S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- VW Passat B5 ATF Fluid & Filter ChangeDocument6 paginiVW Passat B5 ATF Fluid & Filter ChangeJosé Luis Ormeño100% (3)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- 09513550910934501Document16 pagini09513550910934501Sinisa Gale GacicÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Electronics - Low-Noise Amplifier Stability Concept To Practical Considerations, Part 1 PDFDocument39 paginiElectronics - Low-Noise Amplifier Stability Concept To Practical Considerations, Part 1 PDFValiBardaÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Laboratory-Scale Techniques For The Measurement of A Material ResponseDocument8 paginiLaboratory-Scale Techniques For The Measurement of A Material ResponseSinisa Gale GacicÎncă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Craters of Large-Scale Surface Explosions PDFDocument5 paginiCraters of Large-Scale Surface Explosions PDFSinisa Gale GacicÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Cratersize README PDFDocument2 paginiCratersize README PDFSinisa Gale GacicÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- CraterDocument8 paginiCraterSinisa Gale GacicÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- 24a Fuel Injection-Motronic (1.8L)Document14 pagini24a Fuel Injection-Motronic (1.8L)Sinisa Gale GacicÎncă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Advanced Structural Mechanics PDFDocument312 paginiAdvanced Structural Mechanics PDFFelipe Carrasco DuránÎncă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- C++ Version, First EditionDocument189 paginiC++ Version, First EditionMarko AndrejevićÎncă nu există evaluări
- C++ IndustrialDocument244 paginiC++ IndustrialVictor Alfonso ParraÎncă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- AutoCAD 3D Course ManualDocument166 paginiAutoCAD 3D Course ManualJed Tedor98% (47)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Small Scale Ground Shock Tests ZHOU YX DoD SeminarDocument12 paginiSmall Scale Ground Shock Tests ZHOU YX DoD SeminarSinisa Gale GacicÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Beam Examples01Document41 paginiBeam Examples01UNsha bee komÎncă nu există evaluări
- Usepa - 3051 ADocument30 paginiUsepa - 3051 Awrangel_2Încă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Multiscale Micromechanical Modeling of Polymer/clay Nanocomposites and The Effective Clay ParticleDocument20 paginiMultiscale Micromechanical Modeling of Polymer/clay Nanocomposites and The Effective Clay ParticleSinisa Gale GacicÎncă nu există evaluări
- An Assessment of Metal Pollution in Surface Sediments PDFDocument9 paginiAn Assessment of Metal Pollution in Surface Sediments PDFSinisa Gale GacicÎncă nu există evaluări
- Ied SmartcardDocument2 paginiIed Smartcardgunnyusmarine0976100% (2)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Assessment of Metal Pollution Based On Multivariate Statistical PDFDocument7 paginiAssessment of Metal Pollution Based On Multivariate Statistical PDFSinisa Gale GacicÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- A Molecular Dynamic Study of The Effects of Branching Charachteristics of LDPE On Its Miscibility With HDPEDocument6 paginiA Molecular Dynamic Study of The Effects of Branching Charachteristics of LDPE On Its Miscibility With HDPESinisa Gale GacicÎncă nu există evaluări
- A Combined Multi-Instrumental Approach For The Physico-Chemical Characterization of PDFDocument12 paginiA Combined Multi-Instrumental Approach For The Physico-Chemical Characterization of PDFSinisa Gale GacicÎncă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Insight Into Molecular Interactions Between Constituents in Polymer Clay NanocompositesDocument10 paginiInsight Into Molecular Interactions Between Constituents in Polymer Clay NanocompositesSinisa Gale GacicÎncă nu există evaluări
- A Five-Year Study On The Heavy-Metal PDFDocument12 paginiA Five-Year Study On The Heavy-Metal PDFSinisa Gale Gacic0% (1)
- D 5135 - 95 - RduxmzutukveDocument6 paginiD 5135 - 95 - RduxmzutukveSinisa Gale GacicÎncă nu există evaluări
- Correlation Between The Glass Transition Temperatures and Repeating Unit Structure For High Molecular Weight PolymersDocument8 paginiCorrelation Between The Glass Transition Temperatures and Repeating Unit Structure For High Molecular Weight PolymersSinisa Gale GacicÎncă nu există evaluări
- D 2340 - 03Document2 paginiD 2340 - 03Sinisa Gale Gacic100% (1)
- Astm D 2504 - 88Document5 paginiAstm D 2504 - 88Sinisa Gale GacicÎncă nu există evaluări
- Drvo Moduli ElasticnostiDocument5 paginiDrvo Moduli ElasticnostiSinisa Gale GacicÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Mil C 21723aDocument20 paginiMil C 21723aSinisa Gale GacicÎncă nu există evaluări
- Allegheny Power Planning CriteriaDocument19 paginiAllegheny Power Planning Criteriaksdp1Încă nu există evaluări
- 8 - Precast Concrete Structures-Students PDFDocument17 pagini8 - Precast Concrete Structures-Students PDFsitehabÎncă nu există evaluări
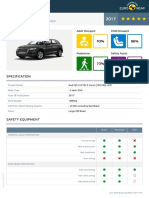
- Euroncap 2017 Audi q5 DatasheetDocument13 paginiEuroncap 2017 Audi q5 DatasheetCosmin AnculiaÎncă nu există evaluări
- System Substation Commissioning TestsDocument8 paginiSystem Substation Commissioning TestsCvijayakumar100% (1)
- Samyung SI-30 ManualDocument2 paginiSamyung SI-30 ManualYan Naing0% (1)
- Osawa Catalogue 2021Document708 paginiOsawa Catalogue 2021lorenzo.lima1706Încă nu există evaluări
- Surface Chemistry: by General CharacteristicsDocument8 paginiSurface Chemistry: by General CharacteristicssriÎncă nu există evaluări
- Vibration ControlDocument513 paginiVibration ControlchandankrdumkaÎncă nu există evaluări
- Testing Fire-ProtectionDocument2 paginiTesting Fire-Protectionmia murciaÎncă nu există evaluări
- MIMSDocument3 paginiMIMSFrancineAntoinetteGonzalesÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- 24 - Al Nahda The Sheffeild Privat To International City, Greece K12 Dubai Bus Service TimetableDocument10 pagini24 - Al Nahda The Sheffeild Privat To International City, Greece K12 Dubai Bus Service TimetableDubai Q&AÎncă nu există evaluări
- Rajesh CVDocument3 paginiRajesh CVS R PramodÎncă nu există evaluări
- Vortex Based MathematicsDocument14 paginiVortex Based Mathematicssepsis19100% (2)
- Inhalation AnestheticsDocument27 paginiInhalation AnestheticsMarcelitaTaliaDuwiriÎncă nu există evaluări
- New Magic Grammar TE3BDocument34 paginiNew Magic Grammar TE3BYume ZhuÎncă nu există evaluări
- Key-Sentence Writing 1Document23 paginiKey-Sentence Writing 1Thảo VyÎncă nu există evaluări
- What Makes A Cup of NESCAFÉ So Special? The Best Coffee Beans andDocument4 paginiWhat Makes A Cup of NESCAFÉ So Special? The Best Coffee Beans andYenny YanyanÎncă nu există evaluări
- Tadabbur I Qur'ānDocument43 paginiTadabbur I Qur'ānamjad_emailÎncă nu există evaluări
- Specifications: Louie Jean Mabanag Ar - 3BDocument8 paginiSpecifications: Louie Jean Mabanag Ar - 3BLouie Jean100% (1)
- CHAPTER VI-Design of Stair, Ramp & Lift CoreDocument15 paginiCHAPTER VI-Design of Stair, Ramp & Lift CoreMahmudul HasanÎncă nu există evaluări
- Process Pipeline Repair ClampsDocument4 paginiProcess Pipeline Repair ClampsHeru SuryoÎncă nu există evaluări
- Harmonization of HR Policies - RoughDocument119 paginiHarmonization of HR Policies - RoughFrancis SoiÎncă nu există evaluări
- S.No. Components Makes: 1 Grab Cranes - Gantry TypeDocument4 paginiS.No. Components Makes: 1 Grab Cranes - Gantry TypeHarish KumarÎncă nu există evaluări
- Mass, Weigth and Density IGCSEDocument6 paginiMass, Weigth and Density IGCSEsapiniÎncă nu există evaluări
- Karakteristik Vegetasi Di Hutan Alam Dataran Rendah, Hutan Tanaman, Dan Lahan Pasca Tambang Nikel Di Kabupaten BombanaDocument6 paginiKarakteristik Vegetasi Di Hutan Alam Dataran Rendah, Hutan Tanaman, Dan Lahan Pasca Tambang Nikel Di Kabupaten BombanaWahyu AdistyaÎncă nu există evaluări
- Rama Varma Anagha Research PaperDocument12 paginiRama Varma Anagha Research Paperapi-308560676Încă nu există evaluări
- 23 - Eave StrutsDocument2 pagini23 - Eave StrutsTuanQuachÎncă nu există evaluări
- Bock09 - Video Compression SystemsDocument300 paginiBock09 - Video Compression SystemsWong_Ngee_SengÎncă nu există evaluări
- The Determinants of Service Quality and Customer Satisfaction in Malaysian e Hailing ServicesDocument8 paginiThe Determinants of Service Quality and Customer Satisfaction in Malaysian e Hailing ServicesYoannisa AtinaÎncă nu există evaluări
- Business Description: Apollo TyresDocument4 paginiBusiness Description: Apollo TyresSrijit SahaÎncă nu există evaluări
- Periodic Tales: A Cultural History of the Elements, from Arsenic to ZincDe la EverandPeriodic Tales: A Cultural History of the Elements, from Arsenic to ZincEvaluare: 3.5 din 5 stele3.5/5 (137)
- Monkeys, Myths, and Molecules: Separating Fact from Fiction, and the Science of Everyday LifeDe la EverandMonkeys, Myths, and Molecules: Separating Fact from Fiction, and the Science of Everyday LifeEvaluare: 4 din 5 stele4/5 (1)
- Is That a Fact?: Frauds, Quacks, and the Real Science of Everyday LifeDe la EverandIs That a Fact?: Frauds, Quacks, and the Real Science of Everyday LifeEvaluare: 5 din 5 stele5/5 (4)
- The Disappearing Spoon: And Other True Tales of Madness, Love, and the History of the World from the Periodic Table of the ElementsDe la EverandThe Disappearing Spoon: And Other True Tales of Madness, Love, and the History of the World from the Periodic Table of the ElementsEvaluare: 4 din 5 stele4/5 (146)
- Organic Chemistry for Schools: Advanced Level and Senior High SchoolDe la EverandOrganic Chemistry for Schools: Advanced Level and Senior High SchoolÎncă nu există evaluări
- The Nature of Drugs Vol. 1: History, Pharmacology, and Social ImpactDe la EverandThe Nature of Drugs Vol. 1: History, Pharmacology, and Social ImpactEvaluare: 5 din 5 stele5/5 (5)