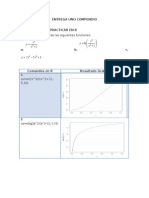
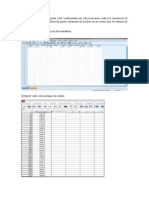
S-ar putea să vă placă și
- HW08S13 ROBERTOPEñA 20155567Document3 paginiHW08S13 ROBERTOPEñA 20155567Birlon Sthill33% (3)
- TEMA 8. Prueba de HipótesisDocument53 paginiTEMA 8. Prueba de HipótesisBrayan GamboaÎncă nu există evaluări
- Modelos Experimentales Trabajo GrupalDocument33 paginiModelos Experimentales Trabajo GrupalCarlos Wilson Quinde ValdiviezoÎncă nu există evaluări
- Trabajo de PaolaDocument4 paginiTrabajo de Paolapaola perez100% (1)
- Tercer CorteDocument65 paginiTercer Cortejessica martinezÎncă nu există evaluări
- Actividad 1 Estados FinancierosDocument12 paginiActividad 1 Estados Financierosjessica martinezÎncă nu există evaluări
- Actividad 6Document13 paginiActividad 6jessica martinezÎncă nu există evaluări
- Mapas Mentales Tercer CorteDocument1 paginăMapas Mentales Tercer Cortejessica martinezÎncă nu există evaluări
- Estadistica Blog PortafolioDocument24 paginiEstadistica Blog Portafoliojessica martinezÎncă nu există evaluări
- Medidas de Asimetria y ApuntamientoDocument1 paginăMedidas de Asimetria y Apuntamientojessica martinezÎncă nu există evaluări
- Compendios 8,9,10Document10 paginiCompendios 8,9,10jessica martinezÎncă nu există evaluări
- Mapas ConceptualesDocument15 paginiMapas Conceptualesjessica martinez0% (1)
- Noticias EconòmicasDocument15 paginiNoticias Econòmicasjessica martinez100% (1)
- Compendio 5 y 6Document34 paginiCompendio 5 y 6jessica martinezÎncă nu există evaluări
- Tercer Corte Derecho LaboralDocument18 paginiTercer Corte Derecho Laboraljessica martinezÎncă nu există evaluări
- Ensayo Ipc e Ipp en ColombiaDocument2 paginiEnsayo Ipc e Ipp en Colombiajessica martinezÎncă nu există evaluări
- PortafolioDocument40 paginiPortafolioAngela TylerÎncă nu există evaluări
- Portafolio Derecho LaboralDocument43 paginiPortafolio Derecho Laboraljessica martinezÎncă nu există evaluări
- TALLER No. 2Document12 paginiTALLER No. 2jessica martinezÎncă nu există evaluări
- Portafolio Derecho WalvinDocument32 paginiPortafolio Derecho Walvinjessica martinezÎncă nu există evaluări
- Noticias Segundo CorteDocument5 paginiNoticias Segundo Cortejessica martinezÎncă nu există evaluări
- Sentencia Prestaciones SocialesDocument23 paginiSentencia Prestaciones Socialesjessica martinezÎncă nu există evaluări
- Portafolio Derecho LaboralDocument32 paginiPortafolio Derecho Laboraljessica martinezÎncă nu există evaluări
- Noticias EconòmicasDocument15 paginiNoticias Econòmicasjessica martinez100% (1)
- Segundo Corte Derecho LaboralDocument13 paginiSegundo Corte Derecho Laboraljessica martinezÎncă nu există evaluări
- Portafolio Derecho LaboralDocument32 paginiPortafolio Derecho Laboraljessica martinezÎncă nu există evaluări
- Curriculo MacroeconomiaDocument9 paginiCurriculo MacroeconomiaCesar A Hernandez HÎncă nu există evaluări
- Mapas ConceptualesDocument3 paginiMapas Conceptualesjessica martinez67% (3)
- Estadistica Blog PortafolioDocument24 paginiEstadistica Blog Portafoliojessica martinezÎncă nu există evaluări
- Noticias EconomicasDocument6 paginiNoticias Economicasjessica martinezÎncă nu există evaluări
- Mapas ConceptualesDocument3 paginiMapas Conceptualesjessica martinez67% (3)
- Mapas ConceptualesDocument3 paginiMapas Conceptualesjessica martinez67% (3)
- Diagrama de Gantt 2015-1 - MacroDocument10 paginiDiagrama de Gantt 2015-1 - MacroCesar A Hernandez HÎncă nu există evaluări
- Pregunta 1Document1 paginăPregunta 1J Cristopher Gamarra0% (2)
- Estadistica FinalDocument10 paginiEstadistica FinalYrene Thalia Vicos PajueloÎncă nu există evaluări
- Cusum y Mann-Kendall..Document4 paginiCusum y Mann-Kendall..Ëddÿ Jëff VâlëncîäÎncă nu există evaluări
- Metodosnumericos Taller Regresion ExponencialDocument2 paginiMetodosnumericos Taller Regresion Exponencialbsarmiento65Încă nu există evaluări
- Pregunta 7Document14 paginiPregunta 7LIZBETH LEONOR REYES ESQUIVELÎncă nu există evaluări
- Variables Aleatorias en ExcelDocument1 paginăVariables Aleatorias en ExcelCarolina Garces JimenezÎncă nu există evaluări
- Histogramas: Facultad de Estudios A DistanciaDocument6 paginiHistogramas: Facultad de Estudios A DistanciaAdriana Abigail Gómez GaliciaÎncă nu există evaluări
- Estadistica de P y QDocument11 paginiEstadistica de P y QSheiler Alvarado SanchezÎncă nu există evaluări
- Paso 5 - Presentación de Resultados - Grupo - 179Document22 paginiPaso 5 - Presentación de Resultados - Grupo - 179Marcelita ValenciaÎncă nu există evaluări
- Quiz Datos AgrupadosDocument3 paginiQuiz Datos AgrupadoscesarÎncă nu există evaluări
- Calculo de Tamaño de MuestraDocument3 paginiCalculo de Tamaño de MuestraJessica Rodriguez ReyesÎncă nu există evaluări
- Practica Calificada 1 Ei 2021 1 Estadistica Inferencial 18103Document5 paginiPractica Calificada 1 Ei 2021 1 Estadistica Inferencial 18103Fredh SanchezÎncă nu există evaluări
- Parte Sophia EstadisticaDocument10 paginiParte Sophia Estadisticagabriel castroÎncă nu există evaluări
- Trabajo EstadisticaDocument14 paginiTrabajo EstadisticaalejandraÎncă nu există evaluări
- Analisis Del Caso Teorema CentralDocument8 paginiAnalisis Del Caso Teorema Centralkarithoo korthezÎncă nu există evaluări
- Estadistica Formulas Anova, Regresion Lineal y MasDocument23 paginiEstadistica Formulas Anova, Regresion Lineal y MasoscarÎncă nu există evaluări
- Pablollumiluisa Estadística 5Document6 paginiPablollumiluisa Estadística 5Pablo LlumiluisaÎncă nu există evaluări
- Investigación Regresión Lineal Simple y MúltipleDocument16 paginiInvestigación Regresión Lineal Simple y MúltipleEdgar PLÎncă nu există evaluări
- Trabajo EstadisticaDocument4 paginiTrabajo EstadisticaValentina Ibañez correaÎncă nu există evaluări
- Ejercicio Semana 9 - Hecho en ClaseDocument3 paginiEjercicio Semana 9 - Hecho en ClaseSKY ClÎncă nu există evaluări
- Tabla Supuestos (Importante!)Document1 paginăTabla Supuestos (Importante!)Sebastian GuatameÎncă nu există evaluări
- Un Almacén de Venta de RepuestosDocument5 paginiUn Almacén de Venta de RepuestosMartha Liliana Gomez BayonaÎncă nu există evaluări
- Actividad de Puntos Evaluables - Escenario 6 - SEGUNDO BLOQUE-CIENCIAS BASICAS - VIRTUAL - ESTADÍSTICA 1 - (GRUPO B03)Document7 paginiActividad de Puntos Evaluables - Escenario 6 - SEGUNDO BLOQUE-CIENCIAS BASICAS - VIRTUAL - ESTADÍSTICA 1 - (GRUPO B03)Laura vanessa ortizÎncă nu există evaluări
- Pagina 70Document15 paginiPagina 70ayrtmoranÎncă nu există evaluări
- Final de Est-IIDocument2 paginiFinal de Est-IIalejandroÎncă nu există evaluări
- Guia de Practica 9-14Document11 paginiGuia de Practica 9-14MARIA ELVINA HUAMAN TARICUARIMAÎncă nu există evaluări