S-ar putea să vă placă și
- Amartya Sen's Capability Approach and Poverty AnalysisDocument18 paginiAmartya Sen's Capability Approach and Poverty AnalysisNurhadi K. SutrisnoÎncă nu există evaluări
- Zakaria, Sabri (2013) - Review of Financial Capability Studies PDFDocument7 paginiZakaria, Sabri (2013) - Review of Financial Capability Studies PDFRicardo IbarraÎncă nu există evaluări
- Financial Access in Nepal: (Exploring The Feature of Deposit Accounts of A, B, C Class Bfis)Document25 paginiFinancial Access in Nepal: (Exploring The Feature of Deposit Accounts of A, B, C Class Bfis)Utsav Raj PantÎncă nu există evaluări
- EXL Acquisition Scorecard Reject Inference MethodologiesDocument13 paginiEXL Acquisition Scorecard Reject Inference MethodologiesTathagata MaityÎncă nu există evaluări
- Presentation On Hrps (Managing Middlescence) : By: Gagan Singh Poonam Chakraborty Anu Singhai Shishir JainDocument6 paginiPresentation On Hrps (Managing Middlescence) : By: Gagan Singh Poonam Chakraborty Anu Singhai Shishir JainshishiriperÎncă nu există evaluări
- The Green Revolution in IndiaDocument3 paginiThe Green Revolution in IndiaSantosh KumarÎncă nu există evaluări
- PLS-SEM Results Reporting FormatDocument46 paginiPLS-SEM Results Reporting FormatMohiuddin QureshiÎncă nu există evaluări
- ACasestudyof Environmental Accountingin Indiawithreferenceto JSWSteelDocument13 paginiACasestudyof Environmental Accountingin Indiawithreferenceto JSWSteelAditya LalÎncă nu există evaluări
- c3 3mazurDocument13 paginic3 3mazurDynn HaroÎncă nu există evaluări
- BM633Document11 paginiBM633Beenish AbbasÎncă nu există evaluări
- Persistent Forecasting of Disruptive TechnologiesDocument137 paginiPersistent Forecasting of Disruptive TechnologiesJeff BegleyÎncă nu există evaluări
- Best Practices For Developing Apache Kafka Applications On Confluent CloudDocument39 paginiBest Practices For Developing Apache Kafka Applications On Confluent CloudDeni DianaÎncă nu există evaluări
- Rural Cooperatives in The Digital Age - An Analysis of The Internet Presence and Degree of Maturity of Agri-Food Cooperatives' E-CommerceDocument12 paginiRural Cooperatives in The Digital Age - An Analysis of The Internet Presence and Degree of Maturity of Agri-Food Cooperatives' E-CommerceSeba FerreroÎncă nu există evaluări
- IIMBx Brochure - 8th AugDocument17 paginiIIMBx Brochure - 8th AugPradeepVemuriÎncă nu există evaluări
- This Study Resource WasDocument3 paginiThis Study Resource WasMumuÎncă nu există evaluări
- Attitudes & Job SatisfactionDocument44 paginiAttitudes & Job SatisfactionÃã Kâã Sh100% (1)
- Kalogeropoulos Study Design TalkDocument35 paginiKalogeropoulos Study Design TalkderieÎncă nu există evaluări
- Laporan ProgramDocument3 paginiLaporan ProgramRatha KumarÎncă nu există evaluări
- Individual Ambidexterity in SMEs Towards A Typology Aligning The Concept, Antecedents and OutcomesDocument33 paginiIndividual Ambidexterity in SMEs Towards A Typology Aligning The Concept, Antecedents and OutcomesnorshamsiahibrahimÎncă nu există evaluări
- PHD Thesis (Adnan Ahmad) - RedactedDocument346 paginiPHD Thesis (Adnan Ahmad) - RedactedmairaÎncă nu există evaluări
- ResumeDocument1 paginăResumeapi-280276751Încă nu există evaluări
- Siva GitaDocument60 paginiSiva GitadonzhangÎncă nu există evaluări
- Factors Affecting The Consumer's Adoption of E-Wallets in India: An Empirical StudyDocument14 paginiFactors Affecting The Consumer's Adoption of E-Wallets in India: An Empirical StudyAmanÎncă nu există evaluări
- Stata 11 Command Reference CardDocument5 paginiStata 11 Command Reference Cardtheage00Încă nu există evaluări
- CIA-3 Software Engineering: Name: Derin Ben Roberts Reg. No.: 1740136 Topic: Software DesignDocument10 paginiCIA-3 Software Engineering: Name: Derin Ben Roberts Reg. No.: 1740136 Topic: Software DesignDerin Ben100% (1)
- ECX5267 Answer Guide Unit1-4Document64 paginiECX5267 Answer Guide Unit1-4Jineth C. HettiarachchiÎncă nu există evaluări
- Machine Learning & Cloud: Advanced Certification inDocument16 paginiMachine Learning & Cloud: Advanced Certification inmanjul.dixitÎncă nu există evaluări
- Introduction To Data ScienceDocument17 paginiIntroduction To Data ScienceAbhinavreddy BÎncă nu există evaluări
- The Effect of Income Inequality On Human DevelopmentDocument18 paginiThe Effect of Income Inequality On Human Developmentpijangg00-1Încă nu există evaluări
- Impact of Digital Transformation On Employment in Banking SectorDocument6 paginiImpact of Digital Transformation On Employment in Banking SectorHARSH MALPANIÎncă nu există evaluări
- Implementation of EMRs, NigeriaDocument17 paginiImplementation of EMRs, NigeriaAsmamaw K.Încă nu există evaluări
- Stock Prediction Using Neural Networks and Evolution AlgorithmDocument13 paginiStock Prediction Using Neural Networks and Evolution AlgorithmIJRASETPublications100% (1)
- Gartner Reprint - Object Storageoct21Document20 paginiGartner Reprint - Object Storageoct21Wolf RichardÎncă nu există evaluări
- Theoretical Milestones in International Business: The Journey To International Entrepreneurship TheoryDocument22 paginiTheoretical Milestones in International Business: The Journey To International Entrepreneurship TheoryAssal NassabÎncă nu există evaluări
- IELTS Listening Actual Test Sec4Document7 paginiIELTS Listening Actual Test Sec4Anonymous N6ccr9MVÎncă nu există evaluări
- A Way Towards Revamping Dynamic Capability Framework A Coherent Approach Towards Superior Firm's PerformanceDocument18 paginiA Way Towards Revamping Dynamic Capability Framework A Coherent Approach Towards Superior Firm's PerformanceApplied Research in Multidisciplinary Studies JournalÎncă nu există evaluări
- Cloud Computing World Issue 3 - December 2014 PDFDocument46 paginiCloud Computing World Issue 3 - December 2014 PDFwulandariweniÎncă nu există evaluări
- Esg 11Document31 paginiEsg 11AlexÎncă nu există evaluări
- Gertler 2004Document7 paginiGertler 2004Carla OrsuÎncă nu există evaluări
- MBA Orientation ProgrammeDocument63 paginiMBA Orientation Programmeraj_47671Încă nu există evaluări
- Financial Analysis of Banking Industry With Special Refference in Icici BankDocument135 paginiFinancial Analysis of Banking Industry With Special Refference in Icici Bankravi singhÎncă nu există evaluări
- SPSS Statistics 17.0: Companion Has Also Been Published by Prentice Hall. It Includes Overviews of TheDocument30 paginiSPSS Statistics 17.0: Companion Has Also Been Published by Prentice Hall. It Includes Overviews of TheScha Reel100% (1)
- IT Masters CloudDocument21 paginiIT Masters CloudMurad sulemanÎncă nu există evaluări
- Discuss The Three Approaches of MIS DevelopmentDocument2 paginiDiscuss The Three Approaches of MIS Developmentndgharat100% (6)
- The Impact of Covid 19 On Human Resource Management Avoiding GeneralisationsDocument10 paginiThe Impact of Covid 19 On Human Resource Management Avoiding GeneralisationsChethan N MÎncă nu există evaluări
- India: Skilled Migration To Developed Countries, Labour Migration To The GulfDocument37 paginiIndia: Skilled Migration To Developed Countries, Labour Migration To The Gulfaman.4uÎncă nu există evaluări
- What's New in z/OS V2.5: Marna WALLE IBM System Z Poughkeepsie, New York USA November 2021 Session 7ACDocument132 paginiWhat's New in z/OS V2.5: Marna WALLE IBM System Z Poughkeepsie, New York USA November 2021 Session 7ACfrpinaÎncă nu există evaluări
- 8 Dimensions of Product Quality David GarvinDocument1 pagină8 Dimensions of Product Quality David GarvinPiyush PareekÎncă nu există evaluări
- Econometrics Revision WorkDocument6 paginiEconometrics Revision WorkCarlos Ferreira100% (6)
- McCARTHY Et Al (2006) A Proposal For The Dartmouth Summer Research Project On Artificial IntelligenceDocument3 paginiMcCARTHY Et Al (2006) A Proposal For The Dartmouth Summer Research Project On Artificial IntelligenceRobertoÎncă nu există evaluări
- Law of Variable ProportionsDocument6 paginiLaw of Variable ProportionsDeepashikhaÎncă nu există evaluări
- NOTES-Business Env.Document8 paginiNOTES-Business Env.Chitra MukimÎncă nu există evaluări
- Can The Bunny Hop Data (Positioning)Document15 paginiCan The Bunny Hop Data (Positioning)Bhargav Sri DhavalaÎncă nu există evaluări
- Unit 2 (Cloud Computing Architecture)Document22 paginiUnit 2 (Cloud Computing Architecture)Binay YadavÎncă nu există evaluări
- Financial Inclusion Through Karad Urban Co Operative Bank, KaradDocument4 paginiFinancial Inclusion Through Karad Urban Co Operative Bank, KaradEditor IJTSRDÎncă nu există evaluări
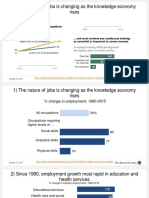
- 1) The Nature of Jobs Is Changing As The Knowledge Economy RisesDocument16 pagini1) The Nature of Jobs Is Changing As The Knowledge Economy Risesmeh3reÎncă nu există evaluări
- Nepal Rastra Bank Strategic Plan 2012-2016Document84 paginiNepal Rastra Bank Strategic Plan 2012-2016mkg_just4u8932100% (1)
- Factor, Cluster and Discriminant AnalysisDocument21 paginiFactor, Cluster and Discriminant AnalysisMadhuÎncă nu există evaluări
- The Entrepreneurial Higher Education Institution A Review-HeinnovateDocument14 paginiThe Entrepreneurial Higher Education Institution A Review-HeinnovateJeronimo SantosÎncă nu există evaluări
- How To Improve Your Skills As A Programmer: StepsDocument7 paginiHow To Improve Your Skills As A Programmer: StepsHarsh KhajuriaÎncă nu există evaluări
- VBA Class ModulesDocument31 paginiVBA Class ModulesAlina StanciuÎncă nu există evaluări
- Lecture 12-NormalizationDocument29 paginiLecture 12-NormalizationSaleh M.IbrahimÎncă nu există evaluări
- DB2 Adapter Send PortsDocument69 paginiDB2 Adapter Send PortsWai Leong WongÎncă nu există evaluări
- Scala Cheat Sheet AmreshDocument2 paginiScala Cheat Sheet AmreshBitCoin MiningÎncă nu există evaluări
- Introduction To Jackson Structured Programming (JSP) : LessonDocument12 paginiIntroduction To Jackson Structured Programming (JSP) : LessonAnubhav VermaÎncă nu există evaluări
- Views: Creating View: Create View View - Name As Select Query. Basically We Use Views ForDocument6 paginiViews: Creating View: Create View View - Name As Select Query. Basically We Use Views ForChandni SharmaÎncă nu există evaluări
- 50 - Apache Hive - CourseDocument57 pagini50 - Apache Hive - CourseAlz 02Încă nu există evaluări
- Namaste Javascript NotesDocument68 paginiNamaste Javascript NotesbedahutiÎncă nu există evaluări
- Lady or The TigerDocument4 paginiLady or The Tigerbajanuj5264Încă nu există evaluări
- Oliver Theobald Machine LearningDocument172 paginiOliver Theobald Machine LearningMuhammad amirÎncă nu există evaluări
- DMPM-LAB-04-Assignment: RcodeDocument11 paginiDMPM-LAB-04-Assignment: RcodeA-10- Amar-SaxenaÎncă nu există evaluări
- Tensorflow - Tensorflow 2.0 - 0 PDFDocument20 paginiTensorflow - Tensorflow 2.0 - 0 PDFGiorgioÎncă nu există evaluări
- Iit Sec 2008 TutorialDocument51 paginiIit Sec 2008 TutorialPhi Ra UchÎncă nu există evaluări
- Document Management System in PHP With Source Code - Source Code & ProjectsDocument9 paginiDocument Management System in PHP With Source Code - Source Code & ProjectsIssaka IddrisuÎncă nu există evaluări
- Computer Science 61ADocument60 paginiComputer Science 61ADaniel AuÎncă nu există evaluări
- Data Types Inn SQL ServerDocument2 paginiData Types Inn SQL Serverlatha sriÎncă nu există evaluări
- Lab: Title: Lab Objectives:: Pointer VariablesDocument14 paginiLab: Title: Lab Objectives:: Pointer Variableselshaday desalegnÎncă nu există evaluări
- LogDocument38 paginiLogAnite XhaferiÎncă nu există evaluări
- QUINDOSDocument20 paginiQUINDOStheflamebearerÎncă nu există evaluări
- IDAPython BookDocument40 paginiIDAPython BookShop MarketÎncă nu există evaluări
- C Lec 101-105Document29 paginiC Lec 101-105Karan SahuÎncă nu există evaluări
- CP - L05 - W03Document34 paginiCP - L05 - W03Ishmaal KhanÎncă nu există evaluări
- CVSourabh PatilDocument1 paginăCVSourabh PatilPrabha KaranÎncă nu există evaluări
- Artificial Neural NetworkDocument36 paginiArtificial Neural NetworkJboar TbenecdiÎncă nu există evaluări
- Middleworks Oracle Service Bus 12c Development Course SyllabusDocument3 paginiMiddleworks Oracle Service Bus 12c Development Course SyllabusYoussef MachhourÎncă nu există evaluări
- Hydrology 3Document1 paginăHydrology 3Engr AbirÎncă nu există evaluări
- Commit Log v1.1Document19 paginiCommit Log v1.1PauloÎncă nu există evaluări
- PPS All Units 2 MarksQuestions With AnswersDocument33 paginiPPS All Units 2 MarksQuestions With AnswersHARIKRISHNA SATVIKÎncă nu există evaluări
- OVERVIEW - Windows API - S and Internals - Reverse EngineeringDocument28 paginiOVERVIEW - Windows API - S and Internals - Reverse EngineeringFelipe RodriguesÎncă nu există evaluări
- OAF Component Reference Guide Release 12.1.3Document493 paginiOAF Component Reference Guide Release 12.1.3smartree100% (1)