S-ar putea să vă placă și
- Chapter 3Document11 paginiChapter 3roopa_kothapalliÎncă nu există evaluări
- Design and Implementation of Digital Clock With Stopwatch On FPGADocument5 paginiDesign and Implementation of Digital Clock With Stopwatch On FPGAjixxy jaxÎncă nu există evaluări
- Conference PaperDocument5 paginiConference PapervtheksÎncă nu există evaluări
- Anesthesia Regularization Using ARM in RTOSDocument43 paginiAnesthesia Regularization Using ARM in RTOSGurram SaiTejaÎncă nu există evaluări
- Ic Design For New Mobility: Andrew Macleod, Mentor, A Siemens BusinessDocument10 paginiIc Design For New Mobility: Andrew Macleod, Mentor, A Siemens Businesssachin_sohaleÎncă nu există evaluări
- DYNAMIC SORTING ALGORITHM VISUALIZER USING OPENGL ReportDocument35 paginiDYNAMIC SORTING ALGORITHM VISUALIZER USING OPENGL ReportSneha Sivakumar88% (8)
- A Comparison of PACs To PLCsDocument3 paginiA Comparison of PACs To PLCskouki982hotmailcomÎncă nu există evaluări
- Intel and Mobileye Autonomous Driving Solutions: Product BriefDocument6 paginiIntel and Mobileye Autonomous Driving Solutions: Product BriefsmkraliÎncă nu există evaluări
- Unity ProDocument8 paginiUnity Prodongotchi09Încă nu există evaluări
- Flowcode8 Datasheet8 1Document22 paginiFlowcode8 Datasheet8 1David TorresÎncă nu există evaluări
- Integrated Design and Test Platform With Ni Multisim, Ultiboard, and LabviewDocument4 paginiIntegrated Design and Test Platform With Ni Multisim, Ultiboard, and LabviewMarcos CayetanoÎncă nu există evaluări
- Gert 32 yDocument18 paginiGert 32 ySmileÎncă nu există evaluări
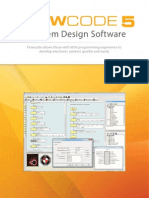
- Flowcode5 BookletDocument14 paginiFlowcode5 BookletBeer GardenÎncă nu există evaluări
- Flowcode5Booklet 2 PDFDocument14 paginiFlowcode5Booklet 2 PDFgrovlhus0% (1)
- Quick Guide To Microchip Development ToolsDocument48 paginiQuick Guide To Microchip Development ToolscireneuttrÎncă nu există evaluări
- Chapter ThreeDocument19 paginiChapter Threeraymond wellÎncă nu există evaluări
- High Level FPGA Modeling For Image Processing Algorithms Using Xilinx System GeneratorDocument8 paginiHigh Level FPGA Modeling For Image Processing Algorithms Using Xilinx System GeneratorKrishnaswamy RajaÎncă nu există evaluări
- 5 6098091079070908613Document65 pagini5 6098091079070908613SanjayÎncă nu există evaluări
- Delmia Robotics SimulationDocument4 paginiDelmia Robotics SimulationBas Ramu0% (1)
- Baniaga Jeandy A Task1Document4 paginiBaniaga Jeandy A Task1Jeandy BaniagaÎncă nu există evaluări
- Sobre o AllianceDocument13 paginiSobre o AllianceCarlos Alberto Rodrigues GouveiaÎncă nu există evaluări
- Xiao Dong ResumeDocument5 paginiXiao Dong ResumeJoven CamusÎncă nu există evaluări
- PcVue Brochure EnglishDocument6 paginiPcVue Brochure EnglishYashveerÎncă nu există evaluări
- TX Factorylink BrochureDocument8 paginiTX Factorylink Brochurefrankp_147Încă nu există evaluări
- Vishal MishraDocument2 paginiVishal Mishrasiddharth.dubeyÎncă nu există evaluări
- Design and FPGA Implementation of Vending Machine: Submitted To: Submitted byDocument39 paginiDesign and FPGA Implementation of Vending Machine: Submitted To: Submitted byManish SarohaÎncă nu există evaluări
- Adaptive VisionDocument8 paginiAdaptive VisionJorge Wanderley RibeiroÎncă nu există evaluări
- Hep1 Technical DetailsDocument8 paginiHep1 Technical DetailsDushyant GuptaÎncă nu există evaluări
- Ijireeice 49 PDFDocument4 paginiIjireeice 49 PDFJohn WangÎncă nu există evaluări
- CoDeSysdevelopmentS W PDFDocument4 paginiCoDeSysdevelopmentS W PDFThanh BaronÎncă nu există evaluări
- Grossenbacher Prospekt ControlsDisplays ENDocument5 paginiGrossenbacher Prospekt ControlsDisplays ENDanijelÎncă nu există evaluări
- FC6 DatasheetDocument32 paginiFC6 DatasheetVivek SinghÎncă nu există evaluări
- Eclipse-Based Expert System Shortens Sales Cycles For APCDocument3 paginiEclipse-Based Expert System Shortens Sales Cycles For APCgenwiseÎncă nu există evaluări
- MCHP-UK-MEL3272-AI Trends-190889 FinalDocument10 paginiMCHP-UK-MEL3272-AI Trends-190889 FinalDiego Damián FernándezÎncă nu există evaluări
- Systemonchip DesignDocument6 paginiSystemonchip Designddeepikam229Încă nu există evaluări
- PLM ComponentsDocument16 paginiPLM ComponentsMurali KrishÎncă nu există evaluări
- Open GLDocument4 paginiOpen GLTage NobinÎncă nu există evaluări
- Flowcode 5 BookletDocument14 paginiFlowcode 5 BookletRed Squerrel100% (1)
- Page Index: Chapter No. Topic 1 2 Grid 3 Requirement SpecificationsDocument14 paginiPage Index: Chapter No. Topic 1 2 Grid 3 Requirement SpecificationssgsÎncă nu există evaluări
- Ajitabh ResumeDocument4 paginiAjitabh ResumePragya Sharma RajoriyaÎncă nu există evaluări
- Machine Learning Internship ReportDocument31 paginiMachine Learning Internship Reportsuchithra Nijaguna33% (9)
- Labmewtraces Code in RealtimeDocument2 paginiLabmewtraces Code in RealtimeLiss D NadieÎncă nu există evaluări
- Ejemplos Mevislab PDFDocument60 paginiEjemplos Mevislab PDFYady Milena Jimenez DuenasÎncă nu există evaluări
- Concept: High Performance IEC 61131-3 Development Environment To Optimize PLC PerformanceDocument8 paginiConcept: High Performance IEC 61131-3 Development Environment To Optimize PLC PerformanceLuis MartinezÎncă nu există evaluări
- Enovia V6: Bringing PLM 2.0 To LifeDocument6 paginiEnovia V6: Bringing PLM 2.0 To LifesaileikÎncă nu există evaluări
- Easy Real-Time DSP Programming With Labview and Visual BasicDocument10 paginiEasy Real-Time DSP Programming With Labview and Visual BasicRakesh KumarÎncă nu există evaluări
- CaQtDM ParisDocument14 paginiCaQtDM ParisCheick Ahmed DiawaraÎncă nu există evaluări
- Budget Analysis ReportDocument62 paginiBudget Analysis Reportmrrakesh786Încă nu există evaluări
- Xapp890 Zynq Sobel Vivado HlsDocument16 paginiXapp890 Zynq Sobel Vivado HlsRamanarayan MohantyÎncă nu există evaluări
- Digital Image Processing Question PapersDocument9 paginiDigital Image Processing Question PapersvasuvlsiÎncă nu există evaluări
- Introduction To Vision Systems in LabVIEWDocument27 paginiIntroduction To Vision Systems in LabVIEWvipula123Încă nu există evaluări
- Summer Training Report On Vlsi and Fpga ImplementationDocument44 paginiSummer Training Report On Vlsi and Fpga ImplementationsaurabhÎncă nu există evaluări
- Applications of Fuzzy Logic in Image Processing - A Brief StudyDocument5 paginiApplications of Fuzzy Logic in Image Processing - A Brief StudyCompusoft JournalsÎncă nu există evaluări
- Programming 8-bit PIC Microcontrollers in C: with Interactive Hardware SimulationDe la EverandProgramming 8-bit PIC Microcontrollers in C: with Interactive Hardware SimulationEvaluare: 2.5 din 5 stele2.5/5 (5)
- Robot Operating System (ROS): The Complete Reference (Volume 6)De la EverandRobot Operating System (ROS): The Complete Reference (Volume 6)Încă nu există evaluări
- Pipelined Processor Farms: Structured Design for Embedded Parallel SystemsDe la EverandPipelined Processor Farms: Structured Design for Embedded Parallel SystemsÎncă nu există evaluări
- V Ug Type ListDocument3 paginiV Ug Type ListDanang BiantaraÎncă nu există evaluări
- PS2103 Electrical Transients in Power SystemsDocument4 paginiPS2103 Electrical Transients in Power Systemssathishkumar3ramasamÎncă nu există evaluări
- Standards National Institute of Standards and TechnologyDocument2 paginiStandards National Institute of Standards and Technologysundhar_vÎncă nu există evaluări
- Software System Safety: Nancy G. LevesonDocument52 paginiSoftware System Safety: Nancy G. LevesonUmer Asfandyar BalghariÎncă nu există evaluări
- Supply Chain - ABCDocument15 paginiSupply Chain - ABCYulia Tri AngganiÎncă nu există evaluări
- Static Timing AnalysisDocument4 paginiStatic Timing AnalysisballisticanaÎncă nu există evaluări
- Catalog AP Merit Installer V4Document264 paginiCatalog AP Merit Installer V4BillÎncă nu există evaluări
- 2019 Husqvarna TE 250i - TE300i Service Repair Manual PDFDocument363 pagini2019 Husqvarna TE 250i - TE300i Service Repair Manual PDFDiego Garagem P7Încă nu există evaluări
- GDS-1000B Quick Start Guide ADocument2 paginiGDS-1000B Quick Start Guide Aketab_doostÎncă nu există evaluări
- XLP Interface V4.0Document3 paginiXLP Interface V4.0Anonymous PedQHSMÎncă nu există evaluări
- B Msgs Server PDFDocument806 paginiB Msgs Server PDFsabkhÎncă nu există evaluări
- Abhishek Aggarwal SEO Specialist Updated CV - 1 3Document3 paginiAbhishek Aggarwal SEO Specialist Updated CV - 1 3dilsonenterprises2022Încă nu există evaluări
- Rail and Safety ConceptDocument4 paginiRail and Safety ConceptJoseÎncă nu există evaluări
- Leak Detection - DC PipeDocument75 paginiLeak Detection - DC Pipeراموندولدولاو50% (2)
- Ez Efi PDFDocument2 paginiEz Efi PDFNathanÎncă nu există evaluări
- Manual TFA 30.3015Document43 paginiManual TFA 30.3015Carlos Ernesto NataliÎncă nu există evaluări
- Final ThesisDocument14 paginiFinal ThesisJyll GellecanaoÎncă nu există evaluări
- Bluetooth KISS TNC PDFDocument12 paginiBluetooth KISS TNC PDFCT2IWW100% (1)
- An Intelligent Algorithm For The Protection of Smart Power SystemsDocument8 paginiAn Intelligent Algorithm For The Protection of Smart Power SystemsAhmed WestministerÎncă nu există evaluări
- ABC Functional Requirements Doc SampleDocument57 paginiABC Functional Requirements Doc SampleSharang Bhasin100% (1)
- PalcoControl CP en PDFDocument7 paginiPalcoControl CP en PDFsulthan ariffÎncă nu există evaluări
- Estadistica Descriptiva 2.ipynbDocument76 paginiEstadistica Descriptiva 2.ipynbADOLFO NAVARRO CAYOÎncă nu există evaluări
- X1 Using VA01 With Digital Call Panel Quick Start ProgrammingDocument4 paginiX1 Using VA01 With Digital Call Panel Quick Start ProgrammingMos CraciunÎncă nu există evaluări
- Core EdifDocument2 paginiCore EdifOsama ElfadniÎncă nu există evaluări
- ITIL TestsDocument54 paginiITIL TestssokzgrejfrutaÎncă nu există evaluări
- Module 1: Introduction To Operating System: Need For An OSDocument15 paginiModule 1: Introduction To Operating System: Need For An OSNiresh MaharajÎncă nu există evaluări
- Problems On Principle of CommunicationsDocument2 paginiProblems On Principle of Communicationsnicdocu100% (1)
- A04 Fabia Symphony CarRadioDocument22 paginiA04 Fabia Symphony CarRadioGoncalo CaetanoÎncă nu există evaluări
- Bootstrap Css Classes Desk Reference BCDocument9 paginiBootstrap Css Classes Desk Reference BCmazer38Încă nu există evaluări
- Sultan Laram 2009CVDocument5 paginiSultan Laram 2009CVSultan LaramÎncă nu există evaluări