S-ar putea să vă placă și
- Data Classification For Cloud ReadinessDocument22 paginiData Classification For Cloud ReadinessHarkirat Singh50% (2)
- Security Trends in Retail OrganizationsDocument8 paginiSecurity Trends in Retail OrganizationsMSFTSIRÎncă nu există evaluări
- Microsoft Security Intelligence Report Volume 16Document152 paginiMicrosoft Security Intelligence Report Volume 16MSFTSIRÎncă nu există evaluări
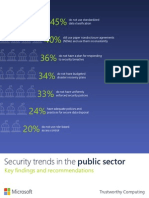
- Security Trends in The Public SectorDocument8 paginiSecurity Trends in The Public SectorMSFTSIRÎncă nu există evaluări
- Security Trends in HealthcareDocument8 paginiSecurity Trends in HealthcareMSFTSIRÎncă nu există evaluări
- Cybersecurity Risk ParadoxDocument12 paginiCybersecurity Risk ParadoxMSFTSIRÎncă nu există evaluări
- The Microsoft Approach To Compliance in The CloudDocument12 paginiThe Microsoft Approach To Compliance in The CloudMSFTSIRÎncă nu există evaluări
- Security Trends in Financial ServicesDocument8 paginiSecurity Trends in Financial ServicesMSFTSIRÎncă nu există evaluări
- CISO Perspectives Data ClassificationDocument5 paginiCISO Perspectives Data ClassificationMSFTSIRÎncă nu există evaluări
- Microsoft Security Response Center (MSRC) Progress Report 2013Document27 paginiMicrosoft Security Response Center (MSRC) Progress Report 2013MSFTSIRÎncă nu există evaluări
- Microsoft Security Intelligence Report Volume 15 Key Findings SummaryDocument24 paginiMicrosoft Security Intelligence Report Volume 15 Key Findings SummaryMSFTSIRÎncă nu există evaluări
- Microsoft Security Intelligence Report Volume 15Document160 paginiMicrosoft Security Intelligence Report Volume 15MSFTSIRÎncă nu există evaluări
- Five Principles For Shaping Cybersecurity NormsDocument12 paginiFive Principles For Shaping Cybersecurity NormsMSFTSIRÎncă nu există evaluări
- AppLocker Design GuideDocument82 paginiAppLocker Design GuideMSFTSIR100% (1)
- CISO Perspectives On ComplianceDocument4 paginiCISO Perspectives On ComplianceMSFTSIRÎncă nu există evaluări
- Developing A National Strategy For CybersecurityDocument24 paginiDeveloping A National Strategy For CybersecurityMSFTSIRÎncă nu există evaluări
- CISO Perspectives Today's RiskDocument4 paginiCISO Perspectives Today's RiskMSFTSIRÎncă nu există evaluări
- Mitigating Pass-The-Hash (PTH) Attacks and Other Credential Theft Techniques - EnglishDocument82 paginiMitigating Pass-The-Hash (PTH) Attacks and Other Credential Theft Techniques - EnglishMSFTSIRÎncă nu există evaluări
- Trends in Cloud Computing Cloud Security Readiness ToolDocument40 paginiTrends in Cloud Computing Cloud Security Readiness ToolChristian Paul Manalo TaburadaÎncă nu există evaluări
- Whitepaper: Evaluating Microsoft's Protection Performance and Capabilities Protection Performance and CapabilitiesDocument13 paginiWhitepaper: Evaluating Microsoft's Protection Performance and Capabilities Protection Performance and CapabilitiesMSFTSIRÎncă nu există evaluări
- Problem Management For Reliable Online Services PDFDocument16 paginiProblem Management For Reliable Online Services PDFsaad14014Încă nu există evaluări
- Resilience by Design For Cloud ServicesDocument19 paginiResilience by Design For Cloud ServicesMSFTSIRÎncă nu există evaluări
- Deploying Highly Available and Secure Cloud SolutionsDocument26 paginiDeploying Highly Available and Secure Cloud SolutionsMSFTSIRÎncă nu există evaluări
- Microsoft Security Intelligence Report Volume 14 EnglishDocument120 paginiMicrosoft Security Intelligence Report Volume 14 EnglishMSFTSIRÎncă nu există evaluări
- Microsoft Malware Protection Center Threat Report: RootkitsDocument16 paginiMicrosoft Malware Protection Center Threat Report: RootkitsMSFTSIRÎncă nu există evaluări
- Learn How Socio-Economic Factors Affect Regional Malware RatesDocument27 paginiLearn How Socio-Economic Factors Affect Regional Malware RatesMSFTSIRÎncă nu există evaluări
- Determined Adversaries and Targeted AttacksDocument22 paginiDetermined Adversaries and Targeted AttacksMSFTSIRÎncă nu există evaluări
- Microsoft Security Intelligence Report Volume 13 EnglishDocument146 paginiMicrosoft Security Intelligence Report Volume 13 EnglishNeagu JellyÎncă nu există evaluări
- MSRC Progress Report 2012Document33 paginiMSRC Progress Report 2012MSFTSIRÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- ANSI-IsA 77.13.01-1999 Fossil Fuel Power Plant Steam Turbine Bypass SystemDocument42 paginiANSI-IsA 77.13.01-1999 Fossil Fuel Power Plant Steam Turbine Bypass SystemArzu AkarÎncă nu există evaluări
- Air Sentry Guardian-BreathersDocument14 paginiAir Sentry Guardian-BreathersNelson PeraltaÎncă nu există evaluări
- Control your ship with Kobelt electronic controlsDocument36 paginiControl your ship with Kobelt electronic controlsBERANGER DAVESNE DJOMALIA SIEWEÎncă nu există evaluări
- 1 GPM V1 vacuum dehydrator removes water down to 20 PPMDocument3 pagini1 GPM V1 vacuum dehydrator removes water down to 20 PPMLuis100% (1)
- ATHENAEUMDocument4 paginiATHENAEUMShubhra PatraÎncă nu există evaluări
- Wacker Silres Ren - 60 - Silicone Resin Solution For Medium Solids or High Solids Heat ResistancDocument3 paginiWacker Silres Ren - 60 - Silicone Resin Solution For Medium Solids or High Solids Heat ResistancJameel AhsanÎncă nu există evaluări
- BHEL - PresentationDocument32 paginiBHEL - Presentationsenthil031277Încă nu există evaluări
- A967517734 - 24017 - 22 - 2018 - 10. Header Linked List (2 Files Merged) PDFDocument25 paginiA967517734 - 24017 - 22 - 2018 - 10. Header Linked List (2 Files Merged) PDFKiran KumarÎncă nu există evaluări
- Reduce Drum Pitch, Yarn Tension and Cradle LoadDocument16 paginiReduce Drum Pitch, Yarn Tension and Cradle LoadJigneshSaradavaÎncă nu există evaluări
- Reliability and Integrity Management 1Document37 paginiReliability and Integrity Management 1Giannos Kastanas100% (1)
- Sustainable Transport Development in Nepal: Challenges and StrategiesDocument18 paginiSustainable Transport Development in Nepal: Challenges and StrategiesRamesh PokharelÎncă nu există evaluări
- 02 - MEE10603 - Fourier Series and Power Computations in Nonsinusoidally Driven CircuitsDocument33 pagini02 - MEE10603 - Fourier Series and Power Computations in Nonsinusoidally Driven CircuitsMohammad HayazieÎncă nu există evaluări
- E 20925Document214 paginiE 20925Ahmed ElshowbkeyÎncă nu există evaluări
- Physics Exit 3q1718 .Document16 paginiPhysics Exit 3q1718 .Mikaella Tambis0% (1)
- Applications: H D P TDocument2 paginiApplications: H D P TEnrique MurgiaÎncă nu există evaluări
- Aerodrome Controller (ADC) ExamDocument5 paginiAerodrome Controller (ADC) ExamaxnpicturesÎncă nu există evaluări
- System ConfigurationDocument13 paginiSystem ConfigurationEdlyn Estopa BuenoÎncă nu există evaluări
- Lincoln FC ElectrodesDocument44 paginiLincoln FC ElectrodeszmcgainÎncă nu există evaluări
- Evaporation: (I) Vapour PressureDocument15 paginiEvaporation: (I) Vapour Pressurevenka07Încă nu există evaluări
- SGP PDFDocument4 paginiSGP PDFpadmajasivaÎncă nu există evaluări
- Vdo Pressure GuageDocument14 paginiVdo Pressure Guagezuma zaiamÎncă nu există evaluări
- Hitachi Sumitomo Scx1500 2 Hydraulic Crawler Crane SpecificationsDocument2 paginiHitachi Sumitomo Scx1500 2 Hydraulic Crawler Crane Specificationsmargeret100% (50)
- Electrical Power Transmission & DistributionDocument18 paginiElectrical Power Transmission & DistributionMd Saif KhanÎncă nu există evaluări
- WM 5.4 CLI Reference Guide PDFDocument1.239 paginiWM 5.4 CLI Reference Guide PDFHermes GuerreroÎncă nu există evaluări
- Microwave Engineering - E-H Plane TeeDocument6 paginiMicrowave Engineering - E-H Plane TeeJoker FÎncă nu există evaluări
- University Institute of Information Technology: Ouick Learn - MCQDocument53 paginiUniversity Institute of Information Technology: Ouick Learn - MCQvimalÎncă nu există evaluări
- Kinematics Horizontal KinematicsDocument5 paginiKinematics Horizontal KinematicsBaiJPÎncă nu există evaluări
- Nabll Mix DesignDocument29 paginiNabll Mix DesignPIDCL WITH SUBUDHIÎncă nu există evaluări
- Dunlop Cement Based Adhesives - SDS10024Document4 paginiDunlop Cement Based Adhesives - SDS10024Dominic LeeÎncă nu există evaluări