S-ar putea să vă placă și
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Understand Sultan Bahu Poetry by Sharief Sabir WorkDocument216 paginiUnderstand Sultan Bahu Poetry by Sharief Sabir WorkSHAHID FAROOQÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Remedies From The Holy Qur'AnDocument79 paginiRemedies From The Holy Qur'Anislamiq98% (220)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Fazli Anwar e ElahiDocument95 paginiFazli Anwar e ElahiSHAHID FAROOQÎncă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Ibtidai Suluk (Urdu)Document28 paginiIbtidai Suluk (Urdu)Jalalludin Ahmad Ar-Rowi100% (1)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Baba Bulehshah Punjabi Read PDF FormatDocument440 paginiBaba Bulehshah Punjabi Read PDF FormatSHAHID FAROOQÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Tears of Rasool PBUH UrduDocument72 paginiTears of Rasool PBUH Urduapi-3704968100% (3)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- All About Tracing Oracle SQL SessionsDocument12 paginiAll About Tracing Oracle SQL SessionsSHAHID FAROOQÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Dil Daryia SamundarDocument303 paginiDil Daryia SamundarSHAHID FAROOQÎncă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Waseela Mufti M Faiz Awasi Qadri UrduDocument28 paginiWaseela Mufti M Faiz Awasi Qadri UrduSHAHID FAROOQÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Anguthay ChoomnaDocument90 paginiAnguthay ChoomnaISLAMIC LIBRARYÎncă nu există evaluări
- Wazu Ka TareekaDocument20 paginiWazu Ka TareekaSHAHID FAROOQÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Syeda Fatima (A.s)Document71 paginiSyeda Fatima (A.s)Syed Imran Shah100% (1)
- Was Eel ADocument158 paginiWas Eel ASHAHID FAROOQÎncă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Sultan Bahu PoetryDocument216 paginiSultan Bahu PoetrySHAHID FAROOQÎncă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Imam-e-Aazam Awr Imam Bukhari (Nisbat o Taaluq Awr Wajuhaat e Adam-e-Riwayat) Part-2Document66 paginiImam-e-Aazam Awr Imam Bukhari (Nisbat o Taaluq Awr Wajuhaat e Adam-e-Riwayat) Part-2MinhajBooksÎncă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Tabarrakut (Relics) Are Blessings (Urdu)Document64 paginiTabarrakut (Relics) Are Blessings (Urdu)faisal.noori5932Încă nu există evaluări
- Hujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahDocument1 paginăHujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahRana Mazhar75% (4)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Nijasaton Kee Pehchaan (Urdu)Document23 paginiNijasaton Kee Pehchaan (Urdu)faisal.noori5932Încă nu există evaluări
- Remedies From The Holy Qur'AnDocument79 paginiRemedies From The Holy Qur'Anislamiq98% (220)
- Sirr Al Israr Urdu by Sh. Gilani R.ADocument204 paginiSirr Al Israr Urdu by Sh. Gilani R.ASHAHID FAROOQÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Complete 136Document25 paginiComplete 136ISLAMIC LIBRARYÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Fatuh Al Ghaib Urdu by Sh. Gilani R.A Urdu TranslationDocument167 paginiFatuh Al Ghaib Urdu by Sh. Gilani R.A Urdu TranslationSHAHID FAROOQ100% (4)
- Nuh Ha Mim Keller - Kalam and IslamDocument14 paginiNuh Ha Mim Keller - Kalam and IslamMTYKK100% (8)
- Hazrat Fatima Sayeda e Qainaat (R.A)Document122 paginiHazrat Fatima Sayeda e Qainaat (R.A)Faisal MalikÎncă nu există evaluări
- Biography of Naqhsbandi Shuyukh (Urdu)Document108 paginiBiography of Naqhsbandi Shuyukh (Urdu)Talib Ghaffari100% (1)
- Naat - Subze Gumbad Kay Sayee MainDocument200 paginiNaat - Subze Gumbad Kay Sayee MainKaleem Ahmed100% (10)
- Dil Daryia SamundarDocument303 paginiDil Daryia SamundarSHAHID FAROOQÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Dreams in Islam - The Window To The Heart! by Shaikh. Imran Nazar HoseinDocument105 paginiDreams in Islam - The Window To The Heart! by Shaikh. Imran Nazar Hoseinm.suh100% (10)
- Aqeedah WastiyahDocument97 paginiAqeedah Wastiyahapi-3700670Încă nu există evaluări
- 99 Perfect Names and Attributes of AllahDocument5 pagini99 Perfect Names and Attributes of AllahSHAHID FAROOQÎncă nu există evaluări
- Fortinet Webinar - FortiADC - Phai La Quy (Sep17,21)Document22 paginiFortinet Webinar - FortiADC - Phai La Quy (Sep17,21)dasker NoÎncă nu există evaluări
- Auction 86 WiMAX Bid PaymentsDocument1 paginăAuction 86 WiMAX Bid PaymentsEsme VosÎncă nu există evaluări
- Tsplus Remote Access Documentation: General InformationDocument408 paginiTsplus Remote Access Documentation: General InformationsantoshkumarÎncă nu există evaluări
- WAAS TShoot GuideDocument192 paginiWAAS TShoot GuideCarlos Chavez0% (1)
- Mercury Series v14Document303 paginiMercury Series v14andriy nbookÎncă nu există evaluări
- xw5033 3.50 Part 1 ChassisDocument153 paginixw5033 3.50 Part 1 ChassisJavier TofaloÎncă nu există evaluări
- McAfee Advanced Threat DefenseDocument6 paginiMcAfee Advanced Threat Defensesunny_dce2k5Încă nu există evaluări
- Virtualization 2Document38 paginiVirtualization 2naamilaÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- HASP SL Network License ToolDocument0 paginiHASP SL Network License Toolppat503Încă nu există evaluări
- QT-ZEUSII-N DVR EspecificacionesDocument3 paginiQT-ZEUSII-N DVR EspecificacionesGabriela AstudilloÎncă nu există evaluări
- OSX ML TT IntegrationDocument96 paginiOSX ML TT IntegrationSzalkai ZsoltÎncă nu există evaluări
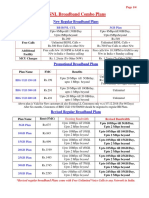
- BSNL All Plans - BB LL FTTH Mobile Aseem Wings Amazon CashbackDocument4 paginiBSNL All Plans - BB LL FTTH Mobile Aseem Wings Amazon Cashbackankushmangal83Încă nu există evaluări
- Amazon - Aws Certified Cloud Practitioner CLF C02.by .Umi .54qDocument21 paginiAmazon - Aws Certified Cloud Practitioner CLF C02.by .Umi .54qvanikaranam587Încă nu există evaluări
- BCS-052 byDocument63 paginiBCS-052 byAnish kumar DasÎncă nu există evaluări
- Thunder Adc: Next-Generation Application Delivery ControllerDocument8 paginiThunder Adc: Next-Generation Application Delivery Controllerrikrdo151Încă nu există evaluări
- Intro Juniper 2Document53 paginiIntro Juniper 2Phylipi Reis TorresÎncă nu există evaluări
- Coop ConsoleDocument120 paginiCoop ConsoleJuani RybeckyÎncă nu există evaluări
- IBM - NFS in AIXDocument334 paginiIBM - NFS in AIXapi-27351105Încă nu există evaluări
- Common Security Attacks and Their CountermeasuresDocument46 paginiCommon Security Attacks and Their Countermeasuresdellibabu50975% (4)
- NE20E-S Series Network Service Processors Data Sheet PDFDocument8 paginiNE20E-S Series Network Service Processors Data Sheet PDFFlávio AraújoÎncă nu există evaluări
- SSL and Millicent ProtocolsDocument15 paginiSSL and Millicent ProtocolsSoorya ColorblindÎncă nu există evaluări
- OSI Reference ModelDocument6 paginiOSI Reference ModelPratimaÎncă nu există evaluări
- Computer Hacking: Hacker: A Person Who Uses Computers To Gain Unauthorized Access ToDocument5 paginiComputer Hacking: Hacker: A Person Who Uses Computers To Gain Unauthorized Access ToEba GobenaÎncă nu există evaluări
- Gacc - Bca507 - Unit 4 NotesDocument20 paginiGacc - Bca507 - Unit 4 NotesAkashÎncă nu există evaluări
- Wifi Integration Into Mobile Broadband Toni Tjarhandy Cisco SystemsDocument40 paginiWifi Integration Into Mobile Broadband Toni Tjarhandy Cisco SystemsFAVE ONEÎncă nu există evaluări
- Huawei HG553Document2 paginiHuawei HG553One Transistor100% (2)
- Vital NetDocument4 paginiVital NetObi ChineduÎncă nu există evaluări
- Product Ci853 ComliDocument3 paginiProduct Ci853 Comlihoangtien1991Încă nu există evaluări
- TL R480T (UN) 9.0 DatasheetDocument4 paginiTL R480T (UN) 9.0 Datasheetaguinaldo alvesÎncă nu există evaluări
- Yukon IMS IED Management Software BrochureDocument8 paginiYukon IMS IED Management Software BrochureKislan MislaÎncă nu există evaluări
- Azure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsDe la EverandAzure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsÎncă nu există evaluări
- iPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]De la EverandiPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]Evaluare: 5 din 5 stele5/5 (2)
- RHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionDe la EverandRHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionÎncă nu există evaluări
- Kali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionDe la EverandKali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionEvaluare: 5 din 5 stele5/5 (1)
- iPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsDe la EverandiPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsEvaluare: 5 din 5 stele5/5 (2)