S-ar putea să vă placă și
- Embedded Systems Design: Pipelining and Instruction SchedulingDocument48 paginiEmbedded Systems Design: Pipelining and Instruction SchedulingMisbah Sajid ChaudhryÎncă nu există evaluări
- Pipe LiningDocument66 paginiPipe Liningsir.erlanÎncă nu există evaluări
- Lec07 Pipelining ReviewDocument121 paginiLec07 Pipelining ReviewdoomachaleyÎncă nu există evaluări
- Ca08 2014 PDFDocument54 paginiCa08 2014 PDFPance CvetkovskiÎncă nu există evaluări
- Parallel Processing Chapter - 3: Instruction Level ParallelismDocument33 paginiParallel Processing Chapter - 3: Instruction Level ParallelismGetu GeneneÎncă nu există evaluări
- Pipelining: Advanced Computer ArchitectureDocument30 paginiPipelining: Advanced Computer ArchitectureShinisg Vava100% (1)
- Content: - Introduction To Pipeline Hazard - Structural Hazard - Data Hazard - Control HazardDocument27 paginiContent: - Introduction To Pipeline Hazard - Structural Hazard - Data Hazard - Control HazardAhmed NabilÎncă nu există evaluări
- ILP - Appendix C PDFDocument52 paginiILP - Appendix C PDFDhananjay JahagirdarÎncă nu există evaluări
- Appendix ADocument93 paginiAppendix AzeewoxÎncă nu există evaluări
- Advanced Topics in Computer Architecture ECE 7373Document40 paginiAdvanced Topics in Computer Architecture ECE 7373razorviperÎncă nu există evaluări
- CS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariDocument82 paginiCS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariParmanand KhajuriyaÎncă nu există evaluări
- EE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Document35 paginiEE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Vishal MehtaÎncă nu există evaluări
- Ch2 Lec7 Instruction PipliningDocument34 paginiCh2 Lec7 Instruction PipliningAlazar DInberuÎncă nu există evaluări
- Module1 UPD W NotesDocument72 paginiModule1 UPD W NotesZhanzhi LiuÎncă nu există evaluări
- Chapter 2 Part FourDocument76 paginiChapter 2 Part FoursileÎncă nu există evaluări
- Approaches For Power Management Verification of SoC Having Dynamic Power and Voltage SwitchingDocument30 paginiApproaches For Power Management Verification of SoC Having Dynamic Power and Voltage SwitchingNageshwar ReddyÎncă nu există evaluări
- Lecture: Pipelining BasicsDocument28 paginiLecture: Pipelining BasicsTahsin Arik TusanÎncă nu există evaluări
- Pipelining Preview: Basics & ChallengesDocument75 paginiPipelining Preview: Basics & ChallengesdoomachaleyÎncă nu există evaluări
- Loops in Assembly Language: and Program DesignDocument23 paginiLoops in Assembly Language: and Program DesignAngelo Michael Clemente100% (1)
- Solution For Exam QuestionsDocument36 paginiSolution For Exam QuestionsakilantÎncă nu există evaluări
- CS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariDocument82 paginiCS 211: Computer Architecture: Instructor: Prof. Bhagi NarahariDuncan KingÎncă nu există evaluări
- UNIT-5: Pipeline and Vector ProcessingDocument63 paginiUNIT-5: Pipeline and Vector ProcessingAkash KankariaÎncă nu există evaluări
- UntitledDocument46 paginiUntitledGaurab GhoseÎncă nu există evaluări
- Chapter 5Document38 paginiChapter 5noussaiba.belhouariÎncă nu există evaluări
- 12 - Processor Structure and FunctionDocument73 pagini12 - Processor Structure and FunctionRao FaisalÎncă nu există evaluări
- CH 13.ppt Type IDocument35 paginiCH 13.ppt Type Iadele5eve55Încă nu există evaluări
- HRY-312 Computer Organization Introduction To PipeliningDocument30 paginiHRY-312 Computer Organization Introduction To Pipelininggami2Încă nu există evaluări
- Chapter 6Document71 paginiChapter 6K S Sanath KashyapÎncă nu există evaluări
- ILPDocument47 paginiILPvengat.mailbox5566Încă nu există evaluări
- 5 6Document26 pagini5 6cn3588Încă nu există evaluări
- Design of 3 Stage Pipelining Processor Using VHDLDocument22 paginiDesign of 3 Stage Pipelining Processor Using VHDLsdmdharwadÎncă nu există evaluări
- Lec04 Pipelining Intro&hazardsDocument77 paginiLec04 Pipelining Intro&hazardsdoomachaleyÎncă nu există evaluări
- 4-Concept of PipeliningDocument20 pagini4-Concept of Pipeliningtabin iftakharÎncă nu există evaluări
- More On PipeliningDocument34 paginiMore On PipeliningRAHA TUDU100% (1)
- Vector and Pipelined ProcessorsDocument12 paginiVector and Pipelined ProcessorsKeshav LamichhaneÎncă nu există evaluări
- Pipelining and ParallelismDocument41 paginiPipelining and ParallelismPratham GuptaÎncă nu există evaluări
- Instruction Level Parallelism: PipeliningDocument6 paginiInstruction Level Parallelism: PipeliningkbkkrÎncă nu există evaluări
- Computer Science 146 Computer ArchitectureDocument22 paginiComputer Science 146 Computer ArchitectureharshvÎncă nu există evaluări
- Computer Architecture 1st Semester Spring Session Unit 3Document33 paginiComputer Architecture 1st Semester Spring Session Unit 3mohsinmanzoorÎncă nu există evaluări
- Computer Architecture: Pipelining Khiyam IftikharDocument36 paginiComputer Architecture: Pipelining Khiyam IftikharHassan AsgharÎncă nu există evaluări
- Pipeline HazardsDocument94 paginiPipeline HazardsManasa RavelaÎncă nu există evaluări
- The Micro-Architecture Level: Ms - Chit Su MonDocument70 paginiThe Micro-Architecture Level: Ms - Chit Su MonAjharuddin AnsariÎncă nu există evaluări
- William Stallings Computer Organization and Architecture 8 Edition Instruction Level Parallelism and Superscalar ProcessorsDocument50 paginiWilliam Stallings Computer Organization and Architecture 8 Edition Instruction Level Parallelism and Superscalar ProcessorsMinkpoo Lexy UtomoÎncă nu există evaluări
- Unit - 1 Microprocessor ArchitectureDocument52 paginiUnit - 1 Microprocessor ArchitectureSasidhar NagisettyÎncă nu există evaluări
- Parallel ProcessingDocument127 paginiParallel ProcessingrichtomÎncă nu există evaluări
- Aca NotesDocument23 paginiAca NotesSriram JanakiramanÎncă nu există evaluări
- Lecture 13: Trace Scheduling, Conditional Execution, Speculation, Limits of ILPDocument21 paginiLecture 13: Trace Scheduling, Conditional Execution, Speculation, Limits of ILPBalasubramanian JayaramanÎncă nu există evaluări
- Assignment5 SolnDocument5 paginiAssignment5 Solnshantanu pathakÎncă nu există evaluări
- William Stallings Computer Organization and Architecture 8 EditionDocument38 paginiWilliam Stallings Computer Organization and Architecture 8 EditionNEOROVEÎncă nu există evaluări
- Two Forms of Pipelining: - E.g., Floating Point OperationsDocument36 paginiTwo Forms of Pipelining: - E.g., Floating Point OperationsslogeshwariÎncă nu există evaluări
- Computer Architecture: Exceptions, Interrupts and Multi Issue Processor Khiyam IftikharDocument18 paginiComputer Architecture: Exceptions, Interrupts and Multi Issue Processor Khiyam IftikharHassan AsgharÎncă nu există evaluări
- NDocument4 paginiNAzri Mohd Khanil0% (1)
- Endpoint Admission Control: Webtp Presentation 9/26/00 Presented by Ye XiaDocument21 paginiEndpoint Admission Control: Webtp Presentation 9/26/00 Presented by Ye Xiamattkoo2222Încă nu există evaluări
- Reduced Instruction Set Computers: William Stallings Computer Organization and Architecture 7 EditionDocument38 paginiReduced Instruction Set Computers: William Stallings Computer Organization and Architecture 7 EditionSaimo FortuneÎncă nu există evaluări
- FPGA Design TechniquesDocument32 paginiFPGA Design TechniquesRavindra SainiÎncă nu există evaluări
- Processor OrganizationDocument55 paginiProcessor OrganizationMinoshini Fonseka100% (1)
- Microprocessor System Design: A Practical IntroductionDe la EverandMicroprocessor System Design: A Practical IntroductionÎncă nu există evaluări
- PNEUMATICS AND AIR CIRCUITS UNDERSTANDING THE CASCADE VALVE AND PLC UNDERSTANDINGDe la EverandPNEUMATICS AND AIR CIRCUITS UNDERSTANDING THE CASCADE VALVE AND PLC UNDERSTANDINGÎncă nu există evaluări
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.De la EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Încă nu există evaluări
- Thin Walled Pressure Vessel: T/R 1 Usually R/T 10Document9 paginiThin Walled Pressure Vessel: T/R 1 Usually R/T 10NishanthoraÎncă nu există evaluări
- Introduction and Review: PreambleDocument127 paginiIntroduction and Review: PreambleNishanthoraÎncă nu există evaluări
- Stress ConcentrationDocument6 paginiStress ConcentrationNishanthoraÎncă nu există evaluări
- Strength of Materials: BEG256CI Year: 2 Semester: 1Document4 paginiStrength of Materials: BEG256CI Year: 2 Semester: 1NishanthoraÎncă nu există evaluări
- Booths AlgorithmDocument24 paginiBooths AlgorithmNishanthoraÎncă nu există evaluări
- Introduction To Parallel ProcessingDocument24 paginiIntroduction To Parallel ProcessingNishanthoraÎncă nu există evaluări
- Open GLDocument106 paginiOpen GLNishanthoraÎncă nu există evaluări
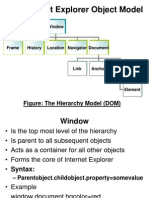
- The Internet Explorer Object ModelDocument7 paginiThe Internet Explorer Object ModelNishanthoraÎncă nu există evaluări
- 13 MemoryDocument13 pagini13 MemoryNishanthoraÎncă nu există evaluări
- Using NetshDocument15 paginiUsing NetshNishanthoraÎncă nu există evaluări
- EDS - NDrive ManualDocument115 paginiEDS - NDrive Manuallfba_16Încă nu există evaluări
- D10T Track-Type Tractor Power Train System: Rjg1-UpDocument2 paginiD10T Track-Type Tractor Power Train System: Rjg1-UpJHOSMAR_22Încă nu există evaluări
- Plastic Caps Moulding Machine Production & MaintenanceDocument204 paginiPlastic Caps Moulding Machine Production & MaintenancePeter Calvo90% (10)
- Tutorial MyrioDocument57 paginiTutorial MyrioLucky Pandu Melyanto100% (1)
- Abb Elog All181212Document68 paginiAbb Elog All181212Teo soon howÎncă nu există evaluări
- Modicon X80 Modules - BMXDRA0815Document5 paginiModicon X80 Modules - BMXDRA0815Blesson P VargheseÎncă nu există evaluări
- Arinc 579 VorDocument10 paginiArinc 579 VorJuanIgnacioÎncă nu există evaluări
- RRB Je Previous Year Paper 8thaug Shift2.PDF 51Document11 paginiRRB Je Previous Year Paper 8thaug Shift2.PDF 51sreenu mÎncă nu există evaluări
- Datasheet Processador MPC555 Usado Nos CooDocument50 paginiDatasheet Processador MPC555 Usado Nos CooRaphael Silveira de SouzaÎncă nu există evaluări
- Precicon-R Dcsim Data Resistor MapDocument3 paginiPrecicon-R Dcsim Data Resistor Mapputul deyÎncă nu există evaluări
- Chapter 10. Substitution Reactions of Alkyl HalidesDocument49 paginiChapter 10. Substitution Reactions of Alkyl HalidesThanh NguyênÎncă nu există evaluări
- GNU Radio lab: Instructor: Proff Do Trong Tuan Group: Kim Trung Hiếu Đỗ Thu Hà Tạ Thị Thanh Lâm DinaliDocument36 paginiGNU Radio lab: Instructor: Proff Do Trong Tuan Group: Kim Trung Hiếu Đỗ Thu Hà Tạ Thị Thanh Lâm DinaliThanh LâmÎncă nu există evaluări
- SY1 s17 s18 v12.01 DFDocument50 paginiSY1 s17 s18 v12.01 DFKhalid Khalifa AtyaÎncă nu există evaluări
- Abstract of Price Quotation: Supplier ParticularsDocument2 paginiAbstract of Price Quotation: Supplier ParticularsJaleann EspañolÎncă nu există evaluări
- How To Use This Competency-Based Learning MaterialDocument12 paginiHow To Use This Competency-Based Learning Materiallourdes estopaciaÎncă nu există evaluări
- Wireless Barcode Scanner Manual Guide: 32-Bit High-Speed CPUDocument2 paginiWireless Barcode Scanner Manual Guide: 32-Bit High-Speed CPUjuan perezÎncă nu există evaluări
- And 8030Document8 paginiAnd 8030varngoldÎncă nu există evaluări
- 1 - Electronic System Design Chapter 1 To 3 PDFDocument17 pagini1 - Electronic System Design Chapter 1 To 3 PDFneda ghiasiÎncă nu există evaluări
- System 4000 - SpecificationsDocument4 paginiSystem 4000 - SpecificationsshunkherÎncă nu există evaluări
- MS-MP01473 IT HandbookDocument30 paginiMS-MP01473 IT HandbookJayJayÎncă nu există evaluări
- PSCAD IntroductionDocument72 paginiPSCAD IntroductionksbwingsÎncă nu există evaluări
- Ieee 450Document2 paginiIeee 450ilmvmvm11Încă nu există evaluări
- Panasonic g30Document104 paginiPanasonic g30PuticMiroslavÎncă nu există evaluări
- Ec2401-Wireless Communication UniversityDocument10 paginiEc2401-Wireless Communication UniversityRajesh Kannan VÎncă nu există evaluări
- GDC31 DAC InternationalDocument72 paginiGDC31 DAC InternationalSeção EletricaÎncă nu există evaluări
- Vision Inspection Applied To Leather Quality ControlDocument3 paginiVision Inspection Applied To Leather Quality ControlchainleighÎncă nu există evaluări
- Water Injection: Atox 30.0 Vendor Instruction Other Information Plant Name: Ha LongDocument127 paginiWater Injection: Atox 30.0 Vendor Instruction Other Information Plant Name: Ha LongDuc Nguyen VanÎncă nu există evaluări
- Vibrations and WavesDocument38 paginiVibrations and WavesKiara De LeonÎncă nu există evaluări
- TA0289 User Manual Rev181017Document7 paginiTA0289 User Manual Rev181017LamÎncă nu există evaluări
- CES 410 Programing InfoDocument12 paginiCES 410 Programing InfoRoberto Carlos MárquezÎncă nu există evaluări