S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Swami Vivekananda's 15 Golden Rules For LifeDocument2 paginiSwami Vivekananda's 15 Golden Rules For Lifeabhijitch100% (1)
- PM Risk For DummiesDocument52 paginiPM Risk For DummiesFelix Rinaldi100% (8)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- AABB Sample New Program Business PlanDocument14 paginiAABB Sample New Program Business Planbiospacecowboy100% (1)
- Math Internal Assessment:: Investigating Parametric Equations in Motion ProblemsDocument16 paginiMath Internal Assessment:: Investigating Parametric Equations in Motion ProblemsByron JimenezÎncă nu există evaluări
- SN Conceptual & Strategic SellingDocument34 paginiSN Conceptual & Strategic Sellingayushdixit100% (1)
- Disneyland (Manish N Suraj)Document27 paginiDisneyland (Manish N Suraj)Suraj Kedia0% (1)
- ch03 PowerpointsDocument35 paginich03 PowerpointsBea May M. BelarminoÎncă nu există evaluări
- CPCCCM2006 - Learner Guide V1.0Document89 paginiCPCCCM2006 - Learner Guide V1.0Sid SharmaÎncă nu există evaluări
- WMS WIP PickDocument14 paginiWMS WIP PickAvinash RoutrayÎncă nu există evaluări
- Big Data Processing With Apache SparkDocument17 paginiBig Data Processing With Apache SparkabhijitchÎncă nu există evaluări
- Big Data Processing With Apache Spark - InfoqdotcomDocument16 paginiBig Data Processing With Apache Spark - InfoqdotcomabhijitchÎncă nu există evaluări
- JSP Vulnerabilities and Fixes For DevelopersDocument6 paginiJSP Vulnerabilities and Fixes For DevelopersabhijitchÎncă nu există evaluări
- Unit V GraphDocument37 paginiUnit V GraphabhijitchÎncă nu există evaluări
- Cakephp Report PDFDocument34 paginiCakephp Report PDFabhijitchÎncă nu există evaluări
- OpenMP Tutorial - Lawrence Livermore National LaboratoryDocument75 paginiOpenMP Tutorial - Lawrence Livermore National LaboratoryabhijitchÎncă nu există evaluări
- What Is UEFI, and How Is It Different From BIOSDocument4 paginiWhat Is UEFI, and How Is It Different From BIOSabhijitchÎncă nu există evaluări
- Advantages of Hadoop MapReduce ProgrammingDocument3 paginiAdvantages of Hadoop MapReduce ProgrammingabhijitchÎncă nu există evaluări
- Ubuntu and Hadoop: The Perfect Match: White PaperDocument11 paginiUbuntu and Hadoop: The Perfect Match: White PaperabhijitchÎncă nu există evaluări
- C TestDocument3 paginiC TestabhijitchÎncă nu există evaluări
- Python Vs Fortran in Scientific ComputingDocument2 paginiPython Vs Fortran in Scientific ComputingabhijitchÎncă nu există evaluări
- 7 Awesome Open Source Cloud Storage Software For Your Privacy and SecurityDocument7 pagini7 Awesome Open Source Cloud Storage Software For Your Privacy and SecurityabhijitchÎncă nu există evaluări
- Chakravyuha - A Play by Dr. Pradip BhattacharyaDocument10 paginiChakravyuha - A Play by Dr. Pradip BhattacharyaabhijitchÎncă nu există evaluări
- Hands On With Docker + Openstack: 24 September 2014Document11 paginiHands On With Docker + Openstack: 24 September 2014abhijitchÎncă nu există evaluări
- Linux Advanced File Permissions - SUID, SGID and Sticky BitDocument8 paginiLinux Advanced File Permissions - SUID, SGID and Sticky Bitabhijitch100% (1)
- Project PlanDocument8 paginiProject PlanRodsheen100% (1)
- Limitations of The Study - Docx EMDocument1 paginăLimitations of The Study - Docx EMthreeÎncă nu există evaluări
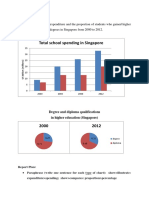
- Total School Spending in Singapore: Task 1 020219Document6 paginiTotal School Spending in Singapore: Task 1 020219viper_4554Încă nu există evaluări
- Stepping Stones Grade 4 ScopeDocument2 paginiStepping Stones Grade 4 ScopeGretchen BensonÎncă nu există evaluări
- Proposal Defense Form Chapter 1 3Document3 paginiProposal Defense Form Chapter 1 3Jason BinondoÎncă nu există evaluări
- Heat and Cooling LoadDocument2 paginiHeat and Cooling LoadAshokÎncă nu există evaluări
- LearnEnglish Reading B1 A Conference ProgrammeDocument4 paginiLearnEnglish Reading B1 A Conference ProgrammeAylen DaianaÎncă nu există evaluări
- 27 EtdsDocument29 pagini27 EtdsSuhag PatelÎncă nu există evaluări
- Charity Connecting System: M.Archana, K.MouthamiDocument5 paginiCharity Connecting System: M.Archana, K.MouthamiShainara Dela TorreÎncă nu există evaluări
- Physical Computing and Android in RoboticsDocument4 paginiPhysical Computing and Android in Roboticsnniikkoolliiccaa100% (1)
- Senior Project Manager Marketing in Toronto Canada Resume Cindy KempDocument2 paginiSenior Project Manager Marketing in Toronto Canada Resume Cindy KempCindyKempÎncă nu există evaluări
- Organizational Behavior - Motivational Theories at Mcdonald's ReportDocument11 paginiOrganizational Behavior - Motivational Theories at Mcdonald's ReportvnbioÎncă nu există evaluări
- EZ-FRisk V 7.52 User Manual PDFDocument517 paginiEZ-FRisk V 7.52 User Manual PDFJames IanÎncă nu există evaluări
- Lesson Plan ComsumerismDocument6 paginiLesson Plan ComsumerismMan Eugenia50% (4)
- 02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxDocument1 pagină02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxMichel van WordragenÎncă nu există evaluări
- Materi Pak ARIEF LAGA PUTRADocument32 paginiMateri Pak ARIEF LAGA PUTRAUnggul Febrian PangestuÎncă nu există evaluări
- Kaizen Idea - Sheet: Suitable Chairs To Write Their Notes Faster & Easy Method While TrainingDocument1 paginăKaizen Idea - Sheet: Suitable Chairs To Write Their Notes Faster & Easy Method While TrainingWahid AkramÎncă nu există evaluări
- Barry Farm Powerpoint SlidesDocument33 paginiBarry Farm Powerpoint SlidessarahÎncă nu există evaluări
- UCOL Online Style GuideDocument8 paginiUCOL Online Style GuideucoledtechÎncă nu există evaluări
- Semi-Conductor Laboratory - MohaliDocument4 paginiSemi-Conductor Laboratory - MohalimanjnderÎncă nu există evaluări
- The Seven Perceptual Learning StylesDocument3 paginiThe Seven Perceptual Learning StylesRamona FloreaÎncă nu există evaluări
- Network Management Systems 10CS834 PDFDocument113 paginiNetwork Management Systems 10CS834 PDFSarfraz AhmedÎncă nu există evaluări