S-ar putea să vă placă și
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- John Locke and Personal Identity Immortality and Bodily Resurrection in 17th Century Philosophy Continuum Studies in British PhilosophyDocument161 paginiJohn Locke and Personal Identity Immortality and Bodily Resurrection in 17th Century Philosophy Continuum Studies in British PhilosophyDoina AlbescuÎncă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- A1 Study Intercultural Comms1Document7 paginiA1 Study Intercultural Comms1Nuraini AhmadÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- Answer - Keys-New International Business English PDFDocument2 paginiAnswer - Keys-New International Business English PDFĐặng Thị Thu Nga79% (19)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Longevity DayDocument14 paginiLongevity DayGeorgeÎncă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Nonverbal Cross Cultural CommunicationDocument5 paginiNonverbal Cross Cultural CommunicationTrà BùiÎncă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Memory and Personal IdentityDocument10 paginiMemory and Personal IdentityGeorgeÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Томский политехнический университет, Томск Российская Федерация E-mail: suntsova.ev@Document5 paginiТомский политехнический университет, Томск Российская Федерация E-mail: suntsova.ev@GeorgeÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Spoken Corpora PDFDocument25 paginiSpoken Corpora PDFGeorgeÎncă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Longevity DayDocument14 paginiLongevity DayGeorgeÎncă nu există evaluări
- Bateson's Levels of Learning: A Framework For Transformative Learning?Document15 paginiBateson's Levels of Learning: A Framework For Transformative Learning?GeorgeÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Professional English in USE ITCDocument115 paginiProfessional English in USE ITCtrenadoraquelÎncă nu există evaluări
- Communicating Across CulturesDocument17 paginiCommunicating Across CulturesGeorgeÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Business EnglishDocument145 paginiBusiness EnglishHo Ha67% (3)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Business EnglishDocument145 paginiBusiness EnglishHo Ha67% (3)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- Do S and Taboos Around The World: Greetings / GesturesDocument5 paginiDo S and Taboos Around The World: Greetings / GesturesAhmad SafarÎncă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Working Cross Culturally: A GuideDocument89 paginiWorking Cross Culturally: A GuideGeorgeÎncă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Critique of CBT 2007 Richard J. Longmore & Michael WorrellDocument15 paginiCritique of CBT 2007 Richard J. Longmore & Michael WorrellCarpenle100% (1)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- Tips For Cross-Cultural CommunicationDocument2 paginiTips For Cross-Cultural CommunicationGeorge100% (1)
- Jumping To ConclusionsDocument8 paginiJumping To ConclusionsGeorgeÎncă nu există evaluări
- Berman, Sanford I. Words Meaning and PeopleDocument56 paginiBerman, Sanford I. Words Meaning and PeopleGeorge100% (1)
- 1Document2 pagini1NhậtNamÎncă nu există evaluări
- Culture Matters The Peace Corps Cross-Cultural Workbook PDFDocument266 paginiCulture Matters The Peace Corps Cross-Cultural Workbook PDFshakes21778Încă nu există evaluări
- 20131201180129005Document12 pagini20131201180129005GeorgeÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Lecsicol PDFDocument48 paginiLecsicol PDFGeorgeÎncă nu există evaluări
- Barriers To Cross Cultural Communication and The Steps Needed To Be Taken For A MNC To Succeed in The Global MarketDocument9 paginiBarriers To Cross Cultural Communication and The Steps Needed To Be Taken For A MNC To Succeed in The Global MarketGeorgeÎncă nu există evaluări
- MetacognitionAndInterculturalCompetence - LaneDocument10 paginiMetacognitionAndInterculturalCompetence - LaneGeorgeÎncă nu există evaluări
- The Unity of Human Problems Through Method - Korzybskis General Semantics As A Transdisciplinary Discipline - LibreDocument16 paginiThe Unity of Human Problems Through Method - Korzybskis General Semantics As A Transdisciplinary Discipline - LibreGeorgeÎncă nu există evaluări
- Conceptualizing Critical ThinkingDocument18 paginiConceptualizing Critical ThinkingCarlos Eduardo Pérez CrespoÎncă nu există evaluări
- Shanahan Jcs 05Document21 paginiShanahan Jcs 05GeorgeÎncă nu există evaluări
- The Epistemology of Creative Inquiry: Mario SpilerDocument42 paginiThe Epistemology of Creative Inquiry: Mario SpilerGeorgeÎncă nu există evaluări
- Court of Appeals: DecisionDocument11 paginiCourt of Appeals: DecisionBrian del MundoÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Basic Unix Commands: Cat - List A FileDocument3 paginiBasic Unix Commands: Cat - List A Filekathir_tkÎncă nu există evaluări
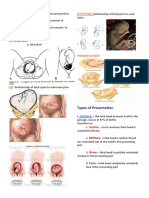
- The 4Ps of Labor: Passenger, Passageway, Powers, and PlacentaDocument4 paginiThe 4Ps of Labor: Passenger, Passageway, Powers, and PlacentaMENDIETA, JACQUELINE V.Încă nu există evaluări
- Traditional Knowledge - The Changing Scenario in India PDFDocument9 paginiTraditional Knowledge - The Changing Scenario in India PDFashutosh srivastavaÎncă nu există evaluări
- Midterm Exam ADM3350 Summer 2022 PDFDocument7 paginiMidterm Exam ADM3350 Summer 2022 PDFHan ZhongÎncă nu există evaluări
- APFC Accountancy Basic Study Material For APFCEPFO ExamDocument3 paginiAPFC Accountancy Basic Study Material For APFCEPFO ExamIliasÎncă nu există evaluări
- 6 Lesson Writing Unit: Personal Recount For Grade 3 SEI, WIDA Level 2 Writing Kelsie Drown Boston CollegeDocument17 pagini6 Lesson Writing Unit: Personal Recount For Grade 3 SEI, WIDA Level 2 Writing Kelsie Drown Boston Collegeapi-498419042Încă nu există evaluări
- Module 1 in Contemporary Arts First MonthDocument12 paginiModule 1 in Contemporary Arts First MonthMiles Bugtong CagalpinÎncă nu există evaluări
- VT JCXDocument35 paginiVT JCXAkshay WingriderÎncă nu există evaluări
- Configure Initial ISAM Network SettingsDocument4 paginiConfigure Initial ISAM Network SettingsnelusabieÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Lantern October 2012Document36 paginiLantern October 2012Jovel JosephÎncă nu există evaluări
- Journal of Electronic MaterialsDocument10 paginiJournal of Electronic MaterialsSanjib BaglariÎncă nu există evaluări
- Class Namespace DesciptionDocument9 paginiClass Namespace DesciptionĐào Quỳnh NhưÎncă nu există evaluări
- PERDEV - Lesson 3 ReadingsDocument6 paginiPERDEV - Lesson 3 ReadingsSofiaÎncă nu există evaluări
- Ecomix RevolutionDocument4 paginiEcomix RevolutionkrissÎncă nu există evaluări
- Catalogo 4life en InglesDocument40 paginiCatalogo 4life en InglesJordanramirezÎncă nu există evaluări
- JKFBDDocument2 paginiJKFBDGustinarsari Dewi WÎncă nu există evaluări
- Strategies in Various Speech SituationsDocument6 paginiStrategies in Various Speech SituationsSky NayytÎncă nu există evaluări
- Introduction To Opengl/Glsl and WebglDocument46 paginiIntroduction To Opengl/Glsl and Webglanon_828313787Încă nu există evaluări
- AnnovaDocument4 paginiAnnovabharticÎncă nu există evaluări
- SEED TREATMENT WITH BOTANICAL EXTRACTSDocument18 paginiSEED TREATMENT WITH BOTANICAL EXTRACTSRohitÎncă nu există evaluări
- JSP - How To Edit Table of Data Displayed Using JSP When Clicked On Edit ButtonDocument8 paginiJSP - How To Edit Table of Data Displayed Using JSP When Clicked On Edit Buttonrithuik1598Încă nu există evaluări
- PNP TELEPHONE DIRECTORY As of JUNE 2022Document184 paginiPNP TELEPHONE DIRECTORY As of JUNE 2022lalainecd0616Încă nu există evaluări
- Eng9 - Q3 - M4 - W4 - Interpret The Message Conveyed in A Poster - V5Document19 paginiEng9 - Q3 - M4 - W4 - Interpret The Message Conveyed in A Poster - V5FITZ100% (1)
- Deforestation Contributes To Global Warming: Bruno GERVETDocument11 paginiDeforestation Contributes To Global Warming: Bruno GERVETMajid JatoiÎncă nu există evaluări
- Yoga Practice Guide: DR - Abhishek VermaDocument26 paginiYoga Practice Guide: DR - Abhishek VermaAmarendra Kumar SharmaÎncă nu există evaluări
- Trends, Networks, and Critical Thinking in The 21st CenturyDocument22 paginiTrends, Networks, and Critical Thinking in The 21st CenturyGabrelle Ogayon100% (1)
- DC Rebirth Reading Order 20180704Document43 paginiDC Rebirth Reading Order 20180704Michael MillerÎncă nu există evaluări
- Intern - Annapolis PharmaceuticalsDocument34 paginiIntern - Annapolis Pharmaceuticalsjoycecruz095Încă nu există evaluări
- RQQDocument3 paginiRQQRazerrdooÎncă nu există evaluări
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDe la EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveÎncă nu există evaluări
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldDe la EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldEvaluare: 4.5 din 5 stele4.5/5 (107)
- Defensive Cyber Mastery: Expert Strategies for Unbeatable Personal and Business SecurityDe la EverandDefensive Cyber Mastery: Expert Strategies for Unbeatable Personal and Business SecurityEvaluare: 5 din 5 stele5/5 (1)
- Chip War: The Quest to Dominate the World's Most Critical TechnologyDe la EverandChip War: The Quest to Dominate the World's Most Critical TechnologyEvaluare: 4.5 din 5 stele4.5/5 (227)
- The Infinite Machine: How an Army of Crypto-Hackers Is Building the Next Internet with EthereumDe la EverandThe Infinite Machine: How an Army of Crypto-Hackers Is Building the Next Internet with EthereumEvaluare: 3 din 5 stele3/5 (12)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldDe la EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldEvaluare: 4.5 din 5 stele4.5/5 (54)
- Algorithms to Live By: The Computer Science of Human DecisionsDe la EverandAlgorithms to Live By: The Computer Science of Human DecisionsEvaluare: 4.5 din 5 stele4.5/5 (722)
- Digital Gold: Bitcoin and the Inside Story of the Misfits and Millionaires Trying to Reinvent MoneyDe la EverandDigital Gold: Bitcoin and the Inside Story of the Misfits and Millionaires Trying to Reinvent MoneyEvaluare: 4 din 5 stele4/5 (51)