S-ar putea să vă placă și
- Attitude of Secondary School Students of Ballia District Towards Online LearningDocument4 paginiAttitude of Secondary School Students of Ballia District Towards Online LearningAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Summer Training ReportDocument77 paginiSummer Training ReportAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Baba Caterers: To, The Coordinator Refreshment Committee Institute Day Celebration Institute of Science, BHU, VaranasiDocument4 paginiBaba Caterers: To, The Coordinator Refreshment Committee Institute Day Celebration Institute of Science, BHU, VaranasiAnonymous V9E1ZJtwoEÎncă nu există evaluări
- DK'KH Fgunw Fo'Ofo - Ky : Lire Izxfr IzfrosnuDocument9 paginiDK'KH Fgunw Fo'Ofo - Ky : Lire Izxfr IzfrosnuAnonymous V9E1ZJtwoEÎncă nu există evaluări
- DLWDocument83 paginiDLWAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Housing Finance Services in Kerala: A Study of HDFC and LICDocument1 paginăHousing Finance Services in Kerala: A Study of HDFC and LICAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Usiky Ls ÇDKF'KR Usikyh HKK"KK Ds Çeq (K Nsfud Lekpkj I Ksa DK Vè UDocument2 paginiUsiky Ls ÇDKF'KR Usikyh HKK"KK Ds Çeq (K Nsfud Lekpkj I Ksa DK Vè UAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Summer InternshipDocument4 paginiSummer InternshipAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Project Report On Online Examination System: Submitted To Submitted By: Pooja Yadav Pinky Singh Bca Vi SemDocument2 paginiProject Report On Online Examination System: Submitted To Submitted By: Pooja Yadav Pinky Singh Bca Vi SemAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Acknowledgement DMPGDocument1 paginăAcknowledgement DMPGAnonymous V9E1ZJtwoEÎncă nu există evaluări
- DLWDocument83 paginiDLWAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Shri Baldev P.G. College - Varanasi: Project On NutritonDocument1 paginăShri Baldev P.G. College - Varanasi: Project On NutritonAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Investors PerceptionsDocument65 paginiInvestors PerceptionsAnonymous V9E1ZJtwoEÎncă nu există evaluări
- 1.1 Gaunyle: The Good Will Project Jan.23,2017)Document40 pagini1.1 Gaunyle: The Good Will Project Jan.23,2017)Anonymous V9E1ZJtwoEÎncă nu există evaluări
- A Study of The Prospective Teachers' Attitude Towaeds 1 Semester Theory Papers of Two Year B.Ed. Programme of Banaras Hindu UniversityDocument7 paginiA Study of The Prospective Teachers' Attitude Towaeds 1 Semester Theory Papers of Two Year B.Ed. Programme of Banaras Hindu UniversityAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Er BankingDocument1 paginăEr BankingAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Working Capital ProjectDocument64 paginiWorking Capital Projectbhawna sonaikar81% (21)
- OC-77 Selection LetterDocument4 paginiOC-77 Selection LetterAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Ananya DissertationDocument33 paginiAnanya DissertationAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Patanjali's growth and PESTLE analysisDocument87 paginiPatanjali's growth and PESTLE analysisAnonymous V9E1ZJtwoE80% (20)
- University of HyderabadDocument1 paginăUniversity of HyderabadAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Summer Training at Coca-ColaDocument5 paginiSummer Training at Coca-ColaAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Prashant DubeyDocument106 paginiPrashant DubeyAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Invoice: Address: Phone: Fax EmailDocument2 paginiInvoice: Address: Phone: Fax EmailAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Resume Anita KumariDocument2 paginiResume Anita KumariAnonymous V9E1ZJtwoEÎncă nu există evaluări
- ZeerasDocument96 paginiZeerasAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Combined Defence Services Examination (II) 2016 11636836879 सं यु d땜 र行⊭ा से वा परी行⊭ा (II) 2016Document1 paginăCombined Defence Services Examination (II) 2016 11636836879 सं यु d땜 र行⊭ा से वा परी行⊭ा (II) 2016Anonymous V9E1ZJtwoEÎncă nu există evaluări
- Ph.D. Thesisi ReportDocument3 paginiPh.D. Thesisi ReportAnonymous V9E1ZJtwoEÎncă nu există evaluări
- Combined Defence Services Examination (II) 2016 11636836879 सं यु d땜 र行⊭ा से वा परी行⊭ा (II) 2016Document1 paginăCombined Defence Services Examination (II) 2016 11636836879 सं यु d땜 र行⊭ा से वा परी行⊭ा (II) 2016Anonymous V9E1ZJtwoEÎncă nu există evaluări
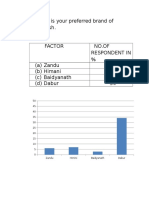
- Q1 What Is Your Preferred Brand of ChawanprashDocument12 paginiQ1 What Is Your Preferred Brand of ChawanprashAnonymous V9E1ZJtwoEÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5782)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (72)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Aguinaldo A Narrative of Filipino AmbitionsDocument428 paginiAguinaldo A Narrative of Filipino AmbitionsalegnaavlisÎncă nu există evaluări
- Famous Movie Quotes Activity TitleDocument8 paginiFamous Movie Quotes Activity TitleIris DariaÎncă nu există evaluări
- Dependent PrepositionsDocument1 paginăDependent PrepositionsAbel HernándezÎncă nu există evaluări
- Ngữ Pháp Tiếng Anh Lớp 8Document14 paginiNgữ Pháp Tiếng Anh Lớp 8Nguyễn Chiến ThắngÎncă nu există evaluări
- Abjad Numerals PDFDocument5 paginiAbjad Numerals PDFrashaxÎncă nu există evaluări
- Complete The Table With The Correct Form of The Verb in The Past Simple (Regular)Document2 paginiComplete The Table With The Correct Form of The Verb in The Past Simple (Regular)João FernandesÎncă nu există evaluări
- Lesson Plan in PoetryDocument5 paginiLesson Plan in PoetryCostales Fea Franzielle C.Încă nu există evaluări
- LANGUAGE of CW Figures of SpeechDocument41 paginiLANGUAGE of CW Figures of Speechkhryslerbongbonga30Încă nu există evaluări
- Understanding Polysemy Through Diachronic and Synchronic ApproachesDocument13 paginiUnderstanding Polysemy Through Diachronic and Synchronic ApproachesВалерия ЛитвиноваÎncă nu există evaluări
- Ingles Nivel 1Document58 paginiIngles Nivel 1Alejandra Verónica Mac garryÎncă nu există evaluări
- Pactborn An Original Race For D&D 5eDocument4 paginiPactborn An Original Race For D&D 5eTelentis Z100% (5)
- Communicating EmotionsDocument44 paginiCommunicating EmotionsEnglish TimeÎncă nu există evaluări
- The Syllabus with Skills for Nature ObservationDocument57 paginiThe Syllabus with Skills for Nature ObservationBushra KashifÎncă nu există evaluări
- Translation StudiesDocument10 paginiTranslation StudiescybombÎncă nu există evaluări
- Daily Lesson Plan MTB 01Document3 paginiDaily Lesson Plan MTB 01CarlaGomez100% (5)
- Verbal Hygiene by D CameronDocument2 paginiVerbal Hygiene by D CameronNandini1008Încă nu există evaluări
- Mental Faculty, Organ or InstinctDocument1 paginăMental Faculty, Organ or InstincthyderalikhawajaÎncă nu există evaluări
- Lesson Plan For Winter Lullaby 2Document3 paginiLesson Plan For Winter Lullaby 2api-385806603Încă nu există evaluări
- Edu521 Declaration of Independence Lesson PlanDocument5 paginiEdu521 Declaration of Independence Lesson Planapi-276463808Încă nu există evaluări
- Reported Speech IBP!Document30 paginiReported Speech IBP!Élite NtambweÎncă nu există evaluări
- Why programming is crucial in our generationDocument2 paginiWhy programming is crucial in our generationAya CorralÎncă nu există evaluări
- SLM-Malayala Sahithyam-III-2017 Admn-Corrected On 02.11.2018 PDFDocument71 paginiSLM-Malayala Sahithyam-III-2017 Admn-Corrected On 02.11.2018 PDFYobabyÎncă nu există evaluări
- Causatives: Using "Have" and "GetDocument3 paginiCausatives: Using "Have" and "GetJesus PonceÎncă nu există evaluări
- English Language 1123 GCE O Level For Examination in 2008Document6 paginiEnglish Language 1123 GCE O Level For Examination in 2008mstudy123456Încă nu există evaluări
- OOP Concept NotesDocument6 paginiOOP Concept NotesYou Are Not Wasting TIME Here100% (2)
- Ms 95-2018 Solved AssignmentDocument15 paginiMs 95-2018 Solved AssignmentPramod ShawÎncă nu există evaluări
- The British Isles DiscoveryDocument97 paginiThe British Isles DiscoveryMint Abdallahi50% (2)
- 2019 Anaconda Buyers GuideDocument11 pagini2019 Anaconda Buyers GuidebgpexpertÎncă nu există evaluări
- Creatures - Storm Lord's Wrath - Sources - D&D Beyond PDFDocument13 paginiCreatures - Storm Lord's Wrath - Sources - D&D Beyond PDFFrancisco Cabral BarbosaÎncă nu există evaluări
- Etruscan CivilizationDocument11 paginiEtruscan CivilizationDimitris KakarotÎncă nu există evaluări