S-ar putea să vă placă și
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- RFC 1557Document11 paginiRFC 1557NickyNETÎncă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- RFC 1545Document7 paginiRFC 1545NickyNETÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (890)
- RFC 1560Document9 paginiRFC 1560NickyNETÎncă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- RFC 1559Document71 paginiRFC 1559NickyNETÎncă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- RFC 1546Document11 paginiRFC 1546NickyNETÎncă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- RFC 1551Document24 paginiRFC 1551NickyNETÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- RFC 1555Document7 paginiRFC 1555NickyNETÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- RFC 1558Document5 paginiRFC 1558NickyNETÎncă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- RFC 1556Document5 paginiRFC 1556NickyNETÎncă nu există evaluări
- RFC 1550Document8 paginiRFC 1550NickyNETÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- RFC 1553Document25 paginiRFC 1553NickyNETÎncă nu există evaluări
- RFC 1544Document5 paginiRFC 1544NickyNETÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- RFC 1554Document8 paginiRFC 1554NickyNETÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- RFC 1552Document18 paginiRFC 1552NickyNETÎncă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- RFC 1549Document20 paginiRFC 1549NickyNETÎncă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- RFC 1548Document55 paginiRFC 1548NickyNETÎncă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- RFC 1540Document36 paginiRFC 1540NickyNETÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- RFC 1547Document23 paginiRFC 1547NickyNETÎncă nu există evaluări
- RFC 1538Document12 paginiRFC 1538NickyNETÎncă nu există evaluări
- RFC 1539Document24 paginiRFC 1539NickyNETÎncă nu există evaluări
- RFC 1542Document25 paginiRFC 1542NickyNETÎncă nu există evaluări
- RFC 1543Document18 paginiRFC 1543NickyNETÎncă nu există evaluări
- Network Working Group Request For Comments: 1541 Obsoletes: 1531 CategoryDocument39 paginiNetwork Working Group Request For Comments: 1541 Obsoletes: 1531 CategorystrideworldÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- RFC 1537Document11 paginiRFC 1537NickyNETÎncă nu există evaluări
- RFC 1535Document7 paginiRFC 1535NickyNETÎncă nu există evaluări
- RFC 1536Document14 paginiRFC 1536NickyNETÎncă nu există evaluări
- RFC 1533Document32 paginiRFC 1533NickyNETÎncă nu există evaluări
- RFC 1532Document24 paginiRFC 1532NickyNETÎncă nu există evaluări
- RFC 1534Document6 paginiRFC 1534NickyNETÎncă nu există evaluări
- RFC 1531Document39 paginiRFC 1531Shiva prasadÎncă nu există evaluări
- slx-20 1 1-L2guideDocument291 paginislx-20 1 1-L2guidePrinceRaiÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- IP Addressing and SubnettingDocument36 paginiIP Addressing and SubnettingRhy Obra100% (1)
- 2isp MikrotikDocument3 pagini2isp MikrotikamirulmÎncă nu există evaluări
- MOCS call setupDocument8 paginiMOCS call setup김상일Încă nu există evaluări
- Diameter and IMS for Call RoutingDocument1 paginăDiameter and IMS for Call Routinglouie mabiniÎncă nu există evaluări
- Ds Ruckus h320Document3 paginiDs Ruckus h320jscerÎncă nu există evaluări
- Configuring SNA Communication over CSNADocument18 paginiConfiguring SNA Communication over CSNAgborja8881331Încă nu există evaluări
- Ame Relay LabDocument6 paginiAme Relay LabasegunloluÎncă nu există evaluări
- Huawei AR 160 Series Configuration.Document15 paginiHuawei AR 160 Series Configuration.Ojijo Kevin100% (3)
- What Is Network AddressingDocument11 paginiWhat Is Network AddressingArgyll GalanoÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- KNX IProuterDocument6 paginiKNX IProuterSanja RuzicÎncă nu există evaluări
- CB 002468 Ta C VST Eng RC Day 1 SlidesDocument122 paginiCB 002468 Ta C VST Eng RC Day 1 SlidesApollos_80Încă nu există evaluări
- Bras Server RequirmentDocument55 paginiBras Server RequirmentDinh Trung KienÎncă nu există evaluări
- Network Programming LabDocument152 paginiNetwork Programming Labraghunath9Încă nu există evaluări
- Honeywell Alarmnet Internet FaqsDocument2 paginiHoneywell Alarmnet Internet FaqsAlarm Grid Home Security and Alarm MonitoringÎncă nu există evaluări
- SMPPDocument2 paginiSMPPLokesh N KÎncă nu există evaluări
- Quiz:Network ProgrammingDocument2 paginiQuiz:Network ProgrammingFrancisco Antonio Hernandez SabatinoÎncă nu există evaluări
- Lec 3Document62 paginiLec 3ggdfdÎncă nu există evaluări
- VoIP Soft Switch 1Document33 paginiVoIP Soft Switch 1Ajaykumar SinghÎncă nu există evaluări
- Maximum Transmission UnitDocument2 paginiMaximum Transmission UnitMansour Al-hazmiÎncă nu există evaluări
- Fortigate SSLVPNDocument69 paginiFortigate SSLVPNMauricio FloresÎncă nu există evaluări
- Installation Happroxy+ipvirtuelDocument5 paginiInstallation Happroxy+ipvirtuelSouleymane FaneÎncă nu există evaluări
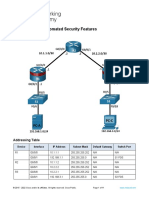
- 6.2.7 Lab - Configure Automated Security FeaturesDocument11 pagini6.2.7 Lab - Configure Automated Security FeaturesHani GoytomÎncă nu există evaluări
- Cisco ACI Fundamentals 41XDocument310 paginiCisco ACI Fundamentals 41XmjdjjainÎncă nu există evaluări
- Protocolo de Comunicación BACNETDocument13 paginiProtocolo de Comunicación BACNETGustavo Choque CuevaÎncă nu există evaluări
- Arp CommandDocument1 paginăArp CommandVarun ShahÎncă nu există evaluări
- Attacking The Foundation - ModifiedDocument31 paginiAttacking The Foundation - ModifiedKing DeedÎncă nu există evaluări
- Como Tener Internet Gratis Con HTTP Injector - BELLEZA SIN DOLORDocument260 paginiComo Tener Internet Gratis Con HTTP Injector - BELLEZA SIN DOLORSamuel VegaÎncă nu există evaluări
- COMPUTER NETWORKS OVERVIEWDocument24 paginiCOMPUTER NETWORKS OVERVIEWDjordje OrasaninÎncă nu există evaluări
- Automatic OMCH Establishment (SRAN12.1 - 01)Document129 paginiAutomatic OMCH Establishment (SRAN12.1 - 01)anthonyÎncă nu există evaluări
- Computer Systems and Networking Guide: A Complete Guide to the Basic Concepts in Computer Systems, Networking, IP Subnetting and Network SecurityDe la EverandComputer Systems and Networking Guide: A Complete Guide to the Basic Concepts in Computer Systems, Networking, IP Subnetting and Network SecurityEvaluare: 4.5 din 5 stele4.5/5 (13)
- CCNA: 3 in 1- Beginner's Guide+ Tips on Taking the Exam+ Simple and Effective Strategies to Learn About CCNA (Cisco Certified Network Associate) Routing And Switching CertificationDe la EverandCCNA: 3 in 1- Beginner's Guide+ Tips on Taking the Exam+ Simple and Effective Strategies to Learn About CCNA (Cisco Certified Network Associate) Routing And Switching CertificationÎncă nu există evaluări
- Computer Networking: The Complete Beginner's Guide to Learning the Basics of Network Security, Computer Architecture, Wireless Technology and Communications Systems (Including Cisco, CCENT, and CCNA)De la EverandComputer Networking: The Complete Beginner's Guide to Learning the Basics of Network Security, Computer Architecture, Wireless Technology and Communications Systems (Including Cisco, CCENT, and CCNA)Evaluare: 4 din 5 stele4/5 (4)
- AWS Certified Solutions Architect Study Guide: Associate SAA-C02 ExamDe la EverandAWS Certified Solutions Architect Study Guide: Associate SAA-C02 ExamÎncă nu există evaluări
- CEH Certified Ethical Hacker Practice Exams, Third EditionDe la EverandCEH Certified Ethical Hacker Practice Exams, Third EditionÎncă nu există evaluări