S-ar putea să vă placă și
- 10 - Chapter 3 Security in M CommerceDocument39 pagini10 - Chapter 3 Security in M CommercehariharankalyanÎncă nu există evaluări
- 2 Marks Questions & Answers: Cs-73 Digital Signal Processing Iv Year / Vii Semester CseDocument18 pagini2 Marks Questions & Answers: Cs-73 Digital Signal Processing Iv Year / Vii Semester CsehariharankalyanÎncă nu există evaluări
- Finite Length Discrete Fourier TransformDocument23 paginiFinite Length Discrete Fourier TransformhariharankalyanÎncă nu există evaluări
- Blooms Taxonomy Action VerbsDocument1 paginăBlooms Taxonomy Action VerbsAmorBabe Tabasa-PescaderoÎncă nu există evaluări
- RarDocument42 paginiRarntc7035Încă nu există evaluări
- How Does FPGA Work: OutlineDocument17 paginiHow Does FPGA Work: OutlinehariharankalyanÎncă nu există evaluări
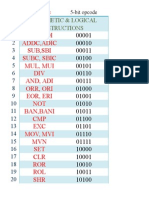
- Add, Adi Addc, Adic Sub, Sbi Subc, Sbic Mul, Mui DIV And, Adi Orr, Ori Eor, Eri NOT Ban, Bani CMP EXC Mov, Mvi MVN SET CLR ROR ROL SHRDocument2 paginiAdd, Adi Addc, Adic Sub, Sbi Subc, Sbic Mul, Mui DIV And, Adi Orr, Ori Eor, Eri NOT Ban, Bani CMP EXC Mov, Mvi MVN SET CLR ROR ROL SHRhariharankalyanÎncă nu există evaluări
- Assignment1 SolutionsDocument15 paginiAssignment1 SolutionshariharankalyanÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- 2 Mark (ED Questions)Document26 pagini2 Mark (ED Questions)Pradeep ravichanderÎncă nu există evaluări
- Circuit Theory: DR Paul S SpencerDocument13 paginiCircuit Theory: DR Paul S SpencerMathew ClewlowÎncă nu există evaluări
- Buck Converter Efficiency App-EDocument16 paginiBuck Converter Efficiency App-EmehdiÎncă nu există evaluări
- TV Sony Manual Service Kdl26m4000 Kdl32m4000 Kdl37m4000 Kdl40m4000Document114 paginiTV Sony Manual Service Kdl26m4000 Kdl32m4000 Kdl37m4000 Kdl40m4000reinaldoÎncă nu există evaluări
- Diagrama de Circuito DURABRAND ChinoDocument1 paginăDiagrama de Circuito DURABRAND ChinoArkadium ElectronicaÎncă nu există evaluări
- AMDemod Lab Op Amp Part 2Document9 paginiAMDemod Lab Op Amp Part 2shonchoyÎncă nu există evaluări
- QP THC-Q5713 Multi Skilled TechnicianDocument101 paginiQP THC-Q5713 Multi Skilled TechnicianABIR ADHIKARIÎncă nu există evaluări
- Beetel Blitz - Apr 28'ver11Document32 paginiBeetel Blitz - Apr 28'ver11sums_devÎncă nu există evaluări
- 132kV Connection Guide Version 9Document44 pagini132kV Connection Guide Version 9ElwanÎncă nu există evaluări
- New Mixer Behringer X18 P0AWZDocument25 paginiNew Mixer Behringer X18 P0AWZSalvatore NotoÎncă nu există evaluări
- Embedded Systems and Its ScopeDocument81 paginiEmbedded Systems and Its Scopenanobala15Încă nu există evaluări
- Mcmurdo E-5 Service ManualDocument42 paginiMcmurdo E-5 Service Manualsathish kumar100% (4)
- 05 NanomaterialsDocument28 pagini05 NanomaterialsVacker GuzelÎncă nu există evaluări
- 727 Manual 1Document31 pagini727 Manual 1Dadang Satyawan Padmanagara100% (2)
- Hill Hold ControlDocument4 paginiHill Hold ControlacairalexÎncă nu există evaluări
- Chapter 10: Vibration Isolation of The SourceDocument12 paginiChapter 10: Vibration Isolation of The SourceAshokÎncă nu există evaluări
- Transducers - 2.1 Sensors and Actuators - IOT2x Courseware - EdXDocument4 paginiTransducers - 2.1 Sensors and Actuators - IOT2x Courseware - EdXzaheeruddin_mohdÎncă nu există evaluări
- Audio Spotlighting - ECE Seminar TopicsDocument3 paginiAudio Spotlighting - ECE Seminar Topicsuday kumarÎncă nu există evaluări
- Akai Dv-p4785kdsm DVD PlayerDocument50 paginiAkai Dv-p4785kdsm DVD PlayerhussainArifÎncă nu există evaluări
- Manual SeguridadDocument47 paginiManual SeguridadJavier González OrduñaÎncă nu există evaluări
- Uniconn Operation Manual Addendum Subject: Operation of Phoenix Select Gauge With Uniconn Firmware: 1.200R1 Wellview Version 2.400R1Document11 paginiUniconn Operation Manual Addendum Subject: Operation of Phoenix Select Gauge With Uniconn Firmware: 1.200R1 Wellview Version 2.400R1ahmed elsheikhÎncă nu există evaluări
- 3G RNP Principles Nokia NSNDocument31 pagini3G RNP Principles Nokia NSNFahmi YasserÎncă nu există evaluări
- L - 02 - Calibration of The Testing SystemDocument60 paginiL - 02 - Calibration of The Testing SystemSanjaya PereraÎncă nu există evaluări
- WaveguidesDocument32 paginiWaveguidesPrajwal Rao100% (15)
- Electronic Troll System Using RfidDocument38 paginiElectronic Troll System Using RfidJashwanth ReddyÎncă nu există evaluări
- Biomerieux BacTAlert 3D 60 - Service ManualDocument332 paginiBiomerieux BacTAlert 3D 60 - Service ManualLeandro Humbert100% (1)
- Cedes: GLS 126 NT and GLS 151 NTDocument2 paginiCedes: GLS 126 NT and GLS 151 NTLoloy NorybÎncă nu există evaluări
- Level 2 Repair: 7-1. Components On The Rear CaseDocument8 paginiLevel 2 Repair: 7-1. Components On The Rear CaseJacobo FeijooÎncă nu există evaluări
- Unit 1Document33 paginiUnit 1nikiÎncă nu există evaluări
- Carte Tehnica UPS-uri Powertronix Quasar enDocument27 paginiCarte Tehnica UPS-uri Powertronix Quasar enEnsign Budi HandokoÎncă nu există evaluări