S-ar putea să vă placă și
- Data WarehousingDocument15 paginiData WarehousingKunal26_MohapatraÎncă nu există evaluări
- Cloud Computing Security BreachesDocument54 paginiCloud Computing Security Breachesleon77bangaÎncă nu există evaluări
- IS AuditDocument27 paginiIS AuditSiddiqui JamilÎncă nu există evaluări
- It Service Continuity Management ItscmDocument4 paginiIt Service Continuity Management ItscmEmina Ahmed maeloumÎncă nu există evaluări
- Presentation Prepared By:: M.BalajiDocument18 paginiPresentation Prepared By:: M.BalajijeebalaÎncă nu există evaluări
- Switch RouterDocument201 paginiSwitch Routersasuke ChibiÎncă nu există evaluări
- Face Recognition TechnologyDocument3 paginiFace Recognition TechnologyijsretÎncă nu există evaluări
- Auditing in CIS Environment DISCUSSION 13Document7 paginiAuditing in CIS Environment DISCUSSION 13Yo Han SongÎncă nu există evaluări
- Core Banking System Implementation PropoDocument8 paginiCore Banking System Implementation PropoIsmael GirmaÎncă nu există evaluări
- What Is NESA Compliance - ValueMentorDocument5 paginiWhat Is NESA Compliance - ValueMentorSachin RatnakarÎncă nu există evaluări
- Unit - 1 PPT OF CYBERDocument50 paginiUnit - 1 PPT OF CYBERVishal GuptaÎncă nu există evaluări
- Common Data Model For Identity Access Management DataDocument45 paginiCommon Data Model For Identity Access Management DataWalter MacuadaÎncă nu există evaluări
- Incident Response Analytics Report enDocument8 paginiIncident Response Analytics Report enLeandro VereaÎncă nu există evaluări
- DFDDocument5 paginiDFDdada212121Încă nu există evaluări
- Business Continuity Risk ManagementDocument38 paginiBusiness Continuity Risk ManagementThilakPATHIRAGEÎncă nu există evaluări
- Threats and Attacks: CSE 4471: Information Security Instructor: Adam C. Champion, PH.DDocument26 paginiThreats and Attacks: CSE 4471: Information Security Instructor: Adam C. Champion, PH.Dswapnil RawatÎncă nu există evaluări
- KnowYourBroadband AIRTELDocument15 paginiKnowYourBroadband AIRTELRohit AgarwalÎncă nu există evaluări
- DCPP Flyer PDFDocument2 paginiDCPP Flyer PDFVicky PanditaÎncă nu există evaluări
- Security and Privacy For Big Data AnalyticsDocument5 paginiSecurity and Privacy For Big Data AnalyticslakshmiÎncă nu există evaluări
- Log Management Policy - GP 470kDocument3 paginiLog Management Policy - GP 470kMahmoud YounesÎncă nu există evaluări
- Ensuring Data Integrity in Storage: Techniques and ApplicationsDocument11 paginiEnsuring Data Integrity in Storage: Techniques and ApplicationsMiro PolgárÎncă nu există evaluări
- Azure FundamentalsDocument18 paginiAzure FundamentalsNicole XiangÎncă nu există evaluări
- ISO27k Model Policy On Change Management and ControlDocument10 paginiISO27k Model Policy On Change Management and Controlowais800Încă nu există evaluări
- HRIS Information SecurityDocument26 paginiHRIS Information SecurityJasminder SahniÎncă nu există evaluări
- Policy StatementDocument2 paginiPolicy StatementUnited CertificationÎncă nu există evaluări
- Data Retention Classes A Complete Guide - 2020 EditionDe la EverandData Retention Classes A Complete Guide - 2020 EditionÎncă nu există evaluări
- PCI DSS ControlsDocument21 paginiPCI DSS ControlsAayushi PradhanÎncă nu există evaluări
- Network Documentation A Complete Guide - 2020 EditionDe la EverandNetwork Documentation A Complete Guide - 2020 EditionÎncă nu există evaluări
- Information Security and Internal Audit - PresentationDocument23 paginiInformation Security and Internal Audit - Presentationadhi ulrichÎncă nu există evaluări
- BMC Service Level Management 7.6.03 - Configuration GuideDocument124 paginiBMC Service Level Management 7.6.03 - Configuration GuidepisofÎncă nu există evaluări
- IamDocument3 paginiIamBunnyÎncă nu există evaluări
- EndUser Backup PolicyDocument3 paginiEndUser Backup Policyaami6Încă nu există evaluări
- Information Backup and Restore PolicyDocument6 paginiInformation Backup and Restore PolicyvijetiÎncă nu există evaluări
- Governance OverviewDocument11 paginiGovernance OverviewM S Dharma SiregarÎncă nu există evaluări
- Lecture - IsPDMDocument105 paginiLecture - IsPDMKhurram SherazÎncă nu există evaluări
- Information Security ManualDocument19 paginiInformation Security ManualTrivesh SharmaÎncă nu există evaluări
- SearchDisasterRecovery Business Impact Analysis QuestionnaireDocument3 paginiSearchDisasterRecovery Business Impact Analysis Questionnairebarber bobÎncă nu există evaluări
- IT Infrastructure Deployment A Complete Guide - 2020 EditionDe la EverandIT Infrastructure Deployment A Complete Guide - 2020 EditionÎncă nu există evaluări
- IT Asset Management Best PracticesDocument5 paginiIT Asset Management Best PracticesGiorgos MichaelidesÎncă nu există evaluări
- Reading Sample Sappress 1481 Sap System Security GuideDocument39 paginiReading Sample Sappress 1481 Sap System Security GuideVitlenÎncă nu există evaluări
- Notes For Unit 5 Mobile Computing ArchitectureDocument29 paginiNotes For Unit 5 Mobile Computing ArchitectureDhruv BhandariÎncă nu există evaluări
- A6.1 Organization - v1Document7 paginiA6.1 Organization - v1Jerome MamauagÎncă nu există evaluări
- DWM Unit 4 Introduction To Data MiningDocument17 paginiDWM Unit 4 Introduction To Data MiningSp100% (1)
- Penetration Testing Report TemplateDocument9 paginiPenetration Testing Report TemplatemedtrachiÎncă nu există evaluări
- Outsourcing and Cloud PolicyDocument31 paginiOutsourcing and Cloud PolicyBert CruzÎncă nu există evaluări
- So sánh thuật toán cây quyết định ID3 và C45Document7 paginiSo sánh thuật toán cây quyết định ID3 và C45Long ThanhÎncă nu există evaluări
- Database Security and PrivacyDocument357 paginiDatabase Security and PrivacyKartik DwivediÎncă nu există evaluări
- Azure Data Catalog Short SetDocument23 paginiAzure Data Catalog Short SetBruno OliveiraÎncă nu există evaluări
- PM - 157 - Project Logistic and Infrastructure TemplateDocument4 paginiPM - 157 - Project Logistic and Infrastructure TemplateJarlei GoncalvesÎncă nu există evaluări
- It6afinals Application ControlsDocument2 paginiIt6afinals Application ControlsCarla Jean CuyosÎncă nu există evaluări
- CISSP-Identity and Access ManagementDocument4 paginiCISSP-Identity and Access ManagementGeelyn Marie LuzonÎncă nu există evaluări
- Top Web App Attack Methods and How To Combat Them: Dennis Hurst, SPI DynamicsDocument74 paginiTop Web App Attack Methods and How To Combat Them: Dennis Hurst, SPI DynamicsSridhar KrishnamurthiÎncă nu există evaluări
- 1Document277 pagini1Arash MohammadiÎncă nu există evaluări
- Security Pillar: AWS Well-Architected FrameworkDocument37 paginiSecurity Pillar: AWS Well-Architected FrameworkRaziwanÎncă nu există evaluări
- Pci Dss v4 0 Roc Aoc MerchantsDocument12 paginiPci Dss v4 0 Roc Aoc MerchantsAnil SÎncă nu există evaluări
- CS341 Software Quality Assurance and Testing - Tutorial2-SolutionDocument3 paginiCS341 Software Quality Assurance and Testing - Tutorial2-SolutionAman PrasadÎncă nu există evaluări
- DatabaseDocument53 paginiDatabaseIzza NasirÎncă nu există evaluări
- Eee4121f - Test - Solution - 2019 - Final PDFDocument7 paginiEee4121f - Test - Solution - 2019 - Final PDFObusitseÎncă nu există evaluări
- TechnicalSpecification SAP BIDocument6 paginiTechnicalSpecification SAP BIUjjaval BhalalaÎncă nu există evaluări
- Cloud Integration A Complete Guide - 2019 EditionDe la EverandCloud Integration A Complete Guide - 2019 EditionEvaluare: 5 din 5 stele5/5 (1)
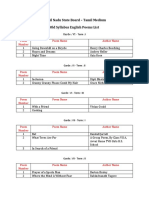
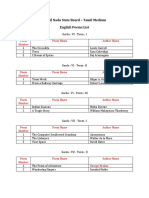
- 6-12 Old Syllabus SB English Poems ListDocument4 pagini6-12 Old Syllabus SB English Poems ListLindaÎncă nu există evaluări
- 6-12 Old Syllabus SB English Prose ListDocument4 pagini6-12 Old Syllabus SB English Prose ListLindaÎncă nu există evaluări
- 6-12 Old Syllabus SBEnglish Supplimentary ListDocument4 pagini6-12 Old Syllabus SBEnglish Supplimentary ListLindaÎncă nu există evaluări
- 6-12 State Board English Poems ListDocument3 pagini6-12 State Board English Poems ListLindaÎncă nu există evaluări
- Unit 1 PDFDocument27 paginiUnit 1 PDFLindaÎncă nu există evaluări
- Cambridge International Advanced Subsidiary LevelDocument12 paginiCambridge International Advanced Subsidiary LevelMayur MandhubÎncă nu există evaluări
- Project (Ravi Saxena) 2 PDFDocument11 paginiProject (Ravi Saxena) 2 PDFVishal SaxenaÎncă nu există evaluări
- Digital Fabrication in Architecture PDFDocument192 paginiDigital Fabrication in Architecture PDFAndrada Iulia NeagÎncă nu există evaluări
- Simplified Analysis of 'Out, Out' - Robert FrostDocument3 paginiSimplified Analysis of 'Out, Out' - Robert FrostSANDREA RUTHÎncă nu există evaluări
- A N S W e R-Accion PublicianaDocument9 paginiA N S W e R-Accion PublicianaEdward Rey EbaoÎncă nu există evaluări
- Batallon de San PatricioDocument13 paginiBatallon de San PatricioOmar Marín OropezaÎncă nu există evaluări
- Principles and Methods of Effective TeachingDocument5 paginiPrinciples and Methods of Effective TeachingerikaÎncă nu există evaluări
- 04 HPGD1103 T1Document24 pagini04 HPGD1103 T1aton hudaÎncă nu există evaluări
- Mediated Read Aloud Lesson PlanDocument4 paginiMediated Read Aloud Lesson PlanMandy KapellÎncă nu există evaluări
- What Does Nature MeanDocument9 paginiWhat Does Nature MeanSo DurstÎncă nu există evaluări
- The Importance of MoneyDocument9 paginiThe Importance of MoneyLinda FeiÎncă nu există evaluări
- Learning Area Grade Level Quarter Date: English 10 4Document4 paginiLearning Area Grade Level Quarter Date: English 10 4Yuki50% (8)
- The Creative Bureaucracy 2Document45 paginiThe Creative Bureaucracy 2IndirannaÎncă nu există evaluări
- Ratten V R (1974) HCA 35 (1974) 131 CLR 510 (25 September 1974)Document20 paginiRatten V R (1974) HCA 35 (1974) 131 CLR 510 (25 September 1974)Freya MehmeenÎncă nu există evaluări
- Applications of Digital - Image-Correlation Techniques To Experimental MechanicsDocument13 paginiApplications of Digital - Image-Correlation Techniques To Experimental MechanicsGustavo Felicio PerruciÎncă nu există evaluări
- Emasry@iugaza - Edu.ps: Islamic University of Gaza Statistics and Probability For Engineers ENCV 6310 InstructorDocument2 paginiEmasry@iugaza - Edu.ps: Islamic University of Gaza Statistics and Probability For Engineers ENCV 6310 InstructorMadhusudhana RaoÎncă nu există evaluări
- General ManagementDocument47 paginiGeneral ManagementRohit KerkarÎncă nu există evaluări
- Startup-Shutdown Oracle LinuxDocument4 paginiStartup-Shutdown Oracle LinuxJosé Florencio de QueirozÎncă nu există evaluări
- Lesson Plan Form Day 2 / 3 (4) Webquest Data GatheringDocument1 paginăLesson Plan Form Day 2 / 3 (4) Webquest Data GatheringMarkJLanzaÎncă nu există evaluări
- Grandinetti - Document No. 3Document16 paginiGrandinetti - Document No. 3Justia.comÎncă nu există evaluări
- Brochure 1st RMLNLU Kochhar Co. Arbitration Moot Court Competition 2023Document21 paginiBrochure 1st RMLNLU Kochhar Co. Arbitration Moot Court Competition 2023Rishi Raj MukherjeeÎncă nu există evaluări
- Research MethodologyDocument5 paginiResearch Methodologysonal gargÎncă nu există evaluări
- Mendezona vs. OzamizDocument2 paginiMendezona vs. OzamizAlexis Von TeÎncă nu există evaluări
- MA in Public Policy-Handbook-2016-17 (KCL)Document14 paginiMA in Public Policy-Handbook-2016-17 (KCL)Hon Wai LaiÎncă nu există evaluări
- Psychological Science1Document23 paginiPsychological Science1Jatin RaghavÎncă nu există evaluări
- Catherine The Great: Catherine II, Empress of RussiaDocument7 paginiCatherine The Great: Catherine II, Empress of RussiaLawrence James ParbaÎncă nu există evaluări
- Question Bank of Financial Management - 2markDocument16 paginiQuestion Bank of Financial Management - 2marklakkuMSÎncă nu există evaluări
- Orthogonal Curvilinear CoordinatesDocument16 paginiOrthogonal Curvilinear CoordinatesstriaukasÎncă nu există evaluări
- Tutorial-Midterm - CHEM 1020 General Chemistry - IB - AnsDocument71 paginiTutorial-Midterm - CHEM 1020 General Chemistry - IB - AnsWing Chi Rainbow TamÎncă nu există evaluări
- BANDAGINGDocument6 paginiBANDAGINGSweet BenitezÎncă nu există evaluări