S-ar putea să vă placă și
- Estudio Caso 1 - Novedad Táctil - Otro CompañeroDocument10 paginiEstudio Caso 1 - Novedad Táctil - Otro CompañeroVerónica Lambert100% (1)
- Prácticas Excel BásicoDocument15 paginiPrácticas Excel BásicoAlberto Blázquez del PinoÎncă nu există evaluări
- Rpo, Diferencias Entre Rto y RpoDocument4 paginiRpo, Diferencias Entre Rto y RpoJesus Martin Yaya TorresÎncă nu există evaluări
- Mapa Conceptual Sobre Hardware y SoftwareDocument1 paginăMapa Conceptual Sobre Hardware y SoftwareCarla Hernandez100% (1)
- (IPC1) Practica2 1S2021Document6 pagini(IPC1) Practica2 1S2021Estuardo EstradaÎncă nu există evaluări
- CuestionariosDocument6 paginiCuestionariosHilda Belem Zepeda EufracioÎncă nu există evaluări
- 1era PractikDocument2 pagini1era PractikHilda Belem Zepeda EufracioÎncă nu există evaluări
- ResumennnnDocument11 paginiResumennnnHilda Belem Zepeda EufracioÎncă nu există evaluări
- SuvirsDocument1 paginăSuvirsHilda Belem Zepeda EufracioÎncă nu există evaluări
- Ctyrt ZuvitDocument8 paginiCtyrt ZuvitHilda Belem Zepeda EufracioÎncă nu există evaluări
- Diapositivas OvidioDocument28 paginiDiapositivas OvidioHilda Belem Zepeda EufracioÎncă nu există evaluări
- Tablas de Acces Practica: No. 1Document2 paginiTablas de Acces Practica: No. 1Hilda Belem Zepeda EufracioÎncă nu există evaluări
- Cecytej 14Document11 paginiCecytej 14Hilda Belem Zepeda EufracioÎncă nu există evaluări
- SQL ImprimirDocument10 paginiSQL ImprimirHilda Belem Zepeda EufracioÎncă nu există evaluări
- Sistemas de La Información BLMDocument3 paginiSistemas de La Información BLMHilda Belem Zepeda EufracioÎncă nu există evaluări
- Valentin PerezDocument28 paginiValentin PerezHilda Belem Zepeda EufracioÎncă nu există evaluări
- Datozz XXDocument11 paginiDatozz XXHilda Belem Zepeda EufracioÎncă nu există evaluări
- Entidad RelacionDocument20 paginiEntidad RelacionPalafoXxXÎncă nu există evaluări
- Hilda Belem Zepeda EufracioDocument10 paginiHilda Belem Zepeda EufracioHilda Belem Zepeda EufracioÎncă nu există evaluări
- Suvir Al BloggDocument3 paginiSuvir Al BloggHilda Belem Zepeda EufracioÎncă nu există evaluări
- Diagrama de Densidad de RelacionesDocument3 paginiDiagrama de Densidad de RelacionesHilda Belem Zepeda EufracioÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument3 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Diapositivas OvidioDocument25 paginiDiapositivas OvidioPalafoXxXÎncă nu există evaluări
- INFM3S2CRXXDocument1 paginăINFM3S2CRXXPalafoXxXÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument2 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelHilda Belem Zepeda EufracioÎncă nu există evaluări
- Inicio de AccessDocument1 paginăInicio de AccessHilda Belem Zepeda EufracioÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument5 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument8 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Fases de ProgramacionDocument2 paginiFases de ProgramacionHilda Belem Zepeda EufracioÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument3 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument7 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument3 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Colegio de Estudios CientÍficos y TecnolÓgicos DelDocument5 paginiColegio de Estudios CientÍficos y TecnolÓgicos DelPalafoXxXÎncă nu există evaluări
- Resultado exAMEN BELEMDocument1 paginăResultado exAMEN BELEMHilda Belem Zepeda EufracioÎncă nu există evaluări
- Ofimatica Guias PracticasDocument16 paginiOfimatica Guias PracticasJontn RomanzÎncă nu există evaluări
- Como Agregar Un Archivo PDF A Un BlogDocument2 paginiComo Agregar Un Archivo PDF A Un BlogMelissaÎncă nu există evaluări
- Tema 1 - Hardware y Software. Redes.Document36 paginiTema 1 - Hardware y Software. Redes.Cuenta PatataÎncă nu există evaluări
- 1.1 Características de Los Sistemas Gestores de Bases de DatosDocument6 pagini1.1 Características de Los Sistemas Gestores de Bases de Datoseboy86bÎncă nu există evaluări
- Manual de Buenas Practicas v1Document30 paginiManual de Buenas Practicas v1jersony2Încă nu există evaluări
- CASIO CLASSPAD II FX CP400 Gu°a Del UsuarioDocument24 paginiCASIO CLASSPAD II FX CP400 Gu°a Del UsuarioÁngel L. RamosÎncă nu există evaluări
- Propuesta de Monografía Proyecto de Ingenieria (Ejguerrerog)Document70 paginiPropuesta de Monografía Proyecto de Ingenieria (Ejguerrerog)Juancho ZarateÎncă nu există evaluări
- Reticula ISC 2021Document1 paginăReticula ISC 2021YukiAsunaÎncă nu există evaluări
- Cybanol, 57-66Document10 paginiCybanol, 57-66sofia villarÎncă nu există evaluări
- Tarea 2 Aplicación de Recursos en LíneaDocument6 paginiTarea 2 Aplicación de Recursos en LíneaAGD SALUSÎncă nu există evaluări
- PCX - ReportDocument38 paginiPCX - ReportPerroÎncă nu există evaluări
- Ejemplo Problemas Producción e InventarioDocument27 paginiEjemplo Problemas Producción e InventarioRuben AragonÎncă nu există evaluări
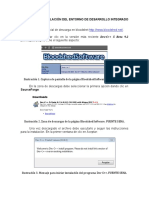
- Tutorial de Instalación Del Entorno de Desarrollo Integrado C++Document9 paginiTutorial de Instalación Del Entorno de Desarrollo Integrado C++Carlos GrisalesÎncă nu există evaluări
- Mi CVDocument2 paginiMi CVmartagaveytiaÎncă nu există evaluări
- Taller de Excel DosDocument6 paginiTaller de Excel DosVictor VargasÎncă nu există evaluări
- Herramientas Informaticas Aplicadas (Guías)Document53 paginiHerramientas Informaticas Aplicadas (Guías)Pablo AvilaÎncă nu există evaluări
- Nuevo Documento de TextoDocument2 paginiNuevo Documento de TextoNOCTURN & NIGHT BLACKÎncă nu există evaluări
- Informática - WordDocument19 paginiInformática - WordJosé Antonio Ortega MatíesÎncă nu există evaluări
- Resumen Coloquio Ingeniería 3Document1 paginăResumen Coloquio Ingeniería 3Antonela MendicciniÎncă nu există evaluări
- Actividad de Puntos Evaluables - Escenario 2 - PRIMER BLOQUE-TEORICO-PRACTICO - VIRTUAL - GESTIÓN DE LA INFORMACIÓNDocument4 paginiActividad de Puntos Evaluables - Escenario 2 - PRIMER BLOQUE-TEORICO-PRACTICO - VIRTUAL - GESTIÓN DE LA INFORMACIÓNherreÎncă nu există evaluări
- Ingeniería software aplicacionesDocument6 paginiIngeniería software aplicacionesG4briel HouseÎncă nu există evaluări
- Introducción A Windows 8.1-Sesión 01 - Revision de ObjetivosDocument9 paginiIntroducción A Windows 8.1-Sesión 01 - Revision de ObjetivosSamuel SanchezÎncă nu există evaluări
- Gestores BibliograficosDocument3 paginiGestores BibliograficosGadiel Armijos VÎncă nu există evaluări
- Cuáles Son Las Ventajas de UbuntuDocument8 paginiCuáles Son Las Ventajas de UbuntuLismar GarciaÎncă nu există evaluări
- Practica 5. Utilizar El Procesador de Textos Word 5Document2 paginiPractica 5. Utilizar El Procesador de Textos Word 5Jose Luis GraneroÎncă nu există evaluări