S-ar putea să vă placă și
- FPGA Workshop User Manual Ver2Document78 paginiFPGA Workshop User Manual Ver2jack_zia5073Încă nu există evaluări
- Cadence IntroductionDocument15 paginiCadence Introductiondragos_bondÎncă nu există evaluări
- Ece5745 Tut5 PT PDFDocument5 paginiEce5745 Tut5 PT PDFStudentÎncă nu există evaluări
- ADPLL Design and Implementation On FPGADocument6 paginiADPLL Design and Implementation On FPGANavathej BangariÎncă nu există evaluări
- Lect08 GM ID Sizing MethodDocument55 paginiLect08 GM ID Sizing MethodAmith NayakÎncă nu există evaluări
- Fpga Programming Using Verilog HDL LanguageDocument89 paginiFpga Programming Using Verilog HDL LanguageSidhartha Sankar Rout0% (1)
- Place & Route Tutorial #1: I. SetupDocument13 paginiPlace & Route Tutorial #1: I. SetupDurgaPrasadÎncă nu există evaluări
- Calibre Perc Ds PDFDocument2 paginiCalibre Perc Ds PDFashwini32Încă nu există evaluări
- Cadence Handout v3 (OTA)Document34 paginiCadence Handout v3 (OTA)Minu PriyaÎncă nu există evaluări
- VHDL PDFDocument112 paginiVHDL PDFvivek patelÎncă nu există evaluări
- WA1.3 Bhat PaperDocument16 paginiWA1.3 Bhat PaperShashank Mishra100% (1)
- Product OverviewDocument9 paginiProduct OverviewUsha KrishnaÎncă nu există evaluări
- CADENCE Custom IC Flow (Digital/Analog)Document85 paginiCADENCE Custom IC Flow (Digital/Analog)Banerjee AnirbanÎncă nu există evaluări
- Pre Final Sem Project ReportDocument79 paginiPre Final Sem Project Reportapi-301719207Încă nu există evaluări
- SCT 4 Platform Design Spec Rev1 4 PDFDocument62 paginiSCT 4 Platform Design Spec Rev1 4 PDFChhoemSovannÎncă nu există evaluări
- Image Processing Using Fpgas: ImagingDocument4 paginiImage Processing Using Fpgas: ImagingAnonymous s516rsÎncă nu există evaluări
- Asic Design Flow Tutorial 3228glDocument138 paginiAsic Design Flow Tutorial 3228glMahesh Reddy MandapatiÎncă nu există evaluări
- Cadence Virtuoso Spectre - Virtuoso - MmsimDocument12 paginiCadence Virtuoso Spectre - Virtuoso - MmsimParker333Încă nu există evaluări
- VLSI Design TechniquesDocument119 paginiVLSI Design Techniquesrajesh26julyÎncă nu există evaluări
- Allegro15 7TrainingBook1-11918Document504 paginiAllegro15 7TrainingBook1-11918Văn CôngÎncă nu există evaluări
- QRC Extraction DsDocument5 paginiQRC Extraction DsLakshman YandapalliÎncă nu există evaluări
- Expanding The Synopsys Primetime Solution With Power AnalysisDocument7 paginiExpanding The Synopsys Primetime Solution With Power AnalysisRamakrishnaRao SoogooriÎncă nu există evaluări
- ADSD Lab Manual For M. Tech. VLSI & Embdeed System I SemDocument121 paginiADSD Lab Manual For M. Tech. VLSI & Embdeed System I SemNitin SonuÎncă nu există evaluări
- Quartus Command LineDocument26 paginiQuartus Command LineAbed MomaniÎncă nu există evaluări
- Short Channel EffectsDocument27 paginiShort Channel Effectsilg10% (1)
- Introduction To VHDLDocument88 paginiIntroduction To VHDLpusd_90Încă nu există evaluări
- Low Power Design of Digital SystemsDocument28 paginiLow Power Design of Digital SystemssuperECEÎncă nu există evaluări
- Haps-54 March2009 ManualDocument74 paginiHaps-54 March2009 Manualjohn92691Încă nu există evaluări
- Nirma University Institute of Technology: B. Tech. in Electronics and Communication Engineering Semester - VDocument15 paginiNirma University Institute of Technology: B. Tech. in Electronics and Communication Engineering Semester - VPragya jhalaÎncă nu există evaluări
- ReadmeDocument1.338 paginiReadmepoojabadiger100% (1)
- 28Nm and Below, New Path and Beyond: Danny Rittman PHDDocument15 pagini28Nm and Below, New Path and Beyond: Danny Rittman PHDAbhesh Kumar TripathiÎncă nu există evaluări
- DSDV MODULE 3 Implementation FabricsDocument17 paginiDSDV MODULE 3 Implementation Fabricssalman shariffÎncă nu există evaluări
- Vlsi ppts1-1Document63 paginiVlsi ppts1-1naveensilveriÎncă nu există evaluări
- 1.FPGA Design Flow Processes PropertiesDocument5 pagini1.FPGA Design Flow Processes Propertiesmachnik1486624Încă nu există evaluări
- Dijsktra ThesisDocument65 paginiDijsktra ThesisGupta AakashÎncă nu există evaluări
- Introduction To RISC-VDocument31 paginiIntroduction To RISC-VsantydÎncă nu există evaluări
- Design and Modeling of I2C Bus ControllerDocument49 paginiDesign and Modeling of I2C Bus ControllerAmareshChaligeriÎncă nu există evaluări
- pg055 Axi Bridge Pcie PDFDocument117 paginipg055 Axi Bridge Pcie PDFattilismÎncă nu există evaluări
- SAR ADC TutorialDocument13 paginiSAR ADC Tutorialvigneshk100% (3)
- Product How To Fully Utilize TSMC S 28HPC ProcessDocument8 paginiProduct How To Fully Utilize TSMC S 28HPC ProcessvpsampathÎncă nu există evaluări
- Master Thesis: Design and Implementation of A DDR Sdram Controller For System On ChipDocument89 paginiMaster Thesis: Design and Implementation of A DDR Sdram Controller For System On ChipAparna TiwariÎncă nu există evaluări
- VHDL Coding Tips and TricksDocument209 paginiVHDL Coding Tips and TricksvinutaÎncă nu există evaluări
- Design Verification Engineer RTL in Austin TX Resume Sumaira KhowajaDocument3 paginiDesign Verification Engineer RTL in Austin TX Resume Sumaira KhowajaSumairaKhowaja4Încă nu există evaluări
- ADS2012 QuickRererenceGuideDocument90 paginiADS2012 QuickRererenceGuidexubuliÎncă nu există evaluări
- VLSI Design LabDocument47 paginiVLSI Design LabqwertyuiopÎncă nu există evaluări
- 3D IC DFT Chen SNUGDocument9 pagini3D IC DFT Chen SNUGUmesh ParasharÎncă nu există evaluări
- Eetop - CN MMIC DesignDocument207 paginiEetop - CN MMIC DesignA Mohan BabuÎncă nu există evaluări
- Considerations For Writing UPF For A Hierarchical Flow: Scope vs. HierarchyDocument9 paginiConsiderations For Writing UPF For A Hierarchical Flow: Scope vs. HierarchymanojkumarÎncă nu există evaluări
- Cadence Virtuoso Setup GuideDocument7 paginiCadence Virtuoso Setup Guidecold_faceÎncă nu există evaluări
- Modified Dual-Coupled Linear Congruential Generator Based Pseudorandom Bit GeneratorDocument11 paginiModified Dual-Coupled Linear Congruential Generator Based Pseudorandom Bit GeneratorGanesamoorthy BÎncă nu există evaluări
- Intel® Core™ Voltage Regulator-Down (VRD) 11.1 - Processor Power Delivery Design GuidelinesDocument132 paginiIntel® Core™ Voltage Regulator-Down (VRD) 11.1 - Processor Power Delivery Design Guidelinesaqua01Încă nu există evaluări
- Cmos Electronic PDFDocument356 paginiCmos Electronic PDFJustin WilliamsÎncă nu există evaluări
- MOS Device Physics FinalDocument15 paginiMOS Device Physics FinalnaniÎncă nu există evaluări
- Ece5745 Tut2 DCDocument15 paginiEce5745 Tut2 DCMisbahÎncă nu există evaluări
- Digital Design Through Verilog-18 PDFDocument31 paginiDigital Design Through Verilog-18 PDFAnanth G NÎncă nu există evaluări
- John Williams Star-WarsDocument2 paginiJohn Williams Star-WarsMiriam NachtigallÎncă nu există evaluări
- New File Trade Heroes ofDocument1 paginăNew File Trade Heroes ofKelly FilettaÎncă nu există evaluări
- InfoDocument1 paginăInfoKelly FilettaÎncă nu există evaluări
- Week 11 Economic Examination QuestionsDocument2 paginiWeek 11 Economic Examination QuestionsKelly FilettaÎncă nu există evaluări
- File PDFDocument1 paginăFile PDFKelly FilettaÎncă nu există evaluări
- U.N. CorruptionDocument16 paginiU.N. CorruptionKelly FilettaÎncă nu există evaluări
- A330 A340 PDP Rev09Document1 paginăA330 A340 PDP Rev09Kelly Filetta0% (1)
- Dessler Hrm12 Tif12Document41 paginiDessler Hrm12 Tif12Kelly FilettaÎncă nu există evaluări
- Disconnect To Reconnect by Pierre Therond - IntroDocument12 paginiDisconnect To Reconnect by Pierre Therond - Introwire-of-InformationÎncă nu există evaluări
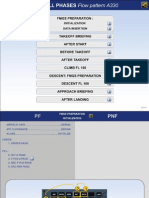
- All Phases - Flow Pattern A330Document14 paginiAll Phases - Flow Pattern A330Kelly Filetta88% (8)
- Dessler Hrm12 Tif12Document41 paginiDessler Hrm12 Tif12Kelly FilettaÎncă nu există evaluări
- Print Backup Verification Codes: CloseDocument1 paginăPrint Backup Verification Codes: CloseKelly FilettaÎncă nu există evaluări
- Eoi 06 01 2015Document1 paginăEoi 06 01 2015Kelly FilettaÎncă nu există evaluări
- 330 IncidentDocument428 pagini330 IncidentKelly FilettaÎncă nu există evaluări
- Guide Cover LettersDocument4 paginiGuide Cover LettersSilver DobellÎncă nu există evaluări
- AleksandarKrculj - Pedagoška Istraživanja U Fizici - Teme I LiteraturaDocument3 paginiAleksandarKrculj - Pedagoška Istraživanja U Fizici - Teme I LiteraturaKelly FilettaÎncă nu există evaluări
- Hypochlorous Acid: Its Multiple Uses For Wound CareDocument3 paginiHypochlorous Acid: Its Multiple Uses For Wound CareKelly FilettaÎncă nu există evaluări
- Samuel Glasstone - Thermodynamics For Chemists PDFDocument532 paginiSamuel Glasstone - Thermodynamics For Chemists PDFRimmon Singh100% (2)
- Computer BitsDocument1 paginăComputer BitsKelly FilettaÎncă nu există evaluări
- MIS Chlorine in WaterDocument5 paginiMIS Chlorine in WaterKelly FilettaÎncă nu există evaluări
- ZZZDocument1 paginăZZZKelly FilettaÎncă nu există evaluări
- Am Opodis09Document15 paginiAm Opodis09Kelly FilettaÎncă nu există evaluări
- Automated Attendance Based On Facial Recognition Using Matlab and ArduinoDocument69 paginiAutomated Attendance Based On Facial Recognition Using Matlab and ArduinoGhana Kiran100% (1)
- Exemple de Dissertation Sur Le CapitalismeDocument8 paginiExemple de Dissertation Sur Le CapitalismeCollegePaperHelpFargo100% (1)
- What'sNew SWOOD2019Document16 paginiWhat'sNew SWOOD2019Muhammad Bustan100% (1)
- Nortel CMDDocument1.054 paginiNortel CMDbarone_28Încă nu există evaluări
- AC - DC Power Supply Reference Design. Advanced SMPS Applications Using The Dspic DSC SMPS FamilyDocument37 paginiAC - DC Power Supply Reference Design. Advanced SMPS Applications Using The Dspic DSC SMPS Familymiengrong anhÎncă nu există evaluări
- Endurance Value SellingDocument33 paginiEndurance Value SellingRahul BharadwajÎncă nu există evaluări
- ADR-3000 System Introduction En122 PDFDocument28 paginiADR-3000 System Introduction En122 PDFJoseph BoshehÎncă nu există evaluări
- NEST I4.0: Nest I4.0 Integrates Your Entire Condition Monitoring ProgramDocument4 paginiNEST I4.0: Nest I4.0 Integrates Your Entire Condition Monitoring ProgramPedro RosaÎncă nu există evaluări
- Rot Op Robe ExDocument2 paginiRot Op Robe ExSiva KumarÎncă nu există evaluări
- 3.1 Storage Devices and MediaDocument21 pagini3.1 Storage Devices and MediaAqilah HasmawiÎncă nu există evaluări
- Vmware Vcenter Chargeback Costing CalculatorDocument7 paginiVmware Vcenter Chargeback Costing CalculatorJoaquim RossellóÎncă nu există evaluări
- Vendor Wira Makmur PratamaDocument1 paginăVendor Wira Makmur PratamaferyÎncă nu există evaluări
- ESPRIT Get StartedDocument182 paginiESPRIT Get StartedArtur Pereira Leite75% (4)
- Cenopdf User'S Manual: Lystech ComputingDocument112 paginiCenopdf User'S Manual: Lystech ComputingTheetaÎncă nu există evaluări
- How To Install XGW and VCS On A New PCDocument10 paginiHow To Install XGW and VCS On A New PCwisamsaluÎncă nu există evaluări
- AIX Vmo TunablesDocument26 paginiAIX Vmo Tunablesblade520Încă nu există evaluări
- SIPROTEC 5, Overcurrent Protection, Manual 9 C53000-G5040-C017-9, Edition 05.2018Document30 paginiSIPROTEC 5, Overcurrent Protection, Manual 9 C53000-G5040-C017-9, Edition 05.2018Nguyễn MẫnÎncă nu există evaluări
- Course Guide-CMSC311Document5 paginiCourse Guide-CMSC311Mark BernardinoÎncă nu există evaluări
- PIC16F15313Document518 paginiPIC16F15313mar_barudjÎncă nu există evaluări
- VT10-B21A - Datasheet - 20220718Document2 paginiVT10-B21A - Datasheet - 20220718TRANG LINDAÎncă nu există evaluări
- Google AdsDocument15 paginiGoogle AdsRituÎncă nu există evaluări
- Urit HL7 LIS Interface 8030 Dev Reference Manual (2020!08!20 02-50-44 UTC)Document22 paginiUrit HL7 LIS Interface 8030 Dev Reference Manual (2020!08!20 02-50-44 UTC)Arnoldo FelixÎncă nu există evaluări
- HP Office Jet 7110Document2 paginiHP Office Jet 7110kamlesh0106Încă nu există evaluări
- Freebitco - in Auto Roll Free BTC Freebitco - in NO Captcha WITH LOTTERY Auto Roll + 100 Reward Points + 1000% Bonus BTCDocument4 paginiFreebitco - in Auto Roll Free BTC Freebitco - in NO Captcha WITH LOTTERY Auto Roll + 100 Reward Points + 1000% Bonus BTCInternet To Cash0% (2)
- Sample Question Paper Final Cs 330Document5 paginiSample Question Paper Final Cs 330DurlavÎncă nu există evaluări
- 1624-MCA (Master of Computer Applications)Document39 pagini1624-MCA (Master of Computer Applications)Leonardo BaileyÎncă nu există evaluări
- OPC and DCOM-5 Things You Need To KnowDocument9 paginiOPC and DCOM-5 Things You Need To Knowmanuel99a2kÎncă nu există evaluări
- Preethi.K: Senior Software EngineerDocument5 paginiPreethi.K: Senior Software Engineersubash pradhanÎncă nu există evaluări
- Website: Vce To PDF Converter: Facebook: Twitter:: Hpe2-E71.Vceplus - Premium.Exam.60QDocument17 paginiWebsite: Vce To PDF Converter: Facebook: Twitter:: Hpe2-E71.Vceplus - Premium.Exam.60Qmally4dÎncă nu există evaluări
- Op3 Demo GuideDocument3 paginiOp3 Demo Guide4wocker4Încă nu există evaluări