Documente Academic
Documente Profesional
Documente Cultură
Introducci On A La Estad Istica Inferencial: Dr. Oldemar Rodr Iguez Rojas Mayo Del 2001
Încărcat de
Herbert HuarangaTitlu original
Drepturi de autor
Formate disponibile
Partajați acest document
Partajați sau inserați document
Vi se pare util acest document?
Este necorespunzător acest conținut?
Raportați acest documentDrepturi de autor:
Formate disponibile
Introducci On A La Estad Istica Inferencial: Dr. Oldemar Rodr Iguez Rojas Mayo Del 2001
Încărcat de
Herbert HuarangaDrepturi de autor:
Formate disponibile
This is page i
Printer: Opaque this
Introduccion a la Estadstica Inferencial
Dr. Oldemar Rodrguez Rojas
Mayo del 2001
ii
This is page iii
Printer: Opaque this
Contents
1 Probabilidades 3
1 Distribuciones de Probabilidad . . . . . . . . . . . . . . . . 3
2 Distribuciones de probabilidad discretas . . . . . . . . . . . 5
2.1 La distribucion binomial . . . . . . . . . . . . . . . . 5
2.2 La distribucion de Poisson . . . . . . . . . . . . . . . 7
3 La distribucion Normal . . . . . . . . . . . . . . . . . . . . 8
2 Teora del muestreo 13
1 Importancia del muestreo . . . . . . . . . . . . . . . . . . . 13
3 Inferencia Estadstica 17
1 Estimacion puntual . . . . . . . . . . . . . . . . . . . . . . . 17
2 Los estimadores como variables aleatorias . . . . . . . . . . 18
2.1 Distribucion muestral del promedio . . . . . . . . . . 18
2.2 Distribucion muestral de la proporcion . . . . . . . . 22
3 Estimacion por intervalo . . . . . . . . . . . . . . . . . . . . 24
3.1 Intervalo para medias . . . . . . . . . . . . . . . . . 24
3.2 Intervalo para proporciones . . . . . . . . . . . . . . 26
4 Prueba de hipotesis 29
1 Prueba de hipotesis para una poblacion con muestras grandes
(n > 30) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
1.1 Plantear la hipotesis nula y alternativa . . . . . . . . 30
1.2 Seleccionar un nivel de signicancia . . . . . . . . . 30
1.3 Identicar el estadstico de la prueba . . . . . . . . . 31
1.4 En una muestra dada rechazar o aceptar la hipotesis
nula . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1.5 Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . 33
2 Prueba de hipotesis para una poblacion con dos muestras
grandes (n > 30) . . . . . . . . . . . . . . . . . . . . . . . . 35
2.1 Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . 37
5 Teora de muestras peque nas 41
1 La distribucion t de Student . . . . . . . . . . . . . . . . . . 41
2 Estimacion por intervalo para muestras peque nas (n < 30) . 42
2.1 Intervalo de conanza para la media . . . . . . . . 42
1
3 Prueba de hipotesis para muestras peque nas (n < 30) . . . 43
3.1 Prueba de hipotesis para una poblacion con muestra
peque na . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Prueba de hipotesis para una poblacion con dos mues-
tras peque nas . . . . . . . . . . . . . . . . . . . . . . 45
4 Conexion entre los intervalos de conanza y las pruebas de
hipotesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
6 Analisis de la Varianza 51
1 Metodo ANOVA para la comparacion de medias provenientes
de muestras del mismo tama no . . . . . . . . . . . . . . . . 52
2 Metodo ANOVA para la comparacion de medias provenientes
de muestras de distinto tama no . . . . . . . . . . . . . . . . 56
7 Regresion y correlacion 59
1 Metodo de mnimos cuadrados . . . . . . . . . . . . . . . . 59
1.1 Error estandar de la estimacion . . . . . . . . . . . . 63
2 Coeciente de correlacion y determinacion . . . . . . . . . . 65
2.1 El coeciente de correlacion . . . . . . . . . . . . . . 65
2.2 El Coeciente de determinacion . . . . . . . . . . . . 66
3 Estimacion de intervalos de conanza para predecir . . . . . 67
3.1 Prediccion del valor particular de y dado un valor de x 67
3.2 Estimacion del valor esperado (media) de y dado un
valor de x . . . . . . . . . . . . . . . . . . . . . . . . 68
2
This is page 3
Printer: Opaque this
Probabilidades
1 Distribuciones de Probabilidad
Denicin 1 Una variable aleatoria es una funcion del espacio muestral
en un conjunto C.
Observacin 1 Si el conjunto C es nito o numerable la variable aleatoria
X se llama discreta, mientras que si C es no numerable (por ejemplo R)
entonces la variable alaeatoria X se llamara continua.
Ejemplo 1 Si se tiene el experimento de lanzar una moneda entonces =
{Escudo,Corona}, luego podemos denir la variable aleatoria X :
{0, 1} como X(Escudo) = 0 y X(Corona) = 1.
Observacin 2 Notese que P(X = 0) = P(Escudo) =
1
2
y que P(X =
1) = P(Corona) =
1
2
.
Denicin 2 Sea X una variable aleatoria discreta con valores x
1
, x
2
, . . . , x
k
con probabilidades p
1
, p
2
, . . . , p
k
respectivamente, con p
1
+p
2
+ +p
k
= 1.
La funcion denida por P(X = x
k
) := P(x
k
) = p
k
para k = 1, 2, . . . , k se
llama Distribucion de Probabilidad Discreta.
Ejemplo 2 Supongase que se tiene el experimento de lanzar dos dados,
sea x el resultado observado en la cara superior del primer dado y sea y el
resultado observado en la cara superior del segundo dado. Se dene la vari-
able aleatoria X = x +y, es decir el resultado de la suma de los resultados
obtenidos en ambos dados. Entonces X tiene la funcion de probabilidad
que se presenta en la siguente tabla:
Ejemplo 3
x 2 3 4 5 6 7 8 9 10 11 12
p(x)
1
36
2
36
3
36
4
36
5
36
6
36
5
36
4
36
3
36
2
36
1
36
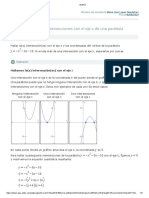
Gracamente se ilustra como sigue (ver gura 1):
Observacin 3 Si X es continua entonces P(X) se llama distribucion de
probalidad continua.
Ejemplo 4 En el siguiente graco se presenta una distribucion de proba-
bilidad continua. El area sobreada representa la probabilidad P(a < X < b).
(ver gura 2)
Ejercicio 1 Hallar la distribucion de probabilidad para la variable aleato-
ria X =n umero de hijos varones en familias de 3 hijos, luego haga la
graca.
4 1. Probabilidades
FIGURE 1. Graco de la distribucion de probabilidad de X.
FIGURE 2. Distribucion de probabilidad continua.
Denicin 3 La funcion acumulativa de probabilidad de una variable aleato-
ria X es la probabilidad de que X sea menor o igual a un valor especco
x. Es decir:
F(x) := P(X x) =
x
i
x
P(x
i
).
Ejemplo 5 Supongase que se tiene nuevamente el experimento de lanzar
dos dados, sea x el resultado observado en la cara superior del primer dado y
sea y el resultado observado en la cara superior del segundo dado. Se dene
la variable aleatoria X = x + y, es decir el resultado de la suma de los
resultados obtenidos en ambos dados. Entonces la funcion de acumulativa
de probabilidad que se presenta en la siguente tabla:
x 2 3 4 5 6 7 8 9 10 11 12
F(x)
1
36
3
36
6
36
10
36
15
36
21
36
26
36
30
36
33
36
35
36
1
Ejercicio 2 Calcule funcion de acumulativa de probabilidad del ejercicio
1.
1. Probabilidades 5
Denicin 4 Sea X una variable aleatoria discreta que puede tomar valores
x
1
, x
2
, . . . , x
k
con probabilidades p
1
, p
2
, . . . , p
k
respectivamente, con p
1
+
p
2
+ +p
k
= 1. La esperanza matematica se dene como:
E(X) = p
1
x
1
+p
2
x
2
+ +p
k
x
k
.
Ejemplo 6 Un boleto de una rifa ofrece dos premios, uno de $5000 y otro
de $2000, con probabilidades 0.001 y 0.003. Cual sera el precio justo a
pagar por el?
Solucin 1 Su esperanza matematica es ($5000)(0.001) +($2000)(0.003) =
$5 + $6 = $11, que es el precio justo.
Ejercicio 3 En un negocio aventurado, una se nora puede ganar $300 con
probabilidad 0.6 o perder $100 con probabilidad 0.4. Hallar su esperanza
matematica.
2 Distribuciones de probabilidad discretas
2.1 La distribucion binomial
Denicin 5 Un experimento se dice binomial si tiene las siguientes car-
actersticas:
1. El experimento consta de n pruebas identicas.
2. Cada prueba tiene 2 resultados, a uno se le llamara el exito E y al
otro el fracaso F.
3. La probabilidad de tener exito en una sola prueba es p, y permanece
constante de prueba en prueba. La probabilidad del fracaso es igual
q = 1 p.
4. Las pruebas son idependientes.
5. La variable aleatoria en estudio es X =n umero de exitos observados.
Ejemplo 7 Supongase que cierto transistor de un radio tiene una proba-
bilidad de 0.2 de funcionar mas de 500 horas: Si probamos 20 transistores,
Cual es la probabilidad de que 3 de ellos funcionen mas de 500 horas?
Solucin 2 Es un experimento binomial pues se vericas las 5 condiciones
de la denicion anterior, veamos:
1. n = 20.
6 1. Probabilidades
2. E = {El transistor funciona mas de 500 horas} y F = {El transistor
funciona menos de 500 horas}.
3. p = 0.2 y q = 0.8, luego p +q = 1.
4. Las pruebas son claramente idependientes.
5. X =n umero de exitos observados en n = 20 pruebas.
Un posible evento es:
E
..
0.2
E
..
0.2
E
..
0.2
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
F
..
0.8
pero existen
_
20
3
_
posibles eventos de este tipo, entonces la probabilidad es:
P(X = 3) =
_
20
3
_
(0.2)
3
(0.8)
17
= 0.205.
En general la probabilidad de tener k exitos es:
P(X = k) =
_
20
k
_
(0.2)
k
(0.8)
nk
=
_
n
k
_
(p)
k
(q)
nk
.
Ejercicio 4 Se lanza un moneda 6 veces. Cual es la probabilidad de obtener
2 escudos?
Denicin 6 La distrucion binomial de una variable aleatoria X se dene
por:
P(X = k) =
_
n
k
_
(p)
k
(q)
nk
=
_
n
k
_
(p)
k
(1 p)
nk
para k = 0, 1, . . . , n.
Ejercicio 5 La experiencia ha demostrado que el 30% de todas las per-
sonas se recuperan de una cierta enfermedad. Si se seleccionan 10 personas
al azar, cual es la probabilidad de que:
1. 9 se recuperen?
2. 10 se recuperen?
3. Al menos 9 se recuperen?
Teorema 1 Sea X una variable aleatoria que sigue una distribucion de
probabilidad binomial, entonces:
1. E(X) = np.
2. La desviacion estandar es =
npq.
Ejemplo 8 En 100 tiradas de una moneda
E(X) = np = 100
1
2
= 50 y =
npq =
_
100
1
2
1
2
= 5.
1. Probabilidades 7
2.2 La distribucion de Poisson
La distribucion de Poisson es un buen modelo para la distribucion de una
variable aleatoria X si esta cuantica el n umero de eventos raros de un
cierto esperimento. Donde por un evento raro entendemos que n es muy
grande y que p la probabilidad de que dicho evento ocurra es muy peque no,
por lo tanto q = 1 p es cas1 1.
Denicin 7 La distrubucion de Poisson de una variable aleatoria X se
dene por:
P(X = k) =
k
e
k!
donde es el valor promedio de X.
Ejemplo 9 Supongase que un sistema aleatorio de una ronda de polica
esta ideado de tal manera que un polica puede visitar cierta localidad de su
ronda X = 0, 1, 2, 3, ... veces en perodos de media hora y que el sistema esta
arreglado de tal manera que pasa por cada localidad un promedio de una
vez por perodo. Supongase que X tiene aproximadamente una distribucion
de probabilidad de Poisson. Calcule la probabilidad de que el polica no
pase por cierta localidad durante un perodo de media hora. Cual es la
probabilidad de que la visite una vez? Dos veces?
Solucin 3 Para este ejemplo el perodo es media hora y la media de las
visitas por intervalo de media hora es 1 . Entonces:
P(X = k) =
1
k
e
1
k!
.
El evento que consiste en que el polica falla en visitar cierta localidad en
un perodo de media hora corresponde a k = 0, luego:
P(X = 0) =
e
1
0!
= 0.368,
Tambien Cual es la probabilidad de que la visite una vez? es P(X = 1) =
1
1
e
1
1!
= 0.368 Dos veces? es P(X = 2) =
1
2
e
1
2!
= 0.184.
Teorema 2 Sea X una variable aleatoria que sigue una distribucion de
probabilidad de Poisson, entonces:
1. E(X) = .
2. La desviacion estandar es =
.
Observacin 4 La distribucion binomial se puede aproximar por la dis-
tribucion de Poisson cuando n es grande y p es peque no.
8 1. Probabilidades
Ejemplo 10 Un 10% de las herramientas producidas en una fabrica son
defectuosas. Hallar la probabilidad de que en una muestra de 10 tomadas
al azar 2 sean defectuosas usando la distribucion binomial y la distribucion
de Poisson.
Solucin 4 1. Usando la distribucion binomial con n = 10, p = 0.1, q =
0.9, E =La herramienta es defectuosa, F =La herramienta NO
es defectuosay X =n umero de herramientas defectuosas, entonces:
P(X = 2) =
_
10
2
_
(0.1)
2
(0.9)
8
= 0.1937.
2. Usando la distribucion Poisson con = E(X) = np = 10 0.1 = 1,
se tiene que:
P(X = 2) =
2
e
2!
=
1
2
e
1
2!
= 0.1839.
Ejercicio 6 Si la probabilidad de que un individuo sufra una reacci on neg-
ativa ante una inyeccion de cierto suero es 0.001, hallar la probabilidad
de que entre 2000 individuos: (a) exactamente 3 y (b) mas de 2 de ellos
reaccionen negativamente.
3 La distribucion Normal
Denicin 8 Una variable aleatoria continua X sigue una distribucion de
probabilidad normal si:
P(X = x) = P(x) =
1
2
e
1
2
(
x
)
2
,
donde:
x es la variacion en consideracion, con < x < .
es la media aritmetica de X, con < < .
es la desvicion estandar de la variable X, con > 0.
Se ilustra gracamente en la gura 3.
Observacin 5 Como existe una cantidad innita de curvas normales, de-
pendiendo de los valores de y , entonces los datos se estandarizan y
se se usa la distribucion de probabilidad normal estandar. Como se hace
texto?. Un dato se estandariza como sigue:
z =
x
.
Luego:
P(X = x) = P(Z = z) =
1
2
e
1
2
z
2
,
1. Probabilidades 9
FIGURE 3. La curva normal
y se usa la tabla del apendice 1 para aproximar los valores de esta funcion.
Gracamente se ilustra el la gura 4.
FIGURE 4. La curva normal estandar.
Ejemplo 11 Los resultados de un examen de admision de un colegio tienen
una distribucion normal con media 75 y desviacion estandar 10. Cual es
la probabilidad de obtener una nota entre 80 y 90?
Solucin 5 Lo primero que se debe hacer es estandarizar la variable:
Z
1
=
80 75
10
= 0.5 y Z
2
=
90 75
10
= 1.5,
10 1. Probabilidades
entonces:
P(80 X 90) = P(0.5 Z 1.5)
= 0.4332 0.1915 = 0.2417.
Esto se ilustra en la siguiente gura.
FIGURE 5. La probabilidad buscada es la parte sobreada.
Ejercicio 7 El peso promedio de 500 estudiantes en la Universidad Latina
es de 151 libras y la desviacion estandar es de 15 libras. Suponiendo que
los pesos estan normalmente distribuidos y redondeados.
1. Cuantos estudiantes pesas entre 120lbs y 155lbs?
2. Cuantos estudiantes pesas mas de 185lbs?
3. Cuantos estudiantes pesas menos de 128lb?
4. Cuantos estudiantes pesas 128lbs?
5. Cuantos estudiantes pesas no mas de 185lbs?
Observacin 6 Se puede probar que cuando n es grande y si ni p ni q
son muy proximos a cero, la distribucion binominal se acerca cada vez
mas a una distribucion normal, es decir la distribucion binominal puede
aproximarse usando una distribucion normal canonica.
Formalmente si X es una variable aleatoria binominal se puede aproxi-
mar por la variable normal canonica (estandar):
Z =
X
=
X np
npq
.
En la practica la aproximacion sera buena si tanto np como nq son
mayores que 5.
En la practica se resta o se suma 0.5 a la variable dado que estamos
aproximando una variable aleatoria discreta por una continua.
1. Probabilidades 11
Ejercicio 8 Hallar la probabilidad de obtener entre 3 y 6 escudos en 10
tiradas de una moneda usando (a) la distribucion binomial (b) la aproxi-
macion normal a la binomial.
Ejercicio 9 Se lanza una moneda 500 veces. Hallar la probabilidad de que
el n umero de caras este entre (a) 240 y 260 (b) entre 220 y 280.
12 1. Probabilidades
This is page 13
Printer: Opaque this
Teora del muestreo
1 Importancia del muestreo
Denicin 9 (Poblacion) Es el total de personas, objetos o mediciones
que tienen una caracterstica com un.
Observacin 7 La poblacion pueder se nita o innita.
Denicin 10 MuestraPoblacion.
Observacin 8 Las muestras generalmente son aleatorias.
Por que se utilizan muestras en lugar de estudiar toda la poblacion?
1. Una poblacion innita o muy grande es imposible estudiarla total-
mente.
2. Puede resultar no imposible pero si muy costosa.
3. En general, no es necesario ya que los resultados que arrojara una
muestra bien seleccionada de tama no razonable seran sucientes.
Denicin 11 La inferencia estadstica es el proceso mediante el cual se
generalizan los resultados observados en una muestra aleatoria a la pobla-
cion total (de la cual se extrajo la muestra).
Observacin 9 La muestras deben ser aleatoria, pues:
1. Elimina los sesgos de seleccion.
2. Los errores aleatorios que se producen son mediables utilizando mod-
elos probabilsticos.
3. El error de muestreo puede hacerse tan peque no como se quiera, au-
mentando el tama no de la muestra.
Observacin 10 El tama no de la muestra n se puede calcular con la si-
guiente formula:
n =
_
z
/2
e
_
2
=
_
z
/2
pq
e
_
2
donde:
e = el error maximo de muestreo que el investigador esta dispuesto a
tolerar.
14 2. Teora del muestreo
= la desvicion estandar de la poblacion.
z
/2
se calcula como sigue:
1 representa el grado de conanza que se tiene contiene el
valor de la poblacion, de esta relacion de calcula .
Se calcula
2
.
Se calcula
_
1
2
_
.
Finalmente se obtiene de z
/2
consultando la tabla acumulada
de la normal estandar y buscando el valor de z para el cual se
encuentra acumulado un
_
1
2
_
% del area bajo la curva.
Ejemplo 12 Se plantea un estudio para determinar el tiempo promedio
que los ni nos de nivel preescolar ven television. Un estudio piloto indico que
el tiempo medio por semana es de 12 horas, con una desviacion estandar
de 3 horas. Se desea estimar el tiempo promedio que un ni no ve television,
pero se desea que la diferencia entre el valor estimado en la muestra se
aleje a lo sumo un cuarto de hora, esto con un nivel de conanza de un
95%. Cuantos ni nos deberan incluirse en la investigacion?.
Solucin 6 e = 0.25 pues se pide que que la diferencia entre el valor
estimado en la muestra se aleje a lo sumo un cuarto de hora.
= 3.
z
/2
se calcula como sigue:
1 = 0.95 de donde obtiene que = 0.05.
Entonces
2
= 0.025.
Luego
_
1
2
_
= 0.975.
Consultando la tabla acumulada de la normal estandar y bus-
cando el valor de z para el cual se encuentra acumulado un
97.5% del area bajo la curva se tiene z = 1.96.
De donde
n =
_
z
/2
e
_
2
=
_
1.96 3
0.25
_
2
= 553.19.
Se debe tomar n = 554.
Ejemplo 13 En una eleccion muy cerrada, un partido poltico desea cono-
cer, por diversas razones, y utilizando la tecnica de encuesta, la proporci on
de personas que piensan votar por el en una ciudad mediana que tiene
2. Teora del muestreo 15
alrededor de 100000 votantes, en la capital que tiene cerca de un millon
de votantes y en todo el pas con un n umero de votantes cercano a los 10
millones. Si se quiere un margen de error maximo de 0,03 y una con-
anza de 95%, que tama no de muestra debe usarse para cada una de estas
encuestas?
Solucin 7 e = 0.03.
Como la elecci on es muy cerrada se puede suponer que la probabilidad
p de que este partido gane las elecciones es del 50%, es decir p = 0.5
por lo que q = 0.5 de donde =
pq =
0.5 0.5 =
0.25 = 0.5.
z
/2
se calcula como sigue:
1 = 0.95 de donde obtiene que = 0.05.
Entonces
2
= 0.025.
Luego
_
1
2
_
= 0.975.
Consultando la tabla acumulada de la normal estandar y bus-
cando el valor de z para el cual se encuentra acumulado un
97.5% del area bajo la curva se tiene z = 1.96.
De donde
n =
_
z
/2
e
_
2
=
_
1.96 0.5
0.03
_
2
= 1067.11.
Se debe tomar n = 1068.
Ejercicio 10 En una region costera de un pas hay un total de 350 escue-
las p ublicas. La Secretara de Instruccion P ublica desea estimar el n umero
de pupitres que por su mal estado deben ser reemplazados, pero temiendo
que los interesados exageren sus necesidades, decide hacer un estudio di-
recto con personal calicado, en una muestra de escuelas. Por un estudio
realizado varios a nos antes se estima que = 55. Que tama no de mues-
tra sugerira Usted, sabiendo que interesa un error de estimacion de 10
pupitres con una conanza del 90%?
Ejercicio 11 La Presidencia de la Rep ublica desea conocer el grado de
acuerdo de los maestros de un pas con ciertos cambios que se desea in-
troducir en el proximo a no lectivo en cuanto a la duracion del curso y el
perodo de vacaciones. Para ello decide hacer un sondeo. Por un estudio
realizado varios a nos antes se sabe que la probabilidad de que los maestros
acepten cambios es bajo, aproximadamente p = 0.3. Estime el tama no de
muestra requerido, si se desea estimar la proporcion que esta de acuerdo
con los cambios, con una conanza de 90% y con un error no mayor de 5
puntos porcentuales.
16 2. Teora del muestreo
This is page 17
Printer: Opaque this
Inferencia Estadstica
1 Estimacion puntual
Denicin 12 Todas aquellas medidas que se extraen estudiando toda la
problacion de llaman Parametros.
Denicin 13 Las medidas que provienen de una muestra aleatoria se lla-
man Estimadores.
Observacin 11 Las caractersticas de un buen estimador son:
1. Insesgado: se dice que un estimador es insesgado si el promedio de
ese estimador es igual al parametro que va a estimar.
2. Eciente: Se dice que un estimador es eciente si tiene la menor
varianza. Es decir si al comparar dos estimadores de una muestra
del mismo tama no y tratamos de decidir cual de los dos estimadores
es mas eciente, seleccionaramos aquel estimador que tenga el error
estandar o desviacion estandar mas peque no.
3. Consistente: Un estimador es consistente si al aumentar el tama no
de la muestra se logra una seguridad casi absoluta de que el valor del
estadstico se acerca mucho al valor del parametro, es decir se torna
mas conable entre mas grande sea la muestra.
4. Suciente: Un estimador es suciente si utiliza la informacion con-
tenida en la muestra, a tal grado que ning un otro estimador podra
extraer de esa muestra mas informacion referente al parametro que
va a ser estimado.
Denicin 14 Un Estimador Puntual es un n umero que se emplea para
estimar un parametro poblacional.
Ejemplo 14 La media de la muestra, denotada por
x
, es un estimador
puntual de la media poblacional , es un buen estimador puesto que es
insesgada, eciente, consistente y suciente. De igual manera la desviacion
estandar de la muestra, denotada por
x
, es un buen estimador de la
desviacion estandar de la poblacion .
Ejemplo 15 La proporcion de unidades que poseen una caracterstica par-
ticular en determinada poblacion se representa con P. Si se conoce la pro-
porcion de unidades de una muestra que tienen esa caracterstica, deno-
tada por p, se puede utilizar esta ultima como un estimador de P. Puede
demostrarse que p tiene todas las caractersticas deseables de un buen es-
timador: insesgado, consistente, suciente y eciente.
18 3. Inferencia Estadstica
2 Los estimadores como variables aleatorias
Debido a que los estimadores se obtienen de una muestra y se pueden
obtener distintas muestras de un mismo tama no, de la misma poblacion y
cada una de esas muestras produce un estimador, entonces los estimadores
se convierten en variables aleatorias sujetas a una determinada muestra, y
por lo tanto al ser variables aleatorias tienen una distribucion de probabili-
dad. A esta distribucion de probabilidad se le conoce como Distribucion
Muestras.
2.1 Distribucion muestral del promedio
Supongase que de una poblacion se seleccionan muestras de tama no n y
que para cada una de ellas se calcula su media x, entonces surgen varias
preguntas:
Cual es la distribucion de x?
Cual es la media de la distribucion de x? es decir: E(x) =?
Cual es la varianza de la distribucion de x? es decir:
E
_
(x E(x))
2
=?
Ejemplo 16 Considere una poblacion formada por 5 escuelas denotadas
por A, B, C, D, E con el n umero de maestros que se presenta en la siguiente
tabla:
Escuela N umero de Maestros
A 2
B 3
C 4
D 5
E 6
Es claro que la media de la ploblacion es = 4 y que la varianza es
2
= 2.
Que pasa si se toman muestras de tama no 2?
Notese que existen
_
5
2
_
= 10 muestras sin reemplazo de tama no 2 que se
pueden tomar de esta poblacion. Las 10 muestras, el n umero de maestros
y sus respectivas medias se muestran en la siguiente tabla:
3. Inferencia Estadstica 19
Muestras N umero de Maestros Promedio
x
A, B 2, 3 2.5
A, C 2, 4 3
A, D 2, 5 3.5
A, E 2, 6 4
B, C 3, 4 3.5
B, D 3, 5 4
B, E 3, 6 4.5
C, D 4, 5 4.5
C, E 4, 6 5
D, E 5, 6 5.5
Luego los promedios varan entre 2.5 y 5.5 con la siguiente distribucion
de probabilidad:
k 2.5 3 3.5 4 4.5 5 5.5
p(x) = k
1
10
1
10
2
10
2
10
2
10
1
10
1
10
Luego la esperenza matematica (media) de esta distribucion es:
x
= E(x) =
1
10
2.5 +
1
10
3 +
2
10
3.5+
2
10
4 +
2
10
4.5 +
1
10
5 +
1
10
5.5 = 4
y la varianza es:
2
x
=
1
n
n
i=1
(x
x
)
2
=
1
10
10
i=1
(x
x
)
2
= 0.75
Que pasa si se toman muestras de tama no 3?
Notese que existen
_
5
3
_
= 10 muestras sin reemplazo de tama no 3 que se
pueden tomar de esta poblacion. Las 10 muestras, el n umero de maestros
y sus respectivas medias se muestran en la siguiente tabla:
Muestras N umero de Maestros Promedio
x
A, B, C 2, 3, 4 3
A, B, D 2, 3, 5 3.3
A, B, E 2, 3, 6 3.7
A, C, D 2, 4, 5 3.7
A, C, E 2, 4, 6 4
A, D, E 2, 5, 6 4.3
B, C, D 3, 4, 5 4
B, C, E 3, 4, 6 4.3
B, D, E 3, 5, 6 4.7
C, D, E 4, 5, 6 5
20 3. Inferencia Estadstica
Luego los promedios varan entre 2.5 y 5.5 con la siguiente distribucion
de probabilidad:
k 3 3.3 3.7 4 4.3 4.7 5
p(x) = k
1
10
1
10
2
10
2
10
2
10
1
10
1
10
Luego la esperenza matematica (media) de esta distribucion es:
x
= E(x) =
1
10
3 +
1
10
3.3 +
2
10
3.7+
2
10
4 +
2
10
4.3 +
1
10
4.7 +
1
10
5 = 4
y la varianza es:
2
x
=
1
n
n
i=1
(x
x
)
2
=
1
10
10
i=1
(x
x
)
2
= 0.334
Observacin 12 Del ejemplo anterior se pueden observar varias aspectos
importantes:
x es una variable aleatoria.
La media de la poblacion global = 4 es igual a la esperanza
matematica de la variable aleatoria x = 4.
La variable aleatoria x tiene un comportamiento como una variable
aleatoria normal y entre mayor sea el tama no de la muestra mayor es
la concentracion de los datos alrededor de la media, pues la varianza
se reduce.
Pero en general Cual es el valor esperado (esperanza matematica) y la
varianza de la distribucion x?
Teorema 3 Supongase que se tiene una poblacion de tama no N y se
toman muestras de tama no n, sin reposicion, entonces:
x
= ,
2
x
=
2
n
N n
N 1
.
donde
2
y son la varianza y la media de la poblacion total respecti-
vamente.
Observacin 13 El factor
N n
N 1
se denomina factor de correccion para
poblaciones nitas.
3. Inferencia Estadstica 21
Teorema 4 Supongase que se tiene una poblacion de tama no N y se
toman muestras de tama no n con reposicion, o si la poblacion es innita,
entonces:
x
= ,
2
x
=
2
n
.
donde
2
y son la varianza y la media de la poblacion total respecti-
vamente.
Ejemplo 17 Una poblacion consta de los n umeros 2, 3, 6, 8 y 11. Con-
sideremos todas las posibles muestras de tama no 2 que pueden tomarse
con reposicion de esa poblacion. Hallar (a) la media de la poblacion, (b)
la varianza de la poblacion, (c) la media de la distribucion de muestreo de
medias y (d) la varianza de la distribucion de muestreo de medias.
Solucin 8 (a) =
2 + 3 + 6 + 8 + 11
5
= 6.
(b)
2
=
(2 6)
2
+ (3 6)
2
+ (6 6)
2
+ (8 6)
2
+ (11 6)
2
5
= 10.8.
(c) Hay 5(5) = 25 muestras de tama no 2 que se pueden tomar, con
reposicion de la poblacion (porque cualquiera de los 5 n umeros de la
primera extraccion puede asociarse con uno cualquiera de la segunda),
y son:
(2, 2) (2, 3) (2, 6) (2, 8) (2, 11)
(3, 2) (3, 3) (3, 6) (3, 8) (3, 11)
(6, 2) (6, 3) (6, 6) (6, 8) (6, 11)
(8, 2) (8, 3) (8, 6) (8, 8) (8, 11)
(11, 2) (11, 3) (11, 6) (11, 8) (11, 11)
Las correspondientes medias muestrales son:
2 2.5 4 5 6.5
2.5 3 4.5 5.5 7
4 4.5 6 7 8.5
5 5.5 7 8 9.5
6.5 7 8.5 9.5 11
(3.1)
de donde la media de la distribucion de muestreo x es:
x
=
suma de todas las medias muestrales en 3.1
25
= 6.0.
con lo que se conrma que =
x
= 6.0.
22 3. Inferencia Estadstica
(d) La varianza de la distribucion de muestreo de medias. es:
2
x
=
2
n
=
10.8
2
= 5.4. Se puede vericar este resultado calculando directamente
con la denicion la varianza la de la tabla 3.1.
Ejercicio 12 Resuelva el ejemplo anterior para el caso de muestreo sin
reposicion.
Ejemplo 18 Las alturas de 3000 estudiantes varones de una universidad
estan normalmente distribuidas con media 68.0 in y desviacion tpica 3.0 in.
Si se toman 80 muestras de 25 estudiantes cada una. Cuales seran la media
y la desviacion tpica esperadas de la resultante distribucion de muestreo
de medias, si el muestreo se hizo (a) con reposicion (b) sin reposicion?
Solucin 9 1.
x
= = 68 y
x
=
n
=
3
25
= 0.6.
2.
x
= = 68 y
x
=
n
_
N n
N 1
=
3
25
_
3000 25
3000 1
= 0.5975
Ejercicio 13 En cuantas muestras del problema anterior esperaramos
encontrar una media (a) entre 66.8 y 68.3 in y (b) menor que 66.4 in?
2.2 Distribucion muestral de la proporcion
En muchas oportunidades no interesa realizar inferencias acerca de un
promedio poblacional , sino respecto a la proporcion de elementos en
la poblacion que tienen una cierta caracterstica, o sea, acerca de una pro-
porcion P.
As, por ejemplo, al director de un colegio podra interesarle la proporcion
de sus N = 2000 alumnos que disponen de computadora en el hogar N
1
. El
valor poblacional de interes es P =
N
1
N
, y para estimarlo, podra tomarse
una muestra de n estudiantes, determinar cuantos de ellos tienen computa-
dora (n
1
) y luego calcular el valor muestras p =
n
1
n
. Con este valor p se
estima el valor poblacional P. Otro ejemplo de poblacion puede ser la de
todas las posibles tiradas de una moneda, en la que la probabilidad (pro-
porcion) de escudo es P =
1
2
, en este caso p sera proporcion de escudos
en las n tiradas..
Teorema 5 Supongamos que una poblacion es innita (o nita en la que el
muestreo se hace con reposicion) y que la probabilidad de ocurrencia de un
suceso (exito) es p, mientras la probabilidad de que no ocurra es q = 1 p.
Consideremos todas las posibles muestras de tama no n de tal poblacion, y
cada una de ellas determinemos la proporcion de exitos p. Obtenemos as la
3. Inferencia Estadstica 23
Distribucion de Muestreo de Proporciones con media
p
y varianza
2
p
dadas por:
p
= p, (3.2)
2
p
=
pq
n
=
p(1 p)
n
.
Observacin 14 Para poblaciones nitas en que se haga muestreo sin reposicion,
las ecuaciones 3.2 quedan sustituidas por las ecuaciones 3.3:
p
= p, (3.3)
2
p
= pq = p(1 q)
Ejemplo 19 Hallar la probabilidad de que en 120 lanzamientos de una
moneda (a) entre el 40% y el 60% sean escudos y (b)
5
8
o mas sean coro-
nas. (c) Si 500 personas lanzan una moneda 120 veces, cuantas personas
obtendran entre el 40% y el 60% de escudos?
Solucin 10 (a)
p
= p =
1
2
= 0.5,
p
=
_
pq
n
=
1
2
1
2
120
= 0.046.
Si X =proporcion de escudos obtenidos, entonces se debe calcular
la probabilidad P(0.4 X 0.6). La variable aleatoria X se debe
estandarizar y ademas dado que como la proporcion X es una variable
aleatoria discreta entonces se debe restar
1
2n
=
1
2 120
= 0.00417 a
0.4 y sumarlos a 0.6, luego:
P
_
(0.4 0.00417) 0.5
0.046
Z
(0.6 + 0.00417) 0.5
0.046
_
=
P(2.28 Z 2.28) = 09887 0.01130 = 0.9774
(b) Como
5
8
= 0.6250 se debe calcular P(X 0.6250), veamos:
P(X 0.6250) = 1 P(X < 0.6250)
1 P
_
Z <
(0.6250 0.00417) 0.5
0.046
_
=
1 P (Z < 2.65) = 1 0.99598 = 0.004
24 3. Inferencia Estadstica
(c) Por (a) sabemos que el 97.74% de las 500 personas obtendran entre
el 40% y el 60% de escudos, es decir 489 personas.
Ejercicio 14 Se ha encontrado que el 2% de las piezas fabricadas en una
cierta maquina son defectuosas Cual es la probabilidad de que en un envo
de 400 piezas (a) el 3% o mas y (b) el 2% o menos, sean defectuosas?.
Ejercicio 15 En unas elecciones uno de los candidatos obtuvo el 46% de
los votos. Hallar la probabilidad de que en un muestreo de (a) 200 y (b)
1000 votantes elegidos al azar salga mayora a su favor.
3 Estimacion por intervalo
Anteriormente se explico la estimacion puntual, en la cual se da un valor
puntual para estimar un parametro poblacional, ahora se tratara la esti-
macion por intervalo, la cual consiste en expresar un intervalo dentro del
cual se espera que este el parametro poblacional, a este intervalo por lo
general se le conoce como intervalo de conanza o lmites de conanza.
En este tipo de estimacion se da un lmite inferior y un lmite superior,
dentro de los cuales vamos a esperar con un nivel de conanza dado, que
ese intervalo contenga al parametro poblacional.
3.1 Intervalo para medias
Teorema 6 Si se tiene una muestra de una poblacion inninta o nita con
reposicion de tama no n, entonces el intervalo de conanza para la media
de una poblacion esta dado por:
_
x z
/2
n
, x +z
/2
n
_
,
es decir:
_
x z
/2
n
, x +z
/2
n
_
,
o equivalentemente:
x z
/2
n
< < x +z
/2
n
,
donde x y podran calcularse como se explico en la seccion anterior.
Teorema 7 Si se tiene una muestra de tama no n de una poblacion nita
de tama no N, entonces el intervalo de conanza para la media de una
poblacion esta dado por:
_
x z
/2
n
_
N n
N 1
, x +z
/2
n
_
N n
N 1
_
,
3. Inferencia Estadstica 25
es decir:
_
x z
/2
n
_
N n
N 1
, x +z
/2
n
_
N n
N 1
_
,
o equivalentemente:
x z
/2
n
_
N n
N 1
< < x +z
/2
n
_
N n
N 1
.
Ejemplo 20 Las medidas de la altura de una muestra aleatoria de 100
estudiantes de la XYZ (que tiene 1546 estudiantes), dieron una media de
67.45 in y una desviacion tpica de 2.93 in. Hallar los lmites del intervalo
para el promedio la altura de todos los estudiantes con una conanza del
95%.
Solucin 11 x = 67.45, = 2.93, n = 100. Luego z
/2
se calcula como
sigue:
1 = 0.95 de donde obtiene que = 0.05.
Entonces
2
= 0.025.
Luego
_
1
2
_
= 0.975.
Consultando la tabla acumulada de la normal estandar y buscando
el valor de z para el cual se encuentra acumulado un 97.5% del area
bajo la curva se tiene z = 1.96.
Como
_
N n
N 1
=
_
1546 100
1546 1
= 0.967 1 se puede usar la formula:
x z
/2
n
< < x +z
/2
n
,
en lugar de la formula:
x z
/2
n
_
N n
N 1
< < x +z
/2
n
_
N n
N 1
.
Entonces debe cumplir:
67.45 1.96
2.93
100
< < 67.45 + 1.96
2.93
100
,
o sea
66.88 < < 68.02,
de donde se puede concluir que tenemos un nivel de conanza del 95% de
la altura promedio (o media verdadera) de un estudiante este entre 66.88
in y 68.02 in
26 3. Inferencia Estadstica
Ejemplo 21 Para determinar el n umero promedio de cursos que un es-
tudiante universitario aprueba en un semestre, se procedio a seleccionar
una muestra aleatoria de 36 estudiantes universitarios, a los cuales se les
pregunto cuantos cursos aprobaron el ultimo semestre; de la informacion
obtenida se obtuvo que en promedio los estudiantes aprobaron 2.6 cur-
sos en un semestre; de los registros de la universidad se determino que la
desviacion estandar del n umero de cursos aprobados es de 0.30. Con la
informacion anterior, encuentre una estimacion por intervalo del n umero
promedio de cursos aprobados por todos los estudiantes con un nivel de
conanza del 95%.
Solucin 12 x = 2.6, = 0.3, n = 36. Luego z
/2
se calcula como sigue:
1 = 0.95 de donde obtiene que = 0.05.
Entonces
2
= 0.025.
Luego
_
1
2
_
= 0.975.
Consultando la tabla acumulada de la normal estandar y buscando
el valor de z para el cual se encuentra acumulado un 97.5% del area
bajo la curva se tiene z = 1.96.
De donde:
x z
/2
n
< < x +z
/2
n
es:
2.6 1.96
0.3
36
< < 2.6 + 1.96
0.3
36
o sea
2.5 < < 2.7,
de donde se puede concluir que con un nivel de conanza del 95% que
un estudiante aprueba en promedio entre 2.5 y 2.7 cursos por semestre.
Ejercicio 16 Las medidas de los diametros de una muestra aleatoria de
200 bolas de rodamientos producidas por una maquina en una semana,
dieron una media de 0.824 cm y una desviacion tpica de 0.042 cm. Hallar
los lmites del intervalo para el diametro medio de todas las bolas con un
nivel de conanza de (a) 95% y (b) 99% .
3.2 Intervalo para proporciones
Teorema 8 Si se tiene una muestra de una poblacion innina o nita
con reposicion de tama no n, entonces el intervalo de conanza para la
3. Inferencia Estadstica 27
proporcion P de la poblacion esta dado por:
_
p z
/2
_
pq
n
, p +z
/2
_
pq
n
_
,
es decir:
P
_
p z
/2
_
pq
n
, p +z
/2
_
pq
n
_
,
o equivalentemente:
p z
/2
_
pq
n
< P < p +z
/2
_
pq
n
,
donde p es la proporcion muestral que podra calcularse como se explico
en la seccion anterior.
Teorema 9 Si se tiene una muestra de tama no n de una poblacion nita
de tama no N, entonces el intervalo de conanza para la proporcion P de
la poblacion esta dado por:
_
p z
/2
_
pq
n
_
N n
N 1
, p +z
/2
_
pq
n
_
N n
N 1
_
,
es decir:
P
_
p z
/2
_
pq
n
_
N n
N 1
, p +z
/2
_
pq
n
_
N n
N 1
_
,
o equivalentemente:
p z
/2
_
pq
n
_
N n
N 1
< P < p +z
/2
_
pq
n
_
N n
N 1
,
donde p es la proporcion muestral que podra calcularse como se explico
en la seccion anterior
Ejemplo 22 Un sondeo de 100 votantes elegidos al azar en un distrito
indica que el 55% de ellos estaban a favor de un cierto candidato. Hallar
los intervalos de conanza (a) 95%, (b) 99% para la proporcion de todos
los votantes favorables a ese candidato.
Solucin 13 p = 0.55, q = 0.45 y n = 100.
(a) z
/2
fue calculado en el ejemplo n umero 21, entonces los lmites de
conanza 95% para la poblacion P son:
0.55 1.96
_
0.55 0.45
100
< P < 0.55 + 1.96
_
0.55 0.45
100
,
28 3. Inferencia Estadstica
o sea que el intervalo de conanza es:
0.45 < P < 0.65,
lo que signica que entre el 45% y 65% de la poblacion total esta a
favor de ese candidato con una conanza del 95%.
(b) Se debe calcular z
/2
como sigue:
1 = 0.99 de donde obtiene que = 0.01.
Entonces
2
= 0.005.
Luego
_
1
2
_
= 0.995.
Consultando la tabla acumulada de la normal estandar y bus-
cando el valor de z para el cual se encuentra acumulado un 99.5%
del area bajo la curva se tiene z = 2.58.
El intervalo de conanza 99% para la poblacion P es:
0.55 2.58
_
0.55 0.45
100
< P < 0.55 + 2.58
_
0.55 0.45
100
,
o sea, lo lmites de conanza son:
0.42 < P < 0.68,
lo que signica que entre el 42% y 68% de la poblacion total esta a
favor de ese candidato con una conanza del 99%.
Ejemplo 23 De que tama no hay que tomar el sondeo del ejemplo anterior
para tener conanza al (a) 95% y (b) 99% de que el candidato saldra electo?
Solucin 14 (a) Seg un la parte (a) el ejemplo anterior P vara como
sigue:
0.55 1.96
_
0.55 0.45
n
< P < 0.55 + 1.96
_
0.55 0.45
n
,
el candidato resulta ganador si P > 0.5, es decir si obtiene mas del
50% de los votos, esto implica que:
1.96
_
0.55 0.45
n
< 0.05 n > 384.2,
de donde se deduce que se puede tomar un tama no de muestra de
n = 385.
(b) Ejercicio.
This is page 29
Printer: Opaque this
Prueba de hipotesis
1 Prueba de hipotesis para una poblacion con
muestras grandes (n > 30)
En la seccion aterior, se desarrollo e ilustro una de las tecnicas mas utiles
de la inferencia estadstica: la estimacion de intervalo. En esta seccion,
aprenderemos acerca de la prueba de hipotesis, el tipo mas com un de infer-
encia estadstica. La prueba de hipotesis ha llegado a ser una caracterstica
universal de la investigacion.
La prueba de hipotesis emplea los mismos conceptos que se usan en la
estimacion de intervalos. El muestreo aleatorio, las distribuciones aleato-
rias, y los valores de probabilidad asociados con los intervalos de conanza
seran vistos ahora en el contexto de la prueba de hipotesis.
La prueba de hipotesis y la estimacion del intervalo se llevan a cabo con
diferente terminologa, pero veremos que producen conclusiones y resulta-
dos comparables que facilmente se convierten de uno al otro. La pregunta
basica dirigida por ambos procedimientos esta relacionada con que puede
estipularse acerca de los parametros de la poblacion y cual es el nivel de
conanza.
En muchos aspectos el procedimiento formal para la prueba de hipotesis
es similar al metodo cientco. El cientco observa la naturaleza, establece
una teora y despues prueba su teora respecto de la observacion. En este
contexto el cientco propone una teora relativa a los valores especcos
de uno o mas parametros poblacionales. Luego obtiene una muestra de la
poblacion y compara la observacion con la teora. Si las observaciones se
contraponen a la teora, el cientco rechaza la hipotesis. En caso contrario
concluye que la teora es valida o bien que la muestra no detecto la dife-
rencia entre los valores reales y los valores de la hipotesis respecto de los
parametros poblacionales.
Los pasos para probar una hipotesis en una poblacion con muestras
grandes (n > 30) son:
Paso 1: Plantear la hipotesis nula y alternativa.
Paso 2: Seleccionar un nivel de signicancia Seleccionar la region de
rechazo.
Paso 3: Identicar el estadstico de la prueba.
Paso 4: En una muestra dada rechazar o aceptar la hipotesis nula.
Veamos en detalle cada uno de estos pasos:
30 4. Prueba de hipotesis
1.1 Plantear la hipotesis nula y alternativa
Al intentar alcanzar una decision, es util hacer hipotesis (o conjeturas)
sobre la poblacion implicada. Tales hipotesis, que pueden ser o no ciertas,
se llaman Hipotesis Estadsticas. Son, en general, enunciados acerca de
las distribuciones de probabilidad de las poblaciones, formalmente:
Denicin 15 Una Hipotesis Estadstica es una armacion o conjetura acer-
ca de una o mas poblaciones.
En muchos casos formulamos una hipotesis estadstica con el unico proposito
de rechazarla o invalidarla. As, si queremos decidir si una moneda esta ma-
nipulada, formulamos la hipotesis de que la moneda es buena (o sea, p = 0.5,
donde p es la probabilidad de escudo). Analogamente, si deseamos de-
cidir si un procedimiento es mejor que otro, formulamos la hipotesis de que
no hay diferencia entre ellos (o sea, que cualquier diferencia observada se
debe simplemente a uctuaciones en el muestreo de la misma poblacion).
Tales hipotesis se suelen llamar Hipotesis Nula y se denotan por H
0
,
formalmente:
Denicin 16 Una Hipotesis Nula (Ho) es una armacion o enunciado ten-
tativo que se realiza acerca del valor de un parametro poblacional. Por lo
general es una armacion de que el parametro tiene un valor especco,
es decir la hipotesis siempre se plantea especicando un parametro de la
poblacion (, P, ).
Toda hipotesis que diera de una hipotesis nula dada se llamara una
Hipotesis Alternativa. Por ejemplo, si una hipotesis es p = 0.5, hipotesis
alternativas podran ser p = 0.7, p < 0.5 o p > 0.5. Una hipotesis alterna-
tiva a la hipotesis nula se denotara por H
1
, formalmente:
Denicin 17 Una Hipotesis Alternativa (H
1
) es una armacion o enuncia-
do que se aceptara si los datos muestrales proporcionan amplia evidencia
de que la hipotesis nula es falsa.
1.2 Seleccionar un nivel de signicancia
Si rechazamos una hipotesis cuando debiera ser aceptada, diremos que se
ha cometido un Error Tipo 1. Por otra parte, si aceptamos una hipotesis
que debiera ser rechazada, diremos que se ha cometido un Error de Tipo
II. En ambos casos, se ha producido un juicio erroneo.
Para que las reglas de decision (o contrastes de hipotesis) sean buenas,
deben dise narse de modo que minimicen los errores de la decision. Y no
es una cuestion sencilla, porque para cualquier tama no de la muestra, un
intento de disminuir un tipo de error suele ir acompa nado de un crecimiento
del otro tipo. En la practica, un tipo de error puede ser mas grave que el
otro, y debe alcanzarse un compromiso que disminuya el error mas grave.
4. Prueba de hipotesis 31
La unica forma de disminuir ambos a la vez es aumentar el tama no de la
muestra, que no siempre es posible.
Denicin 18 Al contrastar una cierta hipotesis, la maxima probabilidad
con la que estamos dispuestos a correr el riesgo de cometer un Error de
Tipo 1 se llama Nivel de Signicacion del contraste. Esta probabilidad
denotada a menudo por , se suele especicar antes de tomar la muestra,
de manera que los resultados obtenidos no inuyan en nuestra eleccion.
En la practica, es frecuente un nivel de signicacion de 0.05 o 0.01, si
bien se usan otros valores. Si, por ejemplo, se escoge el nivel de signi-
cacion 0.05 (o 5%) al dise nar una regla de decision, entonces hay unas 5
oportunidades entre 100 de rechazar la hipotesis cuando debiera haberse
aceptado; es decir, tenemos un 95% de conanza de que hemos adoptado
la decision correcta. En tal caso decimos que la hipotesis ha sido rechazada
al nivel de signicacion 0.05, lo cual quiere decir que la hipotesis tiene una
probabilidad 0.05 de ser falsa.
1.3 Identicar el estadstico de la prueba
Para muestras grandes (n > 30), las distribuciones de muestreo de muchos
estadsticos son distribuciones normales (o casi normales), en la practica se
suelen usar los estadsticos de las medias o de las proporciones.
1. Medias: El valor del estadstico z sera:
z =
x
n
.
donde x es la media de la muestra, la media de la poblacion, es
la desviacion estandar de la poblacion y n el tama no de la muestra.
2. Proporciones: El valor del estadstico z sera:
z =
p P
_
PQ
n
.
donde p la proporcion de exitos en una muestra, P es la proporcion
de exitos en la poblacion, Q = 1 P y n es el tama no de la muestra.
1.4 En una muestra dada rechazar o aceptar la hipotesis nula
Para ilustrar las ideas presentadas hasta este momento, supongamos que
bajo cierta hipotesis la distribucion de muestreo de un estimador S (que
podra se la media x o la proporcion p) es una distribucion normal con
media
s
y desviacion estandar
s
. As pues, la distribucion de la variable
32 4. Prueba de hipotesis
FIGURE 1. Distribucion de la variable estandarizada z.
z estandarizada, dada por z =
S
s
s
, es la distribucion normal canonica
(media 0, varianza l), como indica la Figura 1.
Como se ve en la Figura 1, si deseamos tener, por ejemplo un 95% de
conanza de que la hipotesis hipotesis nula H
0
es falsa y que por lo tanto
la hipotesis alternativa H
1
es verdadera, entonces el valor de z para un
estimador muestral S estara entre 1.96 y 1.96 (porque el area bajo la
curva normal entre esos valores es 0.95). Sin embargo, si al escoger una
sola muestra al azar hallamos que el valor de z esta fuera de ese rango,
debemos concluir que tal suceso podra ocurrir con una probabilidad de
solo 0.05 (el area total sombreada en la gura 1). Diremos entonces que z
diere de forma signicativa de lo que sera de esperar bajo la hipotesis,
y nos veramos empujados a aceptar la hipotesis nula H
0
y por lo tanto a
rechazar la hipotesis alternativa H
1
.
El area total sombreada 0.05 es el nivel de signicacion del contraste,
representa la probabilidad de equivocarnos al rechazar la hipotesis (o sea,
la probabilidad de un error de Tipo l). As pues, decimos que la hipotesis
se rechaza a un nivel de signicacion 0.05, o que el valor del estadstico z
en la muestra es signicativo con un nivel 0.05 (nivel de signicancia).
El conjunto de z fuera del rango 1.96 a 1.96 se llama la region crtica de
la hipotesis (region de rechazo de la hipotesis o region de signicancia). El
conjunto de z en el rango 1.96 a 1.96 se conoce como region de aceptacion
de la hipotesis o region de no signicacion.
Basados en las anteriores observaciones, podemos formular la siguiente
regla de decision (o contraste de hipotesis o signicacion):
Rechazar la hipotesis H
0
nula al nivel de signicacion 0.05 (acep-
tar la hipotesis alternativa H
1
) si el valor de z para el estadstico S esta
fuera del rango 1.96 a 1.96 (o sea, si z > 1.96 o z < 1.96). Esto equiv-
ale a decir que el estadstico muestral observado es signicativo al nivel de
signicancia 0.05.
Aceptar la hipotesis nula H
0
en caso contrario (o, si se desea, no
tomar decision alguna).
En general el procedimiento es la siguiente:
4. Prueba de hipotesis 33
1. Usando el nivel de signicacion el valor crtico de la prueba Z
t
se busca directamente en la tabla de la normal acumulativa, si trata
de un problema de dos colas (el signo en la hipotesis alternativa es
H
1
es =) se debe buscar el valor de 1
2
y si es un problema de
una cola se busca 1 . Para representar el area de aceptacion y de
rechazo se le asigna un signo positivo o negativo de acuerdo con la
direccion de la hipotesis alternativa H
1
(positivo si el signo es > y
negativo si el signo es <).
2. Calcule el valor del estadstico z elegido en el Paso 3 usando la
tabla acumulativa para la curva normal estandar, lo denotamos por
Z
c
.
3. La regla de decision es la siguiente:
Si |Z
c
| > |Z
t
| se rechaza H
0
y se acepta H
1
.
Si |Z
c
| < |Z
t
| no se rechaza H
0
.
1.5 Ejemplos
Ejemplo 24 Se sabe que la distribucion de las tasas de eciencia para
los trabajadores de produccion en cierta compa na se distribuye normal-
mente con media poblacional igual a 200 y una desviacion estandar de 16.
El departamento de investigacion cuestiona esa media, armando que es
diferente de 200. Para ello selecciona una muestra de 100 trabajadores de
la compa na y se analizaron las calicaciones de eciencia, obteniendose
una tasa promedio de eciencia en la muestra de 203.5. Pruebe la hipotesis
con un nivel de signicancia del 1%.
Solucin 15 Paso 1:
La hipotesis nula H
0
es: = 200.
La hipotesis alternativa H
1
es: = 200.
Paso 2: Se utilizara un nivel de signicancia de 1%.
Paso 3: El estadstico de la prueba es Z
c
, debido a que se conoce la
desviacion de la poblacion, es:
Z
c
=
x
n
=
203.5 200
16
100
= 2.19.
Paso 4: Para calcular el valor crtico de la prueba; como es una prueba de
dos colas, la mitad de 0.01, o sea, 0.005 esta en cada zona de rechazo,
y el area de aceptacion se encuentra entre las dos colas, y es por lo
34 4. Prueba de hipotesis
tanto 0.99. Se busca en la tabla de la distribucion normal el valor de
z asociado a una probabilidad de 0.005 y se obtiene que, Z
t
= 2.58
y se plantea la regla de decision:
|Z
c
| < |Z
t
| |2.19| < | 2.58| entonces no se rechaza H
0
,
por lo que se concluye que no existe suciente evidencia para creer
que la tasa de eciencia de los trabajadores es distinta a 200.
Ejemplo 25 Se desea realizar un estudio para determinar si por lo menos
el 55% de las familias desean pasar sus estas de n de a no en un hotel de
playa, por ello, se selecciono una muestra de 400 familias y se les pregunto
en que lugar preferan pasar sus vacaciones de n de a no; al respecto 228
familias respondieron que deseaban sus vacaciones en un hotel de playa,
con un nivel de signicancia del 1%; pruebe la hipotesis planteada.
Solucin 16 Paso 1:
La hipotesis nula H
0
es: P = 0.55.
La hipotesis alternativa H
1
es: P > 0.55.
Paso 2: Se utilizara un nivel de signicancia de 1%.
Paso 3: El estadstico de la prueba es Z
c
:
Z
c
=
p P
_
PQ
n
=
0.57 0.55
_
(0.55)(0.45)
400
= 0.80.
Note que p =
228 100
400
= 57%, es decir el porcentaje de familias
respondieron que deseaban sus vacaciones en un hotel de playa.
Paso 4: Para calcular el valor crtico de la prueba, como es una prueba de
una cola, el area de aceptacion es por lo tanto 0.99, con una region
de rechazo de un 0.01, se busca en la tabla de la distribucion normal
el valor de z asociado a una probabilidad de 0.01 y se obtiene que
Z
t
= 2.33 y se plantea la regla de decision:
|Z
c
| < |Z
t
| |0.80| < | 2.33| por lo tanto no se rechaza H
0
,
por lo que se concluye que no existe suciente evidencia para creer
que una proporcion mayor a un 55% de las familias desean pasar las
estas de n de a no en un hotel de playa.
Ejemplo 26 Una cadena de tiendas expide su propia tarjeta de credito.
El gerente de investigacion desea averiguar si los saldos de las tarjetas son
menores a 40.000 colones. En una revision aleatoria de 172 saldos de tarje-
tas revelo que la media muestras es de 40.700 colones, con una desviacion
estandar de 3.800 colones, con un nivel de signicancia del 5% debera con-
cluir el gerente que el saldo promedio mensual es inferior a 40.000 colones?
4. Prueba de hipotesis 35
Solucin 17 Paso 1:
La hipotesis nula H
0
es: = 40000.
La hipotesis alternativa H
1
es: < 40000.
Paso 2: Se utilizara un nivel de signicancia de 5%.
Paso 3: El estadstico de la prueba es Z
c
:
Z
c
=
x
n
=
40700 40000
3800
172
= 2.42.
Paso 4: Para calcular el valor crtico de la prueba, como es una prueba de
una cola, la zona de rechazo es de un 5% (cola izquierda), y el area
de aceptacion se encuentra entre un valor superior al 5%, y es por lo
tanto 0.95. Se busca en la tabla de distribucion normal el valor de z
asociado a una probabilidad de 0.05 y se obtiene que Z
t
= 1.64 y
se plantea la regla de decision:
|Z
c
| > |Z
t
| |2.42| > |1.64| entonces se rechaza H
0
y se acepta H
1
.
Podemos concluir que si existe suciente evidencia para creer que el
saldo promedio es inferior a 40.000 colones.
Ejercicio 17 En un experimento sobre percepcion extrasensorial (PES),
un individuo en una habitacion es invitado a adivinar el color (rojo o az ul)
de una carta elegida de 50 cartas bien mezcladas por otro individuo en
otra habitacion. El no sabe cuantas rojas y cuantas azules hay. Si el sujeto
identica 32 cartas correctamente, determinar si el resultado es signicativo
con nivel (a) 0.05 y (b) 0.01.
Ejercicio 18 Un laboratorio de farmacia sostiene que uno de sus produc-
tos es 90% efectivo para reducir una alergia en 8 horas. En una muestra
de 200 personas con esa alergia, el medicamento dio buen resultado en
160, Determinar si la armacion del laboratorio es legtima con nivel de
signicancia de 0.01.
2 Prueba de hipotesis para una poblacion con dos
muestras grandes (n > 30)
Anteriormente se desarrollo las pruebas de hipotesis concernientes a si una
media o una proporcion eran iguales a un valor especco; por lo general,
a estas pruebas se les conoce como pruebas de una muestra, puesto que se
selecciona una sola muestra de una poblacion de interes. Existen algunas
36 4. Prueba de hipotesis
situaciones en las cuales interesa determinar si existe alguna diferencia entre
las medias de dos poblaciones independientes, o si existe alguna diferen-
cia entre las proporciones de dos poblaciones independientes; por lo tanto,
se dispondran de dos poblaciones cada una de ellas con una media o pro-
porcion y su desviacion. Por ejemplo, se desea comparar si hay diferencia
entre los rendimientos de los estudiantes en la zona urbana y rural, o si
hay diferencia entre el desempe no de un trabajador en el turno diurno o
nocturno, o si hay diferencia entre las ventas al utilizar un empaque en un
producto u otro empaque, etc. En general la comparacion entre dos me-
dias o proporciones es muy frecuente. El procedimiento para realizar una
prueba de este tipo es similar a lo que se ha venido haciendo; la unica difer-
encia radica en que el estadstico de la prueba es diferente, por lo tanto se
plantearan tambien los 5 pasos para la prueba de una hipotesis.
Para en el caso de la comparacion de medias, cuando se tienen dos mues-
tras aleatorias independientes de tama nos n
1
y n
2
respectivamente, las
cuales se extraen de dos poblaciones con medias
1
y
2
y desviaciones
estandar
1
y
2
, se sabe que:
z =
(x
1
x
2
) (
1
2
)
2
1
n
1
+
2
2
n
2
, (4.1)
es el estadstico apropiado para probar la hipotesis entre dos medias, donde
x
1
y x
2
son las medias muestrales de las muestras aleatorias independientes
de tama nos n
1
y n
2
respectivamente. En la practica, cuando ambas mues-
tras provienen de la misma poblacion, usualmente se toma
1
=
2
por lo
que 4.1 se transforma en 4.2:
z =
x
1
x
2
2
1
n
1
+
2
2
n
2
. (4.2)
Para el caso de la comparacion de dos proporciones, cuando se tiene dos
muestras aleatorias independientes de tama no n
1
y n
2
, respectivamente,
las cuales se extraen de dos poblaciones con proporciones P
1
y P
2
, se sabe
que:
z =
(p
1
p
2
) (P
1
P
2
)
pq
_
1
n
1
+
1
n
2
_
, (4.3)
es el estadstico apropiado para probar la hipotesis entre dos proporciones,
donde p
1
y p
2
son las proporciones muestrales de las muestras aleatorias
independientes de tama nos n
2
y n
2
respectivamente y p se calcula como
4. Prueba de hipotesis 37
sigue:
p =
n
1
p
1
+n
2
p
2
n
1
+n
2
.
En la practica, cuando ambas muestras provienen de la misma poblacion,
usualmente se toma P
1
= P
2
por lo que 4.3 se transforma en 4.4:
z =
p
1
p
2
pq
_
1
n
1
+
1
n
2
_
. (4.4)
2.1 Ejemplos
Ejemplo 27 Para probar un nuevo producto que estimula el crecimiento
de las plantas de cafe, se selecciono aleatoriamente 400 plantas que reci-
bieron el tratamiento, obteniendose un crecimiento mensual promedio de
16cm con una desviacion de 1cm. De igual manera, se seleccionaron aleato-
riamente 100 plantas de cafe no tratado, en donde se midio su crecimiento
mensual, dando como resultado un crecinmiento promedio de 15.2cm y una
desviacion de 1.2cm. Con el nivel de signicancia del 5%, es posible creer
que el nuevo producto acelera el crecimiento?
Solucin 18 Para la muestra n umero 1 tenemos:
n
1
= 400, x
1
= 16, y
1
= 1.
Mientras que para la muestra n umero 2 tenemos:
n
2
= 100, x
2
= 15, y
2
= 1.2.
Paso 1:
La hipotesis nula H
0
es:
1
=
2
.
La hipotesis alternativa H
1
es:
1
>
2
.
De esta forma se esta planteando en la hipotesis alternativa que el
promedio de crecimiento de las plantas tratadas con el producto tu-
vieron un mayor crecimiento, que es lo que se quiere probar.
Paso 2: Se utilizara un nivel de signicancia de 5%.
Paso 3: El estadstico de la prueba es Z
c
, debido a que se conoce la
desviacion de la poblacion, es:
Z
c
=
x
1
x
2
2
1
n
1
+
2
2
n
2
=
16 15
_
1
2
400
+
1.2
2
100
= 6.15.
38 4. Prueba de hipotesis
Paso 4: Para calcular el valor crtico de la prueba; como es una prueba de
una cola, el area de aceptacion es 0.95 y el area de rechazo es 0.05.
Se busca en la tabla de la distribucion normal el valor de z asociado
a una probabilidad de 0.05 y se obtiene que, Z
t
= 1.64 y se plantea
la regla de decision:
|Z
c
| > |Z
t
| |6.15| > |1.64| entonces se rechaza H
0
, y se acepta H
1
,
por lo que se concluye que existe suciente evidencia para creer que
el nuevo producto si acelerara el crecimiento de las plantas.
Ejemplo 28 Se va a registrar el voto de los residentes de un canton y los
residentes de una provincia para determinar si se debe construir un relleno
sanitario. El lugar de la construccion esta dentro de los lmites del canton, y
por esta razon, muchos votantes de la provincia sienten que la propuesta se
rechazara. Para determinar si hay diferencia entre la proporcion de personas
a favor del relleno en el canton y las de la provincia, se toma una muestra de
ello, y se obtienen los siguientes resultados: 120 de los 200 consultados en el
canton y 240 de los 500 consultados en la provincia no estan de acuerdo con
la propuesta de la construccion del relleno. Utilice un nivel de signicancia
del 5%.
Solucin 19 Para la muestra n umero 1 tenemos:
n
1
= 200, p
1
=
120 100
200
= 0.60.
Mientras que para la muestra n umero 2 tenemos:
n
2
= 500, p
2
=
240 100
500
= 0.48.
Ademas:
p =
n
1
p
1
+n
2
p
2
n
1
+n
2
=
200 0.6 + 500 0.48
200 + 500
=
120 + 240
700
= 0.51.
Paso 1:
La hipotesis nula H
0
es: P
1
= P
2
.
La hipotesis alternativa H
1
es: P
1
> P
2
.
Paso 2: Se utilizara un nivel de signicancia de 5%.
Paso 3: El estadstico de la prueba es Z
c
es:
Z
c
=
p
1
p
2
pq
_
1
n
1
+
1
n
2
_
=
0.6 0.48
0.51 0.49
_
1
200
+
1
500
_
= 2.9.
4. Prueba de hipotesis 39
Paso 4: Para calcular el valor crtico de la prueba; como es una prueba de
una cola, el area de aceptacion es 0.95 y el area de rechazo es 0.05.
Se busca en la tabla de la distribucion normal el valor de z asociado
a una probabilidad de 0.05 y se obtiene que, Z
t
= 1.64 y se plantea
la regla de decision:
|Z
c
| > |Z
t
| |2.9| > |1.64| por lo tanto se rechaza H
0
, y se acepta H
1
,
por lo que se concluye que existe suciente evidencia para creer que
la proporcion de personas del canton que esta en desacuerdo con el
relleno es mayor a la proporcion de personas en la provincia que estan
en desacuerdo.
Ejercicio 19 En un mismo examen realizado en dos grupos de 40 y 50 es-
tudiantes respectivamente, la nota media del primero fue 74 con desviacion
tpica 8, y en el otro fue 78 con desviacion tpica 7. Hay diferencia signi-
cativa entre las calicaciones de ambos grupos con nivel de signicancia
de (a) 0.05 y (b) 0.01?
Ejercicio 20 Dos grupos A y B consisten en 100 personas cada uno, aque-
jadas todas de cierta enfermedad. Se suministra un suero al grupo A pero
no al grupo B; por lo demas ambos grupos reciben el mismo tratamiento. Se
encuentra que 75 individuos del grupo A y 65 del grupo B se recuperan de
la enfermedad. Contrastar la hipotesis de que el suero cura la enfermedad
al nivel de signicacion (a) 0.01, y (b) 0.05.
40 4. Prueba de hipotesis
This is page 41
Printer: Opaque this
Teora de muestras peque nas
En los captulos anteriores hemos hecho uso de muestras de tama no n > 30,
llamadas muestras grandes, las distribuciones de muestreo de muchos es-
tadsticos son aproximadamente normales, siendo la aproximacion tanto
mejor cuanto mayor sea n. Para muestras de tama no menor que 30, lla-
madas muestras peque nas, esa aproximacion no es buena y empeora al
decrecer n, de modo que son precisas ciertas modicaciones.
El estudio de la distribucion de muestreo de estadsticos para muestras
peque nas se llama teora de peque nas muestras. Sin embargo, un nombre
mas apropiado sera teora exacta del muestreo, pues sus resultados son
validos tanto para peque nas muestras como para grandes. En ese captulo
analizamos la distribucion t de Student.
1 La distribucion t de Student
La distribucion t de Student
1
es una distribucion simetrica con respecto
a su media, semejante a la normal pero un poco mas extendida, lo que
hace que el area bajo la curva, con respecto a la normal, sea mayor en
las colas y menor en la parte central. Su forma depende del tama no de
la muestra, o mas concretamente, de un parametro denominado grados
de libertad asociados a la desviacion estandar , que es igual a n 1,
donde n es el tam no de la muestra. Por ello no hay una sola distribucion t,
sino una para cada n umero de grados de libertad (tama no de la muestra).
Cuanto mas sean los grados de libertad, mas se acerca la distribucion t a la
distribucion normal estandar, y cuando la muestra es muy grande, ambas
son practicamente iguales.
Denicin 19 La distribucion t de Student se dene como:
t =
x
s
n
=
x
n 1
,
donde:
1
La distribucion de probabilidad de t se publico por primera vez en 1908 en un trabajo
de William S. Gosset estadstico ingles, discpulo de Fisher. En esta epoca Gosset era
empleado de una cervecera irlandesa que desaprobaba la publicacion de trabajos de
investigaci on de sus trabajadores. Para evadir esa restriccion Gosset publico su trabajo
en secreto bajo el seudonimo de Student. En consecuencia, a la distribucion de t
usualmente se le llama distribucion t de Student.
42 5. Teora de muestras peque nas
FIGURE 1. Comparacion entre la normal estandar y la t de Student.
t es la abscisa de la distribucion de Student.
x es la media de la muestra.
es la media de la poblacion.
s es la desviacion estandar corregida: s =
n
i=1
x
i
n 1
.
es la desviacion estandar de la muestra sin corregir: =
n
i=1
x
i
n
.
Gracamente se ilustra en la gura 1
2 Estimacion por intervalo para muestras
peque nas (n < 30)
2.1 Intervalo de conanza para la media
Teorema 10 Si se tiene una muestra peque na de una poblacion tama no
n < 30, entonces el intervalo de conanza para la media de una poblacion
esta dado por:
x t
(1/2,(n1)gl)
n
< < x +t
(1/2,(n1)gl)
n
,
donde:
t
(1/2,(n1)gl)
es el valor de la distribucion de Student con n 1
grados de libertad.
x es la media de la muestra.
es la media de la poblacion.
es la desviacion estandar.
5. Teora de muestras peque nas 43
Ejemplo 29 Suponga que un gerente de mercadeo de una gran tienda
de departamentos, le gustara tomar una muestra de mujeres con tarjetas
de credito para obtener informacion de la cantidad promedio que gastan
cada mes las mujeres en compras de ropa. Para ello selecciono una mues-
tra de 25 mujeres con tarjetas de credito y se pidio a las entrevistadas
que determinaran el monto de sus compras el mes anterior. Los resultados
mostraron un promedio muestras de 8640 colones y una desviacion estandar
de la muestra de 3750 colones. Encuentre una estimacion por intervalo del
monto promedio poblacional del gasto en ropa con una conanza del 95%.
Solucin 20 Para calcular t
(1/2,(n1)gl)
, se tiene que
1 = 0.95 de donde obtiene que = 0.05.
Entonces
2
= 0.025.
Luego
_
1
2
_
= 0.975.
Consultando la tabla acumulada de la t de Student con (n 1) =
(25 1) = 24 grados de libertad obtenemos que el valor de t para
el cual se encuentra acumulado un 97.5% del area bajo la curva es
t = 2.064
entonces:
x t
(1/2,(n1)gl)
n
< < x +t
(1/2,(n1)gl)
n
8640 2.064
3750
25
< < 8640 + 2.064
3750
25
7092 < < 10188,
Se llegara a la conclusion, con una conanza del 95%, de que la cantidad
promedio gastada cada mes en ropa por las mujeres se encuentra entre 7092
y 10188 colones.
Ejercicio 21 Una muestra con 10 medidas de una esfera dan media x =
4.38 cm y una desviacion estandar = 0.06 cm. Encuentre una estimacion
por intervalo con una conanza del 95%.
3 Prueba de hipotesis para muestras peque nas
(n < 30)
El procedimiento teorico y practico para realizar pruebas de hipotesis cuando
se desconoce la desviacion de la poblacion y se tiene un tama no de muestra
44 5. Teora de muestras peque nas
peque no es similar al expuesto con anterioridad; la diferencia radica en el
estadstico de la prueba, que en estos casos correspondera a un valor t de
Student.
3.1 Prueba de hipotesis para una poblacion con muestra
peque na
Ejemplo 30 La longitud promedio de cierta pieza para una refrigeradora
es de 43 cm. Se cree que los ajustes a la maquina que los produce ha
provocado que la longitud cambie. Para ello se selecciono aleatoriamente
12 piezas y se registro su longitud, dando como resultado que la longitud
promedio de las piezas en la muestra es de 41.5 cm, con una desviacion
estandar muestras de 1.78 cm. Con un nivel de signicancia del 2% existe
evidencia para creer que la maquina ha provocado que la longitud de las
piezas cambie?
Solucin 21 Paso 1:
La hipotesis nula H
0
es: = 43.
La hipotesis alternativa H
1
es: = 43.
Paso 2: Se utilizara un nivel de signicancia de 2%.
Paso 3: El estadstico de la prueba es t
c
:
t
c
=
x
n
=
41.5 43
1.78
12
= 2.92.
Paso 4: Para obtener el valor crtico de la prueba, como es una prueba de
dos colas, la mitad de 0.02, o sea 0.01 esta en cada zona de rechazo, y
el area de aceptacion se encuentra entre las dos colas, y es por lo tanto
0.99. Se busca en la tabla de distribucion t de Student con n1 = 11
grados de libertad, y se obtiene que t = 2.718 y se plantea la regla de
decision:
|t
c
| > |t| |2.92| > |2.718| entonces se rechaza H
0
y se acepta H
1
.
Podemos concluir que si existe suciente evidencia para creer que que
los ajustes en la maquina han cambiado la longitud de las piezas.
Ejercicio 22 Se instala una maquina que seg un las especicaciones puede
llenar envases de medicamentos de 9 gramos automaticamente. Sin em-
bargo, se cree que la maquina esta fallando y que el peso que esta envasando
es menor al especicado. Para probar la hipotesis, se selecciono una mues-
tra de 8 envases llenados por la maquina, los pesos que se obtuvieron fueron
los siguientes: 9.2, 8.7, 8.9, 8.6, 8.8, 8.5, 8.7, 9.0. Con un nivel de conanza
del 99% considera usted que hay evidencia para creer que la maquina esta
fallando?
5. Teora de muestras peque nas 45
3.2 Prueba de hipotesis para una poblacion con dos muestras
peque nas
Para el caso de la comparacion de medias, cuando se tienen dos muestras
aleatorias independientes de tama nos n
1
y n
2
respectivamente menores a
30, las cuales se extraen de dos poblaciones con medias
1
y
2
y con
desviaciones estandar
1
y
2
respectivamente, entonces el estadstico de
la prueba es una t de Student con n
1
+n
2
2 grados de libertad:
t =
(x
1
x
2
) (
1
2
)
2
_
1
n
1
+
1
n
2
_
, (5.1)
donde
2
se calcula como sigue:
2
=
(n
1
1)
2
1
+ (n
2
1)
2
2
n
1
+n
2
2
.
En la practica, cuando ambas muestras provienen de la misma poblacion,
usualmente se toma
1
=
2
, por lo que 5.1 se transforma en 5.2:
t =
(x
1
x
2
)
2
_
1
n
1
+
1
n
2
_
. (5.2)
Ejemplo 31 Suponga que una corporacion posee dos tiendas de super-
mercados, una ubicada en la zona urbana del pas y otra en la zona rural
del pas; el gerente de la corporacion desea averiguar si hay diferencia entre
las ventas registradas en cada una de las tiendas; para demostrar ello, se-
lecciono 25 das al azar y registro las ventas promedio que se dieron en ese
perodo en la zona urbana, el cual fue 366.35 con una deviacion estandar
de 16.71. Ademas selecciono 20 das para registrar las ventas en la zona
rural, el promedio en este caso fue de 369.74 con una deviacion estandar
de 14.2. Con un nivel de signicancia del 1%, existe evidencia para creer
que hay diferencia entre las ventas de cada una de las tiendas.
Solucin 22 Para la muestra n umero 1 tenemos:
n
1
= 25, x
1
= 366.35, y
1
= 16.71.
Mientras que para la muestra n umero 2 tenemos:
n
2
= 20, x
2
= 369.74, y
2
= 14.2.
Paso 1:
La hipotesis nula H
0
es:
1
=
2
.
La hipotesis alternativa H
1
es:
1
=
2
.
46 5. Teora de muestras peque nas
Paso 2: Se utilizara un nivel de signicancia de 1%.
Paso 3: El estadstico de la prueba es t
c
es:
t
c
=
(x
1
x
2
)
2
_
1
n
1
+
1
n
2
_
=
(366.35 369.74)
244.943
_
1
25
+
1
20
_
= 0.72.
pues:
2
=
(n
1
1)
2
1
+ (n
2
1)
2
2
n
1
+n
2
2
=
(25 1)(16.71)
2
+ (20 1)(14.2)
2
25 + 20 2
= 244.943.
Paso 4: Para calcular el valor crtico de la prueba; como es una prueba
de dos colas, la zona de rechazo es de 0.01 y el area de aceptacion
es de 0.99, luego 0.01 divido entre 2 es 0.005. Se busca en la tabla
de la distribucion t de Student el valor asociado a una probabilidad
de 0.005 con n
1
+ n
2
2 = 43 grados de libertad y se obtiene que,
t = 2.69 y se plantea la regla de decision:
|t
c
| < |t| | 0.72| < |2.69| entonces no se rechaza H
0
,
por lo que se concluye que no existe suciente evidencia para creer
que hay diferencia entre las ventas de las tiendas de zona rural y zona
urbana.
Ejercicio 23 Los cocientes de inteligeiicia (IQ) de 16 estudiantes de un
barrio dieron una media de 107 con desviacion estandar de 10, y con 14
estudiantes de otro barrio dieron media 112 con desviacion estandar 8. Hay
diferencia signicativa entre los IQ de los dos grupos al nivel de signicancia
0.01?
4 Conexion entre los intervalos de conanza y las
pruebas de hipotesis
Anteriormente se han examinado las dos aplicaciones principales de la infer-
encia estadtica los intervalos de conanza y las pruebas de hipotesis. Am-
bas se basan en los mismos conceptos pero se han utilizado para propositos
diferentes. Los intervalos de conanza se utilizaron para estimar los parametros,
mientras que las pruebas de hipotesis se utilizaron para tomar decisiones
sobre los valores especcos de parametros de la poblacion. En muchas oca-
siones se pueden utilizar los intervalos de conanza para realizar la prueba
de una hipotesis nula, esto es tratando de realizar un intervalo de conanza
5. Teora de muestras peque nas 47
FIGURE 2. Curva normal con dos colas.
en donde nos interesa saber con un nivel de conanza establecido, la prob-
abilidad de que el estimador este dentro del area de aceptacion. Para ello,
existen tres casos:
Caso 1: Si la prueba es de dos colas (ver gura 2), es decir si la hipotesis
nula y alternativa son de la forma:
La hipotesis nula H
0
es: = .
La hipotesis alternativa H
1
es: = ,
en cuyo caso el intervalo se conanza es:
z
/2
n
< x < +z
/2
n
,
luego la regla de decision sera la siguiente:
Se rechaza H
0
si x < z
/2
n
o si +z
/2
n
< x.
Caso 2: Si la prueba es de una cola a la derecha (ver gura 3), es decir si
la hipotesis nula y alternativa son de la forma:
La hipotesis nula H
0
es: = .
La hipotesis alternativa H
1
es: > ,
en cuyo caso el intervalo se conanza es:
z
n
< x < +z
n
,
luego la regla de decision sera la siguiente:
Se rechaza H
0
si +z
n
< x.
48 5. Teora de muestras peque nas
FIGURE 3. Curva normal de una cola a la derecha.
FIGURE 4. Curva normal de una cola a la izquierda.
Caso 3: Si la prueba es de una cola a la izquierda (ver gura 4), es decir
si la hipotesis nula y alternativa son de la forma:
La hipotesis nula H
0
es: = .
La hipotesis alternativa H
1
es: < ,
en cuyo caso el intervalo se conanza es:
z
n
< x < +z
n
,
luego la regla de decision sera la siguiente:
Se rechaza H
0
si x < z
n
.
Ejemplo 32 Un encargado de mercadeo ha recibido m ultiples quejas de
los clientes del cereal que la empresa vende, pues consideran que el con-
tenido que trae el cereal no es el estipulado en la etiqueta (368 gr. con una
desviacion de 10 gr). Para vericar esa armacion, el encargado selecciona
una muestra de 35 cajas de cereal para determinar si el contenido de las
mismas esta de acuerdo con lo especicado en la etiqueta. El peso promedio
de contenidos del cereal en la muestra fue de 363 gr. Existe evidencia de
que los contenidos de los cereales es inferior, utilice un nivel de signicancia
del 5%.
5. Teora de muestras peque nas 49
Solucin 23 En este ejemplo se tiene una cola a la izquierda, pues la
hipotesis nula y alternativa son:
La hipotesis nula H
0
es: = 368.
La hipotesis alternativa H
1
es: < 368.
El intervalo de conanza es:
z
n
< x < +z
n
368 1.64
10
35
< x < 368 + 1.64
10
35
365.2 < x < 370.8.
Como x < z
n
363 < 365.2 entonces se rechaza la hipotesis nula.
Ejercicio 24 Un ndice que mide la asimilacion al medio urbano, ha sido
aplicado a un n umero grande de adultos que llegaron a una area metropoli-
tana procedentes de las zonas costeras. Los resultados indican = 70 y
= 10. Se toma una muestra al azar de 49 inmigrantes provenientes de las
zonas altas del interior y se obtiene x = 67. Se puede concluir que el grado
de asimilacion del inmigrante proveniente de las zonas altas es diferente del
proveniente de las zonas costeras, o puede pensarse que es igual y que la
diferencia obtenida se debe al azar? Utilice un nivel de signicancia de 0.05.
50 5. Teora de muestras peque nas
This is page 51
Printer: Opaque this
Analisis de la Varianza
En el captulo anterior, la prueba t de Student se empleo para determinar
si las medias de dos grupos dieren signicativamente. Que pasa si tres o
mas grupos son comparados? La tecnica estadstica conocida como analisis
de varianza o ANOVA
1
se usa para determinar si las diferencias entre varias
medias del muestreo son mas grandes de lo que se esperara si solo se tomara
en cuenta el azar en caso de que la hipotesis nula fuese cierta.
Podramos pensar en comparar las medias por pares, y repetir la prueba
t de Student para cada par de medias. Si detectaramos una diferencia entre
cualquier pareja de valores, entonces concluiramos que existe evidencia de
por lo menos una diferencia entre las medias y parecera que se hubiera
contestado as la pregunta. El problema con este procedimiento es que si
por ejemplo hay 5 grupos de datos entonces se requieren
_
5
2
_
= 10 pruebas
de hipotesis tipo t de Student. Aunque fueran iguales todas las medias,
se tendra una probabilidad de rechazar la hipotesis nula de que los
valores de un par en particular son iguales. Al repetir este procedimiento
diez veces, la probabilidad de concluir erroneamente que por lo menos un
par de valores medios diera, es muy alta. Debido a que el riesgo de una
decision equivocada puede ser elevado, buscamos una prueba unica de la
hipotesis nula de que son iguales las cinco medias de los grupos.
La tecnica estadstica conocida como analisis de varianza (ANOVA), fue
desarrollada por el estadstico ingles Sir Ronald Fisher en la decada de los
a nos veinte, permite el control de a un nivel predeterminado cuando se
prueba la igualdad de k medias del grupo, donde k > 2. En ANOVA, las
medias se examinan simultaneamente para evaluar la posibilidad de que
todas las k medias de muestreo provengan de la misma poblacion (es decir,
poblaciones con identicos parametros). En otras palabras, los procedimien-
tos ANOVA se pueden usar para determinar si es o no razonable concluir que
no todas las k medias del muestreo provienen de la misma poblacion.
ANOVA es una tecnica estadstica eciente y poderosa; si la hipotesis nula
total esta fundamentada (es decir, si no se encuentra evidencia contundente
para rechazarla), normalmente uno no contin ua con las siguientes compara-
ciones estadsticas entre medias.El analisis de la varianza es un metodo de
inferencia estadstica que permite analizar datos empricos para determi-
nar si hay diferencias signicativas entre el conjunto de k medias (diferen-
cias mayores que las que puedan ser explicadas por errores de muestreo).
Cuando k = 2 grupos, ANOVA y la prueba t independiente son proced-
imientos estadsticos equivalentes; los valores en las tablas seran siempre
1
ANOVA se forma con las letras de la frase ingles ANalysis Of VAriance.
52 6. Analisis de la Varianza
identicos, es decir, son matematicamente equivalentes. Cuando k > 2,
ANOVA tiene ventajas claras sobre las pruebas t m ultiples: a) proporciona
una proteccion contra errores de tipo I, b) es poderoso y eciente, y se
presta para analisis mas avanzados como un ANOVA factorial y el analisis de
la covarianza.
1 Metodo ANOVA para la comparacion de medias
provenientes de muestras del mismo tama no
Para la aplicacion del metodo ANOVA se tienen dos suposiciones:
1. Las muestras se han seleccionado aleatoriamente e independiente-
mente de sus poblaciones respectivas.
2. Las poblaciones se distribuyen normalmente con medias
1
,
2
, . . . ,
k
y varianzas iguales
2
1
,
2
2
, . . . ,
2
k
.
Seguidamente se presenta un esquema para aplicar la tecnica ANOVA para
el caso en que se tienen k muestras (todas del mismo tama no) cuyas medias
muestrales son x
1
, x
2
, . . . , x
k
respectivamente y cuyas varianzas muestrales
son s
2
1
, s
2
2
, . . . , s
2
k
respectivamente.
Paso 1: Enuncie la hipotesis nula y alternativa estadstica que sera probada.
H
0
:
1
=
2
= =
k
(hipotesis nula).
H
1
: uno o mas pares de medias poblacionales dieren.
Paso 2: Se tienen los siguientes subpasos:
Paso 2.1: Seleccionar un nivel de signicancia (seleccionar la region
de rechazo), es decir, especique el nivel de riesgo que esta dis-
puesto a tomar para concluir que H
0
es falsa cuando en realidad
es verdadera. Por ejemplo = 0.05.
Paso 2.2: Calcule los grados de libertad de las las v
F
= k 1.
Paso 2.3: Calcule los grados de libertad de las columnas
v
C
=
k
j=1
n
i
k = nk k = k(n 1),
pues todos los tama nos de muestra n
i
son iguales a n.
Paso 2.4: Usando los valores de , v
F
y v
C
encuentre el valor F
en
la tabla del apendice F.
6. Analisis de la Varianza 53
Paso 3: Calcular el estadstico F de la prueba, para esto se requieren tres
subpasos:
Paso 3.1: Calcular la media de las medias x, mediante la formula:
x =
k
j=1
x
j
k
.
Calcular s
2
x
la varianza entre las k medias, es decir:
s
2
x
=
k
j=1
_
x
j
x
_
2
k 1
.
Calcular la Media Cuadrada Entre denotada como MC
E
con la
formula:
MC
E
= n s
2
x
,
donde n es el tama no de las muestras (todas son del mismo
tama no).
Paso 3.2: Calcule el promedio de las varianzas, conocido como Media
Cuadrada Dentro con la formula:
MC
D
=
k
j=1
s
2
j
k
=
s
2
1
+s
2
2
+ +s
2
k
k
.
Paso 3.3: Calcule la razon F, entre estas dos estimaciones de vari-
anzas:
F =
MC
E
MC
D
.
Paso 4: Encuentre la region de rechazo (se ilustra en la gura 1), luego
rechace H
0
si F > F
, en caso contrario, es decir si F F
concluya
que H
0
esta fundamentada.
Ejemplo 33 Aplique el metodo ANOVA con k = 3 grupos de datos hipoteticos
sobre programas de estudio de igual tama no n
1
= n
2
= n
3
= n = 6 con
nivel de signicancia = 0.05. Estos datos se presentan en la siguiente
tabla:
Observaciones n x s
2
Programa general 65, 54, 54, 59, 47, 65 6 57.33 49.87
Programa academico 62, 52, 59, 62, 65, 62 6 60.33 20.27
Programa vocacional 57, 54, 49, 39, 46, 43 6 48.00 45.60
54 6. Analisis de la Varianza
FIGURE 1. La region de rechazo de H0 aparece sombreada.
Solucin 24 Paso 1:
H
0
:
1
=
2
=
3
.
H
1
: uno o mas pares de medias poblacionales dieren.
Paso 2: Se tienen los siguientes subpasos:
Paso 2.1: = 0.05.
Paso 2.2: Grados de libertad de las las v
F
= 3 1 = 2.
Paso 2.3: Grados de libertad de las columnas v
C
= k(n 1) =
3(6 1) = 15.
Paso 2.4: F
= 3.682 (F de la tabla).
Paso 3: Calcular el estadstico F de la prueba:
Paso 3.1: Calcule la Media Cuadrada Entre:
x =
k
j=1
x
j
k
=
57.33 + 60.33 + 48
3
= 55.22.
s
2
x
=
k
j=1
_
x
j
x
_
2
k 1
=
(57.33 55.22)
2
+ (60.33 55.22)
2
+ (48 55.22)
2
2
= 41.35
MC
E
= 6 41.35 = 248.1.
6. Analisis de la Varianza 55
Paso 3.2: Calcule el promedio de las varianzas, conocido como Me-
dia Cuadrada Dentro con la formula:
MC
D
=
k
j=1
s
2
j
k
=
49.87 + 20.27 + 45.60
3
= 38.58.
Paso 3.3: Calcule la razon F, entre estas dos estimaciones de vari-
anzas:
F =
MC
E
MC
D
=
248.1
38.58
= 6.43
Paso 4: Como F > F
6.43 > 3.682 se rechaza H
0
y se concluye que
las medias de los tres programas de estudio no son todas iguales.
Ejercicio 25 Aplique el metodo ANOVA con k = 3 grupos de datos sobre
tratamientos medicos de igual tama no n
1
= n
2
= n
3
= n = 4 con nivel de
signicancia = 0.05. Estos datos se presentan en la siguiente tabla:
Observaciones n x s
2
Tratamiento intensivo 107, 100, 101, 92
Tratamiento original 91, 95, 90, 88
Grupo de control 87, 86, 82, 85
Ejercicio 26 Se realizo un experimento de percepcion extrasensorial (PES)
en el cual veinte personas fueron asignadas al azar al grupo experimen-
tal o al grupo control. Ambos grupos vieron las mismas cuatro formas
geometricas. En el grupo experimental, el investigador fungio como trans-
misor, concentrandose en una de las formas; las otras personas de este
grupo trataron de recibir la se nal que les fue transmitida. En el grupo con-
trol, las personas fueron instruidas para adivinar al azar antes que cualquier
se nal fuera mentalmente transmitida. La hipotesis nula establece que am-
bas medias de poblacion son iguales (el tratamiento PES no tendra efecto).
Las puntuaciones y calculos preliminares para los diez sujetos experimen-
tales y los diez sujetos de control se dan en la siguiente tabla. Es la difer-
encia en medias observadas suciencientemente grande para permitir que
la hipotesis nula sea rechazada? Use = 0.10 y escriba una conclusion.
Observaciones n x s
2
Grupo experimental 2, 3, 3, 3, 4, 5, 6, 6, 8, 10
Grupo de control 3, 3, 4, 4, 4, 4, 5, 5, 6, 7
56 6. Analisis de la Varianza
2 Metodo ANOVA para la comparacion de medias
provenientes de muestras de distinto tama no
Basicamente se utilizan los mismos pasos que para el caso anterior, sola-
mente cambia la forma en que se calculan v
C
y F.
Paso 1: Enuncie la hipotesis nula y alternativa estadstica que sera probada.
H
0
:
1
=
2
= =
k
(hipotesis nula).
H
1
: uno o mas pares de medias poblacionales dieren.
Paso 2: Se tienen los siguientes subpasos:
Paso 2.1: Seleccionar un nivel de signicancia (seleccionar la region
de rechazo), es decir, especique el nivel de riesgo que esta dis-
puesto a tomar para concluir que H
0
es falsa cuando en realidad
es verdadera. Por ejemplo = 0.05.
Paso 2.2: Calcule los grados de libertad de las las v
F
= k 1.
Paso 2.3: Calcule los grados de libertad de las columnas
v
C
=
k
j=1
n
i
k.
Paso 2.4: Usando los valores de , v
F
y v
C
encuentre el valor F
en
la tabla del apendice F.
Paso 3: Calcular el estadstico F de la prueba, para esto se requieren tres
subpasos:
Paso 3.1: Calcular Media Cuadrada Entre MC
E
median te la
formula:
MC
E
=
k
j=1
n
j
_
x
j
x
_
2
k 1
.
Paso 3.2: Calcule el promedio de las varianzas, conocido como Media
Cuadrada Dentro con la formula:
MC
D
=
k
j=1
nj
i=1
x
2
ij
k
j=1
n
j
x
2
j
v
C
Paso 3.3: Calcule la razon F, entre estas dos estimaciones de vari-
anzas:
F =
MC
E
MC
D
.
6. Analisis de la Varianza 57
Paso 4: Encuentre la region de rechazo (se ilustra en la gura 1), luego
rechace H
0
si F > F
, en caso contrario, es decir si F F
concluya
que H
0
esta fundamentada.
Ejemplo 34 Se sometio a cuatro grupos de estudiantes a diferentes tecnicas
de ense nanza y se les examino al nal de un semestre especco. Debido a
las deserciones de los grupos experimentales (por enfermedad, transferen-
cia, etc.) el n umero de estudiantes vario de grupo a grupo. Presentan los
datos mostrados en la siguiente tabla evidencia suciente para indicar una
diferencia en el rendimiento medio para las cuatro tecnicas de ense nanza?
Use = 0.05.
Observaciones n
j
x
j
s
2
j
Grupo 1 65,87,73,79,81,69 6 75.67 66.67
Grupo 2 75,69,83,81,72,79,90 7 78.43 50.62
Grupo 3 59,78,67,62,83,76 6 70.83 91.77
Grupo 4 94,89,80,88 4 87.85 33.58
Solucin 25 Paso 1: Las hipotesis nula y alternativa son:
H
0
:
1
=
2
=
3
=
4
(hipotesis nula).
H
1
: uno o mas pares de medias poblacionales dieren.
Paso 2: Se tienen los siguientes subpasos:
Paso 2.1: = 0.05.
Paso 2.2: v
F
= k 1 = 4 1 = 3.
Paso 2.3: v
C
=
k
j=1
n
i
k = (6 + 7 + 6 + 4) 4 = 19.
Paso 2.4: F
= 3.127.
Paso 3: Calcular el estadstico F de la prueba, para esto se requieren tres
subpasos:
Paso 3.1: Calcular Media Cuadrada Entre MC
E
:
MC
E
=
k
j=1
nj(xjx)
2
k1
=
6(75.6778.17)
2
+7(78.4378.17)
2
+6(70.8378.17)
2
+4(87.7578.17)
2
41
=
712.6
3
= 237.5
58 6. Analisis de la Varianza
Paso 3.2: Calcule el promedio de las varianzas, Media Cuadrada
Dentro:
MC
D
=
k
j=1
n
j
i=1
x
2
ij
j=1
njx
2
j
v
C
=
139511(6(75.67)
2
+7(78.43)
2
+6(70.83)
2
+4(87.75)
2
19
=
139511138314
19
=
1196.65
19
=
62.95
Paso 3.3: Calcule la razon F:
F =
MC
E
MC
D
=
237.5
62.95
= 3.77.
Paso 4: F > F
3.77 > 3.127 se rechaza H
0
y se concluye que hay evi-
dencia suciente para indicar una diferencia en el rendimiento medio
entre los cuatro procedimientos de ense nanza.
Ejercicio 27 Un psicologo clnico quera comparar los metodos para re-
ducir los niveles de hostilidad en estudiantes universitarios. Cierta prueba
psicologica (PNH) fue utilizada para medir el grado de hostilidad. Las pun-
tuaciones altas en esta prueba indicaron una alta hostilidad. Se utilizaron
en el experimento 11 estudiantes que obtuvieron puntuaciones altas y casi
iguales entre s. Se seleccionaron al azar cinco de los 11 casos con problemas
y se trataron seg un el metodo A. De los 6 estudiantes restantes se tomaron
al azar tres y se trataron seg un el metodo B. Los otros tres estudiantes se
trataron seg un el metodo C. Todos los tratamientos se realizaron durante
todo un semestre. Se aplico nuevamente a cada estudiante la prueba PNH
al nal del semestre, con los resultados mostrados en la tabla siguiente:
Proporcionan los datos evidencia suciente para indicar que al menos uno
de los metodos produce una respuesta media de los estudiantes diferente
de los otros metodos? Que se puede concluir a un nivel de signicacion de
= 0.05?
Metodo A Metodo B Metodo C
73 54 79
83 74 95
76 71 87
68
80
This is page 59
Printer: Opaque this
Regresion y correlacion
1 Metodo de mnimos cuadrados
El problema de los mnimos cuadrados se ilustra en la gura 1 y consiste
en encontrar la recta de mejor ajuste para un conjunto de puntos en el
plano (x
1
, y
1
), (x
2
, y
2
), . . . , (x
n
, y
n
). Luego la ecuacion de esta recta podra
ser utilizada para predecir el valor de y dado un valor de x.
FIGURE 1. Recta de mejor ajuste.
El procedimiento estadstico para encontrar la recta de mejor ajuste
para un conjunto de puntos parece ser, en muchos aspectos, una formal-
izacion del procedimiento que se emplea para ajustar visualmente una recta.
Por ejemplo, cuando ajustamos visualmente una recta a un conjunto de
datos, se desplaza la regla hasta que se considera que hemos minimizado
las desviaciones de los puntos respecto de la lnea. Si denotamos el valor
pronosticado (o de prediccion) de y por y el cual se obtuvo a partir de la
lnea de ajuste, la ecuacion de prediccion es:
y =
0
+
1
x.
As la desviacion en el iesimo punto (x
i
, y
i
) es:
y
i
y
i
donde y
i
=
0
+
1
x
i
,
60 7. Regresion y correlacion
es decir, es la diferencia entre el valor verdadero y con respecto a su
prediccion y. Esto se ilustra en la gura 2.
FIGURE 2. Ecuacion lineal de prediccion.
Como ya mencionamos, la idea es escoger la recta mejor ajuste, es
decir aquella que minimice las desviaciones de los puntos con respecto a la
recta. Para esto, utilizaremos un criterio de bondad que se conoce como
principio de mnimos cuadrados y que puede establecerse como sigue:
escoger como la recta de mejor ajuste a la que minimice la suma de los
cuadrados de las desviaciones de los valores observados de y respecto de los
pronosticados y. Expresado matematicamente, se desea escoger los valores
0
y
1
que minimicen:
SCE =
n
i=1
(y
i
y
i
)
2
.
Se sabe que la solucion a este problema de optimizacion es:
1
=
SC
xy
SC
x
y
0
= y
1
x,
donde:
SC
x
=
n
i=1
x
2
i
_
n
i=1
x
i
_
2
n
,
SC
xy
=
n
i=1
x
i
y
i
_
n
i=1
x
i
__
n
i=1
y
i
_
n
.
7. Regresion y correlacion 61
Donde, x y y son las medias de los valores x
i
y y
i
respectivamente, para
i, j = 1, 2, . . . , n. Una vez calculados
0
y
1
sustituya los valores en la
ecuacion de la recta para obtener as la Recta de Predicci on por
Mmimos Cuadrados:
y =
0
+
1
x.
Observacin 15 Hay que considerar un punto importante aqu, los errores
de redondeo pueden afectar mucho el resultado por esto se recomienda
utilizar por lo menos seis cifras signicativas.
Ejemplo 35 Aplique el metodo de mnimos cuadrados para ajustar una
recta a traves de los n = 5 datos de la siguiente tabla. Cual sera es valor
estimado de y si x = 0.5?
x y
2 0
1 0
0 1
1 1
2 3
Solucin 26 Para facilitar los calculos completamos la tabla anterior como
sigue:
x
i
y
i
x
i
y
i
x
2
i
2 0 0 4
1 0 0 1
0 1 0 0
1 1 1 1
2 3 6 4
x = 0
5
i=1
x
i
= 0
y = 1
5
i=1
y
i
= 5
5
i=1
x
i
y
i
= 7
5
i=1
x
2
i
= 10
luego:
SC
x
=
5
i=1
x
2
i
_
5
i=1
x
i
_
2
5
= 10
0
5
= 10
SC
xy
=
5
i=1
x
i
y
i
_
5
i=1
x
i
__
5
i=1
y
i
_
5
= 7
0 5
5
= 7
62 7. Regresion y correlacion
de donde:
1
=
SC
xy
SC
x
=
7
10
= 0.7 y
0
= y
1
x = 1 0.7 0 = 1
as la ecuacion de la recta de mejor ajuste es:
y = 0.7x + 1.
Esto se ilustra en la gura 3.
FIGURE 3. Recta y = 0.7x + 1.
Finalmente si x = 0.5 entonces una prediccion pata valor de y es y =
0.7 0.5 + 1 = 1.35.
Ejercicio 28 Se dan seis puntos cuyas coordenadas se muestran en la si-
guiente tabla:
x 5 3 1 1 3 5
y 2 1 1 2 2 3
1. Obtenga la recta de mnimos cuadrados.
2. Graque en un mismo plano los pares ordenados y la recta.
3. Estime el valor de y si x = 1.5.
Ejercicio 29 Un fabricante de jabon en polvo realizo un experimento para
investigar el efecto del precio por caja sobre la demanda. Se asigno a cada
una de seis diferentes regiones de venta un precio unitario al por mayor
por caja, para la venta a tiendas mayoristas y a las cadenas de grandes
supermercados en la zona. Despues de un mes se calculo el porcentaje y del
incremento (o decremento) en las ventas por region durante el mes anterior.
7. Regresion y correlacion 63
Se indican los precios unitarios asignados a las regiones y los aumentos
porcentuales en las ventas en la siguiente tabla.
Precio unitario en $ x 6.40 6.45 6.5 6.55 6.6 6.65
% de aumento en las ventas y 9.8 7.6 6.3 4.5 4.2 1.7
1. Obtenga la recta de mnimos cuadrados.
2. Graque en un mismo plano los pares ordenados y la recta.
3. Use la recta de mnimos cuadrados para estimar el porcentaje de
aumento en las ventas para un precio unitario de $6.53 por caja.
1.1 Error estandar de la estimacion
En la seccion anterior se utilizo el metodo de mnimos cuadrados para
predecir el valor de y dado un valor de x. Aunque este metodo da como
resultado una lnea que se ajusta a los datos con el mnimo de variacion, la
ecuacion de regresion no es un dispositivo perfecto de prediccion, a menos
que todos los puntos observados se encuentren en la lnea de regresion
predicha. Del mismo modo que no se puede esperar que todos los valores
de los datos esten ubicados exactamente en su media aritmetica, tampoco
se puede esperar que todos los puntos de los datos caigan exactamente
sobre la lnea de regresion. La lnea de regresion solo sirve como un dispos-
itivo aproximado de prediccion de un valor y para un valor determinado
valor de x. Por lo tanto, se necesita desarrollar un estadstico que mida la
variabilidad de los valores de y reales, a partir de los valores y predichos,
es decir desarrollar una medida que nos cuantique en cuanto se desvan
los verdaderos valores de y con respecto a los valores estimados de y por
la recta de regresion. Esta medida de variabilidad se conoce como Error
Estandar de la Estimacion.
El error estandar de la estimadocion, denotado por el smbolo S
yx
, se
dene como:
S
yx
=
_
n
i=1
(y y)
2
n 2
(7.1)
Este error estandar del estimador representa una medida de la variacion
alrededor de la lnea de regresion ajustada. La interpretacion del error del
estimador es analoga a la de la desviacion estandar, pues mide la variabil-
idad alrededor de la lnea de regresion ajustada. Tambien se utiliza para
determinar si hay relacion estadsticamente signicativa entre las dos vari-
ables. Se ilustra en la gura 4.
64 7. Regresion y correlacion
FIGURE 4. Interpretaci on geometrica del error estandar de estimacion.
Se puede probar que la formula 7.1 es equivalente a:
S
yx
=
_
n
i=1
y
2
i
0
n
i=1
y
i
1
n
i=1
x
i
y
i
n 2
(7.2)
Observacin 16 En la practica se usa la formula 7.2 en lugar de la formula
7.1 pues es mas facil de calcular.
Observacin 17 En las formulas 7.1 y 7.2 muchos estadsticos preeren
utilizar n en lugar de n 2 en el denominador.
Ejemplo 36 Para los datos del ejemplo 35, el Error Estandar de la Esti-
macion es:
S
yx
=
_
n
i=1
y
2
i
0
n
i=1
y
i
1
n
i=1
x
i
y
i
n 2
=
_
11 1 5 0.7 7
5 2
= 0.605.
Ejercicio 30 Calcule el Error Estandar de la Estimacion para las rectas
de regresion de los ejercicios 28 y 29.
7. Regresion y correlacion 65
2 Coeciente de correlacion y determinacion
2.1 El coeciente de correlacion
A veces se desea obtener un indicador de la intensidad, o fuerza, de la
relacion lineal entre dos variables y y x que no dependa de sus respectivas
escalas de medicion. Se designara por medida de correlacion lineal entre y
y x.
La medida de correlacion lineal com unmente utilizada en estadstica se
llama coeciente de correlacion momentoproducto de Pearson.
Esta cantidad, denotada por el smbolo r, se dene como se indica en el
siguiente formula.
Denicin 20 El coeciente de correlacion momentoproducto de Pearson
se dene como:
r =
SC
xy
_
SC
x
SC
y
=
n
i=1
x
i
y
i
i=1
x
i
i=1
y
i
_
_
_
_
_
_
n
i=1
x
2
i
i=1
x
i
2
n
_
_
_
_
_
_
_
_
_
_
n
i=1
y
2
i
i=1
y
i
2
n
_
_
_
_
_
.
Observacin 18 Se tiene que 1 r 1.
Observacin 19 La interpretacion del coeciente de correlacion es la sigu-
iente, si r = 0 implica que no hay correlacion lineal entre y y x. Si r es un
valor positivo implica que la recta de regresion sube a la derecha y si r es
cercano a 1 se considera que hay una correlacion positiva fuerte, si r es
cercano a 0.5 se considera que hay una correlacion positiva moderada y
si r es cercano a 0 se considera que hay una correlacion positiva debil.
Mientras que si r es un valor negativo implica que la recta de regresion
baja hacia a la derecha y si r es cercano a 1 se considera que hay una
correlacion negativa fuerte, si r es cercano a 0.5 se considera que hay
una correlacion negativa moderada y si r es cercano a 0 se considera
que hay una correlacion negativa debil. Esto se ilustra gracamente en
la gura 5.
Ejemplo 37 Para los datos del ejemplo 35 el Coeciente de Correlacion
es:
r =
SC
xy
_
SC
x
SC
y
=
7
10 6
= 0.90,
por lo que hay una correlacion positiva fuerte.
66 7. Regresion y correlacion
FIGURE 5. Interpretaci on geometrica del coeciente de correlacion.
Ejercicio 31 Calcule el Coeciente de Correlacion para las rectas de re-
gresion de los ejercicios 28 y 29, luego interprete los resultados.
2.2 El Coeciente de determinacion
Para interpretar el coeciente de correlacion hemos impleado los terminos
debil , moderada y fuerte, los cuales no tienen un signicado muy
preciso, para algunas personas la relacion puede ser debil y para otras esa
misma relacion podra ser moderada, por lo que es necesario obtener una
medida que nos de un mayor signicado a la relacion, la cual esta dada por
el coeciente de determinacion.
El coeciente de determinacion cuantica en forma porcentual la variacion
total en la variable dependiente y que se explica por la variable x, o sea se
debe a la variacion en la variable independiente x. Este valor oscila entre
0 y 1, y se calcula elevando al cuadrado el coeciente de correlacion de
Pearson.
7. Regresion y correlacion 67
Denicin 21 El coeciente de determinacion se dene como:
R = r
2
.
Observacin 20 El coeciente de determinacion se puede interpretar como
una proporcion o porcentaje de la variacion de la variable y se que se puede
explicar debido a la variacion de la variable x.
Ejemplo 38 Para los datos del ejemplo 35 el Coeciente de Determinacion
es:
R = r
2
= (0.9)
2
= 0.81.
Este resultado se puede interpretar diciendo que un 81% de la variacion de
la variable y se debe a la variacion de la variable x.
Ejercicio 32 Calcule el Coeciente de Determinacion para las rectas de
regresion de los ejercicios 28 y 29, luego interprete los resultados.
3 Estimacion de intervalos de conanza para
predecir
3.1 Prediccion del valor particular de y dado un valor de x
Hasta ahora, dado un valor particular de x hemos evaluado dicho valor en
la recta de regresion y =
0
+
1
x para obtener una prediccion y de y la cual
es una aproximacion del verdadero valor y. Sin embargo, sera mejor tener
un intervalo de prediccion con un cierto coeciente de conanza (1 ).
El intervalo de prediccion para y con un coeciente de conanza
(1 ) dado un valor de x = x
p
es:
yt
/2
S
yx
1 +
1
n
+
(x
p
x)
2
SC
x
< y < y+t
/2
S
yx
1 +
1
n
+
(x
p
x)
2
SC
x
,
donde t
/2
se calcula con n 2 grados de libertad y
SC
x
=
n
i=1
x
2
i
_
n
i=1
x
i
_
2
n
.
Ejemplo 39 Para los datos del ejemplo 35, si x = x
p
= 0.5 encuentre un
intervalo de prediccion para y con un coeciente de conanza del 95%.
Solucin 27 Se debe calcular:
yt
/2
S
yx
1 +
1
n
+
(x
p
x)
2
SC
x
< y < y+t
/2
S
yx
1 +
1
n
+
(x
p
x)
2
SC
x
.
68 7. Regresion y correlacion
Como n 2 = 5 2 = 3, ademas (1 ) = 0.95 entonces = 0.05 y
(1
2
) = 0.975 se debe buscar en la tabla t
0.975
con 3 grados de libertad, de
donde t
/2
= 3.182. Luego sustiyendo los valores que ya han sido calculados
en los ejemplos anteriores tenemos:
1.35 3.182 0.605
_
1 +
1
5
+
(0.5 0)
2
10
< y < 1.35 + 3.182 0.605
_
1 +
1
5
+
(0.5 0)
2
10
,
entonces tenemos nalmente que el intervalo de prediccion para y si x =
x
p
= 0.5 es:
0.78 < y < 3.48.
Ejercicio 33 Para los datos del ejemplo 28, si x = x
p
= 1.5 encuentre un
intervalo de prediccion para y con un coeciente de conanza del 95%.
Ejercicio 34 Para los datos del ejemplo 29, si el precio unitario es x =
$6.53 encuentre un intervalo de prediccion para el porcentaje de aumento
en las ventas, con coeciente de conanza del 90%.
3.2 Estimacion del valor esperado (media) de y dado un valor
de x
La estimacion del valor medio de y para un valor dado de x (es decir, la
estimacion de E(y|x)) puede ser un problema practico muy importante. Si
la ganancia de una corporacion, y, esta relacionada linealmente con los gas-
tos de la publicidad, x, la corporacon deseara estimar la ganancia media
para un gasto dado, x. Vamos a obtener un intervalo de prediccion con un
cierto coeciente de conanza (1 ) para E(y|x).
El intervalo de prediccion para E(y|x) con un coeciente de conanza
(1 ) cuando x = x
p
es:
y t
/2
S
yx
1
n
+
(x
p
x)
2
SC
x
< E(y|x) < y +t
/2
S
yx
1
n
+
(x
p
x)
2
SC
x
,
donde t
/2
se calcula con n 2 grados de libertad y
SC
x
=
n
i=1
x
2
i
_
n
i=1
x
i
_
2
n
.
Ejemplo 40 Para los datos del ejemplo 35, si x = x
p
= 0.5 encuentre
un intervalo de prediccion para E(y|x) con un coeciente de conanza del
95%.
7. Regresion y correlacion 69
Solucin 28 Se debe calcular:
y t
/2
S
yx
1
n
+
(x
p
x)
2
SC
x
< E(y|x) < y +t
/2
S
yx
1
n
+
(x
p
x)
2
SC
x
:
Como n 2 = 5 2 = 3, ademas (1 ) = 0.95 entonces = 0.05 y
(1
2
) = 0.975 se debe buscar en la tabla t
0.975
con 3 grados de libertad, de
donde t
/2
= 3.182. Luego sustiyendo los valores que ya han sido calculados
en los ejemplos anteriores tenemos:
1.35 3.182 0.605
_
1
5
+
(0.5 0)
2
10
< E(y|x) < 1.35 + 3.182 0.605
_
1
5
+
(0.5 0)
2
10
,
entonces tenemos nalmente que el intervalo de prediccion para y si x =
x
p
= 0.5 es:
0.43 < E(y|x) < 2.26.
Ejercicio 35 Para los datos del ejemplo 28, si x = x
p
= 1.5 encuentre
un intervalo de prediccion para E(y|x) con un coeciente de conanza del
95%.
Ejercicio 36 Para los datos del ejemplo 29, si el precio unitario es x =
$6.53 encuentre un intervalo de prediccion para la media del porcentaje de
aumento en las ventas, con coeciente de conanza del 90%.
Ejercicio 37 Se seleccionaron aleatoriamente diez gerentes que trabajan
actualmente en una compa na desde hace cinco a nos. Se muestran en la
siguiente tabla su clasicacion en exito y sus calicaciones como aspirantes.
Gerente Clasicacion como apirante Clasicaci on de exito administrativo
1 39 65
2 43 78
3 21 52
4 64 82
5 57 92
6 47 89
7 28 73
8 75 98
9 34 56
10 52 75
1. Obtenga una recta de prediccion de mnimos cuadrados para estos
datos.
70 7. Regresion y correlacion
2. Graque la recta y los puntos en un mismo plano.
3. Estime una aproximacion para el valor en la escala de exito admin-
istrativo para un aspirante que alcanzo una calicacion de x = 50 en
la prueba de aspirante.
4. Calcule el error estandar de la estimacion.
5. Calcule la correlacion r entre sus calicaciones como aspirantes y su
clasicacion en exito administrativo e interprete el resultado.
6. Calcule el coeciente de determinacion R entre sus calicaciones como
aspirantes y su clasicacion en exito administrativo e interprete el
resultado.
7. Hallar un intervalo de conanza del 95% para el valor de y (la clasi-
cacion en exito administrativo) dado que la calicacion en la prueba
de aspirante es x = 50.
8. Hallar un intervalo de conanza del 95% para el valor esperado de y
(la clasicacion en exito administrativo) dado que la calicacion en
la prueba de aspirante es x = 50.
S-ar putea să vă placă și
- Metrologia Geometrica DimensionalDocument217 paginiMetrologia Geometrica DimensionalJose93% (15)
- Macizo RocosoDocument21 paginiMacizo RocosoyohansdÎncă nu există evaluări
- Unidad 4 de Transporte y AsignaciónDocument9 paginiUnidad 4 de Transporte y AsignaciónAlejandra Martinez100% (1)
- Mensaje de La ObraDocument3 paginiMensaje de La ObraHerbert Huaranga61% (18)
- Estudio Sobre La Oferta y Demanda para La Creacion de Nuevas EAP de La UNSDocument214 paginiEstudio Sobre La Oferta y Demanda para La Creacion de Nuevas EAP de La UNSHerbert HuarangaÎncă nu există evaluări
- Auditoría Tributaria - Sesión 01 y 02Document66 paginiAuditoría Tributaria - Sesión 01 y 02Herbert HuarangaÎncă nu există evaluări
- Mat5-U8-Sesion 13Document7 paginiMat5-U8-Sesion 13Herbert HuarangaÎncă nu există evaluări
- TestDocument118 paginiTestHerbert HuarangaÎncă nu există evaluări
- A5G2E4Document13 paginiA5G2E4Mauricio RoldánÎncă nu există evaluări
- Guia Unidad 1 ProbabilidadDocument12 paginiGuia Unidad 1 ProbabilidadJorge TorresÎncă nu există evaluări
- Conocimientos Básicos de Contabilidad Definición de ContabilidadDocument59 paginiConocimientos Básicos de Contabilidad Definición de Contabilidadlibreriakelita01Încă nu există evaluări
- Física I Y Laboratorio - Paralelo "C" Práctica Nº1: InstruccionesDocument3 paginiFísica I Y Laboratorio - Paralelo "C" Práctica Nº1: InstruccionesMarializ HuallpaÎncă nu există evaluări
- 1 Silabo Matematica Discreta 2018 - IIDocument5 pagini1 Silabo Matematica Discreta 2018 - IIEdverd AriasÎncă nu există evaluări
- Guía de Trabajo - Binomio de NewtonDocument4 paginiGuía de Trabajo - Binomio de NewtonFabiana UrteagaÎncă nu există evaluări
- Proposiciones Básicas - AYERDocument12 paginiProposiciones Básicas - AYERlibrietaliaÎncă nu există evaluări
- 3 1 Horarios GradoDocument19 pagini3 1 Horarios GradoSergio Peñas MayoralÎncă nu există evaluări
- Metodos Estadisticos - Capitulo 4Document9 paginiMetodos Estadisticos - Capitulo 4Marco AlcántaraÎncă nu există evaluări
- 3° Planeación NEM Con Pausas Activas Noviembre 2019Document44 pagini3° Planeación NEM Con Pausas Activas Noviembre 2019JUAN AQUINO100% (2)
- Camacho Corrales Maza L4 SinAnexosDocument39 paginiCamacho Corrales Maza L4 SinAnexosLuis Adrian CamachoÎncă nu există evaluări
- Análisis Complejo: HistoriaDocument5 paginiAnálisis Complejo: HistoriaMARCELOÎncă nu există evaluări
- TopografiaDocument11 paginiTopografiaLUIS ISMAEL SANCHEZ ZAPANAÎncă nu există evaluări
- Sesión 1.1.1 (L) Fundamento para El Análisis Químico 2022-0Document7 paginiSesión 1.1.1 (L) Fundamento para El Análisis Químico 2022-0Christina Aguilar del RioÎncă nu există evaluări
- Ejercicio 22-23Document4 paginiEjercicio 22-23Fan GxrlÎncă nu există evaluări
- Estadistica DescriptivaDocument16 paginiEstadistica DescriptivaAndresFelipePrietoAlarcon100% (1)
- Matriz de Impacto Ambiental Espinosa GrandaDocument10 paginiMatriz de Impacto Ambiental Espinosa GrandaSantiagoGrandaÎncă nu există evaluări
- Primera Unidad Matematica Basica 1Document41 paginiPrimera Unidad Matematica Basica 1Franklin Enrique Cotes CamachoÎncă nu există evaluări
- Características Reológicas de AlimentosDocument20 paginiCaracterísticas Reológicas de AlimentosJunior Artur Carmen VilelaÎncă nu există evaluări
- Matematica Regla de Tres Actualizado 1 10Document25 paginiMatematica Regla de Tres Actualizado 1 10robert guevara cruzÎncă nu există evaluări
- Folleto Aplicado Investigacion OperacionesDocument48 paginiFolleto Aplicado Investigacion Operacioneslobofrank2Încă nu există evaluări
- Numero de Reynolds y Ecuacion de DarcyDocument5 paginiNumero de Reynolds y Ecuacion de Darcyjenipher Batista JÎncă nu există evaluări
- Analisis Del Articulo Rayleigh-FadingDocument6 paginiAnalisis Del Articulo Rayleigh-FadingBrian Quinde SaltosÎncă nu există evaluări
- SESIÓN DE APRENDIZAJE Martes 14 DE NOVIEMBRE MAT REGLA DE TRES SIMPE INVERSADocument5 paginiSESIÓN DE APRENDIZAJE Martes 14 DE NOVIEMBRE MAT REGLA DE TRES SIMPE INVERSACarlos Enrique Argote Chire100% (1)
- Historia Del TangramDocument2 paginiHistoria Del TangramAndres OlayaÎncă nu există evaluări
- Hallar El Vértice y Las Intersecciones Con El Eje X de Una Parábola.Document3 paginiHallar El Vértice y Las Intersecciones Con El Eje X de Una Parábola.Maria Jose Lopez NeedhamÎncă nu există evaluări
- Precalculo Chapter7Document48 paginiPrecalculo Chapter7caren malpicaÎncă nu există evaluări