S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Mandelstam Poems Ilya-Bernstein PDFDocument99 paginiMandelstam Poems Ilya-Bernstein PDFablimitabdukhadir100% (3)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Retail Operations ManualDocument44 paginiRetail Operations ManualKamran Siddiqui100% (2)
- Full Download Ebook PDF Introductory Econometrics A Modern Approach 7th Edition by Jeffrey PDFDocument42 paginiFull Download Ebook PDF Introductory Econometrics A Modern Approach 7th Edition by Jeffrey PDFtimothy.mees27497% (39)
- Chapter S1 (Celestial Timekeeping and Navigation)Document28 paginiChapter S1 (Celestial Timekeeping and Navigation)Марко Д. Станковић0% (1)
- Learning Module - Joints, Taps and SplicesDocument9 paginiLearning Module - Joints, Taps and SplicesCarlo Cartagenas100% (1)
- Curti - Female Literature of Migration in ItalyDocument17 paginiCurti - Female Literature of Migration in Italycycnus13Încă nu există evaluări
- Bob Dylan American DreamDocument4 paginiBob Dylan American Dreamcycnus13Încă nu există evaluări
- CLM 104 C 12Document225 paginiCLM 104 C 12cycnus13Încă nu există evaluări
- Writing Journa ArticlesDocument51 paginiWriting Journa Articlescycnus13Încă nu există evaluări
- BOMB Magazine - Dario Fo by Matthew FleuryDocument8 paginiBOMB Magazine - Dario Fo by Matthew Fleurycycnus13Încă nu există evaluări
- Dialogues About A WallDocument7 paginiDialogues About A Wallcycnus13Încă nu există evaluări
- Adorno The Essay As Form PDFDocument13 paginiAdorno The Essay As Form PDFIvan SokolovÎncă nu există evaluări
- Robert Lowell - The EelDocument3 paginiRobert Lowell - The Eelcycnus13Încă nu există evaluări
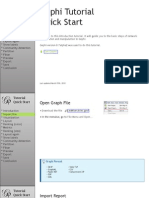
- Gephi Tutorial Quick StartDocument32 paginiGephi Tutorial Quick StartyiorgisÎncă nu există evaluări
- 2012 Polley Netsci Tutorial2Document39 pagini2012 Polley Netsci Tutorial2cycnus13Încă nu există evaluări
- ArguedasDocument2 paginiArguedascycnus13Încă nu există evaluări
- Gephi Tutorial LayoutsDocument37 paginiGephi Tutorial LayoutsSebastian GonzálezÎncă nu există evaluări
- TMDocument56 paginiTMcycnus13Încă nu există evaluări
- Pier Paolo PasoliniDocument8 paginiPier Paolo Pasolinicycnus13Încă nu există evaluări
- Edu-Factory Collection - Toward A Global Autonomous University PDFDocument197 paginiEdu-Factory Collection - Toward A Global Autonomous University PDFcycnus13Încă nu există evaluări
- Pier Paolo PasoliniDocument8 paginiPier Paolo Pasolinicycnus13Încă nu există evaluări
- Ser Da KowskiDocument12 paginiSer Da Kowskicycnus13Încă nu există evaluări
- Europe FederalDocument11 paginiEurope Federalcycnus13Încă nu există evaluări
- Ali FarahDocument1 paginăAli Farahcycnus13Încă nu există evaluări
- Bhabha - DisseminationDocument17 paginiBhabha - Disseminationcycnus13Încă nu există evaluări
- Terzani Letters Against The WarDocument107 paginiTerzani Letters Against The WarnicheloroÎncă nu există evaluări
- Aeternam Requiem CarranoDocument18 paginiAeternam Requiem Carranocycnus13Încă nu există evaluări
- Preparing and Roasting A PeacockDocument1 paginăPreparing and Roasting A Peacockcycnus13Încă nu există evaluări
- Meter HandoutDocument8 paginiMeter HandoutudayanilÎncă nu există evaluări
- Holtz Plates PDFDocument9 paginiHoltz Plates PDFcycnus13Încă nu există evaluări
- OkigboDocument2 paginiOkigbocycnus13Încă nu există evaluări
- Verilog A Model To CadenceDocument56 paginiVerilog A Model To CadenceJamesÎncă nu există evaluări
- Marine-Derived Biomaterials For Tissue Engineering ApplicationsDocument553 paginiMarine-Derived Biomaterials For Tissue Engineering ApplicationsDobby ElfoÎncă nu există evaluări
- Weekly Lesson Plan: Pry 3 (8years) Third Term Week 1Document12 paginiWeekly Lesson Plan: Pry 3 (8years) Third Term Week 1Kunbi Santos-ArinzeÎncă nu există evaluări
- MSDS Formic AcidDocument3 paginiMSDS Formic AcidChirag DobariyaÎncă nu există evaluări
- Alufix Slab Formwork Tim PDFDocument18 paginiAlufix Slab Formwork Tim PDFMae FalcunitinÎncă nu există evaluări
- Rolling TechnologyDocument4 paginiRolling TechnologyFrancis Erwin Bernard100% (1)
- Net Pert: Cable QualifierDocument4 paginiNet Pert: Cable QualifierAndrés Felipe Fandiño MÎncă nu există evaluări
- Understanding Culture Society, and PoliticsDocument3 paginiUnderstanding Culture Society, and PoliticsVanito SwabeÎncă nu există evaluări
- MBA-7002-20169108-68 MarksDocument17 paginiMBA-7002-20169108-68 MarksN GÎncă nu există evaluări
- Jordan CVDocument2 paginiJordan CVJordan Ryan SomnerÎncă nu există evaluări
- Different Principles Tools and Techniques in Creating A BusinessDocument5 paginiDifferent Principles Tools and Techniques in Creating A BusinessLuna LedezmaÎncă nu există evaluări
- Ibragimova Lesson 4Document3 paginiIbragimova Lesson 4Dilnaz IbragimovaÎncă nu există evaluări
- RseDocument60 paginiRseH S Vishwanath ShastryÎncă nu există evaluări
- Distillation ColumnDocument22 paginiDistillation Columndiyar cheÎncă nu există evaluări
- GSE v. Dow - AppendixDocument192 paginiGSE v. Dow - AppendixEquality Case FilesÎncă nu există evaluări
- Chapter 3 Depreciation - Sum of The Years Digit MethodPart 4Document8 paginiChapter 3 Depreciation - Sum of The Years Digit MethodPart 4Tor GineÎncă nu există evaluări
- ProjectDocument22 paginiProjectSayan MondalÎncă nu există evaluări
- Characteristics of Trochoids and Their Application To Determining Gear Teeth Fillet ShapesDocument14 paginiCharacteristics of Trochoids and Their Application To Determining Gear Teeth Fillet ShapesJohn FelemegkasÎncă nu există evaluări
- A Tall Order - Cooling Dubai's Burj Khalifa: FeatureDocument2 paginiA Tall Order - Cooling Dubai's Burj Khalifa: FeatureMohsin KhanÎncă nu există evaluări
- Agency Procurement Request: Ipil Heights Elementary SchoolDocument1 paginăAgency Procurement Request: Ipil Heights Elementary SchoolShar Nur JeanÎncă nu există evaluări
- Carte EnglezaDocument112 paginiCarte EnglezageorgianapopaÎncă nu există evaluări
- Approved College List: Select University Select College Type Select MediumDocument3 paginiApproved College List: Select University Select College Type Select MediumDinesh GadkariÎncă nu există evaluări
- S P99 41000099DisplayVendorListDocument31 paginiS P99 41000099DisplayVendorListMazen Sanad100% (1)
- Tutorial 3 MFRS8 Q PDFDocument3 paginiTutorial 3 MFRS8 Q PDFKelvin LeongÎncă nu există evaluări
- Chapter 10 OutlineDocument3 paginiChapter 10 OutlineFerrari75% (4)
- Black Hole Safety Brochure Trifold FinalDocument2 paginiBlack Hole Safety Brochure Trifold Finalvixy1830Încă nu există evaluări