S-ar putea să vă placă și
- THE Ketofeed Diet Book v2Document43 paginiTHE Ketofeed Diet Book v2jacosta12100% (1)
- Cost-Effective Database Scalability Using Database ShardingDocument19 paginiCost-Effective Database Scalability Using Database ShardingSagar PhullÎncă nu există evaluări
- Neuroscience Core ConceptsDocument2 paginiNeuroscience Core Conceptseglantina alishollariÎncă nu există evaluări
- Content Analysis of Tea BrandsDocument49 paginiContent Analysis of Tea BrandsHumaRiaz100% (1)
- VirtualizationDocument11 paginiVirtualizationVidit AnejaÎncă nu există evaluări
- Ceph Reference ArchitectureDocument12 paginiCeph Reference ArchitectureGermgmaan100% (1)
- ToR Architecture Design 0109Document15 paginiToR Architecture Design 0109Anubhav SinhaÎncă nu există evaluări
- How To Do Virtualization: Your Step-By-Step Guide To VirtualizationDe la EverandHow To Do Virtualization: Your Step-By-Step Guide To VirtualizationÎncă nu există evaluări
- GA WP ArchitectingResilientPrivateClouds 0511Document16 paginiGA WP ArchitectingResilientPrivateClouds 0511onlyforaccountsÎncă nu există evaluări
- CacheCoherencyWhitepaper 6june2011 PDFDocument15 paginiCacheCoherencyWhitepaper 6june2011 PDFShashank MishraÎncă nu există evaluări
- Couchbase Server An Architectural OverviewDocument12 paginiCouchbase Server An Architectural OverviewAnonymous lKAN0M8AxÎncă nu există evaluări
- Exam AZ 900: Azure Fundamental Study Guide-1: Explore Azure Fundamental guide and Get certified AZ 900 examDe la EverandExam AZ 900: Azure Fundamental Study Guide-1: Explore Azure Fundamental guide and Get certified AZ 900 examÎncă nu există evaluări
- Bringing In-Memory Transaction Processing To The Masses: An Analysis of Microsoft SQL Server 2014 In-Memory OLTPDocument38 paginiBringing In-Memory Transaction Processing To The Masses: An Analysis of Microsoft SQL Server 2014 In-Memory OLTPLj ZazagasyÎncă nu există evaluări
- Bringing In-Memory Transaction Processing To The Masses: An Analysis of Microsoft SQL Server 2014 In-Memory OLTPDocument38 paginiBringing In-Memory Transaction Processing To The Masses: An Analysis of Microsoft SQL Server 2014 In-Memory OLTPeliaezekielÎncă nu există evaluări
- Clustering Lower CostDocument6 paginiClustering Lower CostbalkassangÎncă nu există evaluări
- Webcluster Guide en PDFDocument35 paginiWebcluster Guide en PDFRomaric TankoanoÎncă nu există evaluări
- Data Center Switching Solutions White PaperDocument15 paginiData Center Switching Solutions White PaperBon Tran HongÎncă nu există evaluări
- IO Workload in Virtualized Data Center Using HypervisorDocument5 paginiIO Workload in Virtualized Data Center Using HypervisorEditor IJRITCCÎncă nu există evaluări
- Database Sharding White Paper V1Document17 paginiDatabase Sharding White Paper V1Jason ProbertÎncă nu există evaluări
- Server Virtualization and Network Management: White PaperDocument8 paginiServer Virtualization and Network Management: White PaperSteve TaylorÎncă nu există evaluări
- A10 WP 21104 en PDFDocument8 paginiA10 WP 21104 en PDFĐỗ Công ThànhÎncă nu există evaluări
- Guide To Scaling Web Databases With MySQL ClusterDocument20 paginiGuide To Scaling Web Databases With MySQL ClustersergengÎncă nu există evaluări
- Oracle 10g Grid ComputingDocument9 paginiOracle 10g Grid Computingcpriyadba100% (2)
- Oracle Database 11g Power7Document8 paginiOracle Database 11g Power7Ruruh EstiningtyasÎncă nu există evaluări
- Resource Literature ReviewDocument5 paginiResource Literature ReviewpriyaÎncă nu există evaluări
- Server Virtualization ThesisDocument6 paginiServer Virtualization Thesisfexschhld100% (1)
- Beyond Nas Smartfiles A Transformative Approach To Unstructured DataDocument12 paginiBeyond Nas Smartfiles A Transformative Approach To Unstructured DataXavier Lubian SuarezÎncă nu există evaluări
- Ovm3 App Driven 459334Document9 paginiOvm3 App Driven 459334customvalemÎncă nu există evaluări
- ScalabilityDocument7 paginiScalabilityAina RaziqÎncă nu există evaluări
- CLUSTER COMPUTING ReportDocument15 paginiCLUSTER COMPUTING ReportvikasabcÎncă nu există evaluări
- What Is VirtualizationDocument1 paginăWhat Is VirtualizationKrishna ForuÎncă nu există evaluări
- Blade Servers: Evolution and RevolutionDocument5 paginiBlade Servers: Evolution and RevolutionrajmohandwivediÎncă nu există evaluări
- Brocade Cloud Optimized Performance Io Intensive Workloads WPDocument12 paginiBrocade Cloud Optimized Performance Io Intensive Workloads WPsushant_beuraÎncă nu există evaluări
- Colloquium Report: Future Institution OF Engg.&Technoloyg, BareillyDocument13 paginiColloquium Report: Future Institution OF Engg.&Technoloyg, BareillySumit KumarÎncă nu există evaluări
- Project Kittyhawk: Building A Global-Scale Computer: Blue Gene/P As A Generic Computing PlatformDocument8 paginiProject Kittyhawk: Building A Global-Scale Computer: Blue Gene/P As A Generic Computing PlatformKeri SawyerÎncă nu există evaluări
- Literature Review On Server VirtualizationDocument8 paginiLiterature Review On Server Virtualizationzgkuqhxgf100% (1)
- A New IT Management Model EmergesDocument24 paginiA New IT Management Model EmergesMohana Krishnan JanakiramanÎncă nu există evaluări
- Wp-Img-Building Applications For The CloudDocument15 paginiWp-Img-Building Applications For The CloudRandy MarmerÎncă nu există evaluări
- Thin Servers With Smart Pipes: Designing Soc Accelerators For MemcachedDocument12 paginiThin Servers With Smart Pipes: Designing Soc Accelerators For MemcachednewelljjÎncă nu există evaluări
- Cloud Computing: Ii Sem, MbaDocument11 paginiCloud Computing: Ii Sem, MbaSaurabh VermaÎncă nu există evaluări
- Server Infrastructure ProposalDocument5 paginiServer Infrastructure ProposalFadli ZainalÎncă nu există evaluări
- Oracle 10g: Infrastructure For Grid Computing: An Oracle White Paper September 2003Document15 paginiOracle 10g: Infrastructure For Grid Computing: An Oracle White Paper September 2003Naimish SolankiÎncă nu există evaluări
- 11g High AvailabilityDocument27 pagini11g High Availabilitydkr_mlrÎncă nu există evaluări
- Folding at Home - World's Greatest Chemistry Project: Cristian Mihai StancuDocument16 paginiFolding at Home - World's Greatest Chemistry Project: Cristian Mihai StancuiahimztoÎncă nu există evaluări
- Client Server Architecture 1229147658096208 1Document64 paginiClient Server Architecture 1229147658096208 1reenu_shuklaÎncă nu există evaluări
- Cloud 2Document53 paginiCloud 2GFx KidÎncă nu există evaluări
- System Models For Distributed and Cloud ComputingDocument22 paginiSystem Models For Distributed and Cloud Computingchamp riderÎncă nu există evaluări
- Nicira - The Seven Properties of VirtualizationDocument2 paginiNicira - The Seven Properties of Virtualizationtimdoug55Încă nu există evaluări
- Actian SQL in Hadoop Whitepaper FINALDRAFTDocument10 paginiActian SQL in Hadoop Whitepaper FINALDRAFTtrungquan710Încă nu există evaluări
- WS2008 Multi Site ClusteringDocument14 paginiWS2008 Multi Site Clusteringjeevan@netgccÎncă nu există evaluări
- Blad ServerDocument5 paginiBlad ServerbrutalxropÎncă nu există evaluări
- Advanced Load Balancing: 8 Must-Have Features For Today's Network DemandsDocument10 paginiAdvanced Load Balancing: 8 Must-Have Features For Today's Network Demandsvwvr9Încă nu există evaluări
- Oracle Database 11g High Availability: An Oracle White Paper June 2007Document27 paginiOracle Database 11g High Availability: An Oracle White Paper June 2007Ganesh SinghÎncă nu există evaluări
- Cloud Computing 18CS72: Microsoft Windows AzureDocument10 paginiCloud Computing 18CS72: Microsoft Windows AzureAnushaÎncă nu există evaluări
- High Performance SQL Server Workloads On Hyper-V White PaperDocument41 paginiHigh Performance SQL Server Workloads On Hyper-V White PaperDeepak Gupta (DG)Încă nu există evaluări
- To Converge or Not: Drama-Free Infrastructure Solutions For ITDocument13 paginiTo Converge or Not: Drama-Free Infrastructure Solutions For ITLuis BarretoÎncă nu există evaluări
- Virtualization Xeon Core Count Impacts Performance PaperDocument10 paginiVirtualization Xeon Core Count Impacts Performance Paperpro_naveenÎncă nu există evaluări
- BaadalDocument10 paginiBaadalAbdul KhaderÎncă nu există evaluări
- Oversubscription and Density Best PracticesDocument10 paginiOversubscription and Density Best PracticesCarlos Daniel TrujilloÎncă nu există evaluări
- WP High Availability Webrefarchs 362556Document29 paginiWP High Availability Webrefarchs 362556duongatnaÎncă nu există evaluări
- Data Centers en Union EuropeaDocument13 paginiData Centers en Union EuropeaGregory CalleÎncă nu există evaluări
- HRSK II NutzerschulungDocument111 paginiHRSK II Nutzerschulungmax müllerÎncă nu există evaluări
- PRIMEQUEST 2800E ConfigGuideDocument46 paginiPRIMEQUEST 2800E ConfigGuidemax müllerÎncă nu există evaluări
- PRIMEQUEST 2000series HardwareManualDocument58 paginiPRIMEQUEST 2000series HardwareManualmax müllerÎncă nu există evaluări
- PRIMEQUEST 2000series InstallManualDocument162 paginiPRIMEQUEST 2000series InstallManualmax müllerÎncă nu există evaluări
- IBM System x3250 M3: IBM Redbooks Product GuideDocument36 paginiIBM System x3250 M3: IBM Redbooks Product Guidemax müllerÎncă nu există evaluări
- Report System ZDocument64 paginiReport System Zmax müllerÎncă nu există evaluări
- IBM ZEnterprise System RedbookDocument194 paginiIBM ZEnterprise System Redbookmax müllerÎncă nu există evaluări
- SGI UV ArchitectureDocument12 paginiSGI UV Architecturemax müllerÎncă nu există evaluări
- K To 12 Math 7 Curriculum Guide PDFDocument15 paginiK To 12 Math 7 Curriculum Guide PDFEdmar Tan Fabi100% (1)
- Chapter 3 Mine Ventialtion ProblemDocument3 paginiChapter 3 Mine Ventialtion ProblemfahimÎncă nu există evaluări
- Tyler & Wheeler Curriculum ModelDocument8 paginiTyler & Wheeler Curriculum Modelliliyayanono100% (1)
- Avanquest Perfect Image V.12 User GuideDocument174 paginiAvanquest Perfect Image V.12 User GuideShafiq-UR-Rehman Lodhi100% (1)
- One God One People February 2013Document297 paginiOne God One People February 2013Stig DragholmÎncă nu există evaluări
- Keira Knightley: Jump To Navigation Jump To SearchDocument12 paginiKeira Knightley: Jump To Navigation Jump To SearchCrina LupuÎncă nu există evaluări
- Test Cases: Project Name: Virtual ClassroomDocument5 paginiTest Cases: Project Name: Virtual ClassroomTina HernandezÎncă nu există evaluări
- H I Ôn Thi Aptis & Vstep - Tài Liệu - Anna MaiDocument4 paginiH I Ôn Thi Aptis & Vstep - Tài Liệu - Anna Maihanh.mt2022Încă nu există evaluări
- Damask: by ChenoneDocument17 paginiDamask: by ChenoneYasir IjazÎncă nu există evaluări
- Maven MCQDocument55 paginiMaven MCQANNAPUREDDY ANIL KUMAR REDDY CSEÎncă nu există evaluări
- UniFi Quick GuideDocument2 paginiUniFi Quick GuideAndhika TharunaÎncă nu există evaluări
- L15 PDFDocument15 paginiL15 PDFlesÎncă nu există evaluări
- WHITE TOWN GROUP-4 FinalDocument112 paginiWHITE TOWN GROUP-4 Finalaswath manojÎncă nu există evaluări
- CR-805 Retransfer PrinterDocument2 paginiCR-805 Retransfer PrinterBolivio FelizÎncă nu există evaluări
- Advanced Power Electronics Corp.: AP70T03GH/JDocument4 paginiAdvanced Power Electronics Corp.: AP70T03GH/JVolodiyaÎncă nu există evaluări
- Analyse Bacterologique de L EauDocument6 paginiAnalyse Bacterologique de L Eaupeguy diffoÎncă nu există evaluări
- U04 Fxs of Humeral ShaftDocument88 paginiU04 Fxs of Humeral Shaftadrian_mogosÎncă nu există evaluări
- Maryam Ejaz Sec-A Marketing Assignment (CHP #15)Document3 paginiMaryam Ejaz Sec-A Marketing Assignment (CHP #15)MaryamÎncă nu există evaluări
- PD750-01 Engine Data Sheet 12-29-20Document4 paginiPD750-01 Engine Data Sheet 12-29-20Service Brags & Hayes, Inc.Încă nu există evaluări
- Basic: M1736N Model: MW73VR Model Code: Mw73Vr/BwtDocument42 paginiBasic: M1736N Model: MW73VR Model Code: Mw73Vr/Bwtsantiago962Încă nu există evaluări
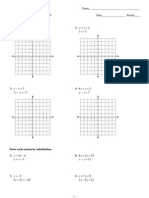
- Review Systems of Linear Equations All MethodsDocument4 paginiReview Systems of Linear Equations All Methodsapi-265647260Încă nu există evaluări
- STS Reviewer FinalsDocument33 paginiSTS Reviewer FinalsLeiÎncă nu există evaluări
- Et200sp Im 155 6 PN ST Manual en-US en-USDocument47 paginiEt200sp Im 155 6 PN ST Manual en-US en-USayaz officeÎncă nu există evaluări
- RCD ManagementDocument6 paginiRCD ManagementPindoterOÎncă nu există evaluări
- p1632 eDocument4 paginip1632 ejohn saenzÎncă nu există evaluări
- Syllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244Document3 paginiSyllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244M O H A N A V E LÎncă nu există evaluări
- Family History Timeline Rubric HonorsDocument1 paginăFamily History Timeline Rubric Honorsapi-291510568Încă nu există evaluări