S-ar putea să vă placă și
- Engineering Optimization: An Introduction with Metaheuristic ApplicationsDe la EverandEngineering Optimization: An Introduction with Metaheuristic ApplicationsÎncă nu există evaluări
- Heart Rate Variability: Measures and ModelsDocument84 paginiHeart Rate Variability: Measures and Modelsygh100% (1)
- Introduction to Machine Learning in the Cloud with Python: Concepts and PracticesDe la EverandIntroduction to Machine Learning in the Cloud with Python: Concepts and PracticesÎncă nu există evaluări
- Operating System Exercises - Chapter 16-SolDocument4 paginiOperating System Exercises - Chapter 16-SolevilanubhavÎncă nu există evaluări
- Operating System Exercises - Chapter 13-SolDocument4 paginiOperating System Exercises - Chapter 13-Solevilanubhav100% (1)
- Digital Light ProcessingDocument22 paginiDigital Light ProcessingRahul Kumar0% (1)
- Nav 6Document6 paginiNav 6shailesh singhÎncă nu există evaluări
- Assignment - IC Binary Trees SolutionsDocument34 paginiAssignment - IC Binary Trees SolutionsDrKrishna Priya ChakireddyÎncă nu există evaluări
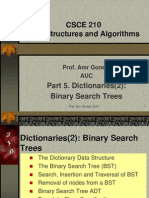
- Binary Search TreesDocument64 paginiBinary Search TreesAhmed HosniÎncă nu există evaluări
- Quiz2 3510 Cheat-SheetDocument4 paginiQuiz2 3510 Cheat-SheetKatherine Pham100% (1)
- Data Mining Is Defined As The Procedure of Extracting Information From Huge Sets of DataDocument6 paginiData Mining Is Defined As The Procedure of Extracting Information From Huge Sets of DataOdem Dinesh ReddyÎncă nu există evaluări
- C# Questions1Document11 paginiC# Questions1Sundari MuruganÎncă nu există evaluări
- MC0080 Analysis and Design of AlgorithmsDocument15 paginiMC0080 Analysis and Design of AlgorithmsGaurav Singh JantwalÎncă nu există evaluări
- Algorithm and ComplexityDocument42 paginiAlgorithm and ComplexityRichyÎncă nu există evaluări
- C# FaqDocument19 paginiC# Faqapi-3748960Încă nu există evaluări
- Operating SystemsDocument7 paginiOperating SystemsIT8109Încă nu există evaluări
- Linked List - SLLDocument15 paginiLinked List - SLLHashmi MajidÎncă nu există evaluări
- Sampling Image Video ProcessingDocument19 paginiSampling Image Video ProcessingSrinivas ReddyÎncă nu există evaluări
- Algorithms, Performativity and Governability - IntronaDocument16 paginiAlgorithms, Performativity and Governability - IntronaCristina AndreeaÎncă nu există evaluări
- Circular Linked List Data StructureDocument47 paginiCircular Linked List Data StructureAdrian IosifÎncă nu există evaluări
- OS TotalDocument50 paginiOS TotalHarisson Pham100% (1)
- Unsupervised LearningDocument29 paginiUnsupervised LearningUddalak BanerjeeÎncă nu există evaluări
- Decision Trees For Predictive Modeling (Neville)Document24 paginiDecision Trees For Predictive Modeling (Neville)Mohith Reddy100% (1)
- ONVIF Streaming Spec v210Document31 paginiONVIF Streaming Spec v210intrawayÎncă nu există evaluări
- Embedded Linux 4d Slides PDFDocument392 paginiEmbedded Linux 4d Slides PDFPaul RattinkÎncă nu există evaluări
- DMDT53 002Document159 paginiDMDT53 002Victor TAÎncă nu există evaluări
- Dsa Assignment: 1. Define Binary TreeDocument6 paginiDsa Assignment: 1. Define Binary Treesethuvm1234Încă nu există evaluări
- Algorithms For Parallel MachinesDocument7 paginiAlgorithms For Parallel Machinesshinde_jayesh2005Încă nu există evaluări
- Crash Course On Data Stream Algorithms: Part I: Basic Definitions and Numerical StreamsDocument76 paginiCrash Course On Data Stream Algorithms: Part I: Basic Definitions and Numerical Streamsumayrh@gmail.comÎncă nu există evaluări
- DecisionTrees RandomForest v2Document27 paginiDecisionTrees RandomForest v2Sandeep MishraÎncă nu există evaluări
- Seminar PPT On PcaDocument17 paginiSeminar PPT On Pcaprince SinghÎncă nu există evaluări
- Clustering Using SasDocument112 paginiClustering Using SasGagandeep SinghÎncă nu există evaluări
- Cluster Analysis in Python Chapter1 PDFDocument31 paginiCluster Analysis in Python Chapter1 PDFFgpeqwÎncă nu există evaluări
- Characteristics of An Algorithm: ExampleDocument8 paginiCharacteristics of An Algorithm: ExampleIqra RajaÎncă nu există evaluări
- Handling and Processing Strings in R PDFDocument113 paginiHandling and Processing Strings in R PDFInstantRamenÎncă nu există evaluări
- Data Mining ToolsDocument31 paginiData Mining ToolsKrishna Dash100% (1)
- COA AssignmentDocument11 paginiCOA AssignmentrajatÎncă nu există evaluări
- Big-O Algorithm Complexity Cheat SheetDocument9 paginiBig-O Algorithm Complexity Cheat SheetManoj PandeyÎncă nu există evaluări
- Design of Experiments Via Taguchi Methods Orthogonal ArraysDocument21 paginiDesign of Experiments Via Taguchi Methods Orthogonal ArraysRohan ViswanathÎncă nu există evaluări
- A Survey On Data MiningDocument4 paginiA Survey On Data MiningInternational Organization of Scientific Research (IOSR)Încă nu există evaluări
- Bitwise OperationDocument8 paginiBitwise Operationsmith_5Încă nu există evaluări
- Life Cycle Cost (LCC) Analysis: Taufik Hamzah, Ir.,MSA.,MBA Civil Engineering Department Bandung State PolytechnicDocument45 paginiLife Cycle Cost (LCC) Analysis: Taufik Hamzah, Ir.,MSA.,MBA Civil Engineering Department Bandung State PolytechnicNia Nurohmah FadillahÎncă nu există evaluări
- Decision TreeDocument30 paginiDecision Treemounika reddyÎncă nu există evaluări
- Dimensionality Reduction: Principal Component Analysis (PCA)Document11 paginiDimensionality Reduction: Principal Component Analysis (PCA)tanmayi nandirajuÎncă nu există evaluări
- Ref 3 Recommender Systems For Learning PDFDocument84 paginiRef 3 Recommender Systems For Learning PDFjoydeepÎncă nu există evaluări
- Predictive Maintenance From Wine Cellars To 40,000ftDocument16 paginiPredictive Maintenance From Wine Cellars To 40,000ftAnonymous 9tJYscsÎncă nu există evaluări
- What Is FL & Its Applications - 1Document95 paginiWhat Is FL & Its Applications - 1rmehfuzÎncă nu există evaluări
- Data Mining ThesisDocument104 paginiData Mining ThesisShaik RasoolÎncă nu există evaluări
- Hands On PythonDocument123 paginiHands On PythonRohit Vishal Kumar100% (1)
- Linear Regression: Major: All Engineering Majors Authors: Autar Kaw, Luke SnyderDocument25 paginiLinear Regression: Major: All Engineering Majors Authors: Autar Kaw, Luke Snydergunawan refiadi100% (1)
- Creating Fast, Responsive, and Energy-Efficient Embedded Systems Using The Renesas RL78 MicrocontrollerDocument388 paginiCreating Fast, Responsive, and Energy-Efficient Embedded Systems Using The Renesas RL78 Microcontrollerchilloutbrah100% (2)
- Genomics and BioinformaticsDocument17 paginiGenomics and BioinformaticsgoswamiphotostatÎncă nu există evaluări
- Advanced Data Structures and AlgorithmsDocument7 paginiAdvanced Data Structures and AlgorithmsPrahitha MovvaÎncă nu există evaluări
- PEB4102 Chapter 3Document46 paginiPEB4102 Chapter 3LimÎncă nu există evaluări
- Matlab SimulinkDocument42 paginiMatlab SimulinkBrian FreemanÎncă nu există evaluări
- 22 Selected Top Papers On Deep LearningDocument393 pagini22 Selected Top Papers On Deep LearningManjunath.RÎncă nu există evaluări
- Titanic Classification Disaster KaggleDocument18 paginiTitanic Classification Disaster KaggleJames AlbertsÎncă nu există evaluări
- PCA & ClusteringDocument6 paginiPCA & ClusteringTan Boon PinÎncă nu există evaluări
- Research Paper On Binary TreeDocument8 paginiResearch Paper On Binary Treevrxhvexgf100% (1)
- Trees: Siblings Are Child Elements With The Same ParentDocument2 paginiTrees: Siblings Are Child Elements With The Same ParentShravaniSangaonkarÎncă nu există evaluări
- Final MCA - Exam - TimeTable Nov-Dec - 2014Document5 paginiFinal MCA - Exam - TimeTable Nov-Dec - 2014ShravaniSangaonkarÎncă nu există evaluări
- Shivaji University Contact NumbersDocument3 paginiShivaji University Contact NumbersShravaniSangaonkarÎncă nu există evaluări
- Economic Survey - 2013 - of MaharashtraDocument279 paginiEconomic Survey - 2013 - of MaharashtraShravaniSangaonkarÎncă nu există evaluări
- Rangoli DesignsDocument17 paginiRangoli DesignsShravaniSangaonkarÎncă nu există evaluări
- File Structure Lab2Document4 paginiFile Structure Lab2mahmoudÎncă nu există evaluări
- IT Data Structures Chapter 3Document53 paginiIT Data Structures Chapter 3romeofatima100% (1)
- Tutorial 2Document5 paginiTutorial 2Miguel DiraneÎncă nu există evaluări
- CSI2110 Data Structures and AlgorithmsDocument39 paginiCSI2110 Data Structures and AlgorithmssalihaÎncă nu există evaluări
- Data Structures - CS1211Document4 paginiData Structures - CS1211Sunil SodegaonkarÎncă nu există evaluări
- AVL Trees: CSE 373 Data StructuresDocument43 paginiAVL Trees: CSE 373 Data StructuresSabari NathanÎncă nu există evaluări
- Balanced Binary Search Tree - Bina NusantaraDocument52 paginiBalanced Binary Search Tree - Bina NusantaraCanon RockÎncă nu există evaluări
- Test 2 Spring 01Document11 paginiTest 2 Spring 01Gobara DhanÎncă nu există evaluări
- QUESTIONS Dynamic ProgrammingDocument6 paginiQUESTIONS Dynamic ProgrammingAnkita PatelÎncă nu există evaluări
- Data Structures and AlgorithmsDocument8 paginiData Structures and AlgorithmsAlaukikDoc100% (1)
- Cs 301 MCQSBYMOAZDocument44 paginiCs 301 MCQSBYMOAZMuhammad Rameez KhalidÎncă nu există evaluări
- Advanced Data Structures NotesDocument142 paginiAdvanced Data Structures NotesChinkal Nagpal100% (2)
- CS3110 Prelim 2 SP09Document9 paginiCS3110 Prelim 2 SP09Lee GaoÎncă nu există evaluări
- Data StructuresDocument110 paginiData StructuresPulkit KumarÎncă nu există evaluări
- CS2201 PDFDocument1 paginăCS2201 PDFSpandan SinhaÎncă nu există evaluări
- EE2204 DSA 100 2marksDocument18 paginiEE2204 DSA 100 2marksVinod DeenathayalanÎncă nu există evaluări
- TOTSOL - Total Solution: Exam Conducted byDocument6 paginiTOTSOL - Total Solution: Exam Conducted bygauravhchavdaÎncă nu există evaluări
- AVL TreeDocument5 paginiAVL TreeChippyVijayanÎncă nu există evaluări
- Data Structures and Algorithms: Unit - 2Document2 paginiData Structures and Algorithms: Unit - 2Manikandan ThangaveluÎncă nu există evaluări
- AVL TreeDocument27 paginiAVL TreeTanmay BaranwalÎncă nu există evaluări
- Cs1201 Design and Analysis of AlgorithmDocument27 paginiCs1201 Design and Analysis of Algorithmvijay_sudhaÎncă nu există evaluări
- Avl TreesDocument12 paginiAvl Treessaiteja1234Încă nu există evaluări
- Computer Science and Applications: Paper-IiDocument8 paginiComputer Science and Applications: Paper-IiShanmugapriyaVinodkumarÎncă nu există evaluări
- A. 2451 B. 4950 C. 4851 D. 9900Document48 paginiA. 2451 B. 4950 C. 4851 D. 9900Jayesh Shinde0% (1)
- Introduction To Data StructuresDocument20 paginiIntroduction To Data StructuresnvÎncă nu există evaluări
- ds102 ps6 PDFDocument11 paginids102 ps6 PDFSumathi KannaÎncă nu există evaluări
- DS Lab 13 - AVL TreesDocument10 paginiDS Lab 13 - AVL TreesASIM ZUBAIR 111Încă nu există evaluări
- Dsa PDFDocument293 paginiDsa PDFAnonymous DFpzhrRÎncă nu există evaluări
- Avl TreesDocument25 paginiAvl TreesNarendra ChindanurÎncă nu există evaluări