S-ar putea să vă placă și
- Redes NeuronalesDocument17 paginiRedes NeuronalesSTEFANNY SALAS JIMENEZÎncă nu există evaluări
- Redes NeuronalesDocument16 paginiRedes NeuronalesAlicia PeraltaÎncă nu există evaluări
- Redes NeuronalesDocument18 paginiRedes NeuronalesLimbercito AguirreÎncă nu există evaluări
- Control Por Redes NeuronalesDocument12 paginiControl Por Redes NeuronalesEdgar BCÎncă nu există evaluări
- Redes - Neuronales - Artificiales Fernando Izaurieta PDFDocument16 paginiRedes - Neuronales - Artificiales Fernando Izaurieta PDFebemolÎncă nu există evaluări
- Trabajo de Investigación RNADocument11 paginiTrabajo de Investigación RNAJose SilvaÎncă nu există evaluări
- Tema 4 Redes de NeuronasDocument39 paginiTema 4 Redes de NeuronasFernanda KharsdalaÎncă nu există evaluări
- 20 Capítulo 13. Redes Neuronales ArtificialesDocument26 pagini20 Capítulo 13. Redes Neuronales ArtificialesvitryÎncă nu există evaluări
- Trabajo Redes NeuronalesDocument37 paginiTrabajo Redes Neuronalesshabedekam75% (4)
- Como Funciona El Cerebro Equipo 1Document5 paginiComo Funciona El Cerebro Equipo 1Carol JimenezÎncă nu există evaluări
- Redes NeuronalesDocument14 paginiRedes NeuronalesTATIANA FLORESÎncă nu există evaluări
- Algoritmos de Aprendizaje en Retropropagación para Perceptron MulticapaDocument18 paginiAlgoritmos de Aprendizaje en Retropropagación para Perceptron MulticapaManuel Currea100% (1)
- Redes NeuronalesDocument5 paginiRedes NeuronalesR'elar KvotheÎncă nu există evaluări
- Redes Neuronales 1Document23 paginiRedes Neuronales 1Luis Emilio Alvarez O.Încă nu există evaluări
- 2.1 Generalidades Redes NeuronalesDocument43 pagini2.1 Generalidades Redes Neuronalesoaraujo1Încă nu există evaluări
- Redes Neuronales para El Reconocimiento de PatronesDocument11 paginiRedes Neuronales para El Reconocimiento de PatronesErnestoÎncă nu există evaluări
- Redes NeuronalesDocument17 paginiRedes NeuronalesCarlos CastroÎncă nu există evaluări
- Fundamentos de Redes NeuronalesDocument23 paginiFundamentos de Redes NeuronalesJose Jose FernandezÎncă nu există evaluări
- Redes Neuronales ConvolucionalesDocument12 paginiRedes Neuronales Convolucionalesantosega100% (1)
- F-Ficha 6 Sistema Nervioso IDocument12 paginiF-Ficha 6 Sistema Nervioso IRocíoÎncă nu există evaluări
- Investigacion RN - AvanzadoDocument50 paginiInvestigacion RN - AvanzadoIgnacioÎncă nu există evaluări
- Miguel Torres - Monografía Redes Neuronales CompletaDocument52 paginiMiguel Torres - Monografía Redes Neuronales CompletajulioÎncă nu există evaluări
- Act 6 Sin RnaDocument5 paginiAct 6 Sin RnaAlondra AldapeÎncă nu există evaluări
- 2.1. Redes Neuronales. - IntroducciónDocument37 pagini2.1. Redes Neuronales. - IntroducciónmonicaÎncă nu există evaluări
- TecsupDocument15 paginiTecsupJuan Ignacio BoggettiÎncă nu există evaluări
- N D I - Semana2Document9 paginiN D I - Semana2josselineÎncă nu există evaluări
- Ensayo La Fisica en La Medicina Nitzia CarrasquedoDocument5 paginiEnsayo La Fisica en La Medicina Nitzia Carrasquedonitzia carrasquedoÎncă nu există evaluări
- Cap 2 Fundamentos de Redes NeuronalesDocument10 paginiCap 2 Fundamentos de Redes NeuronalesJuan RamirezÎncă nu există evaluări
- REDES NEURONALES Capitulo1 IntroduccionDocument39 paginiREDES NEURONALES Capitulo1 IntroduccionAdolfo VelasquezÎncă nu există evaluări
- El - Cerebro Estudia Al Cerebro PDFDocument54 paginiEl - Cerebro Estudia Al Cerebro PDFMarce Feli CalderonÎncă nu există evaluări
- IA-redes Neuronales ArtificialesDocument9 paginiIA-redes Neuronales Artificialesdenys_791Încă nu există evaluări
- Redes NeuronalesDocument12 paginiRedes NeuronalesJean CarlosÎncă nu există evaluări
- Todo Sobre Memoria y Aprendizaje IDocument16 paginiTodo Sobre Memoria y Aprendizaje ILilia GarciaÎncă nu există evaluări
- Un Modelo Matemático Realista para Explicar La VisiónDocument6 paginiUn Modelo Matemático Realista para Explicar La VisiónYahir OstosÎncă nu există evaluări
- Redes NeuronalesDocument15 paginiRedes Neuronalesbryan saul choqueÎncă nu există evaluări
- Introducción A La Computación NeuronalDocument15 paginiIntroducción A La Computación NeuronalBrayhan RojasÎncă nu există evaluări
- Sistemas NeuralesDocument8 paginiSistemas NeuralesDaniel Sanchez100% (1)
- Cómo se comunican las neuronas: El milagro de la transmisión sinápticaDe la EverandCómo se comunican las neuronas: El milagro de la transmisión sinápticaÎncă nu există evaluări
- Informe1 - Introduccion A La Computacion NeuronalDocument15 paginiInforme1 - Introduccion A La Computacion NeuronalCarlos GuarinÎncă nu există evaluări
- Redes Neuronales ArtificialesDocument28 paginiRedes Neuronales ArtificialesRA OseasÎncă nu există evaluări
- Ensayo Argumentativo BioDocument3 paginiEnsayo Argumentativo BioAlex Santiago Angel ZambranoÎncă nu există evaluări
- C6 Redes NeuronalesDocument50 paginiC6 Redes NeuronalesADA MARIANNA SALAS ARIASÎncă nu există evaluări
- Una Introducción Completa A Redes Neuronales Con Python y Tensorflow 2.0 PDFDocument1 paginăUna Introducción Completa A Redes Neuronales Con Python y Tensorflow 2.0 PDFAlejo GarciaÎncă nu există evaluări
- Cómo Funcionan Los Circuitos CerebralesDocument7 paginiCómo Funcionan Los Circuitos CerebralesDaniel Cordero HernándezÎncă nu există evaluări
- CAPÍTULO 3 Fisiologia de Las NeuronasDocument10 paginiCAPÍTULO 3 Fisiologia de Las NeuronasValentina TreppoÎncă nu există evaluări
- Expo de Precepton y MadelineDocument14 paginiExpo de Precepton y Madelineeder albinoÎncă nu există evaluări
- Fundamentos Redes Neuronales TerminadDocument18 paginiFundamentos Redes Neuronales TerminadPaolo PazzagliaÎncă nu există evaluări
- Taz TFG 2018 148Document47 paginiTaz TFG 2018 148Aldo EnFaÎncă nu există evaluări
- S02.s1 - Redes Neuronales y Lógica DifusaDocument25 paginiS02.s1 - Redes Neuronales y Lógica DifusaJonathan Gabriel Catari AlanocaÎncă nu există evaluări
- La Neuro Biología de La PersuasiónDocument22 paginiLa Neuro Biología de La PersuasiónmicaelaÎncă nu există evaluări
- Neurona de McCullochDocument11 paginiNeurona de McCullochJairo E Márquez DÎncă nu există evaluări
- MONOGRAFIA (1) Yomeli (1)Document19 paginiMONOGRAFIA (1) Yomeli (1)Imi Aguirre LiberatoÎncă nu există evaluări
- Triptico - Origenes de La Computación NeuronalDocument2 paginiTriptico - Origenes de La Computación NeuronalFreddy AlcÎncă nu există evaluări
- Las Células Nerviosas y SinapsisDocument22 paginiLas Células Nerviosas y SinapsisEstela De AraujoÎncă nu există evaluări
- Primeros Modelos Matemáticos de Las Neuronas BiológicasDocument5 paginiPrimeros Modelos Matemáticos de Las Neuronas BiológicasCristian valenzuela maciasÎncă nu există evaluări
- Redes Neuronales y Teoría de Conjuntos DifusosDocument14 paginiRedes Neuronales y Teoría de Conjuntos DifusosA-SanThiago Rojas LlerenaÎncă nu există evaluări
- Anatomia y Fisiología del Sistema Nervioso II: Principios Elementales del Sistema Nervioso, #2De la EverandAnatomia y Fisiología del Sistema Nervioso II: Principios Elementales del Sistema Nervioso, #2Încă nu există evaluări
- Anatomia y Fisiología del Sistema Nervioso IIDe la EverandAnatomia y Fisiología del Sistema Nervioso IIEvaluare: 4 din 5 stele4/5 (28)
- Componentes Del Tejido SanguíneoDocument4 paginiComponentes Del Tejido SanguíneoAlexanderBorrayoÎncă nu există evaluări
- Resumen de Sistema EndocrinoDocument7 paginiResumen de Sistema EndocrinoRoland M ReyesÎncă nu există evaluări
- Movilizacion Del Sistema NerviosoDocument230 paginiMovilizacion Del Sistema NerviosoCarol Avrvm100% (5)
- Integración Sensorial en El Niño Con AutismoDocument15 paginiIntegración Sensorial en El Niño Con AutismoBeatrizBardónMontero100% (2)
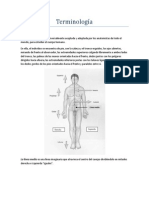
- Terminología Educación para La SaludDocument8 paginiTerminología Educación para La SaludNatalia Sánchez100% (2)
- Infore Tejido Conectivo y Cuadro.Document4 paginiInfore Tejido Conectivo y Cuadro.Maria Alejandra Sarmiento TabordaÎncă nu există evaluări
- Raquis Dorsal y RespiracionDocument20 paginiRaquis Dorsal y RespiracionDANIEL ALEJANDRO100% (2)
- Reactivos Protesis Removible Segundo Parcial Unidad 3 y 4Document28 paginiReactivos Protesis Removible Segundo Parcial Unidad 3 y 4Kelly EscalanteÎncă nu există evaluări
- Ecografia HigadoDocument58 paginiEcografia HigadoFernando Siles OrellanaÎncă nu există evaluări
- SISTEMA VENOSO - AnatomíaDocument4 paginiSISTEMA VENOSO - Anatomíanicole ruizÎncă nu există evaluări
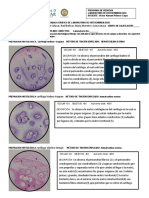
- s.12 Sistema Urinario (Practica de Histoligía)Document38 paginis.12 Sistema Urinario (Practica de Histoligía)Hanny Aracelly Ruiz RiosÎncă nu există evaluări
- Como Ayuda La Actividad Física Al Cerebro yDocument6 paginiComo Ayuda La Actividad Física Al Cerebro yYerson OlmerÎncă nu există evaluări
- Puntos Extras SecundariosDocument68 paginiPuntos Extras SecundariosRicardo Jaramillo VargasÎncă nu există evaluări
- El Nombre de Las Hormonas Que Produce Por El Sistema EndocrinoDocument2 paginiEl Nombre de Las Hormonas Que Produce Por El Sistema EndocrinobrendaÎncă nu există evaluări
- EstómagoDocument8 paginiEstómagoAna Maria Salazar Pulgar100% (1)
- Hablemos Del Sexo Tomo IIIDocument153 paginiHablemos Del Sexo Tomo IIIOrlando LeónÎncă nu există evaluări
- Los Tipos de CirculaciónDocument3 paginiLos Tipos de CirculaciónAnaLuisaPerezGranadosÎncă nu există evaluări
- Clase 2 Respuesta Inmune Mediada Por Anticuerpos - 20200323173325Document28 paginiClase 2 Respuesta Inmune Mediada Por Anticuerpos - 20200323173325victor quispe CastroÎncă nu există evaluări
- 3er Semestre .Disciplina de Alexander - BORRADORDocument91 pagini3er Semestre .Disciplina de Alexander - BORRADORmarrufles5362100% (1)
- (William H Fitzgerald) Reflexología Podálica - Masaje Zonal en Los PiesDocument24 pagini(William H Fitzgerald) Reflexología Podálica - Masaje Zonal en Los PiesBelkis Albertt86% (7)
- Historia Clinica ReumatologiaDocument16 paginiHistoria Clinica ReumatologiajeshiroÎncă nu există evaluări
- Tejido LinfoideDocument31 paginiTejido Linfoideevocrap100% (2)
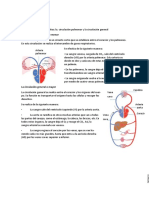
- Aparatos Reproductores BiologíaDocument5 paginiAparatos Reproductores BiologíaEstefany CastroÎncă nu există evaluări
- Relaciones de La Curvatura MenorDocument2 paginiRelaciones de La Curvatura MenorKarina ValdiglesiasÎncă nu există evaluări
- Excel Book FinalDocument10 paginiExcel Book FinalHenryÎncă nu există evaluări
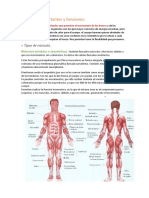
- Músculos Importantes y FuncionesDocument9 paginiMúsculos Importantes y FuncionesJuaaÎncă nu există evaluări
- Anatomia y Fisiologia de La Circulación CoronariaDocument40 paginiAnatomia y Fisiologia de La Circulación CoronariaGiordani Ramirez Ortiz93% (15)
- Masaje LinfáticoDocument3 paginiMasaje Linfáticogeorgina_lingÎncă nu există evaluări
- Mapa Conceptual 6. GametogénesisDocument1 paginăMapa Conceptual 6. GametogénesisPriscila N Gomez Teyer100% (2)
- Triptico AdolescenciaDocument1 paginăTriptico AdolescenciaJorge Mayta PaicoÎncă nu există evaluări