S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Home Theater Speaker System: Simply CinemaDocument20 paginiHome Theater Speaker System: Simply CinemaMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Elystar User Manual NL SHDocument15 paginiElystar User Manual NL SHMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Frodo Guide: Henryford 06/08/2013Document48 paginiFrodo Guide: Henryford 06/08/2013Mario Alberto Gonzalez PeñalverÎncă nu există evaluări
- TD-W8951ND User Guide PDFDocument79 paginiTD-W8951ND User Guide PDFSandi AslanÎncă nu există evaluări
- HUAWEI Y300 SMARTPHONE ROOT GUIDE - How To Unlock and Root Huawei Ascend Y300 (All Versions)Document6 paginiHUAWEI Y300 SMARTPHONE ROOT GUIDE - How To Unlock and Root Huawei Ascend Y300 (All Versions)Mario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Video Streaming Concepts, Algorithms, and SystemsDocument35 paginiVideo Streaming Concepts, Algorithms, and SystemsAhmedSaeedÎncă nu există evaluări
- Mk802 III User Manual W2compDocument22 paginiMk802 III User Manual W2compJordi Alemany0% (1)
- Handbuch MK802IIIS EnglishDocument15 paginiHandbuch MK802IIIS EnglishMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Elyseo 125Document22 paginiElyseo 125Mario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Tl-Pa2010pkit v1 User GuideDocument27 paginiTl-Pa2010pkit v1 User GuideMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Manual IBIZA 2000 AllDocument140 paginiManual IBIZA 2000 AllMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- TD-W8951ND User GuideDocument79 paginiTD-W8951ND User GuideMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Microsoft Word New Inside Out Upper IntermediateDocument11 paginiMicrosoft Word New Inside Out Upper IntermediateMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Ibiza SCDocument4 paginiIbiza SCMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- PIM+IBI COR+inglesDocument43 paginiPIM+IBI COR+inglesMario Alberto Gonzalez PeñalverÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- RCC Rate AnalysisDocument3 paginiRCC Rate AnalysisKingsley ChukwuÎncă nu există evaluări
- Avamar KB 000471330Document1 paginăAvamar KB 000471330jaykkamalÎncă nu există evaluări
- FM Fire Pump Inspection Checklist and FormDocument4 paginiFM Fire Pump Inspection Checklist and Formkrunalb@inÎncă nu există evaluări
- Client Server ModelDocument8 paginiClient Server ModelShreya DubeyÎncă nu există evaluări
- 02 Installing and ConfiguringDocument52 pagini02 Installing and ConfiguringJagdish ModiÎncă nu există evaluări
- AKROUSH, Et Al. (2016) - CFRP Shear Strengthening of Reinforced Concrete Beams in Zones of Combined Shear and Normal StressesDocument18 paginiAKROUSH, Et Al. (2016) - CFRP Shear Strengthening of Reinforced Concrete Beams in Zones of Combined Shear and Normal StressesDaniel GuedesÎncă nu există evaluări
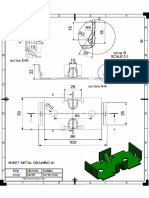
- Siemens NX 10 Sheet Metal TutorialDocument1 paginăSiemens NX 10 Sheet Metal TutorialChokri Atef100% (1)
- FischerPANEEL 06 2012 Engl IDocument12 paginiFischerPANEEL 06 2012 Engl IviviÎncă nu există evaluări
- An 3927Document72 paginiAn 3927Anderson ArjonaÎncă nu există evaluări
- Product Catalogue Camfil FarrDocument61 paginiProduct Catalogue Camfil FarrTrần Hữu DũngÎncă nu există evaluări
- TOGAF 8 Certification For PractitionersDocument101 paginiTOGAF 8 Certification For PractitionersMbaStudent56Încă nu există evaluări
- Design Guidelines For Steel Trapezoidal Box Girder Systems PDFDocument84 paginiDesign Guidelines For Steel Trapezoidal Box Girder Systems PDFGogyÎncă nu există evaluări
- Fountain Design GuideDocument19 paginiFountain Design Guideinfo66567% (3)
- Laser Fiche 8.2 Client OptionsDocument33 paginiLaser Fiche 8.2 Client Optionskifah1405Încă nu există evaluări
- 2012S1 Itsy 2400 5420Document5 pagini2012S1 Itsy 2400 5420Christine Logue0% (1)
- Building Energy Performance Simulation Tools - A Life-Cycle and Interoperable PerspectiveDocument49 paginiBuilding Energy Performance Simulation Tools - A Life-Cycle and Interoperable Perspectivehb_scribÎncă nu există evaluări
- OfficeServ 7070 PDFDocument4 paginiOfficeServ 7070 PDFEduardoÎncă nu există evaluări
- Site Diary 1Document7 paginiSite Diary 1Alia KhalidÎncă nu există evaluări
- Clean Room Classifications - Class 100 To Class 100,000 CleanroomsDocument4 paginiClean Room Classifications - Class 100 To Class 100,000 CleanroomsrajeeshÎncă nu există evaluări
- Konica Minolta Bizhub 165 User GuideDocument146 paginiKonica Minolta Bizhub 165 User GuideAnonymous gptX7l0ARXÎncă nu există evaluări
- TughlaqabadDocument9 paginiTughlaqabadsmrithiÎncă nu există evaluări
- 1 E-Clim Clima Fadu UbaDocument16 pagini1 E-Clim Clima Fadu UbaNatalyRochaÎncă nu există evaluări
- OrbitX - Remote Assistance Setup PDFDocument10 paginiOrbitX - Remote Assistance Setup PDFapisituÎncă nu există evaluări
- EXPANDING AESTHETIC BOUNDARIES OF AUSTRALIAN GARDEN DESIGN Georgia HarveyDocument14 paginiEXPANDING AESTHETIC BOUNDARIES OF AUSTRALIAN GARDEN DESIGN Georgia Harveywilliamartin100% (1)
- SAILOR 6194 TCU - InstUserManual PDFDocument102 paginiSAILOR 6194 TCU - InstUserManual PDFVictor Vello LobatoÎncă nu există evaluări
- HUAWEI E397Bu-501 User Manual (V100R001 01)Document20 paginiHUAWEI E397Bu-501 User Manual (V100R001 01)chaconcgÎncă nu există evaluări
- MML Commands: Object InstructionDocument3 paginiMML Commands: Object Instructionelectronique12Încă nu există evaluări
- Mohenjo-Daro PicturesDocument32 paginiMohenjo-Daro PicturesIzhaŕ ĶẳsìÎncă nu există evaluări
- Sewer Piping Systems Installation Guide PDFDocument33 paginiSewer Piping Systems Installation Guide PDFMahmoud GwailyÎncă nu există evaluări
- AIM High School JPJDocument2 paginiAIM High School JPJKhalidsaifullahÎncă nu există evaluări