S-ar putea să vă placă și
- Affine Transformation: Unlocking Visual Perspectives: Exploring Affine Transformation in Computer VisionDe la EverandAffine Transformation: Unlocking Visual Perspectives: Exploring Affine Transformation in Computer VisionÎncă nu există evaluări
- 2 StatesDocument10 pagini2 StatesVinayak DuttaÎncă nu există evaluări
- Lecture 2: Linear Operators: IIT KanpurDocument13 paginiLecture 2: Linear Operators: IIT KanpurpratapsahooÎncă nu există evaluări
- Anin Mimos MathDocument24 paginiAnin Mimos MathAtul NipaneÎncă nu există evaluări
- Sturm - Lioville ProblemsDocument44 paginiSturm - Lioville ProblemscaemendezÎncă nu există evaluări
- Crash Course: QM MathDocument6 paginiCrash Course: QM MathJosé Luis Salazar EspitiaÎncă nu există evaluări
- Crash Course The Math of Quantum Mechanics PDFDocument6 paginiCrash Course The Math of Quantum Mechanics PDFhuha818Încă nu există evaluări
- Geometry in PhysicsDocument79 paginiGeometry in PhysicsParag MahajaniÎncă nu există evaluări
- Math 5467, Spring 2005 Intro. To Inner Product and Hilbert SpacesDocument13 paginiMath 5467, Spring 2005 Intro. To Inner Product and Hilbert SpacesAmerico CunhaÎncă nu există evaluări
- 3 OperationsDocument8 pagini3 OperationsVinayak DuttaÎncă nu există evaluări
- Chapter I: Qubits, Operators and Quantum GatesDocument18 paginiChapter I: Qubits, Operators and Quantum GatesNilasha GhoshÎncă nu există evaluări
- 221A Lecture Notes: Notes On Tensor Product 1 What Is "Tensor"?Document14 pagini221A Lecture Notes: Notes On Tensor Product 1 What Is "Tensor"?Dita PramestiÎncă nu există evaluări
- Engg AnalysisDocument117 paginiEngg AnalysisrajeshtaladiÎncă nu există evaluări
- Linear OperatorsDocument9 paginiLinear OperatorsANKIT SAHAÎncă nu există evaluări
- Dirac NotationDocument7 paginiDirac NotationDavidÎncă nu există evaluări
- Chapter 6Document12 paginiChapter 6Ariana Ribeiro LameirinhasÎncă nu există evaluări
- Linear Algebra Chapter 12 - Complex Vector SpacesDocument6 paginiLinear Algebra Chapter 12 - Complex Vector Spacesdaniel_bashir808Încă nu există evaluări
- 3195 Study VsDocument6 pagini3195 Study VsBrik ZivkovichÎncă nu există evaluări
- Quantum PhysicsDocument50 paginiQuantum PhysicsSahil ChadhaÎncă nu există evaluări
- Analysis, NotesDocument13 paginiAnalysis, NotesΣωτήρης ΝτελήςÎncă nu există evaluări
- 18.06 - Linear Algebra Cheatsheet: 1 VectorsDocument5 pagini18.06 - Linear Algebra Cheatsheet: 1 VectorsIoannisM.ValasakisÎncă nu există evaluări
- Linear Algebra NotesDocument36 paginiLinear Algebra Notesdeletia666Încă nu există evaluări
- Some Mathematical Preliminaries Linear Vector SpacesDocument9 paginiSome Mathematical Preliminaries Linear Vector SpacesjasmonÎncă nu există evaluări
- Chapter 3 Vector Spaces: 3.1 DefinitionDocument16 paginiChapter 3 Vector Spaces: 3.1 DefinitionJonathan JufenoÎncă nu există evaluări
- Expanding Quasi-MV Algebras by A Quantum Operator: AbstractDocument30 paginiExpanding Quasi-MV Algebras by A Quantum Operator: AbstractRoberto GiuntiniÎncă nu există evaluări
- Matrices & Linear Algebra: Vector SpacesDocument20 paginiMatrices & Linear Algebra: Vector SpacesFelipe López GarduzaÎncă nu există evaluări
- The Logic of CMV-algebrasDocument21 paginiThe Logic of CMV-algebrasSearÎncă nu există evaluări
- Lecture13 AuroraDocument9 paginiLecture13 Auroramartin701107Încă nu există evaluări
- Name 1: - Drexel Username 1Document4 paginiName 1: - Drexel Username 1Bao DangÎncă nu există evaluări
- Block 1Document18 paginiBlock 1muay88Încă nu există evaluări
- Invariant SubspacesDocument7 paginiInvariant SubspacesDipro MondalÎncă nu există evaluări
- MIT18 102s21 Lec5Document5 paginiMIT18 102s21 Lec5vladimirÎncă nu există evaluări
- A Brief Introduction To TensorsDocument12 paginiA Brief Introduction To TensorsJude JudeÎncă nu există evaluări
- Udacity Session10Document52 paginiUdacity Session10mahmoud samirÎncă nu există evaluări
- Linear AlgebraDocument27 paginiLinear AlgebraVicenta RobanteÎncă nu există evaluări
- Tensors Poor ManDocument17 paginiTensors Poor ManSurya GowtamÎncă nu există evaluări
- MIT NoteDocument140 paginiMIT NoteWidmungÎncă nu există evaluări
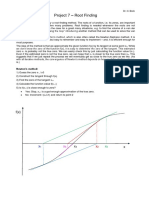
- Project 7 - Root Finding: Newton's MethodDocument4 paginiProject 7 - Root Finding: Newton's Methodhannan1993Încă nu există evaluări
- Chapter 7 - Geometry of Lines and Planes: 7.1 - IntroductionDocument4 paginiChapter 7 - Geometry of Lines and Planes: 7.1 - IntroductionLexÎncă nu există evaluări
- Linear Methods of Applied Mathematics Evans M. Harrell II and James V. HerodDocument16 paginiLinear Methods of Applied Mathematics Evans M. Harrell II and James V. Herodjose2017Încă nu există evaluări
- 1 Eigenvalues and Eigenvectors: Lecture 3: October 5, 2021Document5 pagini1 Eigenvalues and Eigenvectors: Lecture 3: October 5, 2021Pushkaraj PanseÎncă nu există evaluări
- Iiserb Mm1 Notes Oct 4Document30 paginiIiserb Mm1 Notes Oct 4Shruti ShirolÎncă nu există evaluări
- 9.4 Singular Value Decomposition: 9.4.1 Definition of The SVDDocument4 pagini9.4 Singular Value Decomposition: 9.4.1 Definition of The SVDawais04Încă nu există evaluări
- Linear AlgebraDocument7 paginiLinear Algebrataych03Încă nu există evaluări
- Rota On Multilinear Algebra and GeometryDocument43 paginiRota On Multilinear Algebra and Geometryrasgrn7112Încă nu există evaluări
- 3-D Geometry NotesDocument7 pagini3-D Geometry NotesJohn KimaniÎncă nu există evaluări
- Mathematical Methods WK 1: Vectors: 1 Linear Vector SpacesDocument10 paginiMathematical Methods WK 1: Vectors: 1 Linear Vector SpacesW-d DomÎncă nu există evaluări
- MIT18 102s21 Lec1Document7 paginiMIT18 102s21 Lec1vladimirÎncă nu există evaluări
- MIT18 102s21 Full LecDocument125 paginiMIT18 102s21 Full LecProÎncă nu există evaluări
- Multilinear Algebra - MITDocument141 paginiMultilinear Algebra - MITasdÎncă nu există evaluări
- QM 1Document24 paginiQM 1Salim DávilaÎncă nu există evaluări
- Hudyma AlexDocument33 paginiHudyma AlexYogakeerthigaÎncă nu există evaluări
- MA412 FinalDocument82 paginiMA412 FinalAhmad Zen FiraÎncă nu există evaluări
- Numerical Ranges of Unbounded OperatorsDocument22 paginiNumerical Ranges of Unbounded OperatorsAdedokun AbayomiÎncă nu există evaluări
- Cayley HamiltonDocument5 paginiCayley HamiltonSameh ElnemaisÎncă nu există evaluări
- VectorCalculus PDFDocument31 paginiVectorCalculus PDFMaria Hidalgo MurilloÎncă nu există evaluări
- Amenzade Yu.a. - Theory of Elasticity-Mir (1979)Document284 paginiAmenzade Yu.a. - Theory of Elasticity-Mir (1979)Javier100% (1)
- Highway Design ReportDocument27 paginiHighway Design ReportBrendan Johns100% (1)
- Artificial Intellegence & Future Workplace: Submited by - Hitesh Gayakwad B.B.A.LLB. (2019) Roll No.-12Document12 paginiArtificial Intellegence & Future Workplace: Submited by - Hitesh Gayakwad B.B.A.LLB. (2019) Roll No.-12hitesh gayakwadÎncă nu există evaluări
- Taylor Introms11GE PPT 01Document27 paginiTaylor Introms11GE PPT 01hddankerÎncă nu există evaluări
- Solution Manual Mechanical Engineering Design One 8th by ShigleyDocument288 paginiSolution Manual Mechanical Engineering Design One 8th by ShigleyAnonymous HH3dnvF50% (4)
- (Semantic) - Word, Meaning and ConceptDocument13 pagini(Semantic) - Word, Meaning and ConceptIan NugrahaÎncă nu există evaluări
- Cambridge International General Certificate of Secondary EducationDocument16 paginiCambridge International General Certificate of Secondary Educationprathamkumar8374Încă nu există evaluări
- Chap 11Document67 paginiChap 11Reina Erasmo SulleraÎncă nu există evaluări
- Review SessionDocument52 paginiReview SessionEskat Torres FaderonÎncă nu există evaluări
- FreeRTOS - TasksDocument31 paginiFreeRTOS - TasksMani Kandan KÎncă nu există evaluări
- Fuzzy Quasi Regular RingDocument3 paginiFuzzy Quasi Regular RingIIR indiaÎncă nu există evaluări
- An Empirical Investigation of Job StressDocument24 paginiAn Empirical Investigation of Job StressNafees Naseer100% (1)
- Seismic Shear Strength of Columns With Interlocking Spiral Reinforcement Gianmario BenzoniDocument8 paginiSeismic Shear Strength of Columns With Interlocking Spiral Reinforcement Gianmario Benzonijuho jungÎncă nu există evaluări
- Ojimc 2021 (Imo Mock)Document8 paginiOjimc 2021 (Imo Mock)NonuÎncă nu există evaluări
- Algebraic ExpressionDocument99 paginiAlgebraic ExpressionRyan BuboÎncă nu există evaluări
- Urdaneta City UniversityDocument2 paginiUrdaneta City UniversityTheodore VilaÎncă nu există evaluări
- EEL2026-LabsheetDocument23 paginiEEL2026-LabsheetchandraÎncă nu există evaluări
- Playing With Blends in CoreldrawDocument12 paginiPlaying With Blends in CoreldrawZubairÎncă nu există evaluări
- MBR Session 20Document78 paginiMBR Session 20mariamabbasi2626Încă nu există evaluări
- MIniMax AlgorithmDocument8 paginiMIniMax AlgorithmVariable 14Încă nu există evaluări
- Cost-Volume-Profit Relationships: © 2010 The Mcgraw-Hill Companies, IncDocument97 paginiCost-Volume-Profit Relationships: © 2010 The Mcgraw-Hill Companies, IncInga ApseÎncă nu există evaluări
- Algorithm: Computer Science: A Modern Introduction. The Algorithm "Is The Unifying ConceptDocument7 paginiAlgorithm: Computer Science: A Modern Introduction. The Algorithm "Is The Unifying ConceptMaria ClaraÎncă nu există evaluări
- (Clifford) Advances in Engineering Software PDFDocument796 pagini(Clifford) Advances in Engineering Software PDFNguyễn Tấn LậpÎncă nu există evaluări
- A4 Heat Press Manual PDFDocument13 paginiA4 Heat Press Manual PDFmapache66Încă nu există evaluări
- 2015-TamMetin SMAS TutgunUnal DenizDocument21 pagini2015-TamMetin SMAS TutgunUnal DenizRonald AlmagroÎncă nu există evaluări
- Practice IB QuestionsDocument7 paginiPractice IB QuestionsVgyggÎncă nu există evaluări
- Strategies For Administrative Reform: Yehezkel DrorDocument17 paginiStrategies For Administrative Reform: Yehezkel DrorNahidul IslamÎncă nu există evaluări
- Interpreting and Using Statistics in Psychological Research 1St Edition Christopher Test Bank Full Chapter PDFDocument41 paginiInterpreting and Using Statistics in Psychological Research 1St Edition Christopher Test Bank Full Chapter PDFhungden8pne100% (12)
- Dividing Fractions : and What It MeansDocument22 paginiDividing Fractions : and What It MeansFlors BorneaÎncă nu există evaluări
- Spe 163492 Pa PDFDocument17 paginiSpe 163492 Pa PDFsanty222Încă nu există evaluări