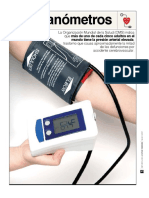
S-ar putea să vă placă și
- PSI DE LA TERCERA EDAD Programa 2020Document11 paginiPSI DE LA TERCERA EDAD Programa 2020pabjorvalÎncă nu există evaluări
- ¿Ciencia o religión?: Exploraciones sobre las relaciones entre fe y racionalidad en el mundo contemporáneoDe la Everand¿Ciencia o religión?: Exploraciones sobre las relaciones entre fe y racionalidad en el mundo contemporáneoÎncă nu există evaluări
- Ensayo Historia de La Muerte en OccidenteDocument4 paginiEnsayo Historia de La Muerte en OccidenteMiguel Esteban AmoresÎncă nu există evaluări
- Análisis Del Libro Los Cortejos Del Diablo de German EspinozaDocument19 paginiAnálisis Del Libro Los Cortejos Del Diablo de German EspinozaFernandoOviedoLópez0% (1)
- Clínica Contemporánea Revista de Diagnóstico Psicológico, Psicot PDFDocument92 paginiClínica Contemporánea Revista de Diagnóstico Psicológico, Psicot PDFMauricioÎncă nu există evaluări
- Viejos: Una mirada reflexiva desde el Trabajo SocialDe la EverandViejos: Una mirada reflexiva desde el Trabajo SocialÎncă nu există evaluări
- Alas Clarín, Leopoldo - Adios Cordera (Vocabulario Útil)Document1 paginăAlas Clarín, Leopoldo - Adios Cordera (Vocabulario Útil)Carlos Gilberto Villamar LinaresÎncă nu există evaluări
- Los Casos de Axel: El Robo de Pakal: Los casos de AxelDe la EverandLos Casos de Axel: El Robo de Pakal: Los casos de AxelEvaluare: 5 din 5 stele5/5 (1)
- Guía de Carreras - Vení A La UNLPDocument11 paginiGuía de Carreras - Vení A La UNLPAnalia SalehÎncă nu există evaluări
- Visiones y debates de la cooperación Sur-Sur y triangular: Actores gubernamentales, sociales y privadosDe la EverandVisiones y debates de la cooperación Sur-Sur y triangular: Actores gubernamentales, sociales y privadosÎncă nu există evaluări
- La Maté Porque Era Mía Psicobiología de La Ira, De... - (PG 78 - 91)Document14 paginiLa Maté Porque Era Mía Psicobiología de La Ira, De... - (PG 78 - 91)leidy lorena angel gomez100% (2)
- Ensayo TDCDocument8 paginiEnsayo TDCDaniel BermeoÎncă nu există evaluări
- Teoría Del Potencial de Acción de La Membrana Postulado Por Lloyd Hodgkin y Andrew Fielding HuxleyDocument7 paginiTeoría Del Potencial de Acción de La Membrana Postulado Por Lloyd Hodgkin y Andrew Fielding HuxleyBrenÎncă nu există evaluări
- Dialnet ExistencialismoYHumanismoAnteLaCrisisDeLaPsicotera 2309509 PDFDocument10 paginiDialnet ExistencialismoYHumanismoAnteLaCrisisDeLaPsicotera 2309509 PDForlando_vidal_2Încă nu există evaluări
- 'La Conjura de Cortés', La Nueva Novela de Matilde AsensiDocument2 pagini'La Conjura de Cortés', La Nueva Novela de Matilde AsensianariameÎncă nu există evaluări
- Isabel MoctezumaDocument4 paginiIsabel Moctezumaabe_jaime1989Încă nu există evaluări
- Síndrome de La CabañaDocument4 paginiSíndrome de La CabañaPauli GarciaÎncă nu există evaluări
- Obesidad MentalDocument4 paginiObesidad MentalMoisesAgredaFuchsÎncă nu există evaluări
- Lehmann, Peter Alternativas A La PsiquiatríaDocument15 paginiLehmann, Peter Alternativas A La PsiquiatríaRonald OSÎncă nu există evaluări
- El Mito Del Siglo XX - RosembergDocument1 paginăEl Mito Del Siglo XX - RosembergPedro Jose Arias RinconÎncă nu există evaluări
- Actividad Entregable CID-1Document2 paginiActividad Entregable CID-1micaelagallardohernandezÎncă nu există evaluări
- 01 - Unidad I - Clastres - Sobre El EtnocidioDocument2 pagini01 - Unidad I - Clastres - Sobre El EtnocidioMaria De Los Angeles Laredo50% (2)
- Sindrome de DesmoralizacionDocument20 paginiSindrome de DesmoralizacionkatherineÎncă nu există evaluări
- Kuukkanen - TraducidoDocument8 paginiKuukkanen - TraducidoBadtz Maru100% (1)
- El Artista y El Psicoanalista Mutante InterpeladosDocument2 paginiEl Artista y El Psicoanalista Mutante InterpeladosLeonor FeferÎncă nu există evaluări
- BaumanometrosDocument15 paginiBaumanometrosrafitamxÎncă nu există evaluări
- Golda Meir - Mariana EscobarDocument9 paginiGolda Meir - Mariana EscobarDiego A. Bernal B.0% (1)
- Ego Alter ObjetoDocument4 paginiEgo Alter ObjetoAngelus ArmagedónÎncă nu există evaluări
- Filosofia BrahamanicaDocument2 paginiFilosofia Brahamanicaelias david orejuela bazurtoÎncă nu există evaluări
- Ensayo Publicado en La Sartén Por El MangoDocument5 paginiEnsayo Publicado en La Sartén Por El MangoFernando PraderioÎncă nu există evaluări
- El Lector de Julio VerneDocument4 paginiEl Lector de Julio VerneMaría Del Pilar PérezÎncă nu există evaluări
- La Angustia y La MuerteDocument4 paginiLa Angustia y La Muertejose lopezÎncă nu există evaluări
- Alain de Botton y Su Polémico Ateísmo 2Document3 paginiAlain de Botton y Su Polémico Ateísmo 2filorancaÎncă nu există evaluări
- Libro Desacuerdos PDFDocument202 paginiLibro Desacuerdos PDFOsalariasÎncă nu există evaluări
- En El Nombre de Los Ninos - Emilio Balaguer y Rosa BallesterDocument268 paginiEn El Nombre de Los Ninos - Emilio Balaguer y Rosa BallesterJhae RosasÎncă nu există evaluări
- La Viruela y El HombreDocument19 paginiLa Viruela y El HombreLibertad DemocraticaÎncă nu există evaluări
- Julio Ramon RibeyroDocument6 paginiJulio Ramon RibeyroAnthonyÎncă nu există evaluări
- Utilitarismo y LiberalismoDocument16 paginiUtilitarismo y LiberalismoJuanCar HiMelÎncă nu există evaluări
- La Peste Negra de 1348 - Jon ArrizabalagaDocument45 paginiLa Peste Negra de 1348 - Jon ArrizabalagaNikolayÎncă nu există evaluări
- Publicar Documento en ScribdDocument11 paginiPublicar Documento en Scribdalbertomejiamanrique0% (1)
- El Micro-Cuento o Micro-Relato en La Cuentística de Edgar Iván HernándezDocument92 paginiEl Micro-Cuento o Micro-Relato en La Cuentística de Edgar Iván HernándezbibliotecalejandrinaÎncă nu există evaluări
- Epidemiologia Social - Rita Barradas - Pt.esDocument11 paginiEpidemiologia Social - Rita Barradas - Pt.esdaysi altezÎncă nu există evaluări
- Cultura de MéxicoDocument21 paginiCultura de MéxicoBere EspinozaÎncă nu există evaluări
- El Miedo Como Desencadenante de La Crísis (Advaita Vedanta)Document13 paginiEl Miedo Como Desencadenante de La Crísis (Advaita Vedanta)Ernesto SoloÎncă nu există evaluări
- PLATÓN, Crítica de La DemocraciaDocument4 paginiPLATÓN, Crítica de La DemocraciafilosofiariojucarÎncă nu există evaluări
- Bibliográfica de Desarrollo SocialDocument1 paginăBibliográfica de Desarrollo SocialVilmer fausto Avalos reyesÎncă nu există evaluări
- Genevieve Galán Tamés Aproximaciones A La Historia Del Cuerpo Como Objeto de Estudio de La Disciplina HistóricaDocument39 paginiGenevieve Galán Tamés Aproximaciones A La Historia Del Cuerpo Como Objeto de Estudio de La Disciplina Históricarojasnatalia100% (1)
- El Cuerpo Tiene La PalabraDocument149 paginiEl Cuerpo Tiene La PalabraChavarriga Reposteria100% (1)
- Origen Histórico de La Esquizofrenia e Historia de La Subjetividad FreniaDocument20 paginiOrigen Histórico de La Esquizofrenia e Historia de La Subjetividad FreniaalienistaxixÎncă nu există evaluări
- Máximo Sandín y Su LibroDocument1 paginăMáximo Sandín y Su LibrocmdsoltecÎncă nu există evaluări
- Fuimos Es Mucha Gente de María Luisa MendozaDocument6 paginiFuimos Es Mucha Gente de María Luisa MendozaCatrinaÎncă nu există evaluări
- Que Son Los Modelos Economicos Fyd 06.2011 PDFDocument2 paginiQue Son Los Modelos Economicos Fyd 06.2011 PDFecorlandoÎncă nu există evaluări
- Medicalizar La Vida - Arnoldo KrausDocument9 paginiMedicalizar La Vida - Arnoldo KrausJuan Carlos Sanchez FloresÎncă nu există evaluări
- Supuesta Violacion A Florencia KirchnerDocument4 paginiSupuesta Violacion A Florencia KirchnerPepo ChonazoÎncă nu există evaluări
- Evolución Del Concepto Salud-EnfermedadDocument24 paginiEvolución Del Concepto Salud-EnfermedadMARIA ADELIA BUITRAGO RONCANCIOÎncă nu există evaluări
- SÍNTESISALZHEIMERDocument26 paginiSÍNTESISALZHEIMERAndrea Iglesias IglesiasÎncă nu există evaluări
- Seleccion de Escritos de Adam Smith - Tamara AvetikianDocument100 paginiSeleccion de Escritos de Adam Smith - Tamara AvetikianCiencia Politica Uahc80% (5)
- Con Derechos Pero Sin TierrasDocument2 paginiCon Derechos Pero Sin TierrasFernando ArenasÎncă nu există evaluări
- Modernidad y Posmodernidad - ObiolsDocument20 paginiModernidad y Posmodernidad - ObiolsCarlos Gallego100% (1)
- Capital y Trabajo en Tiempos de MacriDocument3 paginiCapital y Trabajo en Tiempos de MacriDenis MarSol CoronelÎncă nu există evaluări
- Dobb Maurice Teoria Del Valor y La Distribucion Desde Adam Smith 1973Document112 paginiDobb Maurice Teoria Del Valor y La Distribucion Desde Adam Smith 1973AdssYou100% (1)
- José Natanson. El Empate Hegemónico en A. Latina. El Dipló. Edición Nro 216. Junio de 2017Document3 paginiJosé Natanson. El Empate Hegemónico en A. Latina. El Dipló. Edición Nro 216. Junio de 2017Melvin BurrÎncă nu există evaluări
- Texto 15 - El Viraje Del Siglo XXI - RapoportDocument23 paginiTexto 15 - El Viraje Del Siglo XXI - RapoportFernando ArenasÎncă nu există evaluări
- La Educación Técnica de Nivel SuperiorDocument28 paginiLa Educación Técnica de Nivel SuperiorFernando ArenasÎncă nu există evaluări
- Aldo Ferrer - Hechos y Ficciones de La GlobalizaciónDocument22 paginiAldo Ferrer - Hechos y Ficciones de La GlobalizaciónmarianalucsÎncă nu există evaluări
- 1936 J.M.Keynes. T.Gral - Ocupac.Int - Dinero PDFDocument170 pagini1936 J.M.Keynes. T.Gral - Ocupac.Int - Dinero PDFBryan BernalÎncă nu există evaluări
- Ley de Educación Técnico Profesional 26058Document12 paginiLey de Educación Técnico Profesional 26058Intheyearof39Încă nu există evaluări
- CHEVALLIER, Jean Jacques (1989) "Los Grandes Textos Políticos Desde Maquiavelo A Nuestros Días". Madrid, Aguilar. Capítulo III El Contrato Social (Pág. 145 A 176) .Document17 paginiCHEVALLIER, Jean Jacques (1989) "Los Grandes Textos Políticos Desde Maquiavelo A Nuestros Días". Madrid, Aguilar. Capítulo III El Contrato Social (Pág. 145 A 176) .Fernando Arenas0% (2)
- David Ricardo Principios de Economia Politica y Tributacion Cap 1 y 2 PDFDocument32 paginiDavid Ricardo Principios de Economia Politica y Tributacion Cap 1 y 2 PDFDaniela Peña100% (1)
- La Ciencia Politica Como ProfesionDocument50 paginiLa Ciencia Politica Como ProfesionAdrian Ismael Romero100% (2)
- Jacques Chevalier-Historia Del Pensamiento Tomo IIDocument432 paginiJacques Chevalier-Historia Del Pensamiento Tomo IIFelsonagf100% (3)
- Polanyi, K. - 2001 - La Gran Transformacion - Los Origenes Economicos y Politicos de Nuestro Tiempo. Beacon Press.Document22 paginiPolanyi, K. - 2001 - La Gran Transformacion - Los Origenes Economicos y Politicos de Nuestro Tiempo. Beacon Press.Fernando ArenasÎncă nu există evaluări
- Texto 2 - El Contexto Internacional de La 2 Posguerra - RapoportDocument9 paginiTexto 2 - El Contexto Internacional de La 2 Posguerra - RapoportFernando ArenasÎncă nu există evaluări
- Manual Prezi PDFDocument11 paginiManual Prezi PDFJoel Salazar100% (1)
- Cox, Robert - 1981 - Fuerzas Sociales, Estados y Ordenes Mundiales. Mas Alla de La Teoria de Las Relaciones InternacionalesDocument78 paginiCox, Robert - 1981 - Fuerzas Sociales, Estados y Ordenes Mundiales. Mas Alla de La Teoria de Las Relaciones InternacionalesFernando Arenas100% (1)
- Iniciacion A La Economia MarxistaDocument45 paginiIniciacion A La Economia MarxistaJorge Ait KanariÎncă nu există evaluări
- Historia Del Pensamiento I (El Pensamiento - Chevalier, JacquesDocument368 paginiHistoria Del Pensamiento I (El Pensamiento - Chevalier, JacquesFernando Arenas100% (1)
- X Seneca y Los Padres de La IglesiaDocument9 paginiX Seneca y Los Padres de La IglesiaFernando ArenasÎncă nu există evaluări
- Texto 1 - La Sociedad Contemporanea - Susana BianchiDocument26 paginiTexto 1 - La Sociedad Contemporanea - Susana BianchiFernando ArenasÎncă nu există evaluări
- Etapas Del Creccimiento Econ AL O ConnorDocument19 paginiEtapas Del Creccimiento Econ AL O ConnorFernando ArenasÎncă nu există evaluări
- Marx, Karl - El Capital T1-V1Document213 paginiMarx, Karl - El Capital T1-V1Daniel Suarez RodriguezÎncă nu există evaluări
- Esther Diaz Qué Es La Posmodernidad Pág 11 A 25Document15 paginiEsther Diaz Qué Es La Posmodernidad Pág 11 A 25Fernando ArenasÎncă nu există evaluări
- RODRIGUEZ VARELA, Alberto (1995) "Historia de Las Ideas Políticas". Buenos Aires, A-Z Editora. Capitulo 14 "El Absolutismo" (Pág. 201 A 215) .Document8 paginiRODRIGUEZ VARELA, Alberto (1995) "Historia de Las Ideas Políticas". Buenos Aires, A-Z Editora. Capitulo 14 "El Absolutismo" (Pág. 201 A 215) .Fernando ArenasÎncă nu există evaluări
- Desarrollo EndogenoDocument87 paginiDesarrollo EndogenovianmalÎncă nu există evaluări
- Manual SPSS 13.0 Tomo - 2Document46 paginiManual SPSS 13.0 Tomo - 2Fernando ArenasÎncă nu există evaluări
- Informe InstalacionArranqueDual Cesar CuellarDocument25 paginiInforme InstalacionArranqueDual Cesar CuellarAlex CuéllarÎncă nu există evaluări
- Las Carpetas CompartidasDocument23 paginiLas Carpetas CompartidasCaro BrouchyÎncă nu există evaluări
- TPNDocument2 paginiTPNfedechailaÎncă nu există evaluări
- OpenSUSE 13.1 Con Active Directory Guia IlustradaDocument105 paginiOpenSUSE 13.1 Con Active Directory Guia Ilustradaodioso88Încă nu există evaluări
- Guitar Rig 4 Getting Started SpanishDocument31 paginiGuitar Rig 4 Getting Started SpanishJaxansÎncă nu există evaluări
- Manual de Usuario Sistema de Contribuciones Ver1Document18 paginiManual de Usuario Sistema de Contribuciones Ver1Jose Luis Becerril BurgosÎncă nu există evaluări
- Tutorial DebutDocument6 paginiTutorial Debutamorales11Încă nu există evaluări
- Administración de RedesDocument36 paginiAdministración de RedesΑβγδεΚλμνξ100% (1)
- Manual MaxidasDocument89 paginiManual Maxidasmanuel100% (1)
- Guia Web ServerDocument13 paginiGuia Web ServerGoemon SonoraÎncă nu există evaluări
- Tutorial Efectos en Gimp-2Document77 paginiTutorial Efectos en Gimp-2Jhonie Walker100% (1)
- Corel Draw 12 - Curso CompletoDocument603 paginiCorel Draw 12 - Curso Completorgpontes100% (7)
- DibujosDocument55 paginiDibujosFrancisco MendozaÎncă nu există evaluări
- Ejemplo de Diseño de Marco de Concreto SAP2000Document62 paginiEjemplo de Diseño de Marco de Concreto SAP2000Amanda GriffithÎncă nu există evaluări
- Guia para Utilizar GIMP PDFDocument20 paginiGuia para Utilizar GIMP PDFKimberly DejesusÎncă nu există evaluări
- Códigos de ErrorDocument10 paginiCódigos de ErrorAlejo PalmatramÎncă nu există evaluări
- Cuadros de Excel PDFDocument34 paginiCuadros de Excel PDFAlejandro CarmonaÎncă nu există evaluări
- Band in A BoxDocument486 paginiBand in A BoxEmilio SaugarÎncă nu există evaluări
- Manual para El Desarrollo de Aplicaciones Multilenguaje Con NetbeansDocument7 paginiManual para El Desarrollo de Aplicaciones Multilenguaje Con NetbeansJonathan MataÎncă nu există evaluări
- Elaboracion de Presupuesto en s10-01Document17 paginiElaboracion de Presupuesto en s10-01LuisAlcantaraEstevesÎncă nu există evaluări
- Manual Board MasterDocument6 paginiManual Board MasterchemavalenciaÎncă nu există evaluări
- Reporte Drag and DropDocument11 paginiReporte Drag and DropBen RamosÎncă nu există evaluări
- Retos de ScratchDocument67 paginiRetos de ScratchJuan Gabriel MurciaÎncă nu există evaluări
- Tampón de ClonarDocument4 paginiTampón de ClonarneyigonzalezÎncă nu există evaluări
- Animatefor DummiesDocument116 paginiAnimatefor DummiesFernanda PonceÎncă nu există evaluări
- Ejercicios AltiumDocument28 paginiEjercicios AltiumAdrian CelaÎncă nu există evaluări
- Concepto Limite TecnicoDocument19 paginiConcepto Limite Tecniconetoboy100% (1)
- Normativa para La Inscripción en El Fondo Nacional Del DeporteDocument44 paginiNormativa para La Inscripción en El Fondo Nacional Del Deporteeduardojr140286% (7)
- Manual Contacto APDLDocument8 paginiManual Contacto APDLRebeca LopezÎncă nu există evaluări
- Manual Plataforma para Estudiantes PDFDocument9 paginiManual Plataforma para Estudiantes PDFtlotzinÎncă nu există evaluări