S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Tai Chi Code - Martial Arts Ebook by Chris DavisDocument190 paginiThe Tai Chi Code - Martial Arts Ebook by Chris DavisTomas De Wael100% (2)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- ABCD Vocal Technique Handout PDFDocument9 paginiABCD Vocal Technique Handout PDFRanieque RamosÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Cancer ResearchDocument8 paginiCancer Researchmibs2009Încă nu există evaluări
- Duels and DuetsDocument253 paginiDuels and DuetsM Xenia0% (1)
- Staar Eoc 2016test Bio F 7Document39 paginiStaar Eoc 2016test Bio F 7api-293216402Încă nu există evaluări
- MoPSE Science Module Volume 1 - FINAL4WEBDocument336 paginiMoPSE Science Module Volume 1 - FINAL4WEBSibusiso Ntomby NkalaÎncă nu există evaluări
- 1st Summative Exam in General Biology 2Document1 pagină1st Summative Exam in General Biology 2Eula Pacifico100% (1)
- Chest TubesDocument34 paginiChest TubesMuhd ShafiqÎncă nu există evaluări
- Online Book Store: 1) Usecase DiagramDocument5 paginiOnline Book Store: 1) Usecase Diagramcharu73Încă nu există evaluări
- Dna Computing Final PartDocument6 paginiDna Computing Final Partcharu73Încă nu există evaluări
- Linux CommandsDocument12 paginiLinux Commandscharu73Încă nu există evaluări
- DNA Computing Introductory SeminarDocument21 paginiDNA Computing Introductory Seminarcharu73Încă nu există evaluări
- Ping 2Document15 paginiPing 2charu73Încă nu există evaluări
- Ping 2Document15 paginiPing 2charu73Încă nu există evaluări
- UserDocument2 paginiUsercharu73Încă nu există evaluări
- SteganographyDocument10 paginiSteganographycharu73Încă nu există evaluări
- Dna ComputingDocument1 paginăDna Computingcharu73Încă nu există evaluări
- Entrepreneurship DevelopmentDocument3 paginiEntrepreneurship Developmentcharu73Încă nu există evaluări
- Principles of Management - POMDocument2 paginiPrinciples of Management - POMcharu730% (2)
- The Differences Between HubsDocument10 paginiThe Differences Between Hubscharu73Încă nu există evaluări
- Research MethodologyDocument8 paginiResearch Methodologycharu73Încă nu există evaluări
- MBA Semester-II: CC 207 - Research Methodology and Operations Research (RM & OR)Document3 paginiMBA Semester-II: CC 207 - Research Methodology and Operations Research (RM & OR)charu73Încă nu există evaluări
- Iris RecognitionDocument1 paginăIris Recognitioncharu73Încă nu există evaluări
- Syllabus H3Document3 paginiSyllabus H3charu73Încă nu există evaluări
- India's Information Technology Act, 2000Document2 paginiIndia's Information Technology Act, 2000Rajneesh BarapatreÎncă nu există evaluări
- B.E. Electronics & Communication Second Year-Semester-IIIDocument8 paginiB.E. Electronics & Communication Second Year-Semester-IIIcharu73Încă nu există evaluări
- 3 - Plasma Membrane and Transport MechanismsDocument67 pagini3 - Plasma Membrane and Transport MechanismsThom PaglinawanÎncă nu există evaluări
- Artikel SkripsiDocument12 paginiArtikel SkripsiSari RofiqohÎncă nu există evaluări
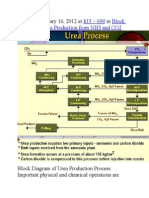
- Published January 16, 2012 at In: 813 × 699 Block Diagram of Urea Production From NH3 and CO2Document9 paginiPublished January 16, 2012 at In: 813 × 699 Block Diagram of Urea Production From NH3 and CO2himanshuchawla654Încă nu există evaluări
- MSDS Ecaro-25Document10 paginiMSDS Ecaro-25ValenteÎncă nu există evaluări
- BIOL 3121 - Lecture 13 - 081116Document91 paginiBIOL 3121 - Lecture 13 - 081116Sara HuebnerÎncă nu există evaluări
- Red Data Book of European Butterflies (Rhopalocera) : Nature and Environment, No. 99Document259 paginiRed Data Book of European Butterflies (Rhopalocera) : Nature and Environment, No. 99TheencyclopediaÎncă nu există evaluări
- Cell Cycle BrainstormingDocument3 paginiCell Cycle BrainstormingKimberley MendozaÎncă nu există evaluări
- TGD FrameworkDocument10 paginiTGD FrameworkMatthew KleeÎncă nu există evaluări
- Social IntelligenceDocument10 paginiSocial IntelligencePeterMarquezÎncă nu există evaluări
- Contoh Arsitektur SimbioisisDocument12 paginiContoh Arsitektur SimbioisisDeni AtahillahÎncă nu există evaluări
- Gen. Zoo. Final ReviewerDocument34 paginiGen. Zoo. Final ReviewerAshley FranciscoÎncă nu există evaluări
- Prelim QuizDocument3 paginiPrelim QuizXyriel MacoyÎncă nu există evaluări
- Can The Unconscious Mind Be Persuaded? An Overview With Marketing ImplicationsDocument9 paginiCan The Unconscious Mind Be Persuaded? An Overview With Marketing ImplicationsAhmed El-ShafeiÎncă nu există evaluări
- Alvin MDocument2 paginiAlvin MRunmel Emmanuel Ramal DampiosÎncă nu există evaluări
- The Differences Between Asexual and Sexual ReproductionDocument2 paginiThe Differences Between Asexual and Sexual ReproductionAmirul IkhwanÎncă nu există evaluări
- CeropegiarevisionDocument116 paginiCeropegiarevisionVirgi CortésÎncă nu există evaluări
- Science of The Total Environment: Megan Carve Graeme Allinson, Dayanthi Nugegoda, Jeff ShimetaDocument16 paginiScience of The Total Environment: Megan Carve Graeme Allinson, Dayanthi Nugegoda, Jeff ShimetaFABIANA PASSAMANIÎncă nu există evaluări
- Trabalho em Saúde e A Implantação Do Acolhimento Na Atenção Primária À Saúde - Afeto, Empatia Ou AlteridadeDocument13 paginiTrabalho em Saúde e A Implantação Do Acolhimento Na Atenção Primária À Saúde - Afeto, Empatia Ou AlteridadeAmérico PastorÎncă nu există evaluări
- PDFDocument570 paginiPDFEshaal FatimaÎncă nu există evaluări
- A Double-Strain TM (gp45) Polypeptide Antigen and Its Application in The Serodiadnosis of Equine Infectius AnemiaDocument8 paginiA Double-Strain TM (gp45) Polypeptide Antigen and Its Application in The Serodiadnosis of Equine Infectius AnemiaFredy MoralesÎncă nu există evaluări
- Ch8 (C)Document28 paginiCh8 (C)fkjujÎncă nu există evaluări
- 0 AlignMeDocument6 pagini0 AlignMeCRISTIAN GABRIEL ZAMBRANO VEGAÎncă nu există evaluări