S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Braun MR30 Hand BlenderDocument2 paginiBraun MR30 Hand BlenderHana Bernard100% (1)
- Reviewer For Bookkeeping NCIIIDocument18 paginiReviewer For Bookkeeping NCIIIAngelica Faye95% (20)
- Individual Reflection ScribdDocument4 paginiIndividual Reflection ScribdJamie Chan JieminÎncă nu există evaluări
- Bill of Quantity: Supply of Pipes and FittingsDocument3 paginiBill of Quantity: Supply of Pipes and FittingssubxaanalahÎncă nu există evaluări
- BZY Series Tension Meter ManualDocument29 paginiBZY Series Tension Meter ManualJORGE SANTANDER0% (1)
- The Library Evolution 2014, MelbourneDocument4 paginiThe Library Evolution 2014, MelbourneArk GroupÎncă nu există evaluări
- Women War Stories From The Digital FrontlineDocument4 paginiWomen War Stories From The Digital FrontlineSteven OesterreichÎncă nu există evaluări
- International Keynotes:: SAVE 10%Document6 paginiInternational Keynotes:: SAVE 10%Steven OesterreichÎncă nu există evaluări
- d004 Ikm WebDocument4 paginid004 Ikm Webmepris84Încă nu există evaluări
- C098 Email Mgtment - WEBDocument4 paginiC098 Email Mgtment - WEBSteven OesterreichÎncă nu există evaluări
- KM Asia2009 6 Page Brochure SeptWEBDocument6 paginiKM Asia2009 6 Page Brochure SeptWEBSteven OesterreichÎncă nu există evaluări
- THE Ketofeed Diet Book v2Document43 paginiTHE Ketofeed Diet Book v2jacosta12100% (1)
- Theben Timer SUL 181DDocument2 paginiTheben Timer SUL 181DFerdiÎncă nu există evaluări
- PLX Model OfficialDocument105 paginiPLX Model OfficialBảo Ngọc LêÎncă nu există evaluări
- Shaft DeflectionDocument15 paginiShaft Deflectionfreek_jamesÎncă nu există evaluări
- SOP For Operation & Calibration of PH Meter - QualityGuidancesDocument9 paginiSOP For Operation & Calibration of PH Meter - QualityGuidancesfawaz khalilÎncă nu există evaluări
- 95 935 Dowsil Acp 3990 Antifoam CompDocument2 pagini95 935 Dowsil Acp 3990 Antifoam CompZhan FangÎncă nu există evaluări
- STS Reviewer FinalsDocument33 paginiSTS Reviewer FinalsLeiÎncă nu există evaluări
- Pointers in CDocument25 paginiPointers in CSainiNishrithÎncă nu există evaluări
- Classical Encryption TechniqueDocument18 paginiClassical Encryption TechniquetalebmuhsinÎncă nu există evaluări
- Impeller Velocity TrianglesDocument2 paginiImpeller Velocity TrianglesLorettaMayÎncă nu există evaluări
- Review Problems On Gas TurbineDocument9 paginiReview Problems On Gas TurbinejehadyamÎncă nu există evaluări
- Toefl StructureDocument50 paginiToefl StructureFebrian AsharÎncă nu există evaluări
- Celestino vs. CIRDocument6 paginiCelestino vs. CIRchristopher d. balubayanÎncă nu există evaluări
- General Information Exhibition Guide Lines - 3P 2022Document6 paginiGeneral Information Exhibition Guide Lines - 3P 2022muhammad khanÎncă nu există evaluări
- Srinivasa Ramanujan - Britannica Online EncyclopediaDocument2 paginiSrinivasa Ramanujan - Britannica Online EncyclopediaEvariste MigaboÎncă nu există evaluări
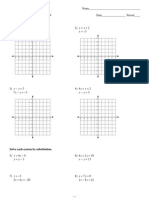
- Review Systems of Linear Equations All MethodsDocument4 paginiReview Systems of Linear Equations All Methodsapi-265647260Încă nu există evaluări
- Pe8 Mod5Document16 paginiPe8 Mod5Cryzel MuniÎncă nu există evaluări
- Complex Poly (Lactic Acid) - Based - 1Document20 paginiComplex Poly (Lactic Acid) - Based - 1Irina PaslaruÎncă nu există evaluări
- Ultimate Prime Sieve - Sieve of ZakiyaDocument23 paginiUltimate Prime Sieve - Sieve of ZakiyaJabari ZakiyaÎncă nu există evaluări
- Hydrogen ReviewDocument53 paginiHydrogen Reviewjuric98Încă nu există evaluări
- Introduction To Regional PlanningDocument27 paginiIntroduction To Regional Planningadeeba siddiquiÎncă nu există evaluări
- Memo ALS Literacy MappingDocument4 paginiMemo ALS Literacy MappingJEPH BACULINAÎncă nu există evaluări
- CR-805 Retransfer PrinterDocument2 paginiCR-805 Retransfer PrinterBolivio FelizÎncă nu există evaluări
- AMX Prodigy Install ManualDocument13 paginiAMX Prodigy Install Manualsundevil2010usa4605Încă nu există evaluări
- Towards A Brighter Ecological Future: Group 2Document24 paginiTowards A Brighter Ecological Future: Group 2As YangÎncă nu există evaluări