S-ar putea să vă placă și
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Power BI Class NotesDocument18 paginiPower BI Class Notesramu9999Încă nu există evaluări
- Technique For Awake Fibre Optic IntubationDocument3 paginiTechnique For Awake Fibre Optic Intubationmonir61Încă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- T TESTDocument24 paginiT TESTanmolgarg129Încă nu există evaluări
- Tonsillectomy and AdiniodectomyDocument0 paginiTonsillectomy and Adiniodectomymonir61Încă nu există evaluări
- Admission Nursing AssessmentDocument20 paginiAdmission Nursing Assessmentmonir61Încă nu există evaluări
- Different Types of Data Analysis - Data Analysis Methods and Techniques in Research ProjectsDocument9 paginiDifferent Types of Data Analysis - Data Analysis Methods and Techniques in Research ProjectsHamed TaherdoostÎncă nu există evaluări
- Answers Are Highlighted in Yellow Color: MCQ's Subject:Introductory EconometricsDocument74 paginiAnswers Are Highlighted in Yellow Color: MCQ's Subject:Introductory EconometricsSimran Simie100% (1)
- Overview Six Sigma PhasesDocument3 paginiOverview Six Sigma Phaseshans_106Încă nu există evaluări
- C191-E016 LabSolutionsDocument20 paginiC191-E016 LabSolutionsJose Carlos Salgado ArimanaÎncă nu există evaluări
- Cystoscopy: A Guide For WomenDocument2 paginiCystoscopy: A Guide For Womenmonir61Încă nu există evaluări
- Ompressions: Irway: Reathing:: Center For Professional Practice of Nursing CPR Guidelines For Health-Care ProvidersDocument11 paginiOmpressions: Irway: Reathing:: Center For Professional Practice of Nursing CPR Guidelines For Health-Care Providersmonir61Încă nu există evaluări
- Coronary ThrombosisDocument1 paginăCoronary Thrombosismonir61Încă nu există evaluări
- 2016 CUSP A Framework For SuccessDocument31 pagini2016 CUSP A Framework For Successmonir61Încă nu există evaluări
- PALS 2010 OverviewDocument26 paginiPALS 2010 Overviewmonir61Încă nu există evaluări
- Update On PDPHDocument18 paginiUpdate On PDPHmonir61Încă nu există evaluări
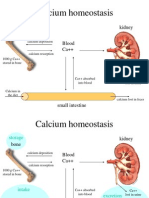
- Calcium Homeostasis: Bone Blood Ca++ KidneyDocument12 paginiCalcium Homeostasis: Bone Blood Ca++ KidneyOmSilence2651Încă nu există evaluări
- Management of Intravascular Catheter Related InfectionDocument19 paginiManagement of Intravascular Catheter Related Infectionmonir61Încă nu există evaluări
- Brenda Creaney PresentationDocument21 paginiBrenda Creaney Presentationmonir61Încă nu există evaluări
- Improving The Patient Experience Through Nursing and Midwifery KpisDocument35 paginiImproving The Patient Experience Through Nursing and Midwifery Kpismonir61Încă nu există evaluări
- TandA 9912Document50 paginiTandA 9912Vinod RajÎncă nu există evaluări
- Hysterectomy: The American College of Obstetricians and GynecologistsDocument0 paginiHysterectomy: The American College of Obstetricians and Gynecologistsmonir61Încă nu există evaluări
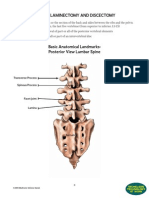
- LumbarlandDocument10 paginiLumbarlandmonir61Încă nu există evaluări
- Regression: Variables Entered/RemovedDocument3 paginiRegression: Variables Entered/RemovedSandoartaÎncă nu există evaluări
- Power BI 5 Mini ProjectsDocument9 paginiPower BI 5 Mini Projectsvogel21cryÎncă nu există evaluări
- Swift-Hackathon-2023 Briefing-Pack Vfinal 1707Document25 paginiSwift-Hackathon-2023 Briefing-Pack Vfinal 1707Navodye GunathilakaÎncă nu există evaluări
- International Journal of Information Management: Boonyarat Phadermrod, Richard M. Crowder, Gary B. WillsDocument10 paginiInternational Journal of Information Management: Boonyarat Phadermrod, Richard M. Crowder, Gary B. WillsgilangÎncă nu există evaluări
- Online Video Effect As A Learning MediaDocument8 paginiOnline Video Effect As A Learning MediaHatomi At-TafassyiiÎncă nu există evaluări
- Analytical SkillsDocument6 paginiAnalytical SkillsGodwilÎncă nu există evaluări
- Qual Analysis CH 2Document13 paginiQual Analysis CH 2Joaquim SilvaÎncă nu există evaluări
- Topic Modeling: Latent Semantic Analysis For The Social SciencesDocument15 paginiTopic Modeling: Latent Semantic Analysis For The Social SciencesDeep GhoseÎncă nu există evaluări
- Evaluating The Relationship of The Daily Income and Expenses of Tricycle Drivers in Angeles CityDocument8 paginiEvaluating The Relationship of The Daily Income and Expenses of Tricycle Drivers in Angeles CityFrancis RosalesÎncă nu există evaluări
- Checklist To Evaluate Qualitative ResearchDocument1 paginăChecklist To Evaluate Qualitative ResearchliloÎncă nu există evaluări
- Plantilla Dos Poblaciones ResueltaDocument22 paginiPlantilla Dos Poblaciones Resueltaluisfernando puesanÎncă nu există evaluări
- Rta Poster PDFDocument1 paginăRta Poster PDFUjang Yana MaulanaÎncă nu există evaluări
- Forecasting ProblemsDocument2 paginiForecasting ProblemsMuhammad Naveed IkramÎncă nu există evaluări
- Prof. Dr. Moustapha Ibrahim Salem Mansourms@alexu - Edu.eg 01005857099Document110 paginiProf. Dr. Moustapha Ibrahim Salem Mansourms@alexu - Edu.eg 01005857099Ahmed ElsayedÎncă nu există evaluări
- Census Analysis Project STAT 330Document22 paginiCensus Analysis Project STAT 330Robert LeeÎncă nu există evaluări
- Factors Influencing Purchasing Intention of Smartphone Among University StudentsDocument9 paginiFactors Influencing Purchasing Intention of Smartphone Among University StudentsJai SharmaÎncă nu există evaluări
- Pre Defense Presentation Presented By: Shishir Rijal (CM2015)Document61 paginiPre Defense Presentation Presented By: Shishir Rijal (CM2015)ShishirRijalÎncă nu există evaluări
- A Study of Safety Culture at An Aviation Organization PDFDocument158 paginiA Study of Safety Culture at An Aviation Organization PDFAlula GebruÎncă nu există evaluări
- It's A Tentative Explanation of Some Process, Wether That Process Is Natural or ArtificialDocument10 paginiIt's A Tentative Explanation of Some Process, Wether That Process Is Natural or Artificialgenelyn ingatÎncă nu există evaluări
- Lesson 3 Logistic Regression DiagnosticsDocument37 paginiLesson 3 Logistic Regression Diagnosticsalaa_h1Încă nu există evaluări
- Exercises For QUIZ 3Document2 paginiExercises For QUIZ 3louise carinoÎncă nu există evaluări
- Anova PDFDocument25 paginiAnova PDFTatsat PandeyÎncă nu există evaluări
- En Tanagra Clustering TreeDocument12 paginiEn Tanagra Clustering TreeUyi Kristina NurainiÎncă nu există evaluări
- DWDMDocument11 paginiDWDMShanthan ReddyÎncă nu există evaluări