S-ar putea să vă placă și
- Java Chap6 Decision Making Statements (Prof. Ananda M Ghosh.)Document8 paginiJava Chap6 Decision Making Statements (Prof. Ananda M Ghosh.)Prof. (Dr) Ananda M Ghosh.100% (1)
- Missing Value TreatmentDocument22 paginiMissing Value TreatmentrphmiÎncă nu există evaluări
- Dataming T PDFDocument48 paginiDataming T PDFKimhorng HornÎncă nu există evaluări
- DMWH M1Document25 paginiDMWH M1vani_V_prakashÎncă nu există evaluări
- Constants Variables DatatypesDocument44 paginiConstants Variables DatatypesSiddharth Gupta100% (1)
- Data Mining - Tasks: Data Characterization Data DiscriminationDocument4 paginiData Mining - Tasks: Data Characterization Data Discriminationprerna ushirÎncă nu există evaluări
- Artificial IntelligenceDocument2 paginiArtificial IntelligenceAbhi AndhariyaÎncă nu există evaluări
- Simple Linear Regression - Assign3Document8 paginiSimple Linear Regression - Assign3Sravani AdapaÎncă nu există evaluări
- Java InterfaceDocument14 paginiJava InterfaceSR ChaudharyÎncă nu există evaluări
- Assignment Module 5Document4 paginiAssignment Module 5Kamlesh NikamÎncă nu există evaluări
- Basic Statistics (Module - 4 ( - 1) ) : © 2013 - 2020 360digitmg. All Rights ReservedDocument3 paginiBasic Statistics (Module - 4 ( - 1) ) : © 2013 - 2020 360digitmg. All Rights ReservedProli PravalikaÎncă nu există evaluări
- DWM Unit3Document54 paginiDWM Unit3Manimozhi PalanisamyÎncă nu există evaluări
- Missing Value Imputation A Review and Analysis of The Literature (2006-2017)Document23 paginiMissing Value Imputation A Review and Analysis of The Literature (2006-2017)tvquynh1Încă nu există evaluări
- Lattices and Boolean AlgebraDocument11 paginiLattices and Boolean AlgebraDimpy GoelÎncă nu există evaluări
- Unit - 3 PHP - 1Document60 paginiUnit - 3 PHP - 1srinivas890Încă nu există evaluări
- Python AssignmentDocument4 paginiPython AssignmentNITIN RAJÎncă nu există evaluări
- Informatics Practices XIIDocument117 paginiInformatics Practices XIIAshutosh Tripathi0% (1)
- Problem Statement - Mathematical FoundationsDocument2 paginiProblem Statement - Mathematical Foundationsdivya bharathÎncă nu există evaluări
- Advanced Certification in Data Science and Artificial IntelligenceDocument18 paginiAdvanced Certification in Data Science and Artificial Intelligenceashok govilkarÎncă nu există evaluări
- Tutorial 2018 OptimizationDocument7 paginiTutorial 2018 OptimizationburhanÎncă nu există evaluări
- Python Assignment 1 ADocument2 paginiPython Assignment 1 Arevanth kumarÎncă nu există evaluări
- AoA Important QuestionDocument3 paginiAoA Important QuestionShubham KumarÎncă nu există evaluări
- Evolving Role of Software PDFDocument2 paginiEvolving Role of Software PDFPamela0% (1)
- Predict 422 - Module 8Document138 paginiPredict 422 - Module 8cahyadi adityaÎncă nu există evaluări
- Machine Learning Lab Assignment Using Weka Name:: Submitted ToDocument15 paginiMachine Learning Lab Assignment Using Weka Name:: Submitted ToZobahaa HorunkuÎncă nu există evaluări
- Rdbms Lab Manual New SchemeDocument23 paginiRdbms Lab Manual New SchemeSanjay Nikhade100% (2)
- Unit 1Document37 paginiUnit 1yashika sarodeÎncă nu există evaluări
- 2 Probability and StatisticsDocument3 pagini2 Probability and StatisticsJoy Dacuan100% (1)
- Unit2-Compiler DesignDocument24 paginiUnit2-Compiler DesigndhanasekarÎncă nu există evaluări
- Factors in RDocument6 paginiFactors in RKarthikeyan RamajayamÎncă nu există evaluări
- Data Mining - IMT Nagpur-ManishDocument82 paginiData Mining - IMT Nagpur-ManishSumeet GuptaÎncă nu există evaluări
- Agenda: - Introduction - Basics - Classification - Clustering - Regression - Use-CasesDocument30 paginiAgenda: - Introduction - Basics - Classification - Clustering - Regression - Use-CasesAmeer MuhammadÎncă nu există evaluări
- Quiz Week 7 - Support Vector MachinesDocument3 paginiQuiz Week 7 - Support Vector Machinescharu.hitechrobot2889100% (1)
- Decision TreeDocument25 paginiDecision Treericardo_g1973Încă nu există evaluări
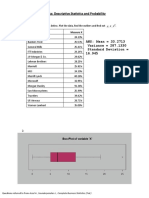
- Topics: Descriptive Statistics and Probability: Name of Company Measure XDocument4 paginiTopics: Descriptive Statistics and Probability: Name of Company Measure XSimarjeet SinghÎncă nu există evaluări
- BSC Computer Science WWW - Alagappauniversity.ac - in Alagappa University Model Question Paper DistDocument32 paginiBSC Computer Science WWW - Alagappauniversity.ac - in Alagappa University Model Question Paper DistradhasubbuÎncă nu există evaluări
- Machine Learning BitsDocument28 paginiMachine Learning Bitsvyshnavi100% (2)
- Data Mining Is Defined As The Procedure of Extracting Information From Huge Sets of DataDocument6 paginiData Mining Is Defined As The Procedure of Extracting Information From Huge Sets of DataOdem Dinesh ReddyÎncă nu există evaluări
- Census Income ProjectDocument4 paginiCensus Income ProjectAmit PhulwaniÎncă nu există evaluări
- Pgdds - Assessment and Learning Experience Manual: Iiitb and Upgrad Post - Graduate Diploma in Data ScienceDocument12 paginiPgdds - Assessment and Learning Experience Manual: Iiitb and Upgrad Post - Graduate Diploma in Data SciencerahulÎncă nu există evaluări
- Machine Learning CA 2Document19 paginiMachine Learning CA 2Rhugved TakalkarÎncă nu există evaluări
- 3213 Final Fall2010 SolutionsDocument15 pagini3213 Final Fall2010 SolutionsSuranga SampathÎncă nu există evaluări
- Tutorial 2 - ClusteringDocument6 paginiTutorial 2 - ClusteringGupta Akshay100% (2)
- BSC Software Computer Science PDFDocument54 paginiBSC Software Computer Science PDFRamg RamÎncă nu există evaluări
- CH1 - Introduction To Soft Computing TechniquesDocument25 paginiCH1 - Introduction To Soft Computing Techniquesagonafer ayeleÎncă nu există evaluări
- Data NormalisationDocument10 paginiData Normalisationkomal komalÎncă nu există evaluări
- June-2012 (Computer Science) (Paper)Document12 paginiJune-2012 (Computer Science) (Paper)futuredata100Încă nu există evaluări
- AI NotesDocument6 paginiAI NotesBryanOkelloÎncă nu există evaluări
- Problem Statement - Foodhub: ContextDocument5 paginiProblem Statement - Foodhub: ContextJeffÎncă nu există evaluări
- AI QuestionBank PartA&PartB RejinpaulDocument111 paginiAI QuestionBank PartA&PartB RejinpaulEdappadi k. PalaniswamiÎncă nu există evaluări
- U L D R: Nsupervised Earning and Imensionality EductionDocument58 paginiU L D R: Nsupervised Earning and Imensionality EductionSanaullahSunnyÎncă nu există evaluări
- Dev Answer KeyDocument17 paginiDev Answer Keyjayapriya kce100% (1)
- Crescentannualreport19 20Document1.146 paginiCrescentannualreport19 20jasonÎncă nu există evaluări
- Topic Knowledge RepresentationDocument25 paginiTopic Knowledge RepresentationAbdela Aman Mtech100% (1)
- Q.1. What Is Data Mining?Document15 paginiQ.1. What Is Data Mining?Akshay MathurÎncă nu există evaluări
- Data Warehouse and Data Mining Question Bank R13 PDFDocument12 paginiData Warehouse and Data Mining Question Bank R13 PDFBalamuni PaluruÎncă nu există evaluări
- (Fall 2011) CS-402 Data Mining - Final Exam-SUB - v03Document6 pagini(Fall 2011) CS-402 Data Mining - Final Exam-SUB - v03taaloosÎncă nu există evaluări
- Dbms Unit 5.2 (Ar16)Document23 paginiDbms Unit 5.2 (Ar16)X BoyÎncă nu există evaluări
- Data Visualization Assignment 1 (Batch 2A)Document1 paginăData Visualization Assignment 1 (Batch 2A)Uma MaheshwarÎncă nu există evaluări
- Research Reports Mdh/Ima No. 2007-4, Issn 1404-4978: Date Key Words and PhrasesDocument16 paginiResearch Reports Mdh/Ima No. 2007-4, Issn 1404-4978: Date Key Words and PhrasesEduardo Salgado EnríquezÎncă nu există evaluări
- Data Mining KDD ProcessDocument22 paginiData Mining KDD Processamiba45Încă nu există evaluări
- Linear Discriminant Analysis SummaryDocument12 paginiLinear Discriminant Analysis Summaryamiba45Încă nu există evaluări
- Data Mining KDD ProcessDocument22 paginiData Mining KDD Processamiba45Încă nu există evaluări
- WP34s Calculator ManualDocument211 paginiWP34s Calculator ManualSteve MynottÎncă nu există evaluări
- Analytic Continuation WikiDocument3 paginiAnalytic Continuation Wikiamiba45Încă nu există evaluări
- Neyman Pearson LemmaDocument2 paginiNeyman Pearson Lemmaamiba45Încă nu există evaluări
- Standard ScoreDocument2 paginiStandard Scoreamiba45Încă nu există evaluări
- Anomaly Detection: Lecture Notes For Chapter 9 Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument33 paginiAnomaly Detection: Lecture Notes For Chapter 9 Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarAndrean SergioÎncă nu există evaluări
- Distance Weighted Moving AveragesDocument6 paginiDistance Weighted Moving AveragessuperbuddyÎncă nu există evaluări
- Missing ValuesDocument16 paginiMissing ValuesPanagiotis KarathymiosÎncă nu există evaluări
- Statistics: Lesson #4 in MMWDocument42 paginiStatistics: Lesson #4 in MMWRicaRhayaMangahas50% (2)
- Random ForestDocument13 paginiRandom ForestAmar KumarÎncă nu există evaluări
- Time Series Analysis AssignmentDocument2 paginiTime Series Analysis AssignmentMusa KhanÎncă nu există evaluări
- Universiti Utara Malaysia Additional Assessment: Confidential 1 CS/JAN 2022/SSQL1113Document3 paginiUniversiti Utara Malaysia Additional Assessment: Confidential 1 CS/JAN 2022/SSQL1113isqmaÎncă nu există evaluări
- Statistics Traning ExamDocument6 paginiStatistics Traning ExamEngy MoneebÎncă nu există evaluări
- Phillips-Perron Test Statistic: 0.9990 I (0) - 12.62137 0.0000 I (1) - 1.686543 0.7533 I (0) - 12.76035 0.0000 IDocument6 paginiPhillips-Perron Test Statistic: 0.9990 I (0) - 12.62137 0.0000 I (1) - 1.686543 0.7533 I (0) - 12.76035 0.0000 IXed XamzÎncă nu există evaluări
- Module #4 Hand in Assignment: Grade Probability 80 .15 70 .25 60 .25 50 .20 40 .15Document1 paginăModule #4 Hand in Assignment: Grade Probability 80 .15 70 .25 60 .25 50 .20 40 .15CarlosÎncă nu există evaluări
- Nat-Statistics and ProbabilityDocument7 paginiNat-Statistics and ProbabilityArnel LomocsoÎncă nu există evaluări
- Time Series ProjectDocument2 paginiTime Series ProjectTina50% (4)
- Linear Regression - Numpy and SklearnDocument7 paginiLinear Regression - Numpy and SklearnArala FolaÎncă nu există evaluări
- PSYC3001 2024 Assignment 1Document5 paginiPSYC3001 2024 Assignment 1Peterson SihotangÎncă nu există evaluări
- Iii MDocument2 paginiIii MChhana inc.Încă nu există evaluări
- 統計ch14 solutionDocument69 pagini統計ch14 solutionH54094015張柏駿Încă nu există evaluări
- Mining Class ComparisonsDocument4 paginiMining Class Comparisonsmurali_20c100% (1)
- Answer Key Problem Set 2Document8 paginiAnswer Key Problem Set 2Lelly MelindaaÎncă nu există evaluări
- Hypothesis Testing Z-Test and T-TestDocument13 paginiHypothesis Testing Z-Test and T-TestmochiÎncă nu există evaluări
- Nonlinear Regression Model - Quadratic ModelDocument18 paginiNonlinear Regression Model - Quadratic ModelLaura StephanieÎncă nu există evaluări
- R06 Time-Series Analysis - AnswersDocument56 paginiR06 Time-Series Analysis - AnswersShashwat DesaiÎncă nu există evaluări
- A Guide To Modern Econometrics, 5th Edition Answers To Selected Exercises - Chapter 2Document5 paginiA Guide To Modern Econometrics, 5th Edition Answers To Selected Exercises - Chapter 2MadinaÎncă nu există evaluări
- Completely Randomized Designs: Gary W. OehlertDocument33 paginiCompletely Randomized Designs: Gary W. OehlertKirandeep KaurÎncă nu există evaluări
- Scikit-Learn Cheat Sheet Python For Data Science: Preprocessing The Data Evaluate Your Model's PerformanceDocument1 paginăScikit-Learn Cheat Sheet Python For Data Science: Preprocessing The Data Evaluate Your Model's PerformanceLourdes Victoria Urrutia100% (1)
- Testing The Validity of The MeasurementDocument2 paginiTesting The Validity of The MeasurementhermancxÎncă nu există evaluări
- SS 02 Quiz 1 - Answers PDFDocument64 paginiSS 02 Quiz 1 - Answers PDFdumboooodogÎncă nu există evaluări
- Week2 LinearRegression Post PDFDocument115 paginiWeek2 LinearRegression Post PDFYecheng Caroline Liu100% (1)
- Testing HypothesisDocument41 paginiTesting HypothesisJean PampagÎncă nu există evaluări
- Science of The Total Environment: Elisavet Tsekeri Dionysia Kolokotsa Mat SantamourisDocument10 paginiScience of The Total Environment: Elisavet Tsekeri Dionysia Kolokotsa Mat SantamouriskikyflÎncă nu există evaluări
- Experiment #2 - Gravimetric Determination of CalciumDocument2 paginiExperiment #2 - Gravimetric Determination of CalciumChristopher Galindo100% (1)