Documente Academic
Documente Profesional
Documente Cultură
Pentaho Vs Jasper
Încărcat de
mishytooTitlu original
Drepturi de autor
Formate disponibile
Partajați acest document
Partajați sau inserați document
Vi se pare util acest document?
Este necorespunzător acest conținut?
Raportați acest documentDrepturi de autor:
Formate disponibile
Pentaho Vs Jasper
Încărcat de
mishytooDrepturi de autor:
Formate disponibile
Facultad de Ingeniera
Ingeniera en Sistemas
BI-FLOSS
Proyecto de Grado
de Almeida, Rodrigo
Heredia, Mariano
Tutor: Garca Matto, Mariano Alberto
Ttulo del Proyecto
Business Intelligence - Free/Libre Open Source Software (BI-
FLOSS)
INSTITUTO UNIVERSITARIO AERONAUTICO FACULTAD DE
INGENIERIA
Aprobado por el Departamento Sistemas en cumplimiento de los
requisitos exigidos para otorgar el Ttulo de Ingeniero en Sistemas al
Seor de Almeida, Rodrigo Guillermo DNI 30900773
Revisado por:
..............................................................
Ing. Garca Matto, Mariano Alberto
Tutor de Trabajo
..............................................................
Mag. Chiodi, Gustavo
Director Departamento Sistemas
..............................................................
Ing. Picco, Juan Eduardo
Director Dpto. Desarrollo Profesional
Tribunal Examinador:
..............................................................
Mag. Chiodi, Gustavo
Presidente del Tribunal Examinador
..............................................................
Ing. Toledo, Lus
Vocal del Tribunal Examinador
Crdoba, 25 de Abril de 2008
INSTITUTO UNIVERSITARIO AERONAUTICO FACULTAD DE
INGENIERIA
Aprobado por el Departamento Sistemas en cumplimiento de los
requisitos exigidos para otorgar el Ttulo de Ingeniero en Sistemas al
Seor Heredia, Mariano Martn DNI 30222058
Revisado por:
..............................................................
Ing. Garca Matto, Mariano Alberto
Tutor de Trabajo
..............................................................
Mag. Chiodi, Gustavo
Director Departamento Sistemas
..............................................................
Ing. Picco, Juan Eduardo
Director Dpto. Desarrollo Profesional
Tribunal Examinador:
..............................................................
Mag. Chiodi, Gustavo
Presidente del Tribunal Examinador
..............................................................
Ing. Toledo, Lus
Vocal del Tribunal Examinador
Crdoba, 25 de Abril de 2008
Dedicado especialmente a nuestros familiares, sin
ellos estas lneas nunca hubieran sido escritas; a
MAGM, instructor, gua y amigo.
Agradecemos a cada una de las personas que a lo
largo de estos 6 aos ayudaron a que hoy nos
encontremos en esta instancia. Para todos ellos
Gracias por apoyarnos y motivarnos.
Ttulo del Proyecto ..................................................................3
Introduccin..........................................................................17
Contenido del Libro ...............................................................19
Primera Parte: Inteligencia de Negocios - Conceptos Previos..... 19
Segunda Parte: Desarrollo BI-FLOSS .......................................... 19
Tercera Parte: Anexos ................................................................ 19
Licencias de Software........................................................................... 19
Carga de datos OLTP............................................................................ 20
Estructura del libro..................................................................... 20
Formato del libro ........................................................................ 20
Fragmentos de cdigo fuente................................................................. 20
Ejecucin desde lnea de comando ......................................................... 20
Notas................................................................................................. 21
Expresiones ........................................................................................ 21
Referencias y recursos................................................................ 21
Palabras Clave.......................................................................23
Abreviaturas..........................................................................25
Objetivo BI-FLOSS.................................................................27
Destinatarios.........................................................................29
Beneficios..............................................................................31
Estudio Tcnico .....................................................................33
Primera Parte: Inteligencia de Negocios - Conceptos Previos37
Inteligencia De Negocios ............................................................ 39
Definicin de Inteligencia de Negocios (Business Intelligence) .................... 39
Benecios........................................................................................... 39
Data Warehouse ......................................................................... 40
Introduccin........................................................................................ 40
Denicin ........................................................................................... 40
Arquitectura del Data Warehouse ........................................................... 40
Referencias y recursos.......................................................................... 50
Segunda Parte: Desarrollo BI-FLOSS.....................................51
Captulo I: Modelo Multidimensional........................................... 53
Planteo del caso .................................................................................. 55
Estructura del OLTP.............................................................................. 56
Productos........................................................................................ 59
Sucursales....................................................................................... 62
Clientes........................................................................................... 64
Indicadores del Negocio (KPIs) .............................................................. 65
Dimensiones de la Base de Datos Multidimensional ................................... 65
Tablas de la Base de Datos Multidimensional............................................ 65
Atributos de las Tablas de la Base de Datos Multidimensional ..................... 65
Definicin de la tabla de hechos y atributos ............................................. 69
Definicin del esquema estrella para el modelo multidimensional ................ 70
Definicin de los cubos multidimensionales necesarios .............................. 71
Referencias y Recursos......................................................................... 74
Captulo II: BigPicture................................................................ 75
Referencias y recursos.......................................................................... 78
Captulo III: Integracin de Datos
[1]
.......................................... 79
Introduccin........................................................................................ 82
Trabajando con Kettle .......................................................................... 83
Licencia........................................................................................... 85
Versin Utilizada .............................................................................. 85
Descripcin general .......................................................................... 85
Spoon............................................................................................. 85
Pan ................................................................................................ 89
Kitchen ........................................................................................... 90
Diseando Transformaciones.............................................................. 90
Diseando un Trabajo ......................................................................117
Referencias y recursos .....................................................................121
Trabajando con JasperETL....................................................................123
Introduccin ...................................................................................125
Licencia..........................................................................................125
Versin Utilizada .............................................................................125
Descripcin general .........................................................................125
GUI: Perspectivas y Vistas ................................................................125
Diseando un Modelo de Negocio.......................................................132
Diseando un Trabajo ......................................................................133
Referencias y recursos .....................................................................177
Mtodo Alternativo Para Generar la Tabla de Hechos................................179
Consideraciones previas ...................................................................181
Consecuencias de excluir los no hechos ..............................................184
Creando la tabla de hechos con Talend ...............................................184
Creando la tabla de hechos con Spoon................................................188
Resultados Obtenidos.......................................................................191
Comparativa Kettle-JasperETL ..............................................................193
Conclusin Data Integration .................................................................201
Referencias y recursos.........................................................................204
Captulo IV: OLAP ..................................................................... 205
Trabajando con Mondrian.....................................................................209
Introduccin ...................................................................................211
Licencia..........................................................................................211
Versin utilizada..............................................................................211
Arquitectura de Mondrian..................................................................211
API................................................................................................214
Diseando un Esquema Mondrian.......................................................215
Esquema definido para GONBI...........................................................222
Conexin con el esquema y ejecucin de consultas MDX .......................229
Mondrian como Servidor XMLA ..........................................................234
Ejecucin de consultas MDX..............................................................237
Referencias y recursos .....................................................................238
Conclusin OLAP.................................................................................241
Captulo V: Reportes y Consultas .............................................. 245
Trabajando con Pentaho Reporting ........................................................249
Introduccin Pentaho Reporting.........................................................251
JFreeReport ....................................................................................253
Report Design Wizard.......................................................................257
Report Designer ..............................................................................271
Adhoc Reporting..............................................................................279
Pentaho Design Studio .....................................................................281
Trabajando con Jasper Reporting ..........................................................287
Introduccin a Jasper Reporting.........................................................289
JasperReports .................................................................................291
IReport ..........................................................................................297
Comparativa Pentaho Reporting-Jasper Reporting....................................317
Tabla Comparativa...........................................................................319
Conclusin Reporting...........................................................................321
Captulo VI: Plataformas de Inteligencia de Negocios .............. 325
JPivot................................................................................................329
Trabajando con Pentaho BI-Server ........................................................331
Introduccin ...................................................................................333
Licencia..........................................................................................333
Versin utilizada..............................................................................333
Configuracin del Servidor con MySQL y Tomcat ..................................333
Probando que la configuracin funcione ..............................................346
Referencias y recursos .....................................................................351
JasperServer......................................................................................353
Introduccin ...................................................................................355
Licencia..........................................................................................355
Versin utilizada..............................................................................355
Instalacin .....................................................................................355
Tareas Administrativas .....................................................................356
Acceso a reportes y vistas de anlisis .................................................371
Referencias y recursos .....................................................................374
Comparativa Pentaho BI-Server JasperServer .........................................375
Conclusin BI Platforms .......................................................................381
Tercera Parte: Anexos .........................................................385
Anexo I : Licencias De Software ............................................... 387
Clasificacin de licencias de software .....................................................389
Licencias Propietarias.......................................................................389
Licencias Libres (de cdigo abierto)....................................................389
Licencias FLOSS .................................................................................390
Licencias de software permisivas .......................................................391
Copyleft .........................................................................................391
Licencias BI-FLOSS .............................................................................392
Referencias y recursos.........................................................................392
Anexo II: Data generator (Carga inicial de datos OLTP) ........... 393
Data Generator ..................................................................................395
GenerateData.com...........................................................................395
GONDataGenerator..........................................................................397
Referencias y recursos.........................................................................399
Anexo III: Contenido del DVD BI-FLOSS................................... 401
Viabilidad Comercial ............................................................405
Conclusin BI-FLOSS ................................................................ 407
Respecto a las Herramientas BI-FLOSS en General ..................................407
Respecto a las Herramientas Pentaho y JasperSoft ..................................407
Respecto a las licencias y las estrategias ................................................408
Bibliografa............................................................................... 409
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Introduccin
17
Introduccin
La Gestin de Conocimiento constituye un factor esencial para las
organizaciones y la mejora de sus procesos. Estas organizaciones
generan grandes volmenes de informacin producto de su operar
diario, la cual correctamente procesada puede ser de vital
importancia para la Direccin.
En un principio se desarrollaban Sistemas destinados a convertir los
datos operacionales en indicadores (casi siempre econmicos-
financieros). Este proceder fue lentamente reemplazado por el
concepto de Inteligencia de Negocio (Business Intelligence, BI), el
cual ha ido evolucionando a pasos agigantados, siempre acompaado
de la Tecnologa de la Informacin (Information Technology, IT) que
lo hace posible.
Desde la perspectiva puramente de las IT, Ibermtica
[1]
define a
Business Intelligence como:
"Conjunto de metodologas, aplicaciones y tecnologas que permiten
reunir, depurar y transformar datos de los sistemas transaccionales e
informacin desestructurada (interna y externa de la compaa) en
informacin estructurada, para su explotacin directa (reporting,
anlisis OLAP) o para su anlisis y conversin en conocimiento
soporte para la toma de decisiones sobre el negocio."
Dentro de la IT las herramientas Software desempean un rol
fundamental, es as que las principales compaas del mercado (IBM,
Oracle, Microsfot) han sostenido un desarrollo continuo de Suites de
BI que abarcan cada aspecto propuesto en la definicin anterior.
Desde hace un tiempo a esta parte, han emergido una serie de
herramientas Software con licencias no restrictivas ni privativas
provenientes de desarrollos FLOSS (Free/Libre/Open-Source
Software). Estas han ido ganando terreno en diferentes mbitos y
disciplinas, y la Inteligencia de Negocios no es la excepcin. Pentaho
Project
[2]
y JasperSoft BI
[3]
son un claro ejemplo de esto y se
presentan como unos de los principales complementos o sustitutos de
los productos comerciales ofrecidos y/o patrocinados por grandes
firmas tecnolgicas.
El presente trabajo consiste en la documentacin de un desarrollo de
Business Intelligence en el cul fueron utilizadas las herramientas
brindadas por los proyectos Pentaho y JasperSoft BI. La
documentacin incluye:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Introduccin
18
1. Conceptos previos de Inteligencia de Negocio.
2. Traduccin de fragmentos claves de documentacin oficial de
JasperSoft y Pentaho (definiciones, arquitectura, etc.).
3. Documentacin adicional, obtenida y plasmada luego del uso de
las herramientas.
4. Procedimiento paso a paso para llevar a cabo las principales
tareas que ofrecen las herramientas.
5. En aquellas reas en las cuales existen herramientas
equivalentes entre los JasperSoft y Pentaho, se ofrece una
comparativa de los aspectos ms relevantes.
6. Conclusiones referentes a las herramientas utilizadas.
La estructura del libro es la descripta a continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Contenido del Libro
19
Contenido del Libro
Primera Parte: Inteligencia de Negocios -
Conceptos Previos
En esta parte se brinda una introduccin a conceptos de Inteligencia
de Negocios cuyo entendimiento ser asumido para la lectura de la
segunda parte. Esta parte consiste en contenidos extrados del libro
DATA WAREHOUSING: Investigacin y Sistematizacin de
Conceptos
[4]
.
Segunda Parte: Desarrollo BI-FLOSS
Esta parte representa el desarrollo principal del libro, en donde se
documenta la implementacin de una solucin de Business
Intelligence, evaluando y comprando las herramientas de JasperSoft
y Pentaho utilizadas.
Los captulos involucrados son los siguientes:
1. Modelo multidimensional: Definicin de la base de datos y
cubos multidimensionales.
2. Big Picture: Un panorama general de las etapas includas en el
desarrollo junto a las herramientas utilizadas.
3. Data Integration (Load Manager): En este captulo se lleva
a cabo el diseo y ejecucin de los procesos ETL necesarios
para construir la base de datos multidimensional.
4. Servidor OLAP: Este captulo est dedicado a la construccin
del cubo multidimensional definido.
5. Reportes y Consultas: En este captulo se realizar el diseo
de los reportes OLAP.
6. Servidores de Busienss Intelligence: Captulo dedicado a la
configuracin y despliegue de portales Web de Business
Intelligence. Estos ofrecen acceso centralizado a reportes y
vistas de anlisis OLAP.
Tercera Parte: Anexos
Licencias de Software
En este anexo se realiza un panorama general del mundo de las
Licencias de Software, puntualizando los aspectos de las licencias
Free/Libre/Open-Source.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Contenido del Libro
20
Carga de datos OLTP
Este anexo documenta las tareas efectuadas y software utilizado para
la carga de la base de datos operacional la cual actuar como fuente
de datos para la construccin del Data Warehouse.
Estructura del libro
Los captulos que componen la segunda parte, estn estructurados de
la siguiente forma:
Descripcin de las herramienta
o Versin utilizada
o Licencia brindada
o Introduccin o descripcin general
o Descripcin de funcionalidad
o Uso y descripcin paso a paso de las principales tareas
con la herramienta
o Referencias y recursos
Conclusin obtenida de las secciones anteriores, junto a una
calificacin en diferentes aspectos
[5]
Formato del libro
En el libro se utilizan un conjunto de reglas para mostrar diferentes
contenidos de manera que sean resaltados:
Fragmentos de cdigo fuente
Cdigo: Cdigo Java de Ejemplo
public static void main(String []args){
System.out.println("Hola BI-FLOSS");
}
Cdigo: Cdigo Bash de Ejemplo
#!/bin/sh
HOLA_MUNDO="HOLA MUNDO"
echo "$HOLA_MUNDO" | sed s/"MUNDO"/"BI-FLOSS"/
Ejecucin desde lnea de comando
$ ./spoon.sh
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Contenido del Libro
21
Notas
Nota: Esto es una nota
Expresiones
Expresin: 1/x
Referencias y recursos
1. Definicin de Business Intelligence:
http://www.ibermatica.com/ibermatica/businessintelligence2
2. Sitio oficial de Pentaho Project: http://www.pentaho.com
3. Sitio oficial de JasperSoft BI Project:
http://www.jaspersoft.com
4. DATA WAREHOUSING: Investigacin y Sistematizacin
de Conceptos HEFESTO: Metodologa propia para la
Construccin de un Data Warehouse Ing. Bernabeu,
Ricardo Daro -Instituto Universitario Aeronutico-
Noviembre de 2007
5. Se brinda una calificacin de 1 a 5 puntos en aspectos tales
como:
o Funcionalidad: En que medida cumple con las funciones
requeridas para llevar a cabo la tarea en cuestin.
o Usabilidad: El grado de simplicidad con el cual la
herramienta permite utilizar las funcionalidad brindadas.
o Flexibilidad: Relacionado con la extensibilidad,
configuracin y personalizacin de las funciones.
o Interoperabilidad: En que medida permite
intercomunicarse o trabajar en cooperacin con otras
herramientas
o Fiabilidad: Grado en que la herramienta responde de
manera aceptable a la interaccin con el usuario.
o Eficiencia: Recursos necesarios para llevar a cabos las
tareas.
o Documentacin: Cantidad, calidad y centralizacin de
documentos instructivos sobre el uso de la herramienta.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Palabras Clave
23
Palabras Clave
Inteligencia de Negocios
Business Intelligence
Free Software
Open Source
Software Libre
JasperSoft
Pentaho
Integracin de Datos
Data Integration
Integracin de Datos
Data Warehouse
Talend
JasperETL
OLAP
Mondrian
Reportes y anlisis OLAP
JasperReports
JFreeReport
iReport
Pentaho Design Studio
Pentaho Designer
Pentaho Design Wizard
Business Intelligence Platforms
JasperServer
Pentaho BI Platform
JasperAnalysis
Pentaho Analysis
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Abreviaturas
25
Abreviaturas
BI: Business Intelligence
F/LOSS: Free/Libre Open-Source Software
ETTL: Extraccin, Transformacin, Transporte y Carga (Load)
de datos.
OLAP: On-Line analytic processing
OLTP: On-Line transactional processing
I18N: Internacionalizacin
L10N: Localizacin
DW: Data Warehouse
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Objetivo BIFLOSS
27
Objetivo BI-FLOSS
De acuerdo a lo expuesto en la introduccin del proyecto, se ha
optado por llevar a cabo una evaluacin de las herramientas ofrecidas
por los proyectos Pentaho y JasperSoft, mediante la realizacin de un
Data Warehouse basado en el Proyecto de Pre-Grado (Gua Online de
Negocios) desarrollado por los integrantes del grupo.
Los objetivos primarios del proyecto son:
1. Realizar el modelado multidimensional, correspondiente a la
perspectiva de negocio elegida para llevar a cabo el Data
Warehouse
2. Implementar el modelo anterior con las herramientas ofrecidas
por Pentaho Project y JasperSoft en las reas de:
o Data Integration
o OLAP Analysis
o Reporting
o BI-Server (BI-Platform)
3. Documentar el proceso llevado para completar los dos primeros
objetivos, obteniendo como resultado final el desarrollo y las
conclusiones plasmados en el Libro de Trabajo Final.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Destinatarios
29
Destinatarios
Debido al objetivo y las caractersticas del proyecto, no se espera
entregar los resultados obtenidos a alguna organizacin, sino que
estos puedan servir para otros desarrollos relacionados.
Se espera generar gran cantidad de documentacin sobre como
realizar un desarrollo de B.I. con estas herramientas. Como
consecuencia, la documentacin generada servir para futuros
desarrollos (propios o de terceros) de este tipo, ya que no hay gran
cantidad de informacin sobre como utilizar estas herramientas
(especialmente, hay muy poca documentacin en espaol).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Beneficios
31
Beneficios
Al tratarse de un proyecto sin una organizacin destino especfica, no
se espera que alguna se beneficie del trabajo realizado. Se ha
recolectado gran cantidad de informacin sobre el desarrollo de
soluciones BI, incluyendo informacin sobre modelado y herramientas
utilizadas.
Debido a la falta de documentacin de desarrollos BI sobre estas
herramientas, se espera que los principales beneficiarios del estudio
realizado, sean la comunidad de desarrolladores que utiliza este tipo
de herramientas. Adems se espera beneficiar a los proyectos
encargados del desarrollo y mantenimiento de las herramientas, ya
que se genera documentacin para que mayor cantidad de usuarios
pueda acceder y conocer estas tecnologas.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Estudio Tcnico
33
Estudio Tcnico
Para la eleccin de las tecnologas, se definen una serie de atributos
que deberan poseer:
Grado en que se adapta la tecnologa para el desarrollo del
sistema
o Estabilidad
o Performance
o Licenciamiento
o Precio
Los atributos se encuentran en orden decreciente de importancia, es
decir se priorizan aspectos relacionados con la productividad y no al
costo monetario o libertades y restricciones impuestos por la licencia.
Dentro de las tecnologas se distingue:
Plataforma Software:
o Sistema Operativo: En este aspecto, se elige como la
mejor solucin un sistema operativo estilo Unix por mejor
prestaciones en los tres primeros atributos. Teniendo en
cuenta los ltimos dos, es que se decide por un SO
GNU/Linux.
o Servidores Web: Por razones idnticas a las expuestas
para SO, se eligen servidores con licencia Apache
(Tomcat).
o Sistema de Gestin de Base de Datos: Las opciones
que mejor se adaptan a los atributos descriptos y
herramientas utilizadas en el desarrollo, son los motores
de base de datos PostgreSQL 8.1 y MySQL 5.0.
Tecnologas BI:
o De acuerdo a estos atributos, es que se elige para el
desarrollo del trabajo las tecnologas BI Open Source
provistas por Pentaho y JasperSoft.
Recursos tecnolgicos necesarios para el desarrollo del proyecto:
Requerimientos Mnimos de hardware para el desarrollo del
sistema:
o 1 PC:
CPU Intel Pentium IV 2.4 Mhz o similar
512 MB RAM
Disco Duro con al menos 10 GB libre
CD-RW y DVD-RW
Monitor SVGA 1024x768 de Resolucin
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Estudio Tcnico
34
Requerimientos Mnimos de Software:
o GNU/Linux con kernel 2.6.*, Windows 2000 o superior
o Java(tm) JDK
o OpenOffice 2.0
Requerimientos Mnimos de hardware para servidor
o 1 PC
o CPU Intel Pentium IV 2.6 Mhz o similar
o 1 GB RAM
o Disco Duro con al menos 60 GB libre
o CD-RW y DVD-RW
Requerimientos Mnimos de Software para el servidor:
o GNU/Linux con kernel 2.6.*, Windows 2000 server o
superior
o Java(tm) JDK
o Web Server
o CVS server
o Application Server
o Proxy y Firewall
o SGBD
Recursos tecnolgicos (infraestructura) necesarios para
ejecutar el sistema de informacin:
Debido a que las herramientas BI utilizadas utilizan tecnologas WEB,
se especifican las caractersticas necesarias tanto de un cliente como
un servidor.
Requerimientos Mnimos de hardware para el lado del servidor:
dem a las caractersticas para el desarrollo. Adicionalmente se
necesitar una conexin estable que brinde disponibilidad y tiempos
de respuestas rpidos de acuerdo a la concurrencia y peticiones de
usuarios.
Requerimientos Mnimos de hardware para el lado del cliente:
Cualquier plataforma capaz de soportar el software descrito a
continuacin
Requerimientos Mnimos de Software:
o Conexin a Internet
o Cualquier navegador con:
o JavaScript habilitado
o Capacidad de conexiones sobre SSL/TLS
o Gestin de Certificados X.509
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Estudio Tcnico
35
Recursos tecnolgicos disponibles para el desarrollo del
sistema:
o Hardware disponible para el desarrollo:
PC Pentium IV, CPU de 3,2 Ghz HT
Memoria 1 GB RAM
Disco Duro de 80GB
Disco Duro de 160GB
CD/DVD-ROM
Monitor 22 SVGA 1680x1050 de Resolucin
2 Placa de red (NIC) de 10/100 Mbps
PC Pentium IV, CPU de 3,2 Ghz HT
Memoria 1 GB RAM
2 Disco Duro de 80GB
CD/DVD-ROM
Monitor 17 SVGA 1024x768 de Resolucin
2 Placa de red (NIC) de 10/100 Mbps
Software disponible para desarrolladores:
o SO GNU/Linux Ubuntu 7.04 - Gentoo 2007.0
o JDK 1.5.0_09
o PostgreSQL 8.1
o PGAdmin
o MySQL Query Browser
o DBVisualizer 5.0
o MySQL 5.0
o Eclipse Platform 3.3
o Spoon 3.0 (Pentaho Data Integration 3.0)
o Talend Open Studio 2.2.0GA
o iReport 2.0.4
o Pentaho Report Design Wizard 1.6
o Pentaho Report Designer 1.6
o Pentaho Design Studio 1.6
o Mondrian 2.4.2
o Mondrian Schema Workbench 2.3.2.9247
Hardware disponible para servidores:
o PC Pentium IV, CPU de 3,2 Ghz HT
o Memoria 1 GB RAM
o Disco Duro de 80GB
o Disco Duro de 160GB
o CD/DVD-ROM
o Monitor 22 SVGA 1680x1050 de Resolucin
o 2 Placa de red (NIC) de 10/100 Mbps
Software disponible para servidores:
o GNU/Linux Debian 3.1
o JDK 1.5.12
o Apache Tomcat
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Estudio Tcnico
36
o Apache Web Server
o PostgreSQL 8.1
o MySQL 5.0
o Mondrian 2.4.2
o JasperServer 2.1.0
o Pentaho BI Platform 1.6
o CVS Server
o Samba Server
o Proxy Server: Squid
o Firewall: Shorewall (Iptables)
Hardware Lan y Wan:
o Cisco 677 ADSL Router
o Linksys WRT300N - Wireless-N Broadband Router
Primera Parte: Inteligencia de
Negocios - Conceptos Previos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
39
Inteligencia De Negocios
En esta seccin se brindar la introduccin a algunos conceptos
referentes a Inteligencia de Negocios que se asumen comprendidos a
lo largo de las secciones posteriores. El contenido de esta seccin,
corresponde a extractos del libro DATA WAREHOUSING: Investigacin
y Sistematizacin de Conceptos
[1]
Definicin de Inteligencia de Negocios
(Business Intelligence)
Se puede describir BI, como un concepto que integra por un lado el
almacenamiento y por el otro el procesamiento de grandes
cantidades de datos, con el principal objetivo de transformarlos en
conocimiento y en decisiones en tiempo real, a travs de un sencillo
anlisis y exploracin. La denicin antes expuesta puede
representarse a travs de la siguiente frmula:
Datos+Analisis=Conocimiento
Benecios
Entre los beneficios ms importantes que BI proporciona a las
organizaciones, vale la pena destacar los siguientes:
Reduce el tiempo mnimo que se requiere para recoger toda la
informacin relevante del negocio, ya que la misma se
encontrar integrada en una fuente nica de fcil acceso.
Automatiza la asimilacin de la informacin, debido a que la
extraccin y carga de los datos necesarios se realizar a travs
de procesos predenidos.
Proporciona herramientas de anlisis para establecer
comparaciones y tomar decisiones.
Cierra el crculo que hace pasar de la decisin a la accin.
Permite a los usuarios no depender de reportes o informes
programados, porque los mismos sern generados de manera
dinmica.
Posibilita la formulacin y respuesta de preguntas que son
claves para el desempeo de la empresa.
Permite acceder y analizar directamente los indicadores de
xito.
Se pueden identicar cules son los factores que inciden en el
buen o mal funcionamiento de la empresa.
Se podrn detectar situaciones fuera de lo normal.
Se encontrarn y/o descubrirn cules son los factores que
maximizarn el benecio.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
40
Permitir predecir el comportamiento futuro con un alto
porcentaje de certeza, basado en el entendimiento del pasado.
El usuario podr consultar y analizar los datos de manera
sencilla.
Data Warehouse
Introduccin
Debido a que para llevar a cabo BI, es necesario gestionar datos
guardados en diversos formatos, fuentes y tipos, para luego
depurarlos e integrarlos, adems de almacenarlos en un solo destino,
depsito o base de datos que permita su posterior anlisis y
exploracin, es imperativo y de vital importancia contar con una
herramienta que satisfaga todas estas necesidades. Esta herramienta
es el Data Warehouse (DW), que bsicamente se encarga de
consolidar, integrar y centralizar los datos que la empresa genera en
todos los mbitos de una actividad de negocios (Compras, Ventas,
Produccin, etc), para luego ser almacenados mediante una
estructura que permite el acceso y exploracin de la informacin
requerida con buena performance, facilitando posteriormente, una
amplia gama de posibilidad de anlisis multivariables, que permitir
la toma de decisiones estratgicas y tcticas.
Denicin
El DW posibilita la extraccin de datos de sistemas operacionales y
fuentes externas, permite la integracin y homogeneizacin de los
datos de toda la empresa, provee informacin que ha sido
transformada y sumarizada, para que ayude en el proceso de toma
de decisiones estratgicas y tcticas. El DW, convertir entonces los
datos operacionales de la empresa en una herramienta competitiva,
debido a que pondr a disposicin de los usuarios indicados la
informacin pertinente, correcta e integrada, en el momento que se
necesita. Una de las deniciones ms famosas sobre DW, es la de W.
H. Inmon, quien dene: Un Data Warehouse es una coleccin de
datos orientada al negocio, integrada, variante en el tiempo y no
voltil para el soporte del proceso de toma de decisiones de la
gerencia.
Arquitectura del Data Warehouse
Introduccin
A travs del siguiente grco se explicitar la estructura del depsito
de datos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
41
Data Warehouse, arquitectura
Tal y como se puede apreciar, el ambiente del depsito de datos esta
formado por diversos elementos que interactan entre s y que
cumplen una funcin especca dentro del sistema. Por ello es que al
abordar la exposicin de cada elemento se lo har en forma ordenada
y teniendo en cuenta su relacin con las dems partes.
Bsicamente, la forma de operar del esquema superior se resume de
la siguiente manera:
Los datos son extrados desde aplicaciones, bases de datos,
archivos, etc. Esta informacin generalmente reside en
diferentes tipos de sistemas y arquitecturas y tienen formatos
muy variados.
Los datos son integrados, transformados y limpiados, para
luego ser cargados en el DW.
La informacin del DW se estructura en cubos
multidimensionales, los cuales preparan esta informacin para
responder a consultas dinmicas con una buena performance.
Los cubos pueden ser explotados tanto por un usuario no
experto como por usuarios avanzados.
Los usuarios acceden al DW utilizando diversas herramientas de
consulta, exploracin, anlisis, reportes, etc.
A continuacin se detallar cada uno de los componentes de la
arquitectura del DW, teniendo como referencia siempre el grco
antes expuesto, pero resaltando el tema que se tratar.
OLTP (On Line Transaction Processing)
Representa toda aquella informacin transaccional que genera la
empresa en su accionar diario, adems, de las fuentes externas con
las que puede llegar a disponer. Como ya se ha mencionado, estas
fuentes de informacin, son de caractersticas muy dismiles entre s,
en formato, procedencia, funcin, etc. Entre los OLTP ms habituales
que pueden existir en cualquier organizacin se encuentran:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
42
Archivos de textos.
Hipertextos.
Hojas de clculos.
Informes semanales, mensuales, anuales, etc.
Bases de datos transaccionales.
Load Manager (ETL)
Para poder extraer los datos desde los OLTP, para luego
manipularlos, integrarlos y transformarlos, para posteriormente
cargar los resultados obtenidos en el DW, es necesario contar con
algn sistema que se encargue de ello. Precisamente los ETL
(Extraccin, Transformacin y Carga) son los que cumplirn con tal
n. Tal y como sus siglas lo indican, los ETL, extraen datos de las
diversas fuentes que se requieran, los transforman para resolver
posibles problemas de inconsistencias entre los mismos y nalmente,
despus de haberlos depurado se procede a su carga en el depsito
de datos.
En sntesis, las funciones especcas de los ETL son tres:
Extraccin.
Transformacin.
Carga.
Puede agregarse una T (Transporte) resultando en ETTL.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
43
Data Warehouse Manager
Data Warehouse, DW Manager
El DW Manager presenta las siguientes caractersticas y funciones:
Transforma e integra los datos fuentes y del almacenamiento
intermedio en un modelo adecuado para la toma de decisiones.
Gestiona el depsito de datos y lo organiza en torno a una base
de datos multidimensional, que tal y como lo indica su nombre
almacena los datos en diversas dimensiones, que conforman un
cubo multidimensional, en donde el cruce de los valores de los
atributos de cada dimensin a lo largo de las abscisas,
determinan un hecho especfico. Los clculos que se aplican
sobre las dimensiones son matriciales, los cuales se procesan
dando como resultado reportes tabulares.
Gestiona y mantiene metadatos.
Base de datos multidimensional
Las bases de datos multidimensionales, proveen una estructura que
permite tener acceso exible a los datos, para explorar y analizar sus
relaciones, y resultados consiguientes. Estas se pueden visualizar
como un cubo multidimensional, en donde las variables asociadas
existen a lo largo de varios ejes o dimensiones, y la interseccin de
las mismas representa la medida, indicador o el hecho que se esta
evaluando. En la siguiente representacin matricial se puede ver ms
claramente lo que se acaba de decir.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
44
Cubo multidimensional
Las bases de datos multidimensionales implican tres variantes
posibles de modelado, que permiten realizar consultas de soporte de
decisin:
Esquema en estrella (Star Scheme).
Esquema copo de nieve (Snowake Scheme).
Esquema constelacin o copo de estrellas (Starake Scheme).
Los mencionados esquemas pueden ser implementados de diversas
maneras, que, independientemente al tipo de arquitectura, requieren
que toda la estructura de datos este desnormalizada o semi
desnormalizada, para evitar desarrollar uniones (Join) complejas para
acceder a la informacin, con el n de agilizar la ejecucin de
consultas. Los diferentes tipos de implementacin son los siguientes:
Relacional ROLAP
Multidimensional MOLAP
Hbrido HOLAP
Tabla de dimensiones
Las tablas de dimensiones denen como estn los datos organizados
lgicamente y proveen el medio para analizar el contexto del negocio.
Representan los ejes del cubo, y los aspectos de inters, mediante los
cuales el usuario podr ltrar y manipular la informacin almacenada
en la tabla de hechos. En la siguiente gura se pueden apreciar
algunos ejemplos:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
45
Tablas de dimensiones
Como se puede observar, cada tabla posee un identicador nico y al
menos un atributo que describe los criterios de anlisis relevantes de
la organizacin, estos son por lo general de tipo texto. Usualmente la
cantidad de tablas de dimensiones, aplicadas a un tema de inters en
particular, varan entre tres y quince. As mismo, dentro de estas
tablas pueden existir jerarquas11 de datos, adems, de acuerdo a
las dimensiones del negocio, estar dada la granularidad que
adoptar el modelo. Los datos dentro de estas tablas, que proveen
informacin del negocio o que describen alguna de sus
caractersticas, son llamados datos de referencia. Entonces, se puede
armar que una tabla de dimensin posee una clave primaria y uno o
ms datos de referencia.
Dimensin Tiempo
En un DW, la dimensin Tiempo es obligatoria, y la denicin de
granularidad y jerarqua de la misma depende de la dinmica del
negocio que se este analizando, toda la informacin dentro de la
bodega, como ya se ha explicado, posee su propio sello de tiempo
que determina la ocurrencia y ubicacin con elementos en iguales
condiciones, representando de esta manera diferentes versiones de
una misma situacin. Es importante tener en cuenta que el tiempo no
es solo una secuencia cronolgica representada de forma numrica,
sino que posee fechas especiales que inciden notablemente en las
actividades de la organizacin. Esto se debe a que los usuarios
podrn por ejemplo analizar las ventas realizadas teniendo en cuenta
el da de la semana en que se produjeron, quincena, mes, trimestre,
semestre, ao, etc. Existen muchas maneras de disear esta tabla, y
en adicin a ello no es una tarea sencilla de llevar a cabo. Por estas
razones se considera una buena prctica evaluar con cuidado la
temporalidad de los datos, la forma en que trabaja la organizacin,
los resultados que se esperan obtener del almacn de datos
relacionados con una unidad de tiempo y la exibilidad que se desea
obtener de dicha tabla. Si bien, el lenguaje SQL ofrece funciones del
tipo DATE, en la dimensin Tiempo, se modelan y presentan atributos
temporales que no pueden calcularse en SQL, lo cual le aade una
ventaja ms.
Jerarquas
Una jerarqua representa una relacin12 lgica entre dos o ms
atributos dentro de una misma dimensin. Las jerarquas poseen las
siguientes caractersticas
Pueden existir varias en una misma dimensin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
46
Estn compuestas por dos o ms niveles.
Se tiene una relacin 1-n entre atributos consecutivos de un
nivel superior y uno inferior.
Tablas de Hechos
Las tablas de hechos contienen los hechos, medidas o indicadores
que sern utilizados por los analistas de negocio para apoyar el
proceso de toma de decisiones.
Los hechos son datos instantneos en el tiempo, que son ltrados,
agrupados y explorados a travs de condiciones denidas en las
tablas de dimensiones.
Los datos presentes en las tablas de hechos constituyen el volumen
de la bodega, y pueden estar compuestos por millones de registros
dependiendo de su granularidad y de los intervalos de tiempo de los
mismos. Los ms importantes son los de tipo numrico.
El registro del hecho posee una clave primaria que est compuesta
por las claves primarias de las tablas de dimensiones relacionadas a
este.
Query Manager
Query Manager
Este componente realiza las operaciones necesarias para soportar los
procesos de gestin y ejecucin de consultas relacionales, tales como
Join y agregaciones, y de consultas propias del anlisis de datos,
como drill-up y drill-down. Query Manager recibe las consultas del
usuario, las aplica a las tablas correspondientes y devuelve los
resultados obtenidos. Cabe aclarar que una consulta a un DW,
generalmente consiste en la obtencin de medidas o indicadores a
partir de datos de una tabla de hechos, restringidas por las
propiedades o condiciones de las dimensiones seleccionadas. Las
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
47
operaciones que se pueden realizar sobre modelos
multidimensionales y que son las que verdaderamente les permitirn
a los usuarios explorar y desmenuzar los datos en busca de
respuestas, son:
Drill-down: Permite apreciar los datos en un mayor detalle,
bajando por la jerarqua de una dimensin. Esto brinda la
posibilidad de introducir un nuevo nivel o criterio de agregacin
en el anlisis, disgregando los grupos actuales.
Drill-up: Permite apreciar los datos en menor nivel de detalle,
subiendo por la jerarqua de una dimensin. Esto brinda la
posibilidad de quitar un nivel o criterio de agregacin en el
anlisis, agregando los grupos actuales.
Drill-across: Es muy similar al funcionamiento de drill-down,
con la diferencia de que drill-across no se realiza sobre
jerarquas de una dimensin, sino que su forma de ir de lo
general a lo especfico es agregar como nuevo criterio de
anlisis una nueva dimensin.
Roll-across: Es muy similar al funcionamiento de drill-up, con la
diferencia de que roll-across no se hace sobre jerarquas de una
dimensin, sino que su forma de ir de lo especco a lo general
es quitar un criterio de anlisis eliminando de la consulta una
dimensin.
Pivot: Permite seleccionar el orden de visualizacin de las
dimensiones, con el objetivo de analizar la informacin desde
diferentes perspectivas.
Page-Slice: Presenta el cubo dividido en secciones, a travs de
los valores de una dimensin, como si se tratase de pginas de
un libro.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
48
Herramientas de Consulta y Anlisis
Herramientas de Consulta y Anlisis
Las herramientas de consulta y anlisis son sistemas que permiten al
usuario realizar la exploracin de datos del DW. Bsicamente
constituyen el nexo entre el depsito de datos y los usuarios. A travs
de una amigable interfaz grca y una serie de simples pasos, el
usuario genera consultas que son enviadas desde la herramienta de
consulta y anlisis al Query Manager, este a su vez realiza la
extraccin de informacin al DW Manager y devuelve los resultados
obtenidos a la herramienta que se los solicit. Luego, estos
resultados son expuestos ante el usuario en formatos que le son
familiares. Este proceso se puede comprender mejor al observar la
siguiente gura:
El mismo, se lleva a cabo a travs de seis pasos sucesivos:
1. El usuario selecciona o establece que datos desea obtener del
DW, mediante las interfaces de la herramienta que utilice.
2. La herramienta recibe el pedido del usuario, construye la
consulta y la enva al Query Manager.
3. El Query Manager ejecuta la consulta en las tablas del DW.
4. El Query Manager obtiene los resultados de la consulta.
5. El Query Manager enva los datos a las herramientas de
consulta y anlisis.
6. Las herramientas presentan al usuario la informacin requerida.
Una de las principales ventajas de utilizar estas herramientas, es que
los usuarios no se tienen que preocupar por conocer cual es la
estructura de los datos, solo se deben enfocar en el anlisis. Existen
diferentes tipos de herramientas de consulta y anlisis, y de acuerdo
a la necesidad, tipos de usuarios y requerimientos del negocio, se
debern seleccionar las ms propicias al caso. Entre ellas se destacan
las siguientes:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
49
Reportes y Consultas
OLAP
Data Mining
EIS
Reportes y Consultas
Se han desarrollado varias herramientas para la produccin de
consultas y reportes, que ofrecen a los usuarios, a travs de pantallas
grcas intuitivas, la posibilidad de generar informes avanzados y
detallados del rea de inters del negocio que se este analizando. El
usuario solo debe seguir una serie de simples pasos, como por
ejemplo seleccionar opciones de un men, presionar tal o cual botn
para especicar los elementos de datos, sus condiciones, criterios de
agrupacin y dems atributos que se consideren signicativos.
OLAP
El procesamiento analtico en lnea OLAP (On Line Analytic
Processing), es la componente ms poderosa de los DW, ya que es el
motor de consultas especializado de la bodega.
Las herramientas OLAP, son una tecnologa de software para anlisis
en lnea, administracin y ejecucin de consultas, que permiten
inferir informacin del comportamiento del negocio.
Su principal objetivo es el de brindar rpidas respuestas a complejas
preguntas, para interpretar la situacin del negocio y tomar
decisiones. Cabe destacar que lo que es realmente interesante en
OLAP, no es la ejecucin de simples consultas tradicionales, sino la
posibilidad de utilizar operadores tales como drill-up, drill-down, etc,
para explotar profundamente la informacin.
Adems, a travs de este tipo de herramientas, se puede analizar el
negocio desde diferentes escenarios histricos, y proyectar como se
ha venido comportando y evolucionando en un ambiente
multidimensional, o sea, mediante la combinacin de diferentes
perspectivas, temas de inters o dimensiones. Esto permite deducir
tendencias, por medio del descubrimiento de relaciones entre las
perspectivas que a simple vista no se podran encontrar
sencillamente.
Usuarios
Los usuarios que posee el DW son aquellos que se encargan de tomar
decisiones y de planicar las actividades del negocio, es por ello que
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conceptos Previos Sobre Business Intelligence
50
se hace tanto nfasis en la integracin, limpieza de datos, etc, para
poder conseguir que la informacin posea toda la calidad posible.
Es a travs de las herramientas de consulta y anlisis, que los
usuarios exploran los datos en busca de respuestas para poder tomar
decisiones proactivas.
Referencias y recursos
1. DATA WAREHOUSING: Investigacin y Sistematizacin
de Conceptos HEFESTO: Metodologa propia para la
Construccin de un Data Warehouse Ing. Bernabeu,
Ricardo Daro -Instituto Universitario Aeronutico-
Noviembre de 2007
Segunda Parte: Desarrollo BI-
FLOSS
Captulo I: Modelo Multidimensional
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
55
Planteo del caso
El Sistema GON agrupa mltiples negocios, correspondientes a
diferentes rubros, con sus correspondientes sucursales en
diferentes zonas geogrficas. Los dueos o administradores de
negocios tienen la capacidad de registrar los productos y promociones
ofrecidas. Un Usuario Externo ingresa al sistema y realiza
bsquedas de negocios o productos; los negocios son consultados por
el UE quien en determinados casos efecta rdenes de productos.
Para obtener una definicin ms amplia de la estructura y
funcionamiento de GON, puede consultarse la seccin Inicio de la
documentacin del proyecto
[1]
.
GON es un Sistema que posee cualidades que lo convierten en una
fuente potencial de informacin estratgica para diferentes niveles de
usuarios. Entre estos usuarios encontramos:
1. Nivel dirigencial GON: para aquellos directivos involucrados
en la explotacin del Sistema, resulta de vital importancia
mantener una visin de cmo evoluciona y crece el conjunto de
Negocios Adheridos desde diferentes perspectivas tales como:
o Zona geogrfica de los negocios que se adhieren.
o Rubros o rama comercial de los negocios.
o Perodo temporal en que se adhieren los negocios.
2. Nivel dirigencial de Negocios Adheridos: estos encuentran
esencial obtener una nocin detallada acerca del
funcionamiento de sus negocios a partir del momento en que se
han convertido en parte del compendio de negocios que
comprende GON. La informacin ser referente a cmo variaron
los productos vendidos desde diversas perspectivas, entre ellas:
o Clientes que realizan pedidos
o Perodo temporal
o Tipos o marcas de los productos pedidos
o Sucursal que recibe el pedido.
3. Nivel directivo de grandes marcas y productos: la
informacin relevante estar relacionada con la forma con que
sus productos son pedidos, teniendo en cuenta perspectivas
significativas como:
o Zona geogrfica
o Informacin del consumidor o comprador
o Detalle y descripcin de productos
o Perodo temporal en que los productos son pedidos
Para desarrollar el caso prctico, se seleccion el nivel dirigencial de
Negocios Adheridos. Los directivos de negocios adheridos necesitan
responder a preguntas tales como:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
56
Que cantidad de productos han sido vendidos por una
sucursal?
Por qu monto un negocio ha efectuado ventas en un lapso
determinado?
En que medida influye la ubicacin geogrfica de las
sucursales en las ventas?
Cmo han evolucionado las ventas de una sucursal en
diferentes perodos?
Cmo influye la edad, el sexo y la ubicacin de los clientes en
adquisicin de diferentes productos?
Estructura del OLTP
Se observa a continuacin el Diagrama Entidad Relacin del OLTP
GON.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
57
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
58
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
59
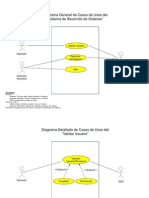
Diagrama Entidad-Relacin de GON
En la imagen anterior observamos resaltadas el diagrama completo
de entidades. A continuacin se ofrecen secciones del mismo
diagrma, dnde se pueden apreciar entidades referentes a
productos, sucursales y clientes:
Productos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
60
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
61
Entidades propias de productos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
62
Sucursales
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
63
Entidades relacionadas a sucursales
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
64
Clientes
1
Entidades referentes a clientes
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
65
Indicadores del Negocio (KPIs)
Monto total de las ventas
Cantidad de productos vendidos
Dimensiones de la Base de Datos
Multidimensional
1. Sucursales: Los productos ordenados por los clientes varan
en funcin de las distintas sucursales de los Negocios
Adheridos.
2. Clientes: Los productos ordenados varan en funcin de los
distintos clientes.
3. Tiempo: Los pedidos de un producto varan en funcin de los
distintos espacios temporales.
4. Productos: La orden de un producto vara en funcin de sus
caractersticas.
5. Estado de orden: Las rdenes pueden presentar dos estados
opuestos: Concretada/Finalizada o Cancelada. Lo cual afecta el
anlisis final de los indicadores.
Tablas de la Base de Datos Multidimensional
lookup_branches
lookup_clients
lookup_products
lookup_time
Atributos de las Tablas de la Base de Datos
Multidimensional
lookup_branches
branch_id
name
legal_name
legal_id
category
heading
since_date
continent
country
state
city
zone
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
66
street
street_number
floor_number
apartment_number
zipcode
email
phonenumber
fax
Dimensin Sucursales
lookup_clients
cliente_id
username
name
last_name
registration_date
gender
birthdate
continent
country
state
city
zone
street
street_number
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
67
floor_number
apartment_number
email
phonenumber
Dimensin Clientes
lookup_products
product_id
name
category
heading
product_type
product_type_description
general_description
particular_description
busiens_description
branch_seller_id
brand
brand_nationality
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
68
Dimensin Productos
lookup_time
year
quarter
month
month_name
week
weekday
weekday_name
Dimensin Tiempo
lookup_orderstate
state
Esta ltima dimensin ser implementada como una dimensin
degenerada
[2]
; al no presentar demasiada complejidad jerrquica, y
slo contar con dos miembros en su nivel raz, se aadir como
campo a la tabla de hechos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
69
Definicin de la tabla de hechos y atributos
Nombre: orders_fact
Medidas:
1. Nmero de pedidos
2. Monto en dinero total de pedidos
Tabla de hechos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
70
Definicin del esquema estrella para el modelo
multidimensional
Esquema Estrella
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
71
Definicin de los cubos multidimensionales
necesarios
Se define el cubo rdenes cuya tabla de hechos es orders_fact, y sus
dimensiones junto a jerarquas, niveles y propiedades se listan a
continuacin:
Dimensin tiempo
Dimensin y jerarquas tiempo
Dimensin sucursales
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
72
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
73
Dimensin y jerarquas de sucursales
Dimensin cliente
Dimensin y jerarquas de clientes
Dimensin producto
Dimensin y jerarquas de productos
Dimensin estado de orden
Dimensin y jerarquas de estado de orden
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Modelo Multidimensional
74
Referencias y Recursos
1. Seccin inicio del libro Gua de Negocios Online. Trabajo Final
de Pre-Grado de Almeida, Rodrigo - Heredia, Mariano. Abril de
2008
2. Ver Seccin Servidor OLAP de la parte Desarrollo
Captulo II: BigPicture
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Big Picture
77
Antes de dar inicio al desarrollo del presente trabajo se ilustrarn las
etapas involucradas
[1]
, junto a las herramientas utilizadas en cada
una de ellas. En el diagrama las etapas son ubicadas desde abajo
hacia arriba de acuerdo a los productos obtenidos; en un nivel dado
sern utilizadas como inputs o entradas las salidas o outputs de
niveles inferiores.
BigPicture - Un panorama general
Modelo de Negocio: se obtendrn los lineamientos generales
para llevar a cabo los pasos posteriores junto a su secuencia.
Representa slo un modelo conceptual como gua a lo largo del
desarrollo.
Load Manager (E.T.L.): se generar la base de datos del
Data Warehouse y en ella se depositarn lo datos integrados
provenientes de fuentes OLTP.
Servidor OLAP: en base a las tablas dimensionales y de
hechos, se construirn los cubos multidimensionales que
podrn ser consultados mediante sentencias MDX.
Reportes y consultas: utilizando la fuente de datos OLAP y
consultas MDX se crearn los reportes pertinentes.
Servidor de Business Intelligence: los reportes generados
sern alojados en un servidor centralizado accesible para los
usuarios involucrados. Desde estos servidores se podrn crear
anlisis olap descriptos mediante sentencias MDX.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Big Picture
78
Servidores de Anlisis Olap: Desde estos se podr ejecutar
los anlisis generados anteriormente. La ejecucin de estos
anlisis permiten la interaccin por parte del usuario, realizando
operaciones de Query Manager como drill-down, pivot, slice,
page, etc.
Referencias y recursos
Ver Parte Conceptos Previos de Inteligencia de Negocios
Captulo III: Integracin de Datos
[1]
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Integracin de Datos
81
El diagrama general del desarrollo de BI-FLOSS servir para tener
una idea de los temas a desarrollar:
Temas a desarrollar
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Integracin de Datos
82
Introduccin
En la siguiente seccin se llevarn a cabo las transformaciones
necesarias para poblar el Data Warehouse y se brinda una
descripcin de las herramientas y pasos involucrados en el proceso.
Como mtodo para el diseo conceptual, se utiliza el Modelado
Dimensional de la seccin anterior
[2]
, mientras que para el diseo
lgico y fsico se utilizan las herramientas brindadas por las Suite
Pentaho BI Project
[3]
y JasperSoft
[4]
(Talend
[5]
). Con cada
herramienta se llevarn a cabo las actividades necesarias para
obtener la misma Base de Datos del Data Warehouse, documentando
los principales pasos involucrados. Al final de esta seccin se ofrece
una tabla comparativa de las caractersticas ms importantes de
ambas herramientas.
Trabajando con Kettle
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
85
Licencia
Kettle (Pentaho Data Integration) se licencia bajo Pentaho Public
Licence
[1]
.
Versin Utilizada
Pentaho Data Integration 3.0 RC1
Descripcin general
Kettle (Kettle E.T.T.L. Environment) es una herramienta de
Extraccin, Transformacin, Transporte y Carga (Load) de datos,
orientada a metadatos de la suite de Business Intelligence Pentaho.
En simples palabras, es la herramienta utilizada para la carga de un
Data Warehouse. Kettle, esta compuesto por un conjunto de
herramientas que le permiten manipular datos provenientes de
diversas fuentes de datos. Estas son:
Spoon: Herramienta grfica destinada a disear
transformaciones y trabajos. La herramienta permite al usuario
describir que es lo que se quiere hacer y no como hacerlo
(diseo de SW de 4ta generacin).
Pan: Interpreta y ejecuta transformaciones diseadas con
Spoon.
Kitchen: Interpreta y ejecuta trabajos diseados con Spoon.
Spoon
Spoon es la herramienta grfica que permite disear
transformaciones (transformations) y trabajos (jobs). Esta facilita
en gran medida el desarrollo de los procesos ETTL, ya que mediante
un conjunto de pasos se puede fcilmente definir como se quieren
realizar las transformaciones y ejecutarlas mediante trabajos.
Antes de introducirse en las caractersticas de Spoon, es menester
resaltar la diferencia entre transformaciones y trabajos:
Transformaciones: Estn relacionadas con el movimiento y
modificacin de datos desde una fuente origen, a un destino de
datos.
Trabajos: Representan tareas de alto nivel. Cada entrada del
trabajo puede ser, por ejemplo, ejecutar una transformacin,
enviar un correo electrnico, subir un archivo va ftp, etc.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
86
Spoon est destinado a la creacin de transformaciones y trabajos los
cuales sern almacenados en formato XML o en un repositorio
Kettle. El repositorio no es ms que una base de datos relacional,
por lo que, para almacenar u obtener una transformacin se debe
previamente establecer una conexin con el mismo.
Definiciones
Como paso previo para disear transformaciones y trabajos, es
preciso introducir las definiciones de los elementos que involucran:
Transformaciones
Valor (Value): un valor es parte de una fila, y puede ser
cualquier tipo de dato.
Fila (Row): en una fila existen 1 o ms valores.
Flujo de Salida (Output Stream): una coleccin de filas
como producto de un paso dado.
Flujo de Entrada (Input Stream): una coleccin de filas que
ingresa en un paso dado.
Salto (Hop): es una representacin grfica del flujo de datos
entre dos pasos. Siempre representa un flujo de salida de un
paso y un flujo de entrada en otro paso.
Nota (Note): informacin adicional de una transformacin.
Trabajos
Entrada del trabajo (Job Entry): es una parte del trabajo y
lleva a cabo una transformacin.
Salto (Hop): representacin grfica de uno o ms flujos de
datos entre dos pasos. Representa el enlace entre dos entradas
del trabajo y puede ser asignado (dependiendo del tipo de
trabajo origen) para ejecutar la prxima entrada del trabajo de
forma incondicional, despus de una ejecucin exitosa o fallida.
Nota (Note): informacin adicional del trabajo.
Nota: Para informacin detallada de Spoon, u otro
componente de Kettle o Pentaho, leer el manual
correspondiente que acompaa a cada producto.
GUI: Descripcin general
En la siguiente imagen se observan los principales componentes que
se encuentran en la herramienta Spoon.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
87
Vista general de Spoon
A continuacin se observa con mayor detalle los elementos
principales que componen la transformacin o trabajo que se
estn editando (en este caso una transformacin). Los
elementos principales de este rbol son:
Las distintas conexiones a bases de datos que se usan en la
transformacin.
Los distintos pasos que conforman la transformacin.
Los distintos saltos que unen los pasos de la transformacin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
88
rbol principal
Esta imagen muestra los distintos pasos que pueden seleccionarse
para incluirse en la transformacin. Spoon organiza estos pasos en
base a la funcin que cumplen. Por ejemplo los pasos relacionados
con lectura de datos de alguna fuente son agrupados bajo la
categora Input. En la ultima parte de la imagen puede apreciarse la
seccin Favorite steps en donde se agrupan los pasos mas usados,
esto permite al usuario ahorrar tiempo al seleccionar los pasos que
desea incluir en una transformacin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
89
Objetos
Pan
Como ya se menciona anteriormente, permite ejecutar
transformaciones diseadas por Spoon desde un repositorio o un
archivo XML. Pan no posee una interfaz grfica que permita al usuario
ejecutar las transformaciones, sino que deben ejecutarse mediante
una lnea de comandos. Spoon facilita el trabajo ya que una vez
definida una transformacin, puede ser ejecutada directamente desde
all. Adems de ejecutar transformaciones, Pan, permite
planificarlas para que se ejecuten segn las necesidades del
usuario. Las transformaciones pueden ser ejecutadas desde un
archivo o un repositorio:
Ejemplo desde un archivo:
pan.sh -file="/gon/branchesTransformation.ktr" -
level=Minimal
Ejemplo desde un repositorio:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
90
pan.sh -rep="SpoonRep" -trans="branchesTransformation" -
dir="/dimensions/" -user="username" -
pass="somepassword" level="Minimal"
Kitchen
Kitchen permite ejecutar trabajos diseados por Spoon desde un
repositorio o un archivo XML. Al igual que Pan, Kitchen no posee una
interfaz grfica que permita ejecutar trabajos, sino que deben
ejecutarse desde una lnea de comandos. Spoon facilita esta tarea
permitiendo ejecutar los trabajos que estn siendo diseados desde
la GUI. Kitchen tambin posee la capacidad de planificar la ejecucin
de trabajos, para ello por ejemplo (en Unix), puede crearse un Script
que ejecute el trabajo y planificar su ejecucin con Cron
[2]
. Un trabajo
puede ser ejecutado desde un archivo o un repositorio, por ejemplo:
Desde un archivo:
kitchen.sh -file=/gon/generateDimensions.kjb -level=Minimal
Desde un repositorio:
kitchen.sh -rep="SpoonRep" -job="generateDimensions" -
dir="/" user="username" pass="somepassword" -
level="Minimal"
Diseando Transformaciones
Introduccin
Las transformaciones son diseadas con el objetivo de generar y
poblar un Data Warehouse. Para ello se deben obtener los datos de
las fuentes OLTP para transformarlos y cargarlos en el DW.
Spoon provee una serie de pasos que permiten obtener los datos a
transformar (por ejemplo desde archivos de texto, tablas de bases de
datos), cmo procesarlos y a dnde desean ser colocados. Una vez
que los pasos son seleccionados, estos pueden ser relacionados entre
s creando una secuencia de acciones que representan los pasos a
seguir en la transformacin. A continuacin se presenta como llevar a
cabo estas tareas con Spoon.
Creando el repositorio Spoon
Antes de que se puedan realizar transformaciones o trabajos en
kettle es necesario definir como se quieren almacenar. Kettle provee
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
91
dos formas; una mediante archivos XML donde se definen las
transformaciones y trabajos; la otra mediante la creacin de un
repositorio en una base de datos donde se encuentran los metadatos
de las transformaciones y trabajos. Para el presente trabajo se utiliz
un repositorio, al ser considerada la forma ms adecuada, pues
facilita el trabajo en equipo y adems brinda la seguridad y
estabilidad de un motor de base de datos relacional.
La primera vez que se ingresa a Spoon debe definirse que repositorio
ser utilizado (en caso de no existir uno, debe ser creado). Para ello,
primero se debe crear una base de datos para usar como repositorio
(en este trabajo se utiliz una base de datos PostgreSQL). Una vez
creada, se define una conexin con la base de datos (remota o local)
en donde sern almacenados los metadatos. Por ltimo, una vez
definida la conexin, se debe indicar a Spoon que cree la estructura
en la base de datos para poder almacenar los metadatos.
En la imagen se aprecia la pantalla de Spoon donde se ingresa el
repositorio al que se desea conectar.
Conexin a un repositorio kettle
Creando una transformacin
Como ejemplo, se describir la secuencia de pasos para crear la
transformacin para generar la tabla representativa de la Dimensin
Tiempo: Time Transformation.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
92
Una vez creado y conectado al repositorio, se puede comenzar a
disear una transformacin o un trabajo. Lo primero que se debe
hacer antes de comenzar el diseo, es definir y elegir los pasos
(steps) que estarn involucrados y como van a interactuar entre s
mediante saltos (hops). Por ltimo se debe especificar, para cada uno
de los pasos, las opciones y comandos necesarios para llevar a cabo
la transformacin.
La dimensin que se disear ser la de Tiempo. Esta es una
dimensin que debe estar en todo data warehouse. Su estructura es
la siguiente:
lookup_time
o year
o quarter
o month
o month_name
o week
o weekday
o weekday_name
Con seguridad, existen diversos modos de generar una tabla que
represente la dimensin tiempo, en este caso el proceso fue
elaborado integralmente por el grupo, sin saber hasta el momento si
existe forma predefinida o ms eficiente. Se asume la existencia de
un proyecto configurado. Se procede con la creacin en el repositorio
de una nueva transformacin.
En la imagen se observan los pasos involucrados en la
transformacin, en la cual se crea la dimensin tiempo del Data
Warehouse.
Transformacin tiempo
A continuacin se explica con mayor detalle cada uno de los pasos
involucrados en la transformacin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
93
Generate Rows: Generador de filas
Este paso genera como salida un nmero determinado de filas,
adems permite especificar los datos que componen la fila, y
opcionalmente asignarle un valor. En el caso de esta transformacin
se generan 3660 filas que equivalen a la cantidad de das en 10 aos.
Cada una de estas filas generadas posee dos valores.
initial_date: Especifica la fecha a partir de la cual se desea
empezar a generar das hasta llegar a 10 aos. Este valor ser
utilizado mas adelante por el paso Modified Java Script Value.
localeParam: Es un parmetro que indica la localidad de la
fecha que se esta generando, esto, por ejemplo, brinda mayor
flexibilidad a la hora de volver a generar la dimensin tiempo
en otro idioma. Este valor ser utilizado mas adelante por el
paso Modified Java Script Value.
A continuacin se observa como realizar lo descrito anteriormente en
Spoon (Para ello se debe editar el paso):
Configuracin Generate Rows
Unin de componentes: Hops
Cuando se definen transformaciones, se debe definir la secuencia de
pasos que sern ejecutados. Para ello, se definen Hops, que
representan la unin de un componente con otro permitiendo
relacionarlos. Cuando dos componentes se relacionan mediante Hops,
el componente destino recibe los datos del componente previo, lo que
permite transformar los datos a medida que se ejecutan distintos
pasos de la transformacin.
Para crear un Hop entre dos pasos se pueden seleccionar los dos
componentes que se quieren unir y desde su men contextual
seleccionar la opcin New hop. Otra posibilidad es crearlo
directamente del rbol de componentes, para ello se debe desplegar
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
94
el men contextual de la rama Hops y seleccionar New Hop. A
continuacin se observa el asistente de esta configuracin.
Creacin de un nuevo Hop
En la imagen se observa como se realiza la unin entre el paso
Generate Rows (origen) y Add sequence (destino).
Add Sequence: Secuencia
Este paso permite generar una serie de enteros definiendo un valor
de inicio y el incremento. Los pasos que requieran el uso de una
secuencia, utilizarn como entrada un paso add sequence. Adems
permite obtener secuencias almacenadas en una base de datos o
auto generarlas. Para este caso se especifica que la secuencia
comience en 1, se incremente de a 1 y que Kettle la genere (cada
valor de la secuencia representa un da). La secuencia se
incrementara hasta la cantidad de filas generadas por el paso
anterior, por lo que tendr como mximo 3660 valores.
A continuacin se observa como configurar estos valores con Spoon:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
95
Configuracin Add Sequence
Modified Java Script Value: Java y Java Script
Este paso permite utilizar cdigo Java Script en una transformacin.
Kettle utiliza el motor de Java Script Rhino
[3]
el cual permite el uso de
clases Java en el cdigo Java Script. Esto representa una gran
ventaja ya que se puede aprovechar la potencia de un lenguaje como
Java en las transformaciones. El Cdigo contenido en este paso ser
ejecutado para cada una de las filas generadas por el paso anterior.
Dentro del Cdigo se puede hacer referencia a los valores que vienen
de los pasos anteriores, procesarlos y generar una nueva salida para
los pasos siguientes.
A continuacin se observa el cdigo para generar los distintos datos
necesarios para la dimensin tiempo:
Se crea una variable de tipo Locale
[4]
, la cual se inicializa con el
parmetro obtenido del paso 1, luego se crea un objeto de tipo
calendario gregoriano (GregorianCalendar
[5]
) que se inicializa
con la variable de localidad definida anteriormente. Una vez
inicializado el calendario, se asigna la fecha de inicio (obtenida
en el paso 1); Luego se debe incrementar de uno en uno el da
para generar las distintas fechas que se requieren. Para ello se
agregan al calendario das, los cuales se irn incrementando en
base a la secuencia definida en el paso 2.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
96
Cdigo: Datos dimensin tiempo
var locale = new java.util.Locale(localeParam.getString());
var calendar = new java.util.GregorianCalendar(locale);
calendar.setTime(initial_date.getDate());
calendar.add(calendar.DAY_OF_MONTH,DaySequence.getInteger() - 1);
Cuando se tiene definido el calendario, se obtiene la fecha, para
luego asignarla a una variable de tipo Date
[6]
, luego se define
una variable de tipo SimpleDateFormat
[7]
, la cual se usar para
obtener los distintos datos necesarios de la fecha. En base a lo
definido en la estructura de la dimensin tiempo, se utiliza la
variable SimpleDateFormat
[7]
para obtener los distintos valores.
Cdigo: Datos dimensin tiempo
var date = new java.util.Date(calendar.getTimeInMillis());
var simpleDateFormat = java.text.SimpleDateFormat("y",locale);
var year = simpleDateFormat.format(date);
simpleDateFormat = java.text.SimpleDateFormat("MMMM",locale);
var month = simpleDateFormat.format(date);
simpleDateFormat = java.text.SimpleDateFormat("MM",locale);
var monthNumber = simpleDateFormat.format(date);
simpleDateFormat = java.text.SimpleDateFormat("w",locale);
var weekInYear = simpleDateFormat.format(date);
simpleDateFormat = java.text.SimpleDateFormat("W",locale);
var weekInMonth = simpleDateFormat.format(date);
simpleDateFormat = java.text.SimpleDateFormat("d",locale);
var dayInMonth = simpleDateFormat.format(date);
simpleDateFormat = java.text.SimpleDateFormat("EEEE",locale);
var dayInWeek = simpleDateFormat.format(date);
var dayInWeekNumber = calendar.get(calendar.DAY_OF_WEEK);
Por ltimo se debe identificar los diferentes trimestres del ao.
Para ellos se comprueban los nmeros de cada mes; segn cual
sea el nmero se aade a la variable quarter_name el nmero
de trimestre. Esto se realiz de esta manera ya que la clase de
Java SimpleDateFormat
[7]
no posee una forma de manejar los
distintos trimestres del ao.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
97
Cdigo: Datos dimensin tiempo
var quarter_name = "Q";
var quarter_number;
switch(parseInt(monthNumber)){
case 1: case 2: case 3: quarter_number = "1"; break;
case 4: case 5: case 6: quarter_number = "2"; break;
case 7: case 8: case 9: quarter_number = "3"; break;
case 10: case 11: case 12: quarter_number = "4"; break;
}
quarter_name += quarter_number;
Cada una de las variables definidas en el cdigo pueden ser utilizadas
como entrada para los pasos siguientes, obviamente muchas de las
variables no son necesarias, por lo cual, no sern incluidas en el paso
siguiente. A continuacin se observa en la imagen como seleccionar
en Spoon las variables que se desean usar en los pasos siguientes.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
98
Configuracin Modified Java Script Value
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
99
Select Values: Seleccin de valores
Este paso recibe como entrada un flujo de datos sobre el cual pueden
realizarse las siguientes acciones:
Seleccionar los campos que se desea que estn disponibles
para los siguientes pasos.
Renombrar campos.
Especificar el largo o la precisin de los campos.
Para esta transformacin, el paso se utiliza para seleccionar que
valores deben continuar al paso siguiente. A continuacin se observa
en la imagen como realizar estas acciones con Spoon.
Configuracin Select Values
Table Output: Creacin de la tabla Lookup_Time
Este paso permite almacenar datos en una tabla de una base de
datos. Si la tabla no existe, Kettle brinda la posibilidad de crearla. Se
configura el paso para que Kettle cree la tabla y la cargue con los
valores recibidos de los pasos anteriores; adems, se especifica que,
cada vez que se ejecute la transformacin se borren los datos
existentes.
A continuacin se observa como realizar esta configuracin con
Spoon.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
100
Configuracin Table Output
Ejecutando la Transformacin
Una vez que se han configurado todos estos pasos, la transformacin
se encuentra en condiciones de ser ejecutada. Para ello se debe
indicar a Spoon que ejecute la transformacin. A continuacin se
observa como se ejecuta la transformacin en Spoon.
Antes de comenzar con la ejecucin de la transformacin, pueden ser
definidos ciertos valores de configuracin (en el caso de este trabajo
se opta por dejar los valores por defecto). En la imagen se observa
como llevarlo a cabo:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
101
Configuracin de la ejecucin de la transformacin
Una vez que comienza la ejecucin de la transformacin, Spoon
brinda informacin detallada de la ejecucin de cada uno de los pasos
y sus resultados. A continuacin se aprecia la pantalla de Spoon:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
102
Informacin de ejecucin
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
103
Creando la tabla de hechos: Orders Fact
Consideraciones previas
Antes de que se realice la transformacin que cree la tabla de hechos,
se deben desarrollar las transformaciones que generen las
dimensiones restantes (definidas en el modelo multidimensional). A
continuacin se observan los diagramas de las transformaciones
diseadas para obtener las tablas que representan estas
dimensiones. Por cuestiones de alcance no se explican en detalle
todos los pasos y configuraciones necesarias para realizar cada una
de estas transformaciones.
Transformacin que genera la dimensin Clientes
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
104
Transformacin que genera la dimensin Sucursales
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
105
Transformacin que genera la dimensin Productos
Definicin del modelo y pasos realizados
A continuacin se presentan las imgenes de las transformaciones
llevadas a cabo para crear y cargar la tabla de hechos. Se decidi
dividir la transformacin en dos ya que se encontraron ciertas
dificultades y restricciones para generar la tabla de hechos con los
pasos provistos por Kettle. Se considera que existen otras formas
ms eficientes de realizar esta transformacin pero por la razn antes
mencionada se opta por la siguiente solucin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
106
Transformacin que genera la tabla auxiliar de rdenes
Transformacin que carga la tabla de hechos
La primera imagen muestra la transformacin que se encarga de
desnormalizar las rdenes de compra que se produjeron, agrupando
las rdenes que realiz un cliente en un mismo da almacenndolas
en una tabla. La segunda, ejecuta una sentencia SQL que cruza las
dimensiones del modelo multidimensional con las rdenes
desnormalizadas y agrupadas, para luego cargar estos datos en la
tabla de hechos. A continuacin se explican los pasos involucrados en
las transformaciones y como llevarlos a cabo en Spoon.
Transformacin Orders Aux
A continuacin se explica la transformacin encargada de generar la
tabla auxiliar de rdenes.
Table Input
Este paso permite leer informacin desde una base de datos, para
ello se debe especificar una conexin para que Kettle sepa de donde
extraer los datos. Para obtener la informacin se debe especificar una
sentencia sql o generar una mediante Spoon (consultas simples).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
107
A continuacin se observa como configurar este paso para obtener los
datos de los negocios cargados en GON.
Table input de negocios
En este paso se ejecuta una sentencia SQL que obtiene los datos de
los negocios cargados en GON. Una vez obtenidos, el flujo de datos
puede ser utilizado como entrada para otro paso del proceso. En este
caso se utilizan para cruzar la informacin de los negocios con el
resto de las entidades involucradas.
El resto de los pasos de este tipo utilizados en esta transformacin se
encargan de obtener la informacin de las otras entidades
involucradas. La configuracin utilizada en cada uno de estos pasos
es similar a lo explicado anteriormente, con la diferencia de la
sentencia SQL ejecutada.
Join Rows (Cartesian Product)
Este paso crea una combinacin (producto cartesiano) de todas las
filas del flujo de datos entrante, en este caso se utiliza para combinar
los datos de las distintas entidades de la transformacin; para limitar
el nmero de filas resultantes, Kettle permite especificar condiciones
que formarn el predicado de la sentencia sql.
A continuacin se observa en la imagen como realizar este paso en
Spoon.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
108
Producto cartesiano de datos relacionados con rdenes de compra
Esta imagen muestra slo algunas de las condiciones que limitan el
resultado del paso. Las siguientes condiciones son las que deberan
ser incluidas para obtener los resultados deseados:
Cdigo: Condiciones para la desnormalizacin de rdenes
WHERE branch.rootbusiness_id = business.id
AND business.id = heading_business.businesses_id
AND heading.id = heading_business.headings_id
AND orders.dtype LIKE 'Order'
AND orders.branch_id = branch.id
AND orderentry.order_id = orders.id
AND orderentry.product_id = basebranchproduct.id
AND basebranchproduct.dtype LIKE 'BranchProduct'
AND basebranchproduct.branch_id = branch.id
AND basebranchproduct.businessproduct_id = basebusinessproduct.id
AND basebusinessproduct.dtype LIKE 'BusinessProduct'
AND basebusinessproduct.business_id = business.id
AND basebusinessproduct.id = businessproductprice.product_id
AND businessproductprice.price_id = price.id
AND bpp.pricesincedateonly <= orders.selldateonly
AND (orders.selldateonly < bpp.priceenddateonly OR bpp.priceenddateonly IS
NULL)
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
109
AND role.dtype LIKE 'Client'
AND role.id = orders.buyer_id
Select Values: Entidades relacionadas con rdenes
Como se menciona en la transformacin previa, este paso permite
seleccionar cuales sern los datos que se utilizaran como entrada
para el paso siguiente y redefinir los metadatos de los datos.
En la siguiente imagen se observan los valores seleccionados como
entrada para el prximo paso.
Valores seleccionados como entrada para el prximo paso
Adems de seleccionar los datos, para este paso se deben especificar
el tipo de dato de los valores de ao, mes y da, ya que Spoon por
defecto deja estos valores como String. En la imagen se observa
como indicar a Kettle que transforme los datos a enteros.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
110
Redefinicin de los metadatos
Calculator
Este paso brinda un conjunto de funciones que pueden ser ejecutadas
sobre los campos de entrada. Por ejemplo sumar A + B, Obtener el
mes del campo A, redondear A, sumar a la fecha A los das del campo
B, etc. Estas funciones tambin podran realizarse con el paso
Modified Java Script Value, pero este paso tiene la ventaja que es
ms rpido para ejecutar los clculos.
En esta imagen se observa como configurar en Spoon el paso para
realizar el clculo del total. El total se obtiene a partir del clculo de
multiplicar el precio del producto ordenado por un cliente en una
sucursal por la cantidad de unidades pedidas.
Clculo de total
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
111
Sort Rows
Este paso permite ordenar las filas que recibe como entrada en base
a los campos que se especifican, pudiendo ordenar ascendente o
descendentemente. Para este paso se especifica que se ordene de tal
forma que las compras que hizo un cliente de un producto en un da
en una sucursal, queden ordenadas consecutivamente. Esto permite
que el paso siguiente agrupe estos valores de manera adecuada.
A continuacin se observa como realizar estas tareas con Spoon.
Ordenamiento de filas
Group By
Este paso permite calcular valores en base a un agrupamiento de
campos. Para que este paso agrupe correctamente los campos,
primero se debe haber realizado un ordenamiento de las filas
(explicado en el paso anterior). En este caso se agrupan todos los
registros de compras que sean de un mismo cliente, producto,
sucursal, rubro, ao, mes, da. Luego, por cada una de estas
coincidencias se agrega a la fila resultante el clculo de:
Suma de los totales de productos comprados.
Suma de los montos de los productos comprados.
Precio del producto comprado.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
112
En la siguiente imagen se observa el paso realizado en Spoon.
Agrupamiento de filas
Table Output: Orders Aux
Este paso ya fue explicado, anteriormente, en la transformacin de
tiempo. Simplemente cabe destacar que se encarga de crear la
estructura de la tabla auxiliar de rdenes, que luego, ser combinada
con las dimensiones para crear la tabla de hechos. La configuracin
de este paso en Spoon no difiere de la realizada en la transformacin
anterior.
Creacin de la tabla de hechos
A continuacin se explican los pasos necesarios para crear la
transformacin encargada de generar la tabla de hechos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
113
Table Input: Combinacin de rdenes y dimensiones
Como se menciona al comienzo de esta transformacin, este paso
permite leer informacin desde una base de datos. Para realizar la
combinacin de los datos de rdenes y sucursales, se creo una
sentencia SQL, que luego es ejecutada por el paso, para crear un
flujo de salida que pueda ser utilizado por el paso siguiente. La
sentencia es:
Cdigo: Cruce dimensional con rdenes desnormalizadas
SELECT dims.branch_id, dims.heading_id, dims.username, dims.year,
dims.monthnumber, dims.dayinmonth, dims.branch_product_id,
CASE WHEN (dims.branch_id = aux.branch_id AND dims.heading_id =
aux.heading_id)
AND ( dims.year = aux.year AND dims.monthnumber =
aux.month AND dims.dayinmonth = aux.day)
AND (dims.username LIKE aux.user_username)
AND (dims.branch_product_id = aux.order_entry_product_id)
THEN aux.count
ELSE 0
END AS count,
CASE WHEN (dims.branch_id = aux.branch_id AND dims.heading_id =
aux.heading_id)
AND ( dims.year = aux.year AND dims.monthnumber =
aux.month AND dims.dayinmonth = aux.day)
AND (dims.username LIKE aux.user_username)
AND (dims.branch_product_id = aux.order_entry_product_id)
THEN aux.price
ELSE 0
END AS price,
CASE WHEN (dims.branch_id = aux.branch_id AND dims.heading_id =
aux.heading_id)
AND ( dims.year = aux.year AND dims.monthnumber =
aux.month AND dims.dayinmonth = aux.day)
AND (dims.username LIKE aux.user_username)
AND (dims.branch_product_id = aux.order_entry_product_id)
THEN aux.total
ELSE 0
END AS total
FROM (SELECT br.branch_id, br.heading_id,c.username, t.year,
t.monthnumber, t.dayinmonth,p.branch_product_id
FROM time_lookup t,branches_lookup br, clients_lookup c,
products_lookup p WHERE br.branch_id = p.branch_id) AS dims
LEFT JOIN orders_aux aux ON dims.year = aux.year AND dims.monthnumber
= aux.month AND dims.dayinmonth = aux.day
AND dims.branch_id = aux.branch_id AND dims.heading_id =
aux.heading_id
AND dims.username LIKE aux.user_username
AND dims.branch_product_id = aux.order_entry_product_id
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
114
A continuacin observamos la imagen de como queda el paso
configurado en Spoon.
Table input que ejecuta sentencia SQL para combinar datos de
rdenes con los de las dimensiones
Select Values: Fact Values
Una vez que se obtienen los datos que poblarn la tabla de hechos
(paso anterior), se debe seleccionar y renombrar los campos que se
quieren ingresar en la tabla de hechos. Para ello se usa el paso ya
explicado Select Values. A continuacin se observa la configuracin
utilizada en Spoon.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
115
Valores seleccionados para la tabla de hechos
Table Output: Facts Load
Finalmente, resta cargar los datos procesados anteriormente en la
tabla de hechos. Para ello se utiliza el paso Table Output, que permite
crear y poblar la tabla correspondiente. La configuracin utilizada en
este paso es igual a la utilizada en los pasos anteriores de este tipo,
con la diferencia que se especifica la tabla de la base de datos que
contendr los hechos.
A continuacin se observa un ejemplo de los datos que sern
cargados en la tabla de hechos visualizados en Spoon.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
116
Hechos generados por la transformacin
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
117
Como resultado final se obtiene una tabla donde se encuentran todos
los hechos, hayan ocurrido o no.
Para finalizar con el proceso de generacin de la estructura y carga
de datos del DW, solo resta definir un trabajo (job) que ejecute las
transformaciones definidas en conjunto. En la siguiente seccin se
especifican los pasos necesarios para crear el trabajo.
Diseando un Trabajo
Introduccin
Como ya se mencion anteriormente los trabajos representan tareas
de alto nivel. Cada entrada de un trabajo puede ser, por ejemplo, una
transformacin como la que se describi en la seccin anterior. Por
cuestiones de alcance de este trabajo, no se explic como realizar
todas las transformaciones necesarias para realizar las distintas
dimensiones del DW. Se asume que para este paso se desarrollaron
el resto de las transformaciones y se encuentran listas para ser
ejecutadas. Para ms detalle sobre la definicin de la estructura de
las distintas dimensiones ver Modelo multidimensional.
Creando un Trabajo: Transformations Job
Una vez definidas y creadas las transformaciones es posible crear un
trabajo que ejecute a todas en conjunto, para ello, se debe crear un
trabajo en Kettle y especificar que transformaciones u otras acciones
(por ejemplo enviar un email, subir un archivo va FTP, etc) sern
ejecutadas. A continuacin se observa el trabajo creado en Spoon.
Trabajo que ejecuta las transformaciones que crean el modelo
multidimensional
Este trabajo ejecuta las distintas transformaciones creadas, una a la
vez, hasta obtener la estructura y datos del modelo multidimensional.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
118
Componente START: comienzo del trabajo
Este paso es donde comienzan los trabajos y es requerido antes que
un trabajo pueda ser ejecutado. En la configuracin de este paso se
pueden definir valores para planificar la ejecucin del mismo. Se
observa en la imagen como se configura el trabajo para que sea
ejecutado semanalmente los das domingos a las 13 horas.
START Step
Componente Transformation: Ejecucin de una
transformacin
Este paso permite ejecutar transformaciones creadas en un
repositorio o archivo XML de Kettle. En este caso se ejecuta desde el
repositorio previamente definido. En la imagen se observa como se
configura este paso para la transformacin de clientes utilizando
Spoon.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
119
Paso que ejecuta una transformacin
Esta es la configuracin utilizada para la transformacin de clientes.
Para el resto de las transformaciones se utiliza la misma
configuracin, con la diferencia que se indica la transformacin
correspondiente a ejecutar.
Unin de componentes
Cuando ya se han definido todos los componentes que componen el
trabajo, es necesario realizar las uniones entre ellos para definir la
secuencia de pasos que se ejecutaran.
Para realizar una unin de dos componentes, se deben seleccionar los
componentes y hacer click derecho sobre uno de ellos para desplegar
su men contextual; dentro de este se debe seleccionar la opcin
New hop. Bsicamente esta accin unir ambos componentes
(mediante un componente hop) para que luego de la ejecucin del
primero se prosiga, con la ejecucin del siguiente.
Los saltos de un componente a otro, hops, pueden configurarse para
variar la secuencia lgica de ejecucin del trabajo segn los
resultados obtenidos de la ejecucin de los pasos anteriores. Existen
tres opciones posibles:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
120
Ejecutar el siguiente paso slo si el paso anterior fue exitoso
(ejecutar si el resultado del paso anterior fue true). Esta fue la
configuracin utilizada en el caso de la transformacin definida.
Ejecutar el siguiente paso slo si en el paso anterior ocurri un
error (ejecutar si el resultado del paso anterior fue false).
Ejecutar siempre el siguiente paso.
En el caso de este trabajo, se incluyen nicamente componentes
Transformation, los cuales representan las transformaciones definidas
para crear y poblar el DW.
Ejecucin de un trabajo
Una vez configurado el trabajo y sus componentes, solo resta
ejecutar el trabajo definido. Para ello debe elegirse la opcin Run del
men, lo cual desplegara el asistente de ejecucin del trabajo que se
observa a continuacin:
Ejecucin del trabajo
Como resultado final de la ejecucin del trabajo (si no se ha
producido ningn error), se obtiene la estructura definida en el
Modelo Multidimensional con sus respectivos datos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Kettle
121
Referencias y recursos
1. Ver anexo Licencias de Software: Anexo I
2. Artculo de Cron en Wikipedia:
http://en.wikipedia.org/wiki/Cron
3. Sitio oficial de Rhino: http://www.mozilla.org/rhino/
4. Locale JavaDoc:
http://java.sun.com/j2se/1.4.2/docs/api/java/util/Locale.html
5. GregorianCalendar JavaDoc:
http://java.sun.com/j2se/1.5.0/docs/api/java/util/GregorianCal
endar.html
6. Date JavaDoc:
http://java.sun.com/j2se/1.4.2/docs/api/java/util/Date.html
7.
7,0
7,1
7,2
SimpleDateFormat JavaDoc:
http://java.sun.com/j2se/1.4.2/docs/api/java/text/SimpleDateF
ormat.html
Kettle Home: http://kettle.pentaho.org/
Trabajando con JasperETL
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
125
Introduccin
JasperETL es el componente de JasperSoft
[1]
destinado a la
Integracin de Datos
[2]
. Est basado en el proyecto Talend
[3]
, y se
espera que no existan mayores diferencias entre la funcionalidad de
JasperETL y Talend.
Licencia
Talend, y por ende JasperETL estn regidos por un esquema de
copyleft
[4]
mediante la licencia GPLv2
[5]
Versin Utilizada
Talend Open Studio 2.2.0GA - build r6191-20071008-1049
Descripcin general
JasperETL brinda un enfoque de desarrollo Top/Down
[6]
. Las
herramientas para iniciar desde lo ms general, permiten expresar
los Modelos de Negocio, mientras que los detalles tcnicos precisos
de la aplicacin se abordan mediante Diseos de Trabajos para la
extraccin, transformacin, transporte y carga de datos. El principal
producto que generar un proyecto JasperETL, sern los Scripts
para planificar y poner en marcha los procesos ETL, obteniendo
como producto secundario toda la documentacin que respalda el
proceso subyacente. Actualmente JasperETL permite elegir entre
Java o Perl como lenguajes para llevar a cabo un proyecto. Los
componentes y sus prestaciones, dependern del lenguaje
seleccionado, tanto los Scripts resultantes y las rutinas escritas por el
usuario, sern en el lenguaje propio del proyecto en cuestin.
GUI: Perspectivas y Vistas
JasperETL basa su interfaz de usuario en la Plataforma Eclipse
[7]
.
Esto hace que su uso y configuracin sea de rpido aprendizaje para
aquellos desarrolladores que ya han tenido experiencias previas con
Eclipse u otros entornos basados en este.
Perspectivas
Una perspectiva de la Interfaz Grfica se compone de una serie
de vistas (ventanas y paneles de herramientas) que en conjunto
brindan la funcionalidad necesaria para llevar a cabo una tarea o
serie de tareas comunes. En JasperETL la perspectiva principal es la
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
126
Design Workspace perspective, la cual hace posible,
principalmente, disear, ejecutar y documentar los trabajos de
transformacin junto con los metadatos que los respaldan. Entre
otras, la perspectiva Java se limita a la gestin de los archivos
generados en el proyecto y la perspectiva Debug est destinada a la
depuracin de los trabajos y rutinas de usuario que componen el
proyecto. Las prximas secciones estn dedicadas a la descripcin de
aquellos componentes de la perspectiva Design Workspace que
resultan fundamentales para el desarrollo de trabajos de
transformacin. No se ahondar en las prestaciones brindadas por las
restantes perspectivas por resultar casi idnticas a las brindadas por
Eclipse.
Design Workspace perpective
Vista del Repositorio (Repository View)
Principales secciones:
Modelos de Negocio (Business Model): Gestin de todos los
modelos de negocio que involucra el proyecto.
Diseos de Trabajos (Job Designs): Gestin de los
trabajos diseados para llevar a cabo las transformaciones
del proyecto.
Contextos (Contexts): En un proyecto, diferentes
configuraciones pueden ser establecidas (por ejemplo, para
produccin y para pruebas). En esta seccin es posible albergar
todas aquellas variables que inciden en un proyecto.
Cdigo (Code):
o Rutinas (Routines): Rutinas (Escritas en el lenguaje
elegido para el proyecto) agrupadas en libreras. Las
brindadas por defecto (System) permiten realizar
operaciones matemticas, formato de fechas y Strings,
etc. Se puede adems, escribir rutinas propias del
proyecto, y ser reutilizadas entre trabajos y proyectos.
Las Rutinas quedan disponibles para ser luego utilizadas
por diferentes componentes de las transformaciones.
o Snippets: No ha sido implementado an.
Metadatos (Metadata): desde esta seccin se gestionan la
descripcin de las fuentes/destino de datos. Se puede
configurar como fuente/destino de datos conexiones a base de
datos, archivos planos, LDAP, xml, etc. Luego se pueden
definir esquemas basados en la estructura de las fuentes, o
simplemente esquemas genricos diseados para crear nuevos
destinos de datos. Vale destacar que los esquemas aqu
definidos, podrn ser reutilizados en distintos componentes de
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
127
un trabajo de transformacin, e incluso, entre diferentes
trabajos.
Documentacin (Documentation): til para aadir
documentacin adicional al proyecto.
Papelera de Reciclaje (Recycle Bin): En esta seccin se
almacenarn todos aquellos elementos borrados o
descartados del proyecto para su posible recuperacin o
uso.
Cada uno de los elementos que son generados en las secciones
anteriores, estarn identificado por un nmero de versin y un
estado, ambos asignados por el usuario. El estado podr ser uno de
los estados pre-definidos en las propiedades del proyecto.
Observamos a continuacin una imagen de lo descrito:
Vista del Repositorio
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
128
Espacio de trabajo grfico (Graphical workspace)
Es un editor grfico en el cual se pueden realizar los diagramas de
flujo, tanto de Modelos de Negocio como de Diseo de Trabajos.
Consta de una paleta con todos los componentes que pueden
intervenir en el diseo del flujograma.
Paleta de Componentes
En esta vista se encuentran agrupados por categoras, todos
aquellos componentes disponibles para utilizar en el diagrama que
se est editando. El espacio de trabajo presenta el siguiente aspecto:
Graphical workspace
Vistas de Propiedades, Ejecucin y Log (Properties,
Run and Logs views)
Propiedades: la informacin desplegada en esta vista
depender del tipo de diagrama y componente seleccionado.
Por ejemplo, al seleccionar un componente en un Diagrama de
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
129
Negocio, la informacin aludir a las propiedades visibles
que tiene el mismo en el diagrama en cuestin (nombre,
tamao, colores, etc). Por otra parte, si en un Diseo de un
Trabajo se seleccionara un componente la informacin se
relacionar ms con la operacin del mismo en el Trabajo
(cadenas de conexiones, ruta de archivos, esquemas, etc).
Ejecucin: exclusiva para Trabajos. En esta vista
encontramos los controles para lanzar la ejecucin de un
Trabajo y una consola que informar el estado actual de
ejecucin. Adems es posible habilitar estadsticas y tiempos
al ejecutar un trabajo.
Log: Exclusiva para trabajos. Informa resultados y errores
de la ejecucin de Trabajos.
Vistas Propiedades-Ejecucin-Logs
Vistas Mdulos y Planificador (Modules and Scheduler
views)
Estas dos vistas son independientes del Trabajo activo o inactivo
en el espacio de trabajo.
Mdulos: algunos componentes pueden depender de
determinados mdulos. En esta vista se puede ver la lista de
todos los componentes disponibles y los mdulos requeridos
para su normal funcionamiento.
Planificador: el planificador o Scheduler est basado en el
programa para Unix Cron
[8]
. Este planificador genera entradas
compatibles con Cron, de forma tal que es posible ejecutar
peridicamente un trabajo va el comando Crontab.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
130
Modulos y Planificador
Hasta aqu se han visto los elementos de la Interfaz Grfica de
Usuario que sern utilizados al momento de disear Trabajos y
Modelos de Negocio. Para finalizar, en la siguiente imagen se puede
observar el entorno completo de JasperETL.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
131
JasperETL entorno completo
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
132
Diseando un Modelo de Negocio
Objetivo
El propsito de disear un Modelo de Negocio no est relacionado
con aspectos tcnicos, ms bien, requiere la visin de procesos desde
una perspectiva de mayor nivel. JasperETL permite disear paso a
paso el flujo de un proceso, acompaado de informacin adicional de
una manera sencilla mediante la modalidad drag & drop de
componentes visuales.
Modelado
JasperETL permite representar los objetos de un proceso mediante
figuras grficas, entre estos objetos se encuentran, desde un
sistema estratgico hasta salidas de reportes y situaciones de
decisin. Cada uno posee un rol especial en el modelo, de acuerdo a
la descripcin, definicin y asignacin que les sean dados. Se inciar
con el desarrollo del caso prctico propuesto modelando el proceso
completo que ser llevado a cabo.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
133
Modelo de Negocio
El Modelo de Negocio anterior servir como gua a lo largo de todo
el desarrollo, desde la carga inicial de la base de datos operacional y
diseos de trabajos ETL, hasta la capa final de presentacin y
reporting.
Diseando un Trabajo
Los Trabajos en JasperETL son la implementacin tcnica del
modelado de negocio descripto anteriormente. El diseo de los
trabajos permitir dejar configurado y funcionando el flujo y
transformacin de datos desde diversas fuentes que darn por
resultado final el Data Warehouse. Un trabajo representa la capa
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
134
ejecutable de la Integracin de Datos
[2]
, traduce las necesidades
en cdigo, rutinas y programas que guan el flujo de datos para lograr
un almacn de datos coherente.
Objetivos
JasperETL brinda una serie de componentes estndares para disear
los trabajos, y adems permite al usuario crear un componente o
familia de componentes relacionados. Estos componentes son
aadidos a los trabajos, conectados y relacionados de manera de
definir una secuencia de acciones. Los elementos guardados en el
Repositorio podrn ser usados en otros proyectos o trabajos e
incluso tambin por otros usuarios.
Conectando componentes
Luego de crear un nuevo trabajo, podemos colocar los componentes
que sean necesarios en el rea de diseo. Los componentes permiten
diferentes tipos de conexiones de acuerdo al rol que cumplen
dentro del trabajo.
Se ofrecer una ilustracin de un diseo de trabajo, indicando las
conexiones utilizadas; esta podr ser consultada a medida que se lea
la descripcin de los distintos conectores:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
135
Conectores de componentes JasperETL
Conexin de fila (Row connection)
Maneja la transferencia de datos, puede ser principal (main),
lookup (secundaria o subflujo), output (salida)
Fila principal (Main Row)
Es la conexin de fila usualmente utilizada. Pasa el flujo de datos de
un componente hacia otro, iterando por cada fila y leyendo los
datos de acuerdo al esquema definido en el componente. Se
caracteriza por la definicin del esquema que describe la
estructura de los datos en el archivo de entrada.
Fila secundaria o subflujo (Lookup Row)
Conecta un componente de un sub-flujo de datos a otro de un flujo
principal de datos. Es usado solamente si se tiene mltiple flujos de
entrada de datos. Una conexin Main Row puede ser convertida en
cualquier momento en una Lookup Row y viceversa.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
136
Fila de salida (Output Row)
Destinado para un componente de fila conectado al componente de
salida final.
Conexin de iteracin (Iterate connection)
Puede ser usado para iterar en archivos contenidos en un directorio,
filas de un archivo o entradas de una Base de Datos. Un componente
puede nicamente ser destino de una conexin de iteracin. Es
generalmente usado como el elemento inicial de un flujo (principal o
secundario). Algunos componentes estn diseados especialmente
para ser destino de una conexin de iteracin, como por ejemplo
tFileList.
Conexiones disparadoras (Trigger Connections)
Definen la secuencia del procesamiento. No realizan procesamiento
de datos, sino que crean dependencias entre trabajos y sub-
trabajos. Los tipos de disparadores, segn sea el evento que los
provoca son:
Correr Antes (Run After) y Correr Despus (Run Before):
disparadores cronolgicos. Ambos son utilizados con
componentes de Inicio (Start).
Correr Si (Run If), Correr Si OK (Run If Ok) y Correr Si Error
(Run If Error): disparadores contextuales. Pueden ser usados
con cualquier componente fuente, pero principalmente con el
de Inicio de un flujo principal o secundario de datos.
o Correr Si (Run If Ok): lanzado cuando se culmina con
xito la ejecucin del componente fuente.
o Correr Si (Run If Error): es lanzado tan pronto como un
error ocurra en el proceso fuente.
o Correr Si (Run If): lanza un sub-trabajo en caso que la
condicin definida se cumpla.
Conexiones Vnculo (Link Connection)
Pueden ser usadas nicamente con componentes ELT.
Modelado
A esta altura, ya se est confortable con el entorno de desarrollo para
disear un Trabajo para realizar una transformacin. De aqu en
adelante se pondrn en prctica cada aspecto descripto, mediante la
realizacin, como ejemplo, de la transformacin para generar la
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
137
dimensin tiempo correspondiente a la etapa ETL para construir el
DW observada a continuacin:
Procesos ETL para obtener el DW
Estructura de la tabla lookup_time
lookup_time
o year
o quarter
o month
o month_name
o week
o weekday
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
138
o weekday_name
Con seguridad, existen diversos modos de generar una tabla que
represente la dimensin tiempo, en este caso el proceso fue
elaborado integralmente desarrollado por el grupo, sin saber hasta el
momento si existe forma predefinida o ms eficiente. Se asume la
existencia de un proyecto configurado para generar cdigo Java. Se
procede con la creacin en el repositorio de una nueva
transformacin
El primer componente a insertar, ser un tRowGenerator.
TimeGenerator (mediante un tRowGenerator)
tRowGenerator es un componente cuyo fin es generar determinada
cantidad de filas, con valores aleatorios o procedentes de cierto
procesamiento. A continuacin se observa el Diseo luego de haber
colocado el nuevo componente, y de haberlo etiquetado
TimeGenerator, para observar sus propiedades en el panel
correspondiente, es necesario seleccionarlo:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
139
Generador de Tiempo
tRowGenerator contiene un editor para simplificar su configuracin.
En este editor, es posible establecer el Esquema que generar el
componente, como as tambin las expresiones de cada una de las
columnas del esquema. Se observa el editor con un esquema vaco
en la siguiente imagen:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
140
Generador de Tiempo con un esquema vaco
El esquema deber quedar configurado como sigue:
Esquema completo del Generador de Tiempo
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
141
Con este esquema, resta definir las expresiones que darn sentido a
cada uno de los campos del mismo. Se observa en el editor la opcin
Number of Rows for RowGenerator. Suponiendo que se ha
elegido un nmero n, el generador evaluar n veces cada una de las
expresiones definidas para cada columna. En cada columna se puede
usar cualquiera de las rutinas incluidas por defecto, pero tambin es
posible crear nuevas rutinas que se adapten a las necesidades. En
este caso se crearan una serie de rutinas Java que definirn una
secuencia temporal.
Rutinas para la dimensin tiempo
Se agruparan todas las rutinas en una clase Java que define los
siguientes campos:
Cdigo: Campos de la Clase de rutinas temporales
private static boolean initialized = false;
private static Calendar calendar;
private static String[] months_names = new
DateFormatSymbols().getMonths();
private static String[] days_names = new
DateFormatSymbols().getWeekdays();
initialized: Define si la rutina year ha sido llamada por primera
vez o no.
calendar: Envuelve lo datos temporales junto a las
operaciones adicionales para incrementar fechas, obtener
nombre de das de la semana, etc.
months_name: Tabla esttica con los nombres de los meses
del ao.
days_names: Tabla esttica con los nombres de los das de la
semana.
La firma de los mtodos, su funcionalidad y un ejemplo pueden
apreciarse en el siguiente grfico:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
142
3
Mtodos para generar la secuencia temporal
En las prximas secciones se explicar en detalle el objetivo e
implementacin de cada uno de los mtodos expuestos en el grfico
anterior.
static public synchronized Integer year(int
startingYear,int startingMonth, int
startingDayOfTheMonth)
Esta rutina devuelve el ao actual de la secuencia temporal.
Cdigo: Rutina para obtener el ao de la secuencia temporal
/**
* return the current year number
*
* {talendTypes} int | Integer
*
* {Category} user-defined
*
* {param} int(2000)
*
* {param} int(0)
*
* {param} int(1)
*
*
*/
static public synchronized Integer year(int startingYear,
int startingMonth, int startingDayOfTheMonth) {
if (!isInitialized()) {
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
143
calendar = Calendar.getInstance();
calendar.set(Calendar.YEAR, startingYear);
calendar.set(Calendar.MONTH, startingMonth);
calendar.set(Calendar.DAY_OF_MONTH,
startingDayOfTheMonth);
init();
}
return calendar.get(Calendar.YEAR);
}
Documentacin: En ella se puede incluir cualquier variante de
Javadoc seguida de la informacin necesaria para la
categorizacin de la rutina:
o talendTypes: El tipo Talend de retorno.
o Category: Categora que incluye a esta rutina. En este
caso es una rutina definida por el usuario.
o Parmetros: El tipo Talend, y opcionalmente el valor por
defecto entre parntesis.
Parmetros de la rutina
o startingYear: Ao en el que comenzar la secuencia
temporal.
o startingMonth: Mes en el que comenzar la secuencia
temporal.
o startingDayOfTheMonth: Da del mes en el que
comenzar la secuencia temporal
Valor de retorno: siempre retorna el ao contenido en
calendar.
static public synchronized int dayOfTheWeek()
Retorna el da de la semana actual de la secuencia temporal, en un
nmero ordinal en el rango (1-7).
Cdigo: Da de la semana de la secuencia temporal
>
return calendar.get(Calendar.DAY_OF_WEEK);
static public synchronized Integer month()
Retorna el mes actual en la secuencia temporal, en un nmero
ordinal en el rango (1-12).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
144
Cdigo: Mes de la secuencia temporal
return calendar.get(Calendar.MONTH) + 1;
static public synchronized Integer dayOfTheMonth()
Retorna el da del mes actual en la secuencia temporal, en un nmero
ordinal en el rango (1-31).
Cdigo: Da del mes de la secuencia temporal
int day = calendar.get(Calendar.DAY_OF_MONTH);
calendar.add(Calendar.DAY_OF_MONTH, 1);
return day;
Como se observa, una llamada a esta rutina dejar la secuencia
temporal aumentada en un da, lo cual puede provocar el cambio de
mes, y ao de la secuencia temporal.
static public synchronized String dayOfTheWeekName(int
i)
Retorna el nombre del da de la semana de acuerdo a su nmero
ordinal.
Cdigo: Nombre del da de la semana de la secuencia temporal
return days_names[i];
Parmetro
o i: Nmero ordinal del da de la semana (1-7).
static public synchronized String monthName(int month)
Retorna el nombre del mes del ao actual de la secuencia temporal,
de acuerdo a su nmero ordinal.
Cdigo: Nombre del mes de la secuencia temporal
return months_names[month-1];
Parmetro
o month: Nmero ordinal del da de la semana (1-12).
Uso de las rutinas en expresiones
Ahora slo es necesario utilizar las rutinas creadas en el editor de
expresiones, de acuerdo a la columna que corresponda. Si se
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
145
observan detenidamente las rutinas, se puede notar que es condicin
que la primera llamada se realice a la rutina year, por ser esta la
responsable de la inicializacin de la secuencia temporal, y como
ltima rutina a dayOfTheMonth ya que la misma realiza la
progresin de la secuencia temporal.
Ejemplo de la expresin para la columna year del esquema:
Expresin de la columna year
El procedimiento es:
Seleccionar la columna cuya expresin se desea editar. En este
caso, year
Editar la expresin, mediante rutinas, variables y operadores
lgicos. En este caso, buscar dentro de la categora user-
defined la rutina year.
Establecer los valores para la rutina. En este caso, dejamos los
valores por defecto. (Ao:2000,Mes:0,Da del mes:1).
Prueba de TimeGenerator (mediante un tLogRow)
tLogRow es utilizado para mostrar datos en la consola de la vista
Ejecucin.
Luego de colocar el componente tLogRow y etiquetarlo como
TimeGeneratorTest, se procede a realizar una conexin de fila
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
146
principal entre los dos componentes (desde TimeGenerator hacia
TimeGeneratorTest). Esto se logra accediendo al men contextual del
componente fuente como se observa a continuacin:
Prueba del Generador del Tiempo
Una vez realizada la conexin, y ser etiquetada como timeData, el
escenario resultante es:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
147
Conexin de salida para probar el Generador del tiempo
El trabajo est listo para ser ejecutado. Luego de lanzarse desde la
vista Ejecucin se obtiene el siguiente resultado:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
148
Prueba del Generador de tiempo ejecutado
Almacenamiento del resultado de TimeGenerator en
una BD (mediante un tMap y un tPostgresqlOutput)
Un componente tMap es un componente para transformar y redirigir
un flujo de datos proveniente de una o mltiples fuentes de datos,
hacia una o mltiples fuentes de datos. Es til para realizar uniones
entre diversas tablas de una base de datos, o entre tablas y un
esquema definido en un archivo CSV, etc. tPostgresqlOutput es uno
de los componentes destinados para realizar inserciones o
actualizaciones en una tabla de una base de datos, en este caso de
PostgreSQL.
Luego de insertar ambos componentes, el diagrama quedar
dispuesto de la siguiente forma:
Time Map y PostgresOutput
En este ejemplo en particular, el componente tMap ser nicamente
utilizado para realizar transformaciones intermedias y no uniones con
otros flujos de datos (esto se ha realizado con otras dimensiones). Al
realizar doble click en TimeMap, se abre el dilogo para realizar
mapeos y transformaciones de campos:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
149
Dilogo de Time Map
El dilogo se compone de dos secciones:
La parte superior, que a su vez, se compone de tres paneles:
o En la primera (la de la izquierda) se encuentran todos los
flujos entrantes de datos a este componente, entre estos
se pueden realizar uniones.
o El panel de la derecha acta como salida de datos, se
pueden tener varios, de acuerdo a diferentes criterios
(por ejemplo, las filas que no cumplen cierta condicin
podran ser dirigidas a un archivo de log y las restantes a
un DW).
o El panel del medio es utilizado para realizar
transformaciones o clculos con las columnas entrantes, y
enviar estos datos transformados como salida.
La parte inferior describe los esquemas entrantes y salientes de
datos.
Transformaciones (Componente tMap)
Si se analiza la estructura de la dimensin en cuestin y el esquema
elaborado hasta el momento, se notar que en este ltimo no se
encuentran los siguientes campos:
month_name
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
150
weekday_name
Para obtenerlos, usaremos el panel intermedio de transformaciones
en pos de obtener dos variables que los representen. Para ello sern
de importancia los siguientes campos del esquema actual:
weekday
month
Y las rutinas dayOfTheWeekName y monthName.
Creacin de las dos variables:
Time Map - Creacin de Variables
Edicin de expresiones:
Time Map - Expresiones para generar variables
La expresin para el nombre del mes resultante ser:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
151
Cdigo: Uso en una expresin de la rutina monthName
TimeLookup.monthName(TimeData.month)
Y la correspondiente para el nombre del da de la semana:
Cdigo: Uso en una expresin de la rutina dayOfTheWeekName
TimeLookup.dayOfTheWeekName(TimeData.day_of_the_week)
Obteniendo el siguiente esquema para el componente TimeMap:
Time Map - Variable
El paso restante, es realizar el flujo de salida. En este caso, se
destinan las nuevas filas a una tabla del DW correspondiente a una
base de datos Postgres.
Flujo de salida con tPostgresqlOutput
Como primera medida, en el editor grfico, se realizar una conexin
de salida de datos desde el componente TimeMap hacia el
componente tPostgresOuput, etiquetada lookup_time. Para ello,
desde el men contextual de TimeMap, se selecciona la opcin Row-
>*New Output* (Main):
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
152
Time Map Conexin de Salida
Y luego se procede a establecer un nombre para el nuevo flujo:
Time Map Nombre de la conexin de Salida
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
153
Se observa que el componente TimeMap ha quedado con un error
luego de la conexin. El mismo indica que debe establecerse al
menos una columna en el esquema de salida:
Time Map Error en la conexin de salida
Para solucionar este error, se debe acceder al editor de TimeMap y
realizar la correspondiente edicin de columnas salientes:
Time Map Esquema de Salida
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
154
Al finalizar con el esquema de salida, se debe confirmar la
propagacin del esquema hacia el componente lookup_time.
Accediendo a las propiedades de dicho componente, se observa la
siguiente configuracin:
Propiedades de lookup_time
Se debe decidir si la conexin a la base de datos ser Built-In o de
Repositorio. La primera opcin, implicar repetir los mismos pasos
para cada configuracin similar venidera. Para estos casos es
conveniente el uso del repositorio, y dentro de este, la seccin de
metadatos/conexiones de base de datos.
Propiedades de la conexin lookup_time
Luego de haber configurado la conexin a la base de datos y la tabla
en la cual se insertarn los nuevos datos, resta configurar el esquema
correspondiente a la tabla de salida. Debe recordarse, que al
propagar la correlacin de columnas de entrada, transformacin y
salida en TimeMap, el esquema ya habr quedado configurado como
Built-In. Ingresando a la opcin de edicin del esquema se obtiene
lo siguiente:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
155
lookup_time Esquema de Salida
Si se observa la parte derecha (el esquema de salida), es de notar
que no existen nombres de columnas asociados con la tabla de la
base de datos destino. Esto es porque la tabla an no existe. Para
crear la tabla con un esquema correspondiente al esquema de salida,
se proceder a guardar el esquema en el repositorio. Luego se
proceder con la creacin la tabla mediante un componente
tCreateTable:
lookup_time Grabar esquema de Salida
Creacin de la tabla de la dimensin tiempo con
tCreateTable
Como primer paso, se debe insertar en el rea de trabajo un
componente tCreateTable etiquetado CreateTimeTable, y realizar una
conexin del tipo target Run if Ok con el primer paso del flujo,
TimeGenerator. De esta forma ser seguro que al inicio de la
ejecucin, la tabla destino estar creada acorde al esquema de salida.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
156
lookup_time Creacin de Tabla
Luego de esto, se pasa a editar el esquema (correspondiente a la
nueva tabla) en las propiedades de CreateTimeTable. Se elegir un
esquema de repositorio, para utilizar el que ha sido previamente
generado. Tambin se deber asignar el tipo de base de datos que
corresponda, en este caso PostgreSQL, y tambin la forma en que la
tabla ser creada, para la tabla de la dimensin tiempo, la opcin de
eliminar la tabla si existe y luego crearla (Drop if exists and create).
El resultado obtenido es la siguiente configuracin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
157
lookup_time Propiedades de la Creacin de Tabla
Con esto, el trabajo est listo para ser ejecutado.
Ejecucin del proceso
Luego de ejecutar el proceso, se obtiene la tabla creada en la base de
datos y se observan los siguientes datos generados:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
158
lookup_time Nueva tabla PostgreSQL y datos generados
Diseos de Trabajos para las Dimensiones restantes
En las siguientes secciones se observar la estructura de los trabajos
requeridos para completar las dimensiones restantes. Aquellos
componentes involucrados que an no han sido explicados en detalle
(como el tPostgresInput) sern debidamente abordados en la seccin
construccin de la Tabla de Hechos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
159
Dimensin Sucursales
Diseo de Trabajo para crear la Dimensin Sucursales
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
160
Dimensin Clientes
Diseo de Trabajo para crear la Dimensin Clientes
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
161
Dimensin Productos
Diseo de Trabajo para crear la Dimensin Productos
Creacin de la Tabla de Hechos
En esta seccin se describir el proceso llevado a cabo para crear y
cargar la tabla de hechos del modelo multidimensional . Para ello slo
se detallarn el uso y configuracin de aquellos componentes
intervinientes que no han sido utilizados previamente.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
162
Configuracin del componente de entrada
Lookup_Branches (tPostgresqlInput)
Luego de crear un nuevo Diseo de Trabajo llamado FactTable, se
insertar un componente tPostgresqlInput etiquetado
Lookup_Branches. Con este componente se describir la
configuracin de entrada para la dimensin sucursales, adems
servir de ejemplo para las restantes dimensiones. En la siguiente
imagen se observa el escenario resultante:
Componente de Entrada Postgresql para la dimensin Sucursales
Creacin de una conexin a una Base de Datos en el
repositorio
Desde la vista del repositorio, en la seccin metadatos se debe
acceder al men contextual de la opcin conexiones de Base de Datos
(Db Connections), luego, ingresar a la opcin de crear conexin
(Create connection). Se puede observar este proceder a
continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
163
Creacin de una nueva conexin
Una vez en el dilogo que gua la configuracin de la nueva conexin,
se inicia asignndole:
Un nombre: El mismo distingue a cada conexin.
Propsito: El fin o utilidad de la nueva conexin.
Versin: Un nmero mayor y otro menor de versin. til a los
fines de gestin de la configuracin del proyecto.
Estado (Status): Uno de los distintos estados propios del
proyecto
Lo expresado puede observarse en la siguiente imagen:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
164
Propiedades de la nueva conexin
El paso siguiente de la configuracin, ser para establecer las
propiedades de la URL o cadena de conexin. Los siguientes datos
referidos a la nueva conexin debern ser completados:
Tipo de Base de Datos (DB Type): La naturaleza u origen de
la base de datos en cuestin. En este caso, PostgreSQL
Login: Nombre de usuario habilitado con permisos para
acceder tanto al Sistema Gestor de DBs como a la Base de
Datos.
Password: la contrasea del usuario correspondiente.
Puerto (Port): El puerto en el cual se encuentra a la espera de
conexiones el Sistema de Gestor de DBs.
Sid: El nombre de la Base de Datos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
165
Esquema (Schema): El esquema de la base de datos. til
para discriminar tablas del sistema, de las tablas de usuario.
Con esto, el campo Cadena de Conexin (String of Connection) se ir
completando automticamente. De igual forma, si se escribiera la
cadena de conexin de forma manual, se observar la actualizacin
en los campos correspondientes.
La imagen siguiente, aclarar un poco ms lo anteriormente
detallado:
Cadena de conexin
Creacin de un esquema desde una tabla de una Base
de Datos
Como ya ha mencionado, un esquema puede provenir de mltiples y
diversas fuentes, entre ellas una tabla o vista de una Base de Datos.
Para esto, es necesario tener una conexin con una Base de Datos ya
configurada en el repositorio. Con la conexin configurada, se
proceder a obtener el/los esquema/s basados en tablas de la Base
de Datos. Para ello, se accede al men contextual de la conexin
objetivo, y se procede con la opcin obtener esquema (Retrieve
Schema) como se aprecia en la siguiente imagen:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
166
Obtener un esquema de una Base de Datos
Una vez elegida la opcin de obtener esquema, ser necesario elegir
al menos una vista o tabla. En este caso se seleccionan todas las
tablas, que representan a las dimensiones del Data Warehouse:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
167
Seleccin del esquema de una Base de Datos
En la imagen anterior se observa que los esquemas han sido
satisfactoriamente obtenidos, slo resta elegir cuales de las columnas
obtenidas automticamente formarn parte de los esquemas. Esto
ltimo, ser configurado al continuar con el dilogo. Dentro de cada
esquema seleccionado y las columnas elegidas se podr cambiar el
nombre de las mismas, el tipo de dato que representan, entre otras
propiedades. Se puede apreciar un ejemplo de edicin de esquemas a
continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
168
Edicin del/los esquema/s seleccionados de una Base de Datos
Una vez que todo ha quedado configurado segn lo deseado, se
finaliza el proceso y los esquemas quedarn a disposicin para ser
usados por los diversos componentes que requieren de ellos como
fuente o destino de datos.
Configuracin de las propiedades del componente
tPostgresqlInput Lookup_Branches
Con los esquemas anteriormente definidos, se procede con el ejemplo
de la Dimensin Sucursales correspondiente al componente
Lookup_Branches. Para ello, sus propiedades de conexin y esquema
debern quedar configuradas como se observa a continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
169
Configuracin del componente Lookup_Branches
Si se observa en detalle la captura de pantalla anterior, la propiedad
Query, contiene una sentencia SQL por defecto "select id, name
from employee". Tambin se nota en la imagen que el componente
presenta una serie de errores, uno de estos errores, es obvio, y se
debe a que el componente an no ha sido conectado con otro
componente destino. El error restante hace alusin a la
incompatibilidad del esquema configurado en el componente (el cual
representa a la tabla lookup_branches) y la sentencia sql
configurada. Se debe tener en cuenta entonces que el esquema de
un componente de entrada debe ser compatible con la
estructura resultante de los datos. Por ejemplo, la estructura de
datos resultante en un componente de entrada desde una base de
datos estar representado por una sentencia SQL y en un archivo
CSV por la fisonoma y formato de los datos contenidos en texto
plano. De no coincidir el componente no podr cumplir con su
funcionalidad y la ejecucin del trabajo producir errores. Con lo
anterior como premisa, es necesario ahora configurar adecuadamente
la sentencia SQL para este componente, para ello se debe ingresar al
editor SQL. El editor SQL presenta un aspecto similar al observado a
continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
170
Editor SQL
Dentro del editor, se puede elegir una las siguientes alternativas.
1. Editar el texto de la sentencia SQL.
2. Obtener la sentencia desde un fichero .sql, previamente
generado.
3. Realizar una edicin de sentencia de forma visual, realizando
las uniones entre distintas tablas y la seleccin de las columnas
incluidas como campos resultantes de la consulta.
Las dos primeras, representan la forma tradicional de edicin de
sentencias, para ilustrar el uso de la tercera se llevar a cabo la
sentencia correspondiente al esquema buscado mediante edicin
grfica. Accediendo al editor grfico SQL, y luego de acceder al men
contextual, se quedar en presencia de la siguiente pantalla:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
171
Editor SQL Grafico
Al elegir la opcin de aadir tablas (Add tables), se procede a elegir
la tabla involucrada, en este caso lookup_branches:
Editor SQL Grfico - Seleccin de tablas
Con la/las tabla/s seleccionadas, se escogen las columnas que
aparecern en los resultados de la consulta. Tambin, en este paso,
se podrn efectuar las uniones correspondientes entre las diferentes
tablas intervinientes. En este ejemplo en particular, se seleccionarn
todas las columnas contenidas en la tabla como se aprecia en la
siguiente imagen:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
172
Editor SQL Grfico - Seleccin de columnas y criterios de unin de
tablas
Luego, la sentencia generada ser:
Editor SQL - Sentencia Generada
En la imagen anterior tambin se observa destacada la opcin para
adivinar (Guess Query) la sentencia SQL que satisfaga al esquema
seleccionado, eliminando los pasos anteriores de edicin de SQL. Es
posible que esta ltima opcin funcione para casos simples, como lo
es este ejemplo, quizs para esquemas ms intrincados la
"adivinanza" no produzca resultados que se correspondan con el
mismo. Con esto se ha finalizado la configuracin del componente
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
173
Lookup_Branches, restar entonces repetir el procedimiento con las
restantes dimensiones, para luego continuar con el Mapeo de datos y
la posterior creacin y carga de datos de la Tabla de Hechos.
El trabajo finalmente quedar dispuesto de la siguiente forma:
Trabajo de la tabla de hechos
Desnormalizacin de rdenes
Para obtener las rdenes desnormalizadas, se utiliza un componente
tPostgresInput definido con el siguiente esquema de entrada:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
174
Esquema de desnormalizacin de rdenes
El esquema anterior representa cada entrada de las rdenes
efectuadas en el sistema y sus campos representan:
id_branch: Sucursal del negocio que efectu la venta.
id_heading: Rubro al que pertenece la sucursal que efectu la
venta.
id_client: Cliente que efectu la compra.
id_product: Producto que fue comprado.
year: Ao en que el la compra se hizo efectiva.
month: Mes del ao en que fue efectuada la compra.
day: Da del mes en el cual se compr el producto.
price: El precio al da de realizada la compra.
count: Cantidad de producto comprado.
total: Monto total de la compra.
La estructura de datos resultante para este componente, est
representada por la siguiente sentencia SQL:
Cdigo: Desnormalizacin de rdenes
SELECT br.id AS id_branch
, h.id AS id_heading
, r.user_username AS id_client
, oe.product_id AS id_product
, pr.price AS price
, extract (YEAR FROM o.selldateonly) AS year
, extract (MONTH FROM o.selldateonly) AS month
, extract (DAY FROM o.selldateonly) AS day
, count
, pr.price*count AS total
FROM branch AS br
, business AS bu
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
175
, heading AS h
, heading_business AS hb
, orders AS o
, orderentry AS oe
, basebranchproduct AS brp
, basebusinessproduct AS bp
, businessproductprice AS bpp
, price AS pr
, role AS r
WHERE br.rootbusiness_id=bu.id
AND bu.id=hb.businesses_id
AND h.id=hb.headings_id
AND o.dtype LIKE 'Order'
AND o.branch_id=br.id
AND oe.order_id=o.id
AND oe.product_id=brp.id
AND brp.dtype LIKE 'BranchProduct'
AND brp.branch_id = br.id
AND brp.businessproduct_id=bp.id
AND bp.dtype LIKE 'BusinessProduct'
AND bp.business_id=bu.id
AND bp.id=bpp.product_id
AND bpp.price_id=pr.id
AND bpp.pricesincedateonly <= o.selldateonly
AND (o.selldateonly < bpp.priceenddateonly OR bpp.priceenddateonly
IS NULL)
AND role.dtype LIKE 'Client'
AND r.id=o.buyer_id
Agregacin de hechos (componente tAggregateRow)
La configuracin del componente tAggregateRow consiste en
establecer criterios Group By, para luego utilizar funciones de
agregacin de datos tales como count o sum u otras para
seleccionar un valor en particular del grupo de filas coincidentes, por
ejemplo first, last, min o max. Las propiedades para la tabla de
hechos debern quedar configuradas como se observa a
continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
176
Propiedades de agregacin de hechos
En los criterios de Group By se incluyen aquellos campos que
pertenecen a las claves primarias de las dimensiones del modelo. Las
operaciones deben incluir tres propiedades configuradas:
Campo de salida (Output Column): Nombre que tendr el
campo en el esquema saliente de este componente.
Funcin (Function): tipo de agregacin del campo (sum,
max, min, count, etc).
Campo de entrada (Input Column): campo al que ser
aplicado la funcin seleccionada.
La cantidad (count) de productos comprados en un punto obtenido
del cruce de dimensiones, sern agregados con la funcin sum al
igual que el monto total, mientras que, para el campo price se
utilizar la funcin first ya que el precio de un producto se
mantendr igual para un mismo da.
Finalizacin y ejecucin del trabajo FactJob
En este punto slo resta efectuar las uniones correspondientes entre
las rdenes agregadas y las tablas de dimensiones, asegurando que
los cruces dimensionales en los que no se produzcan hechos no se
pierdan, y por el contrario, queden registrados como un no hecho o
una no venta.
Una vez ejecutado el trabajo para la tabla de hechos, el resultado
obtenido ser similar al observado en la imagen siguiente:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con JasperETL
177
Tabla de Hechos
Referencias y recursos
1. Sitio oficial de JasperSoft:http://www.jaspersoft.com
2.
2,0
2,1
Ver Data Integration en
Wikipedia:http://en.wikipedia.org/wiki/Data_integration
3. http://www.talend.com
4. Ver Anexo I Licencias de Software
5. http://www.talend.com/download.php
6. Ver estrategia Top/Down en Wikipedia:
http://en.wikipedia.org/wiki/Top_down Explicacin de
estrategia de desarrollo
7. Plataforma Eclipse: http://www.eclipse.org/platform/
8. Artculo de Cron en Wikipedia:
http://en.wikipedia.org/wiki/Cron
Mtodo Alternativo Para Generar la
Tabla de Hechos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
181
Consideraciones previas
Efectuar el producto cartesiano de las dimensiones puede resultar
simple, mientras el tamao de las dimensiones se mantenga
pequeo. A media que las dimensiones incrementan su contenido, el
tiempo de ejecucin del proceso ETL, y el tamao de la tabla de
hechos crecern rpidamente (de forma exponencial). Para explicar
un poco mejor esta situacin, se detallarn a continuacin las
variables que determinan el tamao de la tabla de hechos:
El nmero total de entradas en la tabla de hechos t estar dado por:
Expresin: Total Entradas Tabla de Hechos t
Donde:
a: cantidad de entradas en la dimensin sucursal
b: cantidad de registros en la tabla productos
c: cantidad de entradas en la tabla clientes
d: cantidad de entradas en la tabla tiempo (cantidad de das)
La expresin a x b se encuentra entre parntesis ya que las dos
dimensiones involucradas presentan una incompatibilidad entre s.
La dimensin productos se encuentra desnormalizada hasta el nivel
de producto de sucursal, con lo cual un cliente nunca podr haber
ordenando un producto de una sucursal X a la sucursal Y. Por lo
anterior, es necesario realizar una unin entre las dos dimensiones
en cuestin, resultando el valor de b el cul influir en el tamao de
la tabla de hechos, con lo cual la expresin actualizada resultante es:
Expresin: Total Entradas Tabla de Hechos
Con la definicin anterior, se ilustrar de que manera la tabla de
hechos crece a mediad que el tamao de las dimensiones aumenta.
Se supondrn las siguientes definiciones:
1. o: Promedio de rdenes, por da, por cliente=5
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
182
2. g: Grado en que un cliente repite una orden en un da. Vale
recordar, que si un cliente repite la orden de un producto a una
sucursal el mismo da, se considerar como una sola entrada en
la tabla de hechos (el nivel de agregacin, son los das del ao).
A fines didcticos, este valor se considerar ser muy cercano a
cero, con lo cul no influir en la variacin del nmero de
hechos, es decir se considerar que un cliente nunca repite
una orden el mismo da.
Nota: Vale aclarar que g puede ser mayor a 0 en el sistema
real, se establece el valor a 0 para simplificar los ejemplos a
continuacin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
183
Expresi
n
General
(b=100, c=100,
d=365=1 ao)
(b=2000, c=4000,
d=730=2 aos)
(b=2000,c=4000,d=2920=8
aos)
Cantidad de filas
aplicando
dimensiones-Left
join-ordenes
desnormalizadas
(se registraran los
no hechos): LJ
Cantidad de filas
aplicando rdenes
desnormalizadas -
Inner join-
dimensiones (se
obviaran los no
hechos ): IJ
Relacin Inner Join
/ Left Join
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
184
Si se observa la tabla anterior, se notar que:
Expresin: Inner Join / Left Join
Con lo cul, para saber cuanto espacio se est ahorrando ser
suficiente conocer el nmero promedio de rdenes por da (o) y el
nmero de entradas que contiene la dimensin productos (b). Es fcil
darse cuenta que a medida que, de forma natural, aumenten los das
incluidos en el anlisis, los productos y sucursales que los ofrecen y
los clientes que los ordenan, el nmero b crecer ms rpido que o
(el cul, permanecer casi constante). Todo esto hace evidente el
ahorro en tiempo de ejecucin del proceso ETL y espacio de
almacenamiento.
Para ponerlo en trminos concretos, supongamos que para (b=2000,
c=4000, d=790, o=5) con LJ, la base de datos ocupa 4GB, con IJ el
espacio ocupado ser (4 x 0.0025) 0.01GB=10MB aproximadamente.
Consecuencias de excluir los no hechos
La perdida de la informacin de no hechos, slo ser tangible si se
examina la base de datos de forma manual; accedindola con
herramientas de anlisis, por ejemplo, al ejecutar una consulta contra
el cubo multidimensional Mondrian, se observarn resultados vacos
(a menos que se indique de forma explcita lo contrario).
Creando la tabla de hechos con Talend
De acuerdo a lo expuesto, al finalizar la seccin Creacin de la Tabla
de hechos de JasperETL, resulta ms eficiente obtener la tabla
orders_fact realizando inner joins; a continuacin se detallaran los
pasos para llevarlo a cabo. Se necesitarn los siguientes
componentes:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
185
Diseo de Trabajo alternativo para la tabla de hechos
La configuracin de los componentes observados es la siguiente:
CreateFactTable
Se configura la base de datos, la tabla y el esquema (segn el
esquema resultante) que representar la tabla de hechos.
Orders
Se desnormalizan las entradas de las rdenes, agrupadas por
nombre del negocio
id de sucursal
id de rubro del negocio
estado de orden
id de producto
id del cliente
ao
mes
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
186
da del mes
Cdigo: Desnormalizacin y agrupacin de rdenes
SELECT bu.legalname,
br.id AS id_branch,
o.state_state AS state
, h.id AS id_heading
, r.user_username AS id_client
, oe.product_id AS id_product
, extract (YEAR FROM o.selldateonly) AS year
, extract (MONTH FROM o.selldateonly) AS month
, extract (DAY FROM o.selldateonly) AS day
,avg(pr.price) AS price
, sum(count) AS count
, sum(pr.price*count) AS total
FROM
orderentry AS oe
, orders AS o
, basebranchproduct AS brp
, basebusinessproduct AS bp
, price AS pr
, branch br
,business AS bu
,heading AS h
,heading_business AS hb
,role AS r
,product p
,baseproduct basep
,producttype pt
WHERE
br.rootbusiness_id=bu.id
AND br.id=o.branch_id
AND bu.id=hb.businesses_id
AND h.id=hb.headings_id
AND oe.order_id=o.id
AND oe.product_id=brp.id
AND brp.businessproduct_id=bp.id
AND bp.product_id=p.id
AND basep.id=p.baseproduct_id
AND pt.id=basep.ptype_id
AND pt.heading_id=hb.headings_id
AND oe.sellprice_id=pr.id
AND r.id = o.buyer_id
GROUP BY bu.legalname,
id_branch,id_heading,state,id_product,id_client,year,month,day
Si se observa la sentencia SQL, los campos seleccionados y los
criterios de agrupamiento producirn el resultado necesario para
insertar directamente los datos en la tabla de hechos. Lo nico que
resta, es establecer una nica clave fornea para las dimensiones que
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
187
presentan claves compuestas (tiempo y sucursal). Esto ser realizado
en el paso FactMap, explicado a continuacin:
Diseo de Trabajo alternativo para la tabla de hechos. FactMap
Las expresiones utilizadas para crear las claves forneas son las
siguientes:
Cdigo: Expresin Time Foreign Key
10000 * AggregatedOrders.year + 100 * AggregatedOrders.month +
copyOfAggregatedOrders.day
La expresin anterior, producir un tipo Long compuesto de 8 dgitos,
los cuales representa:
Los dos menos significativos: El da del mes
Los 4 ms significativos: El ao
Los 2 restantes: el mes del ao
Esto garantiza tener una clave nica.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
188
Cdigo: Expresin Branch Foreign Key
AggregatedOrders.legalname + "_br_"+ AggregatedOrders.id_branch + "_h_"
+ AggregatedOrders.id_heading
La expresin anterior, garantiza tener claves nicas para cada
sucursal desnormalizada.
Nota: Es necesario realizar el mismo procedimiento para la
clave primaria de las dimensiones Tiempo y Sucursales, de
otra forma la unin con la tabla de hechos no producir los
resultados esperados.
FactTable
Este componente simplemente realizar las inserciones de acuerdo al
esquema y los datos provenientes de componente FactMap.
Creando la tabla de hechos con Spoon
A continuacin se detallan los pasos para llevar a cabo la
transformacin encargada de generar la tabla de hechos ordes_fact,
de acuerdo a lo expuesto anteriormente, se utiliza el mtodo con
inner joins. Se necesitaran los siguientes componentes:
Vista de la transformacin
Bsicamente esta transformacin desnormaliza las rdenes del
sistema y las coloca en una nueva tabla de la base de datos utilizada
como DW.
Desnormalizacin de rdenes
Para realizar este paso, se utiliza la misma sentencia SQL que se
utiliz en talend dentro de un componente Table Input. Para
configurar este componente se debe seleccionar la conexin de la
cual obtener los datos e introducir la sentencia SQL que extraiga las
rdenes desnormalizadas.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
189
Nota: Por cuestiones de simplicidad de la transformacin, se
decide obtener y desnormalizar los datos con una nica
sentencia SQL en el componente Table Input. El proceso
podra haberse realizado obteniendo los datos de las
diferentes tablas involucradas y luego mediante un
componente Join Rows realizar la unin entre las tablas. Se
considera que el mtodo utilizado es ms simple, rpido y
eficiente para ejecutar.
Creacin de Claves
Ejecutado el paso anterior, se obtendrn los datos necesarios para
cargar la tabla de hechos. Lo nico que resta, al igual que se realiz
en Talend, es establecer una nica clave fornea para las
dimensiones que presentan claves compuestas (tiempo y sucursal).
Para ello se utiliza un componente Modified Java Script Value, el cual,
es configurado para ejecutar la siguiente operacin:
Cdigo: Cdigo JavaScript para creacin de claves
var timeFK = 10000 * year.getNumber() + 100 * month.getNumber() +
day.getNumber();
var branchesFK = legalname.getString() + "_br_" + id_branch.getInteger() +
"_h_" + id_heading.getInteger();
Creacin de claves
Se observa en la imagen anterior que se asignan los tipos adecuados
a las variables creadas, Integer para timeFK y String para
branchesFK.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
190
Seleccin y renombrado de columnas
En este paso se deben seleccionar y renombrar los valores que deben
estar presentes en la tabla de hechos. Para ello se renombra timeFK
a id_time y branchesFK a id_branch, adems se seleccionan las
columnas adecuadas excluyendo year, month, day, legalname,
id_branch e id_heading (valores utilizados para crear las claves
compuestas).
A continuacin se observa la configuracin realizada en Spoon.
Seleccin y renombrado de filas
Creacin de la tabla de hechos
Finalmente se crea un componente Table Output, que se encarga de
crear y cargar los datos en la tabla de hechos. La configuracin
utilizada es la mostrada en la imagen a continuacin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
191
Creacin y carga de datos en la tabla de hechos
Si se selecciona la opcin Use batch update for inserts, el proceso se
ejecutara a mayor velocidad, pero en caso de error se obtendr un
mensaje con pocos detalles de lo sucedido. Si no se selecciona, el
proceso ser ms lento, pero se obtendr un mensaje de error ms
descriptivo.
Resultados Obtenidos
En la imagen a continuacin se observa de qu manera son colocados
los datos en la tabla de hechos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Mtodo Alternativo Para Generar la Tabla de Hechos
192
Diseo de Trabajo alternativo para la tabla de hechos. FactMap
Los resultados obtenidos son los mismos para ambas herramientas.
Comparativa Kettle-JasperETL
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Kettle-JasperETL
195
Talend/JasperETL Kettle
Licencia GPL Pentaho Public Licence
Modelos de
procesos
Se basa en dos tipos de
modelos: Modelos de
Negocio destinados
describir procesos de alto
nivel, bajo contenido
tcnico; Diseo de
Trabajos para la
materializacin de
procesos de
transformacin, se
caracterizan por gran
cantidad de detalles
tcnicos.
Los diagramas estn
divididos en:
Transformaciones,
cuyo fin es el de los
procesos ETTL en si
mismos; por otra
parte los Trabajos
estn orientados a
proceso de alto nivel,
pero an tcnicos,
tales como
ejecuciones de
transformaciones,
transmisiones va FTP,
HTTP o mail, etc.
Formato de
salida
Al ser un entorno basado
en Eclipse, los proyectos
son almacenados en
espacio de trabajo
(workspace). Dentro del
directorio del proyecto se
alojan los diferentes
elementos y sus diferentes
versiones.
Brinda la posibilidad
de elegir entre basar
el proyecto completo
en un repositorio
alojado en una base
de datos o hacerlo en
varios archivos XML.
Formato de los
procesos de
transformacin:
Exporta cada trabajo,
junto a las libreras
necesarias, en el lenguaje
propio del proyecto (Java
o Perl), adems genera un
shell script (.bat para
Windows y .sh para
sistemas Unix like)
encargado de realizar la
ejecucin del trabajo.
Si se esta trabajando
utilizando un
repositorio en una
base de datos, el
formato esta dado por
los datos y la
estructura del
repositorio. Si se
utilizan archivos XML
los procesos de
transformacin se
encuentran definidos
mediante distintos
tags que contienen la
informacin necesaria
para ejecutar los
procesos. Una vez que
se poseen archivos
XML o el repositorio
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Kettle-JasperETL
196
con las
transformaciones, se
debe utilizar Pan para
ejecutar las
transformaciones y
Kitchen para los
trabajos.
Documentacin
generada
Permite exportar toda la
documentacin propia de
un Diseo de Trabajo en
formato HTML. Esta
documentacin, incluye,
pero no se limita a
visualizacin grfica del
diagrama, propiedades de
cada componente que
interviene en el proceso,
documentacin adicional
ingresada en
componentes, etc.
No posee una opcin
para exportar
documentacin de los
trabajos o tareas
desarrolladas. Si se
utiliza Spoon se
pueden obtener los
diagramas que
modelan los distintos
procesos, pero sin
detalle de los valores
de configuracin y
funcionamiento (estos
diagramas dan a un
simple golpe de vista
una idea general de
que hacen las
transformaciones o
trabajos, pero no
como lo hacen).
Interfaz Grfica
de Usuario
Integralmente basada en
Eclipse.
Diseo de UI propio.
Planificacin de
los procesos
ETL
Brinda una perspectiva
Scheduler para facilitar la
planificacin de las
ejecuciones de los
trabajos. Como salida se
obtiene una entrada
crontab.
No brinda una
herramienta integrada
para realizar la
planificacin. Se
deben realizar scripts
que ejecuten los
trabajos o
transformaciones y
luego ejecutarlos
regularmente
mediante alguna
herramienta externa
(por ejemplo Cron).
Ejecucin de los
procesos ETL
se puede realizar la
ejecucin:
Pueden ser ejecutados
mediante Pan
(transformaciones) y
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Kettle-JasperETL
197
1. desde la vista Run
2. ejecutando
manualmente los
scripts generados
3. automticamente
mediante la
planificacin con
Cron
Kitchen (trabajos)
desde una lnea de
comandos. Adems
pueden ser ejecutadas
directamente desde
Spoon.
Herramientas
de debugging
Brinda la Perspectiva
Debug, la cual permite
seguir la traza de
ejecucin como cualquier
otro proyecto Java o Perl
llevado a cabo con Eclipse.
Posee una
herramienta de debug
(brindada por Spoon)
simple.
Componentes
Contiene un amplio
nmero de componentes
agrupados de acuerdo a
su funcionalidad o
naturaleza.
Brinda diversos
componentes
categorizados en las
diferentes funciones
que cumplen.
Entrada desde
BD
Componentes particulares
para AS400, Access,
FireBird, Informix, Ingres,
Interbase, JavaDB, MS
SQL Server, MySQL,
Oracle, PostgreSQL,
SQLite, Sybase y Teradata
en adicin a conexiones
LDAP, Hibernate, y JDBC
genricas. Incluye un
editor SQL para facilitar la
extraccin de datos.
Posee un componente
que permite obtener
informacin de
cualquier base de
datos que pueda
conectarse a JAVA
mediante JDBC.
Tambin permite
obtener datos de
conexiones LDAP.
Salida a un BD
Soporta los mismos
motores de DB listados
anteriormente. A dems
incluye un componente
separado para la creacin
de tablas segn un
esquema dado.
Posee un componente
que permite cargar
datos en cualquier
base de datos que
pueda conectarse a
JAVA mediante JDBC.
Este componente
permite crear o
alterar la tabla en la
base de datos si es
necesario.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Kettle-JasperETL
198
Uniones y
mapeo de datos
El componente tMap es el
componente principal para
llevar a cabo estas
funciones. Permite recibir
mltiples flujos de entrada
de datos y tambin
producir mltiples flujos
de salida. En este
componente se realizan
las uniones de forma
visual y mediante la
utilizacin de un editor de
expresiones. Se eligen
tambin los campos que
componen los flujos
salientes, tambin de
forma visual.
El componente
utilizado en Kettle
para realizar esta
tarea es Join Rows,
Este componente
permite recibir un
flujo de datos de
entrada y mediante
ciertas reglas unir y
limitar el flujo de
salida. Permite
realizar las uniones
mediante la seleccin
de los distintos datos
de entrada que se
desean unir.
Transformacin
y
procesamiento
de datos
Se puede realizar en
diversos componentes.
tMap brinda la posibilidad
de procesar y transformar
los campos entrantes
antes de ser ubicados en
los flujos de salida. En
adicin, el grupo de
componentes Processing
brinda una serie de
funcionalidades tales
como agregar filas,
ordenar filas,
desnormalizar, normalizar,
filtrar columnas, filtrar
filas, procesar mediante
un archivo groovy, cdigo
java, o perl segn
corresponda, entre otras.
Se puede realizar con
diversos
componentes. Los
componentes
agrupados en
Transform permiten
realizar ciertas
acciones sobre los
flujos de entrada,
como por ejemplo
ordenamiento de filas,
calcular un valor para
un nuevo campo,
seleccionar y
renombrar campos,
agrupar campos,
filtrar filas, agregar
secuencias, agregar
constantes, etc.
Funciones
definidas por el
usuario
Se pueden definir tantas
rutinas como se desee
haciendo uso de la librera
estndar o cualquier
librera del lenguaje
elegido. Estas rutinas son
luego agrupadas para ser
usadas en cualquier
componente en el que se
puedan utilizar
No se pueden definir
funciones propias que
luego puedan ser
utilizadas. Se pueden
definir funciones en
los pasos que
ejecutan java script,
pero solo sirven para
ese paso.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Kettle-JasperETL
199
expresiones.
Documentacin
y soporte oficial
Incluye un completo
manual de usuario y foros
activos donde puede
llevarse a cabo diversas
consultas.
Ofrece la
documentacin que
puede ser obtenida
va Web y foros
activos donde puede
llevarse a cabo
diversas consultas.
Conclusin Data Integration
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin Data Integration
203
Finalizada la etapa de Integracin de Datos, se puede concluir que los
procesos ETL necesarios para construir el Data Warehouse han sido
obtenidos satisfactoriamente tanto con JasperETL como con Kettle;
sin embargo, sus prestaciones y caractersticas no son idnticas,
presentando puntos fuertes y dbiles, estas fueron contrastadas en
detalle en la seccin anterior. Para concluir este captulo, se efectuar
una ponderacin de 1 a 5 puntos segn determinadas cualidades
externas que presentan o deberan presentar las herramientas:
Talend/JasperETL Kettle
Funcionalidad 5
[1]
4
[2]
Usabilidad 5
[3]
4
[4]
Flexibilidad 4
[5]
3
[6]
Interoperabilidad 5
[7]
5
[7]
Fiabilidad 5 4
[8]
Eficiencia 4
[9]
4
[10]
Documentacin 5
[11]
5
[12]
Calificacin promedio 4.7 4.15
1. Ofrece las mismas herramientas que para cualquier desarrollo
JSE, adems de herramientas especficas y extensibles de ETL.
2. La herramienta de debugging no es de gran utilidad. Por lo
general cuando se encuentra un problema se deben analizar los
logs de salida generados por la ejecucin.
3. Al ser un entorno eclipse, reduce la curva de aprendizaje
notablemente
4. Como punto dbil se puede decir que posee algunas
imperfecciones sobre, todo en los layouts. En cuanto a puntos a
favor se encontr que es simple y fcil de usar.
5. Algunas propiedades no pueden utilizar variables (por ejemplo
el nmero de filas para un tRowGenerator). Esto hace difcil
cambiar el comportamiento de los scripts con variables de
contextos.
6. No presenta opciones para modificar la funcionalidad de
componentes o agregar nuevos.
7.
7,0
7,1
Presenta la posibilidad de trabajar con distintas
tecnologas y formatos de datos, esto permite crear
transformaciones obteniendo datos de un gran numero de
fuentes.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin Data Integration
204
8. La aplicacin present algunos errores menores que pueden
ser sobrepasados y alcanzar el objetivo deseado.
9. Al elaborar transformaciones complejas con mltiples
entradas desde una nica base de datos, la simplificacin visual
en diferentes pasos de extraccin, puede traer como
consecuencia perdida de eficiencia, resultando una nica
sentencia SQL equivalente mejor alternativa.
10. Cuando se trabaja con gran cantidad de datos las
ejecuciones de transformaciones tardan mucho tiempo en
ejecutarse.
11. Talend ofrece una gua integral del funcionamiento del
UI y de todos los componentes ETL incluidos.
12. Hay una manual con informacin de como utilizar los
distintos componentes de la aplicacin y un foro donde hacer
preguntas.
Referencias y recursos
1. Para ms informacin sobre el concepto Integracin de Datos
ver Seccin Conceptos previos de Business
Intelligence/Load Manager
2. Ver seccin Modelo Multidimensional
3. Sito Web de Pentaho Data Integration:
http://www.pentaho.com/products/data_integration/
4. Sitio Web de JasperETL
http://www.jasperforge.org/sf/projects/jasperetl
5. Sitio Web de talend: http://www.talend.com/
Captulo IV: OLAP
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
OLAP
207
Con el diagrama general de BI-FLOSS en mente, estos son los temas
a desarrollar:
Temas a Desarrollar
Trabajando con Mondrian
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
211
Introduccin
Mondrian
[1]
es un motor de Procesamiento Analtico En Lnea (On
Line Analytical Processing - OLAP)
[2]
escrito en lenguaje Java;
procesa y ejecuta consultas en lenguaje MDX
[3]
, obteniendo datos de
una base de datos relacional por intermedio de una conexin JDBC
con un Sistema de Gestin de Base de Datos Relacional o RDBMS
[4]
,
brindando resultados en formato Multidimensional.
A diferencia del procesamiento transaccional (OLTP)
[5]
, en el cual las
operaciones usualmente consisten en leer o escribir pequeas
porciones de datos, el procesamiento analtico opera con grandes
volmenes de datos y las operaciones son mayormente de lectura.
Cuando se dice que el procesamiento es en linea, no importa cuan
grande sea la cantidad de datos manejados, la respuesta debe ser lo
suficientemente rpida para explorar los datos de forma interactiva.
OLAP utiliza una tcnica denominada Anlisis Multidimensional;
mientras una base de datos relacional almacena los datos en
columnas y filas, una base de datos multidimensional lo hace en ejes
y celdas
[6]
.
Licencia
Mondrian se licencia bajo la Pentaho Public License
[7]
Versin utilizada
Mondrian 2.4.2.9831
Mondrian Workbench 2.3.2.9247
Arquitectura de Mondrian
Primero se observarn las capas y componentes grficamente, para
luego explicar las cuatro capas que conforman un sistema OLAP
Mondrian:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
212
Arquitectura de Mondrian
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
213
Capas de un sistema Mondrian
Un sistema OLAP Mondrian consiste de 4 capas: capa de
presentacin, la capa dimensional, la capa de estrella (Star Layer) y
por ltimo la capa de almacenamiento (Storage Layer). A
continuacin se explicar de forma sinttica la finalidad de cada una
de las capas:
Capa de presentacin (Nro 1)
Determina que es lo que ve el usuario final en el monitor y de que
forma interacta y efecta preguntas. La forma de representacin
puede consistir en tablas pivot, diagramas de torta y barras y
tambin herramientas de visualizacin avanzada como mapas
interactivos o grficos dinmicos. Estos pueden estar escritos en
Swing o JSP, cuadros exhibidos en JPEG y GIF o transmitidos a una
aplicacin remota va XML. Por diversas y heterogneas que
parezcan estas formas de presentacin, tienen en comn la
gramtica multidimensional, medidas y celdas en las cuales la
capa de presentacin efecta preguntas y el servidor OLAP retorna la
respuesta.
Capa dimensional (Nro 2)
Esta capa analiza gramaticalmente (parsing), valida y ejecuta
sentencias MDX
[3]
. Una consulta es evaluada en mltiples fases. Los
ejes son computados primero y luego los valores de las celdas dentro
de los ejes. Por razones de eficiencia, la capa dimensional enva
requerimientos de celdas (cell-requests) a la capa de agregacin en
lotes. Un transformador de sentencias (query transformer) permite
a la aplicacin manipular consultas existentes, en vez de construir
una sentencia nueva por cada peticin. Los metadatos describen el
modelo multidimensional, y de que manera se corresponde o mapea
en el modelo relacional.
Capa de estrella (Nro 3)
Es la responsable de mantener un cach de agregaciones. Una
agregacin es un conjunto de valores de medidas (celdas) en
memoria, descriptas por una serie de valores de columnas
dimensionales. Esta capa recibe peticiones por un conjunto de celdas.
Si las celdas no se encuentran en cach, o disponibles al realizar roll-
up en una agregacin en cach, el gestor de agregacin enva una
peticin a la capa de persistencia.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
214
Capa de almacenamiento (Nro 4)
Esta capa se encuentra representada por un SGBDR, esto es lo que
convierte a Mondrian en un servidor ROLAP. Es la capa responsable
de brindar celdas agregadas de datos y miembros de las tablas
dimensionales. La decisin de utilizar un SGBDR se basa en que
brinda toda la funcionalidad necesaria para efectuar las agregaciones
requeridas para simular un modelo multidimensional, quitando la
complejidad del desarrollo MOLAP y manteniendo independiente la
decisin del SGBDR a ser utilizado, ganando en flexibilidad.
Despliegue
Estas capas pueden existir en una misma mquina, o pueden
encontrarse distribuidos entre diferentes mquinas. Las capas 2 y 3,
las que comprenden el servidor Mondrian, deben estar en la misma
mquina. La capa de persistencia (capa 4) puede encontrarse
separada, siendo accedida remotamente va una conexin JDBC. En
un ambiente multiusuario, la lgica de presentacin (capa 1) se
alojar en la mquina de cada usuario final, a menos que la lgica de
presentacin sea un modelo cliente-servidor como lo es JSP.
API
Mondrian brinda una API para que las aplicaciones clientes puedan
ejecutar consultas. Ya que no existe una API universalmente
aceptada para ejecutar consultas OLAP, la API que ofrece Mondrian es
propietaria. De todos modos, cualquiera que haya utilizado JDBC
debera adaptarse fcilmente; la diferencia fundacional reside en el
lenguaje de consultas: Mientras que JDBC est fuertemente ligado a
SQL, Mondrian (y en general, cualquier motor OLAP) brinda soporte
lenguaje llamado MDX (Multi-Dimensional eXpresions)
[3]
.
olap4j
olap4j
[8]
es la API Java Open Source para OLAP. Muchas
compaas y organizaciones dedicadas al desarrollo de Software OLAP
Open Source, han aunado fuerzas para lograr una API comn que
emule a JDBC. Entre estas organizaciones se encuentra Pentaho, ms
precisamente el proyecto Mondrian, el cul posee en sus planes
incluir olap4j como API oficial. Si bien las versiones existentes de
Pentaho no incluyen olap4j, todo parece indicar que aquellas
versiones de Mondrian que surjan de 2008 en adelante s lo harn.
Por el momento, si se desea hacer uso de olap4j es preciso obtener la
ltima versin (que incluye un Driver Mondrian) y empezar a usar
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
215
esta prominente API. Vale destacar que el valor potencial del uso de
olap4j reside en el hecho de evitar aprender mltiples APIs para
mltiples motores OLAP Java, ya que si se desarrolla un driver olap4j
correspondiente a dichos motores podrn desarrollarse aplicaciones
OLAP, independientemente del motor utilizado, es decir portables.
Diseando un Esquema Mondrian
Que es un esquema
Un esquema define una base de datos multidimensional: contiene un
modelo lgico, compuesto por cubos, jerarquas y miembros en
adicin a un mapeo de este modelo en un modelo fsico.
El modelo lgico consiste en las construcciones usadas para escribir
consultas en lenguaje MDX, esto es, cubos, dimensiones, jerarquas,
niveles y miembros.
El modelo fsico es la fuente de datos, la cul es presentada a
travs del modelo lgico. Es tpicamente un esquema estrella, el cual
consiste en un conjunto de tablas en una base de datos relacional.
Archivos de esquema
Los esquemas Mondrian se alojan en un archivo XML. Este esquema
puede ser editado de forma manual, o utilizando el Workbench de
Mondrian
[9]
.
Modelo lgico
Los componentes ms importantes de un esquema son cubos,
medidas y dimensiones:
Un cubo es una coleccin de dimensiones y medidas en un
rea temtica particular.
Una medida es una cantidad, la cual se est interesado en
medir, por ejemplo, unidades vendidas de un producto.
Una dimensin es un atributo, o un conjunto de atributos por
los cuales se puede dividir medidas en sub-categoras. Por
ejemplo, se podra desear dividir las ventas de un producto por
su color, el gnero de los clientes que los compran, y la
sucursal en la cual el producto fue vendido; en este caso color,
gnero y sucursal son dimensiones.
Se comenzar a desarrollar el esquema correspondiente al modelo
multidimensional Ordenes de Gua Online de Negocios.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
216
Cdigo: Definicin del Esquema
<Schema name="OrdersSchema">
</Schema>
Los atributos usados en el tag Schema son:
name: El nombre asignado al esquema.
measuresCaption: etiqueta que se mostrar para el miembro
'All' Este atributo puede ser de utilidad para fines de
localizacin, es decir, en lugar de asignar un String para
mostrar, se puede asignar una propiedad obtenida de un
archivo properties segn sea la configuracin localizada de
Mondrian.
[10][11]
Cubo
Es una coleccin con nombre de medidas y dimensiones. Lo nico que
tienen en comn medidas y dimensiones es una tabla de hechos. En
el caso prctico en cuestin, dicha tabla es orders_fact. Como es
fcil de apreciar, la tabla de hechos contiene las columnas a partir de
las cuales las medidas son calculadas, tambin contiene referencias a
las tablas que representan las dimensiones.
El elemento XML Cube es el indicado para la definicin del cubo y sus
atributos:
Cdigo: Definicin del cubo
<Cube name="Orders" cache="true" enabled="true">
<Table name="orders_fact" schema="public">
</Table>
</Cube>
Donde los elementos de Cube significan:
name: nombre del cubo
caption: etiqueta que se mostrar para el miembro 'All', este
atributo puede ser de utilidad para fines de localizacin, es
decir, en lugar de asignar un String para mostrar, se puede
asignar una propiedad que ser obtenida de un archivo
properties determinado de acuerdo la configuracin de
Mondrian.
[10][11]
cache: si Mondrian mantendr o no en cache agregaciones de
este cubo. Su valor por defecto es true.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
217
enabled: indica si este cubo debe ser tenido en cuenta o
ignorado.
table: elemento para indicar la tabla de hechos (o central) en
el cubo.
o name: el nombre de la tabla correspondiente
o schema: el mbito o calificador de la tabla.
o alias: ser utilizado en las consultas. Debe ser nico en
el esquema. Una tabla puede utilizarse en mltiples
jerarquas, pero con diferentes alias. Si no se especifica,
se utilizar el nombre de la tabla.
Medidas (Measures)
El cubo de rdenes (OrdersCube) define una serie de medidas, entre
ellas "Unidades vendidas" y "Monto total Vendido":
Cdigo: Definicin de medidas
<Cube>
<Measure name="Branch Sales" column="total" datatype="Numeric"
formatString="#,###.00" aggregator="sum" visible="true">
</Measure>
</Cube>
Donde sus atributos representan:
name: el nombre de la medida.
column: columna de la tabla de hechos correspondiente a la
medida.
datatype: el tipo de datos interno que manejar Mondrian o en
XML para Analisis (XML/A).
formatString: especifica el formato numrico a mostrar. La
puntuacin de miles y milsimas son dependientes de la
configuracin local.
aggregator: funcin para llevar a cabo la agregacin de filas.
Puede ser uno de sum, count, max, min, avg, distinct-count.
formatter: til para personalizar la clase que llevar a cabo el
formateo. Debe implementar la interfaz
mondrian.olap.CellFormatter interface.
caption: etiqueta que se mostrar para el miembro 'All', este
atributo puede ser de utilidad para fines de localizacin, es
decir, en lugar de asignar un String para mostrar, se puede
asignar una propiedad que ser obtenida de un archivo
properties determinado de acuerdo la configuracin de
Mondrian.
[10][11]
visible: especifica si se ver o no en la interfaz de usuario esta
medida. Por defecto, su valor es true.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
218
En lugar de provenir de una columna, una medida puede usar un cell
reader o una expresin SQL para calcular su valor.
Dimensiones, jerarquas y niveles
Antes, algunas definiciones para aclarar ms el panorama:
Un miembro (member) es un punto dentro de una dimensin
determinada por un valor o conjunto de valores de sus
atributos. Por ejemplo en la dimensin tiempo, un miembro es
por ejemplo 11/12/2007 o lo que sera lo mismo los atributos
da, mes y ao con valores 11,12,2007 respectivamente.
Una jerarqua (hierarchy) es un conjunto de atributos
organizados en una estructura para realizar un anlisis
conveniente. Por ejemplo, para sucursales, una jerarqua podra
ser los atributos Sucursal, Negocio, Ciudad, Estado, Pas,
Continente. Una jerarqua permite obtener sub-totales
intermedios: el total de un negocio, es la suma de los sub-
totales de sus sucursales por ejemplo.
Un nivel (level) es un conjunto de miembros que se
encuentran a la misma distancia de la raz de la jerarqua. Si se
habla del nivel Negocios de la jerarqua Sucursales, se hace
referencia a todos los negocios existentes.
Una dimensin es un conjunto de jerarquas, las cuales
discriminan el mismo atributo de la tabla de hechos, por
ejemplo sucursales.
Por razones de consistencia, las medidas son tratadas como
miembros de una dimensin especial denominada Medidas
(Measures).
Dimensin (dimension)
Una dimensin es unida a un cubo por medio de un par de columnas,
una en la tabla de hechos, la otra en la tabla de la dimensin.
Definicin de la dimensin tiempo (DimensionTime) representada por
la tabla lookup_time:
Cdigo: Definicin de una dimensin
<Cube name="Orders" cache="true" enabled="true">
.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
219
.
.
<Dimension type="TimeDimension" foreignKey="id_time" name="Time">
<Hierarchy name="Time" hasAll="true" primaryKey="id_time"
primaryKeyTable="lookup_time">
<Table name="lookup_time" schema="public">
</Table>
<Level name="Year" table="lookup_time" column="year" type="Integer"
uniqueMembers="false" levelType="TimeYears" hideMemberIf="Never">
</Level>
<Level name="Quarter" table="lookup_time" column="quarter"
type="Integer" uniqueMembers="false" levelType="TimeQuarters"
hideMemberIf="Never">
</Level>
<Level name="Month" table="lookup_time" column="month"
nameColumn="month_name" ordinalColumn="month" type="Integer"
uniqueMembers="false" levelType="TimeMonths" hideMemberIf="Never">
</Level>
<Level name="Day" table="lookup_time" column="month_day"
type="Integer" uniqueMembers="false" levelType="TimeDays"
hideMemberIf="Never">
</Level>
</Hierarchy>
</Dimension>
.
.
.
</cube>
Los atributos del elemento XML dimension son los siguientes:
name: el nombre de la dimensin.
foreignKey: la columna de la tabla de hechos que hace
referencia a la clave primaria de la tabla dimensional.
type: Define si la dimensin es una dimensin ordinaria
("Standard") o una dimensin tiempo ("Time"). Una dimensin
tiempo permitir el uso de funciones mdx referentes al tiempo
(WTD, YTD, QTD, etc). El valor por defecto de este atributo es
"Standard". En el ejemplo se trata de una dimensin de tipo
"Time".
caption: etiqueta que se mostrar para el miembro 'All', este
atributo puede ser de utilidad para fines de localizacin, es
decir, en lugar de asignar un String para mostrar, se puede
asignar una propiedad que ser obtenida de un archivo
properties determinado de acuerdo la configuracin de
Mondrian.
[10][11]
Dentro del elemento dimension pueden definirse sub-elementos
hierarchy, el cual es abordado a continuacin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
220
Jerarqua (hierarchy)
Cdigo: Definicin de una jerarqua
<Hierarchy name="Time" hasAll="true" primaryKey="id_time"
primaryKeyTable="lookup_time">
<Table name="lookup_time" schema="public">
</Table>
<Level name="Year" table="lookup_time" column="year" type="Integer"
uniqueMembers="false" levelType="TimeYears" hideMemberIf="Never">
</Level>
<Level name="Quarter" table="lookup_time" column="quarter"
type="Integer" uniqueMembers="false" levelType="TimeQuarters"
hideMemberIf="Never">
</Level>
<Level name="Month" table="lookup_time" column="month"
nameColumn="month_name" ordinalColumn="month" type="Integer"
uniqueMembers="false" levelType="TimeMonths" hideMemberIf="Never">
</Level>
<Level name="Day" table="lookup_time" column="month_day"
type="Integer" uniqueMembers="false" levelType="TimeDays"
hideMemberIf="Never">
</Level>
</Hierarchy>
Los principales atributos del elemento hierarchy son:
name: el nombre de la jerarqua, si no es especificado ser
nombrado igual que la dimensin.
hasAll: valor booleano que indica si esta jerarqua posee o no
un miembro 'All'.
allMemberName: nombre que tomar el miembro 'All', si no
se especifica toma el nombre de la jerarqua antecedido por la
palabra All por ejemplo 'All Time'.
allMemberCaption: etiqueta que se mostrar para el miembro
'All', este atributo puede ser de utilidad para fines de
localizacin, es decir, en lugar de asignar un String para
mostrar, se puede asignar una propiedad que ser obtenida de
un archivo properties determinado de acuerdo la configuracin
de Mondrian.
[10][11]
primaryKey: el nombre de la columna que identifica
miembros, y la cual es referenciada desde la tabla de hechos.
(Ver el elemento foreignKey del elemento dimension).
primaryKeyTable: la tabla que posee a primaryKey. Si la
jerarqua posee una sola tabla, ser esta por defecto.
caption: etiqueta que se mostrar para el miembro 'All', este
atributo puede ser de utilidad para fines de localizacin, es
decir, en lugar de asignar un String para mostrar, se puede
asignar una propiedad que ser obtenida de un archivo
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
221
properties determinado de acuerdo la configuracin de
Mondrian.
[10][11]
Hierarchy puede contener sub-elementos del tipo relation, level y
MemberReaderParameter. Se har a continuacin mencin al
elemento level:
Nivel (level)
Cdigo: Definicin de un nivel
<Level name="Year" table="lookup_time" column="year" type="Integer"
uniqueMembers="false" levelType="TimeYears" hideMemberIf="Never">
</Level>
Los atributos principales de level son:
name: el nombre del nivel.
table: el nombre de la tabla a la cual pertenece el nivel. Si la
jerarqua est basada en una sola tabla no es necesario
especificarla.
column: la columna que identifica los miembros del nivel en la
jerarqua. En el ejemplo, la columna year.
nameColumn: el nombre que ser usado para mostrar en el
nivel. Sino se especifica es el mismo que column.
ordianlColumn: la columna que se usar para ordenar los
miembros. Si no se especifica, es igual que la clave (column).
parentChild: en una relacin parent-child, esta columna
identifica la columna padre del actual nivel.
type: el tipo de dato del nivel.
uniqueMembers: indica si est miembro es nico para todos
los padres. Por ejemplo, un cdigo postal es nico para todos
los padres nico para todas las zonas.
levelType: slo para los niveles correspondientes a jerarquas
de tiempo.
Dimensiones Degeneradas (Degenerated
Dimensions)
Una dimensin degenerada es una dimensin que es tan simple
(un nico miembro), que no es necesario la creacin de una tabla
dimensional; en lugar de ello, se crea un campo en la tabla de hechos
que contenga el valor que toma el miembro para una entrada dada.
Es el caso de una dimensin factible de ser degenerada Order_State
del caso prctico llevado a cabo en el presente libro, la cul
representa si el estado de una orden es, Finalizado (se concret
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
222
exitosamente) o Cancelado (se abort la operacin). De
implementar esta dimensin como una tabla dimensional
independiente, no se estara brindando informacin adicional y se
estara incurriendo en un join adicional. Para declarar una dimensin
degenerada simplemente basta con hacerlo igual que para una
dimensin comn, pero sin declarar la tabla; a continuacin se ofrece
el fragmento xml del esquema donde se define la dimension
OrderStatus como una dimensin degenerada:
Cdigo: Definicin de la dimensin degenerada Order_State
<Dimension type="StandardDimension" name="OrderStatus">
<Hierarchy hasAll="true">
<Level name="Order Status" column="state" type="String"
uniqueMembers="false">
</Level>
</Hierarchy>
</Dimension>
Ntese que el atributo foreignKey en dimension tampoco es
necesario, ya que no se efectuar una unin con la tabla de hechos.
La especificacin oficial del esquema XML de Mondrian
[12]
(en ingls)
puede ser de utilidad para ampliar la nocin sobre sus elementos.
Esquema definido para GONBI
Cubo rdenes: Destinado a analizar los pedidos que fueron
realizados al sistema GON, desde diferentes perspectivas. En el
modelo fsico la tabla de hechos ser orders_fact.
o Dimensin tiempo: tabla lookup_time
Jerarqua tiempo
Nivel ao
Nivel cuatrimestre
Nivel mes
Nivel da del mes
o Dimensin sucursales: tabla lookup_branches
Jerarqua ubicacin sucursales
Nivel continente
Nivel pas
Nivel estado o provincia
Nivel ciudad
Nivel zona
Nivel sucursal
Jerarqua rubros
Nivel categora
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
223
Nivel rubro
Nivel negocio
Nivel sucursal
o Dimensin clientes: tabla lookup_clients
Jerarqua ubicacin clientes
Nivel continente
Nivel pas
Nivel estado o provincia
Nivel ciudad
Nivel zona
Nivel cliente
Jerarqua sexo
Nivel sexo
Nivel cliente
o Dimensin Productos: tabla lookup_products
Jerarqua tipo de producto
Nivel categora
Nivel rubro
Nivel tipo de producto
Nivel marca
Nivel producto
Nivel producto del negocio
Nivel producto de la sucursal
o Dimensin Estado de Orden
Jerarqua Estado de orden
Nivel estado: Finalizado (Concretado) o
Cancelado.
o Medidas
Unidades vendidas: representado por la suma de la
columna count en la tabla de hechos. Desde el
punto de vista de perspectivas o dimensiones,
representar la suma de unidades pedidas para un
producto, por un cliente, en una sucursal, el mismo
da cuyo estado no difiera (Finalizado o Cancelado).
Branch sales: monto vendido por las sucursales,
suma de la columna total de la tabla de hechos.
Representa la suma monetaria de las Unidades
Vendidas.
Nota: Para dejar en claro de que forma se agregan las
medidas, se presenta el siguiente Caso ejemplificador: el
da X, el cliente A realiza tres rdenes a la sucursal B, en
las que incluye el producto C (4 unidades en la primer orden,
9 en la segunda y 15 en la tercera) a un precio unitario de
2. El cliente A cancel la segunda orden. Se ofrecen a
continuacin una serie de situaciones de anlisis del caso
planteado junto a sus resultados:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
224
Cdigo: Ejemplo 1
Pseudo MDX: Unidades Vendidas y Monto de ventas de Sucursal
(Medidas) en Columnas, da X, cliente A, sucursal B, producto C
en filas sin condicin adicional
Resultado esperado
Unit
Sales
Branch
Sales
Da X Cliente A Sucursal B Producto C 28 56
Cdigo: Ejemplo 2
Pseudo MDX: Unidades Vendidas y Monto de ventas de Sucursal
(Medidas) en Columnas, da X, cliente A, sucursal B, producto C,
estado de orden en filas sin condicin adicional
Resultado esperado (luego de efectuar un drill-down por la
dimensin estado de orden):
Unit
Sales
Branch
Sales
Da X
Cliente
A
Sucursal
B
Producto
C
Finalizada 19 38
Da X
Cliente
A
Sucursal
B
Producto
C
Cancelada 9 18
Definicin de orders.xml
Cdigo: orders.xml
<Schema name="OrdersSchema">
<Cube name="Orders" cache="true" enabled="true">
<Table name="orders_fact" schema="public">
</Table>
<Dimension type="TimeDimension" foreignKey="id_time" name="Time">
<Hierarchy name="Time" hasAll="true" primaryKey="id_time"
primaryKeyTable="lookup_time">
<Table name="lookup_time" schema="public">
</Table>
<Level name="Year" table="lookup_time" column="year" type="Integer"
uniqueMembers="false" levelType="TimeYears" hideMemberIf="Never">
</Level>
<Level name="Quarter" table="lookup_time" column="quarter"
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
225
type="Integer" uniqueMembers="false" levelType="TimeQuarters"
hideMemberIf="Never">
</Level>
<Level name="Month" table="lookup_time" column="month"
nameColumn="month_name" ordinalColumn="month" type="Integer"
uniqueMembers="false" levelType="TimeMonths" hideMemberIf="Never">
</Level>
<Level name="Day" table="lookup_time" column="month_day"
type="Integer" uniqueMembers="false" levelType="TimeDays"
hideMemberIf="Never">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" foreignKey="id_branch"
name="Branches">
<Hierarchy name="BranchesZone" hasAll="true" primaryKey="id_branch"
primaryKeyTable="lookup_branches">
<Table name="lookup_branches" schema="public">
</Table>
<Level name="Continent" table="lookup_branches" column="continent"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Country" table="lookup_branches" column="country"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="State" table="lookup_branches" column="state"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="City" table="lookup_branches" column="city" type="String"
uniqueMembers="false" levelType="Regular" hideMemberIf="Never">
<Property name="ZipCode" column="zipcode" type="String">
</Property>
</Level>
<Level name="Zone" table="lookup_branches" column="zone"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Branch" table="lookup_branches" column="street_number"
nameColumn="name" type="String" uniqueMembers="false"
levelType="Regular" hideMemberIf="Never">
<Property name="LegalName" column="legalname" type="String">
</Property>
<Property name="BusinessID" column="businessid" type="String">
</Property>
<Property name="Heading" column="headingname" type="String">
</Property>
<Property name="HeadingDescription" column="description"
type="String">
</Property>
<Property name="Category" column="cateogry" type="String">
</Property>
<Property name="PhoneNumber" column="phonenumber" type="String">
</Property>
<Property name="SecondaryPhone" column="secondaryphonenumber"
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
226
type="String">
</Property>
<Property name="Fax" column="fax" type="String">
</Property>
<Property name="email" column="email" type="String">
</Property>
<Property name="FloorNumber" column="floornumber" type="String">
</Property>
<Property name="ApartmentNumber" column="apartmentnumber"
type="String">
</Property>
<Property name="BusinessName" column="name" type="String">
</Property>
<Property name="StreetNumber" column="street_number" type="String">
</Property>
</Level>
</Hierarchy>
<Hierarchy name="Category" hasAll="true" primaryKey="id_branch"
primaryKeyTable="lookup_branches">
<Table name="lookup_branches" schema="public">
</Table>
<Level name="Category" table="lookup_branches" column="cateogry"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Heading" table="lookup_branches" column="heading_id"
nameColumn="headingname" ordinalColumn="headingname" type="String"
uniqueMembers="false" levelType="Regular" hideMemberIf="Never">
<Property name="Description" column="description" type="String">
</Property>
</Level>
<Level name="Business" table="lookup_branches" column="name"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
<Property name="LegalName" column="legalname" type="String">
</Property>
<Property name="BusinessID" column="businessid" type="String">
</Property>
</Level>
<Level name="Branch" table="lookup_branches" column="branch_id"
nameColumn="street_number" type="String" uniqueMembers="false"
levelType="Regular" hideMemberIf="Never">
<Property name="PhoneNumber" column="phonenumber" type="String">
</Property>
<Property name="SecondaryPhone" column="secondaryphonenumber"
type="String">
</Property>
<Property name="Fax" column="fax" type="String">
</Property>
<Property name="email" column="email" type="String">
</Property>
<Property name="FloorNumber" column="floornumber" type="String">
</Property>
<Property name="ApartmentNumber" column="apartmentnumber"
type="String">
</Property>
<Property name="Continent" column="continent" type="String">
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
227
</Property>
<Property name="Country" column="country" type="String">
</Property>
<Property name="State" column="state" type="String">
</Property>
<Property name="City" column="city" type="String">
</Property>
<Property name="Zone" column="zone" type="String">
</Property>
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" foreignKey="id_client"
name="Clients">
<Hierarchy hasAll="true" primaryKey="username"
primaryKeyTable="lookup_clients">
<Table name="lookup_clients" schema="public">
</Table>
<Level name="Continent" table="lookup_clients" column="continent"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Country" table="lookup_clients" column="country"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="State" table="lookup_clients" column="state" type="String"
uniqueMembers="false" levelType="Regular" hideMemberIf="Never">
</Level>
<Level name="City" table="lookup_clients" column="city" type="String"
uniqueMembers="false" levelType="Regular" hideMemberIf="Never">
<Property name="ZipCode" column="zipcode" type="String">
</Property>
</Level>
<Level name="Zone" table="lookup_clients" column="zone" type="String"
uniqueMembers="false" levelType="Regular" hideMemberIf="Never">
</Level>
<Level name="Client" table="lookup_clients" column="username"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
</Hierarchy>
<Hierarchy name="Gender" hasAll="true" primaryKey="username"
primaryKeyTable="lookup_clients">
<Table name="lookup_clients" schema="public">
</Table>
<Level name="Gender" table="lookup_clients" column="gender"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Client" table="lookup_clients" column="username"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
<Property name="Name" column="name" type="String">
</Property>
<Property name="LastName" column="lastname" type="String">
</Property>
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
228
<Property name="BirthDate" column="birthdate" type="String">
</Property>
<Property name="RegistrationDate" column="registrationdate"
type="String">
</Property>
<Property name="PhoneNumber" column="phonenumber" type="String">
</Property>
<Property name="SecondaryPhone" column="secondaryphonenumber"
type="String">
</Property>
<Property name="Fax" column="fax" type="String">
</Property>
<Property name="email" column="email" type="String">
</Property>
<Property name="Street" column="street" type="String">
</Property>
<Property name="StreetNumber" column="number" type="String">
</Property>
<Property name="ApartmentNumber" column="apartmentnumber"
type="String">
</Property>
<Property name="FloorNumber" column="floornumber" type="String">
</Property>
<Property name="Continent" column="continent" type="String">
</Property>
<Property name="Country" column="country" type="String">
</Property>
<Property name="State" column="state" type="String">
</Property>
<Property name="City" column="city" type="String">
</Property>
<Property name="Zone" column="zone" type="String">
</Property>
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" foreignKey="id_product"
name="Products">
<Hierarchy name="Products" hasAll="true" primaryKey="branch_product_id"
primaryKeyTable="lookup_products">
<Table name="lookup_products" schema="public">
</Table>
<Level name="Category" table="lookup_products" column="category"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Heading" table="lookup_products" column="headingname"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
<Property name="Description" column="heading_description"
type="String">
</Property>
</Level>
<Level name="Product Type" table="lookup_products"
column="product_type" type="String" uniqueMembers="false"
levelType="Regular" hideMemberIf="Never">
<Property name="Product Type Description" column="ptype_description"
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
229
type="String">
</Property>
</Level>
<Level name="Brand" table="lookup_products" column="brand_nationality"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
<Level name="Product" table="lookup_products"
column="particular_description" type="String" uniqueMembers="false"
levelType="Regular" hideMemberIf="Never">
<Property name="General Description" column="general_description"
type="String">
</Property>
<Property name="Product Name" column="product_name" type="String">
</Property>
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" name="OrderStatus">
<Hierarchy hasAll="true">
<Level name="Order Status" column="state" type="String"
uniqueMembers="false">
</Level>
</Hierarchy>
</Dimension>
<Measure name="Unit Sales" column="count" datatype="Numeric"
formatString="#,###" aggregator="sum" visible="true">
</Measure>
<Measure name="Branch Sales" column="total" datatype="Numeric"
formatString="#,###.00" aggregator="sum" visible="true">
</Measure>
</Cube>
</Schema>
Conexin con el esquema y ejecucin de
consultas MDX
Mondrian Workbench
El workbench de Mondrian
[9]
, es un entorno visual para el desarrollo y
prueba de cubos OLAP Mondrian. Si bien la definicin del XML para
esquemas Mondrian no es extremadamente compleja, en la prctica
resulta engorroso recordar cada uno de los elementos junto a sus
atributos y sub-elementos. Con esta aplicacin, se puede configurar
una conexin JDBC como el modelo fsico, para luego elaborar el
esquema lgico de manera simple y efectiva. Para ello el entorno
ofrece:
Un editor de esquemas con la fuente de datos subyacente para
su validacin
Ejecucin de consultas MDX contra el esquema y la base de
datos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
230
Navegacin por la base de datos subyacente
Se observar en forma resumida, de que manera se configura la
fuente que da inicio al diseo del esquema: Para iniciar el
Workbench, se debe descargar la versin compilada desde
http://sourceforge.net/project/showfiles.php?group_id=35302 o bien
compilar desde las fuentes que incluye el archivo comprimido de
Mondrian. Compilarlo no presenta mayores problemas si se tiene
experiencia con javac o un IDE como Eclipse; para simplificar se
usar la versin ya empaquetada. Suponiendo que el directorio en el
que fue descomprimido el Workbench es WORKBENCH_HOME se
procede a ejecutar:
$ $WORKBENCH_HOME/workbench.sh para entornos Unix
> %WORKBENCH_HOME%/workbench.bat para entornos Windows
Una vez que lo ejecutamos, se observa el Workbench con la siguiente
apariencia:
Mondrian Workbench
Para configurar la base de datos que representar el modelo lgico,
es necesario acceder al men preferencias (preferences) desde
herramientas (tools). El dialogo presentado luego, es el siguiente:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
231
Preferencias
Se deben completar los campos correspondientes a la conexin JDBC
de la base de datos del data warehouse. Es necesario asegurarse que
el archivo jar del driver requerido se encuentre en el directorio
$WORKBENCH_HOME/drivers, ya que de no ser as el script de
ejecucin invocar a la JVM con un classpath incompleto para el
correcto funcionamiento de las conexiones.
Nota: La informacin arriba ingresada ser de utilidad para
dos fines:
1. Al crear un nuevo esquema, se realizar una conexin
JDBC con la fuente de datos para validar y facilitar
metadatos para la configuracin del esquema. El
archivo de configuracin del Workbench se encuentra
en el archivo
$HOME/.schemaWorkbench/workbench.properties. En
el mismo reside informacin tanto de ltimos esquemas
editados como de ltimos datos JDBC configurados.
2. Al crear una nueva consulta MDX, se realizar una
conexin Mondrian en la cual los datos referentes a
la conexin JDBC mencionados anteriormente sern
utilizados por la capa Nmero 4. El archivo de
propiedades Mondrian se encuentra en
$HOME/.schemaWorkbench/mondrian.properties, en el
mismo se encuentra las principales propiedades de
Mondrian
Una vez que la fuente de datos qued correctamente configurada, se
elige la opcin nuevo esquema (new/schema) desde el men archivo
(file). Si la conexin con la base de datos fue exitosa, se observara la
siguiente pantalla:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
232
Preferencias
Ahora slo resta completar la informacin del esquema creando
cubos, dimensiones, jerarquas y niveles que se requieran. En la
captura de pantalla siguiente, se observa que la creacin y
configuracin de atributos es muy grfica, autodescriptiva e intuitiva:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
233
Edicin de esquema
Multi-Dimensional eXpressions
MDX es el lenguaje para efectuar consultas a una base de datos
multidimensional (OLAP), de forma anloga a que SQL lo es para
base de datos relacionales. MDX fue introducido por Microsoft en la
especificacin de OLE DB for OLAP (ODBO) en 1997 . MDX no era un
estndar sino, un lenguaje propio de Microsoft; sin embargo ha sido
adoptado por la mayor parte de las empresas y productos
relacionados con base de datos multidimensionales. Con la creacin
de XML para Anlisis (XML for analysis-XML/A) MDX fue
estandarizado como un lenguaje de consultas y se creo mdXML, el
cual es esencialmente MDX envuelto en un tag <statement>.
XMLA
XMLA es un estndar que permite a aplicaciones clientes conectarse
con fuentes de datos OLAP o multidimensionales. XMLA a su vez usa
protocolos estndares de Internet (SOAP, HTTP y XML) para
transmitir sus mensajes.
XMLA consiste en dos mtodos SOAP:
execute: ejecutar una sentencia MDX, DMX o SQL en una
fuente de datos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
234
discover: explorar y descubrir fuentes de datos, esquemas,
propiedades, etc.
Mondrian como Servidor XMLA
Mondrian, puede ser desplegado en un contenedor servlet como un
servidor XMLA. Para el caso prctico desarrollado en est seccin,
ser utilizado Apache Tomcat.
1. es necesario copiar el archivo Mondrian.war al directorio
TOMCAT_HOME/webapps e iniciar tomcat para que la aplicacin
Mondrian sea desplegada. Alternativamente puede
descomprimirse Mondrian.war con unzip Mondrian.war.
2. copiar el archivo del esquema configurado a
TOMCAT_HOME/webapps /WEB-INF/queries/orders.xml
3. Editar el archivo TOMCAT_HOME/webapps/mondrian/WEB-
INF/datasources.xml de forma que quede configurado de la
siguiente manera:
Cdigo: datasource.xml
<?xml version="1.0"?>
<DataSources>
<DataSource>
<DataSourceName>Provider=Mondrian;DataSource=MondrianGonOrders;</DataSo
urceName>
<DataSourceDescription>Mondrian Gon Orders Data
Warehouse</DataSourceDescription>
<URL>http://localhost:8080/mondrian/xmla</URL>
<DataSourceInfo>Provider=mondrian;Locale=es_AR;DynamicSchemaProcessor=m
ondrian.i18n.LocalizingDynamicSchemaProcessor;
Jdbc=jdbc:postgresql://localhost/gonmart;
JdbcUser=gon;JdbcPassword=gon;JdbcDrivers=org.postgresql.Driver;Catalog=/WE
B-INF/queries/orders.xml</DataSourceInfo>
<ProviderName>Mondrian</ProviderName>
<ProviderType>MDP</ProviderType>
<AuthenticationMode>Unauthenticated</AuthenticationMode>
<Catalogs>
<Catalog name="OrdersSchema">
<Definition>/WEB-INF/queries/orders.xml</Definition>
</Catalog>
</Catalogs>
</DataSource>
</DataSources>
1. copiar el driver JDBC correspondiente a la base de datos a
TOMCAT_HOME/webapps/mondrian/WEB-INF/lib
2. reiniciar tomcat
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
235
3. ingresar en la url http://localhost:8080/mondrian
Se quedar en presencia de la siguiente pgina:
Ejecucin Mondrian App
Para observar como Mondrian responde a peticiones XML/A, dentro
de Mondrian Examples se accede a XML for Analysis Tester:
XMLA Tester
En la imagen anterior, se observa una peticin XMLA en la cual se
incluye el mtodo SOAP discover del tipo DISCOVER_DATASOURCES.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
236
Cdigo: Discover DataSource
<Discover xmlns="urn:schemas-microsoft-com:xml-analysis">
<RequestType>DISCOVER_DATASOURCES</RequestType>
<Restrictions>
<RestrictionList/>
</Restrictions>
<Properties>
<PropertyList>
<Format>Tabular</Format>
</PropertyList>
</Properties>
</Discover>
Luego de ejecutar la peticin, se observa la siguiente respuesta:
XMLA Tester respuesta
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
237
Ejecucin de consultas MDX
Una vez que ya se tiene un esquema configurado, puede probarse la
ejecucin de una sentencia MDX. Se procede de la siguiente manera:
Nueva MDX
El evaluador de sentencias MDX presenta el siguiente aspecto:
Editor MDX
Se ejecutar una sentencia para obtener el monto total de pedidos
por sucursales y el monto promedio de pedidos correspondientes a
todas las sucursales.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
238
Cdigo: Sentencia MDX
SELECT {[Measures].[Branch Sales], [Measures].[Average Branch Sales]} ON
COLUMNS, {[Branches.BranchesZone].[ALL Branches.BranchesZones]} ON
rows FROM [Orders]
A continuacin, se observa la imagen de cmo se edita y ejecuta la
sentencia anterior en el Mondrian Workbench:
Edicin y ejecucin MDX
Referencias y recursos
1. Sitio oficial de Mondrian http://mondrian.pentaho.org/]
2. Artculo de OLAP en Wikipedia:
http://en.wikipedia.org/wiki/Olap
3.
3,0
3,1
3,2
Artculo de MDX en Wikipedia:
http://en.wikipedia.org/wiki/MDX
4. Relational Data Base Management System en Wikipedia
http://en.wikipedia.org/wiki/RDBMS
5. Artculo OLTP en Wikipedia: http://en.wikipedia.org/wiki/OLTP
6. A Mutli-Dimensional Modelling Manifesto
http://www.dbmsmag.com/9708d15.html
7. Ver Anexo I Licencias de Software
8. olap4j sitio oficial: http://www.olap4j.org/
9.
9,0
9,1
Documentacin oficial de Mondrian Workbench
10.
10,0
10,1
10,2
10,3
10,4
10,5
I18N y L10N en Wikipedia:
http://en.wikipedia.org/wiki/I18n#Alternative_names
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Mondrian
239
11.
11,0
11,1
11,2
11,3
11,4
11,5
I18N en Mondrian Technical
Guide
12. Mondrian XML Schema:
http://mondrian.pentaho.org/documentation/xml_schema.php
Conclusin OLAP
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin OLAP
243
Ambos proyectos (JasperSoft y Pentaho) se apoyan en el servidor
OLAP Mondrian, el cual en la actualidad forma parte del proyecto
Pentaho
[1]
. En este trabajo se cre de forma efectiva la descripcin
del cubo multidimensional definido en la seccin Modelo
Multidimensional, junto a sus dimensiones, jerarquas, niveles,
propiedades y medidas. Los cubos definidos pueden consultarse a
travs de sentencias MDX, mediante una conexin particular
Mondrian o, de manera ms genricas mediante una conexin XMLA.
En captulos posteriores se efectuarn reportes y anlisis OLAP
basados en la configuracin subyacente obtenida con Mondrian.
A continuacin se ofrece la tabla calificativa de Mondrian, de acuerdo
a la impresin obtenida luego del su utilizacin:
Mondrian OLAP Server
Funcionalidad 4
[2]
Usabilidad 4
[3]
Flexibilidad 5
[4]
Interoperabilidad 5
[5]
Fiabilidad 5
Eficiencia 4
[6][3]
Documentacin 4
[7]
Calificacin promedio 4.4
1. Sitio Web de Pentaho Mondrian http://mondrian.pentaho.org
2. La versin utilizada brinda una API propietaria, esto puede
ser una desventaja a la hora de desarrollar aplicaciones, pues el
cambio del Servidor OLAP supondr la reescritura de la
aplicacin. Se anuncia la inclusin de olap4j en versiones
futuras, con lo cual cualquier aplicacin que utilice olap4j
podr basarse en Mondrian como servidor OLAP.
3.
3,0
3,1
Se basa en la edicin de un esquema simple en lenguaje
XML, adems ofrece herramientas como Mondrian Workbench,
Cube Designer y CommandRunner que simplifican esta tarea. A
pesar de esto, las tareas de tunning para mejorar la
performance se hacen difcil debido a la carencia de
herramientas de anlisis que guen al administrador para
efectuar ajustes en la Base de Datos y en la creacin de tablas
de agregacin de Mondrian. En prximas versiones de Mondrian
se incluirn algunas de estas herramientas:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin OLAP
244
o http://mondrian.pentaho.org/documentation/roadmap.ph
p#Aggregation_designer.
4. Su diseo en capas, soporte a conexiones XMLA, y su alto
grado de extensibilidad hacen de Mondrian un software
altamente flexible.
5. Aquellos sistemas que no soportan una conexin Mondrian
para llevar a cabo el dialecto multidimensional, pueden
continuar apoyndose en Mondrian a travs de una conexin
genrica XMLA.
6. La ganancia en la simplicidad arquitectnica de Mondrian
como servidor ROLAP, trae como consecuencia una perdida en
la eficiencia de ejecucin de consultas multidimensionales.
Mondrian, y cualquier servidor Rolap necesitan efectuar una
conversin entre el dominio relacional y el multidimensional, es
decir para realizar operaciones tales como drill-down, slice,
drill-across, es necesario traducir la sentencia a una serie de
sentencias SQL. En un servidor MOLAP, la escritura de la base
de datos multidimensional es ms lenta, pero las consultas MDX
son obtenidas rpidamente ya que la representacin fsica es
multdimiensional y no relacional. Un conocido servidor Open
Source MOLAP, desarrollado en C/C++, es PALO. Para ms
informacin, puede consultarse el Sitio Oficial del servidor palo
http://www.jedox.com/en/enterprise-spreadsheet-server/excel-
olap-server/palo-server.html y tambin puede accederse a
http://www.jpalo.com/en/ el cual ofrece entre otras cosas una
API Java para Palo.
7. Si bien Mondrian ofrece soporte para I18N y L10N de
aplicaciones, la documentacin existente es incompleta. Existen
en los foros una serie de entradas de referencia, con
explicaciones de como llevar a cabo esta tarea; otras entradas
sealan que I18N no funciona cuando se utiliza Mondrian como
Servidor XMLA.
Captulo V: Reportes y Consultas
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Reportes y Consultas
247
En el diagrama general del desarrollo de BI-FLOSS se puede apreciar
los temas a tratar en este captulo:
BigPicture - Temas a Tratar
Trabajando con Pentaho Reporting
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
251
A continuacin se realiza una explicacin de las diferentes tecnologas
y herramientas de reporting que brinda Pentaho.
Introduccin Pentaho Reporting
Toda Organizacin necesita alguna forma de presentar la informacin
que se obtiene a partir de los datos generados de sus operaciones
diarias (estos datos pueden provenir de un OLTP, un DW, archivos
XML, etc). Pentaho, as como otras herramientas de reportes, permite
consultar los datos de distintas fuentes y ponerlos a disposicin de los
usuarios en diferentes formatos (HTML, PDF, Microsoft Excel, Rich
Text format y texto plano). Adems de generar reportes, las
herramientas de Pentaho permiten distribuir los reportes a los
usuarios interesados, como as tambin publicarlos en un portal
donde cada usuario puede observar la informacin que necesita.
Para poder realizar estas tareas Pentaho utiliza una serie de
herramientas, estas son:
JFreeReport: Es el motor encargado de generar los reportes a
partir de la definicin del mismo (archivo XML).
Report Designer: Es una herramienta que permite generar
definiciones de reportes a travs de una interfaz grfica, en la
cual se disea de manera visual el reporte. La definicin
generada luego es interpretada por JFreeReport.
Report Design Wizard: Permite generar en pocos pasos una
definicin de reportes. A diferencia de la anterior, solo permite
definir algunos parmetros que generan rpidamente un
reporte, pero limita ciertas acciones. Muy til para generar
reportes rpidamente. Al igual que la anterior, la definicin
generada luego es interpretada por JFreeReport.
Adhoc Reporting: Es otra herramienta que permite generar
reportes en base a una serie de parmetros, pero a diferencia
de la anterior se ejecuta va WEB en el portal de Pentaho.
Pentaho Design Studio: Es una herramienta basada en
eclipse que permite hacer, principalmente, debugging de los
reportes y Action Sequence.
BI Platform: Es el servidor de aplicaciones (JBoss por defecto)
ms el portal de Pentaho (aplicacin WEB), el cual permite
acceder a los reportes va WEB, administrar los usuarios
adems de otras tareas (este ser explicado en la seccin que
trata la plataforma BI de Pentaho).
A continuacin se realiza una descripcin ms detallada de las
herramientas antes mencionadas.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
253
JFreeReport
JFreeReport es un motor de reportes escrito en Java que puede ser
integrado con poco esfuerzo en casi cualquier programa. Fue
diseado originalmente para permitir imprimir modelos de tablas
(TableModels) de la tecnologa Swing de Java. A travs del tiempo, el
motor, fue evolucionando hasta convertirse en lo que es hoy, un
generador de reportes.
Actualmente JFreeReport se encuentra en su versin 0.8, la cual tiene
ciertas caractersticas heredadas del diseo original del motor, lo que
trae como consecuencia problemas en la arquitectura del proyecto.
Debido a ello el desarrollo actual se encuentra enfocado en eliminar
todos estos problemas de arquitectura, con lo que se espera que en
la versin 0.9.1 sean eliminados. Adems la nueva versin utilizara
un enfoque completamente nuevo (Layout oriented) para la
generacin de reportes.
JFreeReport es el motor utilizado por Pentaho para generar reportes.
Mediante herramientas grficas (explicadas ms adelante) o
manualmente se pueden generar definiciones (archivos XML), las
cuales son procesadas por el procesador de reportes. Como resultado
se obtiene un documento que puede presentarse en varios formatos
diferentes (Adobe PDF, HTML, Microsoft Excel, Rich Text Format y
texto plano).
Proceso clsico de generacin de reportes
La versin 0.8 de JFreeReport utiliza un proceso de generacin de
reportes simple, el cual genera los reportes mediante una fuente
central de datos. En este enfoque, el procesador de reportes itera
sobre una tabla de datos, en la cual cada fila de datos es utilizada
como elemento de entrada y el procesador genera el contenido para
cada cambio de estado que es encontrado durante la iteracin.
Este es un modelo antiguo que es utilizado hace tiempo en lenguajes
como COBOL, pero trae la ventaja de ser veloz y utilizar pocos
recursos.
Proceso de reporte orientado al Layout
La nueva versin de JFreeReport (0.9) utilizar un enfoque
totalmente distinto al anterior para la generacin de reportes. A
diferencia del anterior, el cual utiliza los datos como el factor de
control, el nuevo enfoque se concentra en el layout que debe ser
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
254
generado. En este enfoque el procesador itera sobre el layout
(definicin del reporte).
Generacin de reportes
Para generar un reporte en JFreeReport, se deben realizar 3 tareas:
Primero se debe definir una fuente de datos. Por lo general esto
se realiza en un archivo XML, pero tambin puede definirse en
el cdigo de la aplicacin que utilice el reporte. Una fuente de
datos contiene la informacin necesaria para acceder a los
datos con los cuales generar el reporte. Adems, puede recibir
parmetros, los cuales condicionarn la salida.
A continuacin observamos un ejemplo de una definicin:
Cdigo: Ejemplo de fuente de datos en formato XML (obtenido de
documentacin de pentaho - JFR9DataProcessing
[1]
)
<?xml version="1.0"?>
<!--
~ Copyright (c) 2006, Pentaho Corporation. All Rights Reserved.
-->
<sql-datasource
xmlns="http://jfreereport.sourceforge.net/namespaces/datasources/sql"
xmlns:html="http://www.w3.org/1999/xhtml">
<connection>
<driver>org.hsqldb.jdbcDriver</driver>
<url>jdbc:hsqldb:./sql/sampledata</url>
<properties>
<property name="user">sa</property>
<property name="pass"></property>
</properties>
</connection>
<!-- First query: get all regions .. -->
<query name="default">
SELECT DISTINCT
QUADRANT_ACTUALS.REGION
FROM
QUADRANT_ACTUALS
ORDER BY
REGION
</query>
<query name="actuals-by-region">
SELECT
QUADRANT_ACTUALS.REGION,
QUADRANT_ACTUALS.DEPARTMENT,
QUADRANT_ACTUALS.POSITIONTITLE,
QUADRANT_ACTUALS.ACTUAL,
QUADRANT_ACTUALS.BUDGET,
QUADRANT_ACTUALS.VARIANCE
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
255
FROM
QUADRANT_ACTUALS
WHERE
REGION = ${REGION}
ORDER BY
REGION, DEPARTMENT, POSITIONTITLE
</query>
</sql-datasource>
Una vez que se define la fuente, se debe especificar en el
cdigo cual es la que se utilizar. Para ello se deben utilizar las
libreras provistas por JFreeReport. A continuacin se observa
como realizar esto en un fragmento de cdigo Java.
Cdigo: Utilizacin de fuente de datos (obtenido de documentacin de pentaho
- JFR9DataProcessing
[1]
)
JFreeReport report; // created elsewhere
Object sourceObject; // either a valid URL, File or String object
ResourceManager manager = new ResourceManager();
Resource resource = manager.createDirectly (sourceObject,
ReportDataFactory.class);
ReportDataFactory dataFactory = (ReportDataFactory) resource.getResource();
report.setDataFactory(dataFactory);
Finalmente se debe especificar cual es la definicin del reporte
a utilizar (archivo XML). Esta definicin contiene toda la
informacin de cmo se desea que se genere el reporte. A
continuacin se observa como asignar esta definicin:
Cdigo: Carga de la definicin del reporte (obtenido de documentacin de
pentaho - JFR9HowToMain
[2]
)
ResourceManager manager = new ResourceManager();
manager.registerDefaults();
Resource res = manager.createDirectly(source, JFreeReport.class);
final JFreeReport report = (JFreeReport) res.getResource();
No debe confundirse la definicin de un reporte generada por una
herramienta grfica (ejemplo Report Designer) que la definicin
utilizada por JFreeReport. La versin que utiliza JFreeReport es la
versin compilada de la definicin del reporte generada por las
herramientas grficas. La versin compilada sigue siendo un archivo
XML, pero posee una estructura acorde para ser ejecutada por
JFreeReport.
Por ltimo, se puede realizar una vista previa del reporte que se esta
generando. A continuacin se observa el cdigo que realiza esta
accin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
256
Cdigo: Previsualizacin de un reporte (obtenido de documentacin de pentaho
- JFR9HowToMain
[2]
)
JFreeReport report; // from the parser ..
// create a report-job
ReportJob job = new DefaultReportJob (report);
final PreviewDialog frame = new PreviewDialog();
frame.setReportJob(reportJob);
frame.pack();
RefineryUtilities.positionFrameRandomly(frame);
frame.setVisible(true);
Nota: Por cuestiones de alcance del trabajo no se entra en
mayor detalle sobre JFreeReport. Para obtener ms
informacin leer la documentacin
[3]
correspondiente provista
por Pentaho. Los ejemplos antes mostrados corresponden a la
versin 0.9 de JFreeReport
Referencias y recursos
1.
1,0
1,1
JFR9DataProcessing:
http://wiki.pentaho.org/display/Reporting/JFR9DataProcessing
2.
2,0
2,1
JFR9HowToMain:
http://wiki.pentaho.org/display/Reporting/JFR9HowToMain
3. Documentacin del motor de Reportes de Pentaho:
http://wiki.pentaho.org/display/Reporting/Pentaho+Reporting+
Latest
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
257
Report Design Wizard
Introduccin
Report Design Wizard, es una asistente que permite al usuario crear
reportes en una serie de pasos predefinidos. Cada uno de los pasos
permite al usuario definir ciertos parmetros que van perfilando la
especificacin del reporte, que luego ser ejecutada por JFreeReport.
Esta herramienta fue creada con el propsito de facilitar la creacin
de reportes, ya que en pocos pasos el usuario puede generar un
reporte completo que cumpla sus necesidades. La mayor desventaja
que posee esta herramienta es que ciertos requerimientos no podrn
ser alcanzados, pero luego pueden lograrse editando el reporte
manualmente. Una vez que el usuario obtiene un reporte puede optar
por publicarlo en la BI Platform provista por Pentaho o utilizarlo en su
propia aplicacin.
Esta herramienta se puede utilizar de distintas maneras. Una de las
formas es independientemente, en la cual el usuario instala Report
Design Wizard individualmente para generar reportes. La otra es
utilizar la versin que viene integrada en otra herramienta, estas
pueden ser Report Designer, Pentaho Design Studio (explicados ms
adelante).
Licencia
Report Design Wizard se licencia bajo la Mozilla Public License,
Version 1.1
[1]
.
Versin utilizada
Pentaho Report Design Wizard 1.6 GA
Estructura de un reporte
Una definicin de reporte consiste en un conjunto de secciones que
definen la disposicin y contenido. Estas secciones son:
Cabecera y pie del reporte: Es impreso al comienzo y fin del
reporte respectivamente.
Cabecera y pie de pgina: Son impresos al comienzo y fin de
cada pgina respectivamente. Report Design Wizard no crea o
manipula estas secciones.
Cabecera y pie de grupo: Son impresos al comienzo y fin de
cada grupo respectivamente. Un grupo, generalmente, contiene
el nombre de una columna y su valor.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
258
tems o detalles: Contienen los datos obtenidos de la
consulta. Estos valores se repiten tantas veces como filas
devueltas en la consulta.
Seccin de funciones y expresiones: Permiten realizar
clculos de valores. Por ejemplo se podra calcular el total de un
valor que pertenece a un grupo.
Esta estructura se repite para los reportes generados con esta
herramienta, Report Designer y Adhoc Reporting.
Creando un reporte con Pentaho Report Design
Wizard
Generacin de Reportes
Pentaho provee distintas herramientas grficas para trabajar con
reportes (Report Design Wizard, adhoc reporting, report designer y
Pentaho design studio). Cada una de estas herramientas genera un
archivo XML (especificacin del reporte) que contiene la informacin
recolectada durante la creacin del reporte, el cual no puede ser
utilizado por JFreeReport. Para que JFreeReport pueda generar el
reporte, Report Design Wizard o las otras herramientas, utilizan el
archivo XML en conjunto con la plantilla utilizada en el reporte y los
combinan. Como resultado se obtiene otro archivo XML el cual puede
ser procesado por JFreeReport para generar un reporte. Esta tarea
debe ser realizada por estas herramientas cada vez que se desea
previsualizar un reporte o utilizarlo en alguna aplicacin.
Una vez que se obtiene este archivo puede optarse por utilizarlo en
alguna aplicacin propia o publicarlo en un servidor de soluciones
Pentaho (mas adelante se explica como utilizar este servidor).
Consideraciones previas
La versin utilizada para generar este reporte es la 1.6 GA que viene
integrada con Report Designer 1.6 GA. Se han encontrado problemas
al utilizar esta herramienta, algunos fueron resueltos y otros son
identificados pero no resueltos, ya que la herramienta no funciona
100% correctamente. Esto se debe a que son tecnologas open
source que tienen poco tiempo en el mercado y que an no han
alcanzado un alto grado de estabilidad. A pesar de estos problemas
tienen un futuro prometedor, por lo que se decide utilizarlas y tratar
de mitigar estos problemas de la mejor manera posible.
A continuacin se describe como crear un reporte que permita
visualizar las ventas y unidades vendidas de las distintas categoras,
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
259
rubros, negocios, sucursales del ao 2007. Se divide el proceso en los
distintos pasos involucrados para generar el reporte.
Pasos involucrados
Paso 1: Nombre y descripcin del reporte
En este paso se deben definir el nombre y descripcin del reporte,
que sern utilizados de manera informativa, ya que no impactaran el
contenido generado. Lo que s impacta en el contenido, es la plantilla
utilizada, ya que esta define la disposicin de los distintos elementos
en el reporte. El wizard permite utilizar plantillas predefinidas o que el
usuario especifique que plantilla utilizar, para ello debe indicar el
archivo donde se encuentra la especificacin.
En este caso, se utiliza una plantilla predefinida por Pentaho como se
aprecia en la siguiente imagen.
Paso 1
Paso 2: Fuente de datos
Para que el reporte pueda generarse y mostrar datos, debe
configurarse una fuente de datos y una sentencia que los extraiga.
Los tipos de fuentes de datos disponibles son:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
260
JNDI: Generalmente conexiones JDBC, para ello debe
configurarse la fuente de datos (explicado ms adelante).
o Pueden utilizarse sentencias SQL. La herramienta permite
utilizar el query designer para generar la sentencia.
o Pueden utilizarse sentencias MDX, para lo cual debe
especificarse cual es el archivo en el que se encuentra la
definicin del cubo mondrian. Este es el tipo usado en el
caso de estudio.
XQuery: Permite especificar un archivo XML del cual extraer los
datos, luego debe utilizarse una sentencia de este tipo para
extraer la informacin que se utilizar en el reporte.
Metadata Query (MQL): Permite utilizar sentencia MQL para
extraer la informacin utilizada en el reporte.
En la siguiente imagen se aprecia como se realiz esta configuracin
en la herramienta.
Paso 2
Cdigo: Sentencia rdenes 2007
SELECT NON EMPTY {[Measures].[Unit Sales], [Measures].[Branch Sales]} ON
COLUMNS,
NON EMPTY {[Branches.Category].members} ON rows
FROM [Orders]
WHERE ([OrderStatus].[ALL OrderStatuss].[Finalizada], [Time.Time].[ALL
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
261
Time.Times].[2007])
Esta consulta desagrega la jerarqua Categora de Sucursales hasta
su menor nivel (Sucursal), mostrando totales de rdenes (en
unidades y monto de venta) en cada uno de sus niveles. Todo esto
para rdenes realizadas en el ao 2007 y que han sido finalizadas. Se
puede apreciar un resultado ms grfico de la sentencia con JPivot:
Report Query
Nota: Es necesario aclarar que debido a uno de los problemas
encontrados en la herramienta no puede obtenerse un
resultado como el que se muestra en la imagen anterior. Esto
se debe a que Pentaho Design Wizard, por algn motivo
desconocido, no reconoce los distintos niveles de la jerarqua
impidiendo la agrupacin de los campos en base a los niveles.
Mas adelante se explica en que paso debera realizar esta
agrupacin.
Configuracin de la fuente de datos
Para configurar una fuente de datos debe elegirse la opcin para
agregar una nueva fuente. Una vez hecho esto, se debe especificar:
Nombre de la fuente de datos.
Driver JDBC a utilizar.
Cadena de conexin.
Nombre de usuario y contrasea del repositorio.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
262
Configuracin de la fuente de datos
Nota: Report Design wizard no posee por defecto el driver
para conectarse con Postgres. Para ello si se desea agregar
este driver o el de alguna otra base de datos, deben incluirse
los archivos .jar en el directorio
HOME_REPORTDESIGN_WIZARD/lib/jdbc. Esto permite, a la
hora de configurar la fuente de datos, seleccionar el driver
desde las opciones.
Paso 3: Mapeo con la plantilla
Este paso es vlido para reportes que utilicen plantillas. Cuando se
utilizan plantillas se deben especificar valores para ciertas etiquetas
que pueden aparecer en el reporte. En este caso se dejan los valores
que asigna la herramienta por defecto.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
263
Paso 3
Paso 4: Disposicin de elementos
En este paso se especifica que campos deben ser incluidos para ser
mostrados por el reporte. Adems pueden seleccionarse campos por
los cuales agrupar el contenido mostrado. En este caso particular se
selecciona que el reporte muestre la cantidad de unidades vendidas,
ventas de las sucursales y sucursales. Como se menciona en el paso
dos, por problemas con la herramienta, no pueden seleccionarse los
distintos elementos de la jerarqua, por lo que solo puede
seleccionarse el elemento sucursales (Branches). Este elemento
mostrara cada campo devuelto por la consulta sin diferenciar el nivel
de la jerarqua. En caso que la herramienta reconociera los distintos
niveles, debera agrupar por cada uno de ellos para generar un
resultado mas apropiado.
La agrupacin debera ser:
Categora.
o Rubro.
Negocio.
Sucursal.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
264
Paso 4
Paso 5: Ajustes del formato
En esta seccin se definen algunos atributos de formato del reporte a
generar. Principalmente se define la alineacin, nombre de las
columnas, funciones a aplicar y mascaras. Esto se aplica tanto para
elementos individuales como para los que pertenecen a grupos.
Como se aprecia en la imagen estas opciones pueden ser aplicadas a
cada uno de los campos que contiene el reporte. En el caso de
estudio se deja el valor por defecto para las sucursales, para las
unidades vendidas y para ventas de sucursales se indica que no se
aplique funcin alguna. Por defecto la herramienta aplica la funcin
de suma a estos dos campos, pero esto no es necesario ya que la
consulta retorna el valor total de las dos columnas.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
265
Paso 5
Paso 6: Configuracin de hoja
Como su nombre lo indica, esta seccin se encarga de configurar el
formato de la hoja que contiene el reporte. Esto es de gran utilidad a
la hora de imprimir los reportes ya que no todos los reportes tienen la
misma distribucin o las impresoras pueden o no imprimir con
determinados tipos de papel.
En este caso se especifica que se utilice un papel de tamao A4 con
orientacin vertical. En la siguiente imagen se aprecia la
configuracin asignada.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
266
Paso 6
Paso 7: Opciones Avanzadas
Por ltimo, el paso de opciones avanzadas permite especificar
algunas opciones de alto nivel como bandas por filas, lneas de tablas
y fuentes. En este caso se dejaron las opciones por defecto con la
salvedad que se deshabilit la opcin de calculo de totales y se
elimin el color de fondo de la fila de totales.
En la imagen siguiente se aprecia la configuracin asignada.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
267
Paso 7 - Tab expressions
Consideraciones finales y pre-visualizacin del
reporte
Como pudo apreciarse, la generacin de reportes con Report Design
Wizard consiste de una serie de pasos de simple ejecucin. Una vez
que se han establecido las configuraciones necesarias puede optarse
por pre-visualizar el reporte con el botn preview. Esto genera una
vista previa que nos ayuda a terminar de configurar el reporte.
Cuando se decide que el reporte esta listo hay dos opciones por
seguir:
1. Si se esta usando la versin independiente del Wizard, puede
guardarse en un archivo para su posterior edicin. Si se esta
usando la versin embebida, al presionar el botn ok el reporte
pasara al modo de edicin de Report Designer. Esto permite
seguir con configuraciones y ediciones ms complejas del
reporte. Tambin puede guardarse en un archivo cuando se
pasa al modo de edicin de Report Designer.
2. Si desea, el usuario puede publicar el reporte en un servidor
Pentaho (solo disponible en la versin independiente de Report
Design wizard. Report Designer tambin brinda esta opcin,
pero la deshabilita en el wizard. Ms adelante se explica como
publicar un reporte en un servidor).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
268
En la siguiente imagen se observa el reporte generado en modo de
pre-visualizacin.
Reporte Generado
Como puede observarse el reporte contiene toda la informacin pero
resulta difcil distinguir entre los distintos niveles de la jerarqua.
Debido al problema explicado anteriormente se utilizara otro ejemplo
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
269
para la prxima seccin en la cual se explica como utilizar Report
Designer para realizar configuraciones avanzadas a los reportes.
Nota: La versin utilizada para este ejemplo (versin incorporada en Report
Designer) corriendo sobre la plataforma de Linux Kubuntu 7.04 presenta un
problema a la hora de pre-visualizar el reporte. Para poder visualizar el reporte,
una vez finalizada la configuracin del wizard, se deben aceptar los cambios
hechos y guardar la versin de Report Designer. Luego se debe editar, con algn
editor de texto, el archivo XML generado. Primero se debe asignar al tag
<property name="useMondrianCubeDefinition">false</property> el valor true y
al tag <property name="mondrianCubeDefinitionFile"></property> se debe
asignar el path del archivo con la definicin del cubo de mondrian. Una vez hecho
esto el reporte puede ser pre-visualizado.
Referencias y recursos
1. Ver anexo Licencias de Software: Anexo I
Documentacin de reportes de Pentaho:
http://wiki.pentaho.org/display/Reporting/Pentaho+Reporting+Latest
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
271
Report Designer
Introduccin
Pentaho Report Designer es un editor visual (What You See Is What
You Get) de reportes para la librera JFreeReport. El editor genera
archivos XML con la definicin del reporte, que luego son
transformados para ser ejecutados por JFreeReport en alguna
aplicacin.
A continuacin se detalla como disear un reporte con esta
herramienta partiendo de un reporte diseado en Report Design
Wizard (no es el mismo reporte de la seccin anterior).
Licencia
Pentaho Report Designer es distribuido bajo la licencia Mozilla Public
License, Version 1.1
[1]
.
Versin utilizada
Pentaho Report Designer 1.6 GA
Diseo de un Reporte
Pasos Previos
Antes de comenzar con el diseo del reporte, se destacan las
configuraciones previas realizadas en Report Design Wizard para
generar el primer contenido. Como se explico en la seccin anterior,
no se utiliza el mismo reporte por los problemas encontrados. El
reporte utilizado, lista ventas finalizadas de sucursales empresa Nunc
(empresa inexistente, solo es utilizada como ejemplo), entre el 2006
y 2007 agrupadas por cuatrimestre.
Las configuraciones utilizadas fueron:
1. Nombre y Descripcin:
o Titulo: Ventas Finalizadas 2006 - 2007.
o Descripcin: Ventas finalizadas de la empresa Nunc entre
2006 y 2007.
o Plantilla: Summer.
2. Fuente de datos y Sentencia:
o Fuente de datos: gon.
o Archivo con definicin del cubo Mondrian: orders.xml.
o Sentencia:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
272
Cdigo: Sentencia ventas Nunc 2006 - 2007
SELECT NON EMPTY CrossJoin({
[Branches.Category].[ALL Branches.Categorys].[Construccion].[Ferreteria y
buloneria].[Nunc].[tristique 6],
[Branches.Category].[ALL Branches.Categorys].[Construccion].[Ferreteria y
buloneria].[Nunc].
[vel, convallis 1634],[Branches.Category].[ALL
Branches.Categorys].[Construccion].[Ferreteria y buloneria].
[Nunc].[lorem, sit 2870]},{[Measures].[Branch Sales]}) ON COLUMNS,
NON EMPTY Hierarchize({
Descendants([Time.Time].[ALL Time.Times], 2.0)})ON ROWS
FROM [Orders]
3. Mapeo de plantilla: Todos los valores por defecto.
4. Distribucin: Se seleccionan los campos de sucursales, tiempo y
ventas para ser mostrados. Deberan ser los valores por
defecto.
5. Formateo: Se dejan los valores por defecto. Se debe confirmar
que se calculen los totales generales (total de todas las ventas
de cada sucursal).
6. Configuracin de pgina: Se asigna orientacin vertical y el
resto de los valores por defecto.
7. Opciones avanzadas: Todos los valores por defecto.
Finalmente se debera obtener un reporte similar al mostrado en la
siguiente imagen.
Pre-visualizacin del reporte generado por el wizard
Como puede apreciarse en el reporte, hay varias mejoras posibles a
realizar. En las siguientes secciones se ver como continuar con la
edicin de este reporte en Report Designer.
Creando una fuente de datos
En caso de que se quiera definir una fuente de datos adicional para el
reporte o una nueva fuente, Report Designer posee una opcin para
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
273
hacerlo. Para ello, se debe seleccionar del rbol de elementos del
reporte, el elemento Data Sets y agregarle una nueva fuente. Los
Data Sets que pueden agregarse son de tres tipos:
Definidos por el usuario (fuera del alcance de este trabajo).
Archivos de propiedades, los cuales se comportan igual que los
archivos de propiedades java.
Los propios de Pentaho. Como se explico en la seccin anterior
estos pueden ser del tipo JNDI, XQuery y MQL.
En la siguiente imagen se observa como agregar un data set de tipo
JNDI.
Definicin de una fuente de datos JNDI
Modificando el reporte generado por Report Design
Wizard
Antes de comenzar se presenta una figura que representa a grandes
rasgos las diferentes secciones del editor de reportes. Para mayor
informacin consultar la documentacin oficial de Pentaho
[2]
.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
274
Vista general de la herramienta
Se modifican los elementos de las secciones del reporte, de la
siguiente manera:
Page Header:
o Se agrega un elemento de tipo label, con el nombre de la
empresa.
Report Header:
o Se agrega un label que contiene un ttulo con el nombre
del reporte (Ventas finalizadas 2006 - 2007).
Group Header:
o Label Time: se le modifica la propiedad Text a
Cuatrimestre ao 2006/2007. Se restablecen sus
coordenadas (ver imagen).
o Label Branch Sales: se le modifica la propiedad Text a
Ventas de sucursales. Se asigna el tipo de letra negrita y
se lo alinea centrado. Se restablecen sus coordenadas
(ver imagen).
o Labels que contienen los nombres de las sucursales son
alineados al centro. Se restablecen sus coordenadas (ver
imagen).
o La figura rectangular: se le aumenta la altura.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
275
Group Footer:
o Se modifica la propiedad Text del label Grand Total a
Total Vendido
En la imagen se aprecia como queda el reporte en modo edicin
luego de las modificaciones realizadas.
Reporte modificado en modo edicin
Por ltimo resta ejecutar el reporte y verificar que los datos y los
cambios realizados se visualicen correctamente. A continuacin se
aprecia el reporte final.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
276
Previsualizacin del reporte editado
Aclaraciones finales
Al igual que Report Design Wizard, Report Designer presenta el
problema de no reconocer las jerarquas definidas en el cubo. Esto
genera complicaciones a la hora de generar reportes y no se ha
encontrado buena documentacin donde se explique como resolver el
problema. Se planeaba mostrar ejemplos de como generar grficos
con estas herramientas, pero debido a las dificultades mencionadas
no se pudieron obtener grficos correctos con los reportes generados.
En la seccin referente al Servidor Pentaho, se mostraran grficos
generados mediante la herramienta de anlisis (JPivot) que provee
Pentaho.
Publicacin de un reporte en el servidor
Antes de publicar un reporte en un servidor se debe haber
configurado la Plataforma BI de Pentaho. Si an no se ha realizado
este paso, dirigirse la seccin Trabajando con Pentaho BI-Server.
Cuando se posee un ambiente ya configurado, Report Designer brinda
la posibilidad de publicar el reporte con el que se esta trabajando en
el servidor. Para esto se debe decidir dentro de que solucin y
directorio del repositorio se desea publicar el reporte. En la siguiente
imagen, se visualiza como utilizar el asistente de publicacin (para
acceder se debe ir a la barra de herramientas File-->Publish to
Server...).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
277
Publicacin de un reporte en la Solucin gon
Name: Texto que se quiere aparezca en el servidor para
acceder al reporte.
Publish Location: Directorio dentro del repositorio donde se
quiere se publique el reporte (se debe utilizar el nombre del
directorio, no el nombre como se visualiza en la aplicacin
Pentaho).
Default Report Type: Formato por defecto del documento que
se obtiene al generar el reporte.
Web Publish URL: URL del servidor (RepositoryFilePublisher
es el nombre del servlet que publica los reportes).
Publish Password: Password de publicacin del servidor.
Debe estar asignado, de lo contrario no se podr publicar el
reporte (este paso se explica en la seccin Trabajando con
Pentaho BI-Server - Configuraciones opcionales).
Server User ID: Nombre del usuario registrado en el servidor.
Debe ser un usuario con privilegios suficientes para publicar en
el directorio seleccionado.
Server Password: Password del usuario que publica el
reporte.
Es importante seleccionar la opcin Publish XAction File ya que esta
publica el Action Sequence correspondiente a la ejecucin del reporte.
En la seccin Trabajando con Pentaho BI-Server - Que es una
solucin Pentaho? se realiza una breve descripcin de Action
Sequence.
Por ltimo se debe seleccionar la opcin Use JNDI ya que publica la
informacin de la fuente de datos del reporte (en caso de un reporte
con una consulta MDX, tambin publica el esquema mondrian). Hay
que tener en cuenta que el nombre utilizado para la fuente de datos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
278
es el mismo que el que se asign al crear la fuente de datos en
Report Designer. En la seccin Trabajando con Pentaho BI-Server se
explica como modificar este valor en caso de que no coincida el
nombre de la fuente de datos definida en Report Designer y Tomcat.
Una vez que se termina de ejecutar el asistente, se obtiene un
reporte publicado en el servidor en la solucin correspondiente. En la
seccin Trabajando con Pentaho BI-Server se explica como navegar
para poder visualizar el reporte publicado.
Referencias y Recursos
1. Ver anexo Licencias de Software: Anexo I
2. Documentacin de reportes de Pentaho:
http://wiki.pentaho.org/display/Reporting/Pentaho+Reporting+
Latest
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
279
Adhoc Reporting
Adhoc Reporting es una herramienta de generacin de reportes
basada tecnologas Web 2.0 (AJAX, DHTML) diseada para ayudar a
usuarios a generar reportes usando la plataforma Pentaho. Provee al
usuario una interfaz que lo ayuda a:
Identificar y agrupar rpidamente datos de inters.
Aplicar restricciones a los datos.
Generar reportes.
Los reportes creados como resultado de este proceso, quedan a
disposicin del usuario a travs de la aplicacin Web de Pentaho.
Muchas herramientas de reportes interactan directamente con bases
de datos relacionales para obtener los datos del reporte. A diferencia
de las herramientas clsicas, los reportes Adhoc, interactan con un
modelo de metadatos. Una de las principales ventajas de un modelo
de metadatos, es que las relaciones entre tablas en el modelo de
negocios puede ser definido en los metadatos. Esto libera a los
usuarios de tener que comprender como se relacionan las tablas en
una base de datos relacional.
Antes de utilizar reportes Adhoc en Pentaho, debe existir un modelo
de metadatos configurado. Para realizar esta configuracin se utiliza
una herramienta provista por Pentaho llamada Pentaho Metadata
Editor. Quedan fuera del alcance de esta gua los pasos necesarios
para realizar las configuraciones y definiciones de un modelo de
metadatos. Para mayor informacin consultar la documentacin
ofrecida
[1][2]
por Pentaho.
Recursos y referencias
1. Documentacin sobre creacin de reportes Adhoc:
http://wiki.pentaho.org/display/PentahoDoc/Creating+Reports+
using+Adhoc+Reporting
2. Documentacin de Pentaho Metadata Editor:
http://wiki.pentaho.org/display/studio/Pentaho+Metadata+Edit
or
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
281
Pentaho Design Studio
Introduccin
Pentaho Design Studio es una aplicacin que provee un entorno
grfico para la edicin y testeo de Action Sequence y JFreeReports
basada en el framework de Eclipse
[1]
.
Debido a como funciona la plataforma Eclipse, Pentaho Design Studio
puede ser utilizada de dos maneras.
1. Utilizando una versin ya instalada de Eclipse. En este caso se
debe descargar nicamente el plug-in de Pentaho Design Studio
e integrarlo a la configuracin existente de Eclipse.
2. Descargar e instalar la plataforma que brinda Pentaho, la cual
consiste en la versin base de Eclipse con el plug-in de Pentaho
ya instalado y configurado.
En el caso de esta gua se utiliza la versin que brinda Pentaho ya
configurada. A continuacin se da una explicacin de como se utiliza
la herramienta para crear y probar un action sequence necesario para
generar un anlisis que brinde la misma informacin generada en el
reporte de la seccin anterior.
Nota: Consultar la documentacin oficial para mayor
informacin sobre Pentaho Design Studio
[2]
y Action
Sequence
[3]
. Se aconseja antes de leer la siguiente gua
completar los pasos descriptos en la seccin
Trabajando_con_Pentaho_BI-Server
Licencia
Pentaho Public Licence
[4]
Versin Utilizada
Pentaho Design Studio 1.6.0 GA
Creando un anlisis con Pentaho Design Studio
Creando un proyecto
El primer paso para crear un action sequence en la herramienta es
crear un nuevo proyecto en eclipse del tipo Project. En la imagen se
observa los datos asignados al nuevo proyecto.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
282
Creacin del proyecto
Cabe destacar que no se utiliza la carpeta de trabajo por defecto, ya
que se indica que se utilice como capeta de inicio la solucin gon
creada dentro del repositorio. El repositorio es creado y configurado
en la seccin Trabajando con Pentaho BI-Server - Configurando la
solucin de Pentaho. A continuacin se observa como queda la
estructura del proyecto una vez que es creado.
Estructura del proyecto
Puede observarse que dentro del directorio reporting se encuentra
creado el action sequence Ventas Nunc que fue creado al publicar el
reporte en la seccin anterior.
Creando el action sequence que genera el anlisis
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
283
Una vez creado el proyecto se debe crear el action sequence que
genera el anlisis. Para ello, se crea dentro del directorio analisis,
mediante el asistente, un nuevo action sequence haciendo click
derecho sobre el directorio y seleccionando: New->Other->Pentaho-
>New Action Sequence Wizard. A continuacin se observa la imagen
donde se selecciona el wizard.
Creando un nuevo action sequence
Una vez que se selecciona, se le asigna la informacin que se observa
en la siguiente imagen.
Creando un nuevo action sequence
Cabe aclarar que debe seleccionarse el Template: Create an Analisis
View ya que se esta creando una nuevo anlisis.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
284
Una vez creado el action sequence, se accede al mismo y se
selecciona la vista General. Dentro de esta vista se debe ingresar
informacin general del action sequence que se esta editando, sin
importar que tipo accin ejecute. A continuacin se observa la
informacin ingresada.
Ingresando informacin general
Lo que falta para que el action sequence se ejecute, es la informacin
del proceso que debe ejecutar. Para ello se ingresa a la vista Define
Process y se selecciona el elemento Ventas Nunc de la lista. A este
elemento se le debe definir:
El esquema mondrian a utilizar (el mismo que se utiliza en
secciones anteriores).
La fuente de datos definida en Tomcat (explicado en la seccin
Trabajando con Pentaho BI-Server - Creando las fuentes de
datos).
Sentencia MDX que obtiene la informacin.
Cdigo: Sentencia ventas Nunc 2006 - 2007
SELECT NON EMPTY CrossJoin({
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
285
[Branches.Category].[ALL Branches.Categorys].[Construccion].[Ferreteria y
buloneria].[Nunc].[tristique 6],
[Branches.Category].[ALL Branches.Categorys].[Construccion].[Ferreteria y
buloneria].[Nunc].
[vel, convallis 1634],[Branches.Category].[ALL
Branches.Categorys].[Construccion].[Ferreteria y buloneria].
[Nunc].[lorem, sit 2870]},{[Measures].[Branch Sales]}) ON COLUMNS,
NON EMPTY Hierarchize({
Descendants([Time.Time].[ALL Time.Times], 2.0)})ON ROWS
FROM [Orders]
A continuacin se observa la informacin ingresada en este paso.
Ingresando informacin del proceso
Probando el action sequence desde la herramienta
Finalmente resta probar el action sequence que se esta editando.
Para ello primero se debe guardar el action sequence y seleccionar la
vista Test. Para poder probarlo, el servidor Pentaho y MySQL deben
estar corriendo (ver seccin Trabajando con Pentaho BI-Server -
Iniciando Tomcat y MySQL). Adems, si se opto en la configuracin
del servidor por manejar el repositorio de soluciones con MySQL, se
debe actualizar el mismo en la aplicacin, ya que sino dar error al
probarlo (ver seccin Trabajando con Pentaho BI-Server -
Actualizando el repositorio de soluciones).
A continuacin se observa como se prueba en Pentaho Design Studio
el action sequence recin creado.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho Reporting
286
Testeando el action sequence
Para generar la url de prueba presionar el botn Generate URL y
aadir al comienzo la url del servidor Pentaho (ej:
http://localhost:8080/pentaho/).
Referencias y recursos
1. Plataforma Eclipse: http://www.eclipse.org/platform
2. Documentacin de Pentaho Design Studio:
http://wiki.pentaho.org/display/studio/Getting+Started+with+
Design+Studio
3. Documentacin de Action Sequence:
http://wiki.pentaho.org/display/PentahoDoc/03.+Action+Seque
nces
4. Ver Anexo Licencias de Software
Trabajando con Jasper Reporting
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
289
A continuacin se realiza una explicacin de las diferentes tecnologas
y herramientas que brinda Jasper para trabajar con reportes.
Introduccin a Jasper Reporting
Jasper, al igual que otras organizaciones, ofrece herramientas que
permiten generar reportes que contienen informacin relevante para
distintas reas y niveles de una organizacin. Los datos pueden
obtenerse de distintas fuentes (generalmente una BD) los cuales son
procesados y luego presentados al usuario final en un formato
apropiado (PDF, XML, HTML, CSV, XLS, RTF, TXT). Adems de
generar reportes, las herramientas de Jasper permiten distribuir los
reportes a los usuarios interesados, como as tambin publicarlos en
un portal donde cada usuario puede observar la informacin que
necesita.
Jasper brinda dos opciones para utilizar sus productos, una son las
versiones pagas y la otra son las que no tienen costo. Bsicamente la
diferencia es el soporte y algunas funcionalidades (para ms
informacin consultar el sitio oficial de JasperSoft:
http://www.jaspersoft.com/).
Las herramientas ofrecidas son:
JasperReports: Librera escrita en JAVA encargada de generar
reportes.
iReport: Herramienta grfica que permite crear reportes para
que puedan ser ejecutados por JasperReports.
JasperServer: Servidor WEB que contiene un portal en el cual
se puede, entre otras cosas, publicar reportes para que sean
accedidos por los usuarios (se explica en la prxima seccin).
JasperAnalysis: Motor OLAP encargado de descender por las
jerarquas, explorar porciones de datos, examinar tendencias,
patrones, anomalas y relaciones mediante un navegador web.
En las siguientes secciones se explica como utilizar las distintas
herramientas de reporting que Jasper ofrece sin costo.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
291
JasperReports
Introduccin
JasperReport es una librera escrita en Java encargada de generar
reportes que entregan informacin en la pantalla, impresora o un
archivo de salida (PDF, HTML, RTF, XLS, ODT, CSV, XML). Al ser una
aplicacin Java puede ser incluida en otras aplicaciones escritas, o
compatibles con este lenguaje para generar contenido dinmico.
JasperReports, al igual que otras aplicaciones de reportes, usa
plantillas estructuradas en varias secciones como ser, ttulo,
encabezados, grupos, etc. A su vez cada una de estas secciones
puede contener otros elementos como imgenes, textos dinmicos y
estticos, rectngulos, etc. Una vez que el motor de reportes tiene
esta informacin, la utiliza con la plantilla para organizar los datos en
un archivo XML (JRXML). Los datos que muestra el reporte pueden
provenir de distintas fuentes como bases de datos relacionales,
colecciones, XML, Cubo OLAP, etc.
EL tiempo de creacin de un reporte puede ser muy extenso si no se
usa una herramienta grfica que nos ayude en esta tarea. Para ello
Jasper ofrece una herramienta, iReport, la cual permite, grficamente
disear el reporte evitando as editar el archivo XML manualmente.
Ms adelante se explica esta herramienta.
Licencia
JasperReport se licencia bajo LGPL
[1]
Trabajando con plantillas (templates) de reportes
Las plantillas son un elemento comn en las distintas aplicaciones
de reportes. Estas definen la distribucin del documento que luego es
cargado con datos. Las plantillas utilizadas por JasperReports, al igual
que las de otras aplicaciones de reportes (por ejemplo JFreeReport),
se encuentran estructuradas en mltiples secciones, cada una, con
sus caractersticas y comportamientos.
El proceso de crear una plantilla se divide en dos pasos:
1. Las plantillas iniciales son compiladas en una versin preparada
para ser cargada con datos.
2. Se realizan varios chequeos de consistencia y se agrega
informacin para evaluar expresiones en tiempo de ejecucin.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
292
Para manejar las plantillas, JasperReports, crea objetos del tipo
net.sf.jasperreports.engine.design.JasperDesign, los cuales
representan las plantillas fuentes a utilizar en el reporte. Estos
objetos son creados usando la API, mediante el parseo de archivos
JRXML (archivo XML que define la plantilla) editados a mano o
mediante alguna herramienta. Una vez compilados, estos objetos se
transforman en una plantilla compilada representada por otro objeto
del tipo net.sf.jasperreports.engine.JasperReport.
A continuacin se explica este proceso.
Creando una plantilla para un reporte
JasperReports brinda dos opciones para crear una plantilla. Una es
utilizar la API creando objetos del tipo
net.sf.jasperreports.engine.design.JasperDesign. La otra forma,
la ms comn, es editar manualmente o con alguna herramienta los
archivos JRXML.
La primera opcin es recomendable en los casos en que la aplicacin
que esta utilizando JasperReports, necesite crear plantillas de
reportes en tiempo de ejecucin. Estos casos se dan cuando los
diseadores del reporte no poseen toda la informacin en tiempo de
diseo y deben permitir al usuario que cree reportes dinmicos segn
algunos parmetros que el defina. Una desventaja de este tipo de
reportes, es que al tener que compilar estos reportes antes de
presentarlos se pierde rendimiento en la aplicacin.
La segunda opcin es la ms utilizada. Por lo general se utilizan
herramientas (como iReport) que permiten editar los archivos JRXML,
las cuales ahorran gran cantidad de tiempo. Una vez que se termina
de editar estos archivos, deben ser compilados para que puedan ser
cargados con datos.
En caso que se opte por editar manualmente los reportes,
JasperReports brinda una herramienta que permite previsualizarlos.
Esta aplicacin, llamada Report Design Preview, esta basada en la
tecnologa Swing de Java, la cual puede previsualizar plantillas en su
forma compilada o desde su JRXML.
Cargando y guardando los archivos de plantillas
Cuando se crean los reportes mediante la API o editando los archivos
JRXML, JasperReports brinda la posibilidad de guardar las plantillas
de reportes como objetos serializados. Esto es posible gracias a que
las clases net.sf.jasperreports.engine.design.JasperDesign y
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
293
net.sf.jasperreports.engine.JasperReport implementan la
interfaz java.io.Serializable, lo que permite guardar objetos en un
estado modificable (objeto JasperDesign) o compilada (objeto
JasperReport). Al ser objetos serializados, existe la posibilidad, por
ejemplo, de enviar estos objetos a travs de la red o almacenarlos en
disco. No siempre debe optarse por almacenar o trabajar con los
objetos serializados, ya que las plantillas pueden ser almacenadas en
archivos JRXML.
Compilando las plantillas
Antes de que una plantilla sea cargada con datos, debe ser
compilada. Esto es necesario, ya que deben realizarse varios
chequeos de consistencia e incorporar datos que sern usados para
evaluar las expresiones del reporte en tiempo de ejecucin.
El proceso de compilacin consiste en transformar objetos del tipo
net.sf.jasperreports.engine.design.JasperDesign en objetos del
tipo net.sf.jasperreports.engine.JasperReport. Una vez que la
plantilla se compila (objetos JasperReport), esta no puede ser
modificada, a diferencia de los objetos JasperDesign que si pueden
ser modificados. Esto es porque las modificaciones que se realicen en
la plantilla deberan ser validadas.
Cargando datos a las plantillas
El proceso de carga de datos al reporte, es de gran importancia, ya
que es el momento en el cual el reporte cobra sentido para el usuario
y puede ser utilizado por este. Antes de este proceso, slo se posee
un archivo con la versin compilada del reporte, la cual no brinda
ninguna informacin al usuario.
Antes de cargar datos en un reporte se debe poseer:
Una versin compilada de la plantilla.
Parmetros.
Una fuente de datos.
El resultado final de este proceso es un documento final listo para ser
revisado, impreso o exportado a otros formatos. La clase encargada
de esta tarea es net.sf.jasperreports.engine.JasperFillManager.
Datos del reporte
La librera de JasperReports, es totalmente independiente del origen
de los datos del reporte. Es responsabilidad de la aplicacin que
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
294
utiliza la librera, proveer los datos y manejar los resultados
obtenidos.
Los parmetros de un reporte, son bsicamente valores con nombres
que son enviados al procesador de reportes al momento de cargar los
datos. Estos parmetros envan informacin que posibilita modificar
los resultados obtenidos en el reporte, por ejemplo podra enviarse
una fecha a partir de la cual mostrar informacin.
En cuanto a la fuente de datos, existen dos opciones:
La primera es utilizar una instancia de la interfaz
net.sf.jasperreports.engine.JRDataSource, de la cual se extraen
los datos para cargar el reporte. Luego, la instancia de esta interfaz,
es utilizada por la clase
net.sf.jasperreports.engine.JasperFillManager (siguiendo un
patrn de fachada), la cual posee una serie de mtodos que reciben
una fuente de datos que ser utilizada para llenar el reporte.
La segunda opcin, es utilizar como parmetro un objeto del tipo
java.sql.Connection como fuente de datos para la clase
JasperFillManager. Luego para obtener los datos, los usuarios
definen una sentencia SQL en la plantilla del reporte, la cual
obtendr los datos de la conexin enviada como parmetro en tiempo
de ejecucin. Lo que ocurrir en este caso, es que se ejecutar la
sentencia y luego se crear un JRDataSource que envuelve los
resultados.
Carga de datos asncrona
JasperReports brinda una clase
(net.sf.jasperreports.engine.fill.AsynchronousFillHandle) que
permite realizar carga de datos a los reportes de manera asncrona.
El mayor beneficio es que el usuario puede cancelar la generacin del
reporte, esto suele darse en el caso en que la aplicacin demore
demasiado en entregar el reporte debido a la gran cantidad de datos
involucrados.
Cuando se utiliza este mtodo de carga, el proceso comienza en un
nuevo hilo de ejecucin. Luego el objeto que lo inici es notificado
mediante escuchadores del progreso del proceso de carga de datos.
Manejo de reportes generados
El proceso que genera un reporte, da como resultado un documento
que contiene mltiples paginas, cada una contiene una serie de
elementos visuales con sus propiedades, tales como tamao y
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
295
ubicacin. Un documento, es una instancia de la clase
net.jasperreports.engine.JasperPrint y es responsabilidad de la
aplicacin que utiliza JasperReports, hacer uso de este documento.
Los objetos de esta clase, pueden ser serializados para ser
almacenados o enviados a travs de la red, visualizados en la
herramienta provista por Jasper, impresos o exportados a uno de los
formatos soportados (PDF, HTML, RTF, XLS, ODT, CSV O XML).
Nota: Cabe aclarar que los objetos de tipo JasperPrint ya
poseen los datos del reporte, a diferencia de los objetos del
tipo JasperReport que estn preparados para se cargados con
datos. Un objeto JasperPrint mantiene sus datos en el tiempo;
los objetos JasperReport luego de ser cargados con datos
generan un objeto del tipo JasperPrint.
Cargando y guardando los reportes generados
Una vez que los objetos JasperPrint han sido generados, pueden ser
serializados y almacenados en archivos. Esto es posible gracias a las
clases net.sf.jasperreports.engine.util.JRSaver y
net.sf.jasperreports.engine.util.JRLoader, las cuales permiten
guardar los objetos en un archivo y luego recuperarlos.
Algunas veces, es conveniente almacenar estos objetos en un archivo
en formato texto, como ser un archivo XML. Esto se logra exportando
los objetos JasperPrint a XML con la implementacin de
net.sf.jasperreports.engine.export.JRXmlExporter. Luego, estos
archivos XML pueden ser parseados y cargados en memoria
nuevamente en un objeto del tipo JasperPrint.
Visualizando e imprimiendo los reportes
JasperReports provee una herramienta grfica basada en la
tecnologa Swing de JAVA que permite visualizar los reportes sin
tener que exportarlos a otro formato. Esto permite utilizar los objetos
JasperPrint que estn en memoria, y presentrselos al usuario en un
formato listo para leer o imprimir sin tener que recurrir a una
aplicacin de terceros. Esta herramienta puede integrarse fcilmente
a cualquier aplicacin JAVA brindado las caractersticas antes
mencionadas.
Para poder imprimir reportes JasperReports, utiliza una clase llamada
net.sf.jasperreports.engine.JasperPrintManager. Si se desea,
pueden exportarse los objetos JasperPrint a otro formato e
imprimirlos en la aplicacin encargada de manejar el formato elegido.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
296
Exportando los reportes
En muchas aplicaciones es til transformar los reportes del formato
propio de JasperReports a otro, como PDF, HTML, XLS, etc. Esto
permite que las aplicaciones no deban utilizar la herramienta grfica
de visualizacin de reportes provista por Jasper y permitir a los
usuarios utilizar la que mejor satisfaga sus necesidades.
Este proceso se realiza mediante la clase
net.sf.jaspereports.engine.JasperExportManager, la cual
transforma el documento original a un formato diferente. Esto
significa que se utiliza el objeto JasperPrint y se lo transforma en el
formato del tipo de documento deseado.
Nota: En la siguiente seccin se muestra un ejemplo de como
crear una plantilla de un reporte mediante una herramienta
grfica (iReport).
Referencias y recursos
1. Ver Anexo I Licencias de Software
The Definitive Guide to JasperReports
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
297
IReport
Introduccin
iReport es un editor visual (What You See Is What You Get) de
reportes para la librera JasperReports. iReport soporta el 100% de
los tags XML de JasperReports (JRXML).
Motivacin
[1]
Desde sus inicio, JasperReports ha sido diseada e implementada
como una librera de renderizado de contenidos; los programadores
Java que requieren generar reportes, pueden bajarla, editar el
JRXML y el cdigo fuente de la aplicacin de reportes y generarlos
sin ningn inconveniente. Sin embargo, a medida que
JasperReports ha ido evolucionando como motor de reporting, las
prestaciones se han acrecentado a punto tal, que recordar la sintaxis
de cada elemento que puede incluir un reporte, se vuelve poco
prctico. Es esta situacin la que hizo evidente la necesidad de
herramientas avanzadas para el diseo de reportes. El creador de
JasperReports (Teodor Danciou) comenz un proyecto a tal fin el
cul no prosper, ya que la complejidad que presentaba hubiera
puesto en riesgo el desarrollo del motor de reportes, perdiendo de
vista el objetivo principal. En ese momento es cuando aparece Giulio
Toffolini, quien comenz el desarroll de iReport. iReport se convirti
rpidamente en el entorno de facto de diseo de reportes Jasper.
Desde entonces, iReport ha seguido de cerca la evolucin de
JasperReports, brindando soporte para cada nueva caracterstica.
En la actualidad, JasperReports e iReport son el ncleo del un mismo
proyecto llamado JasperSoft Business Intelligence Suite, junto a
otras herramientas de Inteligencia de Negocios para ETL, OLAP y
Data Analysis.
Licencia
iReport es distribuido bajo la licencia GNU General Public License
Version 2 o GPLv2
[2]
Diseo de Reportes
Estructura de un reporte
Un reporte se compone de mltiples secciones horizontales
denominadas bandas (bands). Cuando un reporte es impreso o
llenado con datos, estas bandas son incluidas una o varias veces, de
acuerdo con la funcin que cumpla. Por ejemplo, la banda
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
298
encabezado (heading band), aparecer en cada nueva pgina del
reporte, mientras que la banda detalle (detail band), lo har por
cada registro. Un reporte contiene por defecto nueve bandas, estas
son:
title: ttulo del reporte, aparece slo al inicio del mismo.
pageHeader: ttulo por cada pgina del reporte.
columnHeader: encabezados, til para encolumnar los datos
del reporte
detail: el contenido propio del reporte. Aqu irn los datos
obtenidos desde una fuente de datos.
columnFooter: pie de las columnas
pageFooter: pie de pgina, por ejemplo para colocar nmero
de pgina
summary: para colocar un resumen, aparece slo al finalizar el
reporte (ltima pgina).
groupHeader: para cada grupo creado, se genera una banda
al iniciar un grupo.
groupFooter: para cada grupo creado, se genera una banda al
finalizar un grupo.
Las ltimas dos bandas se insertarn (de manera opcional) por cada
nuevo grupo que se cree en el reporte. Podemos observar la
configuracin inicial de un reporte a continuacin:
Bandas de un reporte
A pesar de esta estructura inicial, la configuracin de un reporte, es
lo suficientemente flexible, como para crear el layout que ms se
adapte, segn la situacin (por ejemplo divisin del la estructura
principal del reporte, esto es, columnHeader, detail y columnFooter,
en columnas).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
299
Elementos de un reporte
En cada banda descripta anteriormente se deben colocar aquellos
elementos que reflejan informacin pertinente, o simplemente el
diseo del reporte. Existe una variedad de elementos, u objetos, que
se pueden introducir en un reporte, estos son:
Lneas
Rectngulos
Elipses
Texto esttico
Campos de textos
Imgenes
Sub-reportes
Tablas de mltiples entradas
Diagramas o grficos
Cuadros
Es mediante estos elementos que se crear cualquier tipo de reporte.
La barra de herramientas presenta un aspecto como el siguiente:
Barra de herramientas de iReport
En general, la edicin visual del reporte, es lo suficientemente
autodescriptiva y no presenta mayores dificultades. Para un mejor
conocimiento de los elementos anteriores y sus propiedades puede
consultarse el capitulo 4 Report Elements de The Definitive
Guide to iReport
[1]
Definicin de fuentes de datos (Datasources)
Existen muchas formas de obtener datos para llenar un reporte; por
ejemplo, es posible incluir una sentencia SQL en el reporte y brindar
una conexin JDBC a una base de datos contra la cual se ejecutar la
sentencia y luego ser ledo el conjunto de resultados. iReport ofrece
un amplio espectro de lenguajes de consulta tales como SQL, HQL,
EJBQL y MDX, adems de otros lenguajes como XPath. Es posible
tambin desarrollar un plugin para un lenguaje que no est
soportado. Si la intencin es no usar un lenguaje de consultas, o si no
se quiere colocar la sentencia dentro del reporte, es posible utilizar
una fuente de datos JasperReports (JR datasource). Un JR
datasource es bsicamente un objeto que itera sobre una simple
tabla. Todos los JR datasources implementan la interfaz
JRDataSource. JasperReports incluye wrappers para las fuentes de
datos ms populares como un resultset JDBC, archivos CSV, archivos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
300
XML entre otros. A pesar que es amplio el nmero de fuentes de
datos soportada, siempre es posible implementar un datasource
personalizado.
iReport brinda soporte para configurar conexiones a distintas fuentes
de datos, necesarias para llevar a cabo el diseo de reportes.
Como funciona una fuente de datos en
JasperReports?
JasperReports es un motor de reportes orientado a un conjunto de
registros (record-set-oriented-engine). Vale decir que, es
necesario indicar un conjunto de resultados para llenar de datos un
reporte. Cuando un reporte es ejecutado, el motor itera a travs del
conjunto creando y llenando las bandas de acuerdo a las definiciones
del reporte. Bandas, grupos y variables estn fuertemente atados al
conjunto de resultados, es por ello que slo puede definirse una
sentencia por reporte. Cada registro contiene una serie de campos,
los mismos deben ser declarados en el reporte antes de poder ser
usados (se ver como hacer esto en la prxima seccin). Un
datasource en el contexto de iReport se refiere a tipos de
conexiones de las que se pueden obtener el conjunto de resultados
para realizar el reporte. Estas son los principales fuentes de datos:
Conexin JDBC
Fuente de datos XML
Conexin Hibernate
Proveedor de fuente de dato JR
Conexin OLAP Mondrian
Conexin XML/A
En lo que concierne al presente trabajo, las ltimas dos conexiones
son las necesarias para realizar reportes desde el DataWarehouse que
ya se ha construido en captulos anteriores.
Nota: Es necesario recalcar que existen fuentes alternativas
y que, en adicin, se pueden desarrollar nuevas que se
adapten a las diferentes circunstancias y necesidades
Configurando una conexin Mondrian
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
301
En primer lugar se debe acceder al men Data/Connections-
Datasources, dentro del mismo se observan las conexiones
configuradas:
Connections/Datasources
Para crear una nueva fuente de datos, se deber presionar el botn
new, luego iReport mostrar las posibles conexiones que se pueden
crear:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
302
Propiedades de Conexin
Como ya es sabido, una conexin Mondrian requiere de un atributo
Jdbc para indicar la base de datos que actuar de fuente de datos
para el esquema definido. Luego de seleccionar la opcin Database
JDBC Connection y pulsar next aparecer el dilogo para completar la
informacin de la conexin JDBC. Puede pulsarse Test para
asegurarse que los datos son correctos:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
303
Configurando una conexin JDBC
Una vez creada exitosamente la conexin JDBC, es posible configurar
la conexin mondrian (Mondrian OLAP Connection). Los datos de la
conexin deben quedar de la siguiente manera:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
304
Configurando una conexin Mondrian
De manera alternativa, puede configurarse una conexin XMLA (ms
genrica que una conexin Mondrian):
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
305
Configurando una conexin XML/A
De esta forma ya se tiene todo lo necesario para empezar a trabajar
con los elementos del reporte.
Campos, Parmetros y Variables
En un reporte, hay ciertos objetos que pueden alojar un valor. Estos
son campos (fields), parmetros (parameters) y variables. Estos
poseen las siguientes cualidades:
Deben ser declarados antes de ser usados
Pueden modificar su valor mientras se est imprimiendo el
reporte
Son tipados; deben ser declarados como un tipo Java, por
ejemplo, String, Double o Number.
Cualquiera de los campos, parmetros, variables y sus propiedades
pueden ser observados y/o modificados a travs del panel Document
Structure:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
306
Panel Document Structure
Puede crearse un campo, parmetro o variable, desde este panel.
Slo basta realizar un click secundario sobre el rbol y en el men
contextual seleccionar add.
Un reporte es normalmente creado a partir de una fuente de datos
(datasource). Tal como se ha visto, un datasource est organizado
como un conjunto de registros que a su vez estn compuestos de una
serie de campos. Un campo es identificado por:
Un nombre
Un tipo Java
Una descripcin
La forma de acceder a un campo es la siguiente
Cdigo: Acceso a un campo
$F{MiCampo}
Las variables son definidas automticamente por iReport (built_in)
o creadas por el usuario. Estas son de utilidad para realizar clculos o
conservar estados durante la generacin del reporte. Un ejemplo de
variable built-in es el nmero de pgina; una variable definida por el
usuario podra ser un acumulador de sub-totales para obtener un
total general al final del reporte.
Para ms informacin sobre parmetros puede leerse la seccin
Datos del Reporte de JasperReports.
Definiendo un campo con una consulta MDX
Es posible registrar campos desde una sentencia, en este caso MDX
(aunque podra ser SQL, EJBQL, etc). Para ello, primero hay que
asegurarse que la conexin con la que se est trabajando, sea la
conexin Mondrian, en este caso, GonMondrian; luego se debe
acceder al editor de consultas (desde el men data/report query).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
307
Report Query
La consulta MDX a ejecutar es la siguiente:
Cdigo: Sentencia rdenes 2007
SELECT NON EMPTY {[Measures].[Unit Sales], [Measures].[Branch Sales]} ON
COLUMNS,
NON EMPTY {[Branches.Category].members} ON rows
FROM [Orders]
WHERE ([OrderStatus].[ALL OrderStatuss].[Finalizada], [Time.Time].[ALL
Time.Times].[2007])
Esta consulta desagrega la jerarqua Categora de Sucursales hasta
su menor nivel (Sucursal), mostrando totales de rdenes (en
unidades y monto de venta) en cada uno de sus niveles. Todo esto
para rdenes realizadas en el ao 2007 y que han sido finalizadas. Se
puede apreciar un resultado ms grfico de la sentencia con JPivot:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
308
Report Query
Con la consulta lista dentro de Report Query, se selecciona la opcin
Automatically Retrive Fields, y en la seccin izquierda, aparecer
la estructura del resultado en columnas, filas, jerarquas, niveles y
miembros como puede apreciarse a continuacin:
Result Structure
Se pueden seleccionar cualesquiera de los miembros para agregarlos
como campo del reporte. Por ejemplo, realizando doble click en el
miembro Unit Sales de las columnas, su informacin se colocar en el
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
309
editor de propiedades del campo. Al ser un campo numrico, se debe
colocar su tipo como Numeric. Una vez configurado, se debe
presionar el botn Add Field con lo que el campo quedar ubicado en
la grilla inferior. Este proceder se puede observar a continuacin:
Aadir campo desde la consulta MDX
De igual forma, se seleccionan todos los campos que se requieren
para llevar a cabo el informe. Al finalizar, se presiona OK en el editor
y se retorna a la edicin del reporte. Puede observarse todos los
nuevos campos en el panel Document Structure. Para colocar un
campo en el reporte, slo es necesario arrastrarlo y soltarlo en la
banda correspondiente. A continuacin se observa el ejemplo de Unit
Sales en la banda Detail, que es precisamente el nivel de mayor
detalle (unidades vendidas por la sucursal):
Insercin de campo en el reporte
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
310
Si bien JasperReports e iReport brindan la facilidad de declarar
variables para acumular valores, cada grupo y sub-grupo del reporte
puede valerse de expresiones MDX para obtenerlos. Por ejemplo, si
se quiere el total de unidades vendidas para todos las categoras de
negocios, la siguiente expresin ser la que determinar el valor del
campo:
Cdigo: Expresin MDX para obtener un Grand Total
DATA(Rows[Branches][(ALL)])([Measures].[Unit Sales],?)
De igual manera para el total de unidades vendidas por negocio:
Cdigo: Expresin MDX para obtener total de unidades vendidas por negocio
DATA(Rows[Branches][Business])([Measures].[Unit Sales],?)
Y as, se puede definir cada campo de acuerdo al nivel de detalle que
se desee.
Ejecucin de reportes
Ya diseado el reporte, slo queda compilarlo y ejecutarlo. Las
opciones referentes a compilacin/ejecucin, se encuentran dentro
del men Build. La opcin Build/Compile nicamente generar el
fichero .jasper, el cual luego ser utilizado en las aplicaciones
encargadas de llenar el reporte con datos. Para obtener una
visualizacin del resultado final del reporte, se debe elegir la opcin
Build/Execute (with active connection), si se est trabajando
con una fuente de datos, o Build/Execute (empty data source), si
solamente es el aspecto resultante del reporte. Dentro del men
Build, es posible seleccionar uno de los diferentes formatos de salida
para el reporte. En la siguiente imagen se observa una
previsualizacin del reporte creado en esta seccin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
311
Previsualizacin del reporte
Utilizacin de reportes
Al finalizar el proceso de diseo, se puede utilizar la versin sin
compilar (.jrxml) o compilada (.jasper) para llenar con datos e
imprimir reportes. En el prximo captulo, se ver un ejemplo de uso
de un archivo .jrxml en una aplicacin web, ms precisamente con
JasperServer, el portal Web del proyecto JasperSoft. De esta
manera, es posible, no slo disear reportes de forma simple y
poderosa, sino tambin, realizar el despliegue y distribucin de igual
manera.
Reportes OLAP avanzados
Teniendo en cuenta las diversas combinaciones dimensionales que
pueden realizarse con el DataWarehouse construido, y el cubo
multidimensional definido, es posible realizar reportes avanzados.
Podra, por ejemplo, realizarse un reporte cliente por cliente (de una
zona, de un negocio, o todos) con la distribucin de rdenes por das
de la semana. Tambin sera un reporte interesante, mostrar de que
manera han evolucionado las rdenes de un negocio en particular y
sus sucursales. La consulta MDX que define este ltimo reporte sera:
Cdigo: Consulta MDX rdenes de sucursales de NUNC
SELECT NON EMPTY CrossJoin({[Branches.Category].[ALL
Branches.Categorys].[Construccion].[Ferreteria y buloneria].[Nunc].[tristique
6],
[Branches.Category].[ALL Branches.Categorys].[Construccion].[Ferreteria y
buloneria].[Nunc].[vel, convallis 1634],
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
312
[Branches.Category].[ALL Branches.Categorys].[Construccion].[Ferreteria y
buloneria].[Nunc].[lorem, sit 2870]}, {[Measures].[Branch
Sales]}) ON COLUMNS, NON EMPTY
Hierarchize({Descendants([Time.Time].[ALL Time.Times], 2.0)}) ON rows
FROM [Orders]
El resultado de la consulta anterior observada con JPivot:
rdenes de sucursales Nunc en JPivot
Vista de un grfico de lneas verticales
Luego de realizar los pasos para crear el nuevo reporte, y dentro del
editor de sentencias, se coloca la instruccin MDX anterior. El
resultado de los campos para filas y columnas obtenido es:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
313
Campos de MDX rdenes Nunc en iReport
Se observa que dentro de Columnas/Medidas reconoce un slo campo
denominado measuresLevel, mientras que debera ser: Branch
Sales. Se desconoce el motivo de este problema, pero al intentar
colocar un sentencia que involucre dos dimensiones en las Columnas
(CrossJoin), siendo una de ellas la dimensin de medidas, se
obtiene un resultado que no es el esperado. Si de todas formas se
intenta colocar el campo measuresLevel como Branch Sales, como se
observa en la imagen anterior, el resultado sigue sin ser el esperado.
Puede observarse en la siguiente imagen, un reporte ejecutado con el
campo Branch Sales en el detalle del reporte:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
314
Ejecucin fallida de reporte Nunc
Una alternativa posible para obtener el reporte anterior es intentarlo
con la conexin XML/A creada. Para ello, basta simplemente con
cambiar la conexin activa del reporte, y en el dilogo Report Query
cambiar el tipo de sentencia a MDX/XMLA. Para confirmar que la
sentencia es correcta, se ingresa al Query Designer y luego se
selecciona la opcin ejecutar consulta. Puede observarse dicho
proceder a continuacin:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
315
Campos de MDX rdenes Nunc en iReport - Conexin XMLA
Query Designer XMLA
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Jasper Reporting
316
En el editor de consultas, se obtiene el resultado esperado al ejecutar
la consulta. Al parecer, los campos ledos en Report Query son los
correctos:
Branch
BranchSales
Quarter
Para probar el reporte se colocaran los 3 campos en el detalle. Su
ejecucin muestra el siguiente mensaje:
Mensaje de ejecucin. Sin pginas
Como se puede apreciar, el resultado de la ejecucin es un reporte
que no contiene pginas. Se ha constatado que la sentencia MDX es
la correcta, pero por alguna razn su inclusin en el reporte se hace
imposible.
Nota:
La versin utilizada de iReport es la 2.04, la ms actual al
momento de edicin de esta seccin
Referencias y recursos
1.
1,0
1,1
The Definitive Guide to iReport
2. Ver Anexo I Licencias de Software
Comparativa Pentaho Reporting-
Jasper Reporting
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Pentaho Reporting-Jasper Reporting
319
A continuacin se presentar una serie de tablas para efectuar la
comparativa entre los distintos componentes de Jasper Reporting y
Pentaho Reporting.
Tabla Comparativa
Jasper Reporting Pentaho Reporting
Licencia
GPL salvo JasperReports
LGPL
Pentaho Public Licence
Motor de
Reportes
JasperReports JFreeReport
Fuentes de
Datos
Soportadas
JDBC, archivos XML y
archivos remotos XML,
JavaBeans set, Archivos
CSV, Conexin Hibernate,
Conexin Hibernate cargada
desde Spring, EJBQL, XMLA,
OLAP Mondrian, y cualquier
proveedor de
JRDataSource.
JNDI, XQuery, Metadata
Query (MQL)
Lenguajes
de consultas
soportados
SQL, HQL, XPath, XPath2,
EJBQL, MDX, XMLA-MDX.
Adems permite definir
nuevas fuentes de datos
(JRDataSource) y lenguajes
de consultas
personalizados.
SQL, MDX, XQuery,
MQL.
Editor de
Reportes
iReport
Report Designer/Report
Design Wizard
Soporte de
Grficos
Pueden realizarse diversa
clases de grficos y
diagramas con
JasperReports. iReport
facilita la tarea de diseo y
edicin de grficos.
Soporta distintos tipos
de grficos que pueden
crearse mediante
Report Designer o
editando manualmente
el archivo xml
Formato de
Archivo
Fuente del
Reporte
XML XML
Formatos de
Salida
PDF, HTML, RTF, XLS, ODT,
CSV, XML
HTML, PDF, Microsoft
Excel, CSV, Rich Text
format y texto plano
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Pentaho Reporting-Jasper Reporting
320
Adhoc
Reporting
No incluye reportes Adhoc
en la versin open source
Se debe definir un
modelo de metadatos
para realizar reportes
Adhoc
Publicacin
de Reportes
Consiste en el archivo
.jrxml de la definicin, el
cul luego ser publicado
con otra herramienta, ya
sea una aplicacin a medida
del reporte o JasperServer.
Incluye tanto en Report
Designer como en
Report Design Wizard
un asistente que
permite al usuario
publicar reportes en un
servidor Pentaho
Conclusin Reporting
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin Reporting
323
Finalizada la etapa de generacin de reportes, se concluye que los
reportes necesarios para brindar informacin de alto y bajo nivel al
usuario, han sido obtenidos satisfactoriamente tanto con las
herramientas brindadas por JasperSoft como las de Pentaho; sin
embargo, sus prestaciones y caractersticas no son idnticas. Se
encontraron puntos fuertes y dbiles en ambas herramientas,
destacando en ambas como punto ms fuerte la facilidad de uso y
rpida generacin de reportes y como punto ms dbil los problemas
encontrados al trabajar con consultas MDX. A pesar de estos
problemas, descriptos en la seccin anterior, pueden obtenerse
reportes de calidad que brinden al usuario la informacin que
necesita.
Para concluir este captulo, se efectuar una ponderacin de 1 a 5
puntos para determinadas cualidades externas que presentan o
deberan presentar las herramientas:
Herramientas
Jasper
Herramientas
Pentaho
Funcionalidad 3
[1]
4
[2]
Usabilidad 5
[3]
4
[4]
Flexibilidad 5 3
[5]
Interoperabilidad 4
[6]
4
[6]
Fiabilidad 4 3
[7]
Eficiencia 4 4
[8]
Documentacin 5
[9]
3
[10]
Calificacin
promedio
4.2 3.6
1. La funcionalidad requerida para este trabajo arroj una serie
de inconvenientes, sobre todo para reportes OLAP avanzados.
2. La herramienta permite crear reportes, pero se encontraron
dificultades a la hora de trabajar con las jerarquas de cubo
mondrian.
3. iReport es la clave para lograr que el uso de JasperReports
resulte extremadamente simple.
4. La herramienta es fcil de usar e intuitiva. Debera incluir
algunas herramientas mas para facilitar la edicin de reportes,
sobre todo para disposicin de elementos.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin Reporting
324
5. No presenta la posibilidad de configurar nuevas fuentes de
datos o definir componentes propios.
6.
6,0
6,1
Los reportes generados pueden ser utilizados casi por
cualquier aplicacin web o de escritorio.
7. Deben realizarse configuraciones manuales en los reportes
generados para trabajar con cubos y sentencias MDX.
8. Los reportes se generan rpidamente.
9. Documentacin extensa y variada tanto oficial como no
oficial. Existen bibliografa oficial tal como The Definitive Guide
to JasperReports e iReport que documentan completamente las
herramientas.
10. Existe documentacin online la cual no incluye todos
las capacidades de la herramienta. Se dificulta navegar por la
informacin. Existe un foro en la pagina de Pentaho donde se
tratan problemas con estas herramientas.
Captulo VI: Plataformas de
Inteligencia de Negocios
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Plataformas de Inteligencia de Negocios
327
Se observa en el diagrama general de BI-FLOSS los temas a
desarrollar en las secciones incluidas en este captulo:
Temas a desarrollar
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JPIVOT
329
JPivot
JPivot es una librera estndar de JSP que renderiza una tabla OLAP y
permite al usuario realizar tareas tpicas OLAP, por ejemplo seccionar
un cubo. Tanto la aplicacin web de Pentaho como la de Jasper hacen
uso de esta librera para ejecutar los anlisis definidos por el usuario.
Mas especficamente, un anlisis brinda capacidades OLAP al usuario
gracias a tcnicas como rebanar y dividir (slice and dice), filtrar,
graficar, descender o ascender jerarquas de un cubo en tiempo real;
permitiendo explorar tendencias, patrones, anomalas y correlaciones
en los datos.
Nota: No se pretende dar una gua completa del
funcionamiento de JPivot, ya que queda fuera del alcance de
esta gua. Para mayor informacin consultar la pagina oficial
de JPivot: http://jpivot.sourceforge.net/
Trabajando con Pentaho BI-Server
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
333
Introduccin
La plataforma que ofrece Pentaho, para que sus usuarios ejecuten
soluciones de BI, esta compuesta por un servidor de aplicaciones y
una aplicacin web corriendo sobre este. La instalacin por defecto
ofrecida viene con el servidor Jboss, pero el usuario pude optar por
otro servidor de su preferencia compatible con Java EE.
En cuanto al servidor de aplicaciones pude utilizarse cualquier
servidor compatible con JEE o cualquier contenedor web que
implemente las especificaciones de Java Servlet y JavaServer Pages
(JSP) provistas por SUN. La aplicacin que corre sobre estos
servidores brinda la posibilidad al usuario de navegar por sus
soluciones de BI, obteniendo acceso a reportes, anlisis, tableros de
control, etc. Adems, brinda la posibilidad de realizar configuraciones
de permisos (a usuarios con los privilegios adecuados) para los
distintos documentos, planificar tareas, administrar suscripciones,
etc.
En la siguiente seccin se describen los pasos llevados a cabo para
realizar la configuracin y pruebas del servidor con Tomcat 5.5.26
(contenedor web) y MySQL 5.0 (motor de bases de datos utilizado
por la aplicacin). Para mas detalles sobre las capacidades de la
plataforma de BI de Pentaho dirigirse al sitio oficial Pentaho BI-
Server
[1]
y documentacin oficial Pentaho BI-Server
[2]
.
Licencia
Pentaho Public Licence
[3]
Versin utilizada
Pentaho Platform 1.6 GA
Configuracin del Servidor con MySQL y
Tomcat
Consideraciones previas
La versin ofrecida por Pentaho (a la fecha de escribir este
documento) para que los usuarios bajen y prueben, es la pentaho-
1.6.0GA, tanto para Linux como para Windows. Esta es una versin
que por defecto instala el servidor de aplicaciones JBoss y da la
opcin de utilizar MySQL o HSQLDB como motores de bases de datos.
Si se opta por instalar esta versin, se obtiene una plataforma lista
para ser utilizada con su respectiva aplicacin configurada en JBoss y
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
334
sus bases de datos configuradas en el motor de bases de datos
seleccionado. Cabe aclarar que esta versin, instala la plataforma con
una solucin de prueba, para que los usuarios puedan explorar las
capacidades de la plataforma. No obstante los usuarios pueden crear
sus propias soluciones y modificar la configuracin de la plataforma
para que esta se ajuste a sus necesidades.
Antes de comenzar se debe verificar que se encuentre instalado:
Java SDK or JRE 1.5
[4]
.
Configurada la variable "JAVA_HOME" indicando el directorio
donde la JDK esta instalada.
Apache Ant versin 1.6.2 o superior, la cual puede obtenerse
desde el sitio de apache
[5]
.
Tomcat
[6]
versin 5.5.x
MySQL
[7]
versin 5.0.
A continuacin se explica como configurar el servidor con su
respectiva aplicacin y bases de datos desde cero. Se opt por
realizar la configuracin desde cero, ya que pueden observarse los
pasos involucrados en la configuracin del servidor y obtenerse una
mejor idea de su funcionamiento y partes que lo componen.
Nota: Queda fuera del alcance de esta gua explicar la
configuracin y pasos requeridos para realizar la instalacin de
las herramientas antes mencionadas. Si se detalla como se
configuran para ser utilizadas por la plataforma de Pentaho
Compilando la distribucin adecuada
Generando pentaho.war
El primer paso para configurar la plataforma BI de Pentaho, consiste
en compilar la aplicacin web para ser publicada en el servidor. Para
ello se debe descargar del sitio de descargas de Pentaho
[8]
la
distribucin listada como pentaho_j2ee_deployments-
numero_de_versin.zip.
Una vez descargada la distribucin, se debe compilar, mediante ant,
la versin adecuada. Para ello, desde linea de comandos, ir al
directorio donde se encuentra la distribucin y ejecutar el comando
ant -p para obtener un listado de las tareas disponibles:
Cdigo: Tareas ant
Pentaho BI Platform deployment build process...
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
335
Main targets:
Other targets:
build-all
build-orion2.0.5-ear
ear-all-pentaho-jboss
ear-pentaho-jboss
ear-pentaho-jboss-hsqldb
ear-pentaho-jboss-hsqldb-no-portal
ear-pentaho-jboss-mysql
ear-pentaho-jboss-mysql-no-portal
ear-pentaho-jboss-no-portal
init
init-pentaho-jboss-ears
init-pentaho-jboss-wars
war-all-pentaho
war-all-pentaho-jboss
war-all-pentaho-tomcat
war-pentaho-jboss
war-pentaho-jboss-for-ear
war-pentaho-jboss-for-ear-no-portal
war-pentaho-jboss-hsqldb
war-pentaho-jboss-hsqldb-for-ear
war-pentaho-jboss-hsqldb-for-ear-no-portal
war-pentaho-jboss-hsqldb-no-portal
war-pentaho-jboss-mysql
war-pentaho-jboss-mysql-for-ear
war-pentaho-jboss-mysql-for-ear-no-portal
war-pentaho-jboss-mysql-no-portal
war-pentaho-jboss-no-portal
war-pentaho-tomcat
war-pentaho-tomcat-hsqldb
war-pentaho-tomcat-mysql
zip-pentaho-portal-layout-war
zip-pentaho-steel-wheels-style-war
zip-pentaho-style-war
Ya que se desea la versin compatible con Tomcat y MySQL se
ejecuta el comando ant war-pentaho-tomcat-mysql, lo que crear
dentro del directorio de trabajo un nuevo directorio llamado
/build/pentaho-wars/tomcat/mysql5/ donde se encuentra la versin
compilada (pentaho.war) de la aplicacin web a ser publicada en
Tomcat.
Nota: Si se desea pueden realizarse modificaciones en el
archivo build.properties del directorio descargado del sitio de
Pentaho. Esto permite ajustar algunos parmetros antes de
realizar la compilacin en caso de que se desee. Por ejemplo,
pueden asignarse puertos o host que sern utilizados a la hora
de realizar la conexin con la base de datos. En este caso se
dejan los valores por defecto.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
336
Generando los archivos de estilo
Pentaho separa en aplicaciones distintas los estilos que la solucin
principal utiliza (en el caso de utilizar la compilacin .ear este paso no
es necesario ya que los estilos estn incluidos en el). Debido a esto
se deben generar los archivos war correspondientes. Para ello
debemos dirigirnos al directorio donde se encuentra la distribucin
descargada y ejecutar los comandos ant:
Cdigo: Comandos ant para compilar las aplicaciones de estilos
ant zip-pentaho-style-war
#Utilizado por la solucin de ejemplo provista por pentaho
ant zip-pentaho-steel-wheels-style-war
ant zip-pentaho-portal-layout-war
Estos comandos generan un conjunto de archivos .war que pueden
ser encontrados dentro del directorio build/pentaho-wars/ del
directorio de la distribucin previamente descargada.
Configurando la solucin de Pentaho
Que es una solucin Pentaho?
Antes de comenzar a describir la configuracin de la solucin, se
realiza una descripcin de lo que es una solucin Pentaho.
Una solucin, consiste en un conjunto de documentos que definen los
procesos y actividades que son parte del sistema en la
implementacin de una solucin a un problema de negocios. Estos
documentos incluyen principalmente:
Action Sequence Definitions: Son archivos xml que definen
acciones o un conjunto de acciones a ejecutarse. Por ejemplo
puede especificarse que se ejecute un reporte y que luego sea
enviado por mail a un usuario. En Pentaho todo elemento que
quiera ser ejecutado por el servidor, por ejemplo un reporte,
enviar un mail, anlisis, etc debe ser invocado por un Action
sequence que especifique como ejecutarlos.
Definiciones de reportes: Son las definiciones creadas por el
usuario mediante alguna herramienta como Report Design
Wizard o Report Desginer.
Imgenes: utilizadas en los reportes o para definir las vistas
del repositorio (imgenes de iconos por ejemplo).
Reglas: Reglas de negocios (fuera del alcance de esta gua).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
337
Sentencias: Sentencias (MDX, XQuery, SQL) utilizadas en los
reportes o en los Action sequence.
En conclusin, la solucin contiene los reportes, anlisis, tableros de
control, reglas de negocios, etc, creadas por el administrador para
que puedan ser accedidos por los usuarios correspondientes.
Nota: Queda fuera del alcance de esta gua detallar el
funcionamiento de Action Sequence. Para mas informacin
consultar la documentacin
[9]
.
Configuracin
Para configurar una solucin, se debe bajar del sitio de descargas
[8]
de Pentaho, el archivo listado como pentaho_solutions-
numbero_de_versin. Este archivo debe descomprimirse y colocarse
en un directorio donde se desee almacenar las soluciones. Este
directorio es el repositorio de soluciones, ya que dentro de el, es
donde deben crearse las distintas soluciones. Por defecto cuando se
descarga y se descomprime este archivo, se obtiene un directorio
pentaho-solutions (repositorio) y dentro de el se encuentran creadas
dos soluciones de prueba (samples y test). Los otros directorios
contenidos dentro del repositorio son utilizados para su configuracin.
Los pasos mnimos para crear una solucin son:
1. Crear un directorio dentro del repositorio con el nombre de la
solucin.
2. Crear dentro de la solucin, un archivo llamado index.xml, el
cual contiene:
o Nombre del directorio.
o Descripcin del contenido.
o Icono que mostrar el servidor para acceder al repositorio
(ej: icono.png).
o Si la solucin es visible o no (valor booleano).
o Como desea que se observe el contenido (icons o list).
A continuacin se observa el contenido del archivo index.xml
Cdigo: Contenido de index.xml
<index>
<name>%name</name>
<description>%description</description>
<icon>samples.png</icon>
<visible>true</visible>
<display-type>icons</display-type>
</index>
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
338
Como puede observarse, los tags que contienen un valor que
comienza con %, representan valores que son asignados en base al
archivo index.properties. Este archivo contiene los valores que
remplazaran estas variables. La principal funcin de este archivo es
soportar diferentes idiomas, con lo que se deberan tener varios
index.properties como idiomas deseados. Los diferentes archivos de
propiedades deben ser nombrados como
index_codigo_de_idioma.properties, por ejemplo:
index_es.properties.
A continuacin se observan los valores asignados al archivo
properties utilizado en la solucin gon.
Cdigo: Contenido de index.xml
description=GON Repository
name=GONRep
Dentro de nuestra solucin, pueden crearse distintos directorios y
subdirectorios para agrupar lgicamente los elementos de la solucin
(por ejemplo para agrupar por reas de una organizacin). El nico
requisito es que por cada directorio creado se incluya el archivo
index.xml con la informacin antes detallada.
Configuraciones opcionales
Solo restan dos pasos opcionales, para que la solucin quede
configurada correctamente.
1. Configurar el password de publicacin, el cual permite que
aplicaciones externas (ej: Report Designer), publiquen reportes
dentro de nuestra solucin. Para ello se debe acceder al
directorio llamado system, dentro del repositorio, y editar el
archivo publisher_config.xml. Se deben localizar los tags
<publisher-password></publisher-password> y asignarles un
password. Si no se desea, puede no asignarse esta clave, pero
no podrn publicarse reportes desde aplicaciones externas.
2. Hay dos opciones en cuanto a la manera en la que el servidor
maneja el repositorio. Una es filebased, en la cual el servidor
maneja las soluciones mediante el sistema de archivos (mas
rpido, pero sin la posibilidad de asignar permisos) y la otra es
dbbased en la cual el servidor maneja el repositorio mediante el
motor de base de datos utilizado (mas lento, pero con manejo
de permisos).
En caso que se decida utilizar uno u otro mtodo de manejo de
repositorio, se debe configurar en el archivo pentaho.xml dentro del
directorio system, mencionado anteriormente, lo siguiente:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
339
Localizar los tags <ISolutionRepository
scope="session"></ISolutionRepository> y asignar el valor:
o org.pentaho.repository.filebased.solution.SolutionReposit
ory, en caso de que se desee que se maneje mediante el
sistema de archivos (configuracin por defecto).
o com.pentaho.repository.dbbased.solution.SolutionReposit
ory, en caso que se desee que se maneje mediante el
motor de base de datos (configuracin utilizada en esta
gua).
Para el caso de esta gua, se crea un directorio llamado gon dentro
del repositorio, el cual, ser utilizado como solucin. Dentro del
mismo se crean dos directorios, uno con el nombre reportes (que
contendr los distintos reportes) y el otro con el nombre anlisis (que
contendr los anlisis creados). Cabe aclarar que, por cada directorio
creado, se crean los respectivos archivos index.xml.
Mediante estos pasos, se finaliza la configuracin de la solucin. Lo
nico que resta es publicar reportes o anlisis para que los usuarios
puedan acceder a ellos, de lo contrario, se visualizar la solucin pero
no tendr contenido alguno.
Configurando MySQL
MySQL es el motor de base de datos elegido para crear las bases de
datos que necesita la aplicacin web de Pentaho para operar. Las
Bases de datos necesarias para que la aplicacin funcione con la
configuracin seleccionada para gon son:
quarz: base de datos utilizada por el planificador de Pentaho.
hibernate: base de datos que utiliza la capa de persistencia de
Pentaho. En esta base de datos, se almacenan por ejemplo, las
soluciones Pentaho en caso de que la configuracin as lo
indique.
sampledata: base de datos con datos de prueba necesaria
para correr los ejemplos de prueba. No es necesaria y si el
usuario decide puede borrarla.
userdb: es la base de datos con la informacin sobre los
usuarios del sistema. Por defecto esta base de datos no es
creada, pero en el caso de esta gua se modifica la
configuracin para realizar el manejo de usuarios mediante una
base de datos (explicado mas adelante).
Se provee una versin electrnica de los scripts necesarios para crear
las bases de datos. En el caso, de la base de datos de usuarios
(userdb), se colocan los comandos a continuacin ya que no son
demasiados:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
340
Cdigo: Comandos para crear la base de datos de usuarios
CREATE DATABASE userdb;
USE userdb;
CREATE TABLE users (username VARCHAR(50) NOT NULL PRIMARY KEY,
password VARCHAR(50) NOT NULL, enabled BOOLEAN NOT NULL);
CREATE TABLE authorities (authority VARCHAR(50) NOT NULL PRIMARY KEY,
description VARCHAR(100));
CREATE TABLE granted_authorities (username VARCHAR(50) NOT NULL,
authority VARCHAR(100) NOT NULL,
CONSTRAINT FK_GRANTED_AUTHORITIES_USERS FOREIGN KEY (username)
REFERENCES users(username),
CONSTRAINT FK_GRANTED_AUTHORITIES_AUTHORITIES FOREIGN KEY
(authority) REFERENCES authorities(authority));
INSERT INTO users VALUES('admin','secret',TRUE);
INSERT INTO users VALUES('gonuser','gon',TRUE);
INSERT INTO users VALUES('pat','password',TRUE);
INSERT INTO authorities VALUES('Admin','Super User');
INSERT INTO authorities VALUES('Anonymous','User has not logged in');
INSERT INTO authorities VALUES('Authenticated','User has logged in');
INSERT INTO authorities VALUES('ceo','Chief Executive Officer');
INSERT INTO authorities VALUES('cto','Chief Technology Officer');
INSERT INTO authorities VALUES('dev','Developer');
INSERT INTO authorities VALUES('devmgr','Development Manager');
INSERT INTO authorities VALUES('is','Information Services');
INSERT INTO granted_authorities VALUES('gonuser','Admin');
INSERT INTO granted_authorities VALUES('gonuser','Authenticated');
INSERT INTO granted_authorities VALUES('pat','dev');
INSERT INTO granted_authorities VALUES('pat','Authenticated');
INSERT INTO granted_authorities VALUES('admin','Admin');
INSERT INTO granted_authorities VALUES('admin','Authenticated');
Como puede observarse en el script, se crean 3 tablas. Una contiene
los usuarios, otra los roles del sistema y la ltima, la asignacin de
roles a los usuarios. Se han creado tres usuarios distintos para poder
probarlos en la aplicacin (admin, gonuser y pat). Los roles son los
definidos por defecto en la aplicacin, si se desea cambiarlos o
agregar alguno nuevo, es posible, pero deben realizarse algunas
configuraciones extras.
Configurando Tomcat
Una vez que Tomcat se encuentra instalado y funcionando
correctamente, se procede a configurarlo para que la aplicacin
previamente compilada pueda funcionar.
Creando las fuentes de datos
Para que la aplicacin pueda acceder a las distintas bases de datos
que utiliza, deben definirse las distintas fuentes de datos. Para ello,
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
341
dentro del directorio TOMCAT_HOME/conf, debe editarse el archivo
server.xml y adicionar dentro de los tags <Host> el siguiente
conjunto de lneas:
Cdigo: Definicin de fuentes de datos
<Context path="/pentaho" docbase="webapps/pentaho/">
<Manager
className="org.apache.catalina.session.PersistentManager"
saveOnRestart="false"/>
<Resource name="jdbc/SampleData" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/Hibernate" auth="Container"
type="javax.sql.DataSource"
factory="org.apache.commons.dbcp.BasicDataSourceFactory" maxActive="20"
maxIdle="5"
maxWait="10000" username="hibuser"
password="password"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/hibernate" />
<Resource name="jdbc/Quartz" auth="Container"
type="javax.sql.DataSource"
factory="org.apache.commons.dbcp.BasicDataSourceFactory" maxActive="20"
maxIdle="5"
maxWait="10000" username="pentaho_user"
password="password"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/quartz" />
<Resource name="jdbc/SampleDataAdmin" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000"
username="pentaho_admin" password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/solution1" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/solution2" auth="Container"
type="javax.sql.DataSource" maxActive="20"
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
342
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/solution3" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/solution4" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/solution5" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/datasource1" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/datasource2" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/datasource3" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/datasource4" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
343
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/datasource5" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="pentaho_user"
password="password"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/sampledata" />
<Resource name="jdbc/datasource6" auth="Container"
type="javax.sql.DataSource" maxActive="20"
maxIdle="5" maxWait="10000" username="gon"
password="gon"
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost/gonmart" />
</Context>
Se decidi mantener las fuentes de datos que vienen por defecto,
para dar la posibilidad de probar los distintos ejemplos provistos por
Pentaho. Todas las fuentes de datos que hacen referencia a
sampledata, son utilizadas por los ejemplos provistos por Pentaho.
Las fuentes de datos que hacen referencia a hibernate y quartz son
las que utilizan las bases de datos mencionadas anteriormente, las
cuales almacenan metadatos.
Al final de la lista, puede observarse una fuente definida con el
nombre datasource6, esta es la fuente de datos que apunta a la base
de datos PostgreSQL utilizada en este trabajo. En esa base de datos
se encuentran las tablas (data mart) que utiliza el esquema de
mondrian para acceder a los datos. Esta es la fuente de datos que se
utiliza en los reportes y anlisis, que mas adelante se explica como
utilizar.
Configurando los Drivers de las bases de datos
Para que las fuentes de datos creadas en el paso anterior puedan ser
utilizadas por Tomcat, deben asignarse los drivers de las bases de
datos correspondientes. Para esta gua se utiliza MySQL 5.0 y
PostgreSQL 8.1, por los que deben descargarse ambos drivers y
asignarlos al directorio TOMCAT_HOME/common/lib. Una vez hecho
esto, Tomcat podr acceder a las fuentes de datos definidas en el
paso anterior.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
344
Configurando la aplicacin Pentaho para que
pueda ser publicada por Tomcat
El ltimo paso, para poder iniciar Tomcat y publicar la aplicacin
Pentaho en el, es realizar algunas modificaciones en la configuracin
de la aplicacin. Las configuraciones que deben realizarse son las
siguientes:
Se deben copiar al directorio TOMCAT_HOME/webapps todos los
archivos .war generados en el proceso de compilacin explicado
al principio de esta seccin (pentaho.war, pentaho-portal-
layout.war, pentaho-style.war, sw-style.war).
Una vez que se han copiado los archivos war, se debe
descomprimir el archivo pentaho.war dentro de del directorio
TOMCAT_HOME/webapps/. Finalmente debera quedar creado
un directorio pentaho dentro del directorio webapps de Tomcat
.
Se debe indicar a la aplicacin que utilice la base de datos de
usuarios (userdb) antes creada, ya que por defecto maneja los
usuarios en memoria. Para ello se deben realizar dos
modificaciones:
Modificar en el archivo TOMCAT_HOME/webapps/pentaho/WEB-
INF/applicationContext-acegi-security-jdbc.xml e ingresar la
informacin de conexin de MySQL.
Cdigo: Localizar el bean dataSource y modificar la informacin de conexin para
que quede como la siguiente
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url"
value="jdbc:mysql://localhost:3306/userdb" />
<!-- se debe especificar el nombre de usuario y password
correspondiente a la base de datos userdb -->
<property name="username" value="usuario" />
<property name="password" value="userpassword" />
</bean>
Modificar en el archivo TOMCAT_HOME/webapps/pentaho/WEB-
INF/web.xml e indicar que utilice los archivos correspondientes a la
configuracin de la base de datos de usuarios.
Cdigo: Localizar el parmetro llamado contextConfigLocation y modificar sus
valores para queden como los siguientes
<context-param>
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
345
<param-name>contextConfigLocation</param-name>
<param-value>
/WEB-INF/applicationContext-acegi-security.xml
/WEB-INF/applicationContext-common-authorization.xml
/WEB-INF/applicationContext-acegi-security-jdbc.xml
/WEB-INF/applicationContext-pentaho-security-jdbc.xml
</param-value>
</context-param>
Para que pueda accederse a la aplicacin remotamente (un host
que no sea el mismo donde corre el servidor), debe indicarse
en el archivo TOMCAT_HOME/webapps/pentaho/WEB-
INF/web.xml la url base de la aplicacin (puede ser una ip
pblica o un nombre que sea resuelto por un DNS).
Cdigo: Localizar el parmetro llamado contextConfigLocation y modificar sus
valores para queden como los siguientes
<context-param>
<param-name>base-url</param-name>
<!-- url de ejemplo -->
<param-value>http://rodrigo.albolocura.com.ar:8080/pentaho/</param-
value>
</context-param>
La ultim configuracin que debe realizarse, es indicar a la
aplicacin donde se encuentra nuestro repositorio con las
soluciones Pentaho. Para ello se debe modificar en el archivo
TOMCAT_HOME/webapps/pentaho/WEB-INF/web.xml el
parmetro llamado solution-path de la siguiente manera:
Cdigo: Modificacin del parmetro solution-path
<context-param>
<param-name>solution-path</param-name>
<!-- puede indicarse cualquier directorio donde el usuario decida colocar el
repositorio -->
<param-value>/home/rdealmeida/pentaho-solutions</param-value>
</context-param>
Nota: La descompresin del archivo war no es siempre
necesaria, pero por razones de configuracin se debe
descomprimir primero para editar ciertas propiedades de la
aplicacin. Los archivos war son archivos comprimidos en el
formato zip, por lo que para descomprimirlo, puede utilizarse
cualquier aplicacin que trabaje con este formato. En Linux,
para descomprimir el archivo, se puede utilizar desde la
consola el siguiente comando unzip -d pentaho pentaho.war
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
346
Probando que la configuracin funcione
Iniciando Tomcat y MySQL
Antes de poder ingresar a nuestro navegador web y verificar que la
aplicacin se encuentra funcionando, se debe iniciar Tomcat y MySQL.
Primero debe iniciarse MySQL, ya que Tomcat al iniciarse necesita
que las bases de datos estn inicializadas. Finalmente cuando MySQL
ha terminado de iniciar, puede arrancarse Tomcat.
Nota:
Pueden verificarse los logs de Tomcat para asegurarse que no
ha ocurrido ningn problema al iniciar las aplicaciones. El path
de logs de tomcat es $TOMCAT_HOME/logs
Probando la aplicacin en el navegador
Si todo ha salido bien, al ingresar en el navegador la url
http://localhost:8080/pentaho/ se debera observar la pantalla de
login de la aplicacin Pentaho. En la siguiente imagen puede
apreciarse la pantalla que debera aparecer.
Pantalla de login
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
347
Probando autenticacin de usuarios
Para asegurar que la configuracin del manejo de usuarios, mediante
la base de datos en MySQL, funciona correctamente, se debe ingresar
mediante alguno de los usuarios creados en la base de datos. Para
ello se ingresa la informacin de nombre de usuario y contrasea, si
todo ha salido bien debera observarse la siguiente pantalla de
bienvenida.
Pantalla de inicio
En la imagen se aprecia la pantalla de bienvenida con un tablero de
control inicial. Este es provisto dentro de la solucin de ejemplo de
Pentaho.
Actualizando el repositorio de soluciones
Debido a que se seleccion que el repositorio de soluciones sea
manejado mediante MySQL, se debe actualizar el mismo para que la
aplicacin lo ponga a disposicin de los usuarios. Esto se debe a que
en la configuracin se crearon los directorios correspondientes a la
solucin gon, pero no se actualiz la base de datos de MySQL con
esta informacin. Cada vez que se realice un cambio en los
directorios de la solucin se debe actualizar el repositorio en la
aplicacin, para que estos se vean reflejados.
Para actualizar el repositorio se debe ingresar a la seccin Admin, con
un usuario que posea este rol. Dentro de esta seccin, se debe
seleccionar la opcin Update Solution Repository, como se aprecia en
la siguiente imagen.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
348
Actualizando el repositorio de soluciones
Navegando por las soluciones
Para verificar que la solucin de ejemplo y la creada anteriormente
(gon), estn funcionando, se debe ingresar a la seccin soluciones de
la aplicacin.
Soluciones del repositorio
En la imagen se observan las soluciones configuradas en la
aplicacin. Como puede apreciarse, la solucin gon se encuentra
creada con sus directorios reportes y anlisis.
Si se expanden los distintos directorios puede accederse a los anlisis
o reportes creados anteriormente (ver seccin Report Designer -
Publicacin de un reporte en el servidor y Pentaho_Design_Studio).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
349
Si se accede al reporte creado, se observara una pantalla como la
siguiente.
Seleccin del formato de salida
En esta pantalla se selecciona el formato de salida del reporte que se
va a generar. Si se selecciona pdf, se obtiene un reporte como el que
se observa en la siguiente imagen.
Reporte en formato pdf
Si se accede al anlisis de ventas de Nunc, se obtiene el documento
web generado por JPivot. En la imagen siguiente se observa el
documento generado.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
350
Anlisis de ventas Nunc
Si se desea visualizar el grfico del anlisis, se puede habilitar como
se observa en la figura anterior. A continuacin se observa el
resultado obtenido.
Anlisis de ventas Nunc con grfico
Nota: Debe verificarse que el action sequence que ejecuta el
reporte tenga definida la misma fuente de datos que se defini
en Tomcat, de no ser as debe cambiarse. Esto puede
verificarse en dentro del xml del action sequence:
<component-definition>
<location><![CDATA[mondrian]]></location>
<jndi><![CDATA[datasource6]]></jndi>
</component-definition>
Configuracin de permisos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
351
Dentro de la seccin Admin se encuentra la seccin Permissions, la
cual permite asignar permisos a los directorios y archivos dentro del
repositorio. En la siguiente figura se observan los permisos asignados
al directorio reporte dentro de la solucin gon, adems se observan
los posibles permisos ha asignar.
Seccin permisos
Recordar que esta opcin slo esta disponible si se decide manejar el
repositorio mediante una base de datos. Si se seleccion que se
maneje mediante el sistema de archivos, no se podrn asignar
permisos.
Nota: Para mayor informacin sobre como utilizar todos los
componentes de la aplicacin, consultar la documentacin
[10]
de Pentaho referente a la plataforma BI
Referencias y recursos
1. Sitio oficial Pentaho BI-Server:
http://community.pentaho.com/projects/bi_platform/
2. documentacin oficial Pentaho BI-Server:
http://wiki.pentaho.org/display/PentahoDoc/Latest+BI+Server
+Documentation
3. Ver Anexo licencias de Software
4. SDK or JRE 1.5:
http://java.sun.com/javase/downloads/index.jsp
5. Apache ant home: http://ant.apache.org
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Trabajando con Pentaho BI-Server
352
6. Tomcat home: http://ant.apache.org
7. Sitio de descargas MySQL:
http://dev.mysql.com/downloads/mysql/5.0.html#downloads
8.
8,0
8,1
Sitio de descargas Pentaho:
http://sourceforge.net/project/showfiles.php?group_id=140317
9. documentacin Action Sequence:
http://wiki.pentaho.org/display/PentahoDoc/Creating+Pentaho
+Solutions
10. Comenzando con Pentaho BI-Platform:
http://wiki.pentaho.org/display/PentahoDoc/Getting+Started+
with+the+BI+Platform
JasperServer
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
355
Introduccin
JasperServer es un framework construido sobre JasperReports.
JaspeSoft, inici el desarrollo de JasperServer luego de adquirir el
proyecto JasperReports, con la intencin de agregar valor a los
productos ofrecidos por la empresa. Este framework, ofrece una
interfaz de usuario Web, desde la cul se pueden, realizar tanto las
tareas administrativas (creacin usuarios, reportes y vistas analticas
OLAP) como as tambin, las tareas requeridas por usuarios tales
como, ejecucin de reportes, programacin peridica de ejecucin de
reportes e interaccin con vistas OLAP. Con JasperSoft naci el
concepto de Commercial Open Source.
Licencia
JasperServer es ofrecido en licencia dual:
Versin Open-Source: GPL no ofrece garanta ni soporte y las
prestaciones son limitadas.
Comercial: caractersticas avanzadas, soporte y garanta.
Versin utilizada
JasperServer Open-Source 2.1
Instalacin
La descarga de JasperServer, en su versin Open Source, puede
hacerse desde la seccin correspondiente en el sitio Web oficial
[1]
. El
instalador contiene todo lo necesario para la configuracin de
JasperServer:
1. Sistema de Gestin de Base de Datos Relacionales incluido
(MySQL).
2. Contenedor Servlet/JSP incluido (Apache Tomcat).
En el primero se almacenar todo lo relativo con el funcionamiento de
JasperServer, entre otras entidades que sern alojadas en la base de
datos se encuentran:
Descripciones sobre Fuentes de Datos: Conexiones JDBC,
Mondrian, XMLA, JNDI.
Informacin de usuarios y roles: segn el perfil de cada
usuario, se permitir el acceso limitado a reportes y vistas de
anlisis.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
356
Reportes y elementos requeridos por los mismos: archivos
JRXRML, consultas SQL o MDX y fuentes de datos que los
originarn.
Informacin de Scheduling de Reportes: informacin referente
a fechas y horarios, parmetros necesarios y frecuencia de
ejecucin programada de reportes.
Datos de vistas de anlisis: consulta MDX y fuente de datos
correspondiente a la vista de anlisis.
De esta manera, la base de datos de JasperServer centralizar el
alojamiento de los datos y parmetros de configuracin del servidor.
El contenedor Servlet/JSP ser necesario ya que la interfaz de
JasperServer es Web; desde la cual se realizarn, tanto las tareas
administrativas, como el uso por parte de usuarios finales.
Tareas Administrativas
Para acceder a la interfaz del Servidor, es necesario que los
servidores de base de datos y Servlet se encuentren corriendo.
JasperServer ofrece un script de control de ejecucin, con el cual se
puede iniciar/detener/reiniciar el servidor: Para iniciarlo, suponiendo
que la raz de la instalacin es JASPERSERVER_HOME:
$ $JASPERSERVER_HOME/jasperctl.sh start
Las opciones para detener y reiniciar el servicio son stop y restart
respectivamente.
Iniciado el servidor, puede ser accedido desde la URL:
http://host:XXXX/jasperserver donde:
host: es la direccin ip o nombre de la mquina que aloja al
servidor.
XXXX: el puerto en que se encuentra escuchando el servidor
Servlet, en este caso Tomcat.
jasperserver: el nombre que identifica la aplicacin
JasperServer
Al acceder a http://localhost:8081/jasperserver por ejemplo, se
queda en presencia de la pantalla de login cuyo aspecto es el
siguiente:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
357
JasperServer login
Para ingresar a la vista administracin, se debe acceder como
jasperadmin e ingresar el password que fue establecido durante la
instalacin, por defecto tambin es jasperadmin.
La vista del administrador presenta el siguiente aspecto:
Vista de Administrador
Men de opciones
La estructura del men es la siguiente:
Home: Describe JasperServer
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
358
View: Muestra metadatos, y permite ejecutar reportes del
repositorio. Los reportes que sern accesibles para el usuario,
son aquellos para los que se posee permisos de lectura sin
importar en que directorio se encuentran.
Manage: Accesible slo si se tiene privilegios de administrador.
Brinda acceso a la gestin del repositorio, usuarios y roles.
Logout: Cierra la sesin del usuario.
Gestin del repositorio
Un aspecto que caracteriza a JasperServer, es que su interfaz para
configuracin y uso es simple e intuitiva. Slo basta con tener en
claro, cual es el objetivo que se tiene a la hora de su configuracin,
los pasos para llevar a cabo las tareas son siempre similares, sin
importar cual sea la tarea en cuestin. Para ejemplificar, se realizar
la configuracin de un reporte y de una vista de anlisis.
Para llevar a cabo un reporte desde un cubo multidimensional o una
vista de anlisis es requisito previo contar con:
Un esquema mondrian (archivo .xml) y una fuente de datos
JDBC o una conexin XMLA.
[2]
El reporte de JasperReports en formato .jrxml
[3]
En este punto del trabajo, los requisitos anteriores han sido
completados en secciones precedentes. El reporte que ser
configurado en el servidor, es el desarrollado en la seccin iReport:
rdenes finalizadas por rubro en el ao X, dnde X representa
un parmetro del reporte. La configuracin debe ser bottom/up,
comenzando por las dependencias de nivel inferior hasta llegar a los
detalles del reporte en s. Ingresando al men Manage/Repository
se observa el siguiente detalle de contenidos:
Gestin del repositorio
Se puede apreciar que las herramientas de la UI brindan la facilidad
para llevar a cabo todas las tareas necesarias:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
359
Crear/Eliminar objetos
Asignar permisos a usuarios y roles
Editar las propiedades de los objetos
Entre los tipos de objetos que se pueden crear y gestionar se
encuentran:
Directorios contenedores de todos los objetos
Fuentes de Datos (JDBC,JNDI,JavaBean)
Reportes
Conexin OLAP (Mondrian)
Esquema OLAP (Mondrian)
Conexin XMLA
Archivo JRXML
Consultas SQL o MDX
Vista de anlisis
Creando un reporte OLAP
En el ejemplo, se utilizar una conexin OLAP Mondrian, con lo cual
ser necesario en primera instancia, configurar una conexin JDBC
como fuente de datos.
Creando una fuente de datos JDBC en el repositorio
Una buena prctica es mantener organizados los objetos en
directorios afines; en este caso, dentro de la gestin del repositorio,
se crear la conexin en el directorio analysis/datasources
seleccionando con la opcin add new Data Source. Se ilustra a
continuacin este proceder:
Nueva Fuente de Datos
Luego de presionar el botn Add new, se solicitar la seleccin del
tipo de fuente de datos. En este caso JDBC:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
360
Tipo de fuente de datos
Al presionar next, se debern configurar los datos para la conexin
JDBC:
JDBC DataSource
De forma opcional, puede corroborarse que la conexin es vlida con
test connection. Se procede con save para dejar configurada la
fuente de datos.
Creando un esquema Mondrian en el repositorio
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
361
De manera anloga, se crear en el repositorio el archivo xml
descriptor del esquema Mondrian. Para ello, dentro del directorio
analysis/schemas, se crea el nuevo objeto de tipo Olap Schema:
Nuevo Esquema OLAP
Luego de presionar Add new, ser necesario indicar el archivo .xml
que contiene el esquema Mondrian:
Archivo de Nuevo Esquema OLAP
Si todo funcion correctamente, se podr ver el nuevo esquema
creado en el repositorio:
Nuevo Esquema OLAP Creado
Con los requisitos de la fuente de datos y archivo de esquema
cubiertos, se proceder con la conexin OLAP en s misma:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
362
Creando una conexin OLAP Mondrian en el
repositorio
Conexin OLAP
Una vez seleccionado Add new, deber decidirse si ser una
conexin Mondrian o una XML/A:
Conexin OLAP - Seleccin de Tipo
Luego de seleccionar el tipo de conexin Mondrian, ser necesario
introducir informacin referente a la misma:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
363
Conexin OLAP Mondrian - Info
El paso posterior, ser indicar el recurso que representar el esquema
involucrado en la conexin Mondrian. En este caso, se usar el
recurso creado en el repositorio en pasos previos:
Conexin OLAP Mondrian - Esquema
Al continuar con el proceso, la pantalla siguiente, simplemente
indicar que se ha seleccionado satisfactoriamente el recurso
reutilizable desde el repositorio:
Conexin OLAP Mondrian - Esquema Desde El repositorio
El paso restante consiste en seleccionar la fuente de datos, que
tambin ha sido configurada y almacenada en el repositorio en pasos
previos:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
364
Conexin OLAP Mondrian - Fuente de datos
Si todo fue bien, al presionar next, la siguiente pantalla indicar que
la configuracin ha sido satisfactoria:
Conexin OLAP Mondrian Exitosa
Al presionar save, la configuracin para la conexin Mondrian
quedar almacenada en el repositorio, lista para ser utilizada:
Conexin OLAP Mondrian Lista
Creando un reporte Jasper en el repositorio
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
365
Con la conexin Mondrian, slo resta crear el reporte. Para esta
tarea, se crear una estructura de directorios dentro del directorio
reports del repositorio, de manera que el resultado sea el siguiente:
Reporte - Estructura de Directorios
El primer paso para empezar a crear el reporte, ser obtener el
archivo .jrxml y dejarlo almacenado en el repositorio para su uso:
Reporte - Nuevo archivo JRXML
Luego de presionar Add new, los pasos sern:
Subir el archivo:
Reporte - Seleccin archivo JRXML
Luego se deber ingresar informacin sobre el reporte inherente al
archivo JRXML subido:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
366
Reporte - Nuevo archivo JRXML Informacin
Luego de presionar save, se podr observar el archivo jrxml alojado
en el directorio correspondiente:
Reporte - Nuevo archivo JRXML Creado
El paso final, es crear el reporte de JasperSoft; la secuencia de pasos
consiste en:
Crear el nuevo reporte Jasper:
Reporte - Nuevo reporte Jasper
Seleccionar el JRXML correspondiente al reporte:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
367
Reporte - Seleccin de JRXML
Crear recursos y controles adicionales para el reporte.
Reporte - Lista de recursos y controles
En este reporte se crear un parmetro numrico o control de
entrada, el cul indicar el ao:
Reporte - Control de Entrada para ao
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
368
En el paso siguiente, se indicar tipo de dato y restricciones para el
valor de entrada
Reporte - Control de Entrada tipo de dato
Luego de salvar las propiedades del campo de entrada, la lista de
recursos y controles quedar como se observa a continuacin:
Reporte - Lista de recursos y controles actualizada
El ltimo paso ser establecer la fuente de datos. En este caso ser la
conexin Mondrian configurada previamente:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
369
Reporte - Data source
Finalmente, se presiona save para guardar el reporte. Los pasos
adicionales, no son aplicables ya que la sentencia MDX se encuentra
dentro del archivo JRXML, y no se desea personalizar la url relativa de
la ubicacin del reporte.
Creando de una vista de anlisis
Se crear una vista de anlisis para observar el comportamiento
(distribucin de rdenes realizadas) de los clientes durante los
diferente das de la semana: En el directorio analysis/views se crea
una nueva vista de anlisis (analysis view) cuya configuracin es la
siguiente:
Nombre:
Nombre de vista de anlisis
Fuente de datos, en este caso se utiliza la conexin Mondrian creada
para el reporte:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
370
Fuente de datos para la vista anlisis
Consulta MDX:
MDX para la vista de anlisis
El ltimo paso consistir en validar la sentencia MDX contra la
conexin fuente de datos:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
371
Validacin MDX para la vista de anlisis
Acceso a reportes y vistas de anlisis
Se ingresar como un usuario sin privilegios de administrador, con lo
que slo se podr tener acceso a la utilizacin de reportes y no a su
modificacin.
Acceso a un reporte
Dentro de la vista del repositorio/reportes/gonReports se selecciona
la ejecucin del reporte OrdenesPorRubroAnioX:
Ejecucin del reporte
Una vez ejecutado, ser solicitado el ingreso de un valor para el
campo de control anio, que representar el perodo anual sobre el
cual se elaborar el informe:
Input del reporte
Seleccionado una ao correcto [2006-2007], la salida generada por el
servidor ser:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
372
Output del reporte
Por ltimo, es posible observar el reporte en diferentes formatos. A
continuacin se observa la visualizacin dentro de Firefox en formato
PDF:
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
373
Output en PDF del reporte
Acceso a una vista de anlisis
Dentro del directorio del repositorio analysis/views, se accede a la
vista creada, Weekdays Orders:
Acceso a la vista Weekdays Orders
Dentro de la vista, se encuentran las herramientas brindadas por
JPivot para realizar todas las tareas propias de un query manager
[4]
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
JasperServer
374
Aspecto de JPivot dentro de JasperAnalysis
Referencias y recursos
1. JasperServer y JasperAnalysis en JasperForge:
http://jasperforge.org/sf/projects/jasperserver
2. Ver seccin trabajando con Mondrian
3. Ver la secciones referentes a JasperServer e iReport
4. Ver El captulo Conceptos de Inteligencia de Negocio, seccin
Arquitectura del Data Warehouse-Query Manager
Comparativa Pentaho BI-Server
JasperServer
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Pentaho BI-Server JasperServer
377
JasperServer Pentaho BI Platform
Licencia GPL. Pentaho Public License
Instalacin
Incluye un instalador que
automatiza la instalacin,
despliegue de
JasperServer en un
contenedor Servlet.
Tambin facilita la
inicializacin de la base
de datos subyacente.
Incluye un instalador que
automatiza la instalacin,
despliegue de la
aplicacin en un servidor
de aplicaciones. Tambin
facilita la inicializacin de
la base de datos
subyacente (menos
flexible). Otra opcin es
obtener el cdigo fuente
y construir el archivo
.war para luego realizar
el despliegue en el
servidor (a eleccin) y
configuracin de la base
de datos de forma
manual (Mtodo utilizado
en la gua. Mas flexible).
Servidor JEE
incluido
Apache Tomcat
JBoss. Puede utilizarse
otro servidor de
aplicaciones o contenedor
Servlet compatible con
JEE. En la gua se realiza
la configuracin con
Tomcat
SGBDR
incluido
MySQL
MySQL o HSQLDB,
pueden utilizarse otros
motores de bases de
datos
Configuracin
La configuracin se
realiza completamente
desde al interfaz Web
ofrecida. La configuracin
incluye:
Usuarios/Roles.
Reportes.
Fuentes de datos
JDBC, JNDI,
JavaBean,
Mondrian o XMLA.
Vistas de anlisis.
La configuracin se
realiza casi en su
totalidad manualmente,
sin ayuda de la interfaz
Web ofrecida. La
configuracin manual
incluye:
Usuarios/Roles.
Reportes.
Fuentes de datos.
Vistas de anlisis.
Planificacin de
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Pentaho BI-Server JasperServer
378
Permisos
Ejecucin de
reportes
Planificacin de
ejecucin de
reportes
ejecucin de
reportes.
Creacin de
dashboards.
Gestin del
repositorio de
soluciones.
La configuracin grfica
incluye
Permisos.
Creacin de
reportes Adhoc.
Gestin de
objetos del
sistema
Ofrece un repositorio en
cual se pueden organizar
los elementos (fuentes de
datos, reportes, vistas de
anlisis y archivos)
mediante directorios.
Ofrece un repositorio en
cual se pueden organizar
los elementos (reportes,
vistas de anlisis,
archivos y action
sequence) mediante
directorios (sistema de
archivos). Tambin
permite realizar el
mantenimiento del
repositorio a travs de
una base de datos.
Analysis Olap
Las vistas de anlisis
creadas (mediante
consultas MDX) son
ejecutadas y visualizadas
por el componente JPivot
embebido en
JasperServer. A esta
funcionalidad en su
conjunto se la denomina
JasperAnalysis.
Las vistas de anlisis
creadas (mediante
consultas MDX) son
ejecutadas y visualizadas
por el componente JPivot
embebido en la
plataforma BI de
Pentaho. A esta
funcionalidad en su
conjunto se la denomina
Pentaho Analysis.
Gestin de
usuario, roles
y permisos
Su configuracin, al igual
que lo dems objetos del
sistema, se realiza desde
la interfaz web.
La gestin de usuarios y
roles se realiza
manualmente mediante
archivos o una base de
datos. Los permisos
pueden gestionarse
desde la interfaz web si
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Comparativa Pentaho BI-Server JasperServer
379
se utiliza un repositorio
gestionado por una base
de datos.
Ejecucin y
planificacin
de reportes
Desde la interfaz Web, un
usuario planifica los
reportes a ejecutar, junto
a la frecuencia de
ejecucin. Se ofrece la
posibilidad de notificacin
va correo electrnico, el
cul puede incluir como
archivos adjuntos los
reportes creados, que a
su vez permanecern
almacenados en un
directorio del repositorio
JasperServer.
Pueden ejecutarse los
reportes online o dejar
que corran en
background (esto se
realiza desde la interfaz
web). Se puede planificar
la ejecucin de ciertos
reportes para
determinados usuarios
mediante configuraciones
manuales (en futuras
versiones, Pentaho
prevee agregar una
utilidad grfica a la
aplicacin para realizar
las planificaciones).
Conclusin BI Platforms
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin Plataformas de Inteligencia de Negocios
383
Una vez que los reportes y anlisis OLAP han sido creados, slo resta
distribuirlos para que puedan ser accedidos por los usuarios
indicados. Es para este fin que fueron creados los portales de
Inteligencia de Negocios JasperServer y Pentaho BI Platform.
Con las versiones de licencia Open Source, las prestaciones de estos
dos servidores contrastan en cuanto a sus prestaciones y facilidad de
uso. Mientras que JasperServer reserva la funcionalidad de
reporting Ad-Hoc para su versin profesional, Pentaho BI Platform
la incluye; lo que JasperServer simplifica en configuracin y uso para
el administrador y los usuarios mediante su UI Web, en Pentaho BI
Platform resultan ser pasos complejos y que requieren mayor
conocimiento de sintaxis especfica (por ejemplo una tarea cron) o de
estructuras de archivos de configuracin (se encuentran definidos
requerimientos para extender la funcionalidad de los asistentes
grficos de Pentaho, esto minimizar las actuales configuraciones
manuales). Otra diferencia importante entre ambas herramientas, es
que la versin de JasperServer con licencia Open Source, no ofrece la
posibilidad de crear tableros de control (Dashboards) a diferencia de
la versin Open Source de Pentaho que si lo permite.
Al igual que en los captulos anteriores, se ofrece a continuacin una
tabla calificativa de las principales caractersticas de estos dos
productos:
JasperServer Pentaho BI Platform
Funcionalidad 3
[1]
5
Usabilidad 5
[2]
3
[3]
Flexibilidad 5
[4]
5
[5]
Interoperabilidad 3
[6]
5
[7]
Fiabilidad 5
[8]
4
[9]
Eficiencia 4
[10]
4
[11]
Documentacin 5
[12]
3
[13]
Calificacin promedio 4.2 4.2
1. La versin Open Source no incluye Reporting Ad-Hoc ni
dashboards.
2. Tanto las tareas administrativas como el acceso del usuario
final se realizan desde la Interfaz Web.
3. La herramienta es fcil de usar e intuitiva. Ciertas tareas no
pueden realizarse mediante asistentes, por lo que deben
realizarse manualmente con el conocimiento que esto involucra.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin Plataformas de Inteligencia de Negocios
384
4. Si bien JasperServer incluye Apache Tomcat, puede llevarse
a cabo el despliegue del portal Web con contenedor Servlet, no
as el SGBD. Adems es posible localizar la interfaz de
JasperServer.
5. Pueden realizarse distintas configuraciones para adaptar el
servidor a las necesidades del usuario (ej cambiar: motor de
BD, servidor de aplicaciones, gestin de usuarios, gestin del
repositorio de soluciones, etc).
6. Slo pueden utilizarse reportes JasperReports. Cmo punto
fuerte, JasperServer posee una arquitectura orientada a
servicios, que ofrece los siguientes servicios Web:
o El del repositorio, permite explorar y modificar los
elementos del repositorio.
o El del scheduler, permite programar ejecuciones de
reportes, y ver los trabajos pendientes y as como
tambin eliminarlos.
7. Permite utilizar otras tecnologas de reporting no
pertenecientes a Pentaho, como JasperReports y Birt.
8. No se han evidenciado problemas al realizar las tareas
incluidas en el presente trabajo
9. Ocurrieron algunos errores al utilizar el servidor por un
tiempo prolongado realizando modificaciones en la
configuracin
10. Segn que servidor de aplicaciones, sern los recursos
que utilice la plataforma.
11. Segn que servidor de aplicaciones y motor de BD se
utilice, sern los recursos que utilice la plataforma.
12. Incluye una serie de guas detalladas:
o Instalacin
o De usuario
o Para configurar JasperServer con JBoss
o De los servicios web ofrecidos
o De localizacin de JasperServer
13. Existe documentacin online y foros. No es fcil
navegar por la documentacin y muchas veces se encuentra
desactualizada o incompleta.
Tercera Parte: Anexos
Anexo I : Licencias De Software
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo I Licencias de FLOSS
389
Las licencias de software representan el contrato entre el
publicador de software y el usuario final. Una licencia de
software permite al usuario utilizar una o mas copias del software;
sin este contrato, tal uso estara prohibido por la ley. Una licencia de
software representa la garanta de que el publicador de software no
demandar por el uso del producto al usuario, ya que este se
encuentra bajo la proteccin de la ley de propiedad intelectual, ms
precisamente la de derecho de autor. A menos que el software
desarrollado sea de uso exclusivo de su creador, es necesario
elaborar una licencia que indique las condiciones de uso.
Clasificacin de licencias de software
Desde el punto de vista de libertades y restricciones impuestas al
usuario final se puede clasificar las licencias de software en Licencias
Propietarias y Licencias Libres o de Cdigo Abierto.
Licencias Propietarias
La aceptacin de este tipo de licencias implica que el usuario final
slo ser titular de una licencia para el uso de la copia de software,
permaneciendo en todo momento la pertenencia de la misma al
poseedor de los derechos de autor. Estas son conocidas como End
User Licence Agreement. Un ejemplo caracterstico de este tipo de
licencia es la de Microsoft Windows
[1]
.
Libertades
o Uso del software en su formato de producto final, es
decir ejecucin del cdigo objeto (formato binario).
Restricciones
o No se tiene acceso al cdigo fuente
o No se puede distribuir el producto, slo usarlo.
o Es caracterstico de este tipo de licencias la inclusin de
una serie de trminos bajo los cuales se puede hacer uso
del software, por ejemplo impidiendo usos para tomar
mediciones de perfomance, uso simultaneo de varios
usuarios, etc.
El termino propietario ha sido acuado por el hecho de que el dueo
de la copia de software contina siendo en todo momento el
creador/publicador o autor del software.
Licencias Libres (de cdigo abierto)
Con este tipo de licencias, el propietario de la copia de software es
el usuario final. De esta forma se le garantizan los derechos
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo I Licencias de FLOSS
390
brindados por la ley de derechos de autor al dueo de la copia. Vale
aclarar que el titular de derechos de autor del software contina
siendo quien lo publica. En estas licencias por lo general se brinda
una serie de derechos adicionales que de otra forma estaran slo
reservados para quin publica el software. De esta forma no es
necesario que el usuario final acepte la licencia antes de usar la copia
de software. En algunas licencias particulares, para ejercer algunos
otros derechos, como por ejemplo redistribuir copias, se deber
aceptar licencia en cuestin.
Libertades
o Uso del software y distribucin
o Acceso al cdigo fuente
o Permisos de modificacin del cdigo segn las
necesidades
o Permisos para la distribucin del cdigo con los cambios
que se hayan realizado
Restricciones
o Las restricciones varan de acuerdo a la licencia
especfica. En las prximas secciones se analizaran en
detalle las principales licencias libres.
Licencias FLOSS
A pesar del fin comn de las licencias libres, crear grandes
repositorios de software que puedan ser combinados para producir
nuevo software, han emergido diferentes movimientos cuyas
filosofas difieren y en consecuencias las libertades y restricciones que
ofrecen, no son idnticas. De forma amplia, las licencias libres
pueden ser agrupadas segn dos categoras: Copyleft y Licencias
permisivas.
Antes de entrar en detalle de estas categorizaciones, es importante
tener una nocin de lo que significa que algo pertenece al dominio
pblico.
Dominio publico: El software de dominio publico no posee
restriccin alguna, no existe nadie que pueda reclamar derecho de
autor. La voluntad de liberar cdigo al dominio publico debe ser
explicita por parte del autor; tambin se considerar de dominio
pblico todo cdigo despus de los 70 aos de la muerte del ltimo
de sus autores (este perodo puede variar segn la jurisdiccin de
aplicacin).
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo I Licencias de FLOSS
391
Licencias de software permisivas
Son licencias de software libre para un trabajo con derechos de autor
que ofrecen casi las mismas libertades que liberar el trabajo a
dominio publico. Este tipo de licencias garantiza la libertad de accin
con el cdigo fuente para los usuarios de la primera generacin del
software implicado; estas permiten a los receptores publicar
versiones modificadas bajos licencias ms restrictivas (las cuales
incluyen licencias propietarias y de copyleft).
Copyleft
Es un juego de palabras sobre copyright (o derecho de autor) y
consiste en el uso de la ley de derecho de autor pero permitiendo la
libre distribucin y modificacin del trabajo exigiendo que las mismas
libertades sean preservadas en las versiones modificadas. Es una
forma de licenciamiento y puede ser usada para modificar los
derechos de autor para programas de computacin y otros productos.
En general, la ley de de derecho de autor permite al autor prohibir a
otros la reproduccin, adaptacin o distribucin de copias del trabajo.
En contraste, mediante un esquema de copyleft un autor puede
brindar a cada persona que recibe una copia, permisos para
reproducir, adaptar o distribuir el trabajo siempre y cuando las copias
resultantes o adaptaciones permanezcan sujetas al mismo esquema
de copyleft. Se pueden ver tambin como un esquema de
copyright en el cual el autor renuncia algunos, pero no todos los
derechos. En vez de liberar el cdigo al dominio publico, en donde no
rige ningn derecho de autor, copyleft permite a un autor imponer
algunas restricciones de copyright para permitir realizar actividades
que de otra manera perpetraran violacin de derechos de autor.
Copyleft fuerte (Strong copyleft)
En estos esquemas se respeta todo lo anterior descrito. Se asegura
que las derivaciones del trabajo original sean liberadas bajo el mismo
criterio.
Copyleft dbil (Weak copyleft)
Representa un gris entre licencias permisivas y de copyleft fuerte.
Permiten cambiar la licencia por otra ms restrictivas slo bajo
ciertas circunstancias.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo I Licencias de FLOSS
392
Licencias BI-FLOSS
En esta seccin se mostrar una tabla con las licencias que presenta
el software utilizado para el presente trabajo:
Copyleft Permisiva
General Public License Strong
Mozilla Public License X
Pentaho Public License (Idntica a MPL) X
Lesser General Public License Weak
Referencias y recursos
1. http://www.microsoft.com/windowsxp/home/eula.mspx
Anexo II: Data generator (Carga
inicial de datos OLTP)
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo II Carga Inicial de Datos
395
Cada uno de los pasos involucrados en este proyecto asume la
existencia de una fuente primaria de datos OLTP. Sin esta fuente, los
procesos ETL sern solo diagramas conceptuales, los cubos OLAP no
podrn ser consultados mediante MDX, y slo podrn producirse
reportes vacos. Peor an, puede que todo lo anteriormente
mencionado haya sido creado de forma errnea y no ser detectado
hasta el momento de efectuar pruebas con los datos generados.
Como es sabido, GON representa un sistema conceptual que no
existe ni opera en realidad. BI-FLOSS se apoya en la fuente
potencial de datos que representa GON, y es por ello que es preciso
crear datos operacionales ficticios. Se puede realizar una
categorizacin de las entidades necesarias a crear para la carga de
datos:
1. Aquellas que representan personas u objetos con nombres
propios. (Usuarios, Ubicaciones Geogrfica, Productos, Marcas,
etc).
2. Datos provenientes de transacciones, esto es ventas u rdenes
de compra.
Data Generator
GenerateData.com
Para las primeras, es suficiente con generar scripts con ciclos para
obtener la cantidad de entidades deseadas. Los nombres de las
entidades seran al estilo de Ciudad 1, Ciudad 2, etc. Una opcin ms
atractiva sera obtener una buena base de datos con entidades
comunes, o mejor an una aplicacin que utilice esa base de datos
para generar datos con la estructura deseada. GenerateData
[1]
es
un aplicacin web (php+mysql) gratis y Open Source que realiza
esta tarea. Es posible descargarse GenerateData y realizar el deploy
en un servidor web que soporte PHP o puede usarse el generador en
lnea.
Se observa a continuacin la configuracin para generar datos de la
tabla place, en este caso ciudades de Estados Unidos
(id=11=owner_id)
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo II Carga Inicial de Datos
396
Interfaz del generador de Datos
Los datos obtenidos en sql para mysql:
Datos Generados
Al estar trabajando con una base de datos Postgresql, es necesario
eliminar las comillas simples del nombre de la tabla. Para pocas
sentencias, puede ser sencillo quitarlas a mano, pero si se est
generando un volumen grande de datos resultar engorroso; puede
usarse el script mostrado a continuacin para tal fin:
Cdigo: mysql to postgres script
#!/bin/sh
TABLE=$2
SOURCE=$1
sed s/\'"$TABLE"\'/"$TABLE"/ "$SOURCE" > "$SOURCE.postgres.sql"
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo II Carga Inicial de Datos
397
Se debe ejecutar el script brindando como argumento el nombre del
archivo original y el nombre de la tabla. Suponiendo que el script fue
almacenado con el nombre mysql2postgres.sh, y las sentencias
residen en un archivo us_cities.sql se debe invocar del siguiente
modo:
$ mysql2postgres.sh us_cities.sql place
Lo que dar como resultado un nuevo archivo
us_cities.sql.postgre.sql con las sentencias adecuadas.
GONDataGenerator
Una vez que ya se tiene datos de las entidades principales, resta
crear:
Productos en Negocios y Sucursales
rdenes de compra
Para esto y algunas cuestiones adicionales se desarroll
GONDataGenerator, un programa Java para completar la base de
datos de acuerdo a cierto parmetros pre establecidos. Situados en la
raz del proyecto GONJPA, se debe ejecutar de la siguiente forma:
$ java -cp lib/postgresql-8.0-319.jdbc3.jar:bin
gonjpa.datagenerator.GONDataGenerator
El comando anterior dar la siguiente salida:
Cdigo: Salida de GONDataGenerator sin argumentos
Modo de uso : gonjpa.datagenerator.GONDataGenerator dbstatus |
diversificate | businessProducts <max per business> | branchProducts | orders
<max per client> <max entries per order> [<date info>]| clients |
usersRegistrations | clean
Las opciones que el programa acepta son:
initialLoad: con este opcin se cargarn datos de tablas que
son ledas desde archivos .sql. Entre otras entidades sern
cargadas aquellas referentes a zonas geogrficas, direcciones
postales, datos personales de usuarios, datos de sucursales y
de productos y marcas. Este comando es til cuando la base de
datos ha sido recin creada (con las tablas correspondientes);
luego de la creacin de las entidades se ejecutar
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo II Carga Inicial de Datos
398
automticamente fillUserRegistration, clients y
diversificate, con lo cul, slo restar crear los productos de
negocios (ver comando businessProducts) y sucursales (ver
comando branchProducts) y generar las rdenes (ver
comando orders).
dbstatus: Resumen de las principales entidades del sistema.
Cdigo: Salida de ejemplo dbstatus
Clientes: 799
Negocios: 100
Sucursales: 251
Ordenes: 28535
Productos de negocios: 241
Productos de sucursales: 602
diversificate: Con una probabilidad del 50 %, asigna o no a
cada negocio un nuevo rubro en el cul no estaba registrado
anteriormente.
businessProducts: Asigna a los negocios, productos ofrecidos
acorde los rubros en los que se encuentra registrado. El
parmetro max per business indica cuantos productos, cmo
mximo, ofrecer un negocio.
brancProducts: Una vez que los productos de negocios han
sido creados, se debe ejecutar este comando para crear
productos en las sucursales.
clients: Crea un rol cliente para cada usuario gon registrado.
Es til si se han creado los usuarios con GenerateData por
ejemplo.
usersRegistrations: Crea una entrada de registracin de
usuario, junto a la fecha de alta, para cada usuario gon.
Utilizado en situaciones similares al comando clients.
clean: Efecta la eliminacin de rdenes, entrada de rdenes,
calificacin de rdenes, productos de sucursales y negocios.
orders <max per client> <max entries per order> [<date
info>]: genera rdenes de compra entre Clientes y Sucursales.
Debe especificarse cuantas rdenes se generar como lo
mximo por cliente, y cuantas entradas cmo mximo, puede
presentar una orden. De forma opcional, puede brindarse
informacin adicional sobre el perodo de generacin de
rdenes. date info presenta el siguiente formato:
"yFrom=yyyy:yTo=yyyy:mFrom=mm:mTo=mm" dnde
yFrom y yTo representan el rango de aos en los que las
rdenes sern generadas. Por defecto yFrom=2002 e
yTo=2007.
mFrom y mTo representan el rango de meses en los que las
rdenes sern generadas. Por defecto mFrom=0 e yTo=11.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo II Carga Inicial de Datos
399
Dado que n = yTo - yFrom e i es un ao en el rango
[yFrom=1,yTo=n] La probabilidad p de que una orden sea generada
el ao i es:
Expresin: Probabilidad p de crear una orden en un ao i
Donde:
Expresin: Sumatoria de n
Lo anterior es para no obtener datos temporales homogneos, lo que
permitir observar variaciones en el nmero de rdenes para
diferentes aos.
Referencias y recursos
1. Sitio Oficial de GenerateData: http://www.generatedata.com
Anexo III: Contenido del DVD BI-
FLOSS
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Anexo III Contenido del DVD BIFLOSS
403
Todo el software utilizado y generado a lo largo del desarrollo de
BIFLOSS es entregado en un DVD. El DVD posee la siguiente
estructura:
-- BIFLOSS
|-- DataGenerator -> Software para crear datos OLTP de GON
|-- GON -> Sistema GON
|-- JasperSoft -> Software provisto por JasperSoft
|-- Pentaho -> Software provisto por Pentaho
`-- Software Extra -> SW BI-FLOSS que por razones de alcance no se
ha utilizado en el desarrollo llevado a cabo.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Viabilidad Comercial
405
Viabilidad Comercial
Este desarrollo no pretende obtener ningn beneficio comercial, ya
que se trata principalmente de una comparacin de dos herramientas
open source de B.I. Si podemos identificar como oportunidad para
que este desarrollo tenga xito, la poca documentacin existente
(principalmente en espaol) sobre estas herramientas. Simplemente
se espera generar documentacin sobre las herramientas que sirva
de utilidad a otras personas interesadas en este tipo de tecnologas.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin BI-FLOSS
407
Conclusin BI-FLOSS
Finalizado el desarrollo y documentacin de BI-FLOSS, se obtuvo
una visin general del espectro de aplicaciones de Inteligencia de
Negocios ofrecidas por proyectos Open Source. De forma particular,
fueron aplicadas las herramientas de Pentaho Project y JasperSoft
con las cuales se llev a cabo la construccin de un Data Warehouse,
un modelo OLAP, reportes y anlisis basados en el sistema de
rdenes de Gua Online de Negocios. Con esto como premisa, es
factible sintetizar la experiencia adquirida en una serie de
conclusiones:
Respecto a las Herramientas BI-FLOSS en
General
1. Un proyecto de Inteligencia de Negocios puede ser llevado a
cabo de manera efectiva, desde el modelado conceptual hasta
el anlisis de datos, con herramientas libres.
2. Las herramientas Open Source soportan y fomentan
estndares, mientras que el software propietario ofrece su
funcionalidad de manera programtica a travs de APIs
propietarias. Esto repercute de manera directa en la
flexibilidad e interoperabilidad.
3. Los errores que presentan las herramientas utilizadas, no son
producto de su naturaleza Open Source, ya que la experiencia
seala errores similares en Software propietario; Los problemas
con herramientas Open Source pueden solucionarse con mayor
velocidad, ya sea por correccin directa por parte del usuario, o
bien enviando una notificacin a la comunidad dedicada al
desarrollo y mantenimiento.
Respecto a las Herramientas Pentaho y
JasperSoft
1. Existen algunas diferencias en cuanto a flexibilidad y
funcionalidad
2. De forma general, las herramientas de JasperSoft ofrecen al
usuario mayor facilidad en el uso de sus interfaces grficas.
3. En los productos que aaden el mximo valor a la suites
(JasperServer, Pentaho BI Platform), JasperSoft opta por
reservar funcionalidad para la versin Professional,
contrariamente a Pentaho. Esta diferencia puede incidir en la
eleccin final, al menos en esta etapa del proyecto.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Conclusin BI-FLOSS
408
4. No es necesario utilizar las herramientas de un mismo proyecto
para todas las etapas, por el contrario es posible elegir la mejor
alternativa de acuerdo a sus prestaciones.
5. Ambos proyectos son relativamente jvenes, esto produce que
ciertas funcionalidades no operen como debieran, ya sea
porque no han sido probadas adecuadamente o su desarrollo
an no ha finalizado. A pesar de ello puede llevarse a cabo una
solucin BI que satisfaga las necesidades de los usuarios.
Respecto a las licencias y las estrategias
1. Las licencias que presentan las herramientas pueden influir en
la decisin, de acuerdo a la estrategia y necesidades del grupo
de desarrollo. Los proyectos Open Source Comerciales, como lo
son JasperSoft y Pentaho, ofrecen licencias duales, lo cual
permite tomar una decisin apropiada para cada caso
particular:
La eleccin de licencias Open Source brindara al usuario las
mismas libertades (y obligaciones, en caso de existir) del
mismo modo que cualquier proyecto Open Source
tradicional.
Aquellos usuarios que no estn dispuestos a tolerar las
obligaciones impuestas por licencias Open Source, desean
obtener funcionalidades adicionales, o simplemente
requieren de soporte oficial, pueden adquirir licencias (o
realizar suscripciones, en el caso de Pentaho) comerciales.
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Bibliografa
409
Bibliografa
Definicin de Business Intelligence:
http://www.ibermatica.com/ibermatica/businessintelligence2
DATA WAREHOUSING: Investigacin y Sistematizacin de Conceptos
HEFESTO: Metodologa propia para la Construccin de un Data
Warehouse Ing. Bernabeu, Ricardo Daro -Instituto Universitario
Aeronutico - Noviembre de 2007
API Java 5.0
http://java.sun.com/j2se/1.5.5/docs/api
Spoon User Guide 3.0.0
Pan User Guide 2.5
Kitchen User Guide 2.5
Talend Open Studio User's Guide Versin 2.2_b
Mondrian 2.2.2
Technical Guide
Artculo de MDX en Wikipedia:
http://en.wikipedia.org/wiki/MDX
Documentacin de Pentaho Metadata Editor:
http://wiki.pentaho.org/display/studio/Pentaho+Metadata
+Editor
Documentacin de reportes de Pentaho:
http://wiki.pentaho.org/display/Reporting/Pentaho+Reporting
+Latest
Documentacin de Action Sequence:
http://wiki.pentaho.org/display/PentahoDoc/03.+Action
+Sequences
Documentacin de Pentaho Design Studio:
http://wiki.pentaho.org/display/studio/Getting+Started+with
+Design+Studio
The Definitive Guide to JasperReports
The Definitive Guide to iReport
IUA - Facultad de Ingeniera - Proyectoto de Grado: BIFLOSS
Bibliografa
410
Documentacin oficial Pentaho BI-Server:
http://wiki.pentaho.org/display/PentahoDoc/Latest+BI+Server
+Documentation
documentacin Action Sequence:
http://wiki.pentaho.org/display/PentahoDoc/Creating+Pentaho
+Solutions
Comenzando con Pentaho BI-Platform:
http://wiki.pentaho.org/display/PentahoDoc/Getting+Started
+with+the+BI+Platform
JasperServer Open Source Installation Guide
Version 2.1
JasperServer User's Guide
Version 2.1
JasperServer Web Services Guide
Version 2.1
Artculo de licencias FLOSS en Wikipedia:
http://en.wikipedia.org/wiki/Open_source_license
Artculo de copyleft en wikipedia:
http://en.wikipedia.org/wiki/Copyleft
S-ar putea să vă placă și
- Conceptos Básicos de Bases de DatosDocument9 paginiConceptos Básicos de Bases de DatossonyÎncă nu există evaluări
- Estudio Comparativo de Las Herramientas de Business IntelligenceDocument12 paginiEstudio Comparativo de Las Herramientas de Business Intelligencechechix3Încă nu există evaluări
- Exámenes Redes CorregidosDocument88 paginiExámenes Redes CorregidosAntonioVizcainoÎncă nu există evaluări
- Libro Visual Basic I I Version or Od CLCDocument695 paginiLibro Visual Basic I I Version or Od CLCNavas EmaÎncă nu există evaluări
- Manual de Pentaho Etl TransformacionDocument22 paginiManual de Pentaho Etl TransformacionJosue Sanchez MuentesÎncă nu există evaluări
- InformixDocument56 paginiInformixJose PerezÎncă nu există evaluări
- Inteligencia de Negocios - Data WarehouseDocument7 paginiInteligencia de Negocios - Data WarehouseAhias PortilloÎncă nu există evaluări
- Desarrollador Web Profesional XMLDocument141 paginiDesarrollador Web Profesional XMLAlberto Jimenez PalaciosÎncă nu există evaluări
- Microsoft InfoPath 2010 - Guía Del ProductoDocument33 paginiMicrosoft InfoPath 2010 - Guía Del ProductoHans Canales50% (2)
- Base de Datos ModuloDocument103 paginiBase de Datos ModuloJei CabÎncă nu există evaluări
- Sistemas de Bases de DatosDocument696 paginiSistemas de Bases de DatosIván Almada100% (3)
- TI-ETL-Lineamientos de UsoDocument43 paginiTI-ETL-Lineamientos de UsoIvan BarreraÎncă nu există evaluări
- Backup and Restore en SQL Server 2008 Express EditionDocument18 paginiBackup and Restore en SQL Server 2008 Express EditionMario Ramon Castellanos AranaÎncă nu există evaluări
- Consultas Útiles OracleDocument15 paginiConsultas Útiles OracleniehorlaÎncă nu există evaluări
- Desarrollo Web Con PHP - Oscar CapuñayDocument328 paginiDesarrollo Web Con PHP - Oscar CapuñayJunior Contrera AtocheÎncă nu există evaluări
- Guía para La Optimización de ConsultasDocument49 paginiGuía para La Optimización de ConsultasubaperezÎncă nu există evaluări
- Análisis y Diseño de Un Producto de SoftwareDocument29 paginiAnálisis y Diseño de Un Producto de SoftwareDavid Andrés Gómez ZamoraÎncă nu există evaluări
- MICROSOFT Documentación de Seguridad de Windows ServerDocument410 paginiMICROSOFT Documentación de Seguridad de Windows ServerStayÎncă nu există evaluări
- Consultas Utiles ORACLEDocument7 paginiConsultas Utiles ORACLEniehorlaÎncă nu există evaluări
- Demo InfoPath 2007Document16 paginiDemo InfoPath 2007anon-17730333% (3)
- Uso de Funciones SQL de GrupoDocument24 paginiUso de Funciones SQL de GrupoPato Esteban BecerraÎncă nu există evaluări
- Temas Completo PooDocument351 paginiTemas Completo PooEdgar BarahonaÎncă nu există evaluări
- Guia Windows Server 2012Document40 paginiGuia Windows Server 2012drerthÎncă nu există evaluări
- Ingmmurillo - Business Intelligence y Data Warehousing Con PentahoDocument120 paginiIngmmurillo - Business Intelligence y Data Warehousing Con PentahoByron Boada100% (2)
- Práctica #01Document10 paginiPráctica #01oscar eduardoÎncă nu există evaluări
- Jaspersoft AnálisisDocument10 paginiJaspersoft AnálisisLixbeth ChanÎncă nu există evaluări
- RMANDocument13 paginiRMANroduk01Încă nu există evaluări
- Manual Completo Oracle Español Spanish by SilexDocument162 paginiManual Completo Oracle Español Spanish by Silexcarlos84Încă nu există evaluări
- 2 - Diseño de Bases de DatosDocument4 pagini2 - Diseño de Bases de DatosProfesor PalmaactivaÎncă nu există evaluări
- Especialización en Query y MDocument7 paginiEspecialización en Query y MOscar Alberto QuinteroÎncă nu există evaluări
- LECCION 1 SSIS Tutorial - By: Alva Acosta Hardy AndyDocument85 paginiLECCION 1 SSIS Tutorial - By: Alva Acosta Hardy AndyAndy Alva AcostaÎncă nu există evaluări
- Clase 3 Data WarehouseDocument30 paginiClase 3 Data WarehousePalaloFPVÎncă nu există evaluări
- Construccíon de Un Datamart Orientado A Las Ventas para La Toma de Decisiones en La Empresa Amevet CIA. Ltda.Document47 paginiConstruccíon de Un Datamart Orientado A Las Ventas para La Toma de Decisiones en La Empresa Amevet CIA. Ltda.Alain David FloresÎncă nu există evaluări
- IBM WebSphere Application ServerDocument8 paginiIBM WebSphere Application ServerBtoTcoÎncă nu există evaluări
- TT Cubos de Información OLAPDocument122 paginiTT Cubos de Información OLAPSergio LandinÎncă nu există evaluări
- Etl. M1 PDFDocument32 paginiEtl. M1 PDFFJ GRÎncă nu există evaluări
- Informe Sistema de Compra y Venta Arquitectura 3 Capas Con HibernateDocument32 paginiInforme Sistema de Compra y Venta Arquitectura 3 Capas Con HibernateAlberto Baigorria100% (1)
- Ejercicios FBD - Datawarehouse PDFDocument65 paginiEjercicios FBD - Datawarehouse PDFTomas HermanÎncă nu există evaluări
- Proyecto de Base de Datos FinalDocument7 paginiProyecto de Base de Datos FinalKarsten Alexis Olivares ValenciaÎncă nu există evaluări
- Subconsultas en El Lenguaje SQLDocument9 paginiSubconsultas en El Lenguaje SQLDianitaPrincesÎncă nu există evaluări
- Diseño de Bases de Datos Relacionales PDFDocument0 paginiDiseño de Bases de Datos Relacionales PDFmwandroid54Încă nu există evaluări
- Interesante ERPDocument128 paginiInteresante ERPsadoly7224Încă nu există evaluări
- Informe DolibarrDocument13 paginiInforme DolibarrFernando PonceÎncă nu există evaluări
- Programación en .Net (Avanzado) - Manual WPF - V - DIGITALDocument137 paginiProgramación en .Net (Avanzado) - Manual WPF - V - DIGITALsoyhyoÎncă nu există evaluări
- Diccionario de DatosDocument42 paginiDiccionario de DatosCarmen GarcíaÎncă nu există evaluări
- Lista de Acrónimos de Oracle DatabaseDocument15 paginiLista de Acrónimos de Oracle DatabaseDomenico Ferraguto PlazaÎncă nu există evaluări
- Diseño de Un Sistema de VentasDocument6 paginiDiseño de Un Sistema de VentasGuadalupe Maganda100% (1)
- Manual para Crear Una Base de Datos en SQL Server 2008Document11 paginiManual para Crear Una Base de Datos en SQL Server 2008Lay Qr67% (3)
- Dousdebes Abraham Jose Gabriel. Marco de Trabajo para El DesarrolloDocument120 paginiDousdebes Abraham Jose Gabriel. Marco de Trabajo para El DesarrolloEmmanuel VRÎncă nu există evaluări
- Evaluacion de Capacidad de Procesos Con Cobit 5 Goierno de TiDocument93 paginiEvaluacion de Capacidad de Procesos Con Cobit 5 Goierno de Tidavid ortizÎncă nu există evaluări
- Estrategias Informaticas en La Toma de DecisionesDocument45 paginiEstrategias Informaticas en La Toma de DecisionesEvelyn Castellanos100% (1)
- Enrique Gonzales - Trabajo de Investigacion - Bachiller - 2019Document64 paginiEnrique Gonzales - Trabajo de Investigacion - Bachiller - 2019Mauricio Arce BoladosÎncă nu există evaluări
- Informe Final Equipo 01 Vida RuizDocument79 paginiInforme Final Equipo 01 Vida RuizKEVIN ALONSO PACHERRES JUAREZÎncă nu există evaluări
- Soft Inventario y FacturaDocument123 paginiSoft Inventario y FacturaEddy SarantezÎncă nu există evaluări
- Valdivia González, N., Moreno Ahumada, A., & Carranza Vásquez, D. (2013) - Sistema de Horarios-SiHo.Document76 paginiValdivia González, N., Moreno Ahumada, A., & Carranza Vásquez, D. (2013) - Sistema de Horarios-SiHo.Angel David JaramilloÎncă nu există evaluări
- TFM Luis Augusto Perez Gonzalez PDFDocument145 paginiTFM Luis Augusto Perez Gonzalez PDFjosel5702Încă nu există evaluări
- Informe Final Todo PoderosoDocument65 paginiInforme Final Todo PoderosoAntonioÎncă nu există evaluări
- Herramientas Multimedia - Semana 4Document71 paginiHerramientas Multimedia - Semana 4Carlos GuerraÎncă nu există evaluări
- Gestión de Proyecto de Software Partiendo de Las Líneas Estratégicas de Negocio PDFDocument45 paginiGestión de Proyecto de Software Partiendo de Las Líneas Estratégicas de Negocio PDFDigital Harbor BoliviaÎncă nu există evaluări
- Chavez Huanca EddyDocument205 paginiChavez Huanca EddymishytooÎncă nu există evaluări
- MALIDocument14 paginiMALImishytooÎncă nu există evaluări
- Cronograma BCP - Visa MasivaDocument1 paginăCronograma BCP - Visa MasivamishytooÎncă nu există evaluări
- Reglamento GanagolDocument11 paginiReglamento GanagolmishytooÎncă nu există evaluări
- Robocop yDocument3 paginiRobocop yhevipimaÎncă nu există evaluări
- Base de Detos Con Python PDFDocument36 paginiBase de Detos Con Python PDFjoel js gomez alanocaÎncă nu există evaluări
- Comandos de DiskPartDocument29 paginiComandos de DiskPartBetto Pinto CcunoÎncă nu există evaluări
- Implemntacion Arboles AVLDocument105 paginiImplemntacion Arboles AVLPablo ConstanteÎncă nu există evaluări
- Partes Externas de La ComputadoraDocument8 paginiPartes Externas de La ComputadoraantonioÎncă nu există evaluări
- Diccionario de DatosDocument16 paginiDiccionario de DatosJonathan KiryuÎncă nu există evaluări
- Diagramas Casos de UsosDocument21 paginiDiagramas Casos de UsosMagnoBarreroÎncă nu există evaluări
- Motores de Base de Datos JCWHRDocument12 paginiMotores de Base de Datos JCWHRJean Carlos William Huancoillo RojasÎncă nu există evaluări
- Partes Internas Del CPU y La LaptopDocument15 paginiPartes Internas Del CPU y La LaptopAugusto Rivera Encarnación100% (1)
- Ejemplo 2 de Creación de Base de DatosDocument13 paginiEjemplo 2 de Creación de Base de DatosLeodegario Ramirez100% (2)
- Glosario de Informática Inglés-EspañolDocument54 paginiGlosario de Informática Inglés-Españoleduardo bautistaÎncă nu există evaluări
- Eliminar Elementos de Una Lista EnlazadaDocument10 paginiEliminar Elementos de Una Lista EnlazadaMerÎncă nu există evaluări
- SAP: Field Symbols en ABAPDocument8 paginiSAP: Field Symbols en ABAPAlex de Cuenca80% (5)
- Arquitectura PipelineDocument31 paginiArquitectura Pipelinemdl731Încă nu există evaluări
- XMLDocument48 paginiXMLRicardo MartinezÎncă nu există evaluări
- Manual de UsuarioDocument121 paginiManual de UsuariobitfileÎncă nu există evaluări
- Revista Arquitectura Del ComputadorDocument29 paginiRevista Arquitectura Del ComputadorMiguel Diaz100% (1)
- Dell - Sitio OficialDocument26 paginiDell - Sitio OficialRodrigoMorenoCastilloÎncă nu există evaluări
- Actividad 1 Procedimientos AlmacenadosDocument5 paginiActividad 1 Procedimientos AlmacenadosAlexis Emmanuel RamirezÎncă nu există evaluări
- Manual de Procedimientos 2011 Anexo II Samba V2Document66 paginiManual de Procedimientos 2011 Anexo II Samba V2Fernando CrocioniÎncă nu există evaluări
- Implementación de Matrices de Acces1Document4 paginiImplementación de Matrices de Acces1Braulio DuarteÎncă nu există evaluări
- 005.13 M319 FuncionesDocument573 pagini005.13 M319 FuncionesHackLAGQÎncă nu există evaluări
- Amb Folleto Por CompetenciaSQ1Document58 paginiAmb Folleto Por CompetenciaSQ1Manuel Calero GradisÎncă nu există evaluări
- Kyocera Net Admin 3.1Document61 paginiKyocera Net Admin 3.1Cesar Augusto Gomez PaezÎncă nu există evaluări
- Modalidad de Exámenes - Semana 4 - Revisión Del IntentoDocument2 paginiModalidad de Exámenes - Semana 4 - Revisión Del Intentoluisneira5Încă nu există evaluări
- Manual de Intelisis: Respaldo de Bases de DatosDocument14 paginiManual de Intelisis: Respaldo de Bases de DatosRodrigo Cruz VázquezÎncă nu există evaluări
- Estructura Informatica Del Registro de Aguas - tcm30 377046 2 PDFDocument120 paginiEstructura Informatica Del Registro de Aguas - tcm30 377046 2 PDFErnesto FelipeÎncă nu există evaluări
- Mapa Mental Conceptos Basicos de Bases de DatosDocument1 paginăMapa Mental Conceptos Basicos de Bases de Datosjhonny marinÎncă nu există evaluări
- Manual de BI - ConceptosDocument19 paginiManual de BI - Conceptoscneyra2013Încă nu există evaluări