S-ar putea să vă placă și
- Popular Article Wireless Sensor Network ConceptsDocument6 paginiPopular Article Wireless Sensor Network Conceptsgourav damorÎncă nu există evaluări
- Coolspots: Reducing The Power Consumption Of: Wireless Mobile Devices With Multiple Radio InterfacesDocument13 paginiCoolspots: Reducing The Power Consumption Of: Wireless Mobile Devices With Multiple Radio Interfacesaimen_riyadhÎncă nu există evaluări
- MOTES - Low Power Wireless Sensor NetworkDocument26 paginiMOTES - Low Power Wireless Sensor NetworkVinay MohanÎncă nu există evaluări
- Manet Unit4 Unit5Document71 paginiManet Unit4 Unit5Bot IdÎncă nu există evaluări
- Communication InfrastructureDocument8 paginiCommunication InfrastructureSrinivasan PÎncă nu există evaluări
- Advances in Analog and RF IC Design for Wireless Communication SystemsDe la EverandAdvances in Analog and RF IC Design for Wireless Communication SystemsGabriele ManganaroEvaluare: 1 din 5 stele1/5 (1)
- A Comparison, Opportunities and Challenges of Wireless Communication Technologies For Smart Grid ApplicationsDocument7 paginiA Comparison, Opportunities and Challenges of Wireless Communication Technologies For Smart Grid Applicationssaiful7271Încă nu există evaluări
- Sensor ND 5GDocument7 paginiSensor ND 5GMaleeha SabirÎncă nu există evaluări
- Introduction To Wireless TechnologyDocument26 paginiIntroduction To Wireless TechnologyRatnesh KhainwarÎncă nu există evaluări
- Unit 1Document27 paginiUnit 1Vishal Kumar 1902712Încă nu există evaluări
- Wireless NetworkDocument28 paginiWireless NetworkVikash PradhanÎncă nu există evaluări
- Information Technology: Project Report On NetworkingDocument11 paginiInformation Technology: Project Report On NetworkingArjun VashishtaÎncă nu există evaluări
- INTRODUCTIONDocument7 paginiINTRODUCTIONMazen NabeelÎncă nu există evaluări
- Management Development Program On Network Administration SkillsDocument43 paginiManagement Development Program On Network Administration SkillsJelamDavdaÎncă nu există evaluări
- Wired Equivalent Privacy Algorithm: 10CE100 Wireless LANDocument16 paginiWired Equivalent Privacy Algorithm: 10CE100 Wireless LANJanki ShahÎncă nu există evaluări
- Bagaimana LAN BerfungsiDocument5 paginiBagaimana LAN BerfungsiZarina Abdul RahimÎncă nu există evaluări
- QORIQQONVERGEWPDocument23 paginiQORIQQONVERGEWPlilian novarianÎncă nu există evaluări
- Intro. To Networking & Network DevicesDocument33 paginiIntro. To Networking & Network DevicesAyodeleÎncă nu există evaluări
- Modern Trends in Power ElectronicsDocument15 paginiModern Trends in Power ElectronicsSrini VasuluÎncă nu există evaluări
- Internet TCP Ip AntivirusDocument12 paginiInternet TCP Ip AntivirusNirinjan MuddadaÎncă nu există evaluări
- Protocols For Self-Organization of A Wireless Sensor NetworkDocument24 paginiProtocols For Self-Organization of A Wireless Sensor NetworkMukesh KumarÎncă nu există evaluări
- Block-3 MS-54 Unit-1Document21 paginiBlock-3 MS-54 Unit-1Mayur ChandanÎncă nu există evaluări
- Radio Resource Management in Multi-Tier Cellular Wireless NetworksDe la EverandRadio Resource Management in Multi-Tier Cellular Wireless NetworksÎncă nu există evaluări
- Module III UploadDocument13 paginiModule III UploadssvalliÎncă nu există evaluări
- The Role of Street Furniture in Expanding Mobile BroadbandDocument16 paginiThe Role of Street Furniture in Expanding Mobile BroadbandNaveed KhanÎncă nu există evaluări
- CN Chapter1Document22 paginiCN Chapter1nishitha.eeeÎncă nu există evaluări
- OSI Model (PDFDrive)Document111 paginiOSI Model (PDFDrive)FatimaÎncă nu există evaluări
- Benefits of Wireless TechnologyDocument11 paginiBenefits of Wireless TechnologyAdemola AdesiyiÎncă nu există evaluări
- Cired 2019Document5 paginiCired 2019Ajith SÎncă nu există evaluări
- Dc104 ReportDocument20 paginiDc104 Reportloyda.sitchonÎncă nu există evaluări
- Energy and Congestion-Aware Routing Metric For Smart Grid AMI Networks in Smart CityDocument12 paginiEnergy and Congestion-Aware Routing Metric For Smart Grid AMI Networks in Smart CitydikyÎncă nu există evaluări
- EmbeddedDocument10 paginiEmbeddedAthiramsÎncă nu există evaluări
- Energy-Efficient Communication Protocol For Wireless Microsensor NetworksDocument10 paginiEnergy-Efficient Communication Protocol For Wireless Microsensor NetworksFarooqÎncă nu există evaluări
- Zigbee FinalDocument29 paginiZigbee FinalcvmgreatÎncă nu există evaluări
- Chapter-1: Dept of Ece, MistDocument45 paginiChapter-1: Dept of Ece, MistRajesh Kumar ChituproluÎncă nu există evaluări
- Wireless Communications in Mobile ComputingDocument12 paginiWireless Communications in Mobile Computingapi-19799369Încă nu există evaluări
- Unit-1 Mobile CommunicationsDocument31 paginiUnit-1 Mobile CommunicationsKanteti Sai KrishnaÎncă nu există evaluări
- IJTIR Article 201504011Document10 paginiIJTIR Article 201504011Sanjana DeshmukhÎncă nu există evaluări
- InternetNotes PDFDocument11 paginiInternetNotes PDFSungram SinghÎncă nu există evaluări
- A Study of Communication Protocols For Internet of Things (Iot) Devices: ReviewDocument7 paginiA Study of Communication Protocols For Internet of Things (Iot) Devices: ReviewutpolaÎncă nu există evaluări
- Mobile Computing Unit 2Document158 paginiMobile Computing Unit 2Sabhya SharmaÎncă nu există evaluări
- Wireless Network: Types of Wireless NetworksDocument5 paginiWireless Network: Types of Wireless Networks9466524546Încă nu există evaluări
- System Architecture Challenges in The Home M2M Network: Michael Starsinic, Member IEEEDocument7 paginiSystem Architecture Challenges in The Home M2M Network: Michael Starsinic, Member IEEEVinod TheteÎncă nu există evaluări
- Module 1: Introduction To NetworkingDocument12 paginiModule 1: Introduction To NetworkingKihxan Poi Alonzo PaduaÎncă nu există evaluări
- 1.asses of Comm TechDocument6 pagini1.asses of Comm TechSiddharth Jain 16BEE0276Încă nu există evaluări
- Matrix Based Energy Efficient Routing in Static Wireless Sensor NetworksDocument9 paginiMatrix Based Energy Efficient Routing in Static Wireless Sensor NetworksInternational Journal of Sensor & Related NetworksÎncă nu există evaluări
- NetworkingDocument11 paginiNetworkingHafiz Abdul GhaffarÎncă nu există evaluări
- MODULE 2 - Networking FundamentalsDocument4 paginiMODULE 2 - Networking Fundamentalsjohn doeÎncă nu există evaluări
- Activity 1 1. What Is Computer Networks?Document9 paginiActivity 1 1. What Is Computer Networks?Katrina Mae VillalunaÎncă nu există evaluări
- Computer Network: "Computer Networks" Redirects Here. For The Periodical, SeeDocument11 paginiComputer Network: "Computer Networks" Redirects Here. For The Periodical, Seeabhijeetmorey87Încă nu există evaluări
- Chapter OneDocument118 paginiChapter Onetaha azadÎncă nu există evaluări
- Basics Mesh NetworksDocument6 paginiBasics Mesh NetworksPrasad KaleÎncă nu există evaluări
- 1.1bluetooth:: Department of ECE, SRETDocument26 pagini1.1bluetooth:: Department of ECE, SRETSandeep DangÎncă nu există evaluări
- Efficient Power Consumption Wireless Communication Techniques/Modules For Internet of Things (Iot) ApplicationsDocument22 paginiEfficient Power Consumption Wireless Communication Techniques/Modules For Internet of Things (Iot) Applicationsfadil3m2422Încă nu există evaluări
- Chapter 3Document25 paginiChapter 3haileÎncă nu există evaluări
- IOSR JournalsDocument8 paginiIOSR JournalsInternational Organization of Scientific Research (IOSR)Încă nu există evaluări
- UNIT 3 Notes For Students - 2Document49 paginiUNIT 3 Notes For Students - 2deepesh_gaonkarÎncă nu există evaluări
- The Challenges of Mobile ComputingDocument10 paginiThe Challenges of Mobile ComputingSthephane CorreaÎncă nu există evaluări
- Wireless Networks:: Term Paper For CS395T Network Performance, Fall 1997Document19 paginiWireless Networks:: Term Paper For CS395T Network Performance, Fall 1997poornima24Încă nu există evaluări
- Issues and ChallengesDocument3 paginiIssues and Challengesnanogowtham5358Încă nu există evaluări
- CFP IJCTA Emerging Tech Comp ParadDocument1 paginăCFP IJCTA Emerging Tech Comp ParadJ0SUJ0SUÎncă nu există evaluări
- General Psychology Dedicated To Positive Psychology, Where The EditorsDocument4 paginiGeneral Psychology Dedicated To Positive Psychology, Where The EditorsJ0SUJ0SUÎncă nu există evaluări
- Mindfulness Acceptance9Document6 paginiMindfulness Acceptance9J0SUJ0SUÎncă nu există evaluări
- What Is Acceptance and Commitment Therapy?Document4 paginiWhat Is Acceptance and Commitment Therapy?J0SUJ0SUÎncă nu există evaluări
- The Foundations of Flourishing: Joseph CiarrochiDocument4 paginiThe Foundations of Flourishing: Joseph CiarrochiJ0SUJ0SUÎncă nu există evaluări
- Springer - Swarm Intelligence - Instructions For AuthorsDocument10 paginiSpringer - Swarm Intelligence - Instructions For AuthorsJ0SUJ0SUÎncă nu există evaluări
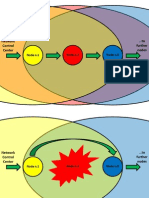
- Network Control Center To Further Nodes: Node n.1 Node n.2 Node n.3Document3 paginiNetwork Control Center To Further Nodes: Node n.1 Node n.2 Node n.3J0SUJ0SUÎncă nu există evaluări
- AUX Magazine 201206-07Document100 paginiAUX Magazine 201206-07J0SUJ0SUÎncă nu există evaluări
- Introduction To Compication in ComputingDocument67 paginiIntroduction To Compication in ComputingBipin BhandariÎncă nu există evaluări
- Contoh Preventive MaintenanceDocument35 paginiContoh Preventive MaintenanceAimanullahÎncă nu există evaluări
- RTOS - RT Linux Porting On S3Cmini2440 ARM9 Board: Ravindra Prasad Bonthu and Subrahmanyam Venkata VeeraghantaDocument4 paginiRTOS - RT Linux Porting On S3Cmini2440 ARM9 Board: Ravindra Prasad Bonthu and Subrahmanyam Venkata VeeraghantaIJERDÎncă nu există evaluări
- Abi WordDocument2 paginiAbi WordEdward SnowdenÎncă nu există evaluări
- Ci 16scs11 AosDocument3 paginiCi 16scs11 Aosinnovatorinnovator0% (1)
- Sun STK 6140 Getting Started Guide Install Config Release 2.0 819-5045-11Document204 paginiSun STK 6140 Getting Started Guide Install Config Release 2.0 819-5045-11alexou79Încă nu există evaluări
- Objective Computer Fundamental Bca FirstDocument11 paginiObjective Computer Fundamental Bca FirstSanjeev Kumar YadavÎncă nu există evaluări
- Razlike Izmedju Dos I Windows 7Document3 paginiRazlike Izmedju Dos I Windows 7Milkovic91Încă nu există evaluări
- Asignment 505 ZangbuDocument128 paginiAsignment 505 ZangbuManawÎncă nu există evaluări
- Iquento Gamified Story TellingDocument157 paginiIquento Gamified Story TellingMarsha SuperioÎncă nu există evaluări
- Embedded SystemsDocument2 paginiEmbedded SystemsGanesh GoturÎncă nu există evaluări
- Computer KnowledgeDocument75 paginiComputer KnowledgeDuggi SumanÎncă nu există evaluări
- Introduction To STELLADocument3 paginiIntroduction To STELLAHamzaÎncă nu există evaluări
- Fundamentals of Computer and Tally Important Questions-1: Part - ADocument3 paginiFundamentals of Computer and Tally Important Questions-1: Part - AShamim AkhterÎncă nu există evaluări
- Mobile MultimediaDocument13 paginiMobile MultimediaRodzainie MatimpanÎncă nu există evaluări
- National Institute of Open Schooling Senior Secondary Course: Data Entry Operations Lesson 1: Basics of Computer Worksheet - 1Document2 paginiNational Institute of Open Schooling Senior Secondary Course: Data Entry Operations Lesson 1: Basics of Computer Worksheet - 1Teena SudhirÎncă nu există evaluări
- JNTU Anantapur M.tech Syllabus For Embedded Systems 2009 10Document19 paginiJNTU Anantapur M.tech Syllabus For Embedded Systems 2009 10RajeshÎncă nu există evaluări
- BL460C Blade ServerDocument61 paginiBL460C Blade ServerImam MalikiÎncă nu există evaluări
- Are Va TrainingDocument620 paginiAre Va TrainingFLAMMMMME100% (4)
- FortiClient v4.0 MR3 Patch 3 Release NotesDocument11 paginiFortiClient v4.0 MR3 Patch 3 Release Notesjcjcjc1024Încă nu există evaluări
- Filetype PDF Computer System ArchitectureDocument2 paginiFiletype PDF Computer System ArchitectureTanyaÎncă nu există evaluări
- The Abstraction The ProcessDocument12 paginiThe Abstraction The ProcessMeghanaÎncă nu există evaluări
- The Linux System: Speaker: Bilal AhmadDocument39 paginiThe Linux System: Speaker: Bilal AhmadBilal A. SalimiÎncă nu există evaluări
- Complete Computer AcronymsDocument161 paginiComplete Computer Acronymsapi-19417993Încă nu există evaluări
- 1st Unit CDocument152 pagini1st Unit CJoshua ScottÎncă nu există evaluări
- CSX-Exam-Guide Bro Eng 1014Document13 paginiCSX-Exam-Guide Bro Eng 1014ellococarelocoÎncă nu există evaluări
- DSE 2 Unit 1 1Document21 paginiDSE 2 Unit 1 1kkant872002Încă nu există evaluări
- CreditLens™ System RequirementsDocument18 paginiCreditLens™ System RequirementsJoe MusÎncă nu există evaluări
- CS-101 Final Paper File New Update 2019 To 2020Document134 paginiCS-101 Final Paper File New Update 2019 To 2020Abdul RehmanÎncă nu există evaluări
- Exam Summary 2INC0Document5 paginiExam Summary 2INC0Niek RongenÎncă nu există evaluări