Linear Regression With One Regressorruthbadoo54Încă nu există evaluări
- Univariate RegressionDocument6 paginiUnivariate RegressionSree NivasÎncă nu există evaluări
- LinearStatisticalModels and Regression AnalysisDocument27 paginiLinearStatisticalModels and Regression AnalysisBhavya JhaÎncă nu există evaluări
- Ordinary Least SquaresDocument21 paginiOrdinary Least SquaresRahulsinghooooÎncă nu există evaluări
- ArunRangrejDocument5 paginiArunRangrejArun RangrejÎncă nu există evaluări
- Regression With One Regressor-Hypothesis Tests and Confidence IntervalsDocument53 paginiRegression With One Regressor-Hypothesis Tests and Confidence Intervalshoalongkiem100% (1)
- Chapter Two: Bivariate Regression ModeDocument54 paginiChapter Two: Bivariate Regression ModenahomÎncă nu există evaluări
- Introductory of Statistics - Chapter 4Document5 paginiIntroductory of Statistics - Chapter 4Riezel PepitoÎncă nu există evaluări
- Regression and CorrelationDocument14 paginiRegression and CorrelationAhmed AyadÎncă nu există evaluări
- Eco 3Document68 paginiEco 3Nebiyu WoldesenbetÎncă nu există evaluări
- QMDocument4 paginiQMJinÎncă nu există evaluări
- Introductory of Statistics - Chapter 4Document5 paginiIntroductory of Statistics - Chapter 4Riezel PepitoÎncă nu există evaluări
- ACC 324 Wk8to9Document18 paginiACC 324 Wk8to9Mariel CadayonaÎncă nu există evaluări
- Regression and Multiple Regression AnalysisDocument21 paginiRegression and Multiple Regression AnalysisRaghu NayakÎncă nu există evaluări
- Simple LR LectureDocument60 paginiSimple LR LectureEarl Kristof Li LiaoÎncă nu există evaluări
- Analysis of Variance (ANOVA)Document9 paginiAnalysis of Variance (ANOVA)americus_smile7474Încă nu există evaluări
- REGRESSION INTRODUCTIONDocument32 paginiREGRESSION INTRODUCTIONRam100% (1)
- ANOVA Approach to Regression AnalysisDocument22 paginiANOVA Approach to Regression AnalysisMariahDeniseCarumbaÎncă nu există evaluări
- Classical Linear Regression Model ExplainedDocument68 paginiClassical Linear Regression Model ExplainedNigussie BerhanuÎncă nu există evaluări
- Jimma University: M.SC in Economics (Industrial Economics) Regular Program Individual Assignment: EconometricsDocument20 paginiJimma University: M.SC in Economics (Industrial Economics) Regular Program Individual Assignment: Econometricsasu manÎncă nu există evaluări
- OLS Regression ExplainedDocument13 paginiOLS Regression ExplainedNanang ArifinÎncă nu există evaluări
- Subjective QuestionsDocument8 paginiSubjective QuestionsKeerthan kÎncă nu există evaluări
- Multiple regression analysis in three variablesDocument19 paginiMultiple regression analysis in three variablesShreyanshu SinghÎncă nu există evaluări
- RegressionDocument14 paginiRegressionAndleeb RazzaqÎncă nu există evaluări
- Regression Analysis Techniques and AssumptionsDocument43 paginiRegression Analysis Techniques and AssumptionsAmer RahmahÎncă nu există evaluări
- W10 - Module 008 Linear Regression and CorrelationDocument6 paginiW10 - Module 008 Linear Regression and CorrelationCiajoy KimÎncă nu există evaluări
- Simple Linear RegressionDocument8 paginiSimple Linear RegressionMarie BtaichÎncă nu există evaluări
- Regression Model Building Steps and DiagnosticsDocument4 paginiRegression Model Building Steps and DiagnosticsShruti MishraÎncă nu există evaluări
- Lab 1 PrintDocument9 paginiLab 1 PrintTawsif ahmedÎncă nu există evaluări
- Metrics10 Violating AssumptionsDocument13 paginiMetrics10 Violating AssumptionsSmoochie WalanceÎncă nu există evaluări
- Linear Regression Model for Backache StudyDocument49 paginiLinear Regression Model for Backache StudyNihal GujarÎncă nu există evaluări
- Cheat SheetDocument5 paginiCheat SheetMÎncă nu există evaluări
- Stats Cheat SheetDocument3 paginiStats Cheat SheetEdriana Isabel Bougrat Fermin50% (4)
- Econometric SDocument4 paginiEconometric SD mathewÎncă nu există evaluări
- Lecture 4 - Correlation and RegressionDocument35 paginiLecture 4 - Correlation and Regressionmanuelmbiawa30Încă nu există evaluări
- Regression Estimators, Assumptions & R-SquaredDocument1 paginăRegression Estimators, Assumptions & R-SquaredYousef KhanÎncă nu există evaluări
- 5-LR Doc - R Sqared-Bias-Variance-Ridg-LassoDocument26 pagini5-LR Doc - R Sqared-Bias-Variance-Ridg-LassoMonis KhanÎncă nu există evaluări
- Regression EquationDocument56 paginiRegression EquationMuhammad TariqÎncă nu există evaluări
- Simple Regression Analysis: Key Concepts ExplainedDocument51 paginiSimple Regression Analysis: Key Concepts ExplainedGrace GecomoÎncă nu există evaluări
- Module-2 - Assessing Accuracy of ModelDocument24 paginiModule-2 - Assessing Accuracy of ModelRoudra ChakrabortyÎncă nu există evaluări
- Week 6Document58 paginiWeek 6ABDULLAH AAMIR100% (1)
- QTIA Report 2012 IQRA UNIVERSITYDocument41 paginiQTIA Report 2012 IQRA UNIVERSITYSyed Asfar Ali kazmiÎncă nu există evaluări
- Chapter4 Regression ModelAdequacyCheckingDocument38 paginiChapter4 Regression ModelAdequacyCheckingAishat OmotolaÎncă nu există evaluări
- PHY107 Lab ManualsDocument56 paginiPHY107 Lab ManualsSam BlackwoodÎncă nu există evaluări
- Regression: Leech N L, Barret K C & Morgan G A (2011)Document35 paginiRegression: Leech N L, Barret K C & Morgan G A (2011)Sam AbdulÎncă nu există evaluări
- 2 The Linear Regression ModelDocument11 pagini2 The Linear Regression ModeljuntujuntuÎncă nu există evaluări
- Flach Roc AnalysisDocument12 paginiFlach Roc AnalysisAnonymous PsEz5kGVaeÎncă nu există evaluări
- Ec204 Introductory Econometrics NotesDocument41 paginiEc204 Introductory Econometrics NotesLOLZIÎncă nu există evaluări
- Regression Explains Variation in Dependent VariablesDocument15 paginiRegression Explains Variation in Dependent VariablesJuliefil Pheng AlcantaraÎncă nu există evaluări
- Simple Regression (Continued) : Y Xu Y XuDocument9 paginiSimple Regression (Continued) : Y Xu Y XuCatalin ParvuÎncă nu există evaluări
- 1602083443940498Document9 pagini1602083443940498mhamadhawlery16Încă nu există evaluări
- 6.1 Basics-of-Statistical-ModelingDocument17 pagini6.1 Basics-of-Statistical-ModelingLady Jane CaguladaÎncă nu există evaluări
- How Does A Change in Expected Inflation Shift The Is CurveDocument1 paginăHow Does A Change in Expected Inflation Shift The Is CurveJade NguyenÎncă nu există evaluări
- Real Vs Nominal Interest Rate HandoutDocument2 paginiReal Vs Nominal Interest Rate HandoutJade NguyenÎncă nu există evaluări
- Expected Present Discounted Value HandoutDocument2 paginiExpected Present Discounted Value HandoutJade NguyenÎncă nu există evaluări
- Financial Markets and ExpectationsDocument10 paginiFinancial Markets and ExpectationsJade NguyenÎncă nu există evaluări
- Chapter14 MR Increase in GDocument1 paginăChapter14 MR Increase in GJade NguyenÎncă nu există evaluări
- An Algebraic Model of The Goods Market in An Open EconomyDocument2 paginiAn Algebraic Model of The Goods Market in An Open EconomyJade NguyenÎncă nu există evaluări
- Chapter 14 MR Increase in MDocument1 paginăChapter 14 MR Increase in MJade NguyenÎncă nu există evaluări
- Homework-E4-8 and E4-15Document12 paginiHomework-E4-8 and E4-15Jade NguyenÎncă nu există evaluări
- Homework1 E3 10Document4 paginiHomework1 E3 10Jade NguyenÎncă nu există evaluări
- Directional and Non-Directional TestsDocument33 paginiDirectional and Non-Directional TestsRomdy LictaoÎncă nu există evaluări
- Individual Project Instructions - 5aDocument1 paginăIndividual Project Instructions - 5aIkhram JohariÎncă nu există evaluări
- Lilly Ryden - Gms - Lesson Plan 3Document4 paginiLilly Ryden - Gms - Lesson Plan 3api-289385832Încă nu există evaluări
- Multiple Choice Test Bank Questions No Feedback - Chapter 5Document7 paginiMultiple Choice Test Bank Questions No Feedback - Chapter 5Đức NghĩaÎncă nu există evaluări
- AddddddddddddddddddddakjDocument14 paginiAddddddddddddddddddddakjSanskar PankajÎncă nu există evaluări
- Fernandez Vs Dela RosaDocument12 paginiFernandez Vs Dela RosaSarah Zabala-AtienzaÎncă nu există evaluări
- STAT2, 2nd Edition, Ann Cannon: Full Chapter atDocument5 paginiSTAT2, 2nd Edition, Ann Cannon: Full Chapter atRaymond Mulinix96% (23)
- Distribusi Normal dan Kurva Normal BakuDocument25 paginiDistribusi Normal dan Kurva Normal BakuYosevira Larasati RomawanÎncă nu există evaluări
- Principles/Foundations of Artificial Intelligence.: Inferencing MethodsDocument35 paginiPrinciples/Foundations of Artificial Intelligence.: Inferencing MethodsSabria OmarÎncă nu există evaluări
- Output Uji HomogenitasDocument10 paginiOutput Uji Homogenitasakbartop1Încă nu există evaluări
- 4-Decision Making For Single SampleDocument71 pagini4-Decision Making For Single SampleHassan AyashÎncă nu există evaluări
- 5 Analyze Hypothesis Testing Normal Data P1 v10 3Document84 pagini5 Analyze Hypothesis Testing Normal Data P1 v10 3Kefin TajebÎncă nu există evaluări
- Statistics 578 Assignment 5 HomeworkDocument13 paginiStatistics 578 Assignment 5 HomeworkMia Dee100% (5)
- Ch2 Slides EditedDocument66 paginiCh2 Slides EditedFrancis Saviour John SteevanÎncă nu există evaluări
- MMW M6 Check-In-Activity2Document3 paginiMMW M6 Check-In-Activity2Romyelle AmparoÎncă nu există evaluări
- REVIEWERDocument2 paginiREVIEWERRyan FullantesÎncă nu există evaluări
- UntitledDocument100 paginiUntitledwilliamp997Încă nu există evaluări
- Lesson 1 - Steps in Hypothesis TestingDocument22 paginiLesson 1 - Steps in Hypothesis TestingAlfredo LabadorÎncă nu există evaluări
- Econometric Modeling: Model Specification and Diagnostic TestingDocument57 paginiEconometric Modeling: Model Specification and Diagnostic TestingKhirstina CurryÎncă nu există evaluări
- Detect Heteroscedasticity Linear RegressionDocument10 paginiDetect Heteroscedasticity Linear RegressionLWANGA FRANCISÎncă nu există evaluări
- Logic - MODULE 5 REASONING AND SYLLOGISMDocument9 paginiLogic - MODULE 5 REASONING AND SYLLOGISMchrystyn arianeÎncă nu există evaluări
- Unit 5 Non-Parametric Tests Parametric TestsDocument5 paginiUnit 5 Non-Parametric Tests Parametric TestsMasuma Begam MousumiÎncă nu există evaluări
- Test for Difference Two ProportionsDocument7 paginiTest for Difference Two ProportionsMuhammad Aly Sa'idÎncă nu există evaluări
- Cheat Sheet for Regression Models and Time Series AnalysisDocument4 paginiCheat Sheet for Regression Models and Time Series AnalysispatÎncă nu există evaluări
- Inference Vs AssumptionDocument3 paginiInference Vs AssumptionShreyas Metkute0% (1)
- ECON2046 - 2005 Week 6 Lecture 9 Slides 1 Per PageDocument26 paginiECON2046 - 2005 Week 6 Lecture 9 Slides 1 Per PagedsascsÎncă nu există evaluări
- ANOVA analysis of productivity levels between three methodsDocument17 paginiANOVA analysis of productivity levels between three methodsKartik MehtaÎncă nu există evaluări
- Reasoning Techniques for Uncertain SituationsDocument17 paginiReasoning Techniques for Uncertain SituationsAy SyÎncă nu există evaluări
- Critical Thinking.Document23 paginiCritical Thinking.Salman KhanÎncă nu există evaluări
- Hetero StataDocument2 paginiHetero StataGucci Zamora DiamanteÎncă nu există evaluări