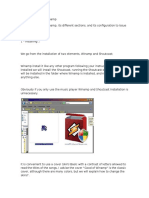
S-ar putea să vă placă și
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1091)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Design Input Output Process Engineering PT Krakatau EngineeringDocument14 paginiDesign Input Output Process Engineering PT Krakatau EngineeringHendrias Ari SujarwoÎncă nu există evaluări
- Control Box ST Installation and UpgradeDocument75 paginiControl Box ST Installation and UpgradeKamal Buddy100% (2)
- ISU CS FunctionalDocument5 paginiISU CS FunctionalDurgesh PandeyÎncă nu există evaluări
- Btech 1st Sem: Maths: Mean Value TheoremDocument7 paginiBtech 1st Sem: Maths: Mean Value TheoremTechno India Group80% (5)
- DreamWeaver CS4 Keyboard ShortcutsDocument3 paginiDreamWeaver CS4 Keyboard Shortcutsrainbow_colorÎncă nu există evaluări
- Dell PowerEdge M1000e & 4 Blades Full SpecificationsDocument2 paginiDell PowerEdge M1000e & 4 Blades Full SpecificationsSantosh BejgumÎncă nu există evaluări
- (Tcs MCQS) : C Programming Language by K.V.Ramana Naresh TechnologiesDocument28 pagini(Tcs MCQS) : C Programming Language by K.V.Ramana Naresh Technologiesakshay gawadeÎncă nu există evaluări
- Manual Siemens 7sj62Document58 paginiManual Siemens 7sj62Erick Jao VergaraÎncă nu există evaluări
- How To Build A Duplicate Standby File & Print Server Using Windows 2003 Server and Windows XPDocument8 paginiHow To Build A Duplicate Standby File & Print Server Using Windows 2003 Server and Windows XPElectroMan53Încă nu există evaluări
- MozartDocument147 paginiMozartgibson150Încă nu există evaluări
- Adapting Next ExtentDocument14 paginiAdapting Next ExtentSateesh Babu PinnojuÎncă nu există evaluări
- Solutions of Equations in One Variable The Bisection Method: Numerical Analysis (9th Edition) R L Burden & J D FairesDocument90 paginiSolutions of Equations in One Variable The Bisection Method: Numerical Analysis (9th Edition) R L Burden & J D FairesCassey ToyuÎncă nu există evaluări
- Delta Robot Simulator (Manual)Document4 paginiDelta Robot Simulator (Manual)Ahmad Bilal100% (1)
- Computer Model TestDocument10 paginiComputer Model TestrathaiÎncă nu există evaluări
- Tutorial 4Document2 paginiTutorial 4Manisha GargÎncă nu există evaluări
- Sol 04Document5 paginiSol 04Cindy DingÎncă nu există evaluări
- Operating Manual WinampDocument7 paginiOperating Manual WinampChristian Jesus Morales Catzin100% (1)
- A Critical Study of The Life and Teachings of Sri Guru Nanak Dev Ji by Sewaram Singh Thapar PDFDocument205 paginiA Critical Study of The Life and Teachings of Sri Guru Nanak Dev Ji by Sewaram Singh Thapar PDFGagan GaganÎncă nu există evaluări
- Grade 6 4th Math Learning CompetenciesDocument3 paginiGrade 6 4th Math Learning CompetenciesMelinda RafaelÎncă nu există evaluări
- Chem4Word Version3Document26 paginiChem4Word Version3Marina OÎncă nu există evaluări
- Quality $26 HSE Management Review Example TemplateDocument2 paginiQuality $26 HSE Management Review Example TemplateBoy BangusÎncă nu există evaluări
- Introduction To Engineering-ScriptDocument5 paginiIntroduction To Engineering-ScriptgcpÎncă nu există evaluări
- ERP Complaint BookDocument12 paginiERP Complaint BookghisuddinÎncă nu există evaluări
- Fortiauthenticator Rest APIDocument16 paginiFortiauthenticator Rest APIcaliqÎncă nu există evaluări
- DATE SHEET For One-Year Diploma Level Course in D.I.T (Diploma in Information Technology) 1 Term Examination 2021Document1 paginăDATE SHEET For One-Year Diploma Level Course in D.I.T (Diploma in Information Technology) 1 Term Examination 2021ZohaibÎncă nu există evaluări
- 1.2 HANA InstallationDocument36 pagini1.2 HANA InstallationAnbu SaravananÎncă nu există evaluări
- Parallel and Distributed ComputingDocument20 paginiParallel and Distributed ComputingMayur Chotaliya100% (1)
- Manual of PT500Document13 paginiManual of PT500patrijuvetÎncă nu există evaluări
- System Software Notes 5TH Sem VtuDocument27 paginiSystem Software Notes 5TH Sem VtuNeha Chinni100% (3)
- 016-ZXUN XGW (V4.10.24) EXtendable GateWay GGSN Performance Index ReferenceDocument37 pagini016-ZXUN XGW (V4.10.24) EXtendable GateWay GGSN Performance Index ReferenceMohamedSalahÎncă nu există evaluări