S-ar putea să vă placă și
- Current Priorities of GovernmentDocument1 paginăCurrent Priorities of Governmentviktor6Încă nu există evaluări
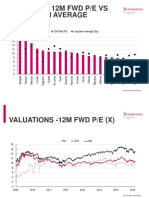
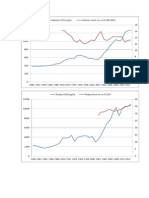
- Commercial Real Estate and The Economy v2Document20 paginiCommercial Real Estate and The Economy v2viktor6Încă nu există evaluări
- Anders Moden - Healed Sealed Soda PDFDocument10 paginiAnders Moden - Healed Sealed Soda PDFsqÎncă nu există evaluări
- Web CasesDocument54 paginiWeb CasesLucy Ngu SiÎncă nu există evaluări
- Fund Flows Geo Focus Table - 05022016Document1 paginăFund Flows Geo Focus Table - 05022016viktor6Încă nu există evaluări
- This Paper Is Not To Be Removed From The Examination HallsDocument9 paginiThis Paper Is Not To Be Removed From The Examination Hallsviktor6Încă nu există evaluări
- Silat Meeting 201112 NotesDocument3 paginiSilat Meeting 201112 Notesviktor6Încă nu există evaluări
- Minutes 28.04.13Document2 paginiMinutes 28.04.13viktor6Încă nu există evaluări
- Minutes 28.04.13Document2 paginiMinutes 28.04.13viktor6Încă nu există evaluări
- British LandDocument9 paginiBritish Landviktor6Încă nu există evaluări
- MSCI Nov15 INTSummaryDocument59 paginiMSCI Nov15 INTSummaryviktor6Încă nu există evaluări
- Renaissance Capital GEM Fund Flows Weekly ReportDocument1 paginăRenaissance Capital GEM Fund Flows Weekly Reportviktor6Încă nu există evaluări
- FRONTIER MARKETS VALUATIONS AND LIQUIDITY ANALYSISDocument10 paginiFRONTIER MARKETS VALUATIONS AND LIQUIDITY ANALYSISviktor6Încă nu există evaluări
- Frontier Pt2Document20 paginiFrontier Pt2viktor6Încă nu există evaluări
- Demidovich Problems in Mathematical AnalysisDocument495 paginiDemidovich Problems in Mathematical Analysisjwcstar7985100% (5)
- EMEA pt2Document20 paginiEMEA pt2viktor6Încă nu există evaluări
- Earnings QualityDocument16 paginiEarnings Qualityviktor6Încă nu există evaluări
- Frontier Pt1Document26 paginiFrontier Pt1viktor6Încă nu există evaluări
- EMEA pt1Document20 paginiEMEA pt1viktor6Încă nu există evaluări
- Turkey PakistanDocument1 paginăTurkey Pakistanviktor6Încă nu există evaluări
- BeyondDocument4 paginiBeyondviktor6Încă nu există evaluări
- Jeremy Silman - The Reassess Your Chess WorkbookDocument220 paginiJeremy Silman - The Reassess Your Chess Workbookalan_du2264590% (29)
- Singapore Institute of Management: University of London Preliminary Exam 2015Document5 paginiSingapore Institute of Management: University of London Preliminary Exam 2015viktor6Încă nu există evaluări
- Chapter SixDocument234 paginiChapter Sixviktor6Încă nu există evaluări
- Breastfeeding Policy Scorecard For Developed Countries-3Document1 paginăBreastfeeding Policy Scorecard For Developed Countries-3viktor6Încă nu există evaluări
- Sweezy CapitalismDocument5 paginiSweezy Capitalismviktor6Încă nu există evaluări
- Term Structures of Credit Spreads With Incomplete Accounting InformationDocument33 paginiTerm Structures of Credit Spreads With Incomplete Accounting Informationviktor6Încă nu există evaluări
- Investing in Canadian Stocks: The Casey Research Guide ToDocument19 paginiInvesting in Canadian Stocks: The Casey Research Guide Toviktor6Încă nu există evaluări
- HoldingsDocument4 paginiHoldingsviktor6Încă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- MCB and ELCB PDFDocument35 paginiMCB and ELCB PDFChris AntoniouÎncă nu există evaluări
- Structural Steel Design: Design of Tension Members 2: Universal College of ParañaqueDocument36 paginiStructural Steel Design: Design of Tension Members 2: Universal College of ParañaqueFritz LuzonÎncă nu există evaluări
- Applications of Redox ReactionsDocument50 paginiApplications of Redox ReactionsMlamuli MlarhÎncă nu există evaluări
- Solidworks Flow SimulationDocument7 paginiSolidworks Flow SimulationpatrickNX94200% (1)
- Energy Criteria in GRIHA PDFDocument71 paginiEnergy Criteria in GRIHA PDFAnisha Prakash100% (1)
- Kidney AnatomyDocument55 paginiKidney AnatomyMohammad zreadÎncă nu există evaluări
- A Git Cheat Sheet (Git Command Reference) - A Git Cheat Sheet and Command ReferenceDocument14 paginiA Git Cheat Sheet (Git Command Reference) - A Git Cheat Sheet and Command ReferenceMohd AzahariÎncă nu există evaluări
- Design of Weirs and BarragesDocument42 paginiDesign of Weirs and BarragesDivyaSlp100% (2)
- Guaranteed Restore Points Oracle 11g - Flash Back to SCN or RP (39Document2 paginiGuaranteed Restore Points Oracle 11g - Flash Back to SCN or RP (39PraveenÎncă nu există evaluări
- List of Practical Cs With SolutionDocument57 paginiList of Practical Cs With SolutionArjun KalaÎncă nu există evaluări
- Ductile deformation finite strain analysisDocument27 paginiDuctile deformation finite strain analysisJorgeBarriosMurielÎncă nu există evaluări
- Thermocouple Wire Reference Guide: WWW - Omega.co - Uk +44 (0) 161 777 6611 WWW - Omega.co - Uk +44 (0) 161 777 6611Document1 paginăThermocouple Wire Reference Guide: WWW - Omega.co - Uk +44 (0) 161 777 6611 WWW - Omega.co - Uk +44 (0) 161 777 6611Mohamed MaltiÎncă nu există evaluări
- MATLAB ApplicationsDocument252 paginiMATLAB Applicationsmadhuri nimseÎncă nu există evaluări
- Cost Estimation TechniquesDocument41 paginiCost Estimation TechniquessubashÎncă nu există evaluări
- Properties of Common Liquids Solids and Foods 2Document2 paginiProperties of Common Liquids Solids and Foods 2Šhëënà de LeonÎncă nu există evaluări
- Nextion InstructionDocument53 paginiNextion InstructionMacp63 cpÎncă nu există evaluări
- DS White-Papers Getting Started With Business Logic 3DEXPERIENCE R2017x V1Document52 paginiDS White-Papers Getting Started With Business Logic 3DEXPERIENCE R2017x V1AlexandreÎncă nu există evaluări
- Balmer PDFDocument3 paginiBalmer PDFVictor De Paula VilaÎncă nu există evaluări
- Biology Notes HSCDocument107 paginiBiology Notes HSCGouri DasÎncă nu există evaluări
- Tut 5. Two-Column Hammerhead Pier PDFDocument35 paginiTut 5. Two-Column Hammerhead Pier PDFOscar Varon BarbosaÎncă nu există evaluări
- An Intelligent Algorithm For The Protection of Smart Power SystemsDocument8 paginiAn Intelligent Algorithm For The Protection of Smart Power SystemsAhmed WestministerÎncă nu există evaluări
- Modeling and Control of 2-DOF Robot ArmDocument8 paginiModeling and Control of 2-DOF Robot ArmOtter OttersÎncă nu există evaluări
- Debating Deponency: Its Past, Present, and Future in New Testament Greek StudiesDocument32 paginiDebating Deponency: Its Past, Present, and Future in New Testament Greek StudiesSeth BrownÎncă nu există evaluări
- Fix Disk & Partition ErrorsDocument2 paginiFix Disk & Partition Errorsdownload181Încă nu există evaluări
- IMS2 Manual EngDocument61 paginiIMS2 Manual EngJhonatan BuenoÎncă nu există evaluări
- Mbs Public School: Topic: Study The Presence of Oxalate Ions in Guava Fruit at Different Stages of RipeningDocument15 paginiMbs Public School: Topic: Study The Presence of Oxalate Ions in Guava Fruit at Different Stages of RipeningSwaraj Patel100% (1)
- 1900.65A Monitor DatasheetDocument26 pagini1900.65A Monitor DatasheetAncuța DanielÎncă nu există evaluări
- The BCA (1) 23Document36 paginiThe BCA (1) 23Aurobind DasÎncă nu există evaluări
- Sling PsychrometerDocument8 paginiSling PsychrometerPavaniÎncă nu există evaluări