S-ar putea să vă placă și
- Bao Hua Liu, Nirupama Bulusu, Huan Pham, Sanjay Jha: Abstract - This Paper Proposes CSMAC (CDMA Sensor MAC)Document6 paginiBao Hua Liu, Nirupama Bulusu, Huan Pham, Sanjay Jha: Abstract - This Paper Proposes CSMAC (CDMA Sensor MAC)Bara' HouraniÎncă nu există evaluări
- A Survey On TDMA-based MAC Protocols For Wireless Sensor NetworkDocument12 paginiA Survey On TDMA-based MAC Protocols For Wireless Sensor NetworkkeliliÎncă nu există evaluări
- A Token Cycle Scheduling of MAC Protocols For TDMA Based Airborne Ad Hoc NetworkDocument5 paginiA Token Cycle Scheduling of MAC Protocols For TDMA Based Airborne Ad Hoc Network33221044Încă nu există evaluări
- A Q-Learning-Based Adaptive MAC Protocol For Internet of Things NetworksDocument14 paginiA Q-Learning-Based Adaptive MAC Protocol For Internet of Things Networkslijalem gezahagnÎncă nu există evaluări
- A Hybrid Medium Access Control ProtocolDocument18 paginiA Hybrid Medium Access Control ProtocolMohd ArshadÎncă nu există evaluări
- Computer Communications: Chun-Yu Lin, Chen-Lung Chan, Chung-Ta King, Huang-Chen LeeDocument15 paginiComputer Communications: Chun-Yu Lin, Chen-Lung Chan, Chung-Ta King, Huang-Chen LeeZaigham AbbasÎncă nu există evaluări
- A Survey On Mac Protocols For Wireless Multimedia Networks.Document18 paginiA Survey On Mac Protocols For Wireless Multimedia Networks.ijcsesÎncă nu există evaluări
- Smart Hybrid Frame Scheduling To Improve Energy Efficiency in Wireless Sensor NetworkDocument6 paginiSmart Hybrid Frame Scheduling To Improve Energy Efficiency in Wireless Sensor NetworkUbiquitous Computing and Communication JournalÎncă nu există evaluări
- A Hybrid MAC Protocol For Wireless Sensor Network: Minsheng Tan Liang TangDocument5 paginiA Hybrid MAC Protocol For Wireless Sensor Network: Minsheng Tan Liang TangZaineb AlaniÎncă nu există evaluări
- An Adaptive Energy-Efficient MAC Protocol For Wireless Sensor NetworksDocument10 paginiAn Adaptive Energy-Efficient MAC Protocol For Wireless Sensor NetworksscribÎncă nu există evaluări
- Design Energy Efficient SMAC Protocol For Wireless Sensor Networks Using Neighbour Discovery Scheduling AlgorithmDocument8 paginiDesign Energy Efficient SMAC Protocol For Wireless Sensor Networks Using Neighbour Discovery Scheduling AlgorithmEditor IJTSRDÎncă nu există evaluări
- Sensors 15 03911Document21 paginiSensors 15 03911Tiranran BakrieÎncă nu există evaluări
- Applying Time-Division Multiplexing in Star-Based Optical NetworksDocument4 paginiApplying Time-Division Multiplexing in Star-Based Optical NetworksJuliana CantilloÎncă nu există evaluări
- Introducing SOFT MAC: Ghassan M. Abdalla, Mosa Ali Abu-Rgheff and Sidi-Mohammed SenouciDocument10 paginiIntroducing SOFT MAC: Ghassan M. Abdalla, Mosa Ali Abu-Rgheff and Sidi-Mohammed SenouciUbiquitous Computing and Communication JournalÎncă nu există evaluări
- Routing ProtocolsDocument6 paginiRouting Protocolssmskdevil008Încă nu există evaluări
- The Energy-Efficient MDA-SMAC ProtocolDocument10 paginiThe Energy-Efficient MDA-SMAC ProtocolAbyot TegegneÎncă nu există evaluări
- Slotted Csma/ca Based Energy Efficient Mac Protocol Design in NanonetworksDocument12 paginiSlotted Csma/ca Based Energy Efficient Mac Protocol Design in NanonetworksJohn BergÎncă nu există evaluări
- Ridhaand Jawad 22 ADocument13 paginiRidhaand Jawad 22 ADr. Ghassan Nihad JawadÎncă nu există evaluări
- Optimizing Energy Efficiency in Wireless Sensor Network Using LEACH ProtocolDocument5 paginiOptimizing Energy Efficiency in Wireless Sensor Network Using LEACH ProtocolInternational Journal of Application or Innovation in Engineering & ManagementÎncă nu există evaluări
- Eneregy 1Document5 paginiEneregy 1ስቶፕ ጀኖሳይድÎncă nu există evaluări
- Research Article: A Scheduling Algorithm For Minimizing The Packet Error Probability in Clusterized TDMA NetworksDocument10 paginiResearch Article: A Scheduling Algorithm For Minimizing The Packet Error Probability in Clusterized TDMA Networkscypa11Încă nu există evaluări
- Congestion-Less Energy Aware Token Based MAC Protocol Integrated With Sleep Scheduling For Wireless Sensor NetworksDocument6 paginiCongestion-Less Energy Aware Token Based MAC Protocol Integrated With Sleep Scheduling For Wireless Sensor NetworksPintu KumarÎncă nu există evaluări
- A Survey On Medium Access Control in Wireless Sensor NetworksDocument8 paginiA Survey On Medium Access Control in Wireless Sensor NetworksInternational Journal of Engineering Inventions (IJEI)Încă nu există evaluări
- Abstract: Due To Significant Advances in Wireless Modulation Technologies, Some MAC Standards Such As 802.11aDocument6 paginiAbstract: Due To Significant Advances in Wireless Modulation Technologies, Some MAC Standards Such As 802.11aVidvek InfoTechÎncă nu există evaluări
- VJJVJVJDocument7 paginiVJJVJVJAnirudh KawÎncă nu există evaluări
- Energy Efficient Approach For Converss: Routing Protocol For Wireless NetworksDocument4 paginiEnergy Efficient Approach For Converss: Routing Protocol For Wireless Networkspiyushji125Încă nu există evaluări
- MAC Vs Routing Protocols in Mobile AdhocDocument3 paginiMAC Vs Routing Protocols in Mobile AdhocHassan ShahÎncă nu există evaluări
- Optical Netw 3ndDocument8 paginiOptical Netw 3ndAnbarasan RamamoorthyÎncă nu există evaluări
- Directional Mac With Deafness Solution For Ad Hoc NetworkDocument6 paginiDirectional Mac With Deafness Solution For Ad Hoc Networkashish chaturvediÎncă nu există evaluări
- E3db PDFDocument11 paginiE3db PDFmeenaÎncă nu există evaluări
- A Performance Comparison of Energy Efficient MAC Protocols For Wireless Sensor NetworksDocument12 paginiA Performance Comparison of Energy Efficient MAC Protocols For Wireless Sensor Networksabd01111Încă nu există evaluări
- Pervasive Communications Handbook 62Document1 paginăPervasive Communications Handbook 62JasmeetÎncă nu există evaluări
- Optimized Latency Secured (LS) MAC Protocols For Delay Sensitive Large Sensor NetworksDocument7 paginiOptimized Latency Secured (LS) MAC Protocols For Delay Sensitive Large Sensor NetworksShafayet UddinÎncă nu există evaluări
- Exploiting Directional Antennas To Provide Quality Service and Multipoint Delivery in Mobile Wireless NetworksDocument6 paginiExploiting Directional Antennas To Provide Quality Service and Multipoint Delivery in Mobile Wireless NetworksSatish NaiduÎncă nu există evaluări
- CS6003 ASN ConceptsDocument15 paginiCS6003 ASN ConceptsVijayaprabaÎncă nu există evaluări
- Joint Aggregation and MAC Design To Prolong Sensor Network Lifetime - ICNP 2013Document10 paginiJoint Aggregation and MAC Design To Prolong Sensor Network Lifetime - ICNP 2013NgocThanhDinhÎncă nu există evaluări
- Comparing Energy-Saving MAC Protocols For Wireless Sensor NetworksDocument9 paginiComparing Energy-Saving MAC Protocols For Wireless Sensor NetworksamgedÎncă nu există evaluări
- Performance of Vehicle-to-Vehicle Communication Using IEEE 802.11p in Vehicular Ad-Hoc Network EnvironmentDocument28 paginiPerformance of Vehicle-to-Vehicle Communication Using IEEE 802.11p in Vehicular Ad-Hoc Network EnvironmentSobhan DasariÎncă nu există evaluări
- A New MAC Protocol Design For Long-Term Applications in Wireless Sensor NetworksDocument8 paginiA New MAC Protocol Design For Long-Term Applications in Wireless Sensor NetworksRamalingÎncă nu există evaluări
- Adaptive Call Admission Control in Tdd-Cdma CellulDocument8 paginiAdaptive Call Admission Control in Tdd-Cdma CellulsocearesÎncă nu există evaluări
- Energy Efficient MAC Protocols For Wireless Sensor NetworkDocument8 paginiEnergy Efficient MAC Protocols For Wireless Sensor NetworkAnonymous lVQ83F8mCÎncă nu există evaluări
- Comparative Study of RMST and STCP Protocol For Qos Provisioning in WSNDocument6 paginiComparative Study of RMST and STCP Protocol For Qos Provisioning in WSNUbiquitous Computing and Communication JournalÎncă nu există evaluări
- 31 - JCIT - JUNE - Binder1-31Document8 pagini31 - JCIT - JUNE - Binder1-31Aditya WijayantoÎncă nu există evaluări
- 3.1 MAC ProtocolDocument48 pagini3.1 MAC ProtocolVENKATA SAI KRISHNA YAGANTIÎncă nu există evaluări
- P A I A P C Mac P (Iapcmp) Manet: Erformance Nalysis of Mproved Utonomous Ower Ontrol Rotocol FOR SDocument11 paginiP A I A P C Mac P (Iapcmp) Manet: Erformance Nalysis of Mproved Utonomous Ower Ontrol Rotocol FOR SijansjournalÎncă nu există evaluări
- Forwarder Set Based Dynamic Duty Cycling in Asynchronous Wireless Sensor NetworksDocument6 paginiForwarder Set Based Dynamic Duty Cycling in Asynchronous Wireless Sensor NetworksSıla Özen GüçlüÎncă nu există evaluări
- Constellation Shared Multiple Access - A Noma Scheme For Increased User Capacity in 5G MMTCDocument17 paginiConstellation Shared Multiple Access - A Noma Scheme For Increased User Capacity in 5G MMTCAIRCC - IJCNCÎncă nu există evaluări
- SCMA SatellitesDocument19 paginiSCMA SatellitesRedouane BelbachirÎncă nu există evaluări
- A Hybrid MAC Protocol For Multimedia Traffic in Wireless NetworksDocument6 paginiA Hybrid MAC Protocol For Multimedia Traffic in Wireless NetworksdavidantonyÎncă nu există evaluări
- Energy and Bandwidth Constrained Qos Enabled Routing For ManetsDocument11 paginiEnergy and Bandwidth Constrained Qos Enabled Routing For ManetsAIRCC - IJCNCÎncă nu există evaluări
- UbiCC 241 241Document12 paginiUbiCC 241 241Ubiquitous Computing and Communication JournalÎncă nu există evaluări
- Inter-Rat Handover Between Umts and WimaxDocument29 paginiInter-Rat Handover Between Umts and WimaxSatyabrata NayakÎncă nu există evaluări
- Contention Based ProtocolsDocument8 paginiContention Based ProtocolsKarna NiLa100% (1)
- Distributed CSMA/CA Algorithms For Achieving Maximum Throughput in Wireless NetworksDocument19 paginiDistributed CSMA/CA Algorithms For Achieving Maximum Throughput in Wireless NetworksMalatesh SudharshanÎncă nu există evaluări
- Final Year Project - (NS2-Networking-Network Security-MANET-VANET-WSN-AdHoc Network) IEEE 2016-17 Project ListDocument19 paginiFinal Year Project - (NS2-Networking-Network Security-MANET-VANET-WSN-AdHoc Network) IEEE 2016-17 Project ListSPECTRUM SOLUTIONSÎncă nu există evaluări
- A Review Paper Based On Various Mac Protocols For Wireless Sensor NetworksDocument6 paginiA Review Paper Based On Various Mac Protocols For Wireless Sensor NetworksK AkshayÎncă nu există evaluări
- A Hybrid Multi-Channel MAC Protocol With Virtual Mechanism and Power Control For Wireless Sensor NetworksDocument12 paginiA Hybrid Multi-Channel MAC Protocol With Virtual Mechanism and Power Control For Wireless Sensor NetworksUsman TariqÎncă nu există evaluări
- Evaluating of Capacities in TD-SCDMA Systems When Employing Smart Antenna and Multi-User Detection TechniquesDocument5 paginiEvaluating of Capacities in TD-SCDMA Systems When Employing Smart Antenna and Multi-User Detection TechniquesPraveen KamalakkanavarÎncă nu există evaluări
- Common So On One Recent To Resonant Some MeasurementsDocument4 paginiCommon So On One Recent To Resonant Some MeasurementsSenthilkumarÎncă nu există evaluări
- Rectangular Microstrips With Variable Air Gap and Varying Aspect Ratio: Improved Formulations and ExperimentsDocument5 paginiRectangular Microstrips With Variable Air Gap and Varying Aspect Ratio: Improved Formulations and ExperimentsSenthilkumar100% (1)
- A Cross-Layer Framework For Overhead Reduction, Traffic Scheduling, and Burst Allocation in IEEE 802.16 OFDMA NetworksDocument16 paginiA Cross-Layer Framework For Overhead Reduction, Traffic Scheduling, and Burst Allocation in IEEE 802.16 OFDMA NetworksSenthilkumarÎncă nu există evaluări
- A Novel Electromagnetic Bandgap Structure For SSN Suppression in PWR/GND Plane PairsDocument6 paginiA Novel Electromagnetic Bandgap Structure For SSN Suppression in PWR/GND Plane PairsSenthilkumarÎncă nu există evaluări
- 05 x05 Standard Costing & Variance AnalysisDocument27 pagini05 x05 Standard Costing & Variance AnalysisMary April MasbangÎncă nu există evaluări
- Dalasa Jibat MijenaDocument24 paginiDalasa Jibat MijenaBelex ManÎncă nu există evaluări
- 1.technical Specifications (Piling)Document15 pagini1.technical Specifications (Piling)Kunal Panchal100% (2)
- 5c3f1a8b262ec7a Ek PDFDocument5 pagini5c3f1a8b262ec7a Ek PDFIsmet HizyoluÎncă nu există evaluări
- Obesity - The Health Time Bomb: ©LTPHN 2008Document36 paginiObesity - The Health Time Bomb: ©LTPHN 2008EVA PUTRANTO100% (2)
- Azimuth Steueung - EngDocument13 paginiAzimuth Steueung - EnglacothÎncă nu există evaluări
- Talking Art As The Spirit Moves UsDocument7 paginiTalking Art As The Spirit Moves UsUCLA_SPARCÎncă nu există evaluări
- Quick Help For EDI SEZ IntegrationDocument2 paginiQuick Help For EDI SEZ IntegrationsrinivasÎncă nu există evaluări
- Chapter13 PDFDocument34 paginiChapter13 PDFAnastasia BulavinovÎncă nu există evaluări
- GT-N7100-Full Schematic PDFDocument67 paginiGT-N7100-Full Schematic PDFprncha86% (7)
- Report On GDP of Top 6 Countries.: Submitted To: Prof. Sunil MadanDocument5 paginiReport On GDP of Top 6 Countries.: Submitted To: Prof. Sunil MadanAbdullah JamalÎncă nu există evaluări
- 04 - Fetch Decode Execute Cycle PDFDocument3 pagini04 - Fetch Decode Execute Cycle PDFShaun HaxaelÎncă nu există evaluări
- Richardson Heidegger PDFDocument18 paginiRichardson Heidegger PDFweltfremdheitÎncă nu există evaluări
- IEC ShipsDocument6 paginiIEC ShipsdimitaringÎncă nu există evaluări
- B.SC BOTANY Semester 5-6 Syllabus June 2013Document33 paginiB.SC BOTANY Semester 5-6 Syllabus June 2013Barnali DuttaÎncă nu există evaluări
- Radiation Safety Densitometer Baker PDFDocument4 paginiRadiation Safety Densitometer Baker PDFLenis CeronÎncă nu există evaluări
- Technical Specification For 33KV VCB BoardDocument7 paginiTechnical Specification For 33KV VCB BoardDipankar ChatterjeeÎncă nu există evaluări
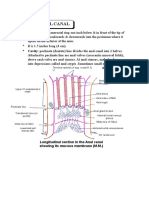
- Anatomy Anal CanalDocument14 paginiAnatomy Anal CanalBela Ronaldoe100% (1)
- Service Manual: SV01-NHX40AX03-01E NHX4000 MSX-853 Axis Adjustment Procedure of Z-Axis Zero Return PositionDocument5 paginiService Manual: SV01-NHX40AX03-01E NHX4000 MSX-853 Axis Adjustment Procedure of Z-Axis Zero Return Positionmahdi elmay100% (3)
- Week 7Document24 paginiWeek 7Priyank PatelÎncă nu există evaluări
- 18 June 2020 12:03: New Section 1 Page 1Document4 pagini18 June 2020 12:03: New Section 1 Page 1KarthikNayakaÎncă nu există evaluări
- How Drugs Work - Basic Pharmacology For Healthcare ProfessionalsDocument19 paginiHow Drugs Work - Basic Pharmacology For Healthcare ProfessionalsSebastián Pérez GuerraÎncă nu există evaluări
- Online Extra: "Economists Suffer From Physics Envy"Document2 paginiOnline Extra: "Economists Suffer From Physics Envy"Bisto MasiloÎncă nu există evaluări
- Acute Coronary SyndromeDocument30 paginiAcute Coronary SyndromeEndar EszterÎncă nu există evaluări
- FAMOUS PP Past TenseDocument21 paginiFAMOUS PP Past Tenseme me kyawÎncă nu există evaluări
- Nama: Yossi Tiara Pratiwi Kelas: X Mis 1 Mata Pelajaran: Bahasa InggrisDocument2 paginiNama: Yossi Tiara Pratiwi Kelas: X Mis 1 Mata Pelajaran: Bahasa InggrisOrionj jrÎncă nu există evaluări
- Chemistry: Crash Course For JEE Main 2020Document18 paginiChemistry: Crash Course For JEE Main 2020Sanjeeb KumarÎncă nu există evaluări
- Nutrition and CKDDocument20 paginiNutrition and CKDElisa SalakayÎncă nu există evaluări
- Dokumen - Pub - Bobs Refunding Ebook v3 PDFDocument65 paginiDokumen - Pub - Bobs Refunding Ebook v3 PDFJohn the First100% (3)
- Chapter 8 Data Collection InstrumentsDocument19 paginiChapter 8 Data Collection InstrumentssharmabastolaÎncă nu există evaluări
- Evaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsDe la EverandEvaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsEvaluare: 5 din 5 stele5/5 (1)
- Hacking: A Beginners Guide To Your First Computer Hack; Learn To Crack A Wireless Network, Basic Security Penetration Made Easy and Step By Step Kali LinuxDe la EverandHacking: A Beginners Guide To Your First Computer Hack; Learn To Crack A Wireless Network, Basic Security Penetration Made Easy and Step By Step Kali LinuxEvaluare: 4.5 din 5 stele4.5/5 (67)
- Cybersecurity: A Simple Beginner’s Guide to Cybersecurity, Computer Networks and Protecting Oneself from Hacking in the Form of Phishing, Malware, Ransomware, and Social EngineeringDe la EverandCybersecurity: A Simple Beginner’s Guide to Cybersecurity, Computer Networks and Protecting Oneself from Hacking in the Form of Phishing, Malware, Ransomware, and Social EngineeringEvaluare: 5 din 5 stele5/5 (40)
- CCNA Certification Study Guide, Volume 2: Exam 200-301De la EverandCCNA Certification Study Guide, Volume 2: Exam 200-301Încă nu există evaluări
- Cybersecurity: The Beginner's Guide: A comprehensive guide to getting started in cybersecurityDe la EverandCybersecurity: The Beginner's Guide: A comprehensive guide to getting started in cybersecurityEvaluare: 5 din 5 stele5/5 (2)
- AWS Certified Solutions Architect Study Guide: Associate SAA-C02 ExamDe la EverandAWS Certified Solutions Architect Study Guide: Associate SAA-C02 ExamÎncă nu există evaluări
- The Compete Ccna 200-301 Study Guide: Network Engineering EditionDe la EverandThe Compete Ccna 200-301 Study Guide: Network Engineering EditionEvaluare: 5 din 5 stele5/5 (4)
- Microsoft Azure Infrastructure Services for Architects: Designing Cloud SolutionsDe la EverandMicrosoft Azure Infrastructure Services for Architects: Designing Cloud SolutionsÎncă nu există evaluări
- Microsoft Certified Azure Fundamentals Study Guide: Exam AZ-900De la EverandMicrosoft Certified Azure Fundamentals Study Guide: Exam AZ-900Încă nu există evaluări
- Azure Networking: Command Line Mastery From Beginner To ArchitectDe la EverandAzure Networking: Command Line Mastery From Beginner To ArchitectÎncă nu există evaluări
- ITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationDe la EverandITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationEvaluare: 5 din 5 stele5/5 (2)
- Palo Alto Networks: The Ultimate Guide To Quickly Pass All The Exams And Getting Certified. Real Practice Test With Detailed Screenshots, Answers And ExplanationsDe la EverandPalo Alto Networks: The Ultimate Guide To Quickly Pass All The Exams And Getting Certified. Real Practice Test With Detailed Screenshots, Answers And ExplanationsÎncă nu există evaluări
- ITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationDe la EverandITIL® 4 Create, Deliver and Support (CDS): Your companion to the ITIL 4 Managing Professional CDS certificationÎncă nu există evaluări
- Set Up Your Own IPsec VPN, OpenVPN and WireGuard Server: Build Your Own VPNDe la EverandSet Up Your Own IPsec VPN, OpenVPN and WireGuard Server: Build Your Own VPNEvaluare: 5 din 5 stele5/5 (1)
- Terraform for Developers: Essentials of Infrastructure Automation and ProvisioningDe la EverandTerraform for Developers: Essentials of Infrastructure Automation and ProvisioningÎncă nu există evaluări
- Open Radio Access Network (O-RAN) Systems Architecture and DesignDe la EverandOpen Radio Access Network (O-RAN) Systems Architecture and DesignÎncă nu există evaluări
- AWS Certified Cloud Practitioner Study Guide: CLF-C01 ExamDe la EverandAWS Certified Cloud Practitioner Study Guide: CLF-C01 ExamEvaluare: 5 din 5 stele5/5 (1)
- ITIL 4 : Drive Stakeholder Value: Reference and study guideDe la EverandITIL 4 : Drive Stakeholder Value: Reference and study guideÎncă nu există evaluări