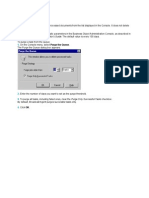
S-ar putea să vă placă și
- ODI Migration ProcessDocument10 paginiODI Migration Processvamsi.prasad100% (2)
- OBIEE Performance TuningDocument9 paginiOBIEE Performance TuningVincenzo PetrucciÎncă nu există evaluări
- Business Intelligence - Ebook - Tutorials For OBIEE Power UsersDocument109 paginiBusiness Intelligence - Ebook - Tutorials For OBIEE Power UsersAsad HussainÎncă nu există evaluări
- OBIEE 12C SecurityDocument8 paginiOBIEE 12C SecurityNarayana AnkireddypalliÎncă nu există evaluări
- NOTICE: Support of BI Applications 11g With OBIEE 12.2.1 (12C)Document25 paginiNOTICE: Support of BI Applications 11g With OBIEE 12.2.1 (12C)syedahmedyasir100% (1)
- Obia DemoDocument20 paginiObia DemodilipÎncă nu există evaluări
- BIAFC - Functional Configuration ReferenceDocument620 paginiBIAFC - Functional Configuration Referenceanamik2100Încă nu există evaluări
- De-Mystifying OBIEE Oracle BI AppDocument106 paginiDe-Mystifying OBIEE Oracle BI Appcrystal_rhoadesÎncă nu există evaluări
- For Power BI Installation:: Get Data: To Get The Data From Different Sources Like CSV, Excel, Test, SQL, Access Etc..Document11 paginiFor Power BI Installation:: Get Data: To Get The Data From Different Sources Like CSV, Excel, Test, SQL, Access Etc..Vasu Dev RaoÎncă nu există evaluări
- Biacm & FSMDocument4 paginiBiacm & FSMYasirÎncă nu există evaluări
- Doubts in OBIEEDocument26 paginiDoubts in OBIEESuman PaluruÎncă nu există evaluări
- CRQ Creation 4 New RemedyDocument62 paginiCRQ Creation 4 New RemedynareshmadhavaÎncă nu există evaluări
- OBIEE 12.2.1 External Subject Area Cache ConfigurationDocument11 paginiOBIEE 12.2.1 External Subject Area Cache ConfigurationSandeep KulkarniÎncă nu există evaluări
- OBIEE Metadata DevelopmentDocument10 paginiOBIEE Metadata DevelopmentMukeshBabuÎncă nu există evaluări
- Aafaaq OBIEE AdminDocument7 paginiAafaaq OBIEE AdminBhimavarapu RamiReddyÎncă nu există evaluări
- Migrate Obiee 11g To Obiee 12cDocument1 paginăMigrate Obiee 11g To Obiee 12cNagarajesh EskalaÎncă nu există evaluări
- OBIEE 12c InstallationDocument24 paginiOBIEE 12c Installationhim4ughzÎncă nu există evaluări
- Course Ag - UnlockedDocument474 paginiCourse Ag - UnlockedGangadri524100% (1)
- BI Apps MaterialDocument12 paginiBI Apps MaterialNarayana AnkireddypalliÎncă nu există evaluări
- Hands On - Oracle Native Sequence With ODI InterfaceDocument14 paginiHands On - Oracle Native Sequence With ODI InterfaceSrinivas KankanampatiÎncă nu există evaluări
- Al Kannan - OBIEE Implementation With EBSDocument103 paginiAl Kannan - OBIEE Implementation With EBSrafiansari20021988Încă nu există evaluări
- OCI Pricing and Billing PDFDocument21 paginiOCI Pricing and Billing PDFvÎncă nu există evaluări
- Financial Reporting RPD Using OBIEEDocument10 paginiFinancial Reporting RPD Using OBIEEAmit SharmaÎncă nu există evaluări
- BI Publisher OverviewDocument14 paginiBI Publisher Overviewpatra_robin9157Încă nu există evaluări
- Simple Understanding of OBIA 11.1.1.8.1Document20 paginiSimple Understanding of OBIA 11.1.1.8.1RamshoneyÎncă nu există evaluări
- Working With Obiee Metadata Dictonary: Amit Sharma OBIEE/Hyperion TrainerDocument12 paginiWorking With Obiee Metadata Dictonary: Amit Sharma OBIEE/Hyperion TrainerAgenor GnanzouÎncă nu există evaluări
- Obiee Material New1Document104 paginiObiee Material New1Naresh Ragala100% (1)
- Obiee 12CDocument6 paginiObiee 12CDilip Kumar AluguÎncă nu există evaluări
- OBIEE - Aggregate TablesDocument3 paginiOBIEE - Aggregate Tablesvenkatesh.gollaÎncă nu există evaluări
- 11168-Tips To Optimize Oracle Business Intelligence Enterprise Edition Upgrade To 12c-Presentation With Notes - 551Document19 pagini11168-Tips To Optimize Oracle Business Intelligence Enterprise Edition Upgrade To 12c-Presentation With Notes - 551Chang장준민Încă nu există evaluări
- ODI 12cDocument92 paginiODI 12cahmed_sft100% (1)
- BI Apps Parameters Configuration DetailsDocument6 paginiBI Apps Parameters Configuration Detailssatyanarayana NVSÎncă nu există evaluări
- OBIA 11g ETL Customization GuideDocument66 paginiOBIA 11g ETL Customization GuidematthieulombardÎncă nu există evaluări
- ObieeDocument11 paginiObieechennam1Încă nu există evaluări
- Oracle Financial Analytics: Key Features and BenefitsDocument5 paginiOracle Financial Analytics: Key Features and Benefitsjbeatofl0% (1)
- DMR TableColumnDescriptionDocument3.479 paginiDMR TableColumnDescriptionmaitri sadar100% (1)
- BI Apps 11.1.1.7.1 Installation and ConfigurationDocument117 paginiBI Apps 11.1.1.7.1 Installation and Configurationnp210291Încă nu există evaluări
- ODI 12C Installation Step by Step PART 1Document4 paginiODI 12C Installation Step by Step PART 1m_saki6665803Încă nu există evaluări
- OBIEE - Performance TuningDocument3 paginiOBIEE - Performance Tuningvenkatesh.gollaÎncă nu există evaluări
- OBIEE - OnLine-Offline ModeDocument1 paginăOBIEE - OnLine-Offline Modevenkatesh.gollaÎncă nu există evaluări
- Obiee Admin Interview QuestionsDocument13 paginiObiee Admin Interview QuestionsNaveenVasireddy100% (3)
- 1Z0 448Document4 pagini1Z0 448pundirsandeepÎncă nu există evaluări
- Tips and Tricks For Oracle Business Intelligence Application ImplementationsDocument71 paginiTips and Tricks For Oracle Business Intelligence Application Implementationsakshitha2807Încă nu există evaluări
- OBI Apps 11gDocument31 paginiOBI Apps 11grao_jayeshÎncă nu există evaluări
- OBIEE 11g Analytics Using EMC Greenplum Database: - An Integration Guide For OBIEE 11g Windows UsersDocument16 paginiOBIEE 11g Analytics Using EMC Greenplum Database: - An Integration Guide For OBIEE 11g Windows UsersmlgovardhanÎncă nu există evaluări
- 01OBI11G ArchitectureDocument18 pagini01OBI11G ArchitecturemanuÎncă nu există evaluări
- Integrigy OBIEE Security ExaminedDocument38 paginiIntegrigy OBIEE Security Examinedgraffs100% (1)
- Obia 11.1.1.8.1Document11 paginiObia 11.1.1.8.1Bhanupavankumar ChandaluriÎncă nu există evaluări
- BIApps ArchitectureDocument31 paginiBIApps ArchitectureVăn Tiến HồÎncă nu există evaluări
- MUDE (Multiuser Development Environment) : Multiple People Can Work On ADocument1 paginăMUDE (Multiuser Development Environment) : Multiple People Can Work On Avenkatesh.gollaÎncă nu există evaluări
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesDe la EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesÎncă nu există evaluări
- Oracle Business Intelligence Enterprise Edition 12c A Complete Guide - 2020 EditionDe la EverandOracle Business Intelligence Enterprise Edition 12c A Complete Guide - 2020 EditionÎncă nu există evaluări
- Oracle Cloud Applications A Complete Guide - 2019 EditionDe la EverandOracle Cloud Applications A Complete Guide - 2019 EditionÎncă nu există evaluări
- Powercenter Mapping Rules: Concatenation and Active Transformations in Powercenter MappingsDocument9 paginiPowercenter Mapping Rules: Concatenation and Active Transformations in Powercenter Mappingsa567786Încă nu există evaluări
- Best Informatica Administrator Interview Questions With Answers - Part 2Document2 paginiBest Informatica Administrator Interview Questions With Answers - Part 2a567786Încă nu există evaluări
- Infi FaQs-3Document2 paginiInfi FaQs-3a567786Încă nu există evaluări
- How-To: Creating A Universe With The BO XI 4.0 Information Design ToolDocument16 paginiHow-To: Creating A Universe With The BO XI 4.0 Information Design ToolpraveenÎncă nu există evaluări
- Universe BO4Document17 paginiUniverse BO4a567786Încă nu există evaluări
- Infi FaQs-1Document2 paginiInfi FaQs-1a567786Încă nu există evaluări
- How To Use Prompts To Select All ValuesDocument1 paginăHow To Use Prompts To Select All Valuesa567786Încă nu există evaluări
- Project Plan RisksDocument1 paginăProject Plan RisksAnand VaÎncă nu există evaluări
- BOBJ - Loops: AboutDocument15 paginiBOBJ - Loops: Abouta567786Încă nu există evaluări
- How To Create Cascading PromptsDocument8 paginiHow To Create Cascading Promptsa567786Încă nu există evaluări
- SAP-IT Internal Migration From XI3 To BI4 SCNDocument9 paginiSAP-IT Internal Migration From XI3 To BI4 SCNa567786Încă nu există evaluări
- Purging The QueueDocument1 paginăPurging The Queuea567786Încă nu există evaluări
- Bo 4Document23 paginiBo 4ketan_potdarÎncă nu există evaluări
- Informatica Questions - 23Document1 paginăInformatica Questions - 23a567786Încă nu există evaluări
- Informatica Questions - 22Document1 paginăInformatica Questions - 22a567786Încă nu există evaluări
- Informatica Questions - 15Document1 paginăInformatica Questions - 15a567786Încă nu există evaluări
- Informatica Questions - 20Document1 paginăInformatica Questions - 20a567786Încă nu există evaluări
- Informatica Questions - 17Document1 paginăInformatica Questions - 17a567786Încă nu există evaluări
- Informatica Questions - 21Document1 paginăInformatica Questions - 21a567786Încă nu există evaluări
- Informatica Questions - 18Document1 paginăInformatica Questions - 18a567786Încă nu există evaluări
- Informatica Questions - 19Document1 paginăInformatica Questions - 19a567786Încă nu există evaluări
- Informatica Questions - 16Document1 paginăInformatica Questions - 16a567786Încă nu există evaluări
- Informatica Questions - 12Document1 paginăInformatica Questions - 12a567786Încă nu există evaluări
- Informatica Questions - 14Document1 paginăInformatica Questions - 14a567786Încă nu există evaluări
- Informatica Questions - 13Document1 paginăInformatica Questions - 13a567786Încă nu există evaluări
- Informatica Questions - 12Document1 paginăInformatica Questions - 12a567786Încă nu există evaluări
- Informatica Questions - 9Document1 paginăInformatica Questions - 9a567786Încă nu există evaluări
- Informatica Questions - 10Document1 paginăInformatica Questions - 10a567786Încă nu există evaluări
- Informatica Questions - 11Document2 paginiInformatica Questions - 11a567786Încă nu există evaluări
- Informatica Questions - 8Document1 paginăInformatica Questions - 8a567786Încă nu există evaluări
- CPS - Data Intensive Distributed ComputingDocument11 paginiCPS - Data Intensive Distributed ComputingManoj KavediaÎncă nu există evaluări
- Data Audit Approach To Developing An Enterprise Data StrategyDocument66 paginiData Audit Approach To Developing An Enterprise Data StrategyAlan McSweeneyÎncă nu există evaluări
- IBM Storage Discover Level 2 Quiz - TOS AttemptDocument13 paginiIBM Storage Discover Level 2 Quiz - TOS AttemptMike ManselÎncă nu există evaluări
- 6.2.3 Release NotesDocument28 pagini6.2.3 Release NotesManjunath GovindarajuluÎncă nu există evaluări
- Creating A Digital Health Smartphone App and Digital Phenotyping Platform For Mental Health and Diverse Healthcare NeedsDocument13 paginiCreating A Digital Health Smartphone App and Digital Phenotyping Platform For Mental Health and Diverse Healthcare NeedsMichaelaÎncă nu există evaluări
- Databricks Certified Data Engineer Associate PDFDocument5 paginiDatabricks Certified Data Engineer Associate PDFAbdul KhaliqÎncă nu există evaluări
- Nest User Manual 5.1Document398 paginiNest User Manual 5.1Nyeinchan MinÎncă nu există evaluări
- Library Management Issue - Case Study - 11.03.12Document4 paginiLibrary Management Issue - Case Study - 11.03.12khannanltÎncă nu există evaluări
- 1 - Study GuideDocument23 pagini1 - Study GuideGasmi SanderÎncă nu există evaluări
- Iso 11620 2023Document15 paginiIso 11620 2023sylvestre3k0% (1)
- MKTG InstallAdminDocument216 paginiMKTG InstallAdminrammohansiebelÎncă nu există evaluări
- Litigation Checklist - ConducDocument4 paginiLitigation Checklist - ConducJoelÎncă nu există evaluări
- Vehicular Accident 2018Document358 paginiVehicular Accident 2018onahlyn santosÎncă nu există evaluări
- Capgemini CRM Modernization Services - Accelerate CRM To The CloudDocument4 paginiCapgemini CRM Modernization Services - Accelerate CRM To The CloudRahul SinhaÎncă nu există evaluări
- HTML Head Elements PDFDocument10 paginiHTML Head Elements PDFAlex OrozcoÎncă nu există evaluări
- Data MiningDocument30 paginiData MiningHarminderSingh Bindra100% (1)
- DRM and DRGDocument14 paginiDRM and DRGjeffconnorsÎncă nu există evaluări
- IFSBusinessAnalyticsTM 20080625Document69 paginiIFSBusinessAnalyticsTM 20080625amalkumarÎncă nu există evaluări
- IBM Webshpere DataStage 8.x Parallel Jobs GuideDocument636 paginiIBM Webshpere DataStage 8.x Parallel Jobs GuideSrinivasa Kumar GullapalliÎncă nu există evaluări
- IBM Product Master 12.0 Functional OverviewDocument26 paginiIBM Product Master 12.0 Functional OverviewmahithaÎncă nu există evaluări
- INF 370 Lab ManualDocument15 paginiINF 370 Lab ManualDr.nagwa yaseenÎncă nu există evaluări
- DOCUNUV2030 Lav3456Document75 paginiDOCUNUV2030 Lav3456Eloy BornazÎncă nu există evaluări
- Coordinating Parallel Hierarchical Storage ManagemDocument16 paginiCoordinating Parallel Hierarchical Storage ManagemAdane AbateÎncă nu există evaluări
- Digitization in The Real World: Lessons Learned From Small and Medium Size Digitization ProjectsDocument593 paginiDigitization in The Real World: Lessons Learned From Small and Medium Size Digitization ProjectsMetropolitan New York Library Council (METRO)0% (1)
- CA ERwin Data Modeler Navigator Edition Data SheetDocument2 paginiCA ERwin Data Modeler Navigator Edition Data Sheetcnst_georgeÎncă nu există evaluări
- Power Center WebServices UserGuideDocument78 paginiPower Center WebServices UserGuideLakshmi ShenoyÎncă nu există evaluări
- Salesforce Flows Interview QuestionsDocument4 paginiSalesforce Flows Interview Questionssandeep VishwakarmaÎncă nu există evaluări
- 3rd CUAHSI Conference On HydroinformaticsDocument52 pagini3rd CUAHSI Conference On HydroinformaticsConsortium of Universities for the Advancement of Hydrologic Science, Inc.Încă nu există evaluări
- Library ClassificationDocument10 paginiLibrary ClassificationKakeembo NasiifuÎncă nu există evaluări
- Presentation On Reflection in C#Document19 paginiPresentation On Reflection in C#harman_bajwa_4Încă nu există evaluări