S-ar putea să vă placă și
- Mobile IPDocument4 paginiMobile IPTân ChipÎncă nu există evaluări
- ProjectReport PDFDocument23 paginiProjectReport PDFTân ChipÎncă nu există evaluări
- Wednesday, October 28, 2015 11:34 AM: Lab RF Page 1Document2 paginiWednesday, October 28, 2015 11:34 AM: Lab RF Page 1Tân ChipÎncă nu există evaluări
- Wednesday, October 28, 2015 11:34 AM: Lab RF Page 1Document2 paginiWednesday, October 28, 2015 11:34 AM: Lab RF Page 1Tân ChipÎncă nu există evaluări
- Mach in PDFDocument1 paginăMach in PDFTân ChipÎncă nu există evaluări
- TIM NotesDocument7 paginiTIM NotesTân ChipÎncă nu există evaluări
- Communication NetworkDocument1 paginăCommunication NetworkTân ChipÎncă nu există evaluări
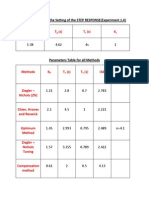
- Parameters From The Setting of The STEP RESPONSE (Experiment 1.4)Document1 paginăParameters From The Setting of The STEP RESPONSE (Experiment 1.4)Tân ChipÎncă nu există evaluări
- MATLAB-Hamming CodesDocument6 paginiMATLAB-Hamming CodesTân ChipÎncă nu există evaluări
- Science Magazine 5684 2004-07-30Document92 paginiScience Magazine 5684 2004-07-30th222bpÎncă nu există evaluări
- Science Magazine 5694 2004-10-08 PDFDocument89 paginiScience Magazine 5694 2004-10-08 PDFTân ChipÎncă nu există evaluări
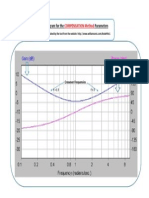
- BODE Diagramm For The COMPENSATION Method ParametersDocument1 paginăBODE Diagramm For The COMPENSATION Method ParametersTân ChipÎncă nu există evaluări
- Some Basic Block Codes - 2804Document3 paginiSome Basic Block Codes - 2804Tân ChipÎncă nu există evaluări
- Event: Selectionchanged: Callback Files Generated by Guide: - Code Files (.M) and FIG-Files (.Fig)Document1 paginăEvent: Selectionchanged: Callback Files Generated by Guide: - Code Files (.M) and FIG-Files (.Fig)Tân ChipÎncă nu există evaluări
- I2C TestDocument3 paginiI2C TestTân ChipÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- MSP430 C Compiler Programming GuideDocument242 paginiMSP430 C Compiler Programming Guidecharles_sieÎncă nu există evaluări
- 1.1.1 Reed - Solomon Code:: C F (U, U, , U, U)Document4 pagini1.1.1 Reed - Solomon Code:: C F (U, U, , U, U)Tân ChipÎncă nu există evaluări
- Decoding of Convolutional CodesDocument3 paginiDecoding of Convolutional CodesTân ChipÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- Makalah Penelitian Tentang LingkunganDocument1 paginăMakalah Penelitian Tentang LingkunganDedi IrhandiÎncă nu există evaluări
- Versuch 5: in Simulation Using Serial InterfaceDocument1 paginăVersuch 5: in Simulation Using Serial InterfaceTân ChipÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- Eula Microsoft Visual StudioDocument3 paginiEula Microsoft Visual StudioqwwerttyyÎncă nu există evaluări
- Coding TheoryDocument67 paginiCoding Theorytrungnv2803Încă nu există evaluări
- Aata 20110810Document438 paginiAata 20110810Tram VoÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- English MCQs For UGC NET - True Blue GuideDocument13 paginiEnglish MCQs For UGC NET - True Blue GuideTrue Blue GuideÎncă nu există evaluări
- Free PDF Reader Sony Ericsson w595Document2 paginiFree PDF Reader Sony Ericsson w595AdamÎncă nu există evaluări
- Chapter 3 Roots of EquationDocument57 paginiChapter 3 Roots of EquationJosafet Gutierrez MasaoayÎncă nu există evaluări
- Excel TrainingDocument23 paginiExcel TrainingsefanitÎncă nu există evaluări
- Cungte's ThesisDocument84 paginiCungte's Thesisapi-3804018Încă nu există evaluări
- Adjective Adverb Worksheets 2 - GrammarBankDocument3 paginiAdjective Adverb Worksheets 2 - GrammarBankNilson Guevara BenavidesÎncă nu există evaluări
- So..that... - Such... That...Document5 paginiSo..that... - Such... That...Ristia Nurul KamilaÎncă nu există evaluări
- TensesDocument2 paginiTensesMarcu RaileanÎncă nu există evaluări
- SPFX NotesDocument9 paginiSPFX NotespriyakantbhaiÎncă nu există evaluări
- Obedience (Beginner 1 B) .A1 Movers 9 Test 3 Reading & Writing (P 1-6) .Document19 paginiObedience (Beginner 1 B) .A1 Movers 9 Test 3 Reading & Writing (P 1-6) .Umroh SyafitriÎncă nu există evaluări
- 11. प्रशासन - प्रशासन-यातायात व्यवस्थापन सहायक तह ४Document7 pagini11. प्रशासन - प्रशासन-यातायात व्यवस्थापन सहायक तह ४Karna RishavÎncă nu există evaluări
- Sports: Fill in The Crossword and Find The Hidden WordsDocument2 paginiSports: Fill in The Crossword and Find The Hidden WordsArturo Fuentes BravoÎncă nu există evaluări
- OGG Best Practice Configuring OGG Monitor v07Document39 paginiOGG Best Practice Configuring OGG Monitor v07Naresh SundaraneediÎncă nu există evaluări
- LBS CodeDocument9 paginiLBS CodeKishore Kumar RaviChandranÎncă nu există evaluări
- About PronounsDocument2 paginiAbout PronounsLawrence OrqueroÎncă nu există evaluări
- Data Strucuture McqsDocument8 paginiData Strucuture McqsDr ManiÎncă nu există evaluări
- EE329 Summary 1Document5 paginiEE329 Summary 1Uji CobaÎncă nu există evaluări
- MacKenzie - Vanguard Lying DownDocument7 paginiMacKenzie - Vanguard Lying DownSergey MinovÎncă nu există evaluări
- Process Description and ControlDocument42 paginiProcess Description and ControlPaolo LegaspiÎncă nu există evaluări
- Joblana Test (JL Test) English Section Sample PaperDocument4 paginiJoblana Test (JL Test) English Section Sample PaperLots infotechÎncă nu există evaluări
- Master SymbolDocument3 paginiMaster Symbolapi-26172340100% (1)
- PDF Export User Guide v10Document22 paginiPDF Export User Guide v10rfffffÎncă nu există evaluări
- Lua Programming - Syntax, Concep - Alexander AronowitzDocument382 paginiLua Programming - Syntax, Concep - Alexander Aronowitzbearmiinator100% (2)
- English Phonetics - Task 2 - Practical Exercises FINISHED WITH LINKDocument4 paginiEnglish Phonetics - Task 2 - Practical Exercises FINISHED WITH LINKjonathanmplusÎncă nu există evaluări
- CV - Muhsin Mashkur-1Document7 paginiCV - Muhsin Mashkur-1Mokhter AhmadÎncă nu există evaluări
- Articles CommonDocument2 paginiArticles CommonAbdullah Al MamunÎncă nu există evaluări
- Koi Desh PunjaboN Sohna NaDocument12 paginiKoi Desh PunjaboN Sohna Nahirdaypallsingh2241Încă nu există evaluări
- Priority Queues With Simple Queue ServiceDocument6 paginiPriority Queues With Simple Queue Servicelokenders801Încă nu există evaluări
- Dokumen - Tips Yue Liang Dai Biao Wo de Xin Fingerstyle TabDocument3 paginiDokumen - Tips Yue Liang Dai Biao Wo de Xin Fingerstyle TabChristian NathanÎncă nu există evaluări
- WebDocument2 paginiWebHazimah SabarudinÎncă nu există evaluări