S-ar putea să vă placă și
- Plan de Auditoria de La Empresa ECOMIN PERU S.A.Document7 paginiPlan de Auditoria de La Empresa ECOMIN PERU S.A.mayco100% (2)
- Teorema de Thevenin en ACDocument25 paginiTeorema de Thevenin en ACSimón De Jesús SalasÎncă nu există evaluări
- DIPTONGODocument8 paginiDIPTONGOSimón De Jesús SalasÎncă nu există evaluări
- Resumen Hacia El Lenguaje, Del Feto Al AdolescenteDocument30 paginiResumen Hacia El Lenguaje, Del Feto Al AdolescenteFrancisca Troncoso Acuña100% (6)
- Qué Son Estilos de Vida y Su Influencia en El Estado de SaludDocument11 paginiQué Son Estilos de Vida y Su Influencia en El Estado de SaludSimón De Jesús Salas100% (2)
- Intereses Dobre Saldos DeudoresDocument3 paginiIntereses Dobre Saldos DeudoresKlever Xavier CajamarcaÎncă nu există evaluări
- Método DialécticoDocument9 paginiMétodo DialécticoSimón De Jesús Salas100% (2)
- Reyes Z Jose Omar Actividad 1 Sesion 3 DepreciacionesDocument15 paginiReyes Z Jose Omar Actividad 1 Sesion 3 Depreciacionesomar reyes100% (2)
- Dermopharmacy Cosmetology MSTDocument14 paginiDermopharmacy Cosmetology MSTDavid LozanoÎncă nu există evaluări
- Introducción A La Ingeniería de Minera Vol. IV LAs Funciones de La Ingeniería MineraDocument46 paginiIntroducción A La Ingeniería de Minera Vol. IV LAs Funciones de La Ingeniería MineraDIOMEDES YUNIOR CHAMORRO MONAGOÎncă nu există evaluări
- Conocimiento AxiologicoDocument8 paginiConocimiento AxiologicoSimón De Jesús SalasÎncă nu există evaluări
- Cómo Una Atmósfera Tóxica Pudo Favorecer La Aparición de VidaDocument2 paginiCómo Una Atmósfera Tóxica Pudo Favorecer La Aparición de VidaSimón De Jesús Salas79% (19)
- Cooperativas de Producción de y Obtención Bienes y ServiciosDocument5 paginiCooperativas de Producción de y Obtención Bienes y ServiciosSimón De Jesús SalasÎncă nu există evaluări
- Ensayo Medios de Comunicacion Parcializados YismaryDocument2 paginiEnsayo Medios de Comunicacion Parcializados YismarySimón De Jesús SalasÎncă nu există evaluări
- Informe Venerice La Oralidad y La EscrituraDocument8 paginiInforme Venerice La Oralidad y La EscrituraSimón De Jesús SalasÎncă nu există evaluări
- Estrategias Redes Socioproductivas Castillo MerlyDocument13 paginiEstrategias Redes Socioproductivas Castillo MerlySimón De Jesús SalasÎncă nu există evaluări
- Aprendizaje SignificativoDocument17 paginiAprendizaje SignificativoSimón De Jesús SalasÎncă nu există evaluări
- Mercado Primario y SecundarioDocument5 paginiMercado Primario y SecundarioSimón De Jesús SalasÎncă nu există evaluări
- 584 CORREGIR 3vezDocument26 pagini584 CORREGIR 3vezSimón De Jesús SalasÎncă nu există evaluări
- Origen Del GuácimoDocument2 paginiOrigen Del GuácimoSimón De Jesús SalasÎncă nu există evaluări
- Radiologia e HistoriaDocument24 paginiRadiologia e HistoriaPam OÎncă nu există evaluări
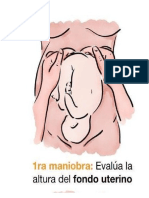
- En Que Consiste Cada Maniobra de LiopolDocument11 paginiEn Que Consiste Cada Maniobra de LiopolAndres BuesoÎncă nu există evaluări
- Libreto de Investigación LavavajillaspdfDocument41 paginiLibreto de Investigación Lavavajillaspdf7q8dvrr469Încă nu există evaluări
- Caso Clínico Obesidad InfantilDocument5 paginiCaso Clínico Obesidad InfantilPaola BejaranoÎncă nu există evaluări
- GP8 HguDocument4 paginiGP8 HguSTHEFANY LUCIA MEZA ACUNAÎncă nu există evaluări
- IVA Exportador 1Document5 paginiIVA Exportador 1Jota CÎncă nu există evaluări
- Conducción Multidimensional de Calor en Régimen TransitorioDocument4 paginiConducción Multidimensional de Calor en Régimen TransitorioframikhÎncă nu există evaluări
- Formato Evidencia Producto Guia1Document4 paginiFormato Evidencia Producto Guia1michell adriana jimenezÎncă nu există evaluări
- UMSNH InfografíaDocument1 paginăUMSNH InfografíaRodrigo PardoÎncă nu există evaluări
- Descripcion de AnimalesDocument4 paginiDescripcion de AnimalesLuis Miguel Sanchez AcostaÎncă nu există evaluări
- Guía de Viaje Misahualli 2023Document26 paginiGuía de Viaje Misahualli 2023Anibal Fuentes MorenoÎncă nu există evaluări
- LA INUTILIDAD DE LO ARQUITECTONICO - Patricio Ortega Celis PDFDocument150 paginiLA INUTILIDAD DE LO ARQUITECTONICO - Patricio Ortega Celis PDFAndres LaraÎncă nu există evaluări
- Examen Probabilidad HPDocument5 paginiExamen Probabilidad HPTatiana RicoÎncă nu există evaluări
- Guía Director KipusDocument5 paginiGuía Director KipusCleto GeronimoÎncă nu există evaluări
- Pasos para Formatear Una ComputadoraDocument2 paginiPasos para Formatear Una ComputadoraAngel Matthew de Mirnd-RodÎncă nu există evaluări
- Taller de DistribuciónDocument2 paginiTaller de DistribuciónMELISA DAYANA JOYA PEDRAZAÎncă nu există evaluări
- Legajo Carla y MartinDocument20 paginiLegajo Carla y MartinJuan PrietoÎncă nu există evaluări
- Laboratorio Ii - Grupo A PDFDocument9 paginiLaboratorio Ii - Grupo A PDFDavid Alex Ojeda JaraÎncă nu există evaluări
- FIS110Document4 paginiFIS110noemi calabuigÎncă nu există evaluări
- Informe de Laboratorio de Fundamentos de QuimicaDocument6 paginiInforme de Laboratorio de Fundamentos de QuimicaYureilis Epieyu FajardoÎncă nu există evaluări
- Diagrama de Flujo - Fuente LinealesDocument6 paginiDiagrama de Flujo - Fuente LinealesTemas del Talento en Sistemas100% (1)
- GUIA 6 Cantillo Eline Criado Laura Garcia Paola PDFDocument12 paginiGUIA 6 Cantillo Eline Criado Laura Garcia Paola PDFstyhtgutyÎncă nu există evaluări
- VDLRR Ev1.3 QFDocument11 paginiVDLRR Ev1.3 QFVanessa De la RosaÎncă nu există evaluări
- Plan Clases Sec Quimica 4-5 Q1junioDocument5 paginiPlan Clases Sec Quimica 4-5 Q1junioEugenia Paola Di NubilaÎncă nu există evaluări