S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- 4Q Sampling Distribution of The Sample MeansDocument26 pagini4Q Sampling Distribution of The Sample MeansErnest TuazonÎncă nu există evaluări
- WTP Dan Ability To Pay PDFDocument15 paginiWTP Dan Ability To Pay PDFPriyono Eka PratiektoÎncă nu există evaluări
- CVM For Protected AreaDocument25 paginiCVM For Protected AreaPriyono Eka PratiektoÎncă nu există evaluări
- Common Nomenclature in WTPDocument21 paginiCommon Nomenclature in WTPPriyono Eka PratiektoÎncă nu există evaluări
- Likert ScaleDocument4 paginiLikert Scaleapi-305319592Încă nu există evaluări
- Higher Algebra - Hall & KnightDocument593 paginiHigher Algebra - Hall & KnightRam Gollamudi100% (2)
- Higher Algebra - Hall & KnightDocument593 paginiHigher Algebra - Hall & KnightRam Gollamudi100% (2)
- Test of Hypothesis: M. Shafiqur RahmanDocument31 paginiTest of Hypothesis: M. Shafiqur RahmanShyshob ahammedÎncă nu există evaluări
- ch6 SlidesDocument55 paginich6 SlidesHarry Apriansani GintingÎncă nu există evaluări
- Sampling Methods ReadingsDocument9 paginiSampling Methods ReadingsTengku Reza MaulanaÎncă nu există evaluări
- Case5 Market - Return Variance Covariance and BetaDocument2 paginiCase5 Market - Return Variance Covariance and BetaKhalil LaamiriÎncă nu există evaluări
- Airbnb - Price PredictionDocument9 paginiAirbnb - Price PredictionSujith KumarÎncă nu există evaluări
- Business Analytics 5E 5Th Edition Jeffrey D Camm Full ChapterDocument67 paginiBusiness Analytics 5E 5Th Edition Jeffrey D Camm Full Chaptermichael.lynch155100% (2)
- Public Service Perfomance During Covid-19 Pandemic Era in Surabaya, IndonesiaDocument9 paginiPublic Service Perfomance During Covid-19 Pandemic Era in Surabaya, IndonesiaInternational Journal of Innovative Science and Research TechnologyÎncă nu există evaluări
- 1categorical Data Analysis (Chi Square) June 2022Document194 pagini1categorical Data Analysis (Chi Square) June 2022Daniel AbomaÎncă nu există evaluări
- CIForMean LargeSample ActivityDocument8 paginiCIForMean LargeSample ActivityrgerergÎncă nu există evaluări
- Incanter Cheat SheetDocument1 paginăIncanter Cheat SheethammfistÎncă nu există evaluări
- Econ 1005 - Final Summer 2020 LastDocument8 paginiEcon 1005 - Final Summer 2020 LastKiller VÎncă nu există evaluări
- Bionic Turtle FRM Practice Questions P1.T2. Quantitative Analysis Chapter 12: Measuring Return, Volatility, and CorrelationDocument25 paginiBionic Turtle FRM Practice Questions P1.T2. Quantitative Analysis Chapter 12: Measuring Return, Volatility, and CorrelationChristian Rey MagtibayÎncă nu există evaluări
- Practice Midterm Exam 1 With AnswerDocument5 paginiPractice Midterm Exam 1 With AnsweremilyÎncă nu există evaluări
- Output Uji T DMC - DM: Group StatisticsDocument4 paginiOutput Uji T DMC - DM: Group Statisticssmk kp3Încă nu există evaluări
- AE 9-STATISTICAL TOOLS FinalsDocument2 paginiAE 9-STATISTICAL TOOLS FinalsJohn Mark PalapuzÎncă nu există evaluări
- Pengaruh Teknik Budidaya Terhadap Produksi Kopi (Coffea Spp. L.) MASYARAKAT KARODocument16 paginiPengaruh Teknik Budidaya Terhadap Produksi Kopi (Coffea Spp. L.) MASYARAKAT KARORuth ElferawiÎncă nu există evaluări
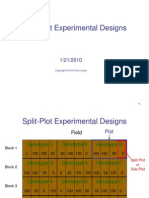
- Chapter9b. Split Plot Experiment 10april2011Document51 paginiChapter9b. Split Plot Experiment 10april2011Nor FaizahÎncă nu există evaluări
- Reading 7 Introduction To Linear RegressionDocument5 paginiReading 7 Introduction To Linear RegressionARPIT ARYAÎncă nu există evaluări
- STAT 2066EL Final Exam Review Problems CorrectedDocument6 paginiSTAT 2066EL Final Exam Review Problems CorrectedsafÎncă nu există evaluări
- Multiple Linear RegressionDocument59 paginiMultiple Linear RegressionAnett RáczÎncă nu există evaluări
- Independent Sample T TestDocument27 paginiIndependent Sample T TestManuel YeboahÎncă nu există evaluări
- Pooled Cross-Section Time Series DataDocument97 paginiPooled Cross-Section Time Series DatathiagarageÎncă nu există evaluări
- Measures of Central Tendency and Dispersion (Week-07)Document44 paginiMeasures of Central Tendency and Dispersion (Week-07)Sarmad Altaf Hafiz Altaf HussainÎncă nu există evaluări
- Pengaruh Desain Produk, Pengetahuan Produk, Dan Kesadaran Merek Terhadap Minat Beli Produk EigerDocument22 paginiPengaruh Desain Produk, Pengetahuan Produk, Dan Kesadaran Merek Terhadap Minat Beli Produk Eigergilang maulanaÎncă nu există evaluări
- HW 6Document7 paginiHW 6melankolia370Încă nu există evaluări
- Easc Ihstat v235Document3 paginiEasc Ihstat v235diogoscvÎncă nu există evaluări
- C. Chemistry 1 L2 Quality Management LectureDocument6 paginiC. Chemistry 1 L2 Quality Management LectureChelze Faith DizonÎncă nu există evaluări
- Linear Trend Projection: Deris & Dimayuga BSA 2Document16 paginiLinear Trend Projection: Deris & Dimayuga BSA 2natalie clyde matesÎncă nu există evaluări
- Stats NotesDocument7 paginiStats NotesMaryam HussainÎncă nu există evaluări