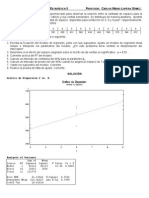
S-ar putea să vă placă și
- RegresionesDocument17 paginiRegresionesbikeflat455Încă nu există evaluări
- UNIDAD #3 EstadisticaDocument15 paginiUNIDAD #3 EstadisticayinbÎncă nu există evaluări
- Econometria - Regresion Lineal Semana 2Document24 paginiEconometria - Regresion Lineal Semana 2peru29Încă nu există evaluări
- Ajuste curvasDocument9 paginiAjuste curvasJhon YajaÎncă nu există evaluări
- Regresion Lineal SimpleDocument23 paginiRegresion Lineal SimpleAarón RivasÎncă nu există evaluări
- Regresion Lineal MultipleDocument16 paginiRegresion Lineal MultipleJorge SaldarriagaÎncă nu există evaluări
- Curso Ana Regres 2Document236 paginiCurso Ana Regres 2Génova Sth BJÎncă nu există evaluări
- Modulo (Regresion y Correlacion)Document4 paginiModulo (Regresion y Correlacion)Bill Malba TahanÎncă nu există evaluări
- Regresión Lineal SimpleDocument34 paginiRegresión Lineal SimpleJuan Carlos Lopez MesaÎncă nu există evaluări
- Calculos - Aproximacion Por Minimos CuadradosDocument18 paginiCalculos - Aproximacion Por Minimos Cuadradosve_asÎncă nu există evaluări
- Minimos CuadradosDocument10 paginiMinimos CuadradosMichu OviedoÎncă nu există evaluări
- Regresion Lineal SimpleDocument14 paginiRegresion Lineal SimplefacenunaÎncă nu există evaluări
- Análisis de Regresión-1Document7 paginiAnálisis de Regresión-1San Marcos EstadisticaÎncă nu există evaluări
- Semana-5-Análisis de Asociación SimpleDocument9 paginiSemana-5-Análisis de Asociación SimpleLuis Angel Meza QuispeÎncă nu există evaluări
- Regresion Lineal MultipleDocument16 paginiRegresion Lineal MultipleKelvin GarciaÎncă nu există evaluări
- González, J. (2021) - Análisis Gráfico (Apunte) - Universidad Andrés Bello, Santiago, ChileDocument15 paginiGonzález, J. (2021) - Análisis Gráfico (Apunte) - Universidad Andrés Bello, Santiago, ChileCESAR PEREZÎncă nu există evaluări
- Regresion Simple 2022 11Document27 paginiRegresion Simple 2022 11Dannis Omar Campos ZavaletaÎncă nu există evaluări
- Tema 1Document32 paginiTema 1nooormaaahernaanndezÎncă nu există evaluări
- Regresion Lineal MultipleDocument20 paginiRegresion Lineal MultipleGii SelleÎncă nu există evaluări
- Cap V Análisis de Regresión Lineal SimpleDocument23 paginiCap V Análisis de Regresión Lineal SimpleAnonymous lmo7YKd3Încă nu există evaluări
- Regresion Lineal SimpleDocument21 paginiRegresion Lineal SimpleSasha Valeria Siguenza RoblesÎncă nu există evaluări
- Regresion Lineal SimpleDocument13 paginiRegresion Lineal Simpleiborella999Încă nu există evaluări
- Representacion Datos ExperimentalesDocument8 paginiRepresentacion Datos ExperimentalesAbdiel Eliu AraguayanÎncă nu există evaluări
- T3 Regresion LinealDocument11 paginiT3 Regresion LinealAlexandra Díaz BurbanoÎncă nu există evaluări
- Análisis Regresión LinealDocument17 paginiAnálisis Regresión LinealSteven Cerna MejiaÎncă nu există evaluări
- Laboratorio de Fisica 2Document4 paginiLaboratorio de Fisica 2Jhon AronsÎncă nu există evaluări
- Regresion Lineal y CorrelacionDocument14 paginiRegresion Lineal y CorrelacionAlexander CheroÎncă nu există evaluări
- Modelo de Regresión Lineal SimpleDocument8 paginiModelo de Regresión Lineal SimpleBYRON FERNANDO SIGUENZA PAGUAYÎncă nu există evaluări
- Regresión Lineal SimpleDocument36 paginiRegresión Lineal SimpleHans Hidalgo AltaÎncă nu există evaluări
- INFORME N°2 Ecuaciones EmpiricasDocument5 paginiINFORME N°2 Ecuaciones EmpiricasEdith Johanna MunévarÎncă nu există evaluări
- Trabajo Escrito de Variables InstrumentalesDocument18 paginiTrabajo Escrito de Variables InstrumentalesKatherine Jimenez MatosÎncă nu există evaluări
- Curso de Econometria BasicaDocument89 paginiCurso de Econometria BasicaDaniel Matheus100% (1)
- Regresion Lineal MultipleDocument15 paginiRegresion Lineal MultipleWILDER CHINCHAY CRUZÎncă nu există evaluări
- Unidad 3. Estadistica IIDocument5 paginiUnidad 3. Estadistica IIGuillermo AlonsoÎncă nu există evaluări
- RegresionDocument8 paginiRegresioneyimer diaz perezÎncă nu există evaluări
- Capitulo 7Document13 paginiCapitulo 7Milady Suarez PinedaÎncă nu există evaluări
- Inferencia Estadistica Anthony MelendezDocument60 paginiInferencia Estadistica Anthony MelendezAnthony Melendez BaezÎncă nu există evaluări
- Curso Ana Regres 2Document245 paginiCurso Ana Regres 2Manuel GarzaÎncă nu există evaluări
- Regresion Lineal Simple PDFDocument12 paginiRegresion Lineal Simple PDFMiguel Angel Serrudo OrtizÎncă nu există evaluări
- Introducción al laboratorio de física: guía para mediciones y gráficosDocument5 paginiIntroducción al laboratorio de física: guía para mediciones y gráficosElmerOrtizÎncă nu există evaluări
- Trabajo Grupal - Alex Haro - David Vega - Regresion Lineal Simple - Regresion Lineal Simple - Probabilidad y Estadistica Basica - GR3Document8 paginiTrabajo Grupal - Alex Haro - David Vega - Regresion Lineal Simple - Regresion Lineal Simple - Probabilidad y Estadistica Basica - GR3Alex HaroÎncă nu există evaluări
- Texto RegresiónDocument187 paginiTexto RegresiónWilmar GamboaÎncă nu există evaluări
- Taller de Calculo Numerico Unidad 1 y 2Document19 paginiTaller de Calculo Numerico Unidad 1 y 2Angel Enrique Cordero FreitesÎncă nu există evaluări
- 1Document39 pagini1Bryan German Pantoja RoseroÎncă nu există evaluări
- Analisis de Correlación y Regresión MúltipleDocument9 paginiAnalisis de Correlación y Regresión MúltipleTeefaa RuizÎncă nu există evaluări
- Guia 17 10 11Document91 paginiGuia 17 10 11David Marshall AndreuÎncă nu există evaluări
- Ejercicios Regresion Lineal SimpleDocument11 paginiEjercicios Regresion Lineal SimpleLesly Leonor Moctezuma VelezÎncă nu există evaluări
- Análisis Del Método de Regresión Lineal Simple.Document12 paginiAnálisis Del Método de Regresión Lineal Simple.alberto100% (1)
- Tutorial EncuaderncacuónDocument14 paginiTutorial EncuaderncacuónEstudianteauxdirectrices SolanoÎncă nu există evaluări
- Libro Analisis y Diseño de Experimentos MontgomeryDocument692 paginiLibro Analisis y Diseño de Experimentos MontgomeryClaudia91% (11)
- ElkinDocument91 paginiElkinEstudianteauxdirectrices SolanoÎncă nu există evaluări
- Libro - ECOLOGÍA DEL PAISAJE - PP - 65-117 211-248 287-313 (07-NOV-2013)Document67 paginiLibro - ECOLOGÍA DEL PAISAJE - PP - 65-117 211-248 287-313 (07-NOV-2013)Estudianteauxdirectrices SolanoÎncă nu există evaluări
- Diseño Factorial 2 3Document10 paginiDiseño Factorial 2 3Estudianteauxdirectrices SolanoÎncă nu există evaluări
- Lectura MuestreoDocument12 paginiLectura MuestreoEstudianteauxdirectrices SolanoÎncă nu există evaluări
- (Complemento) Transformaciones y Pruebas de NormalidadDocument2 pagini(Complemento) Transformaciones y Pruebas de NormalidadEstudianteauxdirectrices SolanoÎncă nu există evaluări
- Lectura Complementaria Muestreo PDFDocument32 paginiLectura Complementaria Muestreo PDFJuan CastilloÎncă nu există evaluări
- Practica 01Document3 paginiPractica 01Estudianteauxdirectrices SolanoÎncă nu există evaluări
- SFI y Los FractalesDocument97 paginiSFI y Los FractalesEstudianteauxdirectrices SolanoÎncă nu există evaluări
- 20 MatematicadocenteDocument118 pagini20 MatematicadocenteClaudia pioli100% (1)
- SGRD Golden Prize Barber ShopDocument59 paginiSGRD Golden Prize Barber ShopWillie SánchezÎncă nu există evaluări
- Fag492a Aclimatacion ChloraeaDocument67 paginiFag492a Aclimatacion ChloraeaReynaldoÎncă nu există evaluări
- Precios Catambo AprobadoDocument1 paginăPrecios Catambo Aprobadomgarnique2595Încă nu există evaluări
- Diapositiva 1 Importancia de La Ética-1Document10 paginiDiapositiva 1 Importancia de La Ética-1Diego Contreras PerezÎncă nu există evaluări
- Distocias OseasDocument29 paginiDistocias OseasIván Martín Pantoja CostaÎncă nu există evaluări
- Elementos circuitos eléctricos industrialesDocument101 paginiElementos circuitos eléctricos industrialesLuisa AngamarcaÎncă nu există evaluări
- Cadena AlimenticiaDocument2 paginiCadena AlimenticiaEvelyn G. Cazares0% (1)
- Certificado estudios Máster TransporteDocument1 paginăCertificado estudios Máster TransporteGrover PumaÎncă nu există evaluări
- Informe Previo1 Electronica de PotenciaDocument9 paginiInforme Previo1 Electronica de PotenciaJhonatan Juño GarciaÎncă nu există evaluări
- CHRONOS Configuracion Rapida POSICIONADOR VALTEKDocument2 paginiCHRONOS Configuracion Rapida POSICIONADOR VALTEKjorge alorÎncă nu există evaluări
- Enterocolitis necrotizanteEEEEEDocument21 paginiEnterocolitis necrotizanteEEEEEMaria Del Pilar EstrellaÎncă nu există evaluări
- Trabajo Dba Ciencias Naturales 9Document3 paginiTrabajo Dba Ciencias Naturales 9Ruben FonsecaÎncă nu există evaluări
- SustentaciónDocument2 paginiSustentaciónMaicol PortillaÎncă nu există evaluări
- 28 - Gabriel Zaid - El Mito Del ProgresoDocument12 pagini28 - Gabriel Zaid - El Mito Del Progresopakonet69Încă nu există evaluări
- PlatyhelmintosDocument13 paginiPlatyhelmintosadileneÎncă nu există evaluări
- Pre y Post TestDocument6 paginiPre y Post TestEmily Dayana GonzalezÎncă nu există evaluări
- Programa4scf PDFDocument3 paginiPrograma4scf PDFKaren PedrazaÎncă nu există evaluări
- EslingasDocument8 paginiEslingasluffy221Încă nu există evaluări
- Learn Python in Y MinutesDocument14 paginiLearn Python in Y MinutesAlonso MaciasÎncă nu există evaluări
- Orun: ¿Deidad o DemonioDocument13 paginiOrun: ¿Deidad o DemonioMiguel Angel Diaz Benitez100% (2)
- 2b - Sim Diagnóstico - RM 2021Document13 pagini2b - Sim Diagnóstico - RM 2021avengersrm 2019Încă nu există evaluări
- Obtención de sandía sin semillas mediante tratamiento floralDocument10 paginiObtención de sandía sin semillas mediante tratamiento floralRuben HerreraÎncă nu există evaluări
- AlarmaDocument4 paginiAlarmaCesar CasasÎncă nu există evaluări
- TFG Readaptación Físico-Deportiva Rugby LCA PDFDocument44 paginiTFG Readaptación Físico-Deportiva Rugby LCA PDFLeonardiniÎncă nu există evaluări
- Actividad Estadistica Inferencial 6Document11 paginiActividad Estadistica Inferencial 6Daniela LunaÎncă nu există evaluări
- Bromatologa Informe 2. Carne de Pollo Hígado Corazón MollejaDocument14 paginiBromatologa Informe 2. Carne de Pollo Hígado Corazón MollejaRonald LP0% (2)
- Examen Final Serie 1Document3 paginiExamen Final Serie 1Jimmy Yahir Chuc SolvalÎncă nu există evaluări
- Motilidad IntestinalDocument4 paginiMotilidad IntestinalBrenda TorresÎncă nu există evaluări
- TDR LiquidacionDocument8 paginiTDR LiquidacionJosselu Esmeralda Cabezas AyuqueÎncă nu există evaluări
- Constumbres y Tradiciones Del ParaguayDocument29 paginiConstumbres y Tradiciones Del ParaguayRolando Mongelos100% (2)