S-ar putea să vă placă și
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- How Einstein Formed RelativityDocument2 paginiHow Einstein Formed RelativityAbraham JyothimonÎncă nu există evaluări
- (Dewa-98%) Anova-Safety and Secuirty ScoreDocument6 pagini(Dewa-98%) Anova-Safety and Secuirty ScoreAbraham JyothimonÎncă nu există evaluări
- Permit Process FOR PV sYSTEMS PDFDocument82 paginiPermit Process FOR PV sYSTEMS PDFAbraham Jyothimon100% (1)
- Consept Mind Mapping PDFDocument23 paginiConsept Mind Mapping PDFDian FithriaÎncă nu există evaluări
- Notes On Work System Concepts1Document12 paginiNotes On Work System Concepts1Abraham JyothimonÎncă nu există evaluări
- Risk Sharing in JVsDocument162 paginiRisk Sharing in JVsAbraham JyothimonÎncă nu există evaluări
- GDL Louvre CalculatorDocument1 paginăGDL Louvre CalculatorAbraham JyothimonÎncă nu există evaluări
- Corrosion PDFDocument5 paginiCorrosion PDFAntonio MartinÎncă nu există evaluări
- Inequalities A Journey Into Linear Analysis - D. J. H. Garling, CUP 2007Document348 paginiInequalities A Journey Into Linear Analysis - D. J. H. Garling, CUP 2007mago622100% (2)
- Selton's Horse (Posterior Lottery Model)Document3 paginiSelton's Horse (Posterior Lottery Model)Abraham JyothimonÎncă nu există evaluări
- Iso 12944 PDFDocument4 paginiIso 12944 PDFAdana100% (1)
- Complex Measure &positive MeasureDocument1 paginăComplex Measure &positive MeasureAbraham JyothimonÎncă nu există evaluări
- E-Dilation (Prohorov Metric)Document19 paginiE-Dilation (Prohorov Metric)Abraham JyothimonÎncă nu există evaluări
- Planning by Minkowiski MetricDocument22 paginiPlanning by Minkowiski MetricAbraham JyothimonÎncă nu există evaluări
- Importance of Loop Impedance TesterDocument4 paginiImportance of Loop Impedance TesterAbraham JyothimonÎncă nu există evaluări
- Computer Organization and Design SolutionsDocument228 paginiComputer Organization and Design SolutionsJonathan Cui58% (12)
- Resource Allocation Mechanism-Detailed ProgtammingDocument27 paginiResource Allocation Mechanism-Detailed ProgtammingAbraham JyothimonÎncă nu există evaluări
- Survey Works Rev 1Document12 paginiSurvey Works Rev 1Abraham JyothimonÎncă nu există evaluări
- Short Guide On UAE Labour LawDocument5 paginiShort Guide On UAE Labour LawPc SubramaniÎncă nu există evaluări
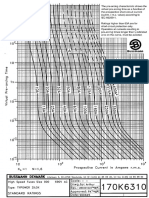
- Bussman CurvesDocument2 paginiBussman CurvesAbraham JyothimonÎncă nu există evaluări
- BEST Sperners Lemma PPADDocument23 paginiBEST Sperners Lemma PPADAbraham JyothimonÎncă nu există evaluări
- Arc Flash - Enclosure-Reducing FactorDocument7 paginiArc Flash - Enclosure-Reducing FactorAbraham JyothimonÎncă nu există evaluări
- Lecture Notes On Differential GamesDocument77 paginiLecture Notes On Differential GamesOctavio MartinezÎncă nu există evaluări
- Examples Done On Orthogonal ProjectionDocument79 paginiExamples Done On Orthogonal ProjectionAbraham JyothimonÎncă nu există evaluări
- 6handle Rule NecDocument95 pagini6handle Rule NecAbraham Jyothimon100% (1)
- Flood DetectorDocument20 paginiFlood DetectorAbraham JyothimonÎncă nu există evaluări
- Bosch PaDocument498 paginiBosch PaAbraham JyothimonÎncă nu există evaluări
- Economicsproofseparating WeitzmanDocument6 paginiEconomicsproofseparating WeitzmanAbraham JyothimonÎncă nu există evaluări
- Riemann SurfaceDocument71 paginiRiemann SurfaceAbir DeyÎncă nu există evaluări
- Upper & Lower Contour SetsDocument12 paginiUpper & Lower Contour SetsAbraham JyothimonÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Ceo DualityDocument3 paginiCeo Dualitydimpi singhÎncă nu există evaluări
- Evaporative CoolingDocument68 paginiEvaporative Coolingshivas34regal100% (1)
- Chapter 10 OutlineDocument3 paginiChapter 10 OutlineFerrari75% (4)
- Weekly Lesson Plan: Pry 3 (8years) Third Term Week 1Document12 paginiWeekly Lesson Plan: Pry 3 (8years) Third Term Week 1Kunbi Santos-ArinzeÎncă nu există evaluări
- Aavi 3Document4 paginiAavi 3Arnie IldefonsoÎncă nu există evaluări
- Assesment Test in English 9Document3 paginiAssesment Test in English 9Chazz SatoÎncă nu există evaluări
- Resa Auditing Theorydocx - CompressDocument64 paginiResa Auditing Theorydocx - CompressMaeÎncă nu există evaluări
- Course: Introduction To Geomatics (GLS411) Group Practical (2-3 Persons in A Group) Practical #3: Principle and Operation of A LevelDocument3 paginiCourse: Introduction To Geomatics (GLS411) Group Practical (2-3 Persons in A Group) Practical #3: Principle and Operation of A LevelalyafarzanaÎncă nu există evaluări
- Lecture 1 Electrolyte ImbalanceDocument15 paginiLecture 1 Electrolyte ImbalanceSajib Chandra RoyÎncă nu există evaluări
- Frequently Asked Questions: Lecture 7 To 9 Hydraulic PumpsDocument5 paginiFrequently Asked Questions: Lecture 7 To 9 Hydraulic PumpsJatadhara GSÎncă nu există evaluări
- MBA-7002-20169108-68 MarksDocument17 paginiMBA-7002-20169108-68 MarksN GÎncă nu există evaluări
- Agency Procurement Request: Ipil Heights Elementary SchoolDocument1 paginăAgency Procurement Request: Ipil Heights Elementary SchoolShar Nur JeanÎncă nu există evaluări
- Mahindra First Choice Wheels LTD: 4-Wheeler Inspection ReportDocument5 paginiMahindra First Choice Wheels LTD: 4-Wheeler Inspection ReportRavi LoveÎncă nu există evaluări
- 4BT3 9-G2 PDFDocument5 pagini4BT3 9-G2 PDFNv Thái100% (1)
- SQLDocument13 paginiSQLRadhakrishnan__7263Încă nu există evaluări
- Turnbull CV OnlineDocument7 paginiTurnbull CV Onlineapi-294951257Încă nu există evaluări
- Chalcedony Value, Price, and Jewelry Information - International Gem SocietyDocument8 paginiChalcedony Value, Price, and Jewelry Information - International Gem Societyasset68Încă nu există evaluări
- Paper 4 Material Management Question BankDocument3 paginiPaper 4 Material Management Question BankDr. Rakshit Solanki100% (2)
- PEA Comp Study - Estate Planning For Private Equity Fund Managers (ITaback, JWaxenberg 10 - 10)Document13 paginiPEA Comp Study - Estate Planning For Private Equity Fund Managers (ITaback, JWaxenberg 10 - 10)lbaker2009Încă nu există evaluări
- BBAG MPR and STR LISTSDocument25 paginiBBAG MPR and STR LISTShimanshu ranjanÎncă nu există evaluări
- Reviewer in EntrepreneurshipDocument6 paginiReviewer in EntrepreneurshipRachelle Anne SaldeÎncă nu există evaluări
- Catch Up RPHDocument6 paginiCatch Up RPHபிரதீபன் இராதேÎncă nu există evaluări
- New Text DocumentDocument13 paginiNew Text DocumentJitendra Karn RajputÎncă nu există evaluări
- BS 215-2-1970-Aluminium Conductors and Aluminium Conductors Steel-Reinforced For Overhead Power TransmissionDocument16 paginiBS 215-2-1970-Aluminium Conductors and Aluminium Conductors Steel-Reinforced For Overhead Power TransmissionDayan Yasaranga100% (2)
- 1 s2.0 S2238785423001345 MainDocument10 pagini1 s2.0 S2238785423001345 MainHamada Shoukry MohammedÎncă nu există evaluări
- Load Schedule: DescriptionDocument1 paginăLoad Schedule: Descriptionkurt james alorroÎncă nu există evaluări
- Edtpa Lesson 3Document3 paginiEdtpa Lesson 3api-299319227Încă nu există evaluări
- Technology ForecastingDocument38 paginiTechnology ForecastingSourabh TandonÎncă nu există evaluări
- Ziarek - The Force of ArtDocument233 paginiZiarek - The Force of ArtVero MenaÎncă nu există evaluări
- Motion To Dismiss Guidry Trademark Infringement ClaimDocument23 paginiMotion To Dismiss Guidry Trademark Infringement ClaimDaniel BallardÎncă nu există evaluări